
Abstract
Trust is widely regarded as a critical component to building artificial intelligence (AI) systems that people will use and safely rely upon. As research in this area continues to evolve, it becomes imperative that the research community synchronizes its empirical efforts and aligns on the path toward effective knowledge creation. To lay the groundwork toward achieving this objective, we performed a comprehensive bibliometric analysis, supplemented with a qualitative content analysis of over two decades of empirical research measuring trust in AI, comprising 1’156 core articles and 36’306 cited articles across multiple disciplines. Our analysis reveals several “elephants in the room” pertaining to missing perspectives in global discussions on trust in AI, a lack of contextualized theoretical models and a reliance on exploratory methodologies. We highlight strategies for the empirical research community that are aimed at fostering an in-depth understanding of trust in AI.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Trust in artificial intelligence (AI)-based systems is a focal concern among researchers and practitioners alike, and increasingly so. At the time of writing, a search for “trust in AI” on Google Scholar returns 157 results for all years until 2017, 1’140 results for the years 2018–2020, and 7’310 results for the years 2021–2023. The surge of interest in how humans trust AI systems is fueled by increasingly capable AI-based technologies that are transforming the way humans work and collaborate in a multitude of society-impacting applications (Jacobs et al. 2021; Chiou and Lee 2021; Lucaj et al. 2023; Shin 2021; Wamba et al. 2021; Feher et al. 2024).
This emphasis on trust builds upon a substantial legacy of prior research focused on trust in technology more broadly (Lee and See 2004; McKnight and Chervany 1996), interpersonal trust (Mayer et al. 1995; Castelfranchi and Falcone 2010), or trust in institutions (Knowles and Richards 2021; Kroeger 2016). Whereas in organizations and interpersonal contexts, trust is considered the cornerstone of effective communication, collaboration in teams, and healthy and positive work cultures (Mayer et al. 1995), in the context of human interactions with technology more broadly, trust is widely regarded as instrumental to enhance effectiveness and efficiency. This is underpinned by a range of desired outcomes of trust, such as successful adoption, acceptance, and appropriate use (Jacobs et al. 2021; Chiou and Lee 2021; Shin 2021; Buçinca et al. 2021). As AI increasingly blurs the distinction between tool and teammate (Rix 2022), a fast-growing research community continues to conduct empirical investigations on trust in AI systems, while engaging in an ongoing discourse on the unique issues and pitfalls surrounding empirical practices and measurement of trust in AI research (Buçinca et al. 2020; Jacovi et al. 2021; Schraagen et al. 2020; Chi et al. 2021; Schemmer et al. 2022). To streamline these discussions, leading academic journals and conferences have introduced initiatives dedicated to the topic. They include “CHI TRAIT” (Bansal et al. 2023) at the ACM Conference on Human Factors in Computing Systems (CHI) or “HRI TRAITS,”Footnote 1 at the ACM/IEEE International Conference on Human-Robot Interaction (HRI). Additionally, Computers in Human Behavior recently organized a special issue on the topic.Footnote 2 Nevertheless, research in this area remains fragmented, in part due to its conceptual heterogeneity (Laux et al. 2023). This fragmentation complicates the comparison of findings across various research domains, presenting a significant challenge to practitioners and policymakers.
The rapid growth of interdisciplinary research on trust in AI offers an opportunity to reflect on this field and place it within a broader historical context. Analyzing publication patterns and trends can help map the development of this research over time and address current discussions pertaining to conceptualization and operationalization of trust in AI within this broader perspective. Moreover, by characterizing its publication patterns and knowledge structure across research domains and over time, researchers could better understand which research trends impede or foster progress in our understanding of trust in human–AI interactions, align research efforts, ultimately leading to the design of AI systems that humans are confident to use and rely upon effectively (Kaur et al. 2022). To facilitate this reflection, this work aims to provide a systematic overview of the empirical research of trust in AI through a comprehensive mapping of over two decades of scientific output. To this end, we employed a mixed-method approach, consisting of bibliometric and content analyses of empirical research measuring trust in AI, thereby shedding light on multiple research trends. Specifically, our contributions are as follows:
-
Based on a comprehensive bibliometric analysis of over two decades of empirical research on trust in AI, encompassing 1’156 core articles and 36’306 cited articles across multiple research domains, we uncover publication patterns, describe the underlying knowledge structure of the field, and examine the most influential articles within each domain. To enrich the quantitative insights, we further conducted a qualitative content analysis of the top 10 % most cited articles per domain.
-
We identify and challenge under-addressed issues within the field, prompting critical questions about these “elephants in the room.” These issues pertain to (a) the research production that is shaped by Western and Global Northern perspectives and driven by technical domains; (b) the rapid diversification of application areas for AI, which hampers in-depth exploration of the concept of trust in AI; (c) the predominantly exploratory research approach that still characterizes its scientific output.
-
We offer practical recommendations that aim to address these limitations by promoting the inclusivity of research on trust in AI, advocating for the development and application of contextualized frameworks, and encouraging systematic investigations to deepen our understanding and measurement of trust in AI.
Our results and recommendations have the potential to significantly influence the future direction of empirical research on trust in AI by encouraging scientific practices to achieve the theoretical clarity and methodological robustness this field deserves. This, in turn, will facilitate the development of theory-grounded and evidence-based policies that effectively foster the social good we commonly refer to as trust in AI.
This paper is structured as follows: In Sect. 2, we provide working definitions of the main concepts of relevance for empirical research on trust in AI. In particular, in Sect. 2.2, we provide an overview of the current state of knowledge on empirical research on trust in AI and introduce the research questions that guide this work. In Sect. 3, we provide an overview over the methodology used in this work, including the search strategy, article selection criteria, and methods used to analyze the data. In Sect. 4, we present the findings from our analyses, which we discuss in Sect. 5. Here, we highlight the “elephants in the room” and propose strategies for future investigations on trust in AI in Sect. 6. Lastly, we summarize our work’s limitations and conclusions in Sects. 7 and 8, respectively.
2 Trust in AI: state of knowledge
2.1 Trust theory: a basis to agree on
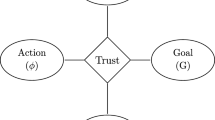
Trust emerges in situations where humans face uncertainty, risk, and interdependence (McKnight and Chervany 2000). At its core, trust arises as a relational process involving a trustor and a trustee, situated within a specific context and driven by a specific goal (Castelfranchi and Falcone 2010). It is now a relevant research topic in human–machine interactions (Lee and See 2004; Mcknight et al. 2011), prominently in the case of AI systems (Jacovi et al. 2021; Chiou and Lee 2021; Toreini et al. 2020). Despite different definitions appearing in the literature,Footnote 3 research agrees that trusting necessarily involves the trustor, i.e., the trusting agent, the trustee, i.e., the trusted agent and the goal and context of the trusting relation.Footnote 4 In particular, there is a growing interest in defining what makes the trustee in an interaction, that is, the AI system, worthy of trust (Jobin et al. 2019; Li et al. 2023; Petersen et al. 2022; Kaur et al. 2022). Authors argue that the trustworthiness of an AI system comprises different properties, such as reliability, robustness, and transparency (Jacovi et al. 2021; Ferrario and Loi 2022; Kaur et al. 2022). Here, research suggests that trust should be grounded in the trustworthiness of the AI. By ensuring user trust is calibrated with the AI’s capabilities, the risk that the user overtrusts and mistrusts the AI is mitigated (Lee and See 2004; Jacovi et al. 2021; Ferrario and Loi 2022). Finally, research often investigates trust in relation to other constructs, including reliance (Lee and See 2004). Reliance is the behavior that the trustor performs after delegating a task to the trustee in order to achieve a goal. For instance, a physician relies on a medical AI by accepting the predictions computed by the system as the result of delegating the task of computing accurate predictions to the AI. As such, reliance can—but does not have to —follow trusting (Lee and See 2004). This concept is applicable also in situations of “reliance without trust”, effectively amounting to reliance accompanied by a minimal, or zero, degree of users’ trust (Loi et al. 2023). Such instances underscore the distinction between trust and reliance, illustrating that while they are interconnected, they are fundamentally separate constructs.
2.2 Reviews of empirical research on trust in AI
A few works have contributed insights for empirical research on trust in AI by reviewing relevant literature. For instance, Glikson and Woolley (2020) performed a literature review of “human trust in AI” with a search on Google Scholar and, subsequently on Business Source Premier, Engineering Village, and PsycINFO, considering the years between 1999 and 2019. Targeting research in organizational science, the review analyzes the determinants of human trust in AI and describes how AI and its integration in organizations differs from other technologies (Glikson and Woolley 2020). Reviewing 150 articles, the authors argue that the (a) representation (robot, virtual, and embedded) and (b) capabilities of an AI system play an important role in how human–AI trust develops (Glikson and Woolley 2020). They further highlight the need to investigate long-term human-AI interactions, calling for more interdisciplinary collaboration to improve research methodologies (Glikson and Woolley 2020).
Furthermore, Vereschak et al. (2021) conducted a systematic review to examine how trust is measured in studies on AI-assisted decision-making, namely, in situations where “humans make decisions based on their own expertise and on recommendations provided by an AI-based algorithm” (Vereschak et al. 2021, p. 327:1). They retrieved 83 articles from the period between 2005 and 2020 using the ACM Digital Library with a search based on keywords (e.g., “artificial intelligence” and “trust”) that did not address specifically the empirical production on trust in AI (Vereschak et al. 2021). Their review shows that trust research employs different definitions that are adopted or adapted from the social sciences (Vereschak et al. 2021). However, these definitions are not appropriately integrated in empirical works, affecting the interpretation and comparison of results across studies (Vereschak et al. 2021), as also remarked by Benk et al. (2022). The authors propose a number of guidelines to improve the empirical study of trust in AI-assisted decision-making. Examples are clarifying the chosen definition of trust in AI, differentiating it from other constructs (e.g., reliance), favoring the analysis of trust in AI in long-term, real-world human–AI interactions and the use of well-established instruments to measure it (Vereschak et al. 2021).
Beyond these traditional reviews, Knickrehm et al. (2023) recently used topic modeling on the abstracts of publications on trust in AI retrieved from Scopus, Web of Science, and the AIS Library. They conducted a broad search on trust in AI, not focusing specifically on empirical research, by searching for the keywords “trust” and “artificial intelligence” in the abstracts of publications. Performing topic modeling with Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al. 2018), they uncovered 56 topics from the abstracts of 3’356 articles published between 1986 and 2022. These topics were then manually collected in 11 clusters, such as “Governance”, “Social Justice” and “Robot–Human Interaction” (Knickrehm et al. 2023). Further, the authors manually identified human-, organization- and AI-related factors in the abstracts, such as confidence, social responsibility, and transparency, which influence trust in AI (Knickrehm et al. 2023).
As highlighted in previous paragraphs, existing reviews of trust in AI have focused on (a) domain-specific aspects of trust (e.g., AI representation within organizational science); (b) empirical methods (e.g., definitions and key elements of experimental protocols); and (c) important factors of trust in AI more broadly. However, trust research continues to be hampered by fragmentation and conceptual heterogeneity (Laux et al. 2023), complicating the comparison of findings across different domains and posing a significant challenge to attempts to review the structure of the field. Consequently, the current state of knowledge regarding trust in AI is insufficient to provide clear guidelines for research advancement. Our work addresses these limitations, as elaborated in the following sections.
2.3 Goal of this work and research questions
Previous related works have explored trust in AI, offering insights into its integration in organizations (Glikson and Woolley 2020), sharing recommendations for empirical studies on AI-assisted decision-making (Vereschak et al. 2021), and providing an exploratory mixed-method analysis of trust in AI using abstracts of relevant work (Knickrehm et al. 2023). Our work differs from theirs in several ways. First, we review empirical trust in AI literature across various research domains and contexts and do not limit ourselves to a particular domain or area of application. In particular, we do not restrict our analysis to the literature on specific AI systems, such as conversational AI or autonomous cars. Second, we employ a mixed-method approach, integrating a bibliometric with a qualitative content analysis. Doing so, we can explore the landscape of empirical research on trust in AI as a research field and characterize the influential works that shape its production over time mapping out the quantitative trends and patterns, as well as to delve deeper into the articles qualitatively. Our goal is to thereby uncover the field’s patterns, trends and gaps and, ultimately, provide a set of strategies for research that are applicable across the various domains and contexts in which trust in AI is empirically explored. Specifically, we address the following research questions:
- RQ1:
-
Which publication patterns characterize the literature on empirical research on trust in AI?
- RQ2:
-
What are the conceptual themes and intellectual citation trends that shape the empirical research community’s understanding and investigation of trust in AI?
- RQ3:
-
How do the overarching patterns and trends manifest within empirical studies and shape investigations on trust in AI?
3 Methodology
3.1 Search strategy and query
We conducted a systematic search of peer-reviewed literature available from 2000 to 2023, using the electronic databases Scopus, Web of Science, ACM Library, PubMed, and IEEE Explorer. Databases were chosen to broadly cover different interdisciplinary lenses on the measurement of trust in AI. The search used a combination of keywords and controlled vocabulary for the concepts of AI, trust and measurement. The search was independently piloted using Scopus and ACM Library by two investigators and subsequently adapted to each database. The identification and extraction of data for the bibliometric analysis conforms to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) protocol (Page et al. 2021). Following prior literature reviews on trust (Vereschak et al. 2021; Glikson and Woolley 2020; Knickrehm et al. 2023)–see Sect. 2.2, we considered all works that referred to their measurement construct as “trust,” thereby including those studies focusing on trusting attitudes, beliefs, intentions, and trusting behaviors, but excluding those that focus on related, but considered distinct constructs, such as “reliance” or “disposition to trust.”
Furthermore, as our work attempts to capture the interdisciplinary nature of empirical research on trust in AI, we wanted to include a variety of terms describing AI systems in our search, but exclude technologies that we deemed out-of-scope of this work, such as automated machinery. Examples of terms that are used in the literature to describe AI systems are “artificial intelligence”, “algorithm”, “machine learning-based system”, or “robot” (Langer et al. 2022). Further, different disciplines may prefer one term over another. Therefore, to mitigate disciplinary biases, a total of eight researchers from diverse disciplines (including Psychology, Information Systems, Marketing, Computer Science, and Human–Computer Interactions) reviewed and refined the terminology used in the search. Our strategy was informed by the framework provided by Glikson and Woolley (2020), which includes three types of AI representations: robots, virtual, and embedded. Following the framework, we differentiate between automation and AI on the basis that traditional automation does not encompass learning processes, a key characteristic of AI.
Our final search query used a combination of terms related to AI, trust, and measurement, resulting in the following query:

The search included English publications from the years 2000 until 2023. The search was carried out in the spring of 2021. Two additional searches were carried out in the spring of 2022 for the year 2021, and in the spring of 2024 for the years 2022 and 2023.
3.2 Article selection
Study selection occurred in three phases. First, two independent investigators conducted the initial screening of a total of 15’144 identified articles, based on titles and abstracts. Next, selected articles were exported into Mendeley, a reference management software, and duplicates removed. Finally, 1’478 full-text articles were screened, using a set of inclusion and exclusion criteria by two independent investigators. All studies were labeled by two independent investigators as meeting the criteria, not meeting the criteria, or possibly meeting the criteria. Disagreements were resolved through discussion until consensus was reached. At the conclusion of this phase, 1’156 articles were selected for inclusion. Figure 1 displays the PRISMA flow diagram detailing the included and excluded articles at each stage of the review process.

PRISMA flow diagram
Articles needed to be (a) published between the years 2000 and 2023 in English language in a journal, conference proceeding, or book chapter; (b) contain quantitative or qualitative empirical research; (c) measure trust of human subjects in AI. Studies were excluded if (a) they measured trust in something other than AI (e.g., the organization providing the AI); (b) measured other constructs than trust, such as reliance or propensity to trust; (c) did not include actual participants (i.e., a simulated study or proposal); (d) did not adequately report the employed methodology. After the full-text review, we extracted the following meta-information from the included articles, using the Scopus API: (a) citation information, including author names, document and source titles, and citation counts; (b) bibliographical information, including affiliations and countries; (c) abstract & keywords, including author keywords; (d) all cited references.
3.3 Analyses
3.3.1 Bibliometric techniques
The quantitative techniques used in this work are based on bibliometrics, which uses meta-data, such as number of citations, references, author information, and keywords, to characterize the scientific landscape of a research field (Culnan 1986; Nerur et al. 2008). To address RQ1, we analyzed the publishing countries and sources with bibliometric techniques, thereby retrieving the most cited articles and influential works, i.e., those that appear most often within the references of the articles in our dataset.
To address RQ2 we used bibliometrics and explored two knowledge structures to gain insights into the scientific landscape of empirical trust in AI research (Liu et al. 2014; Aria et al. 2020; Wamba et al. 2021). We characterized the intellectual structure of the field by analyzing co-citation patterns among articles and sources, thereby determining their degree of relatedness and identifying common schools of thought. We characterized the conceptual structure of the field by analyzing keyword co-occurrences using author keywords, thereby identifying research themes, as well as temporal and thematic trends.
However, we note that bibliometrics does not offer insights into the thematic content of the articles (Salini 2016). Therefore, to complement the statistical findings from the bibliometric analysis, we conducted a thorough content analysis of the most cited works in our database, which we further describe below.
All statistical analyses were conducted using Python and the R bibliometrix package (Aria and Cuccurullo 2017), while all visualizations were generated using VOSviewer (van Eck and Waltman 2009).
3.3.2 Content analysis
To add to the insights from the bibliometric analysis and address RQ3, we conducted a content analysis, in which we systematically coded a subset of our core articles regarding specific categories. Content analysis is a commonly employed method in tandem with bibliometric methods (Arici et al. 2019; Ridwan et al. 2023; Enebechi and Duffy 2020). Whereas bibliometrics offers quantitative insights into the literature, such as publication patterns, citation networks, and trends over time, content analysis complements this by allowing to interpret the use of citations within the articles. Together, this mixed-method approach provides a more holistic overview over the research landscape. First, building on prior works (Fahimnia et al. 2015; Zhao et al. 2023; Corallo et al. 2019), we selected a representative subset of articles to analyze. To derive the representative subset, we retrieved the ten percent most cited articles for each discipline, ensuring a minimum of five and a maximum of ten entries per discipline. This method accounts for the variations in scholarly output and citation frequencies across different disciplines (Cerovšek and Mikoš 2014; Nielsen and Andersen 2021). Articles were annotated, using coding categories that have been generated from prior literature reviews and based on the findings from the bibliometric analysis.
4 Results
4.1 Overview
Our search resulted in a core dataset of 1’156 articles, citing 36’306 articles, which comprise the “cited dataset”. The core dataset covers a wide range of disciplines, including the physical, social, and life sciences. We show the distribution of research domains in Table 1. The majority of articles (57.8%) originate in technology-focused research domains, such as human–robot interactions, computer science, or robotics and engineering. Publications in social sciences and psychology contribute to 17.8% of the total number of retrieved articles. In addition, a few articles originate from transportation and business, management, and marketing. In Fig. 2, we show the number of articles in the core dataset per year and their year-to-year growth rate. In particular, Fig. 2 shows a sustained year-to-year growth in the period 2011–2018, followed by a steep increase in the number of articles focused on empirical research on trust in AI in 2021. However, the growth rate has decreased in 2022 and 2023.

Article count and year-to-year growth rate in the core dataset (2013–2023)
4.2 Publication patterns (RQ1)
4.2.1 Publishing countries
In Table 2, we show the distribution of the top 10 publishing countries in the core dataset. We identified the publishing country of each article, by retrieving the country of the respective corresponding author. Articles from the United States, Germany, and the United Kingdom comprise for slightly more than 56% of all publications in the core dataset. About 46% of all articles in the cited dataset originate from those three countries instead. About one third of publications in the core, and nearly one quarter of the cited datasets originate from the remaining countries. Notably, 80.5% of the articles in the core dataset originate from Global North countries, characterized by the acronym WEIRD (Western, Educated, Industrialized, Rich, Democratic).
4.2.2 Publishing sources
The majority (56.0%) of articles in the core dataset are journal publications, followed by conference proceedings (39.1%) and book chapters (4.9%). In Table 3, we show the top 10 publishing sources in the core and cited datasets, together with their number of citations in the core and cited datasets, as well a their Hirsch Index (Hirsch 2005). About 23% of these publications are distributed across four conferences (HRI, RO-MAN, CHI, IUI) and a conference proceedings series (Lecture Notes in Computer Science). However, their representation in the cited dataset is minimal. Close inspection reveals a “long tail” of 155 distinct sources, illustrating the extent of research dispersion of trust in AI research across diverse application areas. In Fig. 6 in the Appendix, we display the distribution of these sources, highlighting the “core” set of sources in accordance with Bradford’s law (Bradford 1985; Brookes 1969). Bradford’s law is a bibliometric principles that states that if publishing sources in a field are sorted by their productivity, they can be divided into a productive core, followed by several zones of progressively less productive publishing sources (Bradford 1985).
4.2.3 Most cited core articles
In Table 4, we show the top 10 most cited articles in the core dataset. The most cited work appears in the premiere conference on knowledge discovery and data mining (ACM SIGKDD) (Ribeiro et al. 2016) and focuses on machine learning (ML) modeling. In that article, Ribeiro et al. introduce LIME (Local Interpretable Model agnostic Explanations), which is an explanation method for the predictions of ML models. Further, they provide some examples of empirical studies where the effects of LIME on ML model users’ trust are analyzed. However, the authors refrain from defining the construct “trust”, measuring it by asking study participants questions, such as “would you trust this model prediction?” or assessing which classifier is chosen, therefore “trusted”, among different choices (Ribeiro et al. 2016). In the second most-cited work in Table 4, Choi and Ji generalize the Technology Acceptance Model including items, such as perceived ease of use and trust, to study users’ adoption of autonomous vehicles (Choi and Ji 2015). Trust in autonomous vehicles is measured adapting items from existing works in the domains of online shopping and electronic commerce (Gefen 2013; Pavlou 2003). As a result, participants in Choi and Ji’s study are asked to rate the statements “Autonomous vehicle is dependable,” “Autonomous vehicle is reliable” and “Overall, I can trust autonomous vehicle” on a Likert scale to measure their levels of trust in autonomous vehicles—see Table 1 in (Choi and Ji 2015). Similarly, in their work, Waytz et al. (2014) focus on autonomous vehicles. In a study with a driving simulator, the authors measured participants’ self-reported trust in the simulated vehicle using an ad hoc questionnaire comprising eight items, which included “how much [the participants] trust the vehicle to drive in heavy and light traffic conditions, how confident they are about the car driving the next course safely” (Waytz et al. 2014). In addition, behavioral and physiological measures, e.g., number of distractions during the simulation and heart rate change, are analyzed in relation to the self-reported trust levels (Waytz et al. 2014). Interestingly, the remaining most cited works are predominantly recent publications, with three articles focusing on the topic of transparent and explainable AI systems (Shin 2021; Zhang et al. 2020; Yin et al. 2019).
4.2.4 Influential cited articles
The results of the analysis of citation trends in the cited dataset reveal ten most influential theoretical contributions, as seen in Table 5. One quarter of all articles in the core dataset cite the seminal work by Lee and See (2004), where a conceptual model of trust in automation is introduced and the concept of trust calibration (correspondence between trust and automation capabilities) is introduced. The authors employ a definition of automation as “technology that actively selects data, transforms information, makes decisions, or controls processes” (Lee and See 2004, p.50). While their definition is broad, the authors focus on technologies in work-related settings, with costly or catastrophic consequences when inappropriate or mis-calibrated trust leads to disuse or misuse (e.g., automated navigation systems, autopilots, or aviation management systems). Moreover, highly cited articles include the meta-analysis of factors affecting trust in human-robot interactions by Hancock et al. (2011) (16.4%) and the work by Jian et al. (2000) (13.5%) that introduces an empirical scale to measure trust in automation. Hancock et al. identify human-, environment-, and robot-related factors that contribute to trust in human–robot interactions (Hancock et al. 2011), while Jian et al. develop a trust measurement scale by asking university students to rate how certain words relate to (a) trust in general; (b) trust between people; and (c) trust in “automated systems.” A cluster analysis revealed 12 factors of trust in automation, which were subsequently used to build the scale. It is important to note, however, that the scale was not validated by the authors (Jian et al. 2000). Further, Table 5 shows that the majority of influential articles originate in the human factors and ergonomics domain. Most contributions propose theoretical frameworks for understanding trust, followed by comprehensive reviews of factors that influence trust across various contexts, and, finally, empirical studies that quantify and analyze trust using experimental methods.
An investigation of citation trends over time revealed that the works by Lee and See (2004) and Parasuraman and Riley (1997) remain the most cited by the manuscripts in the core dataset across all time periods. Interestingly, the work by Mayer et al. (1995) was not highly cited before 2012 and became the third most cited one in 2021, indicating a renewed interest in this work. An illustration of the citation trends of the five most influential works can be seen in Fig. 8 in the Appendix. Additionally, we analyzed the relative importance of these influential articles across different research domains. For instance, the work by (Lee and See 2004) is particularly significant for HCI research, while the work by (Hancock et al. 2011) holds greater importance for HRI. In contrast, for the less represented research domains, such as Tourism and Law, and Public Policy and Administration, these works do not appear influential. The results of this analysis are visualized in a heatmap shown in Fig. 7 in the Appendix.
4.3 Intellectual structure (RQ2)
To analyze the intellectual structure of empirical trust in AI research, we investigated the co-citation patterns within the cited dataset. We identified two units of analysis: (a) co-cited articles; and (b) co-cited publishing sources. The former allows us to situate influential works in the overall structure of cited articles, while the latter allows us to situate publication outlets among other domains.
4.3.1 Co-cited articles
In Fig. 3, we show the network of articles from the cited dataset for the co-citation analysis. The influential works listed in Table 5 are grouped into two of three primary clusters, with eight out of ten articles belonging to the same cluster. At the center of Fig. 3, the most highly connected and central nodes include the works by Lee and See (2004), Mayer et al. (1995) and Hoff and Bashir (2015). These studies not only have the highest number of co-citations but also serve as a bridge connecting the different clusters. For visibility, we only show the influential works. However, we note that the cluster in blue includes more recent works, including the works by Miller (2019) and Ribeiro et al. (2016), as well as the work by Dietvorst et al. (2018).

Network visualization of frequently co-cited articles. Each node represents a specific article. Thicker links represent a higher number of co-citations, while larger nodes indicate a greater number of occurrences
4.3.2 Co-cited publishing sources
To situate publication outlets of influential works in the overall intellectual structure of cited articles, we analyzed co-citation links between sources (publication outlets), which indicates how the different domains of the co-cited works relate to each other. As seen in Fig. 4, three main clusters emerge. The first cluster (in red, bottom left), called “human factors and ergonomics,” sees Human Factors as being the most relevant and connected publishing outlet. It is the journal where the influential works Lee and See (2004); Hancock et al. (2011); Parasuraman and Riley (1997); Hoff and Bashir (2015) shown in Table 5 are published. Additionally, the cluster includes works from the International Journal of Social Robotics, which are highly co-cited within the network. The second cluster (in green, right), called “management, technology and economics,” contains outlets focused on humans interacting with computer systems with application to business, marketing and management. Among them Computers in Human Behavior shows the highest degree of connectivity. In particular, Academy of Management Review belongs to this cluster; the influential work Mayer et al. (1995) is published there. The final cluster (in blue, top right), called “Computer Science,” includes premier conference outlets, such as CHI, IUI, and FaccT. Two smaller clusters appear in the background and comprise a few sparse nodes, which include Transportation Research and the Journal of Communication. These outlets appear less frequently and are less connected to others in the network.

Network visualization of frequently co-cited sources (cited dataset). Each node represents a source in the cited dataset. Thicker links represent a higher number of co-citations, while larger nodes indicate a greater number of occurrences

Keyword co-occurrence network based on titles and abstracts. Subfigure (a) shows the co-occurrence and frequency of keywords in the dataset. Subfigure (b) shows the temporal evolution of the keyword co-occurrence network for the years 2019–2023
4.4 Conceptual structure (RQ2)
In the following paragraphs, we explore the research themes that emerge from keyword co-occurrences within the core dataset before commenting on recent trends. Both analyses are displayed in Fig. 5.
4.4.1 Research themes
The keyword co-occurrence network is displayed in subfigure (a) of Fig. 5. Results of the keyword co-occurrence analysis revealed several topic clusters, which can be summarized into four main research themes (RT). The topics and themes provide an overview of the breadth of empirical research on trust in AI over time. AI systems that have been investigated over time range from automated fault management (Lorenz et al. 2002), recommender systems (Pu and Chen 2006) to robots (Hayashi and Wakabayashi 2017) and automated vehicles (Ruijten et al. 2018). Examples of most recent systems include decision-support tools (Yin et al. 2019) and explainable AI (Zhang et al. 2020).
For convenience, the researchers assigned labels to each theme. We comment on them in what follows:
RT1: Interactions with robots. This theme is broadly focused on interactions with embodied robots in diverse settings, such as service and security robots, e.g., (Meidute-Kavaliauskiene et al. 2021; Babel et al. 2021; Inbar and Meyer 2019), social robots, e.g., (Guggemos et al. 2020; Kim et al. 2013), or robots in emergency situations (Robinette et al. 2016). For instance, Inbar and Meyer (2019) study trust in autonomous “peacekeeping” robots in shopping malls to understand the willingness of humans to cooperate with them.
Research in this theme also examined different types of embodiments, such as humanoid (Natarajan and Gombolay 2020) or non-humanoid robots, including suitcase-shaped robots to support the navigation of users with loss impairment Guerreiro et al. (2019). This theme also includes the highly cited works Freedy et al. (2007) and Salem et al. (2015). This latter examines how the reliability and personality traits of robotic home companions affect trust in them.
RT2: Interactions with multimodal and collaborative systems. Research in this theme focuses on interactions with autonomous and multimodal systems, where collaboration, coordination, or teamwork is crucial, such as when operating autonomous vehicles or devices in military operations. AIs in this theme include robotic devices (Nikolaidis et al. 2015), self-driving cars, or other autonomous vehicles (Waytz et al. 2014), as well as unmanned vehicles (Mercado et al. 2016) and abstract autonomous agents (Dekarske and Joshi 2021). Research in this theme may rely on simulations, given the difficulty of conducting field studies in high-risk settings. For instance, Freedy et al. (2007) develops a simulation environment to test the performance of mixed human-robot teams in a variety of situations, including military ones (Freedy et al. 2007). The keyword analysis further highlights the importance of specific human factors that are crucial in shaping successful human-AI collaboration, including appropriate reliance, situation awareness, perceived risk, cognitive load, shared mental models, and information quality or transparency.
RT3: AI-assisted decision-making. Research in this theme broadly focuses on decision-making under uncertainty with the aid of abstract “algorithms” or decision-support systems. They include healthcare or other high-risk applications and focus on what the literature considers as “modern” AI systems, e.g., machine learning models (Yin et al. 2019), deep-learning-based systems, artificial intelligence (systems) (Yang et al. 2019), or decision-support systems. Research in this stream is interested in fostering appropriate levels of trust in AIs, in order to optimize (joint) performance. For instance, Yin et al. (2019) examine how a model’s stated performance affects people’s understanding and trust in it. This theme includes the highly cited work Ribeiro et al. (2016). Keywords in this theme include “explainable AI” (Zhang et al. 2020; Kenny et al. 2021; Yang et al. 2020) “interpretability” (Kaur et al. 2020), as well as “trust calibration” (Yang et al. 2020).
RT4: AI in consumer settings. This theme includes research on the use of AIs in the consumer context, which includes recommender systems (Pu and Chen 2007; Zanker 2012), intelligent tutoring systems (Wang et al. 2020), chatbots (Nadarzynski et al. 2019), and other conversational agents (Hoegen et al. 2019). Research explores how various design factors may affect trust and other human factors, such as usability, user experience, or satisfaction. Desired outcomes include increased technology acceptance or adoption (Hegner et al. 2019), or purchase intentions. For instance, Zanker (2012) conducted an online experiment to study the effect of the provision of explanations on trust in and intention to use a recommender system for spa resorts. Here, the authors operationalize the construct trust in AI as trust in information provision by the recommender system (“I trust in the information that I receive from the [recommender system]”) and worry about data usage (“I do not worry about the use of my input data to the [recommender system]”).
4.4.2 Recent trends
Recent trends are visualized in the keyword co-occurrence network in subfigure (b) of Fig. 5. An analysis of the development of the conceptual structure over the last five years in our dataset (2019–2023) reveals a number of additional trends. First, the visualization reveals that numerous keywords have emerged within the past two years alone, signifying a phase of rapid development in AI research. Reflected in these developments are, among others, the impact of the COVID-19 pandemic and advancements in novel technologies like large language models, mixed reality, and voice assistants. Additionally, there’s a growing emphasis on critical themes, such as explainability, transparency, and fairness in AI. For example, Laxar et al. (2023) explore the influence of explainable clinical decision support systems on physicians’ trust in decision support systems in the context of rapid triage decisions, such as those that impacted COVID-19. Similarly, Meidute-Kavaliauskiene et al. (2021) examine how fear of COVID-19 affects trust and intention to use airport service robots. Moreover, Wu et al. (2023) explore students’ trust and usage intentions in the context of interactions with ChatGPT. Overall, topics related to RT1, such as human–robot interaction, as well as recommender systems in RT4 have an older average publication year, while topics related to RT3 have a more recent average publication year.
4.5 Content analysis (RQ3)
In the following, we report our findings from the content analysis of the 128 most cited articles in our core dataset. We split them into elements pertaining to (a) theoretical foundation and (b) research design.
4.5.1 Theoretical foundation
In nearly half of the articles (N = 56, 43.8%), no theoretical model of trust in AI is applied. That is, in these works, the authors measure “trust in AI”, but do not formulate hypotheses to motivate their empirical studies and do not relate their findings to any established theory on trust in human–AI interactions. 30 of these articles originate in technical research domains, such as HCI, HRI, Computer Science, while the rest is distributed across non-technical domains, such as Marketing, Health, and Law, Public Policy and Administration. Often, these works explore whether or to what degree a change in trust can be observed when interacting with AI system featuring different design elements (Kaur et al. 2020; Yang et al. 2017; Cai et al. 2019; Ribeiro et al. 2016; Salem et al. 2015).
Of the remaining 73 articles, 38 (30.0%) extend a theoretical model to include trust in technology or a system. Specifically, the Technology Acceptance Model or TAM is used by 13 studies (Pavlou 2003) and the Unified Theory of Acceptance (UTAUT) (Slade et al. 2015) is used by 10 studies. The remaining articles formulate hypotheses based on theories that are not directly related to trust, such as the the Computers are Social Actors (CASA) theory Nass et al. (1994), used by 5 studies, or based on prior empirical works.
Only six articles explicitly formulate hypotheses about trust in AI that are grounded in theoretical models of trust. For example, Zhang et al. (2020) build on theoretical works on trust in automation, including that of Lee and See (2004). Based on these works, the authors posit that algorithmic confidence information and explanations would have a positive effect on trust calibration in the context of AI. The authors use behavioral measure of trust (i.e., participants’ agreement and switch percentage when presented with algorithmic advice), to model Lee and See (2004)’s concept of trust calibration. Their findings indicate that explanations can improve trust calibration. However, in their discussion section, they do not explicitly relate their findings back to theoretical considerations by Lee and See (2004).
Additionally, some works justify measuring trust solely by referring to empirical trends. For instance Choi et al. (2011, p.131) state “[t]rust, perceived usefulness, and satisfaction are the most widely used constructs for measuring user evaluations.” Similarly, Rau et al. (2009, p.131) state “[Situation awareness, self-confidence, subjective workload, and trust] are typically mentioned in the literature as critical for assessing human–robot team performance.” Finally, we note that, while the theoretical underpinnings of trust are frequently introduced in the opening sections of the 128 most cited articles in the core dataset and trust is subsequently measured, an in-depth discussion on how these findings improve our theoretical understanding of trust is frequently lacking in articles’ discussion and conclusion sections.
4.5.2 Research design
The vast majority of the 128 most cited articles include a single study (N = 108, 84.4%) with a one-time measurement of trust in AI (N = 88, 68.6%). Exceptions include the work by Zhang et al. (2021) who conducted three experiments to compare perceptions of human vs. robo-advisors in the context of financial services, or the work by Buçinca et al. (2020), who conducted three experiments to study the misleading nature of proxy tasks in evaluating explainable AI systems.
Furthermore, quite a few studies develop their own questionnaire items (N = 35, 27.3%). However, the majority of studies (N = 74, 57.8%) use standardized questionnaires. Among these, the questionnaire by Jian et al. (2000), see Table 5, is the most used (N = 17). The rest of the studies show a diverse range of measurement sources (51 unique sources), with each source typically cited by no more than one or two studies.
Lastly, trust is frequently measured among several variables, with human performance (N = 33, 25.8%) being the most common. A performance-related keyword measured in four studies is compliance. Other variables describe (a) attitudes toward the AI, e.g., “perceived usefulness” (N = 16, 12.5%), and “perceived ease of use” (N = 14, 11.0%); (b) personal or situational factors, e.g., perceived risk (N = 11, 8.6%), cognitive load (N = 5, 4.0%), and (c) perceptions of various AI capabilities, including transparency and explainability (N = 10, 7.8%), and “intelligence” (N = 9, 7.0%).
5 Discussion: the elephant(s) in the room
In the following, we identify key trends from our analysis of empirical research on trust in AI. These trends highlight critical, often overlooked issues, or “elephants in the room,” that researchers, practitioners, and policymakers need to address. We formulate these issues into question. In Sect. 6, we propose strategies for their resolution in a subsequent section.
5.1 Publication patterns: is trust in AI WEIRD and techno-centric?
Our descriptive analysis of the publication patterns reveals a dynamically evolving research landscape, characterized by a steady increase in publication volume, which indicates a growing interest in trust in AI. The research production appears to have peaked in 2021, with the subsequent decline in growth rate suggesting possible stagnation. The research production has primarily been driven by a Western- and global North-led discourse, otherwise described by the acronym WEIRD, which mirrors a broader issue known as the “AI divide” (Yu et al. 2023), wherein a few countries lead the research and development of AI. Moreover, the distributions of bibliographic records and most cited articles in the core dataset show that empirical research on trust in AI is mostly driven by technical domains, e.g., computer science. This trend is amplified by the growing emphasis on explainable AI. This research in turn primarily builds on seminal articles from trust in automation research, as shown by the analysis of the influential articles in the cited dataset (Lee and See 2004; Hancock et al. 2011; Jian et al. 2000; Parasuraman and Riley 1997).
These findings prompt several important questions. First, what values characterize WEIRD perspectives and are therefore embedded in the empirical research? For instance, do studies assume that technological advancement is inherently beneficial and, thus, follow a strategic agenda (Laux et al. 2023)? Second, what perspectives are overlooked? Are we missing insights and driving factors of trust from non-Western cultures or marginalized communities? Third, what techno-centric methodologies and assumptions underpin the empirical research? For instance, is trust merely being utilized as an additional performance metric of AI for optimization?
Not addressing these questions will likely perpetuate the dominance of WEIRD perspectives, promoting values and and relying on assumptions that may not be globally applicable. This can exacerbate the AI divide, leading to policies and technologies that fail to consider the needs of non-Western communities. Valuable insights from these perspectives will be missed, hindering the development of globally effective trust frameworks. The research’s current techno-centric focus risks reducing trust to a mere performance metric, overlooking broader social, ethical, and humanistic aspects. Additionally, the observed peak in research production in 2021, followed by a decline in the year-to-year growth rate, suggests potential stagnation. Without integrating diverse perspectives, the field may struggle to innovate and address emerging challenges, limiting its evolution and societal impact.
5.2 Knowledge structures: is trust in AI a moving target?
The intellectual structure of empirical research on trust in AI is shaped by three main disciplinary perspectives: human factors and ergonomics, social robotics, and management, technology and economics, with the former being the most prominent. Despite their distinct viewpoints, e.g., trust between humans in organizations (Mayer et al. 1995) versus trust of human operators in automation (Parasuraman and Riley 1997), the frequent co-citation and centrality of a few influential works indicate their substantial impact on the field.
Additionally, the research themes emerging from the conceptual structure analysis underscore the diversification of application areas for AI. Investigating trust in AI therefore represents a continuously evolving challenge within empirical research, largely because technological advancements are constantly shifting the landscape. On the one hand, these findings indicate a collective interest in consolidating an overarching understanding of trust in AI and a continuous interdisciplinary relevance of the seminal articles. On the other hand, these influential works often serve as foundational references rather than to inform and contextualizing the study. For examples, the influential works are leveraged to inform the definition of trust in the introductory section of an article but are not discussed further, suggesting a lack of deeper theoretical integration to advance the field.
Collectively, this prompts the question whether trust in AI may be a “moving target” where researchers feel pressured to keep up with continuous technological advancements and spend insufficient time exploring any single area of trust in AI and its connection to the theoretical foundations in depth. Indeed, novel technologies, such as generative AI, may exacerbate the challenge posed by the rapid pace of AI development, which often surpasses the pace of scientific publication. Moreover, the contexts in which AI technologies operate differ significantly from traditional contexts typically seen in trust-related automation research or interpersonal settings. Historically, the former traditional context is characterized by automating and facilitating prolonged human tasks in work settings (Chignell et al. 2022; Hoff and Bashir 2015). Here, relational dynamics such as the articulation of intent or alignment of goals were often secondary, as human operators retained control over well-defined tasks (Chignell et al. 2022; Chiou and Lee 2021). In contrast, the emerging technology landscape shows the growing importance of AI systems that assume various roles within dynamic socio-technical contexts, such as explainable AI (Papagni et al. 2022). It remains an open question if and to what extent the influential works are applicable to the broad spectrum of human-AI interactions. Not addressing this gap could result in a limited and fragmented understanding of trust across different disciplinary perspectives, such as human factors and ergonomics, social robotics, and management, technology, and economics. While influential works have substantially impacted the field, their use often remains superficial, serving as foundational references without deeper theoretical integration. This can hinder the development of a cohesive framework for understanding trust in AI. As AI technologies rapidly evolve, researchers may feel pressured to keep up with advancements, leading to insufficient exploration of any single area and its theoretical underpinnings. This challenge is exacerbated by novel technologies like generative AI, which outpace scientific publication rates. Without addressing these issues, the field risks stagnation and a lack of progress in effectively understanding and fostering trust in AI.
5.3 Qualitative content analysis: is “trust” simply a convenient word?
Our content analysis additionally reveals a gap between the theoretical frameworks introduced by influential works and their use in empirical works. In fact, despite the widespread (co-)citation of the influential works, the vast majority of articles in the core dataset do not formulate a theoretical model or hypotheses on trust in AI based on these works, and a large proportion do not introduce any model of trust. Moreover, trust is often measured along other variables, most commonly performance, but without connecting them theoretically. Additionally, results on trust are often only briefly discussed, leaving readers without a deeper exploration of the concept and without a clear perspective on the reproducibility of results or their generalizability.
Overall, these findings suggest that empirical research on trust in AI has primarily adopted an exploratory approach that still persists after more than two decades of active contributions. Exploratory research, while highly valuable for research to flourish, usually serves as a preliminary, less expensive, at times less reproducible approach aimed to point toward promising directions, which can then be exploited in extensive studies (Shiffrin et al. 2017). It is expected to mature and either inform translational studies that turn discoveries into applications, or to inform development of theoretical frameworks (Shiffrin et al. 2017). However, a large proportion of empirical works on trust in AI contain only a single study to evaluate trust, replicating the finding by Vereschak et al. (2021). Additionally, trust is often operationalized using a diverse array of measures, many of which are adapted from other research fields or created as ad hoc single-item questionnaires. Indeed, the current state of research prompts the question whether “trust” is not simply being used as a convenient word—a concern previously raised by Hoffman (2017)—and one which does not predict whether or not people will use AI or appropriately rely on it, as highlighted by Kreps et al. (2023). Without addressing these issues, trust in AI may continue to be used as a convenient but conceptually shallow term, failing to provide meaningful insights into user behavior and the effective deployment of AI technologies. Prominent efforts, such as calibrating trust in the trustworthiness of AI (Lee and See 2004; Jacovi et al. 2021), would remain affected by inconsistently measured outcomes.
6 Strategies for future work
6.1 Considering missing viewpoints and hidden assumptions
Understanding trust in AI from diverse perspectives is crucial, especially for effective global policies, particularly as AI performance continues to advance and integrate into various critical societal applications (Feher et al. 2024). In fact, a recent study by the University of Queensland and KPMG found significant trust disparities in AI among emerging economies like Brazil and India, compared to Western countries (Gillespie et al. 2023). Cultural background influences trust (Rau et al. 2009), but these variations are not well understood. To address this, we recommend fostering inclusive discussions, supporting partnerships with underrepresented regions, and developing and applying uniform measurement tools.Footnote 5 Here, we endorse Linxen et al. (2021)’s recommendations for varied participant samples and cross-cultural study replication. Additionally, we recommend that technical fields actively engage in critically examining the assumptions driving their research production.
6.2 Contextualizing trust in AI
A key challenge is that a one-size-fits-all solution for integrating theoretical models of trust with diverse, evolving AI technologies, is not feasible, as evidenced by the ongoing lack of tailored approaches in current research. Contextualizing theoretical models to different AI systems is crucial for developing an in-depth understanding of trust in AI and addressing unexpected findings (Hong et al. 2014), especially given recent inconclusive results on trust in the domain of explainable AI research (Langer et al. 2022). We recommend avoiding “generic overviews” on trust in AI and instead focusing on specific theoretical contributions that inform empirical studies. This involves:
-
1.
developing and integrating context-specific models of trust, tailored to the distinctive characteristics of various AI systems and dynamics of human-AI interactions;
-
2.
assessing the applicability of these models and analyzing the outcomes of their empirical testing across various interactions and domains.
To provide more concrete guidelines for context-specific theorizing specific to the context of trust in AI, we have adapted the recommendations outlined by (Hong et al. 2014) to fit this particular domain. These adapted guidelines are thoroughly detailed in Table 7 in the Appendix.
6.3 Shifting from exploratory to explanatory research
In addition to the assertion that the absence of theory and robust data leaves AI researchers unprepared to test specific hypotheses in novel contexts (Leichtmann et al. 2022), our findings indicate a different challenge: the dynamic nature of AI itself complicates the development of a theory of trust in AI. This is further perpetuated by newer developments in generative AI. We argue that a strategic shift from primarily exploratory research to more robust and explanatory studies is necessary for the field to mature. To do so, empirical trust in AI research can learn from other domains that have faced similar challenges, such as research in Information Systems (Dubé and Paré 2003; Djamasbi et al. 2018). Possible strategies include (a) the formulation of clear (“why”-)questions on trust that delve into explanatory aspects; (b) the promotion of multiple-study design (Vereschak et al. 2021), and (c) use of single studies to challenge existing assumptions instead. Furthermore, the consistent implementation of standardized methodologies and best practices is essential for harmonizing research efforts in this area.
We have summarized the analyses emerging from our work, the elephants in the room, and our strategies for future empirical research on trust in AI for the interested reader in Table 6.
7 Limitations
While this study aimed to provide a comprehensive overview over two decades of empirical trust in AI research, we wish to acknowledge a number of limitations of this work. First, although we made considerable efforts to ensure an exhaustive literature search on empirical trust in AI research, it is still possible that our analysis may have been limited by researcher’s biases or oversights. For instance, our search criteria may have inadvertently excluded relevant AI technologies or disciplinary perspectives. Second, the focus on mapping the research landscape through quantitative measures limited this study’s ability to explore certain nuances. For example, it did not consider the potential influence of different trustor types (e.g., user vs. patient) that may be characteristic of various disciplinary approaches. Additionally, it did not examine different causal directions in experimental studies, such as trust being treated as a dependent or independent variable. Third, our full analysis took into account research until and including 2023 and may not account for most recent developments on trust in AI. Nevertheless, recognizing that the breadth of novel technologies is continuously evolving, we believe our analysis offers a timely perspective of trends and patterns that can inform future research. We invite the research community to build upon and extend our findings.
8 Conclusion
The growing interest in trust in AI has led to the establishment of an empirical research community focused on the study of this topic. To inform the design of safe and reliable AI that people may trust, it becomes increasingly important that the research community synchronize their efforts and align on the path ahead. This work aimed to contribute to this endeavor by conducting a bibliometric and content analysis of over two decades of empirical research on trust in AI. Based on a thorough mapping of the research landscape, revealing citation patterns, trends and their implications for the research community, we highlight a number of trends and unsolved issues that we named “elephants in the room.” Future research should prioritize the in-depth understanding of the construct ‘trust in AI’ through the development of inclusive, methodologically robust, and contextualized theoretical frameworks of trust in human–AI interactions. The consistent use of theoretical models and robust methodologies, such as clear explanatory questions on trust and multiple-study designs, is essential for harmonizing research efforts and increasing the maturity of the trust in the AI field. Further it will also promote theoretically sound and evidence-based policies for a responsible use of this technology. We hope that this work contributes to furthering research on trust in AI and paves the way forward toward the development and design of AI systems people may use and safely interact with.
Pre-publication versions
This manuscript is based on work that has been shared as a non-archival contribution at the 2023 Workshop on Trust and Reliance in AI-Assisted Tasks at the CHI conference on Human Factors in Computing Systems (https://chi-trew.github.io/#/2023). Furthermore, a preprint, titled “Two Decades of Empirical Research on Trust in AI: A Bibliometric Analysis and HCI Research Agenda,” was made publicly available prior to the submission of this manuscript, providing an early insight into the research findings discussed herein. The arXiv preprint can be accessed via the following identifier: arXiv:2309.09828.
Data Availability
The datasets used for the analyses are available on OSF: https://osf.io/5k4rf/?view_only=2daf814f14b44c9fa6ef26ee2d0b5144.
Notes
https://sites.google.com/view/traits-hri-2022.
https://www.sciencedirect.com/special-issue/102LJP9BFH9.
The context and the goal of trusting remind us that we do not usually trust others in every possible way. I may trust my experienced dentist to perform a root canal flawlessly, but not to perform a heart surgery. Likewise, I may trust my AI-based health coach to help me lowering cholesterol levels, but not suggesting dating advice.
Note, for example, that the German translation of the questionnaire by Jian et al. (2000) recommends dividing trust and distrust into separate factors (Pöhler et al. 2016), in contrast to the original English version, which considers them as opposites of the same factor (Jian et al. 2000; Spain et al. 2008), hindering comparability.
References
Aria M, Cuccurullo C (2017) Bibliometrix: an R-tool for comprehensive science mapping analysis. J Informetrics 11:959–975
Aria M, Misuraca M, Spano M (2020) Mapping the evolution of social research and data science on 30 years of social indicators research. Soc Indic Res 149:803–831
Arici F, Yildirim P, Caliklar Şeyma, Yilmaz RM (2019) Research trends in the use of augmented reality in science education: content and bibliometric mapping analysis. Comput Educ 142:103647
Babel F, Kraus J, Hock P, Asenbauer H, Baumann M (2021) Investigating the validity of online robot evaluations: comparison of findings from an one-sample online and laboratory study. In Companion of the 2021 ACM/IEEE International Conference on Human-Robot Interaction, HRI ’21 Companion, New York, NY, USA, pp 116–120
Bansal G, Buçinca Z, Holstein K, Hullman J, Smith-Renner AM, Stumpf S, Wu S (2023) Workshop on trust and reliance in AI-human teams (TRAIT). In: Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, pp 1–6
Bartneck C, Kulić D, Croft EA, Zoghbi S (2009) Measurement instruments for the anthropomorphism, animacy, likeability, perceived intelligence, and perceived safety of robots. Int J Soc Robot 1:71–81
Benk M, Tolmeijer S, von Wangenheim F, Ferrario A (2022) The value of measuring trust in AI - a socio-technical system perspective. arXiv preprint arXiv:2204.13480
Bradford SC (1985) Sources of information on specific subjects. J Inf Sci 10:173–175
Brookes BC (1969) Bradford’s law and the bibliography of science. Nature 224:953–95
Buçinca Z, Lin P, Gajos KZ, Glassman EL (2020) Proxy tasks and subjective measures can be misleading in evaluating explainable AI systems. In: Proceedings of the 25th International Conference on Intelligent User Interfaces (IUI), pp 454–464
Buçinca Z, Malaya MB, Gajos KZ (2021) To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. In: Proceedings of the ACM on Human-computer Interaction 5(CSCW1), pp 1–21
Cai CJ, Reif E, Hegde N, Hipp J, Kim B, Smilkov D, Wattenberg M, Viegas F, Corrado GS, Stumpe MC, Terry M (2019) Human-centered tools for coping with imperfect algorithms during medical decision-making. In: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pp 1–14
Castaldo S, Premazzi K, Zerbini F (2010) The meaning(s) of trust. A content analysis on the diverse conceptualizations of trust in scholarly research on business relationships. J Bus Ethics 96:657–668
Castelfranchi C, Falcone R (2010) Trust theory: a socio-cognitive and computational model (1st ed.). Wiley Publishing
Cerovšek T, Mikoš M (2014) A comparative study of cross-domain research output and citations: research impact cubes and binary citation frequencies. J Informet 8(1):147–161
Chi OH, Jia S, Li Y, Gürsoy D (2021) Developing a formative scale to measure consumers’ trust toward interaction with artificially intelligent (AI) social robots in service delivery. Comput Hum Behav 118:106700
Chignell MH, Wang L, Zare A, Li JJ (2022) The evolution of HCI and human factors: integrating human and artificial intelligence. ACM Trans Comput–Hum Interact 30:1–30
Chiou EK, Lee JD (2021) Trusting automation: designing for responsivity and resilience. Hum Fact J Hum Fact Ergon Soc 65:137–165
Choi J, Lee HJ, Kim YC (2011) The influence of social presence on customer intention to reuse online recommender systems: the roles of personalization and product type. Int J Electron Commer 16:129–154
Choi JK, Ji YG (2015) Investigating the importance of trust on adopting an autonomous vehicle. Int J Hum-Comput Interact 31:692–702
Corallo A, Latino ME, Menegoli M, Devitiis BD, Viscecchia R (2019) Human factor in food label design to support consumer healthcare and safety: a systematic literature review. Sustainability 11(15):4019
Culnan MJ (1986) The intellectual development of management information systems, 1972–1982: a co-citation analysis. Manage Sci 32:156–172
Davis FD (1989) Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q 13:319–340
Dekarske J, Joshi SS (2021) Human trust of autonomous agent varies with strategy and capability in collaborative grid search task. In: IEEE 2nd International Conference on Human-Machine Systems (ICHMS) pp 1–6
Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 1:171–4186
Dietvorst BJ, Simmons JP, Massey C (2018) Overcoming algorithm aversion: people will use imperfect algorithms if they can (even slightly) modify them. Manage Sci 64(3):1155–1170
Djamasbi S, Galletta DF, Nah FFH, Page X, Robert LP, Wisniewski PJ (2018) Bridging a bridge: bringing two HCI communities together. In: Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, pp 1–8
Dubé L, Paré G (2003) Rigor in information systems positivist case research: current practices. MIS Q 27:597–635
Dzindolet MT, Peterson SA, Pomranky RA, Pierce LG, Beck HP (2003) The role of trust in automation reliance. Int J Hum Comput Stud 58:697–718
Ehsan U, Riedl MO (2020) Human-centered explainable AI: towards a reflective sociotechnical approach. In: 2020 International Conference on Human-Computer Interaction
Enebechi CN, Duffy VG (2020) Virtual reality and artificial intelligence in mobile computing and applied ergonomics: a bibliometric and content analysis. In: Digital Human Modeling and Applications in Health, Safety, Ergonomics and Risk Management. Human Communication, Organization and Work: 11th International Conference, DHM 2020, pp 334–345
Fahimnia B, Sarkis J, Davarzani H (2015) Green supply chain management: a review and bibliometric analysis. Int J Prod Econ 162:101–114
Feher K, Vicsek L, Deuze M (2024) Modeling AI trust for 2050: perspectives from media and info-communication experts. AI Soc 2:1–14
Ferrario A, Loi M (2022) How explainability contributes to trust in AI. In: Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pp 1457–1466
Ferrario A, Loi M, Viganò E (2020) In AI we trust incrementally: a multi-layer model of trust to analyze human-artificial intelligence interactions. Philos Technol 33:523–539
Freedy A, de Visser E, Weltman G, Coeyman N (2007) Measurement of trust in human-robot collaboration. International Symposium on Collaborative Technologies and Systems 2007:106–114
Gefen D (2013) Psychology of trust: new research. Psychology of emotions, motivations and actions. New York: Nova Science Publishers
Gillespie NM, Lockey S, Curtis C, Pool JK, Akbari A (2023) Trust in artificial intelligence: a global study. KPMG. https://kpmg.com/xx/en/our-insights/ai-and-technology/trust-in-artificial-intelligence.html
Glikson E, Woolley A (2020) Human trust in artificial intelligence: review of empirical research. Acad Manag Ann 14:627–660
Guerreiro JPV, Sato D, Asakawa S, Dong H, Kitani KM, Asakawa C (2019) Cabot: designing and evaluating an autonomous navigation robot for blind people. In: Proceedings of the 21st International ACM SIGACCESS Conference on Computers and Accessibility, pp 68–82
Guggemos J, Seufert S, Sonderegger S (2020) Humanoid robots in higher education: evaluating the acceptance of Pepper in the context of an academic writing course using the UTAUT. Br J Educ Technol 51:1864–1883
Hancock PA, Billings DR, Schaefer K, Chen J, Visser ED, Parasuraman R (2011) A meta-analysis of factors affecting trust in human-robot interaction. Human Fact J Human Fact Ergon Soc 53:517–527
Hayashi Y, Wakabayashi K (2017) Can AI become reliable source to support human decision making in a court scene? In Companion of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing, CSCW ’17 Companion, New York, NY, USA, pp 195–198
Hegner SM, Beldad A, Brunswick GJ (2019) In automatic we trust: investigating the impact of trust, control, personality characteristics, and extrinsic and intrinsic motivations on the acceptance of autonomous vehicles. Int J Hum-Comput Interact 35:1769–1780
Hirsch JE (2005) An index to quantify an individual’s scientific research output. Proc Natl Acad Sci 102(46):16569–16572
Hoegen R, Aneja D, McDuff DJ, Czerwinski M (2019) An end-to-end conversational style matching agent. In: Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, pp 111–118
Hoff KA, Bashir M (2015) Trust in automation: integrating empirical evidence on factors that influence trust. Hum Factors 57(3):407–434
Hoffman RR (2017) A taxonomy of emergent trusting in the human–machine relationship. Cognitive Systems Engineering, 137-164
Hong W, Chan FKY, Thong JYL, Chasalow LC, Dhillon G (2014) A framework and guidelines for context-specific theorizing in information systems research. Behav Soc Methods eJ Inf Syst
Inbar O, Meyer J (2019) Politeness counts: perceptions of peacekeeping robots. IEEE Trans Hum–Mach Syst 49:232–240
Jacobs ML, He J, Pradier MF, Lam B, Ahn AC, McCoy TH, Perlis RH, Doshi-Velez F, Gajos KZ (2021) Designing AI for trust and collaboration in time-constrained medical decisions: a sociotechnical lens. In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, pp 1–14
Jacovi A, Marasović A, Miller T, Goldberg Y (2021) Formalizing trust in artificial intelligence: prerequisites, causes and goals of human trust in AI. In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp 624–635
Jian JY, Bisantz A, Drury C, Llinas J (2000) Foundations for an empirically determined scale of trust in automated systems. Int J Cogn Ergon 4:53–71
Jobin A, Ienca M, Vayena E (2019) The global landscape of AI ethics guidelines. Nat Mach Intell 1(9):389–399
Kaur D, Uslu S, Rittichier KJ, Durresi A (2022) Trustworthy artificial intelligence: a review. ACM Comput Surv (CSUR) 55(2):1–38
Kaur H, Nori H, Jenkins S, Caruana R, Wallach H, Wortman Vaughan J (2020) Interpreting interpretability: understanding data scientists’ use of interpretability tools for machine learning. In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, New York, NY, USA, pp 1–14
Kenny EM, Ford C, Quinn MS, Keane M (2021) Explaining black-box classifiers using post-hoc explanations-by-example: the effect of explanations and error-rates in XAI user studies. Artif Intell 294:103459
Kim KJ, Park E, Sundar SS (2013) Caregiving role in human-robot interaction: a study of the mediating effects of perceived benefit and social presence. Comput Hum Behav 29:1799–1806
Knickrehm C, Voss M, Barton MC (2023) Can you trust me? using AI to review more than three decades of AI trust literature. In: 31st European Conference on Information Systems 2023
Knowles B, Richards JT (2021) The sanction of authority: promoting public trust in AI. In: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp 262–271
Kreps S, George J, Lushenko P, Rao AB (2023) Exploring the artificial intelligence “trust paradox”: evidence from a survey experiment in the united states. PLOS ONE 18(7)
Kroeger F (2016) Facework: creating trust in systems, institutions and organisations. Camb J Econ 41:487–514
Langer M, Hunsicker T, Feldkamp T, König CJ, Grgić-Hlača N (2022) “look! it’s a computer program! It’s an algorithm! It’s AI!”: does terminology affect human perceptions and evaluations of algorithmic decision-making systems? In: Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp 1–28
Laux J, Wachter S, Mittelstadt BD (2023) Trustworthy artificial intelligence and the european union AI act: on the conflation of trustworthiness and acceptability of risk. Regul Govern 18:3–32
Laxar D, Eitenberger M, Maleczek M, Kaider A, Hammerle F, Kimberger O (2023) The influence of explainable vs non-explainable clinical decision support systems on rapid triage decisions: a mixed methods study. BMC Med 21:85
Lee JD, See KA (2004) Trust in automation: designing for appropriate reliance. Hum Fact 46(1):50–80
Leichtmann B, Humer C, Hinterreiter AP, Streit M, Mara M (2022) Effects of explainable artificial intelligence on trust and human behavior in a high-risk decision task. Comput Hum Behav 139:107539
Li B, Qi P, Liu B, Di S, Liu J, Pei J, Yi J, Zhou B (2023) Trustworthy AI: from principles to practices. ACM Comput Surv 55(9):1–46
Linxen S, Sturm C, Brühlmann F, Cassau V, Opwis K, Reinecke K (2021) How weird is CHI? In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, pp 1-14
Liu Y, Gonçalves J, Ferreira D, Xiao B, Hosio SJ, Kostakos V (2014) Chi 1994–2013: Mapping two decades of intellectual progress through co-word analysis. In: Proceedings of the 2014 CHI Conference on Human Factors in Computing Systems, pp 3553–3562
Loi M, Ferrario A, Viganò E (2023) How much do you trust me? a logico-mathematical analysis of the concept of the intensity of trust. Synthese 201(6):186
Lorenz B, Nocera FD, Parasuraman R (2002) Display integration enhances information sampling and decision making in automated fault management in a simulated spaceflight micro-world. Proc Hum Fact Ergon Soc Annual Meet 46:31–35
Lucaj L, van der Smagt P, Benbouzid D (2023) AI regulation is (not) all you need. In: Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pp 1267–1279
Mayer RC, Davis JH, Schoorman FD (1995) An integrative model of organizational trust. Acad Manag Rev 20:709–734
McKnight DH, Chervany N (1996) The meanings of trust. Minneapolis, Minn., USA: Carlson School of Management, Univ. of Minnesota
Mcknight DH, Carter M, Thatcher JB, Clay PF (2011) Trust in a specific technology: an investigation of its components and measures. ACM Trans Manag Inf Syst 2(2):1–25
McKnight DH, Chervany NL (2000) What is trust? a conceptual analysis and an interdisciplinary model. In: Americas Conference on Information Systems (AMCIS)
Meidute-Kavaliauskiene I, Yıldız B, Çiğdem Ş, Činčikaitė R (2021) The effect of covid-19 on airline transportation services: a study on service robot usage intention. Sustainability 13(22):12571
Mercado JE, Rupp MA, Chen JY, Barnes MJ, Barber DJ, Procci K (2016) Intelligent agent transparency in human-agent teaming for multi-UxV management. Hum Fact J Hum Fact Ergon Soc 58:401–415
Miller T (2019) Explanation in artificial intelligence: insights from the social sciences. Artif Intell 267:1–38
Nadarzynski T, Miles O, Cowie A, Ridge DT (2019) Acceptability of artificial intelligence (AI)-led chatbot services in healthcare: a mixed-methods study. Digit Health 5:5
Nass C, Steuer J, Tauber ER (1994) Computers are social actors. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp 72–78
Natarajan M, Gombolay MC (2020) Effects of anthropomorphism and accountability on trust in human robot interaction. In: 15th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp 33–42
Nerur SP, Rasheed AA, Natarajan V (2008) The intellectual structure of the strategic management field: an author co-citation analysis. South Med J 29:319–336
Nielsen MW, Andersen JP (2021) Global citation inequality is on the rise. Proc Natl Acad Sci 118(7):e2012208118
Nikolaidis S, Lasota PA, Ramakrishnan R, Shah JA (2015) Improved human–robot team performance through cross-training, an approach inspired by human team training practices. Int J Robot Res 34:1711–1730
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, Shamseer L, Tetzlaff JM, Akl EA, Brennan SE et al (2021) The prisma 2020 statement: an updated guideline for reporting systematic reviews. Int J Surg 88:105906
Panagiotopoulos IE, Dimitrakopoulos GJ (2018) An empirical investigation on consumers’ intentions towards autonomous driving. Transp Res Part C Emerg Technol 95:773–784
Papagni G, de Pagter J, Zafari S, Filzmoser M, Koeszegi ST (2022) Artificial agents’ explainability to support trust: considerations on timing and context. AI Soc 38:947–960
Parasuraman R, Riley VA (1997) Humans and automation: use, misuse, disuse, abuse. Hum Fact J Hum Fact Ergon Soc 39:230–253
Pavlou PA (2003) Consumer acceptance of electronic commerce: integrating trust and risk with the technology acceptance model. Int J Electron Commer 7(3):101–134
Petersen E, Potdevin Y, Mohammadi E, Zidowitz S, Breyer S, Nowotka D, Henn S, Pechmann L, Leucker M, Rostalski P et al (2022) Responsible and regulatory conform machine learning for medicine: a survey of challenges and solutions. IEEE Access 10:58375–58418
Pillai R, Sivathanu B (2020) Adoption of AI-based chatbots for hospitality and tourism. Int J Contemp Hosp Manag 10: 3199-3226
Pöhler G, Heine T, Deml B (2016) Itemanalyse und Faktorstruktur eines Fragebogens zur Messung von Vertrauen im Umgang mit automatischen Systemen. Zeitschrift für Arbeitswissenschaft 70:151–160
Pu P, Chen L (2006) Trust building with explanation interfaces. In: Proceedings of the 11th International Conference on Intelligent User Interfaces, pp 93–100
Pu P, Chen L (2007) Trust-inspiring explanation interfaces for recommender systems. Knowl Based Syst 20:542–556
Rau PP, Li Y, Li D (2009) Effects of communication style and culture on ability to accept recommendations from robots. Comput Hum Behav 25(2):587–595
Ribeiro MT, Singh S, Guestrin C (2016) ‘Why should I trust you?’: explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD, New York, NY, USA, pp 1135–1144
Ridwan AY, Govindaraju R, Andriani M (2023) Business analytic and business value: a review and bibliometric analysis of a decade of research. In: Proceedings of the 7th International Conference on Sustainable Information Engineering and Technology, pp 158–164
Rix J (2022) From tools to teammates: conceptualizing humans’ perception of machines as teammates with a systematic literature review. In: Hawaii International Conference on System Sciences, pp 398–407
Robinette P, Wagner AR, Howard AM (2016) Investigating human-robot trust in emergency scenarios: methodological lessons learned. Robust intelligence and trust in autonomous systems, pp 143–166
Ruijten PAM, Terken JMB, Chandramouli SN (2018) Enhancing trust in autonomous vehicles through intelligent user interfaces that mimic human behavior. Multimodal Technol Interact 2:62
Salem M, Lakatos G, Amirabdollahian F, Dautenhahn K (2015) Would you trust a (faulty) robot? effects of error, task type and personality on human-robot cooperation and trust. In: Proceedings of the 10th annual ACM/IEEE International Conference on Human-Robot Interaction, pp 141–148
Salimzadeh S, He G, Gadiraju U (2023) A missing piece in the puzzle: considering the role of task complexity in human-AI decision making. In: Proceedings of the 31st ACM Conference on User Modeling, Adaptation and Personalization, UMAP ’23, New York, NY, USA, pp 215–227
Salini S (2016) An introduction to bibliometrics, Chapter 14, pp 130–143. John Wiley & Sons, Ltd
Schemmer M, Hemmer P, Kühl N, Benz C, Satzger G (2022) Should I follow AI-based advice? measuring appropriate reliance in human-AI decision-making. arXiv preprint arXiv:2204.06916
Schraagen JMC, Elsasser P, Fricke H, Hof M, Ragalmuto F (2020) Trusting the X in XAI: effects of different types of explanations by a self-driving car on trust, explanation satisfaction and mental models. Proc Hum Fact Ergon Soc Annu Meet 64:339–343
Shiffrin RM, Börner K, Stigler SM (2017) Scientific progress despite irreproducibility: a seeming paradox. In: Proc Natl Acad Sci 115:2632–2639
Shin D (2021) The effects of explainability and causability on perception, trust, and acceptance: implications for explainable AI. Int J Hum Comput Stud 146:102551
Simmler M, Frischknecht R (2021) A taxonomy of human-machine collaboration: capturing automation and technical autonomy. AI Soc 36(1):239–250
Slade EL, Dwivedi YK, Piercy NC, Williams MD (2015) Modeling consumers’ adoption intentions of remote mobile payments in the united kingdom: extending UTAUT with innovativeness, risk and trust. Psychol Market 32(8):860–873
Spain RD, Bustamante EA, Bliss JP (2008) Towards an empirically developed scale for system trust: take two. Proc Hum Fact Ergon Soc Annual Meeting 52:1335–1339
Toreini E, Aitken M, Coopamootoo K, Elliott K, Zelaya CG, van Moorsel A (2020) The relationship between trust in AI and trustworthy machine learning technologies. In: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, New York, NY, USA, pp 272–283
van Eck NJ, Waltman L (2009) Software survey: vosviewer, a computer program for bibliometric mapping. Scientometrics 84:523–538
Venkatesh V, Thong JYL, Xu X (2012) Consumer acceptance and use of information technology: extending the unified theory of acceptance and use of technology. Behav Market J 2:2
Vereschak O, Bailly G, Caramiaux B (2021) How to evaluate trust in AI-assisted decision making? a survey of empirical methodologies. In: Proc ACM Hum-Comput Interact 5:1–39
Wamba SF, Bawack RE, Guthrie C, Queiroz MM, Carillo KDA (2021) Are we preparing for a good AI society? a bibliometric review and research agenda. Technol Forecast Soc Chang 164:120482
Wang S, Yu H, Hu X, Li J (2020) Participant or spectator? Comprehending the willingness of faculty to use intelligent tutoring systems in the artificial intelligence era. Br J Educ Technol 51:1657–1673
Waytz A, Heafner J, Epley N (2014) The mind in the machine: anthropomorphism increases trust in an autonomous vehicle. J Exp Soc Psychol 52:113–117
Wu W, Liu R, Chu J (2023) How important is trust: exploring the factors influencing college students’ use of Chat GPT as a learning aid. In: 16th International Symposium on Computational Intelligence and Design (ISCID): 67–70
Yang F, Huang Z, Scholtz J, Arendt DL (2020) How do visual explanations foster end users’ appropriate trust in machine learning? In: Proceedings of the 25th International Conference on Intelligent User Interfaces, IUI ’20, New York, NY, USA, pp 189–201
Yang K, Zeng Z, Peng H, Jiang Y (2019) Attitudes of chinese cancer patients toward the clinical use of artificial intelligence. Patient Prefer Adher 13:1867–1875
Yang XJ, Unhelkar VV, Li K, Shah JA (2017) Evaluating effects of user experience and system transparency on trust in automation. In: Proceedings of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, pp 408–416
Yin M, Wortman Vaughan J, Wallach H (2019) Understanding the effect of accuracy on trust in machine learning models. In: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI ’19, New York, NY, USA, pp 1–12
Yu D, Rosenfeld H, Gupta A (2023) The ‘AI divide’ between the global north and the global south. World Economic Forum. https://www.weforum.org/agenda/2023/01/davos23-ai-divide-global-north-global-south/. Accessed 20 July 2024
Zanker M (2012) The influence of knowledgeable explanations on users’ perception of a recommender system. In: Proceedings of the sixth ACM Conference on Recommender systems pp 269–272
Zhang L, Pentina I, Fan Y (2021) Who do you choose? comparing perceptions of human vs robo-advisor in the context of financial services. J Serv Market 35(5):634–646
Zhang Y, Liao QV, Bellamy RKE (2020) Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. In: Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp 295–305
Zhao X, Ren Y, Cheah KSL (2023) Leading virtual reality (VR) and augmented reality (AR) in education: bibliometric and content analysis from the web of science (2018–2022). SAGE Open 13(3)
Acknowledgements
We would like to thank Suzanne Tolmeijer for her contributions to the conceptualization and data collection of this project. AF thanks Michele Loi for useful comments on a previous version of this work.
Funding
Open access funding provided by Swiss Federal Institute of Technology Zurich.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Figs. 6, 7, 8, and Table 7.

Cumulative number of articles per source. Core sources are identified using Bradford’s Law (Bradford 1985)

Heatmap, showing the relative importance of the influential works in Table 5 per research domain

Citation trend of the five most influential papers over time
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Benk, M., Kerstan, S., von Wangenheim, F. et al. Twenty-four years of empirical research on trust in AI: a bibliometric review of trends, overlooked issues, and future directions. AI & Soc (2024). https://doi.org/10.1007/s00146-024-02059-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00146-024-02059-y