
Abstract
Introduction
Establishing thresholds of change that are actually meaningful for the patient in an outcome measurement instrument is paramount. This concept is called the minimum clinically important difference (MCID). We summarize available MCID calculation methods relevant to spine surgery, and outline key considerations, followed by a step-by-step working example of how MCID can be calculated, using publicly available data, to enable the readers to follow the calculations themselves.
Methods
Thirteen MCID calculations methods were summarized, including anchor-based methods, distribution-based methods, Reliable Change Index, 30% Reduction from Baseline, Social Comparison Approach and the Delphi method. All methods, except the latter two, were used to calculate MCID for improvement of Zurich Claudication Questionnaire (ZCQ) Symptom Severity of patients with lumbar spinal stenosis. Numeric Rating Scale for Leg Pain and Japanese Orthopaedic Association Back Pain Evaluation Questionnaire Walking Ability domain were used as anchors.
Results
The MCID for improvement of ZCQ Symptom Severity ranged from 0.8 to 5.1. On average, distribution-based methods yielded lower MCID values, than anchor-based methods. The percentage of patients who achieved the calculated MCID threshold ranged from 9.5% to 61.9%.
Conclusions
MCID calculations are encouraged in spinal research to evaluate treatment success. Anchor-based methods, relying on scales assessing patient preferences, continue to be the “gold-standard” with receiver operating characteristic curve approach being optimal. In their absence, the minimum detectable change approach is acceptable. The provided explanation and step-by-step example of MCID calculations with statistical code and publicly available data can act as guidance in planning future MCID calculation studies.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The notion of minimum clinically important difference (MCID) was introduced to establish thresholds of change in an outcome measurement instrument that are actually meaningful for the patient. Jaeschke et al. originally defined it “as the smallest difference in score in the domain of interest which the patient perceives as beneficial and which would mandate, in the absence of troublesome side-effects and excessive cost, a change in the patient’s management” [1].
In many clinical trials statistical analyses only focuses on intergroup comparisons of raw outcome scores using parametric/non-parametric tests and deriving conclusions based on the p-value. Using the classical threshold of p-value < 0.05 only suggests that the observed effect is unlikely to have occurred by chance, but it does not equate to a change that is clinically meaningful for the patient [2]. Calculating MCID scores, and using them as thresholds for “treatment success”, ensures that patients’ needs and preferences are considered and allows for comparison of proportion of patients experiencing a clinically relevant improvement among different groups [3]. Through MCID, clinicians can better understand the impact of an intervention on their patients’ lives, sample size calculations can become more robust and health policy makers may decide which treatments deserve reimbursement [4,5,6].
The MCID can be determined from the patient’s perspective, where it is the patient who decides whether a change in their health was meaningful [4, 7,8,9]. This is the most common “gold-standard” approach and one that we will focus on. Occasionally, the clinician’s perspective can also be used to determine MCID. However, MCID for a clinician may not necessarily mean an increase in a patient’s functionality, but rather a change in disease survival or treatment planning [10]. MCID can also be defined at a societal level, as e.g. improvement in a patient’s functionality significant enough to aid their return to work [11].
MCID thresholds are intended to assess an individual’s clinical improvement and ought not to be applied to mean scores of entire groups post-intervention, as doing so may falsely over-estimate treatment effectiveness. It is also noteworthy to mention that obtained MCID values are not treatment-specific but broadly disease category-specific. They rely on a patient’s perception of clinical benefit, which is influenced by their diagnosis and subsequent symptoms, not just treatment modality.
In this study, we summarize available MCID calculation methods and outline key considerations when designing a MCID study, followed by a step-by-step working example of how MCID can be calculated.
Methods
Navigating the case study
To illustrate the MCID methods and to enable the reader to follow the practical calculation guide of different MCID values, based on the described methods along the way, a previously published data set of 84 patients, as described in Minetama et al., was used based on CC0.10 license [12]. Data can be downloaded at https://data.mendeley.com/datasets/vm8rg6rvsw/1. The statistical R code can be found in Supplementry content 1 including instructions on formatting the data set for MCID calculations The title of different MCID methods in the paper (listed below) and their number correspond to the same title and respective number in the R code. All analyses in this case study were carried out using R version 2023.12 + 402 (The R Foundation for Statistical Computing, Vienna Austria) [13].
The aim of Minetama et al. was to assess the effectiveness of supervised physical therapy (PT) with unsupervised at-home-exercises (HE) in patients with lumbar spinal stenosis (LSS). The main inclusion criteria were presence of neurogenic intermittent claudication and pain/or numbness in the lower extremities with or without back pain and > 50 years of age; diagnosis of LSS confirmed on MRI and a history of ineffective response to therapy for ≥ 3 months. Patients were then randomized into a 6-week PT or HE programme [12]. All data was pooled, as a clinically significant benefit for patients is independent of group allocation and because MCID is disease-specific. Therefore, the derived MCID will be applicable to most patients with lumbar spinal stenosis, irrespective of treatment modality. Change scores were calculated by subtracting baseline scores from follow-up scores.
MCID calculation methods
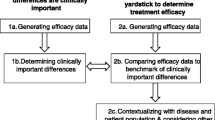
There are multiple approaches to calculate MCID, mainly divided into anchor-based and distribution-based methods (Fig. 1) [4, 10, 14,15,16,17]. Before deciding on the method, it needs to be defined whether the calculated MCID will be for improvement or deterioration [18]. Most commonly, MCID is used to measure improvement (as per Jaeschke et al. definition) [1, 4, 7, 14,15,16, 19, 20]. The value of MCID for improvement should not be directly applied in reverse to determine whether a decrease in patients' scores signifies a clinically meaningful deterioration – those are two separate concepts [18]. In addition, the actual MCID value ought to be applied to post-intervention score of an individual patient (not the overall score for the whole group), to determine whether, at follow-up, he or she experienced a change equating to MCID or more, compared to their baseline score. Such patient is then classified as “responders”.

Flow diagram presenting range of Minimum clinically important difference calculation methods stratified into anchor, distribution-based and “other” described in the study. MCID, Minimum Clinically Important Difference; MIC, Minimal Important Change
According to the Consensus-based Standards for the selection of health measurement instruments (COSMIN) guidelines, the “anchor-based” approach is regarded as the “gold-standard” [21,22,23]. In this approach, we determine the MCID of a chosen outcome measurement, based on whether a pre-defined MCID (usually derived from another published study) was achieved by an external criterion, known as the anchor, usually another patient-reported outcome measure (PROM) or an objective test of functionality [4, 7, 8, 15,16,17,18, 20]. It is best to use scales which allow the patient to rate the specific aspect of their health related to the disease of interest post-intervention compared to baseline on a Likert-type scale. This scale may range, for example, from “much worse”, “somewhat worse”, “about the same”, “somewhat better”, to “much better”, such as the established Global Assessment Rating tool [7, 8, 24, 25]. Depending on the scale, some studies determine MCID by calculating change scores for patients who only ranked themselves as “somewhat better”, and some only consider patients who ranked themselves as “much better” [7, 25,26,27,28,29]. This discrepancy is likely an explanation for a range of MCID for a single outcome measure dependent on the methodology. There appears to be no singular “correct” approach. One of the alternatives to the Global assessment rating is the use of the health transition item (HTI) from the SF-36 questionnaire, where patients are asked about their overall health compared to one year ago [7, 30, 31]. Although quick and easy to conduct, the patient’s response may be influenced by comorbid health issues other than those targeted by intervention. Nevertheless, any anchor where the patient is the one to decide what change is clinically meaningful, captures the true essence of the MCID. One should however, be mindful of the not easily addressed recall bias with such anchors – patients at times do not reliably remember their baseline health status [32]. Moreover, what the above anchors do not consider is, whether the patient would still choose the intervention for the same condition despite experiencing side-effects or cost. That can be addressed through implementing anchors such as the Satisfaction with Results scale described in Copay et al., who found that MCID values based on the Satisfaction with Results scale were slightly higher than those derived from HTI-SF-36 [7, 33].
Other commonly used outcome scales, such as Oswestry Disability Index (ODI), Roland–Morris Disability Questionnaire (RMDQ), Visual Analogue Scale (VAS), or EQ5D-3L Health-Related Quality of Life, can also act as anchors [7, 14, 16, 34, 35]. In such instances, patients complete the “anchor” questionnaire at baseline and post-intervention and the MCID of that anchor is derived from a previous publication [12, 16, 35]. Before deciding on the MCID, full understanding of how it was derived in that previous publication is crucial. Ideally, this should be done for a population similar to our study cohort, with comparable follow-up periods [18, 20]. Correlations between the anchor instrument and the investigated outcome measurement instrument must be recorded, and ought to be at least moderate (> 0.05), as that is the best indicator of construct validity (whether both the anchor instrument and outcome instrument represent a similar construct of patient health) [18, 36]. If such correlation is not available, the anchor-based MCID credibility instrument is available to aid in assessing construct proximity between the two [36, 37].
Once the process for selecting an anchor and classifying “responders” and “non-responders” is established, the MCID can be calculated. The outcome instrument of interest will be defined as an outcome for which we want to calculate the MCID. The first anchor-based method (within-patient change) focuses on the average improvement seen among clear responders in the anchor. The between-patient change anchor-based method additionally subtracts the average improvement seen among non-responders (unchanged and/or worsened) and consequently ends up with a smaller MCID value. Finally, an anchor-based method based on Receiver Operating Characteristic (ROC) curve analysis–that can be considered the current “gold standard”- also exists, which effectively looks at the MCID calculation as a sort of diagnostic instrument and aims to improve the discriminatory performance of our MCID threshold. In the following paragraphs, the three anchor-based methods are described in more detail. The R code (Supplementry Content 1) enables the reader to follow the text and to calculate MCID for the Zurich Claudication Questionnaire (ZCQ) Symptom Severity domain, based on a publicly available dataset [12].
Choice of outcome measurement instruments for MCID calculation case study
The chosen outcome measurement instrument in this case study for which MCID for improvement will be calculated is ZCQ Symptom Severity domain [12]. The ZCQ is composed of three subscales: symptom severity (7 questions, score per question ranging from 1 to 5 points); physical function (5 questions, score per question ranging from 1 to 4 points) and patient satisfaction with treatment scale (6 questions, score per question ranging from to 4 points). Higher scores indicate greater disability/worse satisfaction [38]. To visualize different MCID values, Numeric Rating Scale (NRS) for Leg Pain (score from 0 “no pain” to 10 “worse possible pain) and Japanese Orthopaedic Association Back Pain Evaluation Questionnaire (JOABPEQ) Walking Ability domain are chosen, as they showed high responsiveness in patients with LSS post-operatively [39].Through 25 questions, the JOABPEQ assesses five distinctive domains: pain-related symptoms, lumbar spine dysfunction, walking ability, impairment in social functioning and psychological disturbances. The score for each domain ranges from 0 to 100 points (higher score indicating better health status) [40]. The correlation of ZCQ symptom severity with NRS Leg Pain and JOABPEQ Walking Ability domain, is 0.56 and − 0.51, respectively [39]. For a patient to be classified as a “responder”, using the NRS for Leg pain or JOABPEQ walking ability, the score at 6-week follow-up must have improved by 1.6 points or 20 points, respectively [7, 40, 41].
This publicly available dataset does not report patient satisfaction or any kind of global assessment rating.
To enable calculation of global assessment rating-based MCID methods for educational purposes, despite very limited availability of studies providing MCID for deterioration of JOABPEQ, we decided to stratify patients in this dataset into the three following groups, based on the JOABPEQ Walking Ability as an anchor: likely improved (change score above 20 points according to Kasai et al.), no significant change (− 20– + 20 points change score), and likely deteriorated (lower than − 20 points change score) [41]. As obtained MCID values were expected to be negative, all values, for clarity of presentation, were multiplied by − 1, except in Method (IX), where graphical data distribution was shown.
The different methods in detail
Method (I) calculating MCID using “within-patient” score change
The first method focuses on calculating the change between baseline and post-intervention score of our outcome instrument, for each patient classified as a “responder”. A “responder” is a patient who, at follow-up, has achieved the pre-defined MCID of the anchor (or ranks themselves high enough on Global assessment rating type scale based on our methodology). The MCID is then defined as the mean change in the outcome instrument of interest of those classified as “responders” [4, 7, 16, 31].
The corresponding R-Code formula is described in Step 5a of Supplementry Content 1. Calculated within-patient MCID of ZCQ Symptom Severity based on NRS Leg Pain and JOABPEQ Walking Ability domain was 4.4 and 4.2, respectively.
Method (II) calculating MCID using “between-patient” score change
In this approach, the mean change in our outcome instrument is calculated for not only “responders” but also for “non-responders”. “Non-responders” are patients who did not achieve the pre-defined MCID of our anchor or who did not rank themselves high enough (unchanged, or sometimes: unchanged + worsened) on Global Assessment Rating type scale according to our methodology. The minimum clinically important difference of our outcome instrument is then defined as the difference between the mean change scores of “responders” and “non-responders” [4, 7, 16, 19].
The corresponding R-Code formula is described in Step 5b of Supplementry content 1. Calculated between-patient MCID of ZCQ Symptom Severity based on NRS Leg Pain and JOABPEQ Walking Ability domain was 3.5 and 2.8, respectively.
Method (III) calculating MCID using the ROC analysis
Here the MCID is derived through ROC analysis to identify the “threshold” score of our outcome instrument that best discriminates between “responders” and “non-responders” of the anchor [4, 7, 16, 19, 27]. To understand ROC, one must familiarize oneself with the concept of sensitivity and specificity. In ROC analysis, sensitivity is defined as the ability of the test to correctly detect “true positives”, which in this context refers to patients who have achieved a clinically meaningful change.
“False negative” would be a patient, who was classified as “non-responder” but is really a “responder”. Specificity is defined as the ability of a test to correctly detect a “true negative” result- a patient who did not achieve a clinically meaningful change – a “non-responder” [25].
A “false positive” would be a patient, who was classified as a “responder” but who was a “non-responder”. Values for sensitivity and specificity range from 0 to 1. Sensitivity of 1 means that the test can detect 100% of “true positives”’ (“responders”), while specificity of 1 reflects the ability to detect 100% of “true negatives” (“non-responders”). It is unclear what the minimum sensitivity and specificity should be for a “gold-standard” MCID, which is why the most established approach is to opt for a MCID threshold that maximizes both sensitivity and specificity at the same time, which can be done using ROC analysis [4, 7, 25, 31, 42]. During ROC analysis, the “closest-to-(0,1)-criterion” (the top left most point of the curve) or the Youden index are the two methods to automatically determine the optimal threshold point [43].
When conducting the ROC analysis, the Area under the curve (AUC) is also determined–a measure of how well the MCID threshold discriminates responders and non-responders in general. Values in AUC can range 0–1. An AUC of 0.5 signifies that the score discriminates no better than random chance, whereas a value of 1 means that the score perfectly discriminates between responders and non-responders. In the literature, an AUC of 0.7 and 0.8 is deemed fair (acceptable), while ≥ 0.8 to < 0.9 is considered good and values ≥ 0.9 are considered excellent [44]. Calculating the AUC provides a rough estimate of how well the chosen MCID threshold performs. The corresponding R-Code formula is described in Step 5c of Supplementry content 1. Statistical package pROC was used. The calculated MCID of ZCQ symptom severity based on NRS Leg Pain and JOABPEQ Walking Ability domain was for both 1.5.
Calculation of MCID through distribution-based methods
Calculation of MCID using the distribution-based approach focuses on statistical properties of the dataset [7, 14, 16, 27, 45]. Those methods are objective, easy to calculate, and in some cases, yield values close to anchor-based MCID. The advantage of this approach is that it does not rely on any external criterion or require additional studies on previously established MCIDs or other validated “gold standard” questionnaires for the specific disease in each clinical setting. However, it fails to include the patient’s perspective of a clinically meaningful change, which will be discussed later in this study. In this sense, distribution-based methods focus on finding MCID thresholds that enable mathematical distinction of what is considered a changed vs. unchanged score, whereas anchor-based methods focus on finding MCID thresholds which represent a patient-centered, meaningful improvement.
Method (IV) calculating MCID through Standard Error of Measurement (SEM)
The standard error of measurement conceptualizes the reliability of the outcome measure, by determining how repeated measurements of an outcome may differ from the “true score”. Greater SEM equates to lower reliability, which is suggestive of meaningful inconsistencies in the values produced by the outcome instrument despite similar measuring conditions. Hence, it has been theorized that 1 SEM is equal to MCID, because a change score ≥ 1 SEM, is unlikely to be due to measurement error and therefore is also more likely to be clinically meaningful [46, 47]. The following formula is used: [1, 7, 35, 46, 48].
The ICC, also called reliability coefficient, signifies level of agreement or consistency between measurements taken on different occasions or by different raters [49]. There are various ways of calculating the ICC depending on the used model with values < 0.5, 0.5– 0.75, 0.75–0.9 and > 0.90 indicating poor, moderate, good and excellent reliability, respectively [49]. While a value of 1 × SEM is probably the most established way to calculate MCID, in the literature, a range of multiplication factors for SEM-based MCID have been used, including 1.96 SEM or even 2.77 SEM to identify a more specific threshold for improvement [48, 50]. The corresponding R-Code formula is described in Step 6a of Supplementry Content 1. The chosen ZCQ Symptom Severity ICC was 0.81 [51]. The SEM-based MCID was 1.9.
Method (V) calculating MCID through Effect Size (ES)
Effect size (ES) is a standardized measure of the strength of the relationship or difference between two variables [52]. It is described by Cohen et al. as “degree to which the null hypothesis (there is no difference between the two groups) is false”. It allows for direct comparison of different instruments with different units between studies. There are multiple forms to calculate ES, but for the purpose of MCID calculations, the ES represents the number of SDs by which the post-intervention score has changed from baseline score. It is calculated based on the following formula incorporating the average change score divided by the SD of the baseline score: [52].
According to Cohen et al. 0.2 is considered small ES, 0.5 is moderate ES and 0.8 or more is large ES [53]. Most commonly, a change score with an ES of 0.2 is considered equivalent to MCID [7, 16, 31, 54,55,56]. Using this method, we are basically identifying the mean change score (in this case reflecting the MCID) that equates to an ES of 0.2: [7, 55].
Practically, if a patient experienced small improvement in an outcome measure post intervention, the ES will be smaller than for a patient who experienced a large improvement in outcomes measure. The corresponding R-Code formula is described in Step 6b of Supplementry Content 1. The ES-based MCID was 0.9.
Method (VI) calculating MCID through Standardized Response Mean (SRM)
The Standardized Response Mean (SRM) aims to gauge the responsiveness of an outcome similarly to ES. Initially described by Cohen et al. as a derivative of ES assessing differences of paired observations in a single sample, later renamed as SRM, it is also considered an “index of responsiveness” [38, 53]. However, the denominator is SD of the change scores–not the SD of the baseline scores–while the numerator remains the average change score from baseline to follow-up: [10, 45, 57,58,59].
Similarly, to Cohen’s rule of interpreting ES, it has been theorized that responsiveness can be considered low if SRM is 0.2–0.5, moderate if > 0.5–0.8 and large if > 0.8 [58,59,60]. Again, a change score equating to SRM of 0.2 (although SRM of 1/3 or 0.5 were also proposed) can be considered MCID, although studies have used the overall SRM as MCID as well [45, 54, 56, 61]. However, since SRM is a standardized index, similarly to ES, the aim of the SRM-based method ought to be to identify a change score that indicates responsiveness of 0.2: [61].
Similar to the ES-based method, the SRM-based approach for calculating the MCID is not commonly used in in spine surgery studies [14]. It is a measure of responsiveness, which is the ability to detect change over time in a construct to be measured by the instrument, and ought to be therefore calculated for the study-specific change score rather than extrapolated as a “universal” MCID threshold to other studies. The corresponding R-Code formula is described in Step 6c of Supplementry Content 1. The SRM-based MCID was 0.8.
The limitation of using Method (V) and (VI) in MCID calculations will be later described in Discussion.
Method (VII) calculating MCID through SD
Standard Deviation represents the average spread of individual data points around the mean value of the outcome measure. Norman et al. found in their review of studies using MCID in health-related quality of life instruments that most studies had an average ES of 0.5, which equated to clinically meaningful change score of 0.5 × SD of baseline score [7, 16, 30].
The corresponding R-Code formula is described in Step 6d of Supplementry content 1. The SD-based MCID was 2.1.
Method (VIII) calculating MCID through 95% Minimum Detectable Change (MDC)
The MDC is defined as the minimal change below which there is a 95% chance that it is due to measurement error of the outcome measurement instrument: [7, 61].
Usually, value corresponding to z is the desired level of confidence, which for 95% confidence level is 1.96. Although MDC–like all distribution-based methods–does not consider whether a change is clinically meaningful, the calculated MCID should be at least the same or greater than MDC to enable distinguishing true mathematical change from measurement noise. The 95% MDC calculation, is the most common distribution-based approach in spinal surgery, and it appears to most closely resemble anchor-derived MCID values, as demonstrated by Copay et al. [7, 14, 62]. The corresponding R-Code formula is described in Step 6e of Supplementry Content 1. The 95% MDC was 5.1.
Method (IX) calculating MCID through Reliable Change Index
Another less frequently applied method through which “responders and “non-responders” can be classified but which does not rely on an external criterion is the Reliable Change Index (RCI), also called the Jacobson–Truax index [63, 64]. It indicates whether an individual change score is statistically significantly greater than a change in score that could have occurred due to random measurement error alone [63].
In theory, a patient can be considered to experience a statistically reliably identifiable improvement (p < 0.05), if the individual RCI is > 1.96. Again, it does not reflect whether the change is clinically meaningful for the patient but rather that the change should not be attributed to measurement error alone and likely has a component of true score change. Therefore, this method is discouraged in MCID calculations as it relies on statistical properties of the sample and not patient preferences–as all distribution-based methods do [65]. In the example of Bolton et al. who focused on the Bournemouth Questionnaire in patients with neck pain, RCI was subsequently used to discriminate between “responders” and “non-responders”. The ROC analysis approach was then used to determine the MCID [64]. The corresponding R-Code formula is described in Step 6f of Supplementry Content 1. Again, pROC package was used. The ROC-derived MCID was 2.5.
Other methods
Method (X) calculating MCID through Anchor-Based Minimal Important Change (MIC) distribution model
In theory, combining anchor- and distribution-based methods could yield superior results. Some suggestions include averaging the values of various methods, simply combining two different methods (i.e. both an anchor-based criterion such as ROC-based MCID from patient satisfaction and 95% MDC-based MCID have to both be met to consider a patient as having achieved MCID) [25]. In 2007, de Vet et al. introduced a new visual method of MCID calculations that does not only combine but also integrates both anchor- and distribution-based calculations [25]. In addition, their method allows the calculation of both MCID for improvement and for deterioration, as these can differ.
In short form, using an anchor, patients were divided into three “importantly improved”, “not importantly changed” and “importantly deteriorated” groups (Fig. 2). Then distribution expressed in percentiles of patients who “importantly improved”, “importantly deteriorated” and “not importantly changed” were plotted on a graph. This is the anchor-based part of the approach, ensuring that MCID thresholds chosen have clinical value.

Distribution of the Zurich Claudication Questionnaire Symptom Severity change scores for patients categorized as experiencing “important improvement”, “no important change” or “important deterioration” in JOABPEQ walking ability as an anchor (Method (X)). For ZCQ Symptom Severity score to improve, the actual value must decrease explaining the negative values in the model. ROC, Receiver Operating Characteristic; ZCQ, Zurich Claudication Questionnaire; JOABPEQ, Japanese Orthopaedic Association Back Pain Evaluation Questionnaire
The second part of the approach is then entirely focused on the group of patients determined by the anchor to be “unchanged”, and can be either distribution- or anchor-based:
-
1.
In the first and more anchor-based method, the ROC-based method described in Method (III) is applied to find the threshold for improvement (by finding the ROC-based threshold point that optimizes sensitivity and specificity of identifying improved vs unchanged patients) or for deterioration (by finding the ROC-based threshold point that optimizes sensitivity and specificity of identifying deteriorated vs unchanged patients). For example, the threshold for improvement is found by combining the improved and unchanged groups, and then testing out different thresholds for discriminating those two groups from each other. The optimal point on the resulting ROC curve based on the closest-to-(0,1)-criterion is then found.
-
2.
In the second method, which is distribution-based, the upper 95% (for improvement) and lower 95% (for deterioration) limits are found based solely on the group of patients determined to be unchanged. The following formula is used (instead, subtracting instead of adding the 1.645 × SD for deterioration or improvement, respectively): [25]
$$95\% Upper Limit={Mean Change Score}_{Unchanged Group }+1.645 \times SD(Change Score)$$
The corresponding R-Code formula can be found under Step 7a in Supplementry Content 1. The model is presented in Fig. 2. The 95% upper limit and 95% lower limit was 4.1 and − 7.2 respectively. The ROC-derived MCID using RCI was − 2.5 (important improvement vs unchanged) and − 0.5 (important deterioration vs unchanged). For the purpose of the model, MCID values were not multiplied by − 1 but remained in original form.
Method (XI) calculating MCID as 30% Reduction from Baseline
In recent years, a simple 30% reduction from baseline values has been introduced as an alternative to MCID calculations [66]. It has been speculated that absolute-point changes are difficult to interpret and have limited value in context of “ceiling” and “floor” effects (i.e. values that are on the extreme spectra of the measurement scale) [4]. To overcome this, Khan et al. found that 30% reduction in PROMs has similar effectiveness as traditional anchored or distribution-based methods in detecting patients with clinically meaningful differences post lumbar spine surgery [15]. The corresponding R-Code formula can be found under Step 7b in Supplementry Content 1.
Method (XII) Calculating MCID through Delphi method
The Delphi Method is a systemic approach using the collective opinion of experts to establish a consensus regarding a medical issue [67]. It has mostly been used to develop best practice guidelines [68]. However, it can also be used to aid MCID determination [69]. The method focuses on distributing questionnaires or surveys to panel of members. The anonymized answers are grouped together and shared again with the expert panel in subsequent rounds. This allows the experts to reflect on their opinions and consider strengths and weaknesses of the others response. The process is repeated until consensus is reached. Ensuring anonymity, this prevents any potential bias linked to a specific participant’s concern about their own opinion being viewed or influenced by other personal factors [67].
Method (XIII) calculating MCID through Social Comparison Approach
The final approach is asking patients to compare themselves to other patients, which requires time and resources [70]. In a study by Redelmeier et al. patients with chronic obstructive pulmonary disease in a rehabilitation program were organized into small groups and observed each other at multiple occasions [70]. Additionally, each patient was paired with another participant and had a one-to-one interview with them discussing different aspects of their health. Finally, each patient anonymously rated themselves against their partner on a scale “much better”, “somewhat better”, “a little bit better”, “about the same”, “a little bit worse” “somewhat worse” and “much worse”. MCID was then calculated based on the mean change score of patients who graded themselves as “a little bit better” (MCID for improvement) or a “little bit worse” (MCID for deterioration), like in the within-patient change and between-patient change method described in Method (I) and (II) [70].
Substantial Clinical Benefit
Over the years, it has been noted that MCID calculations based either purely on distribution-based method or only group of patients rating themselves as “somewhat better” or “slightly better” does not necessarily constitute a change that patients would consider beneficial enough “to mandate, in the absence of troublesome side effects and excessive cost, to undergo the treatment again” [3, 24]. Therefore, the concept of substantial clinical benefit (SCB) has been introduced as a way of identifying a threshold of clinical success of intervention rather than a “floor” value for improvement- that is MCID [24]. For example, in Carreon et al., ROC derived SCB “thresholds” were defined as a change score with equal sensitivity and specificity to distinguish “much better” from “somewhat better” patients post cervical spinal fusion [71]. Glassman et al. on the other hand used ROC derived SCB thresholds to discriminate between “much better” and “about the same” patients following lumbar spinal fusion. The authors stress that SCB and MCID are indeed separate entities, and one should not be used to derive the other [24]. Thus, while the methods to derive SCB and MCID thresholds can be carried out similarly based on anchors, the ultimate goal of applying SCB versus MCID is different.
Results
Using the various methods explained above, overall, MCID for improvement for ZCQ Symptoms Severity domain ranged from 0.8 to 5.1 (Table 1). Here, the readers obtained results can be checked for correctness. On average distribution-based MCID values were lower than anchor-based MCID values. Within distribution-based approach, method (VIII) “Minimum detectable change” resulted in MCID of 5.1, which exceeded the MCID’s derived using the “gold-standard” anchor-based approaches. The average MCID based on anchor of NRS Leg pain and JOABPEQ walking ability was 3.1 and 2.8, respectively. Dependent on methods used, percentage of responders to HE and PT intervention fell within range of 9.5% for “30% Reduction from Baseline” method to 61.9% using ES- and SRM-based method (Table 2). Method (X) is graphically presented in Fig. 2.
Discussion
As demonstrated above, the MCID is dependent upon the methodology and the chosen anchor, highlighting the necessity for careful preparation in MCID calculations. The lowest MCID of 0.8 was calculated for Method (VI) being SRM. Logically, if a patient on average had a baseline ZCQ Symptom Severity score of 23.2, an improvement of 0.8 is unlikely to be clinically meaningful, even if rounded up. It rather informs on the measurement error property of our instrument as explained by COSMIN. Additionally, the distribution-based methods rely on statistical properties of the sample, which varies from cohort to cohort making it only generalizable to patient groups with similar SD but not applicable to others with a different spread of data [52]. Not surprisingly, anchor-based methods considering patient preferences yielded on average higher MCID values than distribution-based methods, which again varied from anchor to anchor. The mean MCID for improvement calculated for NPRS Leg Pain was 3.1, while for JOABPEQ Walking Ability it was 2.8—such similar values prove the importance of selecting responsive anchors with at least moderate correlations. Despite assessing different aspects of LSS disease, the MCID remained comparable in this specific case.
Interestingly, Method (VIII) MDC yielded the highest value of 5.1, exceeding the “gold-standard” ROC-derived MCID. This suggests that, in this example, using this ROC-derived MCID in clinical practice would be illogical, as the value falls within the measurement error determined by MDC. Here it would be appropriate to choose MDC approach as the MCID. Interestingly, ROC-derived MCID values based on Global Assessment Rating like stratification of patients based on their JOABPEQ Walking Ability (Method X) yielded higher MCID, than in Method (III). This may be attributed to a more a balanced distribution of “responders” and “non-responders” (only unchanged patients) in Method (X), unlike in the latter (Method III) where patients were strictly categorized into “responders” and “non-responders” (including both deteriorated and unchanged). This further highlights the importance of using global assessment rating type scales in determining the extent of clinical benefit.
Although ES-based (Method (V)) and SRM-based (Method (VI)) MCID calculations have been described in the literature, ES and SRM were originally created to quantify the strength of relationship between scores of two samples (in case of ES) and change score of paired observations in one sample (in case of SRM) [53, 58, 59]. They do offer an alternative to MCID calculations. However, verification with other MCID calculation methods, ideally anchor-based, is strongly recommended. As seen in this case study and other MCID’s derived similarly, they often result small estimates [7, 55]. There is also no consensus regarding the choice of SD of Change Score vs. SD of Baseline Score as denominator. Additionally, whether the calculated MCID (mean change score) should represent value, such as the ES is 0.2 indicating small effect, or value should be 0.5 suggesting moderate effect is currently arbitrary and often relies on the researcher’s preference [53, 55, 59]. Both ES and SRM can be used to assess whether the overall change score observed in single study is suggestive of a clinically meaningful benefit in that specific cohort or in case of SRM, whether the outcome measure is responsive. However, it is our perspective that extending such value as “MCID” from one study to another is not recommended.
One can argue whether there is even a place for distribution-based methods in MCID calculations. They ultimately fail to provide an MCID value that meets the original definition of Jaeschke et al. “of smallest change in the outcome that the patient would identify as important”. At no point are patients asked about what constitutes a meaningful change for them, and the value is derived from statistical properties of the sample solely [1]. Nevertheless, conduction of studies on MCID implementing scales such as Global Assessment Rating is time-consuming and performing studies for each patient outcome and each disease is likely not feasible. Distribution-based methods still have some merit in that they–like the 95% MDC method—can help distinguish measurement noise and inaccuracy from true change. Even if anchor-based methods should probably be used to define MCID thresholds, they ought to be supported by a calculation of MDC so that it can be decided whether the chosen threshold makes sense mathematically (i.e., can reliably be distinguished from measurement inaccuracies) as seen in our case study.
Calculating MCID for different diagnoses
Previously, MCID thresholds for outcome measurement instruments were calculated for generic populations, such as patients suffering from low back pain. More recently, MCID values for commonly used PROMs in spine surgery, such as ODI, RMDQ or NRS have been calculated for more narrowly defined diagnoses, such as lumbar disc herniation (LDH) or LSS. The question arises as to whether a separate MCID is needed for all the different spinal conditions. In general, establishing an MCID specific to these patient groups is only recommended if these patient’s perception of meaningful change is different from that of low back pain in general. Importantly, again, the MCID should not be treatment-specific, but rather broadly disease specific. Therefore, it is advisable to use MCID based on patients who had the most similar disease characteristics to our cohort. For example, an MCID for NRS Back Pain based on study group composed of different types of lumbar degenerative disease, may in some cases, be applied to study cohort composed solely of patients with LDH. However, no such extrapolation should be performed for populations with back pain secondary to malignancy, due to a totally different pathogenesis and associated symptoms that may influence the ability to detect a clinically meaningful change in the above NRS Back Pain such as fatigue or anorexia.
Study cohort characteristics that influence MCID
Regardless of robust methodology, it can be expected that it is impossible to obtain the same MCID on different occasions even in the same population due to the inherent subjectivity of what is perceived as “clinically beneficial” and day-to-day symptom fluctuation. However, it was found that patients who have worse baseline scores, reflecting e.g., more advanced disease, require greater overall change at follow-up to report it as clinically meaningful [72]. One should also be mindful of “regression to the mean” where extremely high or low-scoring patients then subsequently score closer to baseline at second measurement [73]. Therefore, adequate cohort characteristics need to be presented, for the readers to judge how generalizable the MCID may be to their study cohort. If a patient pre-operatively experiences NRS Leg Pain of 1, and the MCID is 1.6, they cannot achieve MCID at all, as the maximum possible change score is smaller than the MCID threshold (“floor effect”). A similar situation can occur with patients closer to the higher end of the scale (“ceiling effect”). The general rule is, that if at least 15% of the study cohort has the highest or lowest possible score for a given outcome instrument, one can expect significant “ceiling/floor effects” [50]. One way to overcome this, is through transferring absolute MCID scores to percentage change scores [4, 45]. However, percentage change scores only account for high baseline scores, if high baseline scores indicate larger disability (as seen with ODI) and have a possibility of larger change. If a high score in an instruments reflects better health status (as seen in in SF-36), than percentage change scores will increase the association with baseline score [4]. In general, it is important to consider which patient to exclude from certain analyses when applying MCID: For example, patients without relevant disease preoperatively (for example, those exhibiting so-called “patient-accepted symptom states”, PASS) should probably be excluded altogether when reporting the percentage of patients achieving MCID [74].
Conclusions
Establishing reliable thresholds for MCID is key in clinical research and forms the basis of patient-centered treatment evaluations when using patient-reported outcome measures or objective functional tests. Calculation of MCID thresholds can be achieved using a variety of different methods, each yielding completely different results, as is demonstrated in this practical guide. Generally, anchor-based methods relying on scales assessing patient preferences/satisfaction or global assessment ratings continue to be the “gold-standard” approach- the most common being ROC analysis. In the absence of appropriate anchors, the distribution-based MCID based on the 95% MDC approach is acceptable, as it appears to yield the most similar results compared to anchor-based approaches. Moreover, we recommend using it as a supplement to any anchor-based MCID thresholds to check if they can reliably distinguish true change from measurement inaccuracies. The explanation provided in this practical guide with step-by-step examples along with public data and statistical code can add as guidance for future studies calculating MCID thresholds.
References
Jaeschke R, Singer J, Guyatt GH (1989) Measurement of health status. Ascertaining the minimal clinically important difference. Control Clin Trials 10:407–415. https://doi.org/10.1016/0197-2456(89)90005-6
Concato J, Hartigan JA (2016) P values: from suggestion to superstition. J Investig Med 64:1166. https://doi.org/10.1136/jim-2016-000206
Zannikos S, Lee L, Smith HE (2014) Minimum clinically important difference and substantial clinical benefit: Does one size fit all diagnoses and patients? Semin Spine Surg 26:8–11. https://doi.org/10.1053/j.semss.2013.07.004
Copay AG, Subach BR, Glassman SD et al (2007) Understanding the minimum clinically important difference: a review of concepts and methods. Spine J 7:541–546. https://doi.org/10.1016/j.spinee.2007.01.008
Lanario J, Hyland M, Menzies-Gow A et al (2020) Is the minimally clinically important difference (MCID) fit for purpose? a planned study using the SAQ. Euro Respirat J. https://doi.org/10.1183/13993003.congress-2020.2241
Neely JG, Karni RJ, Engel SH, Fraley PL, Nussenbaum B, Paniello RC (2007) Practical guides to understanding sample size and minimal clinically important difference (MCID). Otolaryngol Head Neck Surg 136(1):14–18. https://doi.org/10.1016/j.otohns.2006.11.001
Copay AG, Glassman SD, Subach BR et al (2008) Minimum clinically important difference in lumbar spine surgery patients: a choice of methods using the Oswestry disability index, medical outcomes study questionnaire short form 36, and pain scales. Spine J 8:968–974. https://doi.org/10.1016/j.spinee.2007.11.006
Andersson EI, Lin CC, Smeets RJ (2010) Performance tests in people with chronic low back pain: responsiveness and minimal clinically important change. Spine 35(26):E1559-1563. https://doi.org/10.1097/BRS.0b013e3181cea12e
Mannion AF, Porchet F, Kleinstück FS, Lattig F, Jeszenszky D, Bartanusz V, Dvorak J, Grob D (2009) The quality of spine surgery from the patient’s perspective. Part 1: the core outcome measures index in clinical practice. Euro Spine J 18:367–373. https://doi.org/10.1007/s00586-009-0942-8
Crosby RD, Kolotkin RL, Williams GR (2003) Defining clinically meaningful change in health-related quality of life. J Clin Epidemiol 56:395–407. https://doi.org/10.1016/S0895-4356(03)00044-1
Gatchel RJ, Mayer TG (2010) Testing minimal clinically important difference: consensus or conundrum? Spine J 10:321–327. https://doi.org/10.1016/j.spinee.2009.10.015
Minetama M, Kawakami M, Teraguchi M et al (2019) Supervised physical therapy vs. home exercise for patients with lumbar spinal stenosis: a randomized controlled trial. Spine J 19:1310–1318. https://doi.org/10.1016/j.spinee.2019.04.009
R Core Team (2021) R A Language and Environment for Statistical Computing
Chung AS, Copay AG, Olmscheid N, Campbell D, Walker JB, Chutkan N (2017) Minimum clinically important difference: current trends in the spine literature. Spine 42(14):1096–1105. https://doi.org/10.1097/BRS.0000000000001990
Khan I, Pennings JS, Devin CJ, Asher AM, Oleisky ER, Bydon M, Asher AL, Archer KR (2021) Clinically meaningful improvement following cervical spine surgery: 30% reduction versus absolute point-change MCID values. Spine 46(11):717–725. https://doi.org/10.1097/BRS.0000000000003887
Gautschi OP, Stienen MN, Corniola MV et al (2016) Assessment of the minimum clinically important difference in the timed up and go test after surgery for lumbar degenerative disc disease. Neurosurgery. https://doi.org/10.1227/NEU.0000000000001320
Kulkarni AV (2006) Distribution-based and anchor-based approaches provided different interpretability estimates for the hydrocephalus outcome questionnaire. J Clin Epidemiol 59:176–184. https://doi.org/10.1016/j.jclinepi.2005.07.011
Wang Y, Devji T, Qasim A et al (2022) A systematic survey identified methodological issues in studies estimating anchor-based minimal important differences in patient-reported outcomes. J Clin Epidemiol 142:144–151. https://doi.org/10.1016/j.jclinepi.2021.10.028
Parker SL, Godil SS, Shau DN et al (2013) Assessment of the minimum clinically important difference in pain, disability, and quality of life after anterior cervical discectomy and fusion: clinical article. J Neurosurg Spine 18:154–160. https://doi.org/10.3171/2012.10.SPINE12312
Carrasco-Labra A, Devji T, Qasim A et al (2021) Minimal important difference estimates for patient-reported outcomes: a systematic survey. J Clin Epidemiol 133:61–71. https://doi.org/10.1016/j.jclinepi.2020.11.024
Prinsen CAC, Mokkink LB, Bouter LM et al (2018) COSMIN guideline for systematic reviews of patient-reported outcome measures. Qual Life Res 27:1147–1157. https://doi.org/10.1007/s11136-018-1798-3
Mokkink LB, de Vet HCW, Prinsen CAC et al (2018) COSMIN risk of bias checklist for systematic reviews of patient-reported outcome measures. Qual Life Res 27:1171–1179. https://doi.org/10.1007/s11136-017-1765-4
Terwee CB, Prinsen CAC, Chiarotto A et al (2018) COSMIN methodology for evaluating the content validity of patient-reported outcome measures: a Delphi study. Qual Life Res 27:1159–1170. https://doi.org/10.1007/s11136-018-1829-0
Glassman SD, Copay AG, Berven SH et al (2008) Defining substantial clinical benefit following lumbar spine arthrodesis. J Bone Joint Surg Am 90:1839–1847. https://doi.org/10.2106/JBJS.G.01095
de Vet HCW, Ostelo RWJG, Terwee CB et al (2007) Minimally important change determined by a visual method integrating an anchor-based and a distribution-based approach. Qual Life Res 16:131–142. https://doi.org/10.1007/s11136-006-9109-9
Solberg T, Johnsen LG, Nygaard ØP, Grotle M (2013) Can we define success criteria for lumbar disc surgery? Acta Orthop 84:196–201. https://doi.org/10.3109/17453674.2013.786634
Power JD, Perruccio AV, Canizares M et al (2023) Determining minimal clinically important difference estimates following surgery for degenerative conditions of the lumbar spine: analysis of the Canadian spine outcomes and research network (CSORN) registry. The Spine Journal 23:1323–1333. https://doi.org/10.1016/j.spinee.2023.05.001
Asher AL, Kerezoudis P, Mummaneni PV et al (2018) Defining the minimum clinically important difference for grade I degenerative lumbar spondylolisthesis: insights from the quality outcomes database. Neurosurg Focus 44:E2. https://doi.org/10.3171/2017.10.FOCUS17554
Cleland JA, Whitman JM, Houser JL et al (2012) Psychometric properties of selected tests in patients with lumbar spinal stenosis. Spine J 12:921–931. https://doi.org/10.1016/j.spinee.2012.05.004
Norman GR, Sloan JA, Wyrwich KW (2003) Interpretation of changes in health-related quality of life: the remarkable universality of half a standard deviation. Med Care 41:582–592. https://doi.org/10.1097/01.MLR.0000062554.74615.4C
Parker SL, Mendenhall SK, Shau DN et al (2012) Minimum clinically important difference in pain, disability, and quality of life after neural decompression and fusion for same-level recurrent lumbar stenosis: understanding clinical versus statistical significance. J Neurosurg Spine 16:471–478. https://doi.org/10.3171/2012.1.SPINE11842
Gatchel RJ, Mayer TG, Chou R (2012) What does/should the minimum clinically important difference measure?: a reconsideration of its clinical value in evaluating efficacy of lumbar fusion surgery. Clin J Pain 28:387. https://doi.org/10.1097/AJP.0b013e3182327f20
Lloyd H, Jenkinson C, Hadi M et al (2014) Patient reports of the outcomes of treatment: a structured review of approaches. Health Qual Life Outcomes 12:5. https://doi.org/10.1186/1477-7525-12-5
Beighley A, Zhang A, Huang B et al (2022) Patient-reported outcome measures in spine surgery: a systematic review. J Craniovertebr Junction Spine 13:378–389. https://doi.org/10.4103/jcvjs.jcvjs_101_22
Ogura Y, Ogura K, Kobayashi Y et al (2020) Minimum clinically important difference of major patient-reported outcome measures in patients undergoing decompression surgery for lumbar spinal stenosis. Clin Neurol Neurosurg 196:105966. https://doi.org/10.1016/j.clineuro.2020.105966
Wang Y, Devji T, Carrasco-Labra A et al (2023) An extension minimal important difference credibility item addressing construct proximity is a reliable alternative to the correlation item. J Clin Epidemiol 157:46–52. https://doi.org/10.1016/j.jclinepi.2023.03.001
Devji T, Carrasco-Labra A, Qasim A et al (2020) Evaluating the credibility of anchor based estimates of minimal important differences for patient reported outcomes: instrument development and reliability study. BMJ 369:m1714. https://doi.org/10.1136/bmj.m1714
Stucki G, Daltroy L, Liang MH et al (1996) Measurement properties of a self-administered outcome measure in lumbar spinal stenosis. Spine 21:796
Fujimori T, Ikegami D, Sugiura T, Sakaura H (2022) Responsiveness of the Zurich claudication questionnaire, the Oswestry disability index, the Japanese orthopaedic association back pain evaluation questionnaire, the 8-item short form health survey, and the Euroqol 5 dimensions 5 level in the assessment of patients with lumbar spinal stenosis. Eur Spine J 31:1399–1412. https://doi.org/10.1007/s00586-022-07236-5
Fukui M, Chiba K, Kawakami M et al (2009) JOA back pain evaluation questionnaire (JOABPEQ)/ JOA cervical myelopathy evaluation questionnaire (JOACMEQ) the report on the development of revised versions April 16, 2007: the subcommittee of the clinical outcome committee of the Japanese orthopaedic association on low back pain and cervical myelopathy evaluation. J Orthop Sci 14:348–365. https://doi.org/10.1007/s00776-009-1337-8
Kasai Y, Fukui M, Takahashi K et al (2017) Verification of the sensitivity of functional scores for treatment results–substantial clinical benefit thresholds for the Japanese orthopaedic association back pain evaluation questionnaire (JOABPEQ). J Orthop Sci 22:665–669. https://doi.org/10.1016/j.jos.2017.02.012
Glassman SD, Carreon LY, Anderson PA, Resnick DK (2011) A diagnostic classification for lumbar spine registry development. Spine J 11:1108–1116. https://doi.org/10.1016/j.spinee.2011.11.016
Perkins NJ, Schisterman EF (2006) The inconsistency of “optimal” cutpoints obtained using two criteria based on the receiver operating characteristic curve. Am J Epidemiol 163:670–675. https://doi.org/10.1093/aje/kwj063
Nahm FS (2022) Receiver operating characteristic curve: overview and practical use for clinicians. Korean J Anesthesiol 75:25–36. https://doi.org/10.4097/kja.21209
Angst F, Aeschlimann A, Angst J (2017) The minimal clinically important difference raised the significance of outcome effects above the statistical level, with methodological implications for future studies. J Clin Epidemiol 82:128–136. https://doi.org/10.1016/j.jclinepi.2016.11.016
Wyrwich KW, Tierney WM, Wolinsky FD (1999) Further evidence supporting an SEM-based criterion for identifying meaningful intra-individual changes in health-related quality of life. J Clin Epidemiol 52:861–873. https://doi.org/10.1016/s0895-4356(99)00071-2
Wolinsky FD, Wan GJ, Tierney WM (1998) Changes in the SF-36 in 12 months in a clinical sample of disadvantaged older adults. Med Care 36:1589–1598
Wyrwich KW, Nienaber NA, Tierney WM, Wolinsky FD (1999) Linking clinical relevance and statistical significance in evaluating intra-individual changes in health-related quality of life. Med Care 37:469–478. https://doi.org/10.1097/00005650-199905000-00006
Koo TK, Li MY (2016) A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J Chiropr Med 15:155–163. https://doi.org/10.1016/j.jcm.2016.02.012
McHorney CA, Tarlov AR (1995) Individual-patient monitoring in clinical practice: are available health status surveys adequate? Qual Life Res 4:293–307
Hara N, Matsudaira K, Masuda K et al (2016) Psychometric assessment of the Japanese version of the Zurich claudication questionnaire (ZCQ): reliability and validity. PLoS ONE 11:e0160183. https://doi.org/10.1371/journal.pone.0160183
Kazis LE, Anderson JJ, Meenan RF (1989) Effect sizes for interpreting changes in health status. Med Care 27:S178–S189. https://doi.org/10.1097/00005650-198903001-00015
Cohen J (1988) Statistical power analysis for the behavioral sciences. L Erlbaum Associates, Hillsdale, NJ
Franceschini M, Boffa A, Pignotti E et al (2023) The minimal clinically important difference changes greatly based on the different calculation methods. Am J Sports Med 51:1067–1073. https://doi.org/10.1177/03635465231152484
Samsa G, Edelman D, Rothman ML et al (1999) Determining clinically important differences in health status measures: a general approach with illustration to the health utilities index mark II. Pharmacoeconomics 15:141–155. https://doi.org/10.2165/00019053-199915020-00003
Wright A, Hannon J, Hegedus EJ, Kavchak AE (2012) Clinimetrics corner: a closer look at the minimal clinically important difference (MCID). J Man Manip Ther 20:160–166. https://doi.org/10.1179/2042618612Y.0000000001
Stucki G, Liang MH, Fossel AH, Katz JN (1995) Relative responsiveness of condition-specific and generic health status measures in degenerative lumbar spinal stenosis. J Clin Epidemiol 48:1369–1378. https://doi.org/10.1016/0895-4356(95)00054-2
Liang MH, Fossel AH, Larson MGS (1990) Comparisons of five health status instruments for orthopedic evaluation. Med Care 28:632–642
Middel B, Van Sonderen E (2002) Statistical significant change versus relevant or important change in (quasi) experimental design: some conceptual and methodological problems in estimating magnitude of intervention-related change in health services research. Int J Integr care. https://doi.org/10.5334/ijic.65
Revicki D, Hays RD, Cella D, Sloan J (2008) Recommended methods for determining responsiveness and minimally important differences for patient-reported outcomes. J Clin Epidemiol 61:102–109. https://doi.org/10.1016/j.jclinepi.2007.03.012
Woaye-Hune P, Hardouin J-B, Lehur P-A et al (2020) Practical issues encountered while determining minimal clinically important difference in patient-reported outcomes. Health Qual Life Outcomes 18:156. https://doi.org/10.1186/s12955-020-01398-w
Parker SL, Mendenhall SK, Shau D et al (2012) Determination of minimum clinically important difference in pain, disability, and quality of life after extension of fusion for adjacent-segment disease. J Neurosurg Spine 16:61–67. https://doi.org/10.3171/2011.8.SPINE1194
Jacobson NS, Truax P (1991) Clinical significance: a statistical approach to defining meaningful change in psychotherapy research. J Consult Clin Psychol 59:12–19
Bolton JE (2004) Sensitivity and specificity of outcome measures in patients with neck pain: detecting clinically significant improvement. Spine 29(21):2410–2417. https://doi.org/10.1097/01.brs.0000143080.74061.25
Blampied NM (2022) Reliable change and the reliable change index: Still useful after all these years? Cogn Behav Ther 15:e50. https://doi.org/10.1017/S1754470X22000484
Asher AM, Oleisky ER, Pennings JS et al (2020) Measuring clinically relevant improvement after lumbar spine surgery: Is it time for something new? Spine J 20:847–856. https://doi.org/10.1016/j.spinee.2020.01.010
Barrett D, Heale R (2020) What are Delphi studies? Evid Based Nurs 23:68–69. https://doi.org/10.1136/ebnurs-2020-103303
Droeghaag R, Schuermans VNE, Hermans SMM et al (2021) Evidence-based recommendations for economic evaluations in spine surgery: study protocol for a Delphi consensus. BMJ Open 11:e052988. https://doi.org/10.1136/bmjopen-2021-052988
Henderson EJ, Morgan GS, Amin J et al (2019) The minimum clinically important difference (MCID) for a falls intervention in Parkinson’s: a delphi study. Parkinsonism Relat Disord 61:106–110. https://doi.org/10.1016/j.parkreldis.2018.11.008
Redelmeier DA, Guyatt GH, Goldstein RS (1996) Assessing the minimal important difference in symptoms: a comparison of two techniques. J Clin Epidemiol 49:1215–1219. https://doi.org/10.1016/s0895-4356(96)00206-5
Carreon LY, Glassman SD, Campbell MJ, Anderson PA (2010) Neck disability index, short form-36 physical component summary, and pain scales for neck and arm pain: the minimum clinically important difference and substantial clinical benefit after cervical spine fusion. Spine J 10:469–474. https://doi.org/10.1016/j.spinee.2010.02.007
Wang Y-C, Hart DL, Stratford PW, Mioduski JE (2011) Baseline dependency of minimal clinically important improvement. Phys Ther 91:675–688. https://doi.org/10.2522/ptj.20100229
Tenan MS, Simon JE, Robins RJ et al (2021) Anchored minimal clinically important difference metrics: considerations for bias and regression to the mean. J Athl Train 56:1042–1049. https://doi.org/10.4085/1062-6050-0368.20
Staartjes VE, Stumpo V, Ricciardi L et al (2022) FUSE-ML: development and external validation of a clinical prediction model for mid-term outcomes after lumbar spinal fusion for degenerative disease. Eur Spine J 31:2629–2638. https://doi.org/10.1007/s00586-022-07135-9
Funding
Open access funding provided by University of Zurich. This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that the article and its content were composed in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Klukowska, A.M., Vandertop, W.P., Schröder, M.L. et al. Calculation of the minimum clinically important difference (MCID) using different methodologies: case study and practical guide. Eur Spine J 33, 3388–3400 (2024). https://doi.org/10.1007/s00586-024-08369-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00586-024-08369-5