
Abstract
Acute kidney injury (AKI) is a frequent and severe complication in intensive care unit (ICU) patients with respiratory failure, associated with high mortality, prolonged hospitalization, and substantial healthcare burden. Conventional risk scores, such as SOFA and APACHE II, are not optimized for AKI prediction in this heterogeneous population. This study aimed to develop and validate an early AKI prediction model using machine learning. We analyzed 10,780 adult ICU patients with unspecified respiratory failure from the MIMIC-IV database, of whom 53.96% developed AKI according to KDIGO criteria. Ten supervised learning algorithms were trained using predictors from the first 48 h of ICU admission, with each model independently selecting its 15 most informative features via recursive feature elimination. Extreme gradient boosting (XGBoost) achieved the best performance (AUC 0.9023; accuracy 0.8247; sensitivity 0.8077; specificity 0.8386; precision 0.8040; negative predictive value 0.8419; F1-score 0.8058; Brier score 0.108). SHAP analysis identified creatinine_max, length of hospital stay, BUN_max, preexisting renal disease, and urine output as the most influential predictors. Leveraging routinely available early ICU data, this model enables accurate and interpretable AKI risk stratification. With external validation and integration into electronic health records, it could support proactive prevention and individualized management of AKI in critically ill respiratory failure patients.
Similar content being viewed by others
Introduction
Acute hypoxemic respiratory failure is a major cause of intensive care unit (ICU) admission, associated with high mortality, long-term morbidity, and a considerable healthcare burden [1]. Acute kidney injury (AKI) is a frequent and serious complication in ICU patients, particularly among those with respiratory failure [2]. Globally, AKI-related mortality exceeds that of major diseases such as heart failure and diabetes [3], with persistently high mortality over the past five decades. In high-income countries, AKI is most prevalent in ICU settings—especially among elderly patients with multiple organ failure—where its severity correlates with higher mortality, longer ICU stays, and greater healthcare costs [4,5,6,7]. The co-occurrence of respiratory failure and AKI is common and is thought to be mediated by complex lung–kidney interactions, leading to accelerated disease progression and worse outcomes [8,9,10,11].
Early identification and timely intervention are critical for improving AKI prognosis [12]. However, widely used ICU risk assessment tools such as SOFA, APACHE II, and SAPS II were not specifically designed for AKI prediction. These scores rely on limited physiological parameters captured at a single time point, overlook dynamic trends, and lack AKI specificity in heterogeneous ICU populations [13]. Their performance may be further reduced in ICU patients with respiratory failure due to overlapping organ dysfunction and complex lung–kidney pathophysiology [14].
Developing accurate AKI prediction models in ICU patients with respiratory failure presents additional challenges: (1) marked heterogeneity in etiology and presentation—such as acute respiratory distress syndrome (ARDS), acute exacerbation of COPD, and hypoxemic vs. hypercapnic respiratory failure—each with distinct AKI risk profiles [1]; (2) frequent missing or incomplete clinical variables in ICU datasets [15]; and (3) multifactorial AKI pathophysiology in critically ill patients, involving hemodynamic instability, systemic inflammation, nephrotoxic exposures, and mechanical ventilation effects [16]. These factors demand predictive tools capable of integrating diverse, high-dimensional data while remaining robust across patient subgroups.
Machine learning (ML) offers a promising solution, with the ability to process complex datasets, identify subtle patterns, and generate more accurate, individualized predictions [17, 18]. The MIMIC-IV database contains comprehensive ICU patient data and provides an ideal platform for developing and validating ML models. Prior retrospective studies have demonstrated the potential of ML algorithms to predict AKI up to 48 h before onset [19] and shown their applicability across diverse patient populations [20,21,22,23,24]. This study aims to develop and validate an ML-based AKI prediction model for ICU patients with respiratory failure using demographic, clinical, and laboratory data from the MIMIC-IV database, with the goal of enabling timely, informed clinical decisions and improving patient outcomes.
Materials and methods
Data source
This study is a retrospective cohort study based on the Medical Information Mart for Intensive Care IV (MIMIC-IV, version 3.0) database. The MIMIC-IV database contains over 250,000 electronic health records from Beth Israel Deaconess Medical Center, spanning from 2008 to 2019 [25]. All identifiable patient information in the database has been de-identified, eliminating the need for informed consent from patients. The MIMIC-IV project has been approved by the Institutional Review Boards of both the Massachusetts Institute of Technology and Beth Israel Deaconess Medical Center. The authors of this study have completed the required online training program through the collaborative institutions and are certified authorized users of the MIMIC-IV database (Certification number: 42304428).
Inclusion and exclusion criteria
Patients diagnosed with ICD-10-CM J96 Respiratory Failure, Not Elsewhere Classified, were eligible for inclusion in this study. Among these patients, individuals diagnosed with AKI were selected as the study population. AKI is characterized by a sudden loss of kidney function, indicated by elevated serum creatinine levels (a marker of renal excretory function) and reduced urine output (oliguria, a quantitative marker of urine production). AKI was diagnosed based on an increase in serum creatinine (sCr) of ≥ 50% within 7 days, or an increase of ≥ 0.3 mg/dl (26.5 µmol/l) within 2 days, or oliguria lasting ≥ 6 h [26]. The following patients were excluded from the study: (1) patients under 18 years of age; (2) patients with multiple ICU admissions; (3) patients with an ICU stay of less than 48 h; and (4) patients with incomplete AKI data, missing partial pressure of oxygen (PaO2) or carbon dioxide information, or insufficient follow-up data within the first 48 h of ICU admission.
Data extraction and processing
Baseline characteristics of the patients were extracted using structured query language (SQL) from the PostgreSQL (version 14.2) database. These features included demographic data such as age, gender, body mass index (BMI), and race; clinical indicators including length of hospital stay (LOS), length of ICU stay (ICU-LOS), height, and weight; comorbidities such as myocardial infarction, congestive heart failure (CHF), peripheral vascular disease, cerebrovascular disease, dementia, chronic pulmonary disease, rheumatic disease, peptic ulcer disease, mild liver disease, diabetes without complications, diabetes with chronic complications, paraplegia, renal disease, malignant cancer, severe liver disease, metastatic solid tumors, and acquired immunodeficiency syndrome (AIDS); as well as the Charlson comorbidity index (CCI).
Vital signs and physiological measurements included minimum, maximum, and mean values of heart rate, systolic blood pressure (SBP), diastolic blood pressure (DBP), mean arterial pressure (MAP), respiratory rate, body temperature, and oxygen saturation (SpO₂). Neurological and organ failure assessments included the Glasgow Coma Scale (GCS) and the Sequential Organ Failure Assessment (SOFA) score.
Laboratory parameters extracted from the database encompassed values of lactate, blood pH, PaO₂, partial pressure of carbon dioxide (PaCO₂), base excess, bicarbonate, arterial/alveolar oxygen gradient (A-aDO2), PaO2/FiO2 ratio, serum glucose, creatinine, blood urea nitrogen (BUN), serum electrolytes (sodium, potassium, chloride, calcium), hemoglobin, hematocrit, platelet count, white blood cell count (WBC), international normalized ratio (INR), prothrombin time (PT), partial thromboplastin time (PTT), alanine aminotransferase (ALT), aspartate aminotransferase (AST), alkaline phosphatase (ALP), and total bilirubin. Additionally, differential leukocyte parameters included absolute basophil, eosinophil, lymphocyte, monocyte, and neutrophil counts.
Medication and intervention-related variables included the use of angiotensin-converting enzyme inhibitors (ACEI), angiotensin receptor blockers (ARB), angiotensin receptor–neprilysin inhibitors (ARNI), beta-blockers, aspirin, statins, fibrates, proton pump inhibitors (PPIs), oral hypoglycemic agents (e.g., metformin), nonsteroidal anti-inflammatory drugs (NSAIDs), anticoagulants, antibiotics, antacathartics, glucocorticoids, vasoactive drugs (e.g., dobutamine, dopamine, epinephrine, norepinephrine, isoprenaline), sedatives (e.g., midazolam, dexmedetomidine, propofol), oxygen inhalation, and mechanical ventilation.
The primary outcome of this study was the development of AKI during ICU stay, as defined by the diagnostic criteria recorded in the MIMIC-IV database. A secondary outcome was 28-day ICU mortality, assessed via survival analysis. Survival status was determined based on the number of days the patient survived following ICU admission. Patients with a survival time of 28 days or less and confirmed death were included in the Kaplan–Meier survival analysis and log-rank test.
To address missing data, variables with less than 20% missingness were imputed using multiple imputation by chained equations (MICE). Variables with a missing rate exceeding 20% were excluded from the final analysis [26].
Statistical analysis
Continuous variables were expressed as Ms with interquartile ranges (IQRs), and intergroup differences were assessed using the Mann–Whitney U test. Categorical variables were presented as counts (n) and percentages (%), with between-group comparisons conducted using the Chi-squared test or Fisher’s exact test as appropriate. Kaplan–Meier survival curves were constructed to evaluate 28-day ICU mortality, and differences between groups were assessed using the log-rank test.
The MIMIC-IV dataset was randomly divided into a training set and an internal validation set in a 7:3 ratio. To identify the most informative predictors, recursive feature elimination (RFE) was employed for feature selection [27]. This technique recursively removes the least important features during model training to obtain an optimal subset that maximizes predictive performance. Based on the selected features, we developed ten supervised ML models: (1) extreme gradient boosting (XGBoost); (2) support vector machine (SVM); (3) AdaBoost; (4) multilayer perceptron (MLP); (5) neural network (NNET); (6) naive Bayes; (7) logistic regression; (8) light gradient boosting machine (LightGBM); (9) random forest (RF); and (10) ElasticNet regression. For each model, we applied RFE with tenfold cross-validation independently to identify its own optimal set of 15 predictors, rather than using a single unified feature set across all algorithms. This approach was chosen deliberately to allow each model architecture—given its unique learning mechanism, bias–variance trade-off, and sensitivity to feature interactions—to leverage the predictors best suited to its strengths. While a unified feature set would facilitate direct comparison under identical input conditions, it could constrain the performance of certain models. Allowing independent feature optimization ensures that each algorithm is evaluated under its optimal configuration, aligning with the primary objective of identifying the best-performing AKI prediction model rather than directly comparing model structures.
Model performance was evaluated using multiple metrics, including the area under the receiver operating characteristic curve (AUC), accuracy, sensitivity, specificity, precision, negative predictive value (NPV), F1-score, Cohen’s kappa coefficient, and Brier score.
The AUC reflects the model’s overall ability to distinguish between different outcome classes, with values closer to 1 indicating stronger discriminative power. Accuracy measures the proportion of correct predictions across all instances but may be biased in the presence of class imbalance. Sensitivity (recall) refers to the model’s ability to correctly identify true positives, while specificity indicates its ability to correctly recognize true negatives. Precision measures the proportion of true positives among those predicted as positive, which helps reduce the false positive rate. NPV reflects the proportion of true negatives among those predicted as negative, making it useful for assessing the model’s ability to rule out low-risk individuals. The F1-score is the harmonic mean of precision and sensitivity, offering a balanced measure of performance, particularly in imbalanced datasets. Cohen’s kappa quantifies the agreement between predicted and actual labels, adjusting for agreement due to chance. Finally, the Brier score evaluates the calibration of predicted probabilities, with lower scores indicating better alignment between predicted and observed outcomes.
Statistical analyses were performed using R version 4.4.3 (Vienna, Austria), with P values < 0.05 considered statistically significant. The ML code and original patient data are available on GitHub (https://github.com/DRQ66/AKI).
Ethics approval and consent to participate
The MIMIC-IV database was approved by the Institutional Review Boards of Beth Israel Deaconess Medical Center and the Massachusetts Institute of Technology. All protected health information in the database has been de-identified, eliminating the need for individual patient consent. All methods were conducted in accordance with relevant guidelines and regulations.
Results
Participants and baseline characteristics
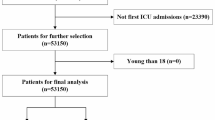
After applying exclusion criteria, a total of 10,780 ICU patients with respiratory failure were included from the MIMIC-IV database (Fig. 1), out of an initial cohort of 17,900. Baseline characteristics, including continuous, categorical, and binary variables, are summarized in Table 1. Among the included patients, 5819 (53.96%) developed AKI, while 4961 did not.

Research flowchart
Kaplan–Meier survival curves (Fig. 2) demonstrated a significantly higher 28-day ICU mortality rate in the AKI group compared to the non-AKI group (log-rank test, P < 0.01). Moreover, the ICU length of stay was notably prolonged in patients with AKI (Mann–Whitney U test, P < 0.01; Fig. 3).

Kaplan–Meier survival curves for 28-day ICU mortality by AKI status. Note: The numbers of patients in the survival analysis (AKI = 5819, non-AKI = 4961) reflect those with complete follow-up data. A small number of patients with missing or invalid survival time or event status were excluded from the analysis

ICU length of stay in patients with and without AKI
Further analysis of baseline characteristics demonstrated that patients in the AKI group were older (M: 70 vs. 65 years), had higher body weight and BMI, and longer hospital and ICU stays (all P < 0.001). The AKI group also showed a higher CCI (M: 6 vs. 5), with significantly greater prevalence of cardiovascular diseases (e.g., myocardial infarction, CHF), diabetes, chronic pulmonary disease, and malignancies (all P < 0.001). They presented more abnormal vital signs and laboratory findings suggestive of hemodynamic instability and metabolic disturbances, including elevated creatinine and BUN, electrolyte imbalances, and acid–base disorders. Moreover, the use of critical care interventions, such as vasopressors, sedatives, antibiotics, and invasive mechanical ventilation, was more frequent in the AKI group, indicating a more severe clinical condition.
Feature selection and model development
A total of 156 candidate feature variables were included in this study (Table 1). To efficiently identify key predictors contributing to model performance, RFE with cross-validation was applied to select the top 15 most important features for each ML algorithm. Based on the selected features, ten supervised ML models were developed, including SVM, XGBoost, RF, logistic regression, AdaBoost, naive Bayes, MLP, NNET, LightGBM, and ElasticNet regression. All models were trained using their respective RFE-selected features to ensure comparability and interpretability. This feature selection strategy improved modeling efficiency, reduced redundancy, enhanced model robustness, and emphasized the clinical variables most closely associated with AKI prediction.
Continuous variables are presented as Ms with IQRs. The Mann–Whitney U test was used to compare these variables between the two groups (AKI vs. non-AKI). Categorical variables are presented as frequencies (n) with corresponding percentages (%), and comparisons were made using the Chi-squared test or Fisher’s exact test, as appropriate. The variables are grouped by demographics, comorbidities, vital signs, laboratory values, and therapeutic interventions for clarity. Binary variables are presented as frequencies (n) and percentages (%). Comparisons between the groups (AKI vs. non-AKI) were performed using the Chi-squared test or Fisher’s exact test. Variables include demographics, comorbidities, and therapeutic interventions.
Model performance
To comprehensively compare the predictive performance of all ten ML models, multiple evaluation metrics were considered, including AUC, accuracy, sensitivity, specificity, precision, NPV, F1-score, kappa, and Brier score (Table 2). Among these, the XGBoost model achieved the highest AUC (0.9023), indicating superior overall discrimination ability. It also demonstrated high accuracy (0.8247), specificity (0.8386), and NPV (0.8419), while maintaining a balanced sensitivity (0.8077) and F1-score (0.8058). These results collectively suggest strong predictive performance and robustness.
The RF and SVM models also showed competitive AUCs, but were slightly inferior to XGBoost in most key metrics. Models, such as AdaBoost and ElasticNet, yielded moderate performance but displayed trade-offs between sensitivity and specificity.
The ROC curves (Fig. 4) further illustrated that XGBoost outperformed other models in terms of distinguishing between AKI and non-AKI cases, confirming its superior discriminative ability. Decision curve analysis (DCA) (Fig. 5) demonstrated that XGBoost consistently provided the highest net benefit over a wide range of threshold probabilities, surpassing all other models in clinical utility. Additionally, calibration curve analysis (Fig. 6) further revealed that the XGBoost model had the best alignment between predicted and observed probabilities across the full probability range. Furthermore, the clinical impact of the XGBoost model was clearly demonstrated in Fig. 7, where the model showed consistently high net benefits at clinically relevant thresholds, suggesting that it could be a valuable tool for clinical decision-making.

Receiver Operating Characteristic (ROC) Curves. ROC curves comparing ten ML models: Logistic regression, RF, XGBoost, SVM, ElasticNet, LightGBM, AdaBoost, naive Bayes, MLP, and NNET. The XGBoost model achieved the highest AUC (0.9023), indicating the strongest overall discriminative capability for predicting AKI among ICU patients

Decision Curve Analysis. The XGBoost model provided the highest net clinical benefit across a wide range of threshold probabilities, confirming its utility in guiding AKI-related decision-making in ICU settings

Calibration Curves. The calibration curve for the XGBoost model demonstrated the best agreement between predicted probabilities and observed outcomes, closely aligning with the ideal 45-degree reference line diagonal reference line, thus reflecting excellent model calibration

Clinical Impact Curve (CIC) for XGBoost. The red curve represents the number of patients predicted to be at high risk for AKI at each probability threshold, while the dark curve indicates the number of true positive cases. The close alignment of these curves across a range of thresholds suggests strong clinical utility and low false positive rates
Given its superior performance in discrimination, calibration, and clinical net benefit, XGBoost was selected as the optimal model for predicting AKI among ICU patients in this study. These interpretable visualizations reinforce the clinical plausibility and transparency of the model’s predictions. Collectively, the results highlight the XGBoost model’s capability to integrate physiologically meaningful features and deliver both accurate and explainable risk stratification for AKI in ICU settings.
Model interpretations
To interpret the contribution of individual predictors within the XGBoost model, we employed SHapley Additive exPlanations (SHAP) for both global and individual-level interpretation. As illustrated in the SHAP summary plot (Fig. 8), creatinine_max emerged as the most influential variable, with a mean absolute SHAP value of 1.168, significantly exceeding those of all other features. This suggests that elevated serum creatinine levels are a major driving factor in the model’s prediction of AKI occurrence.

SHAP summary plot of feature importance in the XGBoost model. Each dot represents the SHAP value of a feature for an individual patient. Features are ranked by their average absolute SHAP value. The color gradient indicates the feature value, where yellow represents higher values and purple represents lower values. Creatinine_max was the most important predictor contributing to AKI risk
Following creatinine_max, other important contributors included length of hospital stay (los_hospital), bun_max, presence of renal disease (rel_disease), and urine output. These features are clinically interpretable, as prolonged hospitalization, azotemia, and oliguria are well-established risk indicators for AKI.
In addition, several physiological and biochemical variables—such as mean SpO2, minimum bicarbonate, minimum INR, A-aDO2, and both minimum and maximum BUN—were retained in the model, reflecting their more subtle yet meaningful roles in risk estimation. Notably, administration of dexmedetomidine and elevated CCI scores were associated with increased predicted risk, underscoring the impact of sedative exposure and comorbidity burden on renal vulnerability.
For individualized interpretation, SHAP-based visualization techniques were applied. In the waterfall plot of a representative high-risk case (Sample 2) (Fig. 9), the model classified the patient as high risk for AKI, primarily due to markedly elevated creatinine_max, increased bun_max, and reduced urine output. These features exhibited large positive SHAP values, highlighting their substantial contribution to the predicted outcome. Conversely, the force plot of a low-risk case (Sample 7) (Fig. 10) depicted a low-risk case, driven by normal levels of creatinine and BUN, along with relatively elevated hemoglobin and SpO₂, which exerted negative SHAP influences.

SHAP-based visualization of individual-level predictions in the XGBoost model. Waterfall plot of a representative high-risk case (Sample 2) selected from the internal validation set. The patient’s risk was primarily driven by elevated creatinine_max, bu n_max, and reduce urineoutput

Force plot of a low-risk case (Sample 7) showing protective effects from higher hemoglobin and SpO₂ levels. Red and blue bars indicate positive and negative contributions to AKI risk, respectively
These individualized SHAP visualizations help elucidate the model’s internal decision-making process and affirm the clinical relevance of its predictions. Collectively, the results underscore the XGBoost model’s strength in integrating physiologically meaningful variables to deliver accurate and explainable AKI risk stratifications for ICU patients.
Application of the model
In the MIMIC-IV database, a total of 4961 patients were not diagnosed with AKI at initial assessment (Table 1). To evaluate their potential risk of future AKI development, we applied the XGBoost model constructed with features selected by RFE. Using a predicted probability threshold of ≥ 0.6 to define high risk, the model identified 796 patients (16.0%) as individuals at elevated risk for developing AKI. Early identification of these high-risk patients may support timely clinical interventions, enhanced monitoring, and individualized management strategies to reduce the incidence and adverse outcomes associated with AKI.
Discussion
In this study, approximately 54.0% of ICU patients with respiratory failure developed AKI, which was associated with higher 28-day mortality and prolonged ICU stay. To address this challenge, we developed an XGBoost-based prediction model with strong predictive performance in the validation cohort, enabling early risk identification at ICU admission. The AKI outcome variable was defined as the final discharge diagnosis in the electronic medical record, while predictor variables were limited to data from the first 48 h after ICU admission—a temporal separation that provides predictive value. However, we acknowledge that in some patients, AKI may have already been present but unrecognized at admission, meaning variables such as creatinine_max may partially reflect early, undetected AKI. Thus, our model may serve both to predict future AKI and to identify early or subclinical cases. Future prospective studies with time-stamped AKI onset data are warranted to clarify its true predictive capacity.
Unlike traditional scoring systems, our model used XGBoost’s embedded feature importance to select the top 15 routinely available variables, enhancing interpretability and practicality. Notably, each machine learning model was trained on its own optimally selected 15-feature subset via independent RFE, rather than a single unified set—a deliberate trade-off prioritizing performance maximization over strict comparability.
To our knowledge, this is the first model specifically developed for predicting AKI in ICU patients with respiratory failure. Prior studies have focused mainly on septic or cardiovascular populations [23, 28,29,30,31,32,33,34]. Our model distinguishes itself by integrating comorbidities and laboratory values via data-driven feature selection, achieving robust performance in discrimination, calibration, and decision curve analysis.
Beyond enhanced monitoring, several actionable interventions can be implemented immediately when a patient is flagged high risk: (1) individualized fluid management to avoid both hypovolemia and fluid overload [35];(2) adjustment of nephrotoxic medications, minimizing agents such as aminoglycosides, high-dose loop diuretics, and certain contrast agents [35, 36]; (3) early adoption of kidney-protective hemodynamic targets [37]; (4) strict glycemic control to prevent hyperglycemia, which has been linked to increased AKI risk in ICU patients [38]; (5) early nephrology consultation for patients with rising creatinine, declining urine output, or complex fluid/drug management needs [36]; and (6) lung-protective ventilation strategies—such as low tidal volume ventilation and avoiding excessive airway pressures or PEEP—to reduce hemodynamic compromise and protect renal perfusion [35]. These measures can be rapidly integrated into ICU workflows, aligning with the model’s goal of timely, precise intervention.
The top-ranked predictive features identified by the XGBoost model included creatinine_max, los_hospital, bun_max, rel_disease, urineoutput, spo2_mean_vitalsign, bicarbonate_min, bun_min, aado2_calc_min_bg, inr_min, dexmedetomidine, charlson_comorbidity_index, creatinine_min, hemoglobin_min, and congestive_heart_failure. These variables are clinically meaningful and play a critical role in evaluating the risk of AKI in patients with respiratory failure.
Our study identified serum creatinine as the most influential predictor, followed by BUN and urine output, consistent with prior models [31, 39] and reflecting their central role in renal function assessment [40]. Elevated creatinine and BUN with reduced urine output signify declining kidney function, often accompanied by metabolic imbalances that drive uremic symptoms. Patients with preexisting renal disease face substantially higher AKI risk [41, 42].
AKI also significantly impacts acid–base homeostasis. In AKI patients, impaired excretion of fixed acids leads to tubular metabolic acidosis, which is partially compensated by increased respiratory ventilation [43]. This compensatory response manifests clinically as alterations in respiratory rate, elevated heart rate, fluctuations in blood pressure, and increases in serum bicarbonate. Additionally, arterial blood gas analysis often reveals decreased base excess, a reduced anion gap, and electrolyte imbalances, including abnormalities in sodium, potassium, calcium, and phosphate levels [41]. These biochemical changes are consistent with the important predictive variables identified in our model.
The CCI, widely recognized as a predictor of long-term mortality, also modulates the relationship between AKI severity (particularly stages 2–3) and 1-year mortality [44]. Notably, a lower CCI score has been associated with a higher risk of developing AKI, although this association diminishes in patients with CCI ≥ 8, suggesting a ceiling effect in risk stratification. In patients with CHF, complex hemodynamic changes—including hypotension driven by elevated cardiac filling pressure and increased right ventricular pressure—can impair glomerular filtration and tubular reabsorption. Paradoxically, this may result in a reduced glomerular filtration rate (GFR) and decreased urine output. This pathophysiological mechanism aligns with the observed predictive strength of the congestive_heart_failure feature in our SHAP-based risk model [45].
While dexmedetomidine has shown renoprotective effects in some contexts [46, 47], our findings suggest that its predictive value likely reflects illness severity and ICU-level sedation use, rather than direct causality. Thus, its positive SHAP contribution may serve as a surrogate marker for critical illness.
Conversely, when patients with respiratory failure develop AKI, the pulmonary system becomes further compromised. This is due to compensatory respiratory depression in response to metabolic acidosis, along with hypervolemia, cytokine-induced cytotoxicity, oxidative stress, and accumulated necrotic cellular debris. These factors contribute to pulmonary microvascular injury, ultimately leading to acute respiratory distress syndrome (ARDS) [9, 48], which further deteriorates lung function.
In addition, several other variables—ICU length of stay, SpO₂, alveolar–arterial oxygen gradient, and INR of hemoglobin—have also been validated as important predictors in prior studies and AKI prediction models [22, 28, 29, 31, 49,50,51].
Despite these promising results, several limitations should be noted. First, this was a retrospective, single-center analysis using data from one healthcare system, which may introduce selection bias (e.g., exclusions for < 48-h ICU stay, multiple ICU admissions, and missing key variables) and limit generalizability. Features were primarily collected at ICU admission, without incorporating longitudinal changes or certain clinically relevant predictors such as nephrotoxin exposure, fluid overload, or inflammatory biomarkers. The absence of precise AKI onset timing precluded assessment of performance across different prediction windows (e.g., within 24 vs. 48 h) and made it difficult to distinguish true prediction from early detection of existing but uncoded AKI. Moreover, external validation in independent, multicenter cohorts is currently lacking and will be essential to confirm transportability and mitigate the risk of overfitting. In addition, reliance on broad, non-specific respiratory failure codes may introduce clinical heterogeneity; more refined subtyping could improve predictive specificity. From an implementation standpoint, translating the model into routine practice and scaling it across ICUs pose several challenges: (1) interoperability with diverse electronic health record systems and real-time data availability/latency; (2) variability in case-mix, measurement frequency, laboratory assays, and clinical practices across sites that can cause dataset shift and calibration drift; (3) clinician adoption and workflow integration, including alert burden and the need for clear, actionable thresholds; and (4) ongoing model governance—local threshold tuning, performance monitoring, and periodic recalibration/retraining to maintain safety and reliability.
Future studies should focus on external validation, dynamic updating using real-time data with recorded AKI onset times, and integration into clinical workflows. With further refinement, this model has the potential to support timely AKI prevention and intervention strategies in critically ill patients.
Conclusion
In this retrospective cohort study using the MIMIC-IV database, we developed and validated an XGBoost-based machine learning model to predict acute kidney injury (AKI) in ICU patients with respiratory failure, based solely on clinical data from the first 48 h of ICU admission. The model demonstrated superior predictive performance compared with traditional scoring systems and other supervised learning algorithms, highlighting the importance of early laboratory indicators (e.g., creatinine, blood urea nitrogen, urine output) and comorbidity indices in AKI risk assessment. By simulating a real-world clinical scenario, our approach may facilitate timely risk stratification and early interventions to improve patient outcomes. Nevertheless, the model may partly capture undiagnosed early-stage AKI, and its generalizability is limited by the single-center, retrospective design. Future prospective, multicenter studies incorporating real-time AKI onset data are warranted to further validate and refine its predictive utility.
Data availability
The ML code and original patient data are available on GitHub (https://github.com/DRQ66/AKI).
References
Bellani G, Laffey JG, Pham T, Fan E, Brochard L, Esteban A, et al. Epidemiology, patterns of care, and mortality for patients with acute respiratory distress syndrome in intensive care units in 50 countries. JAMA. 2016;315(8):788–800.
Kellum JA, Romagnani P, Ashuntantang G, Ronco C, Zarbock A, Anders HJ. Acute kidney injury. Nat Rev Dis Primers. 2021;7(1):52.
Lewington AJP, Cerdá J, Mehta RL. Raising awareness of acute kidney injury: a global perspective of a silent killer. Kidney Int. 2013;84(3):457–67.
Susantitaphong P, Cruz DN, Cerda J, Abulfaraj M, Alqahtani F, Koulouridis I, et al. World incidence of AKI: a meta-analysis. Clin J Am Soc Nephrol. 2013;8(9):1482–93.
Hoste EAJ, Kellum JA, Selby NM, Zarbock A, Palevsky PM, Bagshaw SM, et al. Global epidemiology and outcomes of acute kidney injury. Nat Rev Nephrol. 2018;14(10):607–25.
Lameire NH, Levin A, Kellum JA, Cheung M, Jadoul M, Winkelmayer WC, et al. Harmonizing acute and chronic kidney disease definition and classification: report of a Kidney Disease: Improving Global Outcomes (KDIGO) consensus conference. Kidney Int. 2021;100(3):516–26.
Hoste EAJ, Bagshaw SM, Bellomo R, Cely CM, Colman R, Cruz DN, et al. Epidemiology of acute kidney injury in critically ill patients: the multinational AKI-EPI study. Intensive Care Med. 2015;41(8):1411–23.
Komaru Y, Bai YZ, Kreisel D, Herrlich A. Interorgan communication networks in the kidney-lung axis. Nat Rev Nephrol. 2024;20(2):120–36.
Faubel S, Edelstein CL. Mechanisms and mediators of lung injury after acute kidney injury. Nat Rev Nephrol. 2016;12(1):48–60.
Murugan R, Kerti SJ, Chang C-CH, Gallagher M, Clermont G, Palevsky PM, et al. Association of net ultrafiltration rate with mortality among critically ill adults with acute kidney injury receiving continuous venovenous hemodiafiltration: a secondary analysis of the randomized evaluation of normal vs augmented level (RENAL) of renal replacement therapy trial. JAMA Netw Open. 2019;2(6):e195418.
Chen D, Jiang L, Li J, Tan Y, Ma M, Cao C, et al. Interaction of acute respiratory failure and acute kidney injury on in-hospital mortality of patients with acute exacerbation COPD. Int J Chron Obstruct Pulmon Dis. 2021;16:3309–16.
Joannidis M, Forni LG, Klein SJ, Honore PM, Kashani K, Ostermann M, et al. Lung-kidney interactions in critically ill patients: consensus report of the Acute Disease Quality Initiative (ADQI) 21 workgroup. Intensive Care Med. 2020;46(4):654–72.
Vincent JL, Moreno R, Takala J, Willatts S, De Mendonça A, Bruining H, et al. The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure. On behalf of the Working Group on Sepsis-Related Problems of the European Society of Intensive Care Medicine. Intens Care Med. 1996;22(7):707–10.
Darmon M, Ostermann M, Cerda J, Dimopoulos MA, Forni L, Hoste E, et al. Diagnostic work-up and specific causes of acute kidney injury. Intensive Care Med. 2017;43(6):829–40.
Johnson AEW, Pollard TJ, Shen L, Lehman L-WH, Feng M, Ghassemi M, et al. MIMIC-III, a freely accessible critical care database. Sci Data. 2016;3:160035.
Zarbock A, Nadim MK, Pickkers P, Gomez H, Bell S, Joannidis M, et al. Sepsis-associated acute kidney injury: consensus report of the 28th acute disease quality initiative workgroup. Nat Rev Nephrol. 2023;19(6):401–17.
Shamout F, Zhu T, Clifton DA. Machine learning for clinical outcome prediction. IEEE Rev Biomed Eng. 2021;14:116–26.
Andaur Navarro CL, Damen JAA, van Smeden M, Takada T, Nijman SWJ, Dhiman P, et al. Systematic review identifies the design and methodological conduct of studies on machine learning-based prediction models. J Clin Epidemiol. 2023. https://doi.org/10.1016/j.jclinepi.2022.11.015.
Schwager E, Ghosh E, Eshelman L, Pasupathy KS, Barreto EF, Kashani K. Accurate and interpretable prediction of ICU-acquired AKI. J Crit Care. 2023;75:154278.
Malhotra R, Kashani KB, Macedo E, Kim J, Bouchard J, Wynn S, et al. A risk prediction score for acute kidney injury in the intensive care unit. Nephrol Dial Transplant. 2017;32(5):814–22.
Demirjian S, Bashour CA, Shaw A, Schold JD, Simon J, Anthony D, et al. Predictive accuracy of a perioperative laboratory test-based prediction model for moderate to severe acute kidney injury after cardiac surgery. JAMA. 2022;327(10):956–64.
Neyra JA, Ortiz-Soriano V, Liu LJ, Smith TD, Li X, Xie D, et al. Prediction of mortality and major adverse kidney events in critically ill patients with acute kidney injury. Am J Kidney Dis. 2023;81(1):36–47.
Fan Z, Jiang J, Xiao C, Chen Y, Xia Q, Wang J, et al. Construction and validation of prognostic models in critically ill patients with sepsis-associated acute kidney injury: interpretable machine learning approach. J Transl Med. 2023;21(1):406.
Kuang L, Lin W, Chen B, Wang D, Zeng Q. A nomogram for predicting acute kidney injury following hepatectomy: a propensity score matching analysis. J Clin Anesth. 2023;90:111211.
Johnson AEW, Bulgarelli L, Shen L, Gayles A, Shammout A, Horng S, et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci Data. 2023;10(1):1.
Li J, Wang Z, Wu L, Qiu S, Zhao H, Lin F, et al. Method for incomplete and imbalanced data based on multivariate imputation by chained equations and ensemble learning. IEEE J Biomed Health Inform. 2024;28(5):3102–13.
Guyon I, Weston J, Barnhill S, Vapnik V. Gene selection for cancer classification using support vector machines. Mach Learn. 2002;46(1):389–422.
Yue S, Li S, Huang X, Liu J, Hou X, Zhao Y, et al. Machine learning for the prediction of acute kidney injury in patients with sepsis. J Transl Med. 2022;20(1):215.
Peng M, Deng F, Qi D. Development of a nomogram model for the early prediction of sepsis-associated acute kidney injury in critically ill patients. Sci Rep. 2023;13(1):15200.
Xin Q, Xie T, Chen R, Wang H, Zhang X, Wang S, et al. Construction and validation of an early warning model for predicting the acute kidney injury in elderly patients with sepsis. Aging Clin Exp Res. 2022;34(12):2993–3004.
Zhou H, Liu L, Zhao Q, Jin X, Peng Z, Wang W, et al. Machine learning for the prediction of all-cause mortality in patients with sepsis-associated acute kidney injury during hospitalization. Front Immunol. 2023;14:1140755.
Wang Z, Xu J, Zhang Y, Chen C, Kong C, Tang L, et al. Prediction of acute kidney injury incidence following acute type A aortic dissection surgery with novel biomarkers: a prospective observational study. BMC Med. 2023;21(1):503.
Yang Y-Q, Da J-J, Nie S, Yuan J, Liu B-C, Liu H-F, et al. A prediction model for moderate to severe acute kidney injury in people with heart failure. Mil Med Res. 2024;11(1):57.
Uzendu A, Kennedy K, Chertow G, Amin AP, Giri JS, Rymer JA, et al. Contemporary methods for predicting acute kidney injury after coronary intervention. JACC Cardiovasc Interv. 2023;16(18):2294–305.
Pickkers P, Darmon M, Hoste E, Joannidis M, Legrand M, Ostermann M, et al. Acute kidney injury in the critically ill: an updated review on pathophysiology and management. Intensive Care Med. 2021;47(8):835–50.
Moore PK, Hsu RK, Liu KD. Management of acute kidney injury: core curriculum 2018. Am J Kidney Dis. 2018;72(1):136–48.
Zarbock A, Kellum JA, Schmidt C, Van Aken H, Wempe C, Pavenstädt H, et al. Effect of early vs delayed initiation of renal replacement therapy on mortality in critically ill patients with acute kidney injury: the ELAIN randomized clinical trial. JAMA. 2016;315(20):2190–9.
Ruan J, Huang W, Jiang J, Hu C, Li Y, Peng Z, et al. Association between hyperglycemia at ICU admission and postoperative acute kidney injury in patients undergoing cardiac surgery: analysis of the MIMIC-IV database. J Intensive Med. 2024;4(4):526–36.
James MT, Pannu N, Hemmelgarn BR, Austin PC, Tan Z, McArthur E, et al. Derivation and external validation of prediction models for advanced chronic kidney disease following acute kidney injury. JAMA. 2017;318(18):1787–97.
Kellum JA, Lameire N. Diagnosis, evaluation, and management of acute kidney injury: a KDIGO summary (Part 1). Crit Care. 2013;17(1):204.
Singbartl K, Joannidis M. Short-term effects of acute kidney injury. Crit Care Clin. 2015;31(4):751–62.
Jullien P, Diconne E, Darmon M. Uremic frost: a clinical symptom of severe azotemia. Intensive Care Med. 2015;41(7):1357–8.
Lee SA, Cozzi M, Bush EL, Rabb H. Distant organ dysfunction in acute kidney injury: a review. Am J Kidney Dis. 2018;72(6):846–56.
de Borges Sá SL, Faria MLM, Gonçalves TLO, Libório AB. Comorbidities, acute kidney injury and long-term mortality in elderly patients hospitalized because of hip fracture: a moderation analysis. Aging Clin Exp Res. 2024;36(1):123.
Verbrugge FH, Guazzi M, Testani JM, Borlaug BA. Altered hemodynamics and end-organ damage in heart failure: impact on the lung and kidney. Circulation. 2020. https://doi.org/10.1161/CIRCULATIONAHA.119.045409.
Zhao J, Tang M-H, Shen Q-H, Xu D-C. The effectiveness of dexmedetomidine for preventing acute kidney injury after surgery: a systematic review and meta-analysis. Front Med. 2024;11:1414794.
Liu H, Luo R, Qian L, Zhang Y, Zhang W, Tan J, et al. The effect of dexmedetomidine on acute kidney injury after elective major abdominal surgery: a retrospective single-center propensity score matched study. BMC Anesthesiol. 2024;24(1):456.
Nakazawa D, Kumar SV, Marschner J, Desai J, Holderied A, Rath L, et al. Histones and neutrophil extracellular traps enhance tubular necrosis and remote organ injury in ischemic AKI. J Am Soc Nephrol. 2017;28(6):1753–68.
McMahon GM, Zeng X, Waikar SS. A risk prediction score for kidney failure or mortality in rhabdomyolysis. JAMA Intern Med. 2013;173(19):1821–8.
Koyner JL, Carey KA, Edelson DP, Churpek MM. The development of a machine learning inpatient acute kidney injury prediction model. Crit Care Med. 2018;46(7):1070–7.
Jiang X, Hu Y, Guo S, Du C, Cheng X. Prediction of persistent acute kidney injury in postoperative intensive care unit patients using integrated machine learning: a retrospective cohort study. Sci Rep. 2022;12(1):17134.
Acknowledgements
The authors declare that there are no acknowledgments for this study.
Funding
None declared.
Author information
Authors and Affiliations
Contributions
H.Q. wrote the main manuscript text, designed the research and analyzed the data. Q.W., J.T., and X.T. performed the research; H.Z. and Y.Y. designed the research; W.L. analyzed the data; B.Y., G.S., and S.D. contributed analytical tools. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qin, H., Wu, Q., Tan, J. et al. Development of a machine learning-based prediction model for acute kidney injury associated with respiratory failure in the intensive care unit. Clin Exp Med 25, 326 (2025). https://doi.org/10.1007/s10238-025-01873-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1007/s10238-025-01873-y