
Abstract
Purpose
Depressive symptoms are associated with reduced processing of and memory for positive content. These cognitive biases maintain depressive states, and are presumed to be interrelated. This study examined the effect of a single-session training to process (or inhibit) positive stimuli, on memory of new emotional content.
Methods
Participants (N = 138) were randomly assigned to conditions designed to increase or inhibit processing of positive content. Then, they made self-referential judgments concerning positive, negative and neutral words. Lastly, they free-recalled the words and completed a depression questionnaire.
Results
Training was effective in directing participants’ processing efforts. However, the effect of the training on self-referential judgment and memory for new positive content was only significant when contingent on depression levels. Positive endorsement and recall biases were negatively affected by the positive training among participants with higher depression scores.
Conclusions
These findings shed light on possible adverse effects of extensive exposure to positive content in depression.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Cognitive theories of depression (Beck, 1976; Beck & Bredemeier, 2016; Ingram, 1984; Teasdale, 1988), suggest that people with depression are characterized by biases in attention control and memory, that play a crucial causal role in the onset and maintenance of depression (Everaert et al., 2022; Joormann & Quinn, 2014; LeMoult & Gotlib, 2019).
Empirical research supports these theories, showing depression-related difficulties in attention control, the ability to selectively attend to or inhibit the processing of stimuli (Wante et al., 2017), in accordance with their goal relevance (Gable & Harmon-Jones, 2010; Hart & Gable, 2013; Liu & Wang, 2014; Wen et al., 2023). Individuals with current or remitted depression or those with dysphoria show impaired cognitive control over negative, as compared to both neutral and positive stimuli. Conversely, non-depressed controls display a reverse pattern of weaker cognitive control over positive compared to negative stimuli (Quigley et al., 2022; Villalobos et al., 2021). Similar patterns are also manifested in memory biases that characterize depression. Specifically, people with high levels of depressive symptoms show enhanced retrieval of negative and diminished retrieval of positive content from memory (Everaert et al., 2022; Gaddy & Ingram, 2014; Sorenson et al., 2014).
These biases toward processing positive or negative content are amplified when stimuli are processed self-referentially (Dai et al., 2015; Ji et al., 2017; Kuiper & Derry, 1982). Individuals with high levels of depression often self-identify with negative adjectives, reject positive ones faster, and remember fewer positive and more negative descriptors than their non-depressed counterparts (Auerbach et al., 2015; Kircanski et al., 2013; LeMoult et al., 2017). These biases, which suggest deeper engagement in later processing stages rather than early attention differences (Dainer-Best et al., 2017; Ji et al., 2017), emphasize the significance of self-referential processing in depression. Modifying self-referential processing is vital for people with depressive symptoms, as studies show that negative self-referential processing predicts more detrimental symptoms and course of depression (Disner et al., 2017; Hards et al., 2020). Although the tendency to endorse emotional content as self-relevant may be considered a stable one (Dozois, 2007), studies report that self-referential processing biases are affected by experimental manipulations, such as mood induction, self-focus or positive imaginary training (Dainer-Best et al., 2018a, 2018b; Hedlund & Rude, 1995; Ramel et al., 2007). Therefore, given the understanding that biases in self-referential content can be influenced by experimental manipulation, in the current research we encouraged processing of (vs. inhibiting) positive content to foster positive self-referential processing (Dainer-Best et al., 2017).
Cognitive biases do not cause or maintain depressive symptoms independently (Borsboom, 2017; Hankin, 2012). Instead, the combined cognitive bias hypothesis (CCBH) posits that these biases interact, and their combined impact on emotional symptoms is more pronounced than the effect of each bias alone (Chun & Turk-Browne, 2007; Hirsch et al., 2006). Empirical support for CCBH reveals links among attention, interpretation, and memory biases (Everaert & Koster, 2020; Imbriano et al., 2022; Leung et al., 2022; Nieto & Vazquez, 2021; Wang et al., 2022). An updated extension of the CCBH highlights the mechanisms of interactive effects between biases in depression (Brzozowski & Philip Crossey, 2024; Everaert & Koster, 2020; Everaert et al., 2020; Fernandez et al., 2022). Specifically, negative memories that are more easily accessed in depression (Joormann & Siemer, 2004) orient and maintain attention on negative stimuli. This increased attention not only enhances the processing of negative content but also attenuates processing of new positive information (Ellis et al., 2011; Koster et al., 2010). Over time, such biased processing can solidify initial negative memories, further directing attention towards similarly negative environmental content and away from positive content. In the present study, rather than attempting to directly alter the bias towards negative content, our aim was to explore the potential of prompting individuals with varying levels of depression to engage with positive content (as opposed to inhibit positive content). Specifically, we sought to investigate whether this approach can influence participants’ self-referential processing and recall of new emotional content.
Studies testing the CCBH have adopted one of two approaches. The first investigates if training one bias to a specific content affects its processing in a related cognitive process (Ellis et al., 2014; Everaert et al., 2014). However, the repeated presentation of the same stimuli, while enhancing task reliability (Hertel & Mathews, 2011), makes broader conclusions challenging, particularly regarding transfer of the training to memory of novel stimuli. Therefore, another approach to test the CCBH extensions assumes that the transfer of training of one bias to another should be assessed with different stimuli (Blaut et al., 2013; Henricks et al., 2022; LeMoult et al., 2018; Rozenman et al., 2014).
To study the influence of one cognitive bias on another and their effects on emotional disorders, the cognitive bias modification (CBM) procedure is employed (Hallion & Ruscio, 2011). CBM involves repeatedly encouraging participants to process stimuli in a bias-consistent or inconsistent manner (Cristea et al., 2015; Fodor et al., 2020; MacLeod & Mathews, 2012). Apart from impacting emotional symptoms (Qu et al., 2019), CBM has been used to understand causal relations between attention, inhibition, and memory biases. For instance, training participants with elevated levels of depression to process positive content and disengage from negative content, increased retrieval of positive and reduced retrieval of negative content (Blaut et al., 2013; Woolridge et al., 2021). Furthermore, in a line of studies, participants have been trained to inhibit negative word stimuli (Daches & Mor, 2014; Daches et al., 2015, 2019). The training was based on the negative affective priming task (NAP; Joormann, 2006), wherein participants were presented with word-pairs (a target and a distractor, each identified by a different color) and indicated the valence of the target while ignoring the distractor. In the negative training condition, the target was mostly neutral and in the control training condition it was mostly negative. The negative training condition fosters inhibition of negative targets and was found to reduce rumination. Most recently, we found that the training reduced negative memory bias for subsequent newly-presented and self-referentially processed content (Daches & Mor, 2014; Daches et al., 2015, 2019).
The current work is an extension of this line of work to processing and memory of positive content. This focus is crucial due to avoidance of positivity and reduced processing of positive content that characterize depression (Epp et al., 2012; Gallagher et al., 2023a, 2023b; Pool et al., 2016). Therefore, rather than contrasting negative and neutral content, we examined positive and neutral content. The study consisted of two conditions. In the positive processing (PP) condition, participants learned to recognize the relevant stimuli (positive) through their consistent association with a target color, and in the positive inhibition (PI) condition, they learned to inhibit the positive stimuli.
Unlike the commonly used dot-probe training task (e.g., Beevers et al., 2015; LeMoult et al., 2016; Mogoaşe et al., 2014; Yang et al., 2015) which trains visual attention, the NAP-based training demands deep semantic processing and is suitable for assessing attention control (Daches et al., 2015). It encourages reading of both words and learning which is a more likely target. To direct processing resources toward positive stimuli, while ensuring processing of both words, the task incorporates three elements: (1) randomization of the target word location (top or bottom), (2) participant responses are determined by target word valence, and (3) 16% of the trials are training-incongruent, urging participants to process valence, rather than responding automatically. High accuracy on training-incongruent trials signifies proper word processing, beyond mere target color response.
Previous CBM studies primarily trained people to shift from negative stimuli to neutral or positive ones (e.g., Daches et al., 2019; Ellis et al., 2014). Few studies have attempted to modify attention control for positive content (Gao et al., 2022; Iacoviello et al., 2014; Sanchez-Lopez et al., 2019), and the effects of training on memory have not been explored. A key limitation in research on positive content is that positive and negative stimuli are often presented together, making it hard to discern the effects of one from the other (Ferrari et al., 2016; Möbius et al., 2018). In the current research, drawing from prior work (Daches et al., 2015), we contrast engagement with positive and neutral counterparts, to assure that training to process positive, does not concomitantly train to inhibit negative.
The current research has two goals. First, we assessed the effect of prompting participants to process vs. inhibit positive content, on subsequent processing and retrieval of new self-referential emotional information. As in prior research (Grafton et al., 2012; MacLeod et al., 2002), we also tested training effects on mood. Given inconsistent effects of cognitive training on depression (Fodor et al., 2020) and avoidance of positivity among those with depression (Gallagher et al., 2023a, 2023b; Gollan et al., 2016; Winer & Salem, 2016), we examined if depression severity reduces training effects on positive memory bias.
In order to examine the effect of the training task on memory bias, we used the self-referential encoding task (SRET; Gotlib et al., 2004). The SRET is an index of self-schema that measures self-referential processing. In this task, participants indicate whether valenced words describe them, and are later asked to recall the words presented in the task. The number of endorsed words of each valence category and the speed of deciding whether adjectives were self-descriptive, are strongly correlated with depression severity (Dainer-Best et al., 2018a, 2018b). Nonetheless, the SRET is also frequently used as a measure of processing or memory biases (Bentley et al., 2017; Durbin et al., 2017; Kalenzaga & Jouhaud, 2018). The memory index yielded in this task is designed to account for and control the influence of self-referential processing (Dainer-Best et al., 2018a, 2018b; Gotlib et al., 2004) by focusing on the retrieval of self-endorsed words across different valence categories.
We predicted that participants in the positive training condition (as compared to positive inhibition) will be successfully trained to regard positive content as relevant. Furthermore, in line with the CCBH, we predicted that training participants to regard positive stimuli as relevant will affect retrieval on a subsequent SRET. Thus, we expected that participants trained to process positive content, would show increased endorsement of positive content as self-relevant and subsequently increased retrieval of positive content compared to those trained to inhibit positive content. Moreover, we predicted that training effects would be moderated by depression levels. Specifically, we predicted that the transfer effect would be less pronounced among participants with higher depression scores. Lastly, we predicted increased positive affect following the training among participants in the positive training condition compared to those in the inhibition condition, and that the effect will be less pronounced among participants with higher depression levels effect.
Given the novelty of the modified NAP task, we first evaluated its effectiveness in training participants to either process or inhibit the processing of positive words. Effectiveness is typically examined using assessment trials that do not encourage preferential processing of positive or neutral content (e.g., Clarke et al., 2017; Grafton et al., 2014). However, the presence of assessment trials could dilute the training and reduce its effect on subsequent tasks. Therefore, we conducted a separate study to assess the efficacy of the training task, later followed by the main experiment in which we assessed training effects on self-referential processing and memory. This pilot study comprised the training task, followed by assessment trials to evaluate participants’ bias to respond to positive vs. neutral target words. To examine the efficacy of the training in the main experiment, we examined response times to training-congruent and incongruent stimuli at the beginning and end of the training, as a measure of change in processing bias.
Method
Pilot Study
Participants (N = 78) were university students, recruited via the Hebrew University of Jerusalem’s recruiting system (Sona Systems). The participants took part in the study in return for course credit or payment. All participants were native Hebrew speakers of Israeli nationality and had normal or corrected-to-normal vision. Using a power analysis software (G*Power; Faul et al., 2007), we determined that a sample size of 66 would suffice to provide power = 0.80, and to detect a small-medium effect (f = 0.176). Due to the Covid-19 epidemic, we anticipated a higher than usual dropout rate, and therefore, recruited a slightly larger sample to account for possible attrition. Data from one participant were excluded based on the interquartile method (Laurikkala et al., 2000; Smiti, 2020)Footnote 1 due to high frequency of responses faster than 200 ms (< 8SD from mean). Gender was assessed in a non-binary fashion and participants were asked to choose whether they identified as a woman, man, or other (and given the option to specify). The final sample consisted of 77 participants (53 females, 24 males). Participants’ mean age was 24.14 (SD = 4.23).Footnote 2 The majority of participants completed high school (N = 68), and 9 participants indicated they held a bachelor’s degree.
NAP Training Task
The training task was designed based on a training procedure developed in our lab (Daches & Mor, 2014; Daches et al., 2015, 2019). The original task consisted of pairs of negative and neutral words, each in a different color (blue or red). Participants were asked to focus on the words in one of the colors (target words) and to indicate the valence of the target words. In the current version, instead of negative and neutral target words, target words were either positive or neutral in order to train participants to process (PP) or inhibit (PI) positive content.
Following a centrally located fixation cross, displayed for 500 ms (ms), participants were presented with a display of two words: one positive and one neutral, each in a different color (blue or red) one above the other. Participants were instructed to respond to words in one color (target words) and ignore words in the other color and to indicate by pressing a selected key on the keyboard, the valence of the target word. The location of the target word (top vs. bottom) was randomized across trials. Words remained present until the participant’s response, or for 2000 ms.
In the PP condition, positive words were the targets in 85% of trials, while neutral words were the targets in approximately 15%. The reverse was true for the PI condition. We used 85% of the trials instead of 100% to encourage participants to process the words before they respond to them. Thus, participants in the PP condition were trained to regard positive words as relevant and process them, whereas those in the PI condition were trained to inhibit them. The word pairs were repeated across blocks and appeared in random order in each block and across participants. Between blocks, participants were offered a short break. RTs and participants' valence classifications were recorded.
Words in the training task were selected from Warriner et al., (2013) and translated to Hebrew. In order to confirm that the translated words preserved their valence during the translation, 20 undergraduate participants categorized 180 words (nouns) as positive or neutral. Only words that were consistently categorized as positive or neutral (by more than 85% of participants) were chosen for the training task. The positive and neutral words did not differ in mean length (t(76) = 1.83, p = 0.07) or frequency (t(76) = − 0.05, p = 0.95) in the Hebrew language (Frost & Plaut, 2005). Each positive word was paired with a neutral word of the same length. Because words vary vastly in their length (number of letters and the space they take on a page), to control for effects of word-length, positive and neutral words were paired a-priori based on length.
Procedure
The pilot study consisted of the NAP training task followed by assessment trials. The training task consisted of 27 positive and neutral word-pairs repeated over 12 blocks (324 trials in total). In the PP condition, positive words were the targets in 23 trials, while neutral words were the targets in 4 trials. The reverse was true for the PI condition. The assessment task, comprising 32 trials of novel positive and neutral words, was administered immediately following the training task. In both conditions, half of the target words in the assessment task were positive, while in the other half the target words were neutral.
Results
We conducted two analyses, assessing RT (response time) and accuracy rates (i.e., percentage of correct responses) in the assessment task. For the training task to be successful in training processing bias, we predicted an interaction effect in which RT would be lower and accuracy would be higher for training congruent compared to training-incongruent words (e.g., RT for positive words will be lower than neutral words in the PP condition). RTs that were 4 SD above or below the mean RT for each participant were eliminated (0.6%; see main study for a detailed explanation).
RTs were submitted to a repeated measures analysis of variance (ANOVA) with valence as a within-subject variable (positive, neutral) and condition (PP, PI) as a between-subjects variable.Footnote 3 The analysis revealed main effects for valence (F(1,75) = 31.80, p < 0.001, ηp2 = 0.30) and condition (F(1,75) = 5.82, p = 0.018, ηp2 = 0.07), and an interaction between valence and condition (F(1,75) = 9.42, p = 0.003, ηp2 = 0.11). In order to interpret the interaction, we examined the simple main effects for each condition separately. In the PP condition (F(1,75) = 37.43, p < 0.001, ηp2 = 0.33), RT for positive words (M = 820.94, SE = 17.86) was significantly lower than for neutral words (M = 923.84, SE = 21.57), whereas in the PI condition (F(1,75) = 3.35, p = 0.07), the difference between RT for positive words (M = 796.38, SE = 17.63) and neutral words (M = 826.756, SE = 21.30) was not significant. This effect indicated that in PP condition, participants successfully responded to positive words faster than to neutral words.
Next, because the percentage of correct responses violated the assumptions of normality, we submitted log transformed percentage of correct responses to a repeated measures ANOVA with valence as a within-subject variable (positive, neutral) and condition (PP, PI) as a between-subjects variable. The interaction between valence and condition was significant (F(1,75) = 15.86, p < 0.001, ηp2 = 0.18). The main effect of valence (F(1,75) = 0.001, p = 0.97) and condition (F(1,75) = 1.06, p = 0.30) were not significant. In order to interpret the interaction, we examined the simple main effects for each condition separately. In the PP condition (F(1,75) = 7.70, p = 0.007, ηp2 = 0.09), there were more correct responses for positive (M = 0.94, SE = 0.02) than for neutral words (M = 0.88, SE = 0.02), whereas, in the PI condition (F(1,75) = 8.17, p = 0.006, ηp2 = 0.10), there were fewer correct responses for positive (M = 0.89, SE = 0.02) than for neutral words (M = 0.96, SE = 0.02). This indicated that in the PP condition, participants responded more accurately to positive words, while in the PI condition, participants responded less accurately to positive words.Footnote 4
In summary, participants in the PP condition responded faster to positive vs. neutral words. Furthermore, those in the PP condition showed significantly higher accuracy and lower error rate for positive words, while those in the PI condition showed significantly lower accuracy and higher error rate for positive words. Together, these findings suggest that there is increased processing of positive content in the PP condition as compared to the PI condition.
Main Study
Participants
Participants (N = 138) were university students, recruited via the Hebrew University of Jerusalem’s recruiting system (Sona Systems). The participants took part in the study in return for course credit or payment. All participants were native Hebrew speakers of Israeli nationality and had normal or corrected-to-normal vision. Participants’ mean age was 23.88 (SD = 2.84). Gender was assessed in a non-binary fashion, and 113 participants identified as females and 25 as males. The majority of participants completed high school (N = 127), and 11 participants indicated they held a bachelor’s degree. Participants were equally and randomly assigned to one of two conditions: positive processing (PP, N = 70) and positive inhibition (PI, N = 68). Using a power analysis software (G*Power; Faul et al., 2007), we determined that a sample size of 128 would suffice to provide power = 0.80, and to detect a medium effect (f = 0.25) as was reported in Daches et al. (2019). Due to the Covid-19 epidemic, we anticipated a higher than usual dropout rate, and therefore, recruited a slightly larger sample to account for possible attrition.
Training Task
The training task was similar to the task in the pilot study, with several minor adjustments: Because we did not use assessment trials, we increased the number of word pairs and reduced the number of blocks, in order to strengthen the training. This potentially prevents habituation and maintains engagement, as participants are less likely to become bored or overly familiar with the training stimuli. Therefore, the task was comprised of 9 blocks instead of 12 as in the pilot study, each of which consisted of 38 word-pairs (342 trials in total). In the PP condition, positive words were the targets in 32 trials (84.21%), while neutral words were the targets in 6 trials (15.79%). The reverse was true for the PI condition.
Self-Referential Encoding Task (SRET)
The task was designed based on Gotlib et al. (2004) to assess memory bias. Participants were presented with positive, negative or neutral words, one at a time. On each trial, the words “Describes me or is related to me?” appeared in the center of the screen for 500 ms, followed by a 250 ms black screen. Then, a word was centrally presented, and participants indicated by pressing selected keys on the keyboard their response to the word. Following the participants’ response, the word disappeared. The intertrial interval was 500 ms. The words were presented in a random order. Subsequently, participants completed a minute-long distractor task (computerized “find the differences” task), and then were asked to recall as many words as possible from the rating phase, regardless of whether they endorsed the words as self-descriptive or not, and were allotted three minutes for the recall. Participants' classifications of self-relevance were recorded, and recall scores were calculated (see results section).
A set of 60 words (different from those used in the NAP training task), 20 in each valence were used in the SRET. Words were based on Gotlib et al. (2004) word lists (positive, depressogenic and neutral lists) and were translated to Hebrew by the first author and were then back-translated by another researcher. As in Gotlib et al. (2004) the word lists consisted of positive and negative adjectives (e.g., caring, creative, honest, and lonesome, ruined, indifferent respectively) and neutral adjectives (e.g., analytic, fluid, automatic) and nouns (e.g., object, space, event). Because neutral adjectives are rare (Anderson, 1968; Warriner et al., 2013), and neutral words are crucial for our research question we included in our word list a number of neutral adjectives and supplemented them with neutral nouns. As in the original task, participants were asked to indicate for each word whether it “Describes me or is related to me?”, to accommodate for the inclusion of neutral nouns.
Mood Questionnaire
Mood was measured using a six-item mood questionnaire based on the PANAS-X (Watson & Clark, 1994) that consisted of three positive and three negative mood items from the joviality and sadness subscales.Footnote 5 Participants were asked to indicate, on a visual analog scale ranging from 0 (not at all) to 100 (very much) whether they currently experience each emotional state. Additional items were added for exploratory purposes and are not reported in this study. These mood items (with reverse-scoring of the negative items) were submitted to a factor analysis by conducting principal axis factoring with oblique rotation. The Kaiser–Meyer–Olkin measure (0.85) verified the excellent sampling adequacy for the analysis (Field, 2009). Bartlett’s test of sphericity, χ2 (15, N = 132) = 696.43, p < 0.001, indicated that correlations among items were sufficiently large for the principal axis factoring. Parallel analysis was conducted to validate our factor retention decisions which compares the eigenvalues derived from the actual data with those obtained from randomly generated data sets using Patil et al. (2017) software. The initial eigenvalues indicated that the first factor accounted for a substantial portion of the variance (70.84%, eigenvalue = 4.25), while the second factor explained an additional 15.63% (eigenvalue = 0.94), with subsequent factors contributing minimal variance. The parallel analysis results confirmed that only the first factor had an eigenvalue exceeding the 95th percentile of the distribution generated from random data (1.44). The second factor's eigenvalue, along with those of the subsequent factors, did not exceed this threshold (eigenvalue = 0.94 vs. 1.22 for the 95th percentile), suggesting that these should not be retained. Based on these findings, we concluded that a single factor should be retained, which accounted for 66.53% of the variance. Therefore, we reverse-scored the negative items and computed a total score of positive mood that included the reversed negative items.Footnote 6 The internal consistency of the scale was excellent (α = 0.91).
Depression Levels Questionnaire
Depression levels were assessed using the PHQ-8 (Kroenke & Spitzer, 2002). This questionnaire is originally a 9-item questionnaire that measures depressive symptom severity. For ethical reasons, the question assessing thoughts about death and self-harm was not included.Footnote 7 A score of 10 or above is typically used as the clinical cutoff to indicate significant depressive symptoms (Levis et al., 2019). Average PHQ-8 score in the general population in Israel (Weisman et al., 2022) is 5.8 (SD = 4.3). The internal consistency of the scale in the current study was very good (α = 0.89).
Procedure
The study was administered online. Participants were instructed to find a quiet space in their home with minimum distractions, to turn off their phones and to complete the study sequence without taking breaks. After signing a consent form, they completed baseline mood measure (time 1), and were randomly assigned to one of the training conditions (PP, PI). Then, they completed a second mood measure (time2), and the SRET. Lastly, participants were asked to complete the Patient Health Questionnaire (PHQ-8; Kroenke & Spitzer, 2002) and additional questionnaires that are not reported in this study. The experimental session took approximately 30 min to complete.
Results
Data Reduction
Participant characteristics (by training condition) are presented in Table 1. There were no significant group differences in these characteristics. The mean PHQ-8 in this study (ME = 7.7) is higher than is typical for an Israeli sample (5.8; Weisman et al., 2022), most likely because data collection took place during the Covid-19 pandemic (Ettman et al., 2020). Data from six participants were removed from further analyses based on the interquartile method for the following reasons: high frequency of responses faster than 200 ms (< 6SD, N = 2), low frequency of correct responses (< 7SD from mean; N = 1), long duration (10 h to complete the experiment, < 14,200 SD, N = 1). Data from two participants was also removed as result of failure to recall any words on the SRET (N = 2). The final sample included 132 participants.
Training Efficacy: Change in Processing Bias During the Training Task
To demonstrate training efficacy, mean RT for each participant was calculated by averaging RTs for trials with correct responses (95% of trials). We hypothesized that participants in PP condition would show reduced RT in the last block compared to the first one in response to positive stimuli but not neutral stimuli. We expected the reverse pattern among participants in the PI condition.
RTs that were 4SD above or below the mean RT for each participant were eliminated (0.6% of correct trials). Although a commonly used cutoff is 3SD, well-established guidelines suggest that the location of the optimal cutoff depends on the shape of the distribution (Ratcliff, 1993). The 3SD cutoff represents an expected 0.5% percentage of excluded data points in a normal distribution (Berger & Kiefer, 2021). In the current sample, a cutoff of 3SD resulted in loss of 2% data points, well above the expected. Therefore, we selected a cutoff of 4SD, which resulted in 0.6% of data loss. In addition, we used the a-priori lower threshold of 200 ms, which is the necessary time for attention and response execution (Whelan, 2008).
Because RT data violated the assumptions of normality, log transformed RTs for positive and neutral targets in the first and last blocks were submitted to a 2 (condition: PP, PI) × 2 (block: first, last) × 2 (valence: positive, neutral) repeated measures ANCOVA with standardized depression scores as a covariate (Table 2). Data from two participants were removed from this analysis due to no correct responses in either the first or last block of one target valence.
The analysis revealed significant main effects of valence (F(1, 126) = 18.14, p < 0.001, ηp2 = 0.13), block (F(1, 126) = 271.54, p < 0.001, ηp2 = 0.69), and of standardized depression scores (F(1,126) = 4.08, p = 0.045, ηp2 = 0.03), as well as a significant interaction between valence and condition (F(1,126) = 249.61, p < 0.001, ηp2 = 0.66), which were further qualified by the predicted three way interaction of block, valence and condition (F(1, 126) = 50.78, p < 0.001, ηp2 = 0.29). RT for neutral words (M = 750.30, SE = 8.61) was higher than for positive words (M = 721, SE = 8.23). RT in the first block (M = 807.27, SE = 9.79) was higher than the in the last block (M = 664.18, SE = 8.58). Moreover, participants with higher depression scores responded slower than those with lower depression scores (r = 0.18, p = 0.03). All other main effects and interactions were non-significant (see supplementary materials).
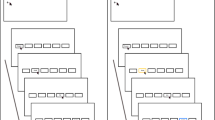
To explore the three-way interaction, a 2 (block: first, last) by 2 (valence: positive, neutral) repeated measures analysis of variance (ANOVA) was conducted for each condition separately (Fig. 1). As expected, in the PP condition participants showed a significant decrease in RT for positive targets compared to neutral targets (F (1,65) = 29.70, p < 0.001, ηp2 = 0.31). In the PI condition, participants showed a significant decrease in RT for neutral targets compared to positive targets (F(1,63) = 21.34, p < 0.001, ηp2 = 0.25). Thus, the training was successful in increasing processing bias of positive stimuli in the PP condition and inhibiting processing of positive stimuli in the PI condition. Notably, accuracy rates for incongruent trials in the latter blocks remained consistently high (70% in the PP condition and 78% in the PI condition; see supplementary materials). This pattern suggests that the participants did not respond automatically to the task. Thus, faster RTs in later blocks is not solely a result of a tendency to press the key repeatedly, but likely reflects processing of the semantic meaning of the words.

Reaction times (RTs) for positive and neutral target words in the first and last blocks in the two training conditions. Error bars represent 95% confidence intervals. PP positive processing. PI positive inhibition. The dark gray line represents responses to positive target words whereas the light gray line represents responses to neutral target words
We then examined accuracy rates by calculating the percentage of correct responses for positive and neutral stimuli in the first and last blocks for each participant. We hypothesized that participants in the PP condition would show higher accuracy in the last block compared to the first for positive stimuli, but not for neutral stimuli. We expected the reverse pattern among participants in the PI condition.
Because percentage of correct responses violated the assumptions of normality, we submitted log transformed percent of correct responses to a repeated measures ANCOVA with valence (positive, neutral) and block (first, last) as a within-subject variables and condition (PP, PI) as a between-subjects variable and depression scores as a moderator. The main effect of block (F(1,126) = 17.89, p < 0.001, ηp2 = 0.12), and the interaction between valence and condition were significant (F(1,126) = 89.57, p < 0.001, ηp2 = 0.42). Similarly, the interactions of block and condition (F(1,126) = 9.30, p = 0.003, ηp2 = 0.07) and block and valence (F(1,126) = 8.71, p = 0.004, ηp2 = 0.06) and the three way interaction between valence, block and condition (F(1,126) = 49.82, p < 0.001, ηp2 = 0.28) were all significant. All other main effects and interactions were non-significant (see supplementary materials).
In order to interpret the three-way interaction, we examined the interaction between valence and block for each condition separately. In the PP condition the main effect of valence (F(1,65) = 46.46, p < 0.001, ηp2 = 0.42), block (F(1,65) = 30.52, p < 0.001, ηp2 = 0.32) and the interaction between block and valence (F(1,65) = 54.02, p < 0.001, ηp2 = 0.45) were significant. Pairwise comparisons with Bonferroni adjustment for multiple comparisons showed that in neutral target words the effect of block was significant (F(1,65) = 43.85, p < 0.001, ηp2 = 0.40), indicating that the percentage of correct responses for neutral words was higher in the first block compared to the last block. Moreover, pairwise comparisons showed that in positive target words the effect was also significant (F(1,65) = 15.20, p < 0.001, ηp2 = 0.19), indicating that the percentage of correct responses for positive words was higher in the last block compared to the first block (Table 2). In the PI condition, the main effect of valence (F(1,63) = 43.02, p < 0.001, ηp2 = 0.41) and the interaction between block and valence (F(1,63) = 7.74, p = 0.007, ηp2 = 0.11) were significant. The main effect of block was not significant (F(1,63) = 0.60, p = 44). Pairwise comparisons with Bonferroni adjustment for multiple comparisons showed that in neutral target words the effect of block was significant (F(1,63) = 15.26, p < 0.001, ηp2 = 0.20), indicating that the percentage of correct responses for neutral words was higher in the last block compared to the first block. The effect of block was not significant for positive target words (F(1,63) = 3.27, p = 0.08).
In summary, participants in the PP condition showed higher accuracy for positive words and lower accuracy for neutral words in the final block compared to the first block, while those in the PI condition exhibited higher accuracy for neutral words in the final block compared to the first block, but no significant change for positive words.
Training Effects on Self-Referential Ratings
We examined whether participants in the two experimental conditions differed in the proportion of words endorsed in each valence category (Table 2). Specifically, we computed an index of the proportion of words endorsed in each valence category, out of the total number of words that a participant endorsed as self-descriptive (Gotlib et al., 2004). For example, a mean of 0.75 for positive words indicates that of all the endorsed words, 75% were of positive valence. We expected a higher endorsement rate of positive words among participants in the PP condition compared to those in the PI condition, and that the transfer effect would be less pronounced among participants with higher depression scores. We also expected a main effect of depression scores on endorsement of negative words, such that higher levels of depression would be associated with a higher proportion of endorsement of negative words. In order to examine the effect of depression levels, depression scores were included as a moderator in all the analyses. Because the three proportions sum to 1 and cannot be compared directly in a single analysis, we conducted 3 separate moderation analyses using Hayes’s (2013) PROCESS bootstrapping command (Model 1: 5000 iterations). Also, because the proportion data violated the assumptions of normality, log transformed proportions of endorsed words were used.
The first analysis included Condition (PP, PI) as the independent variable, log transformed proportions of endorsed positive words (positive endorsement bias) as the dependent variable, and standardized depression scores as a moderator. The overall model was significant (F(3,128) = 16.35, p < 0.001), revealing a significant moderation effect of depression on the effect of condition on positive endorsement bias. Contrary to our hypothesis, the main effect of condition (b = − 0.02, p = 0.31) was not significant. The main effect of depression scores (b = − 0.04, p = 0.002) was significant, and indicated that participants with higher depression levels endorsed fewer positive words. Importantly, the interaction between condition and depression level was also significant (b = − 0.05, p = 0.02). Using the Johnson–Neyman technique (Johnson & Neyman, 1936) that allows the exact computation of conditions and boundary values where a moderator elicits statistically significant slopes (Bauer & Curran, 2005), we identified regions of significance of the moderation effect. The analysis showed that the effect of condition on the positive endorsement bias was significant when depression scores on the PHQ-8 were higher than 10.40 (z = 0.48, effect = − 0.04, SE = 0.02; p = 0.05, 95% CI = [− 0.09, 0.00]). Because the clinical cut-off for depression is 10 (Levis et al., 2019), these results indicate that for participants with clinically-significant levels of depression, preferential processing of positive (as compared to neutral) content reduced their positive endorsement bias (Fig. 2).

The Effect of Depression Scores (Z Scores on the PHQ-8) on Positive Endorsement and Memory Biases in the Two Training Conditions. PHQ-8 Depression Scale of the Patient Health Questionnaire (excluding the suicidal ideation question). PP positive processing condition, PI positive inhibition condition. Shading represents 95% confidence bands. Rectangles represent regions of significance
The second analysis included Condition (PP, PI) as the independent variable, log transformed proportions of endorsed neutral words as the dependent variable, and standardized depression scores as a moderator. The overall model (F(3,120) = 1.44, p = 0.24), the main effects of condition (b = 0.05, p = 0.27) and depression scores (b = − 0.06, p = 0.08), as well as the interaction (b = 0.08, p = 0.13) were non-significant.
The third analysis included Condition (PP, PI) as the independent variable, log transformed proportions of endorsed negative words as the dependent variable, and standardized depression scores as a moderator. The overall model (F(3,109) = 9.08, p < 0.001) and the main effect of depression levels (b = 0.12, p = 0.004) were significant, indicating that participants with higher depression levels endorsed more negative words compared to participants with lower depression scores. The main effect of condition (b = 0.06, p = 0.30) and the interaction were not (b = 0.06, p = 0.31).
Training Effects on Recall
As in previous studies (Gotlib et al., 2004; Hayden et al., 2013; LeMoult et al., 2017), recall rates on the SRET were operationalized as the proportion of words endorsed and subsequently recalled in each valence category (positive, negative or neutral), out of the total number of words that they endorsed and recalled (Gotlib et al., 2004). For example, a mean of 0.8 for positive words indicates that of all the endorsed and recalled words, 80% were of positive valence (Table 2). This scoring method assures that memory bias is not confounded with group differences in endorsement (Gotlib et al., 2004). We hypothesized that participants in the PP condition would recall more positive words than those in the IP condition, and that the transfer effect would be less pronounced among participants with higher depression scores. We also hypothesized a main effect of depression scores on the proportion of recall of negative words.
As described above, the proportion of words endorsed and recalled in the three valence categories also sum to 1. Therefore, we conducted 3 separate moderation analyses using Hayes’s (2013) PROCESS bootstrapping command (Model 1: 5000 iterations). Moreover, as above, we conducted log transformation of the recall data. The first analysis included Condition (PP, PI) as the independent variable, log transformed proportions of recalled positive words (positive memory bias) as the dependent variable, and standardized depression scores as a moderator.
The overall model was significant, revealing a significant moderation effect of depression on the effect of condition on positive memory bias (F(3,128) = 8.18, p < 0.001). Although the main effects of condition (b = − 0.007, p = 0.78) and depression scores were insignificant (b = − 0.02, p = 0.23), the interaction was significant (b = − 0.06, p = 0.008). Using the Johnson–Neyman technique (1936), we identified regions of significance of the moderation effect. The effect of condition on the positive memory bias was significant when depression scores were either zero (z = − 1.36, effect = 0.08, SE = 0.04; p = 0.05, 95% CI = [0.00, 0.16]) or higher than 12.5 (z = 0.86, effect = − 0.06, SE = 0.03; p = 0.05, 95% CI = [− 0.12, 0.00]). These results indicate that for participants who report no symptoms of depression, preferentially processing positive (as compared to neutral) content led to increased positive memory bias. An opposite pattern emerged among those with higher (and clinically-significant) depression scores, whereby preferentially processing positive (as compared to neutral) content led to a decreased positive memory bias (Fig. 2).
The second analysis included condition (PP, PI) as the independent variable, log transformed proportions of recalled neutral words as the dependent variable, and standardized depression scores as a moderator. The overall model (F(3,64) = 0.95, p = 0.42), the main effects of condition (b = − 0.02, p = 0.69) and depression scores (b = − 0.07, p = 0.13) as well as the interaction (b = 0.06, p = 0.31) were non-significant.
The third analysis included Condition (PP, PI) as the independent variable, log transformed proportions of endorsed negative words as the dependent variable, and standardized depression scores as a moderator. The overall model (F(3,82) = 6.47, p = 0.006) and the main effect of depression (b = 0.11, p = 0.005) were significant, indicating that participants with higher depression levels recalled more negative words compared to participants with lower depression scores. The main effect of condition (b = − 0.04, p = 0.43) and the interaction between depression level and condition (b = 0.02, p = 0.75) were non-significant.
Training Effects on Positive Mood
Lastly, we examined whether training to process positive stimuli affected positive mood. The positive mood measure met the ANOVA assumptions of normality and homogeneity. Therefore, positive mood was submitted to a 2 (condition: PP, PI) × 2 (time: time1, time2) repeated measures ANCOVA with standardized depression scores as a covariate (Table 2). The main effect of depression scores was significant (F(1,128) = 67.67, p < 0.001, ηp2 = 0.35), indicating that participants with lower depression scores showed lower overall positive mood (r = − 0.59, p < 0.001). The main effect of time (F(1,128) = 1.56, p = 0.21) and condition (F(1,128) = 0.48, p = 0.49), as well as the interactions between time and condition (F(1,128) = 2.44, p = 0.12), between time and depression score (F(1,128) = 2.86, p = 0.09) and the interaction between time, condition and depression scores (F(1,128) = 0.04, p = 0.84) were non-significant. These results indicate that positive mood did not change from pre- to post-training, and that depression levels did not influence this effect.
Discussion
The current study examined the effect of training participants to preferentially process positive content (as opposed to inhibit) on self-referential processing and memory, and whether these effects varied by self-reported depression levels. Our pilot work provided evidence for the efficacy of the training procedure in increasing processing (vs. inhibiting) of positive content. The efficacy of the procedure was further supported in RT and accuracy rates analyses in the main experiment, demonstrating that participants responded faster and more accurately to training-congruent than -incongruent stimuli.
Our main prediction concerned the transfer effect of training to memory for emotional content processed self-referentially. We expected to find depression-related differences in the degree to which the training affects self-referential processing and memory. Our findings were partially consistent with our predictions, as the effect of the training on memory was contingent on depression levels. Training participants to process (vs. inhibit) positive stimuli, increased recall of new positive content only among individuals with no depressive symptoms. In contrast, training participants with high levels of depressive symptoms to process positive stimuli, yielded a training-incongruent effect and reduced their recall of new positive content. Similarly, the effect of training on positive self-referential ratings was contingent on depression levels. Training participants with high levels of depressive symptoms to process positive stimuli reduced their self-endorsement of new positive content.
Such training-incongruent effects on cognitive biases as well as emotional symptoms have been reported previously, and factors that have contributed to such effects may help explain the training-incongruent effects in depressed participants in the current study. First, some studies found that the effect of CBM depends on participants’ attitudes and ability to relate to the training materials (Smith et al., 2019; Standage et al., 2014). Those who did not relate to the training materials or had an evaluative orientation towards the materials showed increased emotional vulnerability following positive CBM training (Standage et al., 2014).
Second, studies showed effects of training dose on efficacy, and ineffective dosing was related to training-incongruent or iatrogenic effects (Price et al., 2017). For example, meta-analyses have shown that an excessive number of training sessions or trials can negatively impact CBM effectiveness (Cristea et al., 2015; Price et al., 2017), possibly due to fatigue and cognitive load induced by the training. In contrast, single-session training protocols were less effective (Beard et al., 2012; Hallion & Ruscio, 2011), potentially due to the lack of critical between-session consolidation effects (Abend et al., 2013, 2014).
Third, some studies have found training incongruent effects specifically among those with a cognitive vulnerability to depression or those who ruminate habitually (Baert et al., 2010; Daches et al., 2015; Jones & Sharpe, 2017; Ronold et al., 2022). Such vulnerability may limit cognitive resources and impact the ability to benefit from training and change cognitive biases (Haeffel et al., 2012). Indeed, several studies showed that high cognitive load reduces people’s ability to benefit from CBM (Wei & Zhou, 2020; Yap et al., 2021).
Our findings concerning depressive symptoms are complex. Depression did not moderate training effects in the training task itself: all participants, regardless of depression levels, showed the trained bias, which indicated that participants were able to acquire the intended learning during the training task, irrespective of their depression levels. Nonetheless, the transfer of the training to positive self-referential ratings and memory was contingent on depression levels: only participants without depressive symptoms showed the predicted training effect on memory for positive content. In contrast, high depression levels (above clinical threshold of the PHQ-8 measure) were associated with training-incongruent effects.
Thus, for participants with clinically-meaningful levels of depression, repeated processing of positive content in the absence of additional instructions or context, might not be beneficial. Aligning with previous work (e.g., Standage et al., 2014) that demonstrated increased emotional vulnerability in individuals who did not relate to CBM training materials, our findings suggest that positive training could potentially exacerbate cognitive biases in depressed people. This paradox may be explained by the well-documented negative bias in self-referent processing that is characteristic of depression (Everaert et al., 2018; Gotlib & Joormann, 2010). Depressed individuals are more likely to engage in negative self-referent processing. This tendency may have counteracted the benefits of the training, leading to a reverse effect when applied to a self-referent task.
Based on previous research, we propose several possible explanations for the reduced recall of positive words in the PP condition among participants with higher depression levels. People with depression show impaired intrinsic motivation for positive self-reference (Takano et al., 2016). In the current study, this reduced motivation may have manifested itself in lowered relating to the positive training materials. Indeed, depressed participants trained to process positive stimuli, showed a negative bias in self-referential rating, suggesting that they did not relate to the positive training materials, and possibly leading to training-incongruent effects in memory. Moreover, directional epistemic motives theory proposes that people use self-regulation strategies to verify their beliefs about the self and the world (Kunda, 1990; Tamir, 2016). Given that people with high depression levels have negative views of the self and the world, it could be that the exposure to positive stimuli in the training task, contradicted their views of the self and the world. Consequently, they rated fewer positive words as self-relevant, in order to be consistent with (and restore) their self-views. In line with this hypothesis, it was found that people with depression have been found to be driven by self-verification motives, which make them more motivated to feel sadness (Millgram et al., 2015), use suboptimal emotion regulation strategies such as dampening to downregulate positive emotions (Bean et al., 2022; Vanderlind et al., 2020) and use strategies to upregulate happiness less frequently (Arens & Stangier, 2020; Millgram et al., 2019). Thus, it is possible that for participants with high levels of depression, processing positive content activated self-verification motives and down-regulation strategies of positive emotion, that resulted in active avoidance of the positive content in the SRET.
Another way to understand the paradoxical memory effect may concern depressed people’s pattern of response to positive situations. Rumination, a common response in depression, which is associated with faster disengagement from positive content (Yaroslavsky et al., 2019) may be a possible mechanism for the incongruent effects of exposure to positive content. Rumination increases cognitive load, limits cognitive resources, and impacts the ability to benefit from training and change cognitive biases (Haeffel et al., 2012; Wei & Zhou, 2020; Yap et al., 2021). Therefore, it is possible that people with elevated depression levels were distracted by rumination and as a result were less likely to endorse positive words as self-descriptive and to process the positive words thoroughly. Moreover, theoretical models of rumination propose that focusing on discrepancies between actual and ideal states underlies rumination (Martin & Tesser, 1996). Accordingly, intense exposure to positive stimuli, likely draws attention to the discrepancy between an individual’s current depressive state and possible alternative positive states. Adding to this dynamic, the excessive exposure inherent in numerous CBM training trials could intensify this discrepancy and increase cognitive load, making the task even more challenging for individuals with high levels of depression. Thus, instead of prompting positive memories, the exposure to positive stimuli may prompt a ruminative response among participants with higher depression levels. In light of the potential role of rumination in our findings, we conducted a post-hoc analysis examining the relationship the brooding subscale of the Ruminative Responses Scale (RRS; Nolen-Hoeksema & Morrow, 1991) and depression, self-referential processing and recall (positive and negative). Although this rumination scale was assessed in the study, it was not a primary focus of the current research, and therefore we did not report it in the main analysis. This analysis revealed a strong positive correlation with depression (r = 0.53, p < 0.001) and with negative self-referential processing (r = 0.55, p < 0.001) and recall (r = 0.38, p < 0.001), and a strong negative link with positive self-referential processing (r = − 0.45, p < 0.001) and recall (r = − 0.29, p = 0.001). These findings imply that the effects observed in the training and transfer tasks may be influenced by underlying rumination tendencies. While this result provides preliminary support for the hypothesis that rumination could be driving some of the effects associated with depression, further research using validated rumination measures is needed to explore this relationship more systematically.
The absence of beneficial transfer to self-referent processing in participants with negligible depression symptoms complicates the interpretation of training effectiveness and underscore the need for a more nuanced understanding of how cognitive training tasks interact with underlying depressive processes. CBM research has highlighted that while these interventions can modify biases in non-self-referent contexts, translating these changes to self-referent processing is complex and may not always yield positive outcomes (MacLeod & Clarke, 2015; Mogoaşe et al., 2014). Our findings contribute to this body of research by suggesting that the cognitive processes involved in self-referent processing may not benefit uniformly from such training. This complexity highlights the importance of considering individual differences in cognitive biases, as these may influence the effectiveness of interventions. Indeed, studies have emphasized the potential for personalized interventions to enhance the effectiveness of such training (e.g., Hoorelbeke & Koster, 2017).
The results show that contrary to our prediction, the training did not affect mood. Several other studies were unable to show direct effect of processing positive content on mood (e.g., Vrijsen et al., 2019; Woolridge et al., 2021). One possible explanation is that increased processing of positive content might heighten the value individuals place on happiness. Paradoxically, this heightened value can create discrepancies between their desired and actual emotional states, potentially leading to no improvement or even a decrease in positive mood (Troy & Mauss, 2011). Alternatively, it could be that the nature of our task—repetitive, non-self-referential, and perhaps monotonous—did not provide sufficient engagement or emotional evocation to influence mood.
Future research should consider people’s value of happiness and their evaluation of their ability to reach happiness as determinants of the effects of cognitive training on mood. Moreover, exploring whether more engaging or self-referent tasks might yield different mood-related outcomes could be a valuable direction for further studies. Nonetheless, the insignificant results emphasize that the effects reported in this study are not due to momentary change in mood.
We note several limitations. First, our power analysis did not account for depression as a moderating factor, and our recruitment strategy did not specifically target individuals with high levels of depression, possibly affecting our ability to detect interaction effects involving depression. It is important to replicate these findings with a clinical sample. Moreover, while a few studies have shown the efficacy of the NAP as a training task (Daches & Mor, 2014; Daches et al., 2015, 2019), we were unable to directly examine the change in bias as a result of the training, as our focus was on examining the training's effects on memory. Ideally, pre- and post-assessments of bias with equal positive and neutral targets would have been included, but this was omitted to avoid interfering with memory effects. Our training also focused on associating color with valence, rather than directly training visual attention to positive stimuli, which might limit insights into specific cognitive processes in depression. Nonetheless, associating positive content with color aligns with our training goals. Also, although the task consisted of 14% training-incongruent trials to control for response bias, we cannot say for certain that we fully controlled for response bias. Other limitations include the use of neutral nouns in addition to neutral adjectives in the SRET, which could influence peoples’ relatability to the neutral words, and the potential lack of cross-cultural generalizability (due to the specific cultural context of our sample). Additionally, the online data collection may have resulted in lowered data quality compared to that obtained in a controlled laboratory setting. Thus, future replication in diverse cultural contexts and in more controlled environments, is advised. Our findings emphasize the importance of studying what happens following biased processing of external stimuli, and future research should further explore additional effects such as interpretation and assigned value of new content.
Conclusions
The current study provides an initial examination on the effect of training to process positive content on memory for new information. Moreover, it sheds light on the ineffectiveness of the training among depressed participants. The results of the study did not show that training participants to process positive stimuli results in an overall increased recall for new positive content. However, training individuals with high levels of depression to process positive stimuli has a paradoxical effect and it impaired their self-referential ratings and recall of new positive content. These findings may point to the importance of investigating training biases to positive content in the context of depression, as repeated processing of positive content without specific instruction or context, may be unhelpful and increase cognitive biases.
Availability of Data and Materials
Data for this study can be downloaded from the Open Science Framework https://doi.org/10.17605/OSF.IO/TQY47. None of the studies from which the data used in this article was derived were preregistered.
Notes
Outlier cutoff was based on interquartile range (IQR) method, which defines outliers as any data which lies beyond 2.7σ from the mean. According to this method the lower bound for outliers is: Q1—1.5 * IQR (Q3-Q1) and the upper bound is: Q3 + 1.5 * IQR.
The differences in mean age (t(75) = -0.46, p = .64) or gender (χ2(1) = .32, p = .57) were non-significant between groups.
Depression scores were assessed in the pilot study, and there were no significant effects of depression scores on performance in the assessment task. The analyses are reported in the supplementary materials.
We present the actual accuracy rates, rather than the log-transformed rates, to enhance the clarity of data.
The positive items used were Hebrew translations of cheerful, happy and enthusiastic, and the negative items were translations of sad, blue and downhearted.
One of the positive items had lower factor loadings than the others (0.39). Nonetheless, we decided to include it because the factor explained a substantial proportion of the variance (70.83%) and had high internal consistency (α = .91). This allowed us to use a balanced measure that consists of 3 positive and 3 negative items.
Omitting this question in population-based surveys has only a minor effect on the assessment of depression because thoughts of self-harm are uncommon in the general population (Kroenke et al. 2010).
References
Abend, R., Karni, A., Sadeh, A., Fox, N. A., Pine, D. S., & Bar-Haim, Y. (2013). Learning to attend to threat accelerates and enhances memory consolidation. PLoS ONE, 8(4), e62501. https://doi.org/10.1371/journal.pone.0062501
Abend, R., Pine, D. S., Fox, N. A., & Bar-Haim, Y. (2014). Learning and memory consolidation processes of attention-bias modification in anxious and nonanxious individuals. Clinical Psychological Science, 2(5), 620–627. https://doi.org/10.1177/2167702614526571
Anderson, N. H. (1968). Likableness ratings of 555 personality-trait words. Journal of Personality and Social Psychology, 9(3), 272. https://doi.org/10.1037/h0025907
Arens, E. A., & Stangier, U. (2020). Sad as a matter of evidence: The desire for self-verification motivates the pursuit of sadness in clinical depression. Frontiers in Psychology, 11(February), 1–8. https://doi.org/10.3389/fpsyg.2020.00238
Auerbach, R. P., Stanton, C. H., Proudfit, G. H., & Pizzagalli, D. A. (2015). Self-referential processing in depressed adolescents: A high-density event-related potential study. Journal of Abnormal Psychology, 124(2), 233. https://doi.org/10.1037/abn0000023
Baert, S., De Raedt, R., Schacht, R., & Koster, E. H. W. (2010). Attentional bias training in depression: Therapeutic effects depend on depression severity. Journal of Behavior Therapy and Experimental Psychiatry, 41(3), 265–274. https://doi.org/10.1016/j.jbtep.2010.02.004
Bauer, D. J., & Curran, P. J. (2005). Probing interactions in fixed and multilevel regression: Inferential and graphical techniques. Multivariate Behavioral Research, 40(3), 373–400. https://doi.org/10.1207/s15327906mbr4003_5
Bean, C. A. L., Summers, C. B., & Ciesla, J. A. (2022). Dampening of positive affect and depression: A meta-analysis of cross-sectional and longitudinal relationships. Behaviour Research and Therapy, 156, 104153. https://doi.org/10.1016/j.brat.2022.104153
Beard, C., Sawyer, A. T., & Hofmann, S. G. (2012). Efficacy of attention bias modification using threat and appetitive stimuli: A meta-analytic review. Behavior Therapy, 43(4), 724–740. https://doi.org/10.1016/j.beth.2012.01.002
Beck, A. T. (1976). Cognitive theory and the emotional disorders. International Universities Press.
Beck, A. T., & Bredemeier, K. (2016). A unified model of depression: Integrating clinical, cognitive, biological, and evolutionary perspectives. Clinical Psychological Science, 4(4), 596–619. https://doi.org/10.1177/2167702616628523
Beevers, C. G., Clasen, P. C., Enock, P. M., & Schnyer, D. M. (2015). Attention bias modification for major depressive disorder: Effects on attention bias, resting state connectivity, and symptom change. Journal of Abnormal Psychology, 124(3), 463. https://doi.org/10.1037/abn0000049
Bentley, S. V., Greenaway, K. H., & Haslam, S. A. (2017). An online paradigm for exploring the selfreference effect. PLoS ONE, 12(5), 1–21. https://doi.org/10.1371/journal.pone.0176611
Berger, A., & Kiefer, M. (2021). Comparison of different response time outlier exclusion methods: A simulation study. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2021.675558
Blaut, A., Paulewicz, B., Szastok, M., Prochwicz, K., & Koster, E. (2013). Are attentional bias and memory bias for negative words causally related? Journal of Behavior Therapy and Experimental Psychiatry, 44(3), 293–299. https://doi.org/10.1016/j.jbtep.2013.01.002
Borsboom, D. (2017). A network theory of mental disorders. World Psychiatry, 16(1), 5–13. https://doi.org/10.1002/wps.20375
Brzozowski, A., & Philip Crossey, B. (2024). Maladaptive emotion regulation strategies mediate the relationship between biased cognitions and depression. Journal of Behavioral and Cognitive Therapy. https://doi.org/10.1016/j.jbct.2024.100485
Chun, M. M., & Turk-Browne, N. B. (2007). Interactions between attention and memory. Current Opinion in Neurobiology, 17(2), 177–184. https://doi.org/10.1016/j.conb.2007.03.005
Clarke, P. J. F., Branson, S., Chen, N. T. M., Van Bockstaele, B., Salemink, E., MacLeod, C., & Notebaert, L. (2017). Attention bias modification training under working memory load increases the magnitude of change in attentional bias. Journal of Behavior Therapy and Experimental Psychiatry, 57, 25–31. https://doi.org/10.1016/j.jbtep.2017.02.003
Cristea, I. A., Kok, R. N., & Cuijpers, P. (2015). Efficacy of cognitive bias modification interventions in anxiety and depression: Meta-analysis. The British Journal of Psychiatry, 206(1), 7–16. https://doi.org/10.1192/bjp.bp.114.146761
Daches, S., & Mor, N. (2014). Training ruminators to inhibit negative information: A preliminary report. Cognitive Therapy and Research, 38(2), 160–171. https://doi.org/10.1007/s10608-013-9585-5
Daches, S., Mor, N., & Hertel, P. (2015). Rumination: Cognitive consequences of training to inhibit the negative. Journal of Behavior Therapy and Experimental Psychiatry, 49, 76–83. https://doi.org/10.1016/j.jbtep.2015.01.010
Daches, S., Mor, N., & Hertel, P. (2019). Training to inhibit negative content affects memory and rumination. Cognitive Therapy and Research, 43(6), 1018–1027. https://doi.org/10.1007/s10608-019-10023-0
Dai, Q., Rahman, S., Lau, B., Kim, H. S., & Deldin, P. (2015). The influence of self-relevant materials on working memory in dysphoric undergraduates. Psychiatry Research, 229(3), 858–866. https://doi.org/10.1016/j.psychres.2015.07.068
Dainer-Best, J., Lee, H. Y., Shumake, J. D., Yeager, D. S., & Beevers, C. G. (2018a). Determining optimal parameters of the self-referent encoding task: A large-scale examination of self-referent cognition and depression. Psychological Assessment, 30(11), 1527–1540. https://doi.org/10.1037/pas0000602
Dainer-Best, J., Shumake, J. D., & Beevers, C. G. (2018b). Positive imagery training increases positive self-referent cognition in depression. Behaviour Research and Therapy, 111, 72–83. https://doi.org/10.1016/j.brat.2018.09.010
Dainer-Best, J., Trujillo, L. T., Schnyer, D. M., & Beevers, C. G. (2017). Sustained engagement of attention is associated with increased negative self-referent processing in major depressive disorder. Biological Psychology, 129, 231–241. https://doi.org/10.1016/j.biopsycho.2017.09.005
Disner, S. G., Shumake, J. D., & Beevers, C. G. (2017). Self-referential schemas and attentional bias predict severity and naturalistic course of depression symptoms. Cognition and Emotion, 31(4), 632–644. https://doi.org/10.1080/02699931.2016.1146123
Dozois, D. J. A. (2007). Stability of negative self-structures: A longitudinal comparison of depressed, remitted, and nonpsychiatric controls. Journal of Clinical Psychology, 63(4), 319–338. https://doi.org/10.1002/jclp.20349
Durbin, K. A., Mitchell, K. J., & Johnson, M. K. (2017). Source memory that encoding was self-referential: The influence of stimulus characteristics. Memory, 25(9), 1191–1200. https://doi.org/10.1080/09658211.2017.1282517
Ellis, A. J., Beevers, C. G., & Wells, T. T. (2011). Attention allocation and incidental recognition of emotional information in dysphoria. Cognitive Therapy and Research, 35(5), 425–433. https://doi.org/10.1007/s10608-010-9305-3
Ellis, A. J., Wells, T. T., Vanderlind, W. M., & Beevers, C. G. (2014). The role of controlled attention on recall in major depression. Cognition and Emotion, 28(3), 520–529. https://doi.org/10.1080/02699931.2013.832153
Epp, A. M., Dobson, K. S., Dozois, D. J. A., & Frewen, P. A. (2012). A systematic meta-analysis of the Stroop task in depression. Clinical Psychology Review, 32(4), 316–328. https://doi.org/10.1016/j.cpr.2012.02.005
Ettman, C. K., Abdalla, S. M., Cohen, G. H., Sampson, L., Vivier, P. M., & Galea, S. (2020). Prevalence of depression symptoms in US adults before and during the COVID-19 pandemic. JAMA Network Open, 3(9), e2019686–e2019686. https://doi.org/10.1001/jamanetworkopen.2020.19686
Everaert, J., Bernstein, A., Joormann, J., & Koster, E. H. W. (2020). Mapping dynamic interactions among cognitive biases in depression. Emotion Review, 12(2), 93–110. https://doi.org/10.1177/1754073919892069
Everaert, J., Bronstein, M. V., Cannon, T. D., & Joormann, J. (2018). Looking through tinted glasses: Depression and social anxiety are related to both interpretation biases and inflexible negative interpretations. Clinical Psychological Science, 6(4), 517–528. https://doi.org/10.1177/2167702617747968
Everaert, J., Duyck, W., & Koster, E. H. W. (2014). Attention, interpretation, and memory biases in subclinical depression: A proof-of-principle test of the combined cognitive biases hypothesis. Emotion, 14(2), 331–340. https://doi.org/10.1037/a0035250
Everaert, J., & Koster, E. H. W. (2020). The interplay among attention, interpretation, and memory biases in depression: Revisiting the combined cognitive biases hypothesis. Paper Knowledge. toward a Media History of Documents. https://doi.org/10.1016/B978-0-12-816660-4.00009-X
Everaert, J., Vrijsen, J., & N., Martin-Willet, R., van de Kraats, L., & Joormann Jutta. (2022). A meta-analytic review of the relationship between explicit memory bias and depression: depression features an explicit memory bias that persists beyond a depressive episode. Psychological Bulletin, 148, 435–463. https://doi.org/10.1037/bul0000367435
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Fernandez, A., Quigley, L., Dobson, K., & Sears, C. (2022). Coherence of attention and memory biases in currently and previously depressed women. Cognition and Emotion, 36(7), 1239–1254. https://doi.org/10.1080/02699931.2022.2099348
Ferrari, G., Becker, E., Smit, F., Rinck, M., & Spijker, J. (2016). Investigating the (cost-) effectiveness of attention bias modification (ABM) for outpatients with major depressive disorder (MDD): A randomized controlled trial protocol. BMC Psychiatry, 16(1), 1–15. https://doi.org/10.1186/s12888-016-1085-1
Field, A. (2009). Discovering statistics using SPSS (3rd ed.). SAGE Publications.
Fodor, L. A., Georgescu, R., Cuijpers, P., Szamoskozi, Ş, David, D., Furukawa, T. A., & Cristea, I. A. (2020). Efficacy of cognitive bias modification interventions in anxiety and depressive disorders: A systematic review and network meta-analysis. The Lancet Psychiatry, 7(6), 506–514. https://doi.org/10.1016/S2215-0366(20)30130-9
Frost, R., & Plaut, D. (2005). The word-frequency database for printed Hebrew. https://word-freq.huji.ac.il/index.html. Retrieved October 15, 2019.
Gable, P., & Harmon-Jones, E. (2010). The motivational dimensional model of affect: Implications for breadth of attention, memory, and cognitive categorisation. Cognition and Emotion, 24(2), 322–337. https://doi.org/10.1080/02699930903378305
Gaddy, M. A., & Ingram, R. E. (2014). A meta-analytic review of mood-congruent implicit memory in depressed mood. Clinical Psychology Review, 34(5), 402–416. https://doi.org/10.1016/j.cpr.2014.06.001
Gallagher, M. R., Collins, A. C., & Winer, E. S. (2023a). A network analytic investigation of avoidance, dampening, and devaluation of positivity. Journal of Behavior Therapy and Experimental Psychiatry. https://doi.org/10.1016/j.jbtep.2023.101870
Gallagher, M. R., Salem, T., & Winer, E. S. (2023b). When hope springs a leak: Aversion to positivity as a key to understanding depressed persons. Current Psychology. https://doi.org/10.1007/s12144-023-04917-2
Gao, C., Wedell, D. H., & Shinkareva, S. V. (2022). Crossmodal negativity bias in semantic processing. Emotion, 22(6), 1270. https://doi.org/10.1037/emo0000918
Gollan, J. K., Hoxha, D., Hunnicutt-Ferguson, K., Norris, C. J., Rosebrock, L., Sankin, L., & Cacioppo, J. (2016). Twice the negativity bias and half the positivity offset: Evaluative responses to emotional information in depression. Journal of Behavior Therapy and Experimental Psychiatry, 52, 166–170. https://doi.org/10.1016/j.jbtep.2015.09.005
Gotlib, I. H., & Joormann, J. (2010). Cognition and depression: Current status and future directions. Annual Review of Clinical Psychology, 6, 285.
Gotlib, I. H., Kasch, K. L., Traill, S., Joormann, J., Arnow, B. A., & Johnson, S. L. (2004). Coherence and specificity of information-processing biases in depression and social phobia. Journal of Abnormal Psychology, 113(3), 386. https://doi.org/10.1037/0021-843X.113.3.386
Grafton, B., Ang, C., & MacLeod, C. (2012). Always look on the bright side of life: The attentional basis of positive affectivity. European Journal of Personality, 26(2), 133–144. https://doi.org/10.1002/per.1842
Grafton, B., Mackintosh, B., Vujic, T., & MacLeod, C. (2014). When ignorance is bliss: Explicit instruction and the efficacy of CBM-A for anxiety. Cognitive Therapy and Research, 38, 172–188. https://doi.org/10.1007/s10608-013-9579-3
Haeffel, G. J., Rozek, D. C., Hames, J. L., & Technow, J. (2012). Too much of a good thing: Testing the efficacy of a cognitive bias modification task for cognitively vulnerable individuals. Cognitive Therapy and Research, 36, 493–501. https://doi.org/10.1007/s10608-011-9379-6
Hallion, L. S., & Ruscio, A. M. (2011). A meta-analysis of the effect of cognitive bias modification on anxiety and depression. Psychological Bulletin, 137(6), 940–958. https://doi.org/10.1037/a0024355
Hankin, B. L. (2012). Future directions in vulnerability to depression among youth: Integrating risk factors and processes across multiple levels of analysis. Journal of Clinical Child & Adolescent Psychology, 41(5), 695–718. https://doi.org/10.1080/15374416.2012.711708
Hards, E., Ellis, J., Fisk, J., & Reynolds, S. (2020). Negative view of the self and symptoms of depression in adolescents. Journal of Affective Disorders, 262, 143–148. https://doi.org/10.1016/j.jad.2019.11.012
Hart, W., & Gable, P. A. (2013). Motivating goal pursuit: The role of affect motivational intensity and activated goals. Journal of Experimental Social Psychology, 49(5), 922–926. https://doi.org/10.1016/j.jesp.2013.05.002
Hayden, E. P., Olino, T. M., Mackrell, S. V. M., Jordan, P. L., Desjardins, J., & Katsiroumbas, P. (2013). Cognitive vulnerability to depression during middle childhood: Stability and associations with maternal affective styles and parental depression. Personality and Individual Differences, 55(8), 892–897. https://doi.org/10.1016/j.paid.2013.07.016
Hayes, A. F. (2013). Mediation, moderation, and conditional process analysis. Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach, 1, 20.
Hedlund, S., & Rude, S. S. (1995). Evidence of latent depressive schemas in formerly depressed individuals. Journal of Abnormal Psychology, 104(3), 517. https://doi.org/10.1037/0021-843X.104.3.517
Henricks, L. A., Lange, W.-G., Luijten, M., van den Berg, Y. H. M., Stoltz, S. E. M. J., Cillessen, A. H. N., & Becker, E. S. (2022). The longitudinal interplay between attention bias and interpretation bias in social anxiety in adolescents. Cognitive Therapy and Research, 46(5), 940–955. https://doi.org/10.1007/s10608-022-10304-1
Hertel, P. T., & Mathews, A. (2011). Cognitive bias modification: Past perspectives, current findings, and future applications. Perspectives on Psychological Science, 6(6), 521–536. https://doi.org/10.1177/174569161142120
Hirsch, C. R., Clark, D. M., & Mathews, A. (2006). Imagery and interpretations in social phobia: Support for the combined cognitive biases hypothesis. Behavior Therapy, 37(3), 223–236. https://doi.org/10.1016/j.beth.2006.02.001
Hoorelbeke, K., & Koster, E. H. W. (2017). Internet-delivered cognitive control training as a preventive intervention for remitted depressed patients: Evidence from a double-blind randomized controlled trial study. Journal of Consulting and Clinical Psychology, 85(2), 135. https://doi.org/10.1037/ccp0000128
Iacoviello, B. M., Wu, G., Alvarez, E., Huryk, K., Collins, K. A., Murrough, J. W., Iosifescu, D. V., & Charney, D. S. (2014). Cognitive-emotional training as an intervention for major depressive disorder. Depression and Anxiety, 31(8), 699–706. https://doi.org/10.1002/da.22266
Imbriano, G., Waszczuk, M., Rajaram, S., Ruggero, C., Miao, J., Clouston, S., Luft, B., Kotov, R., & Mohanty, A. (2022). Association of attention and memory biases for negative stimuli with post-traumatic stress disorder symptoms. Journal of Anxiety Disorders. https://doi.org/10.1016/j.janxdis.2021.102509
Ingram, R. E. (1984). Toward an information-processing analysis of depression. Cognitive Therapy and Research, 8(5), 443–477. https://doi.org/10.1007/BF01173284
Ji, J. L., Grafton, B., & MacLeod, C. (2017). Referential focus moderates depression-linked attentional avoidance of positive information. Behaviour Research and Therapy, 93, 47–54. https://doi.org/10.1016/j.brat.2017.03.004
Johnson, P. O., & Neyman, J. (1936). Tests of certain linear hypotheses and their application to some educational problems. Statistical Research Memoirs, 1, 57–93.
Jones, E. B., & Sharpe, L. (2017). Cognitive bias modification: A review of meta-analyses. Journal of Affective Disorders, 223, 175–183. https://doi.org/10.1016/j.jad.2017.07.034
Joormann, J. (2006). Differential effects of rumination and dysphoria on the inhibition of irrelevant emotional material: Evidence from a negative priming task. Cognitive Therapy and Research, 30(2), 149–160. https://doi.org/10.1007/s10608-006-9035-8
Joormann, J., & Quinn, M. E. (2014). Cognitive processes and emotion regulation in depression. Depression and Anxiety, 31(4), 308–315. https://doi.org/10.1002/da.22264
Joormann, J., & Siemer, M. (2004). Memory accessibility, mood regulation, and dysphoria: Difficulties in repairing sad mood with happy memories? Journal of Abnormal Psychology, 113(2), 179–188. https://doi.org/10.1037/0021-843X.113.2.179
Kalenzaga, S., & Jouhaud, V. (2018). The self-reference effect in memory: An implicit way to assess affective self-representations in social anxiety. Memory, 26(7), 894–903. https://doi.org/10.1080/09658211.2018.1430833
Kircanski, K., Mazur, H., & Gotlib, I. H. (2013). Behavioral activation system moderates self-referent processing following recovery from depression. Psychological Medicine, 43(9), 1909–1919. https://doi.org/10.1017/S0033291712002851
Koster, E. H. W., De Raedt, R., Leyman, L., & De Lissnyder, E. (2010). Mood-congruent attention and memory bias in dysphoria: Exploring the coherence among information-processing biases. Behaviour Research and Therapy, 48(3), 219–225. https://doi.org/10.1016/j.brat.2009.11.004
Kroenke, K., & Spitzer, R. L. (2002). The PHQ-9: A new depression diagnostic and severity measure. Psychiatric Annals, 32(9), 509–515. https://doi.org/10.3928/0048-5713-20020901-06
Kuiper, N. A., & Derry, P. A. (1982). Depressed and nondepressed content self-reference in mild depressives. Journal of Personality, 50(1), 67–80. https://doi.org/10.1111/j.1467-6494.1982.tb00746.x
Kunda, Z. (1990). The case for motivated reasoning. Psychological Bulletin, 108(3), 480. https://doi.org/10.1037/0033-2909.108.3.480
Laurikkala, J., Juhola, M., Kentala, E., Lavrac, N., Miksch, S., & Kavsek, B. (2000). Informal identification of outliers in medical data. Fifth International Workshop on Intelligent Data Analysis in Medicine and Pharmacology, 1, 20–24.
LeMoult, J., Colich, N., Joormann, J., Singh, M. K., Eggleston, C., & Gotlib, I. H. (2018). Interpretation bias training in depressed adolescents: Near- and far-transfer effects. Journal of Abnormal Child Psychology, 46(1), 159–167. https://doi.org/10.1007/s10802-017-0285-6
LeMoult, J., & Gotlib, I. H. (2019). Depression: A cognitive perspective. Clinical Psychology Review, 69, 51–66. https://doi.org/10.1016/j.cpr.2018.06.008
LeMoult, J., Kircanski, K., Prasad, G., & Gotlib, I. H. (2017). Negative self-referential processing predicts the recurrence of major depressive episodes. Clinical Psychological Science, 5(1), 174–181. https://doi.org/10.1177/2167702616654898
LeMoult, J., Yoon, K. L., & Joormann, J. (2016). Rumination and cognitive distraction in major depressive disorder: An examination of respiratory sinus arrhythmia. Journal of Psychopathology and Behavioral Assessment, 38(1), 20–29. https://doi.org/10.1007/s10862-015-9510-1
Leung, C. J., Yiend, J., Trotta, A., & Lee, T. M. C. (2022). The combined cognitive bias hypothesis in anxiety: A systematic review and meta-analysis. In Journal of anxiety disorders (Vol. 89). Elsevier. https://doi.org/10.1016/j.janxdis.2022.102575
Levis, B., Benedetti, A., & Thombs, B. D. (2019). Accuracy of Patient Health Questionnaire-9 (PHQ-9) for screening to detect major depression: Individual participant data meta-analysis. BMJ. https://doi.org/10.1136/bmj.l1476
Liu, Y., & Wang, Z. (2014). Positive affect and cognitive control: Approach-motivation intensity influences the balance between cognitive flexibility and stability. Psychological Science, 25(5), 1116–1123. https://doi.org/10.1177/0956797614525213
MacLeod, C., & Clarke, P. J. F. (2015). The attentional bias modification approach to anxiety intervention. Clinical Psychological Science, 3(1), 58–78. https://doi.org/10.1177/2167702614560749
MacLeod, C., & Mathews, A. (2012). Cognitive bias modification approaches to anxiety. Annual Review of Clinical Psychology, 8, 189–217. https://doi.org/10.1146/annurev-clinpsy-032511-143052
MacLeod, C., Rutherford, E., Campbell, L., Ebsworthy, G., & Holker, L. (2002). Selective attention and emotional vulnerability: Assessing the causal basis of their association through the experimental manipulation of attentional bias. Journal of Abnormal Psychology, 111(1), 107–123. https://doi.org/10.1037/0021-843X.111.1.107
Martin, L. L., & Tesser, A. (1996). Some ruminative thoughts. In Wyer R.S. Jr. (Ed.), Ruminative thoughts (9th ed.). Erlbaum.
Millgram, Y., Joormann, J., Huppert, J. D., Lampert, A., & Tamir, M. (2019). Motivations to experience happiness or sadness in depression: Temporal stability and implications for coping with stress. Clinical Psychological Science, 7(1), 143–161. https://doi.org/10.1177/2167702618797937
Millgram, Y., Joormann, J., Huppert, J. D., & Tamir, M. (2015). Sad as a matter of choice? Emotion-Regulation Goals in Depression. Psychological Science, 26(8), 1216–1228. https://doi.org/10.1177/0956797615583295
Möbius, M., Ferrari, G., van den Bergh, R., Becker, E., & Rinck, M. (2018). Eye-tracking based attention bias modification (ET-ABM) facilitates disengagement from negative stimuli in dysphoric individuals. Cognitive Therapy and Research, 42(4), 408–420. https://doi.org/10.1007/s10608-018-9889-6
Mogoaşe, C., David, D., & Koster, E. H. W. (2014). Clinical efficacy of attentional bias modification procedures: An updated meta-analysis. Journal of Clinical Psychology, 70(12), 1133–1157. https://doi.org/10.1002/jclp.22081
Nieto, I., & Vazquez, C. (2021). Disentangling the mediating role of modifying interpretation bias on emotional distress using a novel cognitive bias modification program. Journal of Anxiety Disorders. https://doi.org/10.1016/j.janxdis.2021.102459
Nolen-Hoeksema, S., & Morrow, J. (1991). A prospective study of depression and posttraumatic stress symptoms after a natural disaster: The 1989 Loma Prieta Earthquake. Journal of Personality and Social Psychology, 61(1), 115. https://doi.org/10.1037/0022-3514.61.1.115
Patil, V. H., Singh, S. N., Mishra, S., & Donavan, D. T. (2017). Parallel analysis engine to aid in determining number of factors to retain using R. https://Analytics.Gonzaga.Edu/Parallelengine.
Pool, E., Brosch, T., Delplanque, S., & Sander, D. (2016). Attentional bias for positive emotional stimuli: A meta-analytic investigation. Psychological Bulletin, 142(1), 79–106. https://doi.org/10.1037/bul0000026
Price, R. B., Kuckertz, J. M., Amir, N., Bar-Haim, Y., Carlbring, P., & Wallace, M. L. (2017). Less is more: Patient-level meta-analysis reveals paradoxical dose-response effects of a computer-based social anxiety intervention targeting attentional bias. In Depression and anxiety (Vol. 34, Issue 12, pp. 1106–1115). Blackwell Publishing Inc. https://doi.org/10.1002/da.22634
Qu, C., Sas, C., & Doherty, G. (2019). Exploring and designing for memory impairments in depression. Conference on Human Factors in Computing Systems - Proceedings. https://doi.org/10.1145/3290605.3300740
Quigley, L., Thiruchselvam, T., & Quilty, L. C. (2022). Cognitive control biases in depression: A systematic review and meta-analysis. Psychological Bulletin, 148(9–10), 662–709. https://doi.org/10.1037/bul0000372
Ramel, W., Goldin, P. R., Eyler, L. T., Brown, G. G., Gotlib, I. H., & McQuaid, J. R. (2007). Amygdala reactivity and mood-congruent memory in individuals at risk for depressive relapse. Biological Psychiatry, 61(2), 231–239. https://doi.org/10.1016/j.biopsych.2006.05.004
Ratcliff, R. (1993). Methods for dealing with reaction time outliers. Psychological Bulletin, 114(3), 510. https://doi.org/10.1037/0033-2909.114.3.510
Ronold, E. H., Joormann, J., & Hammar, Å. (2022). Computerized working memory training in remission from major depressive disorder: Effects on emotional working memory, processing speed, executive functions, and associations with symptoms. Frontiers in Behavioral Neuroscience. https://doi.org/10.3389/fnbeh.2022.887596
Rozenman, M., Amir, N., & Weersing, V. R. (2014). Performance-based interpretation bias in clinically anxious youths: Relationships with attention, anxiety, and negative cognition. Behavior Therapy, 45(5), 594–605. https://doi.org/10.1016/j.beth.2014.03.009
Sanchez-Lopez, A., De Raedt, R., van Put, J., & Koster, E. H. W. (2019). A novel process-based approach to improve resilience: Effects of computerized mouse-based (gaze)contingent attention training (MCAT)on reappraisal and rumination. Behaviour Research and Therapy, 118(April), 110–120. https://doi.org/10.1016/j.brat.2019.04.005
Smith, H. L., McDermott, K. A., Carlton, C. N., & Cougle, J. E. (2019). Predictors of Symptom Outcome in Interpretation Bias Modification for Dysphoria. Behavior Therapy, 50, 646–658. https://www.elsevier.com/locate/bt
Smiti, A. (2020). A critical overview of outlier detection methods. In Computer Science Review (Vol. 38). Elsevier Ireland Ltd. https://doi.org/10.1016/j.cosrev.2020.100306
Sorenson, J. E., Furman, D. J., & Gotlib, I. H. (2014). Memory for novel positive information in major depressive disorder. Cognition and Emotion, 28(6), 1090–1099. https://doi.org/10.1080/02699931.2013.866936
Standage, H., Harris, J., & Fox, E. (2014). The influence of social comparison on cognitive bias modification and emotional vulnerability. Emotion, 14(1), 170–179. https://doi.org/10.1037/a0034226
Takano, K., Iijima, Y., Sakamoto, S., Raes, F., & Tanno, Y. (2016). Is self-positive information more appealing than money? Individual differences in positivity bias according to depressive symptoms. Cognition and Emotion, 30(8), 1402–1414. https://doi.org/10.1080/02699931.2015.1068162
Tamir, M. (2016). Why do people regulate their emotions? A taxonomy of motives in emotion regulation. Personality and Social Psychology Review, 20(3), 199–222. https://doi.org/10.1177/1088868315586325
Teasdale, J. D. (1988). Cognitive vulnerability to persistent depression. Cognition & Emotion, 2(3), 247–274. https://doi.org/10.1080/02699938808410927
Troy, A. S., & Mauss, I. B. (2011). Resilience in the face of stress: Emotion regulation as a protective factor. Resilience and Mental Health: Challenges Across the Lifespan. https://doi.org/10.1017/CBO9780511994791.004
Vanderlind, W. M., Millgram, Y., Baskin-Sommers, A. R., Clark, M. S., & Joormann, J. (2020). Understanding positive emotion deficits in depression: From emotion preferences to emotion regulation. Clinical Psychology Review, 76, 101826. https://doi.org/10.1016/j.cpr.2020.101826
Villalobos, D., Pacios, J., & Vázquez, C. (2021). Cognitive Control, Cognitive Biases and Emotion Regulation in Depression: A New Proposal for an Integrative Interplay Model. In Frontiers in psychology (Vol. 12). Frontiers Media S.A. https://doi.org/10.3389/fpsyg.2021.628416
Vrijsen, J. N., Dainer-Best, J., Witcraft, S. M., Papini, S., Hertel, P., Beevers, C. G., Becker, E. S., & Smits, J. A. J. (2019). Effect of cognitive bias modification-memory on depressive symptoms and autobiographical memory bias: Two independent studies in high-ruminating and dysphoric samples. Cognition and Emotion, 33(2), 288–304. https://doi.org/10.1080/02699931.2018.1450225
Wang, X., He, Y., & Feng, Z. (2022). The antidepressant effect of cognitive reappraisal training on individuals cognitively vulnerable to depression: Could cognitive bias be modified through the prefrontal–amygdala circuits? Frontiers in Human Neuroscience. https://doi.org/10.3389/fnhum.2022.919002
Wante, L., Mueller, S. C., Demeyer, I., Naets, T., & Braet, C. (2017). Internal shifting impairments in response to emotional information in dysphoric adolescents. Journal of Behavior Therapy and Experimental Psychiatry, 57, 70–79. https://doi.org/10.1016/j.jbtep.2017.04.002
Warriner, A. B., Kuperman, V., & Brysbaert, M. (2013). Norms of valence, arousal, and dominance for 13,915 English lemmas. Behavior Research Methods, 45(4), 1191–1207. https://doi.org/10.3758/s13428-012-0314-x
Watson, D., & Clark, L. A. (1994). The PANAS-X: Manual for the positive and negative affect schedule-expanded form. https://doi.org/10.17077/48vt-m4t2
Wei, H., & Zhou, R. (2020). High working memory load impairs selective attention: EEG signatures. Psychophysiology, 57(11), e13643. https://doi.org/10.1111/psyp.13643
Weisman, A., Yona, T., Gottlieb, U., & Masharawi, Y. (2022). The reliability and validity of an online version of the Hebrew patient health questionnaire (PHQ-9) in the general population. Israel Journal of Psychiatry and Related Sciences, 59(2), 8-32. https://doi.org/10.1101/2021.07.13.21260485
Wen, A., Fischer, E. R., Watson, D., & Yoon, K. L. (2023). Biased cognitive control of emotional information in remitted depression: A meta-analytic review. Journal of Psychopathology and Clinical Science, 132(8), 921–936. https://doi.org/10.1037/abn0000848
Whelan, R. (2008). Effective analysis of reaction time data. The Psychological Record, 58, 475–482. https://doi.org/10.1007/BF03395630
Winer, E. S., & Salem, T. (2016). Reward devaluation: Dot-probe meta-analytic evidence of avoidance of positive information in depressed persons. Psychological Bulletin, 142(1), 1–61. https://doi.org/10.1037/bul0000022
Woolridge, S. M., Harrison, G. W., Best, M. W., & Bowie, C. R. (2021). Attention bias modification in depression: A randomized trial using a novel, reward-based, eye-tracking approach. Journal of Behavior Therapy and Experimental Psychiatry, 71, 101621. https://doi.org/10.1016/j.jbtep.2020.101621
Yang, W., Ding, Z., Dai, T., Peng, F., & Zhang, J. X. (2015). Attention bias modification training in individuals with depressive symptoms: A randomized controlled trial. Journal of Behavior Therapy and Experimental Psychiatry, 49, 101–111. https://doi.org/10.1016/j.jbtep.2014.08.005
Yap, D., Denefrio, S., & Dennis-Tiwary, T. A. (2021). Low working memory load facilitates attention bias modification training. Behaviour Research and Therapy. https://doi.org/10.1016/j.brat.2021.103828
Yaroslavsky, I., Allard, E. S., & Sanchez-Lopez, A. (2019). Can’t look away: Attention control deficits predict rumination, depression symptoms and depressive affect in daily Life. Journal of Affective Disorders, 245, 1061–1069. https://doi.org/10.1016/j.jad.2018.11.036
Funding
Open access funding provided by Hebrew University of Jerusalem. This work was supported by a grant from the Ariane De Rothschild fellowship awarded to Nour Kardosh and by the Joseph Meyerhoff Chair in Special Education awarded to Nilly Mor.
Author information
Authors and Affiliations
Contributions
Nour Kardosh: conceptualization, methodology, preparation of study materials, conducting pilot work, data collection, formal analysis, visualizations, interpretation, writing—original draft. Nilly Mor: conceptualization, methodology, supervision, interpretation, writing—original draft.
Corresponding author
Ethics declarations
Conflict of Interest
Nour Kardosh and Nilly Mor declare they have no conflict of interest.
Ethical Approval
The study was approved by the research ethics committee of the Hebrew University of Jerusalem (Approval No. 2020Y2810)
Informed Consent
Informed consent was obtained from all individual subjects participating in the study.
Animal Rights Statement
This study did not involve any animal subjects.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kardosh, N., Mor, N. Training to Increase Processing of Positive Content Paradoxically Decreases Positive Memory Bias in High Levels of Depression. Cogn Ther Res (2024). https://doi.org/10.1007/s10608-024-10532-7
Accepted:
Published:
DOI: https://doi.org/10.1007/s10608-024-10532-7