
Abstract
Bivariate extreme value distributions can be used to model dependence of observations from random variables in extreme levels. There is no finite dimensional parametric family for these distributions, but they can be characterized by a certain one-dimensional function which is known as Pickands dependence function. In many applications the general approach is to estimate the dependence function with a non-parametric method and then conduct further analysis based on the estimate. Although this approach is flexible in the sense that it does not impose any special structure on the dependence function, its main drawback is that the estimate is not available in a closed form. This paper provides some theoretical results which can be used to find a closed form approximation for an exact or an estimate of a twice differentiable dependence function and its derivatives. We demonstrate the methodology by calculating approximations for symmetric and asymmetric logistic dependence functions and their second derivatives. We show that the theory can be even applied to approximating a non-parametric estimate of dependence function using a convex optimization algorithm. Other discussed applications include a procedure for testing whether an estimate of dependence function can be assumed to be symmetric and estimation of the concordance measures of a bivariate extreme value distribution. Finally, an Australian annual maximum temperature dataset is used to illustrate how the theory can be used to build semi-infinite and compact predictions regions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A general approach in risk management is first to identify the factors which have a significant effect on the outcome of a process which could impose some kind of risk to a society or a business. In many applications the factors turn out to be dependent so in order to quantify the risks, a model has to be developed next which takes into account the dependence structure. For instance, an insurance company might be interested in assessing the risk of flooding in a residential area and the most influential factors could be for instance wind speed and wave height in a nearby coast.
Bivariate extreme value (BEV) distributions provide a natural framework for modeling extreme levels of two dependent random variables. One of the significant features of the BEV distributions is that they can be characterized by Pickands dependence function, denoted hereafter by \(A(w), w\in [0, 1]\). It can be shown that the function A has to be convex in a triangular area defined by the corner points (0, 1),(1/2, 1/2) and (1, 1) where \(A(0)=A(1)=1\).
Due to the simple properties of A(w), a great amount of research has been carried out to address how it can be estimated based on a sample from the underlying BEV distribution. The parametric approach is fairly straightforward as it requires a proper estimation method (for instance maximum likelihood) to be used to estimate the unknown parameters. As there is no finite dimensional parametric family which contains all possible dependence functions, the drawback of this approach is that one has to choose a certain subfamily of distributions for the analysis. Consequently, the non-parametric approach has attracted lots of attention. Apart from the original estimator by Pickands (1975), major recent references include Capéraà et al. (1997), Hall and Tajvidi (2000), Zhang et al. (2008), Gudendorf and Segers (2011, 2012) and Marcon et al. (2017). All these methods provide an estimate which does not have a closed form but it can be numerically evaluated in the domain of dependence function for \(w\in [0, 1]\). This paper provides a compromise between the parametric and non-parametric approach in the sense that it combines the flexibility of a non-parametric estimator with the advantage of having an analytic expression for an estimate based on parametric approach. It suggests a general methodology which can be used to find a closed form approximation of an exact or an arbitrary estimate of dependence function. In addition, it is shown that even second derivative of A(w) admits a similar expansion. This can be useful in any application which requires a density of a BEV distribution such as construction of prediction regions discussed in Hall and Tajvidi (2004).
A rigorous treatment of mathematical theory for multivariate extremes can be found for instance in de Haan and Resnick (1977) and Pickands (1975, 1989, 1981). For monograph length treatments of this topic we refer to de Haan and Ferreira (2006), Dey and Yun (2016), Embrechts et al. (1997), Joe (1997, Chapter 6) and Resnick (2008), to mention a few.
The paper is organized as follows. In Section 2 we give a brief account of bivariate extreme value theory. The main theoretical results are presented in Section 3. This is followed by some examples of applications in Section 4. The technical details of the theoretical results are presented in the last section.
2 Bivariate extreme value distributions
In this section we present a short summary of the main results for bivariate extreme value distributions which is used in subsequent sections. A rigorous account of the general theory for multivariate extremes can be found in de Haan and Resnick (1977), Beirlant et al. (2004) and Resnick (2008).
Let \(X_{1},X_{2},{\dots },X_{n}\) be a sequence of independent and identically distributed random variables with continuous distribution function F(x). Further, let \(M_{n}=\max (X_{1},X_{2},{\dots },X_{n}),\) \(n \in \mathbb {N}\) and suppose normalizing constants \(a_{n}>0\) and \(b_{n} \in \mathbb {R}\) are such that
where G(x) is non-degenerate. It can be shown that the only possible limit in the above equation is the following distribution
where \(\sigma > 0\), \(\mu\) and \(\gamma \in \mathbb {R}\). This is called the generalised extreme value (GEV) distribution. For thorough treatment of the theory see Leadbetter et al. (1983), de Haan and Ferreira (2006) Resnick (2008) and Beirlant et al. (2004).
The generalization to multivariate case is based on taking component-wise maxima of d-dimensional random vectors. Different characterizations of multivariate extreme value distributions based on different assumptions on distribution of margins can be found in the literature. As this paper concerns only the bivariate extremes, for brevity we will only present the characterization for this case. The following result is due to de Haan and Resnick (1977) and it is based on the assumption that all univariate marginals are unit Fréchet which is the special case of GEV distribution for \(\mu =1, \sigma =1 \text { and }\gamma =1\). Denoting this “standardized” distributions by \(G_*\), it is shown that
where
Measure \(\mathbb {S}\) is called the spectral or angular measure and it has to satisfy
The function A(w) is called dependence function. It is a convex function which is contained in triangular area defined by the corner points \((0, 1), (1/2, 1/2) \text { and } (0, 1)\) such that \(A(0)=A(1)=1\).
3 Theoretical results
Assume that the measure \(\mathbb {S}\) is differentiable in [0, 1] and denote the corresponding spectral density by S. The representation of dependence function A(w) in (2.3) can be seen as the following integral equation:
with
We will refer to K(w, q) as kernel below. According to Polyanin and Manzhirov (1998, page 577), Eq. (3.5) is a non-homogeneous integral equation of the first kind with symmetric kernel given in (3.6). The Picard theorem given below provides the necessary and sufficient conditions for existence of a solution to the above integral equation. The theorem is formulated based on characteristic values and eigenfunctions of the kernel so we define them first; see e.g. Polyanin and Manzhirov (1998) for further details.
The sequences \(\lambda _k,S_k, k=0, 1,2,\dots\) are called characteristic values and eigenfunctions of the kernel respectively if
It is assumed that \(|\lambda _k|\) are in increasing order so \(|\lambda _{k-1}|\le |\lambda _k|\). In addition, the eigenfunctions \(S_k(w)\) are assumed to be normalized and mutually orthogonal in \(L^{2}[0, 1]\). According to Polyanin and Manzhirov (1998, page 640), “the system of eigenfunctions is said to be incomplete if there exists a non-zero square integrable function that is orthogonal to all functions of the system. Otherwise, the system of eigenfunctions is said to be complete.”. A kernel is said to be complete if the corresponding system of eigenfunctions is complete.
As mentioned above the Picard theorem is the main basis for the results in the current paper so for convenience, we restate it below.
Theorem 1
Picard Theorem see Polyanin and Manzhirov (1998, page 578): The integral equation defined in (3.5) and (3.6) has a solution if and only if A(w) can be expanded into a mean-square convergent series with respect to eigenfunctions of the kernel K(w, q):
and the series \(\sum _{k=0}^\infty \lambda _k^2|a_k|^2\) is convergent. In this case the general solution of Eq. (3.5) has the form
where \(S_h(q)\) is an arbitrary solution of the homogeneous Eq. (3.5) for \(A(w) \equiv 0\). If the kernel K(w, q) is complete, then \(S_h(q) \equiv 0\), and Eq. (3.5) has only one solution, namely
To apply this theorem we need to find characteristic values and eigenfunctions of the kernel in (3.6). The following theorem with subsequent propositions are our main results.
Theorem 2
Characteristic values of the kernel defined in (3.6) have to satisfy the condition
For \(\lambda >0\) there is only one characteristic value which will be referred to as \(\lambda _0\) henceforth. It has to be calculated numerically and its approximate value is \(\lambda _{0}=2.38\). For \(\lambda <0\) there is an infinite and countable number of characteristic values given by the following equations:
The corresponding eigenfunctions are
and
where \(c_i\, \, i=0, 1, \dots\) are constants.
Remarks
-
1.
Equation (3.11) can be written as
$$S_k(w)=c_{k} \sqrt{\left| \lambda_k \right|+1}\cos \left(w \sqrt{\left| \lambda_k \right|}+ \arctan\left(\frac{1}{\sqrt{\left| \lambda_k \right|} }\right)\right) , \,\, k=1,2,\dots.$$ -
2.
To make the eigenfunctions orthonormal, the constants \(c_{k}\) have to be calculated by numerical integration.
Proposition 1
The integral equation defined in (3.5) and (3.6) has a solution \(S(w)=A''(w)\). In addition S can be expanded in terms of the eigenfunctions of K(w, q).
Proposition 2
Suppose that the measure \(\mathbb {S}\) defined in (2.3) has point masses \(\mathbb {S}(0) \text { and } \mathbb {S}(1)\) at points 0 and 1, respectively. Further, assume that \(\mathbb {S}\) is differentiable in (0, 1). Then \(A(w)=a+bw+B(w)\) where \(a \text { and } b\) do not depend on w and \(S(w)=B''(w)\) in (0, 1). In addition S can be expanded in terms of the eigenfunctions of K(w, q).
The proofs are provided in Section 5.
4 Applications
The theoretical results from the previous section can be used in different ways. Below we will discuss some applications in detail. The first step is to calculate eigenvalues and normalize eigenfunctions derived in Theorem 2. In the results reported below all calculations have been carried out with precision 20.
The equations which define eigenvalues are given in (5.25) and (5.27). The first equation has only one solution while the second has an infinite but countable number of solutions. Panels (a) and (b) in Fig. 1 show the corresponding equations. We calculated 100 eigenvalues from (5.27) so together with the single solution of (5.25) we will use maximum of 101 eigenvalues in our analysis below. Panel (c) depicts the first 101 eigenvalues of the kernel (3.6).

Panels a and b depict plots of eigenvalue equations according to (5.25) and (5.27). The first 101 eigenvalues are shown in panel c where \(\lambda _{0}\) is obtained from the equation in panel (a) and \(\lambda _{1}, \dots , \lambda _{100}\) are calculated from eigenvalue equation shown in panel (b)
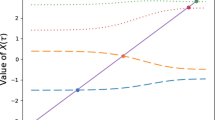
The eigenfunctions derived in Theorem 2 are orthogonal so we just need to find \(c_i, i=0,1,2,\dots\) to make them orthonormal. This has been performed by numerical integration and the following results are based on orthonormal eigenfunctions. In Fig. 2 the first 9 eigenfunctions are plotted. Note that \(S_{i}(q)\) alternate between even and odd functions depending on if their corresponding index i is even or odd, respectively.

4.1 Approximating a dependence function and its derivatives
In this section we will denote an expansion of a dependence function in terms of eigenfunctions \(S_{i}\) by \(A_{\text {e}}\) where the number of eigenfunctions employed in the approximations will be clear from the context. Specifically, let \(M\subsetneq \mathbb {N}_{0}\) be a finite subset of non-negative integers which contains the indices of eigenfunctions we choose to use in the approximation. Then \(A_{\text {e}}(w)=\sum _{k\in M} a_kS_k(w)\) which can be seen as finite sum approximation of the expansion defined in (3.7).
As a first application we present expansion of the logistic dependence function which is defined as
The independent case corresponds to \(r=1\) and for \(r\rightarrow +\infty\) we get the complete dependence. Below we consider the case with parameter \(r=2\).
As mentioned above the eigenfunctions alternate between even and odd functions so, for symmetric dependence functions the theoretical values of the coefficients \(a_{i}\) in (3.7) are exactly zero for odd i. The non-zero coefficients vanish very fast. The first 6 coefficients corresponding to the first 6 even eigenfunctions are 0.81622, 0.02137, 0.00028, 0.00009, 0.00003 and 0.00001 where we have rounded up to 5 decimal points.

Approximations of the symmetric logistic dependence function A(w). The corresponding number of eigenfunctions is shown at the top of each panel. Solid (blue) line is the approximation \(\hat{A_{e}}\) and dashed (red) line is the logistic dependence function for \(r=2\). The bottom right panel shows the \({\ell}\!_{2}\) solid (brown) line and \({\ell}\!_{\infty}\) dashed (brown) line norms of \(( A_{\text {e}}- {A})\) as a function of number of eigenfunctions in the approximations
The first five plots of Fig. 3 show approximations of logistic dependence function for different numbers of eigenfunctions which are shown at the top of each plot. To illustrate the rate of convergence the bottom right panel of Fig. 3 shows the \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms of the difference between A and \(A_{\text {e}}\) in terms of the number of approximating eigenfunctions. The logistic dependence function satisfies the boundary conditions in (5.28) and (5.29) so it is also possible to find an approximation to the second derivative \(A''(w)\) according to the representation in (3.8). The results are shown in Fig. 4. Note that compared with Fig. 3 the convergence rate is slower in this case.

Approximations of the second derivative of the logistic dependence function for \(r=2\). The notation is the same as in Fig. 3
As Proposition 2 suggests, it is also possible to use this methodology with some modifications to calculate series expansion of a dependence function and its second derivative even when it does not satisfy the boundary conditions in (5.28) and (5.29). As an illustration we consider the asymmetric logistic model (Tawn, 1988) with dependence function defined as:
This model reduces to the symmetric logistic model for \(\theta =\phi =1\). Independence is obtained for \(\theta =0\) and for \(\phi =0 \text { or } r=1\).
By evaluating the first partial derivative of (4.13) in \(w=0 \text { and } 1\) we find that
so the boundary conditions (5.28) and (5.29) are not satisfied. This is of course due to the fact that the measure \(\mathbb {S}\) in (2.3) has point masses \(\mathbb {S}(0)=1-\phi \text { and } \mathbb {S}(1)=1-\theta\) so it is not differentiable at these points. However, it can be easily checked that these conditions are satisfied for the first term in the dependence function. Specifically, with the same notation as in Proposition 2, we have
and
This implies that we can find approximations of dependence function A(w) even in this case although the boundary conditions are not satisfied. The only difference is that the coefficients \(a_{i}\) in (3.7) have to be calculated based on B(w) defined in (4.15) instead. These coefficients provide an approximation to B(w) according to (3.7) so by adding the linear term in dependence function we get an expansion of A(w). As a numerical example, below we present the case with parameters \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). Different approximations of A are shown in Fig. 5. Note that the linear term \(0.1+0.7w\) has been added to the approximations of B(w) by eigenfunctions. The bottom right panel in the figure shows the \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms of \(( A_{\text {e}}- {A})\).

Approximations of the asymmetric logistic dependence function A(w). The corresponding number of eigenfunctions is shown on the top of each panel. Solid (blue) line is the approximation \(\hat{A_{e}}\) and dashed (red) line is the asymmetric logistic dependence function for \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). Note the linear term \(0.1+0.7w\) which has been added to the approximations on the top of each panel. The bottom right panel shows the \({\ell}\!_{2}\) solid (brown) line and \({\ell}\!_{\infty}\) dashed( brown) line norms of \((A_{\text {e}}- {A})\) as a function of number of eigenfunctions in the approximation
The coefficients we have calculated above provide approximations to the second derivative of dependence function \(A^{''}\) as well. For comparison, in Fig. 6 we present some approximations of the second derivative of asymmetric logistic dependence function for the same parameter values mentioned above as well. To illustrate the rate of convergence the bottom right panel of Fig. 6 shows the \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms of the difference between \(A^{''}\) and \({A''_{\text {e}}}\).

Approximations of the second derivative of the asymmetric logistic dependence function for \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). The notation is the same as in Fig. 5
For further comparison, Fig. 7 shows the difference between approximations of dependence function and its second derivative for taking all 101 eigenfunctions in the two examples above. The results for symmetric and asymmetric logistic dependence functions are shown in the first and the second row, respectively. Comparing the panels in the left column, we see that the errors in approximations are of the same order but for the asymmetric logistic the large errors occur in the right boundary which is in contrast to the first panel with rather symmetric errors. The same pattern can be seen for the derivatives. This is of course expected due to the shape of the dependence functions and their second derivatives.

The errors in approximations of dependence functions (first column) and its second derivative (second column) for logistic (first row) and asymmetric logistic dependence functions (second row)
We have also evaluated the performance of the method for the whole range of dependence parameter r. Our general conclusion was that the method works fine for the whole range of strength in dependence function, but one has to take more eigenfunctions in the approximations as the dependence approaches independent case. As some specific examples, the left panel of Fig. 8 shows the approximations of symmetric logistic dependence function for \(r=1.1 \text { and } r=4\). The approximation for the same values of r and \(\theta =0.9, \,\, \phi =0.2\) in the asymmetric logistic case are shown in the right panel of the figure.

Approximations of symmetric and asymmetric logistic dependence function. The \(3\times 3\) panel at the top shows the results for symmetric logistic dependence function where the first row is for \(r=1.1\) and the last two rows correspond to the case for \(r=4\). The \(3\times 3\) panel at the bottom shows the corresponding results for asymmetric case with same values of parameter r, \(\theta =0.9 \text { and } \phi =0.2\). The bottom right panels show the \({\ell}\!_{2}\) solid (brown) line and \({\ell}\!_{\infty}\) dashed (brown) line norms of \(( A_{\text {e}}- {A})\) as a function of number of eigenfunctions in the approximations
4.2 Approximating a non-parametric estimate of dependence function
The methodology outlined in the previous section can be applied to an estimate of dependence function as well. If a BEV distribution is estimated completely parametrically, for instance by maximum likelihood method, then finding an expansion for the corresponding dependence function can be achieved by just calculating the corresponding coefficients in (3.7) as shown in the previous section. However, in case of non-parametric estimator we need to ensure that the approximation satisfies all the necessary and sufficient conditions that define a dependence function, including convexity and the restriction that its curve has to lie within a certain triangular region discussed in Section 1. The following estimation method can be used in this context.
Let \(0=w_{0}< \dots < w_{t}=1\) be \(t+1\) points in the interval [0, 1]. Further, suppose \(\hat{A}\) is a non-parametric estimator of the dependence function and let \(M\subsetneq \mathbb {N}_{0}\) be a finite subset of non-negative integers containing the indices of eigenfunctions employed in the approximation as defined in Section 4.1. A valid closed form expansion for \(\hat{A}\) can be obtained by the following constrained optimization:
where \(\Vert \cdot \Vert _{p}\) denotes an arbitrary \({\ell}\!_{p}\) norm for \(p\ge 1\) and \(\{a_{k}:k \in M\}\) is the set of coefficients which are calculated by the optimization routine in (4.16). It should be noted that all constraints are linear in the parameters \(\{a_{k}:a_{k} \in M\}\) and since the \({\ell}\!_p\) norm is convex for all \(p\ge 1\), this is a convex optimization routine and there are many efficient algorithms available for finding optimal values of \(\{a_{k}:k \in M\}\). These values define a finite sum approximation for \(\hat{A}\) in terms of eigenfunctions \(S_{i}\).
We note that many estimation methods suggested in the literature provide a numerical estimate of the dependence function which can be used as an input, \(\hat{A}\), in the optimization routine above. This includes the classical Pickands estimator Pickands (1981), CFG estimator (\(\hat{A}_{\text {cfg}}\)) developed by Capéraà et al. (1997), modified Pickands estimator (\(\hat{A}_{\text {p}}\)), greatest convex minorant of modified Pickands estimator (\(\hat{A}_{\text {gcmp}}\)) and smoothed spline estimator (\(\hat{A}_{\text {s}}\)) discussed in Hall and Tajvidi (2000). The last three estimators will be used in the examples below. Recall that \(A_{\text {e}}\) denotes approximation of a dependence function with any number of eigenfunctions.
To illustrate our method, we will discuss some numerical examples below. In all the calculations presented here we have used Euclidean norm \(p=2\) in the objective function in (4.16). In addition, we have taken the \(w_{i}, i=0, \dots , 1000\) equally spaced on [0, 1]. We simulated 200 random variates from the asymmetric logistic BEV distribution with unit Fréchet margins and parameters \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=10\). Plots of the modified Pickands estimator \(\hat{A}_{\text {p}}\) and smoothed spline estimate of dependence function \(\hat{A}_{\text {s}}\) are shown in Fig. 9.

Three estimates of dependence function for a sample of size 200 from asymmetric logistic extreme value distribution with same parameters as in Fig. 5. The underlying dependence function is also depicted

Approximations of the smoothed spline estimate of a sample from asymmetric logistic dependence function are presented. The corresponding number of eigenfunctions is shown on the top of each panel. Solid (blue) line is the approximation \(\hat{A_{e}}\) and dashed (black) line is the smoothed spline estimate \(\hat{A_{s}}\). The underlying dependence function is also depicted with dashed (red) line. The bottom right panel shows the \({\ell}\!_{2}\) (solid brown line) and \({\ell}\!_{\infty}\) (dashed brown line) norms of \(( \hat{A_{s}}- \hat{A_{e}})\) as a function of number of eigenfunctions in the approximation
Eight approximations of \(\hat{A_{s}}\) with varying number of eigenfunctions are shown in Fig. 10 where the last panel shows the \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms of the difference between \(\hat{A}_{\text {s}}\) and \(\hat{A}_{\text {e}}\).
To assess performance of the proposed method we conducted a simulation study where we generated 100 samples from asymmetric logistic distribution with the same parameters as in Fig. 10 and calculated \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms of \(( \hat{A_{s}}- \hat{A_{e}})\) as a function of number of eigenfunctions in the approximation. The results are shown in Fig. 11. Changing the non-parametric estimator to \(\hat{A}_{\text {p}}\) or \(\hat{A}_{\text {gcmp}}\) produced very similar results so for brevity they are not presented here.

Monte Carlo study of approximations errors for asymmetric logistic dependence function with \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). Box plots of \(N=100\) simulated values of \({\ell}\!_{2}\) (left) and \({\ell}\!_{\infty}\) norms (right) of \(( \hat{A_{s}}- \hat{A_{e}})\) as a function of number of eigenfunctions in the approximation are shown
Similarly to the settings in Fig. 8, we also studied the performance of the method under weaker dependence conditions with all three non-parametric estimators \(\hat{A}_{\text {s}}\), \(\hat{A}_{\text {p}}\) and \(\hat{A}_{\text {gcmp}}\). The results presented in Figs. 10 and 11 are representative even when another estimator of a dependence function is used in the approximation. As mentioned in Section 4.1, the only noticeable difference is that more eigenfunctions are needed for weaker dependence cases in order to obtain a fine approximation.
4.3 Testing for symmetry
In recent years many methods have been proposed for testing symmetry in the underlying dependence structure of a pair of random variables. Recent literature includes the work by Lyu and Belalia (2023) where a test was developed using empirical Bernstein copula process. Another important method based on Cramér-von Mises and Kolmogorov-Smirnov functionals of a rank-based empirical process was suggested in Genest et al. (2012). Competing methods to these tests were developed in Bahraoui et al. (2018). Some other relevant literature includes Quessy and Bahraoui (2013) and Erdely and González-Barrios (2010). Below we will discuss a new non-parametric test based on the theoretical results developed in this paper.
As mentioned in Section 4, the eigenfunctions alternate between even and odd functions. This implies, of course, that if the underlying dependence function is symmetric then all the theoretical odd coefficients in (3.7) are 0. In statistical inference context, this property can be used to develop a non-parametric method for testing symmetry which we discuss next.
Suppose \(\hat{A}_{\text {eSym}}\) and \(\hat{A}_{\text {eNonSym}}\) denote an approximation of a given estimate of dependence function \(\hat{A}\) according to the method discussed in Section 4.2. Note that in order to obtain a symmetric approximation \(\hat{A}_{\text {eSym}}\), we just need to use only even numbered eigenfunctions (including \(S_{0}(w)\)) in the set M in the optimization routine (4.16). A test for symmetry can be obtained as an analogue of the classical Cramér-von Mises statistic as
For numerical evaluation purposes the following approximate can be used:
where \(0=w_{0}< \dots < w_{t}=1\) are \(t+1\) points in the interval [0, 1]. An approximate p-value can be obtained as follows.
-
1.
For a given estimate of a dependence function \(\hat{A}\), find the approximations \(\hat{A}_{\text {eSym}}\) and \(\hat{A}_{\text {eNonSym}}\) and calculate the empirical value of the test-statistic \(d_{0}:= \tilde{D}\).
-
2.
Simulate a sample of the same size as the original one from the BEV distribution (2.2) using the symmetric approximation of the dependence function \(\hat{A}_{\text {eSym}}\) found in step (1).
-
3.
Calculate \(\hat{A}_{\text {eSym}}\) and \(\hat{A}_{\text {eNonSym}}\) for the sample in step (2).
-
4.
Repeat the steps (2) and (3) for a large integer N and compute their corresponding test-statistic \(d_{i}\) for any \(1\le i \le N\).
-
5.
The approximate p-value is \(\#\{1\le i \le N \mid d_{i} >d_{0} \}/N\).
To study the performance of the above testing method we conducted a small simulation study. In the first case, we simulated 100 samples of size 100 from logistic distribution (4.12) with \(r=2\). For each sample we calculated \(d_{0}\) using both \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms in (4.17) and found the approximate p-value based on \(N=100\) in the methodology outlined above. In all simulations we took the first 11 eigenfunctions \(S_{i}, i=0, \dots , 10\) in approximating the dependence function. The null hypothesis “\(\mathcal {H}_{0}:A \text { is symmetric}\)” could not be rejected for any of the 100 samples for nominal significance level \(\alpha =0.05\). A typical example of the results for a sample is shown in Fig. 12.

Testing symmetry for logistic dependence function with \(r=2\). Histogram of \(N=100\) simulated values of the test statistic for \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) are depicted. The small (black) circle shows the value of \(d_{0}\) and the large (red) circle is the 95% quantile of simulated values of \(d_{1}, \dots , d_{100}\). The left and right panels depict the results for \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\), respectively
Monte Carlo approximations of the power of the test were evaluated by simulating from asymmetric logistic dependence function in (4.13) with parameters \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). The only difference with the simulations for symmetric logistic was that we took the first 21 eigenfunctions \(S_{i}, i=0, \dots , 20\) in approximating the dependence function. The null hypothesis was rejected in 93 of 100 samples. Figure 13 shows two typical cases from simulations where in the first row the null hypothesis is correctly rejected (true positive) while the second row shows a false negative case where the null hypothesis could not be rejected.

Testing symmetry for asymmetric logistic dependence function with \(\theta =0.9, \,\, \phi =0.2\, \text { and } r=2\). Histogram of \(N=100\) simulated values of the test statistic for \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\) norms are shown. The small (black) circle shows the value of \(d_{0}\) and the large (red) circle is the 95% quantile of simulated values of \(d_{1}, \dots , d_{100}\). The left and right panels depict the results for \({\ell}\!_{2}\) and \({\ell}\!_{\infty}\), respectively
4.4 Numerical approximation of a BEV copula and concordance measures
In recent years copulas have emerged as a standard tool for modelling dependence between random variables. The formal development of the theory for copulas goes back more than half a century to the seminal paper by Sklar (1959) although the major interest in the applications started about two decades ago. One significant contributing factor to the popularity of copulas in recent years seems to be the huge advances in computing technology which has made it possible to analyse fairly complicated models in a straightforward manner. The approximations presented in this paper rely also heavily on the advancements in computer algebra system. A BEV copula is defined as
so, the methods discussed in Sections 4.1 and 4.2 can be used to find a series expansion of the BEV copula or its density. In this section we provide an example of application.
The classical correlation is arguably the most well-known measure for quantifying the dependence between two random variables. However, considering its dependence on marginal distributions and other limitations, concordance measures have been developed which are defined as integrals that involve only a copula or its partial derivatives. For instance, Kendall’s \(\tau\) and Spearman’s \(\rho\) are respectively defined as
For BEV distributions, it can be shown that the corresponding formulas are (see Capéraà et al. (1997, page 568))
In many cases calculating these integrals have proved challenging so the proposed approximations based on sum of simple analytical functions can be useful. For instance, if A is twice differentiable, one can use the Eqs. (3.7) and (3.8) to approximate \(\frac{A''(w)}{A(w)}\) in (4.19). Then the integral can be seen as \(6E[\frac{A''(W)}{A(W)}]\) where W has Beta(2, 2) distribution and \(E[\cdot ]\) denotes expected value.
As an example, we took \(r=2\) in the logistic dependence function in (4.12) and conducted a simulation study according to the following settings to obtain Monte Carlo approximations of Kendall’s \(\tau\) and Spearman’s \(\rho\):
-
1.
based on the true underlying logistic dependence function A and its derivatives,
-
2.
based on an approximation of logistic dependence function \(A_{e}\) according to the methodology discussed in Section 4.1, and
-
3.
based on simulating 100 samples of size 200 from the true underlying BEV distribution with logistic dependence function and then approximating smoothing spline estimate of the dependence function \(\hat{A}_{\text {s}}\) according to the methodology discussed in Section 4.2 (denoted by æas before).
In the last two cases, in order to approximate the dependence function and its derivatives we took the first 16 and 31 eigenfunctions, respectively. The reason to include more terms in the sum approximating \(A^{''}\) is due to slower rate of convergence as can be seen in Fig. 4. In all cases we generated 100 samples each with 10 000 random observations from Beta(2, 2) distribution and found the Monte Carlo approximation to the integral in (4.19).
The same methodology can be applied to estimating Spearman’s \(\rho\) with the only difference that in the corresponding integral in (4.20) we use Beta(1, 1) distribution instead. Summary of the results for both cases are shown in Fig. 14. As expected, the simulation results for first two scenarios are very similar (labeled as A and \(\hat{A}\) in the figure) while the last case introduces more variation due to the extra random element involved in estimating \(\hat{A}_{\text {s}}\) and approximating it by \(\hat{A}_\text {e}\).

Box plots of 100 estimates of Kendall’s \(\tau\) (left) and Spearman’s \(\rho\) (right) for the logistic dependence function with \(r=2\) are depicted. The three cases in each plot correspond to where A, \(A_{\text {e}}\) or \(\hat{A}_{\text {e}}\) are used in the Monte Carlo approximations of the corresponding integrals in (4.19) and (4.20)
In this section we have only discussed how the approximation of a BEV copula can be used to estimate Kendall’s \(\tau\) and Spearman’s \(\rho\) but the methodology might be useful in calculating other measures of dependence such as upper and lower tail dependence.
4.5 Prediction regions for bivariate extremes
It is clear from the definition of BEV copula in (4.18) that its conditional distribution and the density involve the first two derivatives of dependence function. To illustrate how the results in this paper can be used for analysis of extreme value data, we apply our methods to maximum annual values of average daily temperature measurements at two meteorological stations, Leonora and Menzies in Western Australia during the period 1898–1993. The dataset was first analysed in Hall and Tajvidi (2004) and it was published in SimCop package (see Tajvidi and Turlach (2017)) which is in turn based on the paper by Tajvidi and Turlach (2018). The left panel of Fig. 15 shows a scatterplot of maximum annual temperatures in degrees Celsius in these two stations. In the right panel two estimates of dependence function, \(\hat{A}_{\text {p}}\) and \(\hat{A}_{\text {s}}\), are depicted.

Scatterplot of the annual temperature maxima at meteorological stations Leonora and Menzies, in Western Australia, from 1898 to 1993 is shown in the top left panel. Modified Pickands estimator of dependence function, \(\hat{A}_{\text {p}}\), and the smoothed Spline estimator, \(\hat{A}_{\text {s}}\), are shown in the top right panel. Approximations of \(\hat{A}_{\text {s}}\) are presented at the bottom
The correlation coefficient of temperatures in two stations is 0.8518. To calculate concordance measures we followed the approach in Section 4.4 and Kendall’s \({\tau }\) was estimated to 0.69998 using the first 11 eigenfunctions. This is very close to the sample estimate of Kendall’s \(\tau\) which is 0.69692. Similarly, the Spearman’s \({\rho }\) was estimated to 0.878328 where the corresponding sample estimate is 0.85471. An alternative approach to these calculations would be to simulate directly from the approximation of the copula similar to the methods discussed in Section 4.3 and construct a bootstrap confidence interval for the concordance measure of interest.
In the next step, we applied the methods of Section 4.2 which resulted in the approximations of \(\hat{A}_{\text {s}}\) shown in the second and third row of Fig. 15. Testing symmetry according to the approach outlined in Section 4.3 did not give any indication of asymmetry in the dependence function, as it would be expected from the shape of \(\hat{A}_{\text {s}}\) in Fig. 15.

The fitted BEV copula density and the corresponding BEV density for the annual temperature maxima at meteorological stations Leonora and Menzies are shown in the left and right panel, respectively

Semi-infinite prediction regions estimated from BEV distribution fitted to annual maximum temperature data, \(\hat{G}(x, y)\), are depicted in the left panel. The corresponding nominal levels for \(\hat{G}(x, y)=\alpha\) ranging from 0.1 to 0.99 are shown in the legend. Three compact prediction regions along with the dataset are shown in the right panel. The nominal coverage levels are shown in the legend
An estimate of the density of the corresponding BEV copula was calculated next based on (4.18) where we took the first 11 eigenfunctions in the approximations of the dependence function and its second derivative. As the margins are assumed to have GEV distribution in (2.1), we used the estimates of the marginal parameters and calculated the density function of the corresponding BEV distribution. The fitted BEV copula and the corresponding BEV density are shown in Fig. 16.
The semi-infinite prediction regions shown in the left panel of Fig. 17 are comparable to Fig. 5 in Hall and Tajvidi (2004) but, due to analytical expressions available for the dependence function, the calculations are much less time consuming. Of course one can improve the approximations by including more eigenfunctions in the analysis but in this case the coefficients \(a_{i}\) obtained from (4.16) are of order \(10^{-7}\) so they can safely be neglected. The calculated analytical expressions for the density makes it fairly straight forward to calculate the integral of the BEV density resulting in compact prediction regions. A few examples are shown in the right panel of Fig. 17 which are equivalent to regions in Fig. 7 of Hall and Tajvidi (2004). For calibration of prediction regions, Hall and Tajvidi (2004) suggested simulating observations from histogram density whereas, with the methods presented in this paper, similar approach as in Section 4.3 can be employed for sampling from an approximation of the copula in (4.18) instead.
5 Proofs
Theorem 2 We need to find characteristic values and eigenfunctions of the kernel function given in (3.6), i.e. we want to find \(S_k(w)\) and \(\lambda _k\) such that
where the kernel function is given by
Considering the above kernel, it can be easily seen that the left hand side of Eq. (3.5) can be written as:
Taking the second derivative of both sides of the above integral equation with respect to w we find
Plugging this back to the second derivative of (5.21) gives the differential equation:
By evaluating the integral Eq. (5.21) and its first derivative at \(w=0\) and \(w=1\) we find that the solutions must satisfy the following boundary conditions:
Solving the differential Eq. (5.22) with the above boundary conditions leads to the following results:
-
1.
For \(\lambda >0\) there is only one solution
$$\begin{aligned} S(w)=\frac{2 c \left( \sqrt{\lambda } \cosh \left( w \sqrt{\lambda }\right) -\sinh \left( w \sqrt{\lambda }\right) \right) }{1+\sqrt{\lambda }} \end{aligned}$$(5.24)where c is a constant and \(\lambda\) is the solution of
$$\begin{aligned} 1-e^{\sqrt{\lambda }} \left( -1+\sqrt{\lambda }\right) +\sqrt{\lambda }=0. \end{aligned}$$(5.25)The approximate solution of the equation with precision 10 is \(\lambda =2.382097878\). We denote this characteristic function with the corresponding characteristic value with \(S_{0}(w)\) and \(\lambda _{0}\), respectively.
-
2.
For \(\lambda <0\) there is an infinite and countable number of solutions given by
$$\begin{aligned} S_k(w)=c_{k} \left( -\sqrt{\left| \lambda _k \right| } \cos \left( w \sqrt{\left| \lambda _k \right| }\right) +\sin \left( w \sqrt{\left| \lambda _k \right| }\right) \right) \text { for }\,\, k=1,2,\dots \end{aligned}$$(5.26)where \(c_{k}\) is a constant and \(\lambda _k\) can be found from the following equation:
$$\begin{aligned} 2 \sqrt{\left| \lambda _k \right| } \cos \left( \sqrt{\left| \lambda _k \right| }\right) +(-1+\left| \lambda _k \right| ) \sin \left( \sqrt{\left| \lambda _k \right| }\right) =0 \text { for } \,\, k=1,2,\dots . \end{aligned}$$(5.27)
Proposition 1 Assuming that the measure \(\mathbb {S}\) is differentiable on [0, 1], the Eq. (3.5) can be written as
where we have denoted the corresponding spectral density by S. Taking second derivative of the above equation gives \(S(w)=A''(w)\). In addition by evaluating the above equation and its first derivative at \(w=0 \text { and } 1\) we see that A must satisfy the boundary conditions
Since the above conditions are also satisfied by the eigenfunctions then it is possible to expand \(A''\) in terms of eigenfunctions found in Theorem 2.
Proposition 2 If \(\mathbb {S}\) has point masses at 0 and 1, then (2.3) becomes
where
where we have denoted the corresponding spectral density on (0, 1) by S. Theorem 2 implies that \(S(w)=B''(w)\). Using the fact that \(A(0)=A(1)=1\) and Eq. (2.4) it can be seen that
so B must satisfy the same boundary conditions as the eigenfunctions.
References
Bahraoui, T., Bouezmarni, T., Quessy, J.F.: Testing the symmetry of a dependence structure with a characteristic function. Depend. Model. 6, 331–355 (2018)
Beirlant, J., Goegebur, Y., Teugels, J., Segers, J.: Statistics of extremes: theory and applications. In: Wiley series in probability and statistics. Wiley, Hoboken, N.J. (2004)
Capéraà, P., Fougeres, A.L., Genest, C.: A nonparametric estimation procedure for bivariate extreme value copulas. Biometrika 3, 567 (1997)
de Haan, L., Ferreira, A.: Extreme Value Theory: An Introduction. Springer Series in Operations Research and Financial Engineering, New York: Springer-Verlag (2006)
de Haan, L., Resnick, S.: Limit theory for multivariate sample extremes. Zeitschrift Für Wahrscheinlichkeitstheorie Und Verwandte Gebiete 40, 317 (1977)
Dey, D.K., Yun, J. (eds.): Extreme Value Modeling and Risk Analysis: Methods and Applications. Chapman & Hall/CRC, Boca Raton (2016)
Embrechts, P., Klüppelberg, C., Mikosch, T.: Modelling Extremal Events: for Insurance and Finance, Applications of Mathematics: Stochastic Modelling and Applied Probability, vol. 33. Springer-Verlag, Berlin (1997). https://doi.org/10.1007/978-3-642-33483-2
Erdely, A., González-Barrios, J.M.: A nonparametric symmetry test for absolutely continuous bivariate copulas. Stat. Methods Appt. 19, 541–565 (2010)
Genest, C., Nešlehová, J., Quessy, J.F.: Tests of symmetry for bivariate copulas. Ann. Inst. Stat. Math. 64, 811–834 (2012)
Gudendorf, G., Segers, J.: Nonparametric estimation of an extreme-value copula in arbitrary dimensions. J. Multivar. Anal. 102, 37–47 (2011). https://doi.org/10.1016/j.jmva.2010.07.011
Gudendorf, G., Segers, J.: Nonparametric estimation of multivariate extreme-value copulas. J. Stat. Plan. Inference 142, 3073–3085 (2012). https://doi.org/10.1016/j.jspi.2012.05.007
Hall, P., Tajvidi, N.: Distribution and dependence-function estimation for bivariate extreme-value distributions. Bernoulli 6, 835–844 (2000)
Hall, P., Tajvidi, N.: Prediction regions for bivariate extreme events. Aust. N. Z. J. Stat. 46, 99–112 (2004). https://doi.org/10.1111/j.1467-842X.2004.00316.x
Joe, H.: Multivariate models and dependence concepts. Monographs on statistics and applied probability: 73, London: Chapman & Hall (1997)
Leadbetter, M.R., Lindgren, G., Rootzén, H.: Extremes and related properties of random sequences and processes. Springer series in statistics, New York ; Berlin : Springer-Vlg, cop (1983)
Lyu, G., Belalia, M.: Testing symmetry for bivariate copulas using bernstein polynomials. Stat. Comput. 33 (2023)
Marcon, G., Padoan, S., Naveau, P., Muliere, P., Segers, J.: Multivariate nonparametric estimation of the Pickands dependence function using Bernstein polynomials. J. Stat. Plan. Inference 183, 1–17 (2017). https://doi.org/10.1016/j.jspi.2016.10.004
Pickands, J.: Statistical inference using extreme order statistics. Ann. Stat. 3, 119 (1975)
Pickands, J.: Modelling extreme multivariate events. Proc. 43rd Session I.S.I. pp 859–878 (1981)
Pickands, J.: Multivariate negative exponential and extreme value distributions. Proc. 43rd Session I.S.I. Springer Lecture Notes in Statistics 51, 859–878 (1989)
Polyanin, A., Manzhirov, A.: Handbook of Integral Equations. Taylor & Francis (1998). https://books.google.se/books?id=CcLNYseATEQC
Quessy, J.F., Bahraoui, T.: Graphical and formal statistical tools for assessing the symmetry of bivariate copulas. Can. J. Stat./La Revue Canadienne de Statistique 41, 637–656 (2013)
Resnick, S.I.: Extreme values, regular variation and point processes. In: Springer series in operations research and financial engineering. Springer, cop, New York, NY (2008)
Sklar, A.: Fonctions de répartition à n dimensions et leurs marges. Publications de l’Institut de Statistique de L’Université de Paris 8, 229–231 (1959)
Tajvidi, N., Turlach, B.: A general approach to generate random variates for multivariate copulae. Aust. N. Z. J. Stat. 60, 140–155 (2018)
Tajvidi, N., Turlach, B.A.: SimCop: Simulate from Arbitrary Copulae. R package version 0.7.0 (2017)
Tawn, J.A.: Bivariate extreme value theory: Models and estimation. Biometrika 75, 397–415 (1988)
Zhang, D., Wells, M.T., Peng, L.: Nonparametric estimation of the dependence function for a multivariate extreme value distribution. J. Multivar. Anal. 99, 577–588 (2008). https://doi.org/10.1016/j.jmva.2006.09.011
Acknowledgements
I am grateful to the reviewers for very constructive comments and suggestions in both revisions of the paper. I would also like to thank Berwin Turlach for the discussions at the early stage of the research behind this paper.
Funding
Open access funding provided by Lund University. I have not received any funding for this article.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval
Not Applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tajvidi, N. On approximating dependence function and its derivatives. Extremes 27, 479–503 (2024). https://doi.org/10.1007/s10687-024-00484-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10687-024-00484-2