
Abstract
X-ray cone-beam computed tomography (CBCT) is a powerful tool for nondestructive testing and evaluation, yet the CT image quality can be compromised by artifact due to X-ray scattering within dense materials such as metals. This problem leads to the need for hardware- and software-based scatter artifact correction to enhance the image quality. Recently, deep learning techniques have merged as a promising approach to obtain scatter-free images efficiently. However, these deep learning techniques rely heavily on training data, often gathered through simulation. Simulated CT images, unfortunately, do not accurately reproduce the real properties of objects, and physically accurate X-ray simulation still requires significant computation time, hindering the collection of a large number of CT images. To address these problems, we propose a deep learning framework for scatter artifact correction using projections obtained solely by real CT scanning. To this end, we utilize a beam-hole array (BHA) to block the X-rays deviating from the primary beam path, thereby capturing scatter-free X-ray intensity at certain detector pixels. As the BHA shadows a large portion of detector pixels, we incorporate several regularization losses to enhance the training process. Furthermore, we introduce radiographic data augmentation to mitigate the need for long scanning time, which is a concern as CT devices equipped with BHA require two series of CT scans. Experimental validation showed that the proposed framework outperforms a baseline method that learns simulated projections where the entire image is visible and does not contain scattering artifacts.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
X-ray cone-beam computed tomography (CBCT) is a powerful tool for industrial nondestructive testing and evaluation. X-rays have the strong capability of penetrating objects and enable visualizing even inside the objects in a nondestructive manner [1]. Owing to this property, X-ray CT scanners are able to obtain three-dimensional volumetric CT images. In CBCT, the CT image is typically obtained by a reconstruction algorithm, such as filtered back projection, also known as Feldkamp–Davis–Kress (FDK) algorithm [2], and simultaneous algebraic reconstruction technique (SART). These algorithms typically processes a set of projections captured by hundreds or thousands of X-ray radiations from different directions on a trajectory. Each voxel value of the CT image represents a linear attenuation coefficient (LAC) of the material at the voxel, where an LAC is approximately proportional to the material density. We can distinguish the target object from the air in the CT image and extract the surface geometry of the object by isosurfacing [3]. Thus, we can inspect the target objects from geometric perspectives, e.g., the amount of manufacturing errors against the nominal object defined by a CAD model. However, the quality of CT images is limited by various artifacts. The scatter artifact is one of the factors that damages the CT image quality in industrial X-ray CT because X-ray is scattered strongly in heavy materials such as metals [4, 5].
X-ray scattering inevitably occurs during the interaction of X-ray photons with materials [6]. The sources of X-ray scattering include Rayleigh scattering, Compton scattering, the photoelectric effect, and pair production. Among these four, the first three are the dominant sources of X-ray scattering for off-the-shelf X-ray CT devices, while pair production occurs when the photon energy is higher than about \({1}\,\hbox {MeV}\). While CT reconstruction assumes that X-rays attenuate in a straight primary beam path, the principle of reconstruction is no longer satisfied if the direction of X-ray transport changes due to scattering. Specifically, scattered X-rays enter the detector pixels from the path deviating from the primary beam path, resulting in increased X-ray intensity at certain detector pixels. This increase in X-ray intensity leads to scatter artifacts which appears like hazes in CT images. Thus, the scatter artifacts hinder surface extraction from a volumetric CT image and precise shape measurement of the object.
1.1 Hardware Scatter Correction
Scatter artifact is often corrected by special hardware, such as bowtie filter (BTF) [7,8,9,10,11,12], air-gap [13], anti-scatter grid (ASG) [14, 15], beam-stop array (BSA) [16, 17], and beam-hole array (BHA) [18]. They are installed near either the X-ray source or the detector and reduce or block a part of scattered X-rays. The BTF and air-gap decrease a scatter-to-primary ratio (SPR), but the amount of reduction is limited. The ASG is a collimator grid installed in front of the detector. Depending on the thickness of the collimation grid, it can reduce scattered X-rays reaching the detector. However, the brightness in projections will be significantly darker, which results in a low signal-to-noise ratio (SNR).
BSA and BHA are complementary hardware components. The BSA, composed of a set of cylindrical solid metal components, serves to extract scattered X-rays, whereas the BHA, a metal plate drilled by a set of cylindrical holes, serves to extract primary X-rays, namely, the X-rays entering from the primary beam line. The drawback of these arrays is that the scattered or primary X-rays are detected only by a part of the detector pixels. Therefore, the software process is required to interpolate pixel values. Since another set of projections consisting of both scattered and primary X-rays are used as a guide for the interpolation, we need to take two series of projections using and not using the array to obtain a scatter-free CT image. Furthermore, while BSA and BHA are effective hardware for scatter correction, devices equipped with such hardware are not yet widely available.

The overview of the proposed deep learning framework, where two series of projections are used for training: one captured without the BHA and another with both sets of projections are split into small patches to construct mini-batches. The CNN is trained to estimate scatter components from a mini-batch of scatter-contaminated patches. The parameters of the CNN are updated to minimize the losses computed for the masked images and the outputs from the CNN. The spatial gradients of images, such as \(\nabla \textbf{I}_i\), are visualized by RGB colors. In this visualization, red and green channels represent gradients along x- and y-axes, respectively, and the blue channel is set to one (Color figure online)
1.2 Software Scatter Correction
The standard software-based scatter correction begins with reconstructing a coarse CT image using uncorrected projections that are contaminated by scatter artifacts. Then, the scatter component in each projection is estimated using the coarse CT image. Finally, the scatter-free projections are obtained by subtracting the scatter component from another CT image with a higher resolution. Thus, the key component of the software-based scatter correction is how to estimate the scatter component. We refer the readers to the literature [19] for a comprehensive survey of the estimation techniques.
Monte Carlo (MC) simulation is an approach to accurately reproduce the behavior of X-rays attenuated and scattered while traveling through the object medium. A classic approach [20] utilized the MC simulation to compute a system matrix, which describes the magnitude of X-rays traveling from a light source to a detector pixel. Once the system matrix has been computed, the system of linear equations is solved in order to obtain the image with scatter artifacts being compensated. Recently, there are several MC simulation systems for CBCT [21, 22] used for the scatter correction [23]. Since the accurate simulation inevitably requires much computation time, efficient approximation for X-ray scattering has also been investigated [24, 25]. Moreover, other approaches consider only first-order scattering to derive a closed-form solution as an approximation of the comprehensive X-ray transport [26, 27].
Empirically, the influence of X-ray scattering is known to be approximated as a spatially varying 2D convolution on the detector [28, 29]. An early approach employed isotropic Gaussian functions to approximate X-ray scattering in CBCT systems [30]. Afterward, anisotropic kernels [31] and a weighted sum of Gaussian functions [32, 33] were applied to more precisely reproduce X-ray scattering and varied the magnitude of convolution kernels depending on the penetration lengths of X-rays along their primary beam paths.
Recently, deep learning techniques using convolutional neural networks (CNNs) have been applied to projection-domain scatter estimation. Although the capability of CNNs to represent a projection-domain convolution kernel has been known since the 1990s [34], its performance has been significantly improved owing to the availability of deeper networks and plenty of training data synthesized by MC simulation [35,36,37,38,39]. Several medical-purpose methods used datasets comprised of actual images, e.g., those of patients’ pelvis [40] and those captured by the positron emission tomography (PET) [41]. However, it is still challenging to construct such a large dataset of real CT images for industrial purposes because industrial CT systems are often expensive and do not prevail sufficiently among industries.
1.3 Problem Statement
We consider the requirement of many training data has hindered the full application of deep learning techniques for industrial-purpose CT. In general, collecting training data of CT images through simulation can be time-consuming due to the limitations of typical approaches, such as MC and linear Boltzmann transport (LBT) methods. These limitations are addressed by many studies on the efficient variants of MC methods [24, 42, 43] and LBT methods [44, 45]. However, MC methods are inherently time-consuming due to the stochastic nature of the simulation, which requires tracing a large number of photons to achieve high accuracy. LBT methods are generally more computationally efficient than MC methods. However, they still require a precise mesh grid to solve the LBT equation more accurately. Fine discretization can increase the computation time required for the simulation process.
Moreover, the items examined by industrial CBCT differ significantly from those in the medical field. The variety in shapes of industrial products is more diverse than that of human organs, and even identical shapes can be made of different materials. These products are often captured using diverse devices with varying optics and tube voltages. Although a previous study [37] showed that a neural network trained with a few simulated data worked well for scatter correction, it remains uncertain if the dataset size was adequate, as the network is tested solely on a single specimen. Even if the data quantity is sufficient, MC simulation for X-ray CT cannot obtain CT images that perfectly replicate the real ones, as reported by a prior study [38].
To address these problems, we explore a novel deep learning framework for scatter correction that only uses real projections for training the CNN. The overview of the proposed method is shown in Fig. 1. The training data is captured by a CT scanner equipped with the BHA. We capture ordinary projections with scatter components and other projections with only primary intensities but shadowed by the BHA. However, the latter set of projections only has proper primary intensities on a portion of pixels. To also reproduce the primary intensities at shadowed pixels, our method employs several loss functions, which aid in learning scatter artifact correction from incomplete projections.
As we need to scan each target object twice, once with and once without the BHA, constructing a training dataset for deep learning requires a significant amount of time. To address this, we introduce radiographic data augmentation to reduce the amount of required data. The data augmentation enables the proposed method to work properly with only one series of projections captured for a single sample object. Once the CNN has been trained, it can be used for other sets of projections captured by CT scanners that are NOT equipped with the BHA.
2 Learning Scatter Artifact Correction Using Beam Hole Array
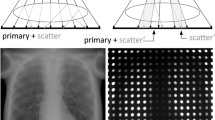
To let the CNN to learn scatter artifact correction, we capture scatter-free projections using a BHA. The mechanism of canceling X-ray scattering with the BHA is illustrated at the top of Fig. 2. The BHA is a metal plate where a set of cylindrical holes are made to collimate X-rays. The X-ray with a low SPR will be detected on the part of the detector pixels. The projections captured with and without the BHA are shown at the bottom of Fig. 2. As shown, the image captured without the BHA consists of both the primary and scatter X-rays, while that captured with the BHA consists only of the primary X-rays.

The top illustration shows a CBCT system with a BHA, which is a heavy metal plate with multiple cylindrical holes. The bottom two images illustrate the impact of the BHA on the sample projections
Notations. We denote a projection image \(\textbf{I} \in [0, 1]^Q\) as a vector of scalar intensities and the intensity of qth pixel as \(I_q\), where Q is the number of detector pixels. The intensity of each pixel in \(\textbf{I}\) represents the ratio of attenuation of an X-ray. Further, we denote the set of images captured without the BHA as \(\mathcal {I} = \{ \textbf{I}_i: i = 1, \ldots , N \}\), where N is the number of projections captured by a single CT scan. We represent the primary and scatter components of \(\textbf{I}_i\) as \(\textbf{P}_i\) and \(\textbf{S}_i\), respectively. Let \(\textbf{M} \in \{ 0, 1 \}^{Q}\) be a mask image associated with the BHA, where 0 is for masked pixels and 1 is for exposed pixels. Then, we can write the second set of images captured with the BHA as \(\mathcal {J} = \{ \textbf{J}_i = \textbf{P}_i \odot \textbf{M}: i = 1, \ldots , N \}\), where \(\odot \) represents the element-wise product.
2.1 Network Architecture
The CNN in our system serves to estimate the scatter component \(\textbf{S}_i\) of projection image \(\textbf{I}_i\). Let F be a function associated with the CNN and \(\Theta \) be the parameters of the CNN. Then, the estimation of the primary component is formulated as
where \(\hat{\textbf{P}}_i\) and \(\hat{\textbf{S}}_i\) with the hat sign denote the estimated ones for primary and scatter components.
The proposed method can employ an arbitrary CNN for image-to-image transformation, such as autoencoder [46], U-net [47], and its variants [35, 37]. In this study, we employed the CNN used in Deep Scatter Estimation (DSE) [37] because we confirmed it works better for scatter correction. After convolution layers except the last one of this network, we installed batch normalization to accelerate the training. Following the last convolution layer, we installed a sigmoid activation to ensure that \(\textbf{S}_i(\Theta )\), i.e., the output from the network, falls in the range [0, 1].
2.2 Loss Functions
The network parameters \(\Theta \) are determined by minimizing a loss function L computed with training image pairs (i.e., \(\mathcal {I}\) and \(\mathcal {J}\)). The minimization problem is formulated as
When fully visible and scatter-free projections are available through simulation, as with the previous studies [37], the loss function can be defined by an error between scatter-free images and those estimated by the CNN. However, the scatter-free images are incomplete when obtained by real scans with the BHA, and a large part of the detector pixels are shadowed. Therefore, we need to train the CNN not only to reproduce the primary intensities in incomplete projections but also to interpolate the intensities for the shadowed pixels.
Loss for reproduction. To ensure the CNN accurately predict the scatter component \(\textbf{S}_i\) at unshadowed pixels, we use a simple mean absolute error (MAE) between \(\textbf{J}_i\) and \(\hat{\textbf{P}}_i \odot \textbf{M}\). When calculating \(\hat{\textbf{P}}\) using Eq. 1a, several pixels may exhibit negative values when corresponding entries of \(\hat{\textbf{S}}_i\) is larger than those of \(\textbf{I}_i\). Such negative pixel values of \(\hat{\textbf{P}}_i\) may cause inappropriate CT reconstruction and, as such, should be prevented. To this end, we penalize the negative element of \(\hat{\textbf{P}}_i\) by modifying the MAE. Then, \(L_{\textrm{mae}}\) is defined as
where \(\Vert \cdot \Vert _1\) is the sum of absolute values of vector or matrix entries, and \(R_q\) is the qth element of the vector-valued remapping function \(R: [-1, 1]^Q \rightarrow (-\infty , 1]^Q\), which is defined as

Here, the entries of \(\textbf{P}_i\) fall between -1 and 1 because those of \(\hat{\textbf{I}}_i\) and \(\hat{\textbf{S}}_i\) are in [0, 1]. The remapping function magnifies negative \(P_q \in [-1, 0]\) to fall in \((-\infty , 0]\) such that it will be penalized more heavily in Eq. 3.

a A double logarithmic chart illustrating the variation of LAC as a function of photon energy. b A plot showing the correlation between tube voltage and the effective photon energy of an X-ray computed specifically for a tungsten target

a The chart shows the change in \(\ln \mu \) against \(\ln V\) is approximately linear in the domain \(V \in [100, 400]\). b The table shows the inclination and the intercept for each approximation line of the curves in a
Losses for interpolation. To interpolate the scatter component for shadowed pixels, we assume that the scatter component is hazy and consists mainly of low-frequency signals over the detector. In this case, the high-frequency signals in \(\textbf{I}_i\) will not change significantly by subtracting \(\hat{\textbf{S}}_i\). Therefore, we penalize the gradient difference between \(\textbf{I}_i\) and \(\hat{\textbf{P}}_i = \textbf{I}_i - \hat{\textbf{S}}_i\) to ensure that the high-frequency signals of these two images are equivalent.
where \(\nabla \textbf{I} \in \mathbb {R}^{Q\times 2}\) be a matrix corresponding to the projection-space gradients of \(\textbf{I}\) along x- and y-axes.
In addition, we suppress white noises in the estimated primary component \(\hat{\textbf{P}}_i\) using the total variation with \(\ell _1\) norm (TV-L1).
We employ another total variation with \(\ell _2\) norm (TV-L2) to encourage the strong smoothness in \(\hat{\textbf{S}}_i\).
where \(\Vert \cdot \Vert _{2,1}\) is a sum of \(\ell _2\) norms of row vectors:
Then, the weighted sum of above loss terms are used as a loss function to train the CNN.
where \(\lambda _{\textrm{grad}}\), \(\lambda _{\mathrm {TV- L1}}\), and \(\lambda _{\mathrm {TV- L2}}\) are the constants to balance the influence of loss terms. We used \(\lambda _{\textrm{grad}}=0.1\) and \(\lambda _{\mathrm {TV- L1}}=\lambda _{\mathrm {TV- L2}}=0.01\) in the experiments shown later.
2.3 Data Augmentation
To make the most of a limited amount of data collected through real CT scanning, we employ two kinds of data augmentation techniques, radiographic data augmentation and image transformation. These techniques are applied to both \(\mathcal {I}\) and \(\mathcal {J}\). While the proposed method requires two series of projections for each sample, data augmentation significantly reduces the amount of data required. In fact, it can even enhance the proposed method to get sufficient performance solely with just one series of projections obtained from a single sample.
2.3.1 Radiographic Data Augmentation
The LACs stored in a CT image are varied by X-ray energy. Hence, the intensities in the image can be different for the same object when the CT scan is performed with different tube voltages. To overcome the different intensities obtained by various tube voltages, we propose a radiographic data augmentation to augment the intensities of projections by proactively approximating X-ray physics. Therefore, it is worth noting that the data augmentation technique introduced here does not aim to accurately reproduce the effects in X-ray physics but to increasing the variety of image intensities based on a radiography-inspired technique.
Figure 3a is a double logarithmic chart of the change in LAC \(\mu \) against the photon energy E. In contrast, Fig. 3b is another chart of the change in the effective photon energy \(\bar{E}\) against tube voltage V, specifically computed for a tungsten target. These charts are computed using aRTist, X-ray CT simulation software. From these two charts, we calculated the relationship between tube voltage and LACs of typical metals: Al, Cu, Fe, and Ti. Figure 4 shows the linearity between the logarithmic tube voltage \(\ln V\) and the logarithmic LAC \(\ln \mu \). The domain of the tube voltage in this chart is narrowed to the typical one in industrial X-ray CT devices (i.e., from \(100\, \hbox {kV}\) to \({400}\,\hbox {kV}\)). We write the linear relationship between \(\ln V\) and \(\ln \mu \) as
where A and B are the inclination and intercept of the line. On the other hand, the Lambert–Beer law relates the attenuation of the X-ray to the LAC of the material multiplied by the path length that the X-ray is traveling. Assume the intensity \(l_0\) of the X-ray emitted from the source attenuates to l while traveling through a material. In this case, the attenuation is written as
where L is the length of a straight path on which the X-ray travels. It is worth noting that we utilized the Lambert–Beer law with the LAC \(\mu \) at the effective photon energy \(\bar{E}\), while the actual value of \(\mu \) varies with the photon energy. Next, consider two X-rays generated with different tube voltages V and \(V'\). Because the attenuation ratio \(\frac{l}{l_0}\) is stored in each projection pixel I, we can relate the intensities of the projections I and \(I'\) using Eqs. 10 and 11:
Based on this relationship, we randomly vary the value of r for data augmentation. Within the range of typical tube voltages from \({100}\,\hbox {kV}\) to \({400}\,\hbox {kV}\), we choose \({200}\,{kV}\) to capture projections as training data. In this case, the ratio \(\frac{V'}{V}\) will be between \(\frac{100}{200}=0.5\) to \(\frac{400}{200}=2.0\). Furthermore, Fig. 4b shows that the inclinations A of approximate lines of the curves in Fig. 3a ranges from \(-\)1.087 to \(-\)0.307 and their average is \(-\)0.778. Getting these observations altogether, the range of r will be \([2.0^{-0.778}, 0.5^{-0.778}] = [0.583, 1.715] \approx [2/3, 3/2]\). Thus, the radiographic data augmentation picks a random real number r in [2/3, 3/2] and augments the intensity I of a projection to \(I'\) using Eq. 12.
In summary, based on Eq. 10, the approximated linear relationship between the logarithmic tube voltage and the logarithmic LAC, we can use Eq. 12, a simple tone mapping operation, to simulate the change in the intensities of projections by varying the tube voltage. As we will demonstrate through several experiments, this radiographic data augmentation is effective to enhance scatter artifact correction performance despite its approximated nature.
2.3.2 Image Transformation
After the radiographic data augmentation, we perform the image transformation, i.e., random image flipping, rotation, scaling, and cropping to obtain small image patches. In this way, the CNN can learn richer image features of a limited amount of projections. In the following, these operations are described in the order that they are performed for each projection.
-
(i)
Flip: The projection is flipped against each of the vertical and horizontal axes with 50% possibility.
-
(ii)
Rotation: The projection is rotated around the image center by a random degree of angle between \(-30^{\circ }\) and \(30^{\circ }\).
-
(iii)
Scaling: The projection is resized by a random scaling ratio between 2/3 and 3/2.
-
(iv)
Crop: Finally, we extract a small patch of the image by random cropping.
In the experiment shown later, the original size of projections is \(2024 \times 2024\) pixels. We crop out image patches with \(512 \times 512\) pixels randomly from projection images. Such image cropping is a common technique not only for data augmentation but also for stabilize the training of neural networks. Moreover, owing to the small size of cropped image patches, the CNN can be efficiently trained in terms of computational time and memory consumption. In contrast, during the evaluation phase, the trained CNN is used to correct the scatter components of the entire part of projections.

Sample objects used in our experiments
2.4 Training
We solve the minimization problem in Eq. 2 to train the CNN using a stochastic gradient descent method. Specifically, random image patches after the data augmentation are collected to construct a mini-batch, and the loss function in Eq. 9 is calculated for each mini-batch. Then, the gradients of the loss with respect to the network parameters \(\Theta \) are calculated using auto-differentiation provided by deep learning frameworks, such as PyTorch [48]. Finally, the parameters are updated by the adaptive momentum estimation (ADAM) method [49]. In the ADAM method, the learning rate \(\gamma \) and the decay parameters \((\beta _1, \beta _2)\) was initially set as \(\gamma = {1.0 \times 10^{-4}}\) and \((\beta _1, \beta _2) = (0.9, 0.999)\), respectively. We trained the CNN over 100 epochs, which is equal to 25000 steps using mini-batches comprised of four image patches when 1000 projections were available, and the number of training steps was increased proportionally to the number of projections. Furthermore, the learning rate was scheduled to decrease by a factor of 0.9 for every 2000 learning steps.
3 Experiments
The proposed method is implemented using PyTorch [48] and tested on a computer equipped with Intel® \(Core^{\textrm{TM}}\) i7-6800K CPU \({3.40}\,\hbox {GHz}\), NVIDIA GeForce RTX 3080 GPU (\({10}\,\hbox {GB}\) graphics memory), and \({128}\,{GB}\) of RAM. The samples used in the experiments are shown in Fig. 5, which consist of mechanical parts (i.e., the engine cover and crankcase), a titanium piece made by metal additive manufacturing, and a terra-cotta figurine of shisa (Okinawan lion dog). We scanned these objects with a CT scanner (Baker Hughes Phoenix V|tome|x C450) equipped with a BHA and obtained two series of projections using and not using the BHA. We spent approximately 30 min taking one series of 2000 projections for a single object; hence, we spent approximately one hour taking the two series. For both sets of projections, we apply the flat-field correction to every projection to ensure that the image intensity of projections consistently corresponds to the penetration lengths of X-rays.
In addition to the above data, we prepared several sets of simulated projections to compare our method with the baseline method using fully visible projections. To this end, we extracted surface meshes by isosurfacing [3] from the scatter-free CT images obtained by the above CT scanner. This particular CT scanner provides a software-based function of scatter artifact correction using the two projection series. Then, we simulated X-ray transport using aRTist [22], commercial software for X-ray simulation, obtaining two series of projections with and without scatter components. With this simulator, the Monte Carlo photon tracing took approximately 10 h to obtain 1000 projections when X-ray scattering was considered. In contrast, it took only 15 min when X-ray scattering was NOT considered. Through this simulation, we obtain two series of unshadowed projections: one consisting of only primary X-ray intensity and another consisting of both primary and scattered X-ray intensities.
In the following experiments with simulated and real scans, we used the projections of the terra-cotta shisa figurine to train the neural network. While the use of a terra-cotta figurine appears atypical in the context of industrial X-ray CT that typically deal with plastic and metal components, our choice was guided by the intention of ensuring robust scatter correction. Through comparative analysis, we found that CNN’s performance was notably enhanced when trained using more challenging data where projections exhibit strong scatter components. It is noteworthy that the terra-cotta figurine, owing to its numerous micropores, involves with “scattering effect” of general electromagnetic waves, which deviates the X-rays from the original path to many different directions. Thus, the terra-cotta figurine provides such challenging data. Therefore, we used the projections of the terra-cotta shisa figurine for training the CNN in both experiments using real and simulated scans.

Comparison of intensity errors in CT images. The scale of errors is indicated by the color bar at the bottom left, with positive differences shown in reddish colors and negative differences in bluish colors

Charts comparing the MAPEs of methods using unshadowed and shadowed projections, as well as those with either regularization losses or radiographic data augmentation ablated. The vertical dashed line in each chart indicates projections with long X-ray penetration lengths. Corresponding error visualizations are shown in Fig. 8

Visualization of signed SPRs for the projections with particularly long X-ray penetration lengths, which are marked with broken vertical lines in Fig. 7. The SPRs at projection pixels are colorized using a color map at the bottom of each “uncorrected” projection
3.1 Evaluation and Visualization Methods
As we can obtain a reference image \(\textbf{P}\) of primary X-ray intensities by simulation, we evaluated the quality of a scatter-corrected image \(\hat{\textbf{P}}\) in comparison with the reference. Both the projections and reconstructed CT image are evaluated with the mean absolute percentage error (MAPE):
where N is the number of pixels of each projection, and \(P_q\) and \(\hat{P}_q\) denote the pixel values of qth pixel in the scatter-corrected image \(\hat{\textbf{P}}\) and reference scatter-free image \(\textbf{P}\), respectively. The MAPE is equivalent to the average SPR for scatter-corrected images (i.e., the ratio of remaining scatter intensity to the primary intensity). Therefore, the more scatter components remain in \(\hat{\textbf{P}}\), the larger the MAPE is, while the better-corrected \(\hat{\textbf{P}}\) exhibits a lower MAPE.
For the pixel-level evaluation of scatter-corrected projections, we visualize the signed SPR of each pixel with a color map. The signed SPR is computed with \((\hat{P}_q - P_q) / | P_q |\) for each pixel q. On the other hand, for the voxel-level evaluation of a CT image, we apply a color map to the simple difference between the reference CT image and that reconstructed with scatter-corrected projections. Given that each voxel intensity represents the LAC of the material at that location, we opted not to normalize the CT value before applying the color map. We used the “cool-warm” color map to visualize errors on both projections and CT images, where zero difference appears as light gray, and positive and negative differences appear as reddish and bluish hues, respectively, as illustrated in Fig. 6.
We also evaluated the surface geometries extracted from CT images via isosurfacing. To visualize the deviations of surfaces extracted from each CT image, we used an “RGB” color map. In this map, zero difference appears as light green, while outward and inward surface displacements appear warm and cool colors, respectively, as in Figs. 9 and 10.
3.2 Ablation Study on Simulated Scans
For ablation studies, we used simulated scans of the engine cover, crankcase, and shisa figurine (see Fig. 5). As mentioned previously, the data of the shisa figurine were used for training the CNN, and those of the other two objects were used for evaluation. We simulated X-ray projections against these sample objects by setting the scanning geometry, tube voltage, and virtual materials, as shown in Table 1. Although we set aluminum as the virtual materials for all the objects in this experiment, the scanning geometry and tube voltages are varied intentionally to demonstrate robustness against the difference in these parameters.
The experiment with simulated scans evaluates the proposed method from two aspects. First, we assessed the accuracy of our deep learning framework using BHA-shadowed projections. To do this, we used a CAD model of the BHA to simulate scans with and without the BHA. We also computed scatter-free reference projections by ignoring X-ray scattering during photon transport simulation. Note that both sets of projections include beam-hardening effects, as we simulated with polychromatic X-ray generated by a tungsten target. Then, we compared the performance of two networks: one learning complete scatter-free projections and the other learning incomplete shadowed projections.
Furthermore, we evaluated the need for the loss terms in Eq. 9 and the radiographic data augmentation detailed in Sect. 2.3.1. To this end, we trained the CNN either by ablating the regularization losses (i.e., \(L_{\textrm{edge}}\), \(L_{\mathrm {TV- L1}}\), and \(L_{\mathrm {TV- L2}}\)) or by disabling the radiographic data augmentation (but image transformation is still performed). For brevity, we denote the method using fully visible projections and that using shadowed projections as FP and SP, respectively, with the suffices “-NoRL” and “-NoRDA” denoting the ablation of regularization losses or radiographic data augmentation, respectively.
Figure 6 shows that both FP and SP could reduce scatter artifacts in uncorrected projections in terms that the size of the colored areas decreases. Moreover, the results also show that the proposed components, i.e., the regularization losses and radiographic data augmentation, are effective for both FP and SP. In their results, the size of colored regions and the saturation of colors is decreased by introducing these components. The benefits of these components are also demonstrated quantitatively by Table 2, in which the MAPEs for CT images are compared. This table indicates that the MAPE is increased (i.e., the performance gets worse) when either the regularization losses or radiographic data augmentation is ablated. The parenthetical signed values show the performance decrease compared to the corresponding baseline method (i.e., either FP or SP) using both components. As these values indicate, the proposed components are particularly more effective when using only real projection data.

The scatter artifact correction results for the “titanium piece” sample. The results are compared using the CNNs trained with simulated fully visible projections (FP) and real shadowed projections (SP). The real projections are obtained by the first CT scanner (Phoenix V|tome|x C450). Each row shows a slice of the CT image and mesh models colored according to the amount of deviation (Color figure online)

The scatter artifact correction results for the “engine cover” sample. The results are compared using the CNNs trained with simulated fully visible projections (FP) and real shadowed projections (SP). The real projections are obtained by the first CT scanner (Phoenix V|tome|x C450). Each row shows a slice of the CT image and mesh models colored according to the amount of deviation (Color figure online)
To further investigate the impact of the proposed components, we plotted the MAPEs for each projection in Fig. 7. This figure compares the performances of FP/SP with those where either one of the proposed components is ablated. The results show that the MAPEs increase (i.e., get worse) for both the engine cover and crankcase, as indicated by the higher positions of the FP-NoRL and SP-NoRL curves compared to those of FP and SP, respectively. In contrast, as for the radiographic data augmentation, the overall positions of curves for FP-NoRDA and SP-NoRDA are lower than those for FP and SP, respectively. However, for some specific projections, the MAPEs of FP-NoRDA and SP-NoRDA are significantly higher than FP and SP. These projections, e.g., #780 for the engine cover and #270 for the crankcase, are those that include pixels with long X-ray penetration lengths. As seen in Fig. 8, these projections include nearly black pixels, representing long penetration lengths. For such pixels, radiographic data augmentation results in smaller SPRs, as evidenced by the fainter blue colors in the SPR visualization for FP and SP. These results suggest that the CNN may overfit to bright pixels, which are more numerous than dark pixels. As a result, the overall quality of CT images is not increased without radiographic data augmentation, as shown in Table 3 and Fig. 6. Thus, the radiographic data augmentation enhances the scatter correction for X-rays with long penetration lengths and improves the quality of reconstructed CT images.

3.3 Evaluation on Real Scans
The experiment for real scans uses three samples listed in Table 3, which are made of terra-cotta, titanium, aluminum, and iron. The experiment in this subsection uses the CT scanner, Phoenix V|tome|x C450, to obtain both the training and evaluation data. As with the previous experiment, we used the projections of the shisa figurine to train the CNN, while two other metal samples were used for evaluation. While the titanium piece is made of titanium, as its name indicates, the engine cover is made of aluminum and iron. The titanium piece is scanned with a different tube voltage from that used for the shisa figurine.
We evaluated the accuracy of scatter correction by comparing the surface geometry extracted from a CT image with reference data. The reference data for surface geometries are acquired with the GOM ATOS Core, a high-resolution optical range scanner. Depending on the object sizes, we scanned the titanium piece using the GOM ATOS Core 135 with \({0.05}\,\hbox {mm}\) resolution and the engine cover using the GOM ATOS Core 300 with \({0.12}\,\hbox {mm}\) resolution. Then, the output surface geometry is aligned with the reference using the GOM Inspect, commercial software for 3D shape inspection, to compute the surface deviation between them.
The performance of the proposed method is compared with a baseline method learning fully visible scatter-free projections given by simulation. For a fair comparison, the simulation to obtain the training data is performed for the shisa figurine. The virtual material is set as aluminum because its density is approximately the same as typical pottery. Other radiographic setups: the number of projections, image size, tube voltage, source-to-detector distance (SOD), and object-to-detector distance (ODD), are the same as those for the real scanning shown in Table 3. To clearly show whether the training data are synthesized by simulated or real scans, we denote FP and SP with suffixes, such as “-Simu” (i.e., trained with simulated scans) and “-Real” (i.e., trained with real scans). We also compare the proposed method with the built-in BHA-based scatter artifact correction (Built-in) of the CT scanner, Phoenix V|tome|x C450, which is provided by the manufacturer.
As shown in Figs. 9 and 10, the proposed method (SP-Real), which involves training the CNN with real scans, effectively corrects scatter artifacts. This efficiency is especially noticeable in the surface deviation visualization, where yellow and red areas (indicating outward surface deviation) shift closer to green (signifying zero deviation) by SP-Real in comparison with FP-Simu. Moreover, Fig. 11 presents histogram comparisons of surface deviations after scatter correction by each method, while Table 4 provides a quantitative statistical analysis of these deviations. This figure and table also show that our method exhibits consistently low average and standard deviations of surface deviations across different examples, which contrasts with the somewhat variable results from FP-Simu. Thus, even though the alternative approach (FP-Simu), which trains the CNN with simulated scans, uses fully visible and scatter-free projections, it has not significantly enhanced the quality of scatter correction.
Furthermore, the proposed method (SP-Real) demonstrated a comparable performance to the built-in method (Built-in), although it is not optimized for the specific CT scanner. Upon examination of the slices of CT images, the results of the built-in method are appealing due to their high contrast. However, the surface geometries extracted from the CT images are not as precise. For the titanium piece, the variation of the surface deviation is relatively minor, but the surface positions are slightly deviated outward from the reference. For the engine cover, the variation of the surface deviation is not insignificant, while the surface deviation is not as small as the proposed method. Overall, the results of the built-in method are not significantly accurate, given that it requires a BHA every time in the runtime process. In contrast, the proposed method does not require a BHA and is comparable in accuracy to the built-in method.
The results in Figs. 9 and 10 also show the capability of the proposed method to correct the projections captured with a different source voltage and scanning geometry. In this example, the CNN is trained with the projections of the shisa figurine captured with \({200}\,\hbox {kV}\) source voltage and a scanning geometry with SOD\(\,=\, {810}\,\hbox {mm}\) and ODD\(\,=\, {357}\,\hbox {mm}\). As shown in Table 3, these conditions differ from those used to capture the evaluation data of the titanium piece. Even with the inconsistency, the proposed method successfully corrected scatter artifacts to obtain a surface geometry closer to that given by the reference projections.
Additionally, we conducted a parameter study for the loss weights in Eq. 9 to examine the effects of loss terms on real scan data. In this experiment, the weight for each loss term was set to either zero or ten times its default value. The results are shown in Table 5. Adjusting the weights for \(L_{\textrm{grad}}\) and \(L_{\mathrm {TV- L1}}\) may result in suboptimal performance. In contrast, the behavior when changing \(L_{\mathrm {TV- L2}}\) is not as consistent. When the weight for \(L_{\mathrm {TV- L2}}\) is set to zero, the performance for the engine cover improves, while that for the titanium piece degrades. It can be seen that \(L_{\mathrm {TV- L2}}\) is somewhat important for the performance of the proposed method, yet the change in performance is not that significant. Therefore, the default parameters represent a reasonable choice, as they yielded the best performance for the titanium piece and the second-best performance for the engine cover.

Comparisons of scatter correction results using the CNNs trained with simulated and real projection data. The real projections for evaluation are obtained by the second CT scanner (Zeiss Metrotom 1500 G1), while those for training are obtained by the first CT scatter (Phoenix V|tome|x C450). Results in each row show a slice of the CT image and mesh models colored according to the amount of deviation (Color figure online)

Histogram comparisons of surface deviations for two examples: the titanium piece and the engine cover. The histograms corresponding to each object, which are depicted at the top and bottom of Fig. 12, are shown on the left and right, respectively
3.4 Evaluation on Scans of Another Device
The previous experiment showed that the properties of real and simulated scans are inevitably different; hence, training the network with real scans is advisable to correct another set of real scans. However, as the simulated and real scans differ, the scans using different CT scanners may also differ. Therefore, we conducted another experiment by capturing real evaluation scans using another CT scanner. Specifically, we scanned other sets of evaluation data using the Curl Zeiss Metrotom 1500 G1 with the scanning setup in Table 6. Even in this experiment, the training data for both SP and FP are the same as in the previous experiment.
The experimental results, presented in Fig. 12, demonstrate that the proposed method (SP-Real) effectively corrects data captured with the second CT scanner and outperforms FP-Simu, where the CNN is trained with simulated scans. Specifically, a CT image slice, depicted on the right of Fig. 12, clearly illustrates the superior performance of SP-Real. The white regions, indicative of scatter correction performance, are more apparent in the image corrected by SP-Real compared to FP-Simu. Furthermore, when comparing the surface geometries extracted from CT images, the results obtained by SP-Real exhibit fewer erroneous regions (highlighted in red and yellow) than those obtained by FP-Simu. Quantitative comparisons in Table 7 and the histograms in Fig. 13 corroborate this observation, indicating that SP-Real reduces the average surface deviation closer to zero compared to FP-Simu. The high scatter correction capability demonstrated by SP-Real is particularly noteworthy, given that most CT scanners, including the Zeiss Metrotom 1500 G1, lack specialized apparatus, such as the BHA, to mitigate scatter artifacts.
On the other hand, the results in Fig. 12 also show a limitation of the proposed method. As shown, the engine cover scanned with the Zeiss Metrotom 1500 G1 has several unexpected holes on the extracted surface geometry, as we highlighted with a red circle in Fig. 12. These holes are considered due to the insufficient resolution of the detector for low-energy photons. Unfortunately, the Zeiss Metrotom 1500 G1 cannot use the tube voltage beyond \({225}\,\hbox {kV}\), and we could not solve this problem by increasing the tube voltage. In such a case, the proposed method (i.e., SP-Real) and even FP-Simu cannot correct the inappropriate holes because they are not only due to scatter artifacts. This limitation is also shown in Table 7 as the large absolute values of minimum and maximum deviation. Although the proposed method (SP-Real) contributed to decreasing the mean of surface deviation as shown in Fig. 13, standards representing the variance of surface deviations (i.e., standard deviation and interquartile range) remain as large as those of FP-Simu. Thus, despite the high capability of scatter correction of the proposed method, we may need to use a sufficiently high tube voltage to get enough X-ray penetrations.

Cylinder head, an additional test sample for cross validation. Left: The picture of the object. Right: The surface mesh obtained by an optical scatter
3.5 Effect of Training Data
The choice of training data is an important factor to determine the quality of our deep-learning-based scatter correction method, while we trained the CNN using data obtained for shisa figurine in the previous experiments. To investigate the effect of training data for the quality of output geometries, we conducted cross validation using four experimental samples shown in Fig. 5. We also tested the importance of the variety of sample shapes in the training dataset, where the data from all four test samples were used for training and its quality is tested with another test sample, “Cylinder head,” which is made of titanium and iron. The picture and the surface mesh of the sample are shown in Fig. 14. In the same manner for the other test samples, the surface geometry obtained with scatter-corrected CT image was compared with the surface mesh captured with an commercial optical scatter.
The surface deviation for each sample is shown in Table 9. In this table, the labels in the first column shows the samples used to compose the training data, while the first row shows the samples used for evaluation. Since the sizes of the models are diverse, we presented the average surface deviation in units of percent rather than the length unit. The percentage denotes the ratio of the surface deviation to the diagonal length of the bounding box.
Table 9 gives us several insights on the training datasets. As we mentioned previously, the choice of the shisa figurine as the default training data is the best choice among the four. The engine cover can also be a good choice because it is composed of two materials, i.e., aluminum and iron, and offers the projection data containing more scatter components. In contrast of these two, the crankcase is made of aluminum, which is comparatively a light metal, and the titanium piece has a simple shape while titanium is comparatively a heavy metal. Because of the lightness of the material and the simplicity of the shape, the projection data obtained for these samples can be less challenging. Accordingly, the scatter correction qualities are significantly worse than those of the engine cover and shisa figurine.
Furthermore, when using all the four test samples to compose the training data, the surface deviation for Cylinder head could be corrected the best. However, the improvement over the results trained using the engine cover and shisa figurine data is insignificant. This means that the use of a set of projections obtained for a single object is practically sufficient when the object for that is carefully chose such that the projection data contains strong scatter components.
3.6 Limitations
As we have shown, the proposed deep learning framework using BHA-shadowed projections performs well for scatter artifact correction. However, it is important to note that the dependency on the BHA can also cause a limitation. The BHA has collimation holes with several millimeters of diameter, and the X-ray scattering spreading the beam narrower than this diameter is included in the BHA-shadowed projections. Therefore, it is possible that our method may not be able to fully remove scatter artifacts with a little beam spreading. Despite this fact, the proposed method could be a practical solution for scatter correction in industrial CT scanning, where the BHA is a powerful tool to mitigate scatter artifacts.
4 Conclusion
We introduced a novel CNN-based scatter correction technique that uses physically measured projections for training data. While it is impossible to obtain strictly scatter-free projections by real scanning, we exploited the BHA to mitigate scatter artifacts. Although the BHA shadows a large part of the detector pixels, we trained the neural network to predict the primary X-ray intensities at these shadowed locations. This was achieved by introducing several loss functions, which take into account the low-frequency nature of the scatter component on the 2D detector image. On the other hand, to overcome the time-consuming process of dual scanning with and without the BHA, we opted to train the CNN using only a single set of projections. To compensate for the reduced amount of original training data, we proposed radiographic data augmentation, a technique grounded in the physical X-ray properties.
The experiment part of this paper demonstrated the strong capability of the proposed method in correcting scatter artifacts. We found that the image properties of real and simulated scans were different, and the capability of scatter correction has been substantially improved by training the CNN with real projections. While the lower performance due to simulated scans might be resolved by collecting more training data, gathering a large amount of training data through highly accurate MC photon tracing is hardly feasible in practice. From our tests, the simulation software we used in the experiments took ten times longer to obtain a CT image than a real scanner. Therefore, data collection with a real scanner would be the more advisable approach, even if the data quantity is small.
Despite the high capability of scatter correction of the proposed method, there is still room for improvement in the data augmentation associated with the nature of X-rays. Currently, the proposed data augmentation only considers the variety of the LAC arising from different tube voltages and materials. This could be improved by considering other factors, such as the combination of multiple materials, the photon energy distribution of polychromatic X-rays, the ratio of scattering coefficient to absorption coefficient, and the specific sensitivity characteristics of the detector. In addition, correcting other types of artifacts, such as beam hardening, is another important research topic, since the image degradation due to such artifacts can be seen in part of Figs. 9, 10 and 12. However, we should also be aware of the potential increase in computation time that may result from an overemphasis on the physical plausibility of data augmentation. Thus, in the future, we would like to explore a more sophisticated data augmentation technique, achieving a good balance between accuracy and computational complexity.
Data Availability
No datasets were generated or analysed during the current study.
References
Carmignato, S., Dewulf, W., Leach, R. (eds.): Industrial X-Ray Computed Tomography. Springer, Switzerland (2018). https://doi.org/10.1007/978-3-319-59573-3
Feldkamp, L.A., Davis, L.C., Kress, J.W.: Practical cone-beam algorithm. J. Opt. Soc. Am. A 1(6), 612–619 (1984). https://doi.org/10.1364/josaa.1.000612
Lorensen, W.E., Cline, H.E.: Marching cubes: a high resolution 3D surface construction algorithm. In: Proceedings of the Annual Conference on Computer Graphics and Interactive Techniques, pp. 163–169. Association for Computing Machinery, New York (1987). https://doi.org/10.1145/37401.37422
Endo, M., Tsunoo, T., Nakamori, N., Yoshida, K.: Effect of scattered radiation on image noise in cone beam CT. Med. Phys. 28(4), 469–474 (2001). https://doi.org/10.1118/1.1357457
Bhatia, N., Tisseur, D., Buyens, F., Létang, J.M.: Scattering correction using continuously thickness-adapted kernels. NDT & E Int. 78, 52–60 (2016). https://doi.org/10.1016/j.ndteint.2015.11.004
Hsieh, J. (ed.): Computed Tomography: Principles, Design, Artifacts, and Recent Advances. SPIE Press, Bellingham (2015). https://doi.org/10.1117/3.2197756
Tkaczyk, J.E., Du, Y., Walter, D.J., Wu, X., Li, J., Toth, T.: Simulation of CT dose and contrast-to-noise as function of bowtie shape. In: Yaffe, M.J., Flynn, M.J. (eds.) Physics of Medical Imaging. SPIE, Bellingham (2004). https://doi.org/10.1117/12.535161
Kwan, A.L.C., Boone, J.M., Shah, N.: Evaluation of x-ray scatter properties in a dedicated cone-beam breast CT scanner. Med. Phys. 32(9), 2967–2975 (2005). https://doi.org/10.1118/1.1954908
Graham, S.A., Moseley, D.J., Siewerdsen, J.H., Jaffray, D.A.: Compensators for dose and scatter management in cone-beam computed tomography. Med. Phys. 34(7), 2691–2703 (2007). https://doi.org/10.1118/1.2740466
Mail, N., Moseley, D.J., Siewerdsen, J.H., Jaffray, D.A.: The influence of bowtie filtration on cone-beam CT image quality. Med. Phys. 36(1), 22–32 (2009). https://doi.org/10.1118/1.3017470
Liu, R., Zhang, S., Zhao, T., O’Sullivan, J.A., Williamson, J.F., Webb, T., Porras-Chaverri, M., Whiting, B.: Impact of bowtie filter and detector collimation on multislice CT scatter profiles: a simulation study. Med. Phys. 48(2), 852–870 (2020). https://doi.org/10.1002/mp.14652
Blessing, M., Bhagwat, M.S., Lyatskaya, Y., Bellon, J.R., Hesser, J., Zygmanski, P.: Kilovoltage beam model for flat panel imaging system with bow-tie filter for scatter prediction and correction. Physica Med. 28(2), 134–143 (2012). https://doi.org/10.1016/j.ejmp.2011.04.001
Persliden, J., Carlsson, G.A.: Scatter rejection by air gaps in diagnostic radiology. Calculations using a Monte Carlo collision density method and consideration of molecular interference in coherent scattering. Phys. Med. Biol. 42(1), 155–175 (1997). https://doi.org/10.1088/0031-9155/42/1/011
Zhu, L., Bennett, N.R., Fahrig, R.: Scatter correction method for X-ray CT using primary modulation: theory and preliminary results. IEEE Trans. Med. Imaging 25(12), 1573–1587 (2006). https://doi.org/10.1109/tmi.2006.884636
Alexeev, T., Kavanagh, B., Miften, M., Altunbas, C.: Two-dimensional antiscatter grid: a novel scatter rejection device for cone-beam computed tomography. Med. Phys. 45(2), 529–534 (2018). https://doi.org/10.1002/mp.12724
Ning, R., Tang, X., Conover, D.: X-ray scatter correction algorithm for cone beam CT imaging. Med. Phys. 31(5), 1195–1202 (2004). https://doi.org/10.1118/1.1711475
Peterzol, A., Létang, J.M., Babot, D.: A beam stop based correction procedure for high spatial frequency scatter in industrial cone-beam X-ray CT. Nucl. Instrum. Methods Phys. Res. Sect. B 266(18), 4042–4054 (2008). https://doi.org/10.1016/j.nimb.2008.07.005
Schörner, K., Goldammer, M., Stephan, J.: Comparison between beam-stop and beam-hole array scatter correction techniques for industrial X-ray cone-beam CT. Nucl. Instrum. Methods Phys. Res. Sect. B 269(3), 292–299 (2011). https://doi.org/10.1016/j.nimb.2010.11.053
Rührnschopf, E.P., Klingenbeck, K.: A general framework and review of scatter correction methods in x-ray cone-beam computerized tomography. Part 1: scatter compensation approaches. Med. Phys. 38(7), 4296–4311 (2011). https://doi.org/10.1118/1.3599033
Floyd, C.E., Jaszczak, R.J., Coleman, R.E.: Inverse Monte Carlo: a unified reconstruction algorithm for SPECT. IEEE Trans. Nucl. Sci. 32(1), 779–785 (1985). https://doi.org/10.1109/tns.1985.4336940
National Research Council of Canada. Metrology Research Centre. Ionizing Radiation Standards: EGSnrc: Software for Monte Carlo Simulation of Ionizing Radiation. National Research Council of Canada (2000). https://doi.org/10.4224/40001303
Bundesanstalt für Materialforschung und -prüfung (BAM): aRTist—analytical RT inspection simulation tool (2019). http://www.artist.bam.de/
Jarry, G., Graham, S.A., Moseley, D.J., Jaffray, D.J., Siewerdsen, J.H., Verhaegen, F.: Characterization of scattered radiation in kV CBCT images using Monte Carlo simulations. Med. Phys. 33(11), 4320–4329 (2006). https://doi.org/10.1118/1.2358324
Zbijewski, W., Beekman, F.J.: Efficient Monte Carlo based scatter artifact reduction in cone-beam micro-CT. IEEE Trans. Med. Imaging 25(7), 817–827 (2006). https://doi.org/10.1109/tmi.2006.872328
Poludniowski, G., Evans, P.M., Hansen, V.N., Webb, S.: An efficient Monte Carlo-based algorithm for scatter correction in keV cone-beam CT. Phys. Med. Biol. 54(12), 3847–3864 (2009). https://doi.org/10.1088/0031-9155/54/12/016
Rinkel, J., Gerfault, L., Estève, F., Dinten, J.-M.: A new method for x-ray scatter correction: first assessment on a cone-beam CT experimental setup. Phys. Med. Biol. 52(15), 4633–4652 (2007). https://doi.org/10.1088/0031-9155/52/15/018
Yao, W., Leszczynski, K.W.: An analytical approach to estimating the first order x-ray scatter in heterogeneous medium. Med. Phys. 36(7), 3145–3156 (2009). https://doi.org/10.1118/1.3152114
Swindell, W., Evans, P.M.: Scattered radiation in portal images: a Monte Carlo simulation and a simple physical model. Med. Phys. 23(1), 63–73 (1996). https://doi.org/10.1118/1.597792
Hansen, V.N., Swindell, W., Evans, P.M.: Extraction of primary signal from EPIDs using only forward convolution. Med. Phys. 24(9), 1477–1484 (1997). https://doi.org/10.1118/1.598036
Ohnesorge, B., Flohr, T., Klingenbeck-Regn, K.: Efficient object scatter correction algorithm for third and fourth generation CT scanners. Eur. Radiol. 9(3), 563–569 (1999)
Star-Lack, J., Sun, M., Kaestner, A., Hassanein, R., Virshup, G., Berkus, T., Oelhafen, M.: Efficient scatter correction using asymmetric kernels. In: Samei, E., Hsieh, J. (eds.) Physics of Medical Imaging. SPIE, Bellingham, WA, USA (2009). https://doi.org/10.1117/12.811578
Sun, M., Star-Lack, J.M.: Improved scatter correction using adaptive scatter kernel superposition. Phys. Med. Biol. 55(22), 6695–6720 (2010). https://doi.org/10.1088/0031-9155/55/22/007
Meyer, M., Kalender, W.A., Kyriakou, Y.: A fast and pragmatic approach for scatter correction in flat-detector CT using elliptic modeling and iterative optimization. Phys. Med. Biol. 55(1), 99–120 (2009). https://doi.org/10.1088/0031-9155/55/1/007
Lo, J.Y., Floyd, C.E., Baker, J.A., Ravin, C.E.: An artificial neural network for estimating scatter exposures in portable chest radiography. Med. Phys. 20(4), 965–973 (1993). https://doi.org/10.1118/1.596978
Hansen, D.C., Landry, G., Kamp, F., Li, M., Belka, C., Parodi, K., Kurz, C.: Scatternet: a convolutional neural network for cone-beam CT intensity correction. Med. Phys. 45(11), 4916–4926 (2018). https://doi.org/10.1002/mp.13175
Lee, H., Lee, J.: A deep learning-based scatter correction of simulated X-ray images. Electronics 8(9), 944 (2019). https://doi.org/10.3390/electronics8090944
Maier, J., Sawall, S., Knaup, M., Kachelrieß, M.: Deep scatter estimation (DSE): accurate real-time scatter estimation for X-ray CT using a deep convolutional neural network. J. Nondestr. Eval. 37(3), 57 (2018). https://doi.org/10.1007/s10921-018-0507-z
Maier, J., Eulig, E., Vöth, T., Knaup, M., Kuntz, J., Sawall, S., Kachelrieß, M.: Real-time scatter estimation for medical CT using the deep scatter estimation: method and robustness analysis with respect to different anatomies, dose levels, tube voltages, and data truncation. Med. Phys. 46(1), 238–249 (2018). https://doi.org/10.1002/mp.13274
Nomura, Y., Xu, Q., Shirato, H., Shimizu, S., Xing, L.: Projection-domain scatter correction for cone beam computed tomography using a residual convolutional neural network. Med. Phys. 46(7), 3142–3155 (2019). https://doi.org/10.1002/mp.13583
Jiang, Y., Yang, C., Yang, P., Hu, X., Luo, C., Xue, Y., Xu, L., Hu, X., Zhang, L., Wang, J., Sheng, K., Niu, T.: Scatter correction of cone-beam CT using a deep residual convolution neural network (DRCNN). Phys. Med. Biol. 64(14), 145003 (2019). https://doi.org/10.1088/1361-6560/ab23a6
Berker, Y., Maier, J., Kachelries, M.: Deep scatter estimation in PET: fast scatter correction using a convolutional neural network. In: IEEE Nuclear Science Symposium and Medical Imaging Conference Proceedings (NSS/MIC). IEEE, New York, NY, USA (2018). https://doi.org/10.1109/nssmic.2018.8824594
Alsaffar, A., KießS, Sun, K., Simon, S.: Computational scatter correction in near real-time with a fast Monte Carlo photon transport model for high-resolution flat-panel CT. J. Real-Time Image Proc. 19(6), 1063–1079 (2022). https://doi.org/10.1007/s11554-022-01247-7
Dremel, K., Fuchs, T.: Scatter simulation and correction in computed tomography: a reconstruction-integrated approach modelling the forward projection. NDT & E Int. 86, 132–139 (2017). https://doi.org/10.1016/j.ndteint.2016.12.002
Wang, A., Maslowski, A., Wareing, T., Star-Lack, J., Schmidt, T.G.: A fast, linear Boltzmann transport equation solver for computed tomography dose calculation (Acuros CTD). Med. Phys. 46(2), 925–933 (2018). https://doi.org/10.1002/mp.13305
Principi, S., Wang, A., Maslowski, A., Wareing, T., Jordan, P., Schmidt, T.G.: Deterministic linear Boltzmann transport equation solver for patient-specific CT dose estimation: comparison against a Monte Carlo benchmark for realistic scanner configurations and patient models. Med. Phys. 47(12), 6470–6483 (2020). https://doi.org/10.1002/mp.14494
Baldi, P.: Autoencoders, unsupervised learning, and deep architectures. In: Proceedings of ICML Workshop on Unsupervised and Transfer Learning, pp. 37–49 (2012). JMLR Workshop and Conference Proceedings
Ronneberger, O., Fischer, P., Brox, T.: U-NET: convolutional networks for biomedical image segmentation. In: Proceedings of the International Conference on Medical Image Computing and Computer-assisted Intervention, pp. 234–241 (2015). Springer, Berlin
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: PyTorch: an imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems, pp. 8024–8035 (2019)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2014). arXiv:1412.6980
Funding
This study is supported by Japan Society for the Promotion of Science, Grant-in-Aid (JP24K00783). This study is also supported by the Isotope Science Center of the University of Tokyo.
Author information
Authors and Affiliations
Contributions
H.H worked on the computer implementation and experimental validation of the proposed method, T.Y worked on the conceptualization of this study and computer implementation. Y.O and H.S supervised the overall progress of this study. T.Y wrote the manuscript, and all the authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known Conflict of interest or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hattori, H., Yatagawa, T., Ohtake, Y. et al. Learning Scatter Artifact Correction in Cone-Beam X-Ray CT Using Incomplete Projections with Beam Hole Array. J Nondestruct Eval 43, 99 (2024). https://doi.org/10.1007/s10921-024-01113-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10921-024-01113-5