
Abstract
Buildings that are constructed without the necessary permits and building inspections affect many areas, including safety, health, the environment, social order, and the economy. For this reason, it is essential to determine the number of buildings and their boundaries. Determining the boundaries of a building based solely on its location in the world is a challenging task. In the context of this research, a new approach, BBD, is proposed to detect architectural objects from large-scale satellite imagery, which is an application of remote sensing, together with the geolocations of buildings and their boundaries on the Earth. In the proposed BBD method, open-source GeoServer and TileCache software process huge volumes of satellite imagery that cannot be analyzed with classical data processing techniques using deep learning models. In the proposed BBD method, YOLOv5, DETR, and YOLO-NAS models were used for building detection. SAM was used for the segmentation process in the BBD technique. In addition, the performance of the RefineNet model was investigated, as it performs direct building segmentation, unlike the aforementioned methods. The YOLOV5, DETR and YOLO-NAS models in BBD for building detection obtained an f1 score of 0.744, 0.615, and 0.869 respectively on the images generated by the classic TileCache. However, the RefineNet model, which uses the data generated by the classic TileCache, achieved an f1 score of 0.826 in the building segmentation process. Since the images produced by the classic TileCache are divided into too many parts, the buildings cannot be found as a whole in the images. To overcome these problems, a fine-tuning based optimization was performed. Thanks to the proposed fine-tuning, the modified YOLOv5, DETR, YOLO-NAS, and RefineNet models achieved F1 scores of 0.883, 0.772, 0.975 and 0.932, respectively. In the proposed BBD approach, the modified YOLO-NAS approach was the approach that detected the highest number of objects with an F1 score of 0.975. The YOLO-NAS-SAM approach detected the boundaries of the buildings with high performance by obtaining an IoU value of 0.912.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Illegal buildings or buildings that exceed their limits are often built in violation of local building and zoning regulations [1, 2]. These buildings often pose safety risks. As these buildings are not constructed according to proper engineering calculations or their structural integrity is not ensured, precautions should be taken before natural disasters such as earthquakes occur. Because these types of buildings often do not comply with local codes, they can be structurally unsafe and present a variety of hazards. These hazards may include structural weaknesses, fire hazards, and environmental damage. The existence of illegal buildings can therefore endanger human life and the environment, and urgent action may be required. In particular, natural disasters such as earthquakes can severely test the structural integrity of these buildings and cause them to collapse. It is therefore essential to implement effective policies and practices to reduce the number of illegal buildings and to make existing ones safe. To do this, it is necessary to identify buildings and building boundaries and to determine which buildings have been constructed without complying with building regulations. However, to determine building boundaries [3,4,5], it is almost impossible to constantly check all building boundaries by having teams measure on site. On the other hand, remote sensing technologies and application images have recently been analysed [6,7,8,9,10,11,12,13,14]. However, because satellite images are large in size, they fall into the category of comprehensive data about the area they cover [15, 16]. By 2028, remote sensing technology is expected to capture images at a rate of 160 terabytes per second [17]. These big data images are difficult to analyse using traditional methods.
Innovative solutions are utilized to rapidly process huge volumes of images and provide quick access to users. For instance, platforms like Mapbox divide huge volumes of images into smaller and manageable chunks for this purpose [18]. The breaking up of a huge size of satellite image into small pieces is called a tile [19]. Tile process refers to saving huge size satellite imagery in z/x/y format by dividing them into parts. ’z’ represents what level the image is at, and ’x’ and ’y’ denote the image’s position on the X and Y axes [20]. Small images are usually produced and saved at 256x256. When the client wants to access the image in a region, it is quite time-consuming to process the huge size image with conventional methods and present the desired region. In the Tile system, users are able to access quickly and effectively since small-size images at the relevant location are pre-created [21].
In recent times, deep learning models have been widely used in classification, object detection and segmentation processes, popular topics in computer vision [22, 23]. Classification is a process that employs deep learning methods to assign an input dataset to a specific category or class. For instance, Khalid et al. [24] employed a deep learning approach to categorize plants’ diseases. Object detection is the process of detecting the positions and classes of specific objects within an image. This method is used to recognize and classify different objects in an image and determine their location. Segmentation is a process that divides an image into smaller pieces (segments) and classifies each segment as a separate object or region [25, 26]. This method allows the objects in the image to be analyzed by separating them into their pixels. In object detection, the object is detected together with the bounding box containing it. In the segmentation process, precise boundaries are used in the polygon format surrounding the object while classifying the object.
Identifying building objects and their boundaries is a classification problem that falls within the field of computer vision [27, 28]. In the literature, there have been several studies on building detection and segmentation with a deep learning model [29,30,31,32]. In the context of this research, a new hybrid method called BBD has been proposed for the detection of architectural structures and boundaries together with their geolocations from huge size satellite imagery. Classical deep learning models cannot process huge size satellite imagery that take up to 21 gigabytes in compressed form. In the proposed BBD approach, these images were converted into small-volume coordinated images using the open-source strategy GeoServer and TileCache software [33] so that deep learning techniques could process these images. Classical segmentation methods also segment the objects on the building or identify the building by dividing it into parts. In the proposed BBD method, a new technique based on the detection of the building first and then the detection of the polygon boundaries of the building has been developed in order to determine only the building and building boundaries. For building object detection, the YOLOv5 [34], DETR [35] and YOLO-NAS [36] models, which have recently come to the fore with their high performance in object detection, have been employed. SAM [37] trained with more than one billion image masks was used for the segmentation process. In addition, the performance of the direct building segmentation process RefineNet model [38] was also examined to see what the result would be if the building segmentation process was carried out contrary to the proposed study. The main features of the proposed BBD approach are presented below.
1.1 Contributions
-
A new method, called BBD, has been proposed for the detection of architectural structures, their boundaries and geolocations from large satellite images.
-
A two-stage method has been proposed for building boundary detection, first building detection and then building polygon boundary detection. This ensured that the building boundaries were more clearly defined.
-
In order to improve the object detection performance of the proposed BBD method, a fine-tuning based optimization has been performed. Thanks to this improvement, the F1 score performance of the deep learning models in building detection has been increased by at least 10%.
1.2 Scope and outline
-
The aim of this study is to determine the area of buildings on a pixel basis. The area of buildings based on metres is outside the scope of this study.
The following organisation is maintained throughout the rest of this paper: An overview of the relevant literature is given in Section 2. The basic concepts are explained in Section 3. The proposed approach is detailed in Section 4. Section 5 describes the experimental evaluations that have been carried out. Finally, Section 6 outlines the conclusions and future directions.
2 Related work
Detection of building objects with deep learning models from satellite imagery has been examined by dividing them into two categories. First, object detection-based deep learning models are presented, then the studies on building object detection and segmentation with deep learning models are discussed.
Object detection with deep learning models automatically detects objects located in images or videos [39,40,41]. This type of detection helps the computer to understand images like a human and identify the objects they contain. The development of object detection-based deep learning models has progressed quite rapidly. In 2014, Girshick et al. [42] proposed the R-CNN model to detect objects in an image with multiple objects. R-CNN includes different processing steps to identify and classify the object regions. The selective Search algorithm is used for regions suggestion. In 2015, the Fast R-CNN model was proposed by Ross Girshick to increase the speed of the R-CNN model [43]. In addition, the Faster R-CNN model, which works faster than other R-CNN models, was introduced by Ren et al. [44] in 2015. In 2016, Redmon et al. introduced the YOLO architecture [45]. YOLO detects the objects in a single network stream. Instead of analyzing the image at several scales, it performs simultaneous object detection. It has been further developed with iterations such as YOLOv2, YOLOv3, YOLOv4, and recently known as YOLOv8 [46]. In 2016, Liu et al. [47] proposed the SSD model capable of detecting objects of different scales in a single network stream. In 2017, He et al. proposed the [48] Mask R-CNN model. This model precisely determines not only the position of objects but also their shape. DETR model was proposed by Carion et al. [35] in 2020. DETR performs object detection using a transformer architecture instead of traditional object-based methods.
When the studies on building object detection are examined, Ma et al. [49] suggested using the YOLOv3 model to detect collapsed buildings from remote sensing images after the earthquake. With the YOLOv3 model, they achieved a 0.904 f1 score performance in building object detection. However, in the study, only determining whether the building object exists and building segmentation is not performed. Liu et al. [50] proposed a three-step approach for building change detection from remotely acquired images. With the method they named DTCDSCN, they achieved an f1 score of 0.890 in building segmentation. However, despite the segmentation process in the study, huge volume images are not processed. Gao et al. [51] proposed a new method, which was named YOLO-S-CIOU, to detect private buildings in remotely sensed images. Although they obtain an f1 score of 0.975 with the proposed YOLO-S-CIOU method, they do not process huge size satellite imagery and do not perform segmentation. Han et al. [30] have obtained a new Mask R-CNN based method for building segmentation from remotely sensed images. However, although they performed segmentation with their proposed Mask R-CNN-based method, they could only achieve 0.818 accuracy. Chen et al. [52] proposed a new approach for building detection from high-resolution satellite imagery. With their proposed Res2-Unet approach, they obtained a f1 score 0.906 in building segmentation. However, despite performing segmentation, they did not determine the real geolocations of the detected buildings in the world. Tasyurek et al. [53] proposed a new approach called DSHFS on using CNN-based deep learning and GIS applications in house object detection from satellite imagery. However, they only performed object detection in their proposed approaches. They only used CNN-based deep learning models, in other words, they did not examine the transformer-based object detection method. They used YOLOv4 version, which is an older version of YOLO versions, as the CNN model. Additionally, their proposed approach did not make any improvements to segmentation.
Table 1 summarizes the studies on building detection from satellite images in a comparative manner. The results indicate that building detection from satellite images can be achieved with high accuracy rates when IoU and F1 score metrics are examined. However, the actual geolocation of the detected buildings in the world has not been calculated. Therefore, there is a need to identify buildings together with their real spatial locations in the world. To achieve higher classification performance rates, it is recommended to use techniques such as fine-tuning and hybrid approaches in the proposed methods.
Although there are studies in the literature on building object detection and segmentation from remote satellite imagery, there is a need for new approaches that can segment buildings from huge size satellite imagery with a high success rate. However, to the best of our knowledge, there is currently no technique capable of segmenting buildings along with their precise geographic coordinates from extensive satellite imagery that cannot be processed by conventional computers. In the context of this research, a new technique called BBD, which uses different disciplines together, is proposed to segment buildings from huge size satellite imagery along with their actual locations on Earth. In the proposed BBD method, fine-tuning based improvement has been applied to make the building objects appear as a whole and to increase the detection achievement of methods. GeoServer and TileCache software, widely used and free software in the field of maps, were employed to process huge size satellite imagery by the classical computer. YOLOv5, DETR and YOLO-NAS models, which have been widely performed recently, have been utilized for the detection of architectural structures from satellite imagery. The SAM method, trained with a dataset containing more than 1 billion images, was used to segment the buildings detected by deep learning models with a high success rate.Furthermore, in contrast to the proposed work, we also evaluated the RefineNet model’s performance in direct building segmentation.
3 Basic concept
In the BBD method proposed in the context of this research, open-source GeoServer and TileCache software were employed to make huge size satellite imagery that deep learning models can process. For this reason, in this section, primarily GeoServer and TileCache software are presented. YOLO and DETR, well-known deep learning models, have recently been utilized for the detection of architectural structures in the satellite image. Therefore, YOLO and DETR models are presented in this section as well. In order to find the boundaries of the detected building object, the SAM model, the popular boundary detection model of recent times, was performed. Finally, SAM is introduced in this section.
3.1 GeoServer
GeoServer is an open-source geographic information system software for serving, sharing and managing geographic data and maps [62]. GeoServer allows broadcasting geospatial data from the specified internet address via standard geoweb services. GeoServer allows users to present their geometric data and satellite imagery and access this data remotely. GeoServer works as a Java-based application server and supports a wide range of geographic data formats, allowing you to integrate different data sources and process various types of geographic data. GeoServer supports standard geographic web services such as WMS (Web Map Service), WFS (Web Feature Service), and WCS (Web Coverage Service) [63]. These services allow geographic data to be shared over the internet and integrated into different map and geographic information applications. GeoServer is open source, allowing developers and geospatial data experts to build customized geographic information systems and enhance existing applications.
3.2 TileCache
TileCache is an open-source geodata caching tool that serves geospatial data quickly and efficiently [64]. TileCache is developed by MetaCarta and is free. TileCache has been designed to help users deliver geographic data faster and with lower network traffic, especially in mapping applications and geographic information systems [20, 65]. TileCache divides geodata into small pre-computed "tiles" and caches these tiles, providing faster responses to repetitive requests. TileCache is an essential tool for applications where geographic data needs to be served quickly. Data access speed and data transfer optimization provided by TileCache can provide significant advantages in map services, geospatial analysis applications, location-based services and other geospatial data usage scenarios [66]. TileCache saves the data it receives as WMS to disk as an image in z/x/y.jpg format [67]. ’z’ refers to the magnification level, ’x’ refers to the position of the image on the x-axis at the z level, and ’y’ refers to the part of the image on the y-axis at the z level. Thanks to TileCache, while the data in WMS format is saved as an image, the geolocation of the image on the world is also recorded. In this way, when an image of a point is desired to be obtained, the image recorded for that point is taken directly by TileCache. Very high performance is achieved in the TileCahe system as a tiny image is presented without any query [68].
3.3 YOLO
The nomenclature "YOLO" is derived from the acronym "You Only Look Once," signifying a singular visual assessment [45]. This methodology enables swift and comprehensive predictions concerning the objects depicted within an image, along with their precise spatial coordinates [69]. Object detection is a computer vision problem that falls specifically into discovering what objects are in a given image and where they are in the image. Object detection is a more complex and challenging problem than image classification problems since it also finds where the object is in the image. Utilizing the YOLO methodology often yields a high degree of accuracy while maintaining real-time functionality, a feature that has gained significant traction in recent times due to its remarkable capabilities [70]. This approach essentially involves a singular pass of forward propagation through the neural network to make predictions, earning its name from the concept of "looking only once" at the image. Following a procedure known as non-maximum suppression, which ensures each object is detected only once, the algorithm proceeds to provide outputs containing recognized objects alongside their corresponding bounding boxes. One of YOLO’s distinguishing features lies in its ability to predict multiple bounding boxes and their associated class probabilities concurrently through a solitary CNN. Additionally, YOLO is adept at processing entire images and directly enhancing detection performance.
The YOLO methodology has undergone continuous development over time. The initial version, YOLOv1, was introduced by Redmon et al. in 2016 [45]. This version featured a fully connected output layer, and during testing, the YOLO training model only supported input resolutions identical to the training images. To address the limitations of YOLOv1 and build upon its success, a more precise, faster, and potent architecture called YOLOv2 was presented by Redmon et al. in 2017, capable of recognizing 9,000 objects [71]. In 2018, Redmon et al. further advanced the field with YOLOv3, a more intricate model compared to its predecessors. The YOLOv3 architecture allows for dynamic adjustments to its structure, enabling modifications to speed and accuracy. In 2020, Bochkovskiy et al. introduced YOLOv4 as an optimal solution for speed and accuracy in object recognition [72]. Another notable contribution in 2020 was the YOLOv5 model developed by Jocher [34], which unlike its predecessor (V4), is implemented in PyTorch. Studies have indicated that the YOLOv5 model yields superior estimations with reduced computational costs compared to the V4 model [73, 74]. Unlike earlier YOLO versions that were primarily coded in C, YOLOv5 was developed using the Python programming language. This shift facilitated easier installation and integration of YOLOv5 into IoT devices. Notably, YOLOv5 is considerably smaller in size, approximately 27 MB, compared to YOLOv4 which utilizes Darknet and occupies 244 MB. Due to these compelling attributes, the V5 model was also selected for implementation in the present study.
YOLO-NAS is the new object detection model that provides superior real-time processing capabilities and production-ready achievement, a game-changer in the object detection realm [36, 75]. YOLO-NAS is a method used to optimize or search the neural network structure of the YOLO model. Such approaches seek to automate human-made processes for designing or tuning deep learning models. Specifically, YOLO-NAS aims to achieve better performance by automatically determining the object detection model’s layers, blocks, filters and other structural components. YOLO-NAS methods aim to make the development and improvement of object detection models more efficient and effective. Such approaches can explore a larger architectural search space and optimize the model structure for better results than human trial and error methods. Experimental evaluations YOLO-NAS model outperforms YOLOv6 and YOLOv8 [76]. For this reason, the YOLO-NAS model was employed as a building object detection model in the context of this research.
3.4 DETR
Detection with Transformers (DETR) is an artificial intelligence model used in object detection. Unlike traditional object detection methods, this model uses a transformation-based approach [35]. Ever since the introduction of the transformers network by the Facebook team, its primary application and success have been observed predominantly in the realm of natural language processing [77]. However, researchers have been progressively exploring the potential of transformers in the context of image processing, aiming for a deeper comprehension of image data [78].
Scholars who have been captivated by the promising performance of transformers have conducted studies that exhibit remarkable achievements in image detection tasks [79,80,81]. As an emerging architecture in the field of computer vision, transformers have been harnessed for diverse tasks such as image classification , target detection, and segmentation , capitalizing on their robust feature extraction capabilities [82, 83]. Notably, the DETR architecture [35] emerges as an open-source framework that pioneers the application of transformers in the domain of object detection. The core principle underlying DETR is to reframe the detection process as a prediction set issue and employ attribute sets for forecasting bounding box sets, thereby achieving precise end-to-end detection operations even with limited prior information. The network architecture of DETR is both straightforward and intuitive. The integration of transformers is strategically positioned to assimilate substantial semantic information through pixel-level attention mechanisms. Consequently, the extraction of target positional data is confined to the sinusoidal encoding of the ultimate layer of attribute maps. Due to the utilization of single-scale location information, the pursuit of accuracy becomes more compelling during the prediction-based object detection process.
As DETR has gained extensive popularity in contemporary times for tasks like image classification and object detection, it has also been used for building detection in the context of this research.
3.5 SAM
Meta Research introduced SAM in April 2023 [37]. SAM is an image segmentation model trained using a new dataset. SAM is trained with a dataset containing over one billion image masks and 11 million images. SAM draws a segmentation mask for all objects the model can find in an image. Segmentation masks, on the other hand, are the process of drawing a detailed outline by following the exact shape of the object. SAM which provides a powerful and versatile solution for image object segmentation, allows to enhance datasets with segmentation masks. SAM works in two ways [84]. In the first working principle, if the entire image is presented as an input, it performs segmentation for all the objects it can find in the image. However, since it defines all the detail points in this case, it also perceives an area with a different colour within the targeted polygon as a different object [85]. On the other hand, if the SAM model wants to detect the most abundant object in an area, not the entire image, then it segments a single object in that area. In this case, even if two objects are in the image, the object with the highest area is segmented.
Object detection-based deep learning models detect the object with bounding boxes around it. This detected bounding box gives information about the object. However, they do not provide information about the exact shape of the object and the area it occupies. In the context of this research, the achievement of the SAM model trained with a vast dataset to detect the exact shape and area of building objects was investigated.
4 Proposed hybrid method for geospatial building boundary detection from huge size satellite imagery
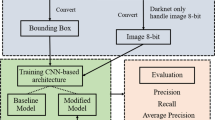
The polygonal boundary of a building represents the area covered by the building. This limit is critical for regulating personal and commercial use. In addition, this boundary plays a decisive role in the construction process and architectural planning. In order to calculate the distances of the buildings to each other, the building boundaries must be known. Detection of building boundaries is critical in preventing illegal construction and minimizing the damage that may occur in disasters such as earthquakes. On the other hand, it is difficult to determine and update the building boundaries, especially in areas where construction is common, as new buildings are constantly being built. However, in recent times, remote sensing technologies have been used to obtain huge size satellite imagery and analyze on these images. However, since these images cover a large area in computer systems, they are challenging to process with classical data processing methods. In the context of this research, a new technique called BBD (buildings boundary detection) is proposed for detecting building polygon boundaries from huge size satellite imagery. The architecture of the proposed method is presented in Fig. 1.

System architect of proposed BBD method
As presented in Fig. 1, a huge size of satellite imagery is provided as input to the proposed system. The compressed satellite image in the context of this research takes up 21 gigabytes of space for computer systems.Converting a 21GB compressed satellite image to a normal jpeg format results in a file size of approximately 160GB. Processing an image of this size requires a computer with at least 160GB of RAM, a high-end CPU, and a large amount of disk space. These requirements exceed those of a normal computer. Therefore, this image cannot be processed by classical data processing methods. Since it cannot be processed using classical data processing methods, deep learning models cannot detect house objects in the satellite image. It has been proposed to convert the satellite image into small images with GeoServer and TileCache software, which have an open source strategy, in order to process huge size satellite imagery by deep learning methods and to detect objects. The flow chart of the pre-processing applied with GeoServer and TileCacye software in order to process huge volumes of satellite imagery by deep learning methods is presented in Fig. 2.

Processing huge volumes of satellite imagery for readable by deep learning
As presented in Fig. 2, the huge size satellite image is divided into small pieces at each magnification level. In order to make huge size satellite imagery processable by deep learning, it is first added to GeoServer as a new data source. GeoServer [62] is a freeware that can store satellite imagery and publish them as WMS. Thanks to GeoServer, a satellite image that is difficult to access and read by conventional computers can be accessed online in WMS format. However, achievement loss occurs when GeoServer continuously broadcasts WMS. It is common in cartography systems to render the same data once and save it to disk instead of repeatedly generating the same data. In the context of this research, it is proposed to use TileCache software to save satellite imagery broadcast as WMS by GeoServer to disk in small pieces. TileCache [64] is a tile system used to improve achievement in geographic information systems. TileCache sequentially saves data published as WMS to computer disks. TileCache returns the data it has saved sequentially, or in other words, according to its coordinates, when requested again, according to its coordinates. As shown in Fig. 2, the image increases by 4 times at each magnification level. In other words, while the image appears from very far away at the first magnification level, the image appears closer at the second magnification level. Objects in the previous image are brought closer. Therefore, at each magnification level, the number of images increases four times the previous magnification level. While these images with geolocation information are recorded on computer disks, each zoom is recorded with the z, x and y values corresponding to the latitude and longitude information, as presented in Algorithm 1 [86] The recorded image is saved in z/x/y.jpg coordinate. The fetch or read operation reads the small data in the directory. The TileCache process performs well because it presents small images in response to requests and does not take any action. Classic Tilecache software creates 256x256 images. With the GeoServer and TileCache system, the compressed image that occupies at least 21 gigabytes and cannot be processed by classical data processing methods becomes operable. In this way, it transforms into images that can be processed at the kilobyte level.

Get x and y for tile(z,long,lat).
In the context of this research, YOLOv5, DETR and YOLO-NAS models, widely used in recent times, were used as object detection-based deep learning models for detecting building objects. The bounding box values \(x_1\), \(y_1\), \(x_2\) and \(y_2\) of the building object detected by the deep learning models are presented as input to the SAM model. The SAM model takes the whole picture as input and draws the boundaries of the objects it can detect in the picture. In this case, it separately detects roofs, chimneys or similar areas in buildings. In this way, the exact determination of the building boundary and area becomes impossible due to separate detections. To overcome these problems and to determine the building boundary exactly, the bounding box values are provided as input, which allows the SAM model to perform a single segmentation operation. In this way, since the SAM focuses on a single object within the determined area and draws the polygon boundary of that object only, the building is determined as a whole and clearly.
Images at the 18th level (z=18) were examined to obtain high achievement in detecting buildings and building boundaries. The pseudo-code for the number of images produced by the classic TileCache configuration at a magnification level is presented in Algorithm 2 [86]. However, deep learning methods cannot make detections sufficiently successful in building object detection since the images formed by the classical TileCache in 256x256 dimensions are divided too much. In the context of this research, a fine-tuning-based improvement was made to increase the object detection achievement of deep learning models. With the progress made, the parameters of the TileCache software were changed, and it was provided to produce images with a size of 512x512. The pseudo-code for the number of images produced by the proposed TileCache with fine-tuning-based configuration at a magnification level is presented in Algorithm 3. Since the proposed fine-tuned TileCache model produces \(512\times 512\) images (the merge of 4 different \(256\times 256\) images), it produces one-fourth of the image of the classical TileCache model, as seen in Algorithm 3.

Total of classic tiles(z).

Total of proposed tiles(z).
One of the most important features of the BBD technique proposed in the context of this study is that it detects building boundaries together with their real locations in the world. The location (z/x/y.jpeg) values of the image presented as input to the proposed BBD technique on the disk are known. Using the x, y and z values in this directory information, the spatial position of this image on the world is calculated using Algorithm 4 [87].

Get latitude and longitude of tile(x,y,z).
In the proposed BBD technique, building objects in the input image are detected along with their boundaries. Since the position of the input image is calculated with Algorithm 4,the geographical location of the detected building boundaries on the world is also automatically calculated. The achievement of the proposed BBD technique is examined in detail in the experiments section.
5 Experimental evaluation
In this section, the achievement of the proposed BBD methods for the detection of building polygon boundaries from huge size satellite imagery is examined. The proposed BBD approach consists of first determining the bounding box of the building object and then determining the building boundary within this bounding box. To assess the effectiveness of the suggested BBD method, the following questions were sequentially addressed.
-
What is the building object detection achievement of approaches?
-
What is the disk and computational cost of approaches?
-
What is the building polygon boundary detection achievement of approaches? and the geolocation of buildings?
-
What is the geographical location of the building boundaries determined by the approaches?
5.1 Dataset, metrics and model configuration
In the context of this research, a huge size satellite image that takes up 21 gigabytes of space in ECW format, which was taken from Kayseri Metropolitan Municipality, was used. For the huge size satellite image to be processed by deep learning methods, it was initially released in WMS format through GeoServer. Then, the data published in this WMS format were processed by TileCache and saved to the disk system as small-size images in z/x/y.jpeg format. The values of the hyper-parameters of the classical TileCache and the proposed fine-tuned based TileCache models used in the context of this research are presented in Table 2.
As seen in the Table 2, the classic TileCache model produces images with dimensions of 256x256, while the proposed fine-tuned based TileCache model produces images with dimensions of \(512\times 512\). The \(512\times 512\) image consists of four different \(256\times 256\) images. For this reason, the number of images in the proposed TileCache model is one quarter of the number of images in the classical TileCache model. As presented in Table 2, when the number of images in the 18 levels of the classic TileCache software is calculated using the Algorithm 2, there have been 273760 images. On the other hand, for the proposed fine-tuned TileCache model, the number of images at 18 magnification levels has been 68440 images when calculated using Algorithm 3. Approaches using the proposed TileCache model operate on much fewer images. In the context of this study, the data of the 18th layer (\(z=18\)) of the satellite image was used. This data, published by KMM as an open data set, is also accessible at tile.kayseri.bel.tr/tilecache/Cache/2020UYDU3857/z/x/y.jpeg. When \(z=18\), \(x=156930\) and \(y=100143\) values are entered, the resulting image is presented in Fig. 3.

Tile image (\(z=18\), \(x=156930\) ve \(y=100443\))
The tile image presented in Fig. 3 occupies 12.1 kilobytes of space on the computer disk system. In the context of this study, huge size application images that classical computers cannot process were converted into small-volume images with GeoServer and TileCache software with open source strategy. This way, deep learning models can process huge volumes of satellite imagery. Evaluation of training and test achievement of deep learning methods is done through metrics [88]. Accuracy, recall, precision, f1 score and mAP values are among the most widely used deep learning metrics [40].
To calculate these metrics, it is necessary to collect TP, TN, FP, and FN values from all the images in the test dataset. TP indicates instances where the model successfully identifies and accurately localizes the desired object within the image. TN represents cases where the model correctly identifies an object’s absence when there is no object present. FP denotes situations where the model erroneously detects an object that isn’t actually in the image. FN signifies scenarios where the model fails to detect an object that is present in the image.
Accuracy demonstrates the model’s precision once computed for the objects intended for detection within each image present in the test dataset. This value is derived using the formula with (1).
Precision reveals the proportion of true positives, referring to the correctly identified instances, within the set of positive classifications made by the model. The calculation for this metric is conducted using (2).
Recall captures the efficacy of identifying positive instances (marked by a drawn bounding box around the object) corresponding to houses among the entirety of positive samples (objects). The computation of this measure is carried out using (3).
In scenarios where there is an imbalanced distribution in the dataset, the F1 score is employed for a more comprehensive evaluation of the models’ performance [39]. The F1 score is calculated as presented in (4).
The mean average precision (mAP) is computed by determining the average precision (AP) for individual classes and subsequently averaging across multiple classes. The mAP comprehensively balances the interplay between precision and recall, taking into account false positives (FP) and false negatives (FN). The mAP is calculated as presented in (5).
To evaluate the accuracy of machine learning algorithms in detecting objects in an image, the Intersection over Union (IoU) metric is commonly used. This metric measures the degree of agreement between the size of the object detected by the deep learning model and the actual size of the object. The IoU metric is calculated using (6).
The study’s experimental phase was conducted utilizing a desktop computer with an Intel i9 12900 processor operating at 3.19 GHz, 64 GB of RAM, a 12 GB QUADRO graphics card, a 2 TB SSD, and running the Windows 10 Pro operating system. The task of object detection using deep learning was accomplished using Python 3.9 in conjunction with the Open-CV library.
In the context of this research, YOLOv5, DETR and YOLO-NAS models, widely used recently, were used as object detection-based deep learning models. Labeling was performed using LabelImg in a rectangular format [89]. By performing a single tagging process, only the format of the tagging process was changed according to the deep learning model. While the YOLOv5 and YOLO-NAS models are trained with tagged files in .txt format, the DETR model is trained with the labelled format in coco-JSON format. In this way, the models are provided to work under equal conditions. For experimental evaluation, 160000 images at the 18th magnification level produced by TileCache were used. The geolocations of the dataset, which consists of 16000 images, are shown on the map in Fig. 4(a). Out of the 16000 images in the dataset, 10000 were randomly selected for training using the ’random-image-from-folder’ [90] function. Another 2000 images were randomly selected from the remaining 6000 as validation. The remaining 4000 images were used as test data. Figure 4(b) shows the geolocation of the test image on the map.

Spatial locations of datasets
Deep learning models were trained for building detection using the provided training and validation datasets for up to 250 epochs. The mAP values obtained by the models during the training process are presented in Fig. 5.

Training mAP of deep learning models
As presented in Fig. 5 , the mAP values obtained by the models start from the low value and increase as the training process rises. The fact that the mAP value is close to 1 indicates that the deep learning model performs the training process successfully. As shown in Fig. 5, the YOLO-NAS model completed better training because it achieved higher mAP values than YOLOv5 and DETR models. The mAP value obtained by the models increases at a higher rate up to 200 epochs but does not increase slightly after 200 epochs. For this reason, the weights obtained by the models at 250 epochs were used. However, the RefineNet model trained with a different dataset was utilized to evaluate the impact of the improvement made on tilecache on deep learning models trained across different datasets. Specifically, the performance of the RefineNet model, called BFS, trained by Palnak [38] to detect building objects from satellite images, was examined on datasets produced by classical and improved tilecache. Table 3 presents the parameter values for the YOLOv5, DETR, YOLO-NAS, and RefineNet models used in this study.
5.2 Experiments
In this section, the determination of polygon boundaries of buildings from huge size satellite imagery of the proposed BBD methods is discussed. In the proposed BBD method, building bounding box values are first determined to determine the building polygon boundaries. The object detection achievement of the YOLOv5, DETR and YOLO-NAS models, widely used recently for the detection of architectural structures in the satellite image, is presented. In order to increase the object detection achievement of the BBD method, a fine-tuning based improvement was made to the input data and the temporal and dimensional costs of this improvement were discussed. Then, the building segmentation results of the BBD approaches are examined.Finally, the spatial building boundary detection performance of the proposed methods was examined.
5.2.1 Performances of proposed BBD methods
In the context of this experiment, the building object detection achievement of BBD methods from huge size satellite imagery was investigated. In the proposed BBD approach, huge size satellite imagery are processed. However, since the compressed version of the satellite image examined in the context of the study is 21 GB, it cannot be processed with the classical image reading methods. In the proposed method, the satellite image is made available online in WMS format with the GeoServer software, widely used in map-based systems, to process huge size satellite imagery. Then, with the TileCache system, these images are saved on computer disk systems in z/x/y.jpg format. The z value represents the zoom value, which represents the display level of the image on the map. The x and y values represent the coordinate of the image at the z level. Classic TileCache method produces 256x256 images. However, since there is much splitting in the images created in 256x256 size, one part of the building may remain in one image and the other. A fine-tuning based optimization has been made to overcome this problem and improve the object detection achievement of deep learning methods. 512x512 images correspond to four 256x256 images. Methods using 512x512 input images are called improved, while methods using 256x256 images are called classical. The object detection achievement of the methods was investigated on 4000 images with 256x256 dimensions. With the improvement made, these images create 1000 images in 512x512 sizes. The achievement of classical and improved deep learning methods are examined separately, and the table is presented in Table 4.
As presented in Table 4, the classical YOLOv5, DETR, YOLO-NAS and RefineNet models correctly detected 4321, 3271, 5549 and 5301 houses, respectively (TP). However, the comparison should be made instead of the f1 score, which contains all the values, rather than just the correct determination. The classic DETR model has the lowest success rate, with an F1 score of 0.615. On the other hand, the traditional YOLO-NAS model has the highest success rate with an F1 score of 0.869. Classic deep learning models take 256x256 input images. In order to increase the object detection achievement of deep learning models, a fine-tuning-based development process was carried out in the context of this study. With this process, TileCache is enabled to generate 512x512 images, which are presented as input to deep learning models. Improved YOLOv5, DETR, YOLO-NAS and RefineNet methods, which take 512x512 input images, obtained f1 scores of 0.883, 0.772, 0.975 and 0.932, respectively. Thanks to the improvement, the f1 score achievement of the deep learning models was increased by 0.139, 0.157, 0.105 and 0.106 for the YOLOv5, DETR, YOLO-NAS and RefineNet models, respectively. The improved YOLO-NAS method showed superior performance by obtaining an f1 score of 0.975. On the other hand, the IoU metric is used to measure the similarity between two regions or areas. A high IoU indicates that the perceived object or segmentation is close to the real object or segmentation. Thanks to the proposed fine-tuning process, the IoU value of the methods has increased. The Improved YOLO-NAS model has an IoU value of 0.912, which demonstrates its successful performance in the segmentation process.
In order to better examine the object detection achievement of classical deep learning and enhanced deep learning methods, the performance of the methods on a sample image is examined. Since classical deep learning takes 256x256 input images, four input images presented to classical deep learning form one image presented to enhanced deep learning. Figure 6 presents the object detection result of classical deep learning methods. Figure 7 presents the object detection result of improved deep learning methods. Figures 6(a), 6(b), 6(c) and 6(d) are the fragment form of the Fig. 7(a).

Result of classic deep learning methods
When the object detection achievement of classical deep learning methods presented in Fig. 6 is examined, the classical YOLOv5 model was able to detect only the home object in the first image (Fig. 6(e)) in 4 input images. It could not detect the house objects in the other image. Similarly, the classical DETR model only detected the house object in the first input image. But it did not detect the house objects in the other images. On the other hand, the YOLO-NAS model detected the home objects in the first and fourth input images, and these results are presented in Figs. 6(g) and 6(h), respectively. The RefineNet model, which performs direct segmentation, detected house objects in the fourth image. The detection results of the RefineNet method are shown in Fig. 6(e). The YOLO-NAS model outperforms YOLOv5, DETR and RefineNet models because it optimizes its hyperparameters according to the model data set. Because the image is divided into many parts in classical deep learning models, sometimes buildings cannot be formed entirely within the image. For this reason, classical deep learning models do not perform well enough.

Result of proposed deep learning methods
When the object detection achievement of the improved deep learning methods presented in Fig. 7 is examined, the improved YOLOv5 model detected 2 objects in the image, whereas the classical YOLOv5 model detected 1 object. The improved DETR model detected 1 building object as in the classical DETR model. The improved YOLO-NAS model, on the other hand, shows superior achievement by detecting all 4 buildings in the input image. Using the images generated by the proposed TileCache, the RefineNet model improved object detection performance by detecting 3 house objects as shown in Fig. 7(e). As with the classical models, the improved YOLO-NAS model outperforms the YOLOv5 and DETR models. When comparing the achievement of classical and improved deep learning models presented in Figs. 6 and 7, improved deep learning models outperform classical deep learning models. This is because the images produced by the classic TileCache are split up to 4 times the improved TileCache model. For this reason, some parts of the buildings are in one view and other parts in the other images. Traditional deep learning models cannot detect the building object because no entire building is processed in the image. On the other hand, since 1 image is formed from 4 images in the improved TileCache model, the buildings are fully included in the image. Therefore, improved deep learning models show superior performance.
5.2.2 Disk size and run time of proposed methods
In studies on big data, computational cost and disk cost are essential. In the context of this experiment, the space occupied by the BBD approaches on the disk and the computational costs were examined. In the proposed BBD approach, building bounding box values are determined by classical and improved deep learning models. These values are then presented as input to the SAM model. The computational cost of BBD methods depends on the computational cost of classical and deep learning models. The running time of the methods on the images in the test dataset was examined and presented in Table 5 with the data sizes.
As presented in Table 5 , classical deep learning methods worked on 4000 pieces of data, while improved deep learning models worked on 1000 data. While classical deep learning models process 256x256 images, deep learning models improved based on fine-tuning process 512x512 images. The 512x512 image includes 4 256x256 images. For this reason, the improved deep learning models work 4 times faster than the classical deep learning models. Since there is no data loss in the fine-tuning of the TileCache process, although there is a minimal residual in the image sizes, they are generally very close to each other. On the other hand, when the running time of deep learning models is examined, the improved YOLOv5, DETR, YOLO-NAS and RefineNet models detect building objects in an image at approximately 0.016, 0.033, 0.051 and 0.602 seconds. The YOLOv5 model performs approximately twice as fast as the DETR model, three times as fast as the YOLO-NAS model, and twelve times as fast as the RefineNet model.
5.2.3 Segmentation result of methods with geolocation
In the context of this experiment, the performance of BBD methods for detecting building polygon boundaries and areas was investigated. The SAM method is used to determine the building boundaries in the proposed BBD approach. The SAM model detects all the polygons in the image presented as input. In the context of this study, firstly, huge size satellite imagery has been made accessible in WMS format with GeoServer so that deep learning models can process it. Later, these images were converted into small-volume images with TileCache and made to be processed by deep learning models. Figure 8 presents segments obtained by the SAM method on the image produced by TileCache.

Segmentation result of SAM
Figure 8(a) presents the image produced by TileCache. Figure 8(b) shows the segmentation results of the SAM model. However, as seen in Fig. 8(b), although the SAM model performs the segmentation process successfully, the building objects cannot be detected. On the other hand, the SAM model can perform segmentation within a specific area instead of performing segmentation on the entire image. In the context of this research, in order to determine the building boundaries and areas with the SAM model, first of all, the bounding box values (x1, y1, x2, y2) covering the building are determined by object detection-based CNN models. On the other hand, the classic TileCahe creates small 256x256 images. However, CNN-based deep learning models did not perform well enough for the detection of architectural structures in 256x256 images. Because the buildings can be cut in the middle in the images formed in 256x256 dimensions. Thanks to the fine-tuning developed in the context of this study, TileCahce produced 512x512 images. As described in Chapter 5.2.1, deep learning methods have detected building objects with a higher success rate thanks to the improvement. The improved BBD approach introduced in Section 5.2.1, which takes 512x512 images as input, showed superior performance. Therefore, in the context of this experiment, the results produced by the improved approaches were presented as input to the SAM model. The performance of the methods was examined on 1000 images, and the results are shown in Table 6.
As presented in Table 6, YOLOv5, DETR and YOLO-NAS models are used as improved object detection models on the test dataset. The bounding box values of the building objects detected by these models are presented as input to the SAM model.However, the RefineNet model directly segmented the test dataset. The results of the RefineNet model were not used as input for any subsequent models. Improved YOLOv5, DETR, YOLO-NAS and RefineNet models detected 5612, 4473, 6741 and 6245 building objects, respectively. Since the bounding boxes of these detected objects are also presented as input to the SAM model, the same polygons as the number of detected objects are obtained. In the proposed BBD approach, the Improved YOLO-NAS-SAM method detected the highest area with a total polygon area of 30238642.98. The improved DETR-SAM method, on the other hand, detected 21885091.83 areas in total and determined the lowest area amount. When the average area values of the polygons detected by these methods are examined, the Improved YOLOv5-SAM, DETR-SAM, YOLO-NAS-SAM, and RefineNet methods determine the average values of approximately 4616.71, 4892.71, 4485.78 and 4393.73, respectively. When the average values of the detected polygons are examined, the DETR-SAM model has the highest average value, while the RefineNet method has the lowest value. In order to better analyse the performance of the improved YOLOv5-SAM, DETR-SAM, YOLO-NAS-SAM and RefineNet methods, the results of the methods on a sample image are examined and Figs. 9, 10, 11 and 12.

Segmentation result of YOLOv5-SAM
Examining Fig. 9 showing the results of the improved YOLOv5-SAM method in the proposed BBD approach, Fig. 9(a) shows the object detection achievement of the improved YOLOv5 method. The improved YOLOv5 model detected 6 out of 7 clearly distinguishable buildings with a confidence score above 0.8. The bounding box values of these detected building objects are also presented as inputs to the SAM, respectively. The polygon boundary results detected by the SAM model are respectively as Figs. 9(b), 9(c), 9(d), 9(e), 9(f) and 9(g). Comparing the segmentation results of the classic SAM model presented in Fig. 8 with the results of the improved YOLOv5-SAM model, whose segmentation results are shown in Fig. 9, the success of the improved YOLOv5-SAM model more clearly understood. In Fig. 8, the classical SAM model detects buildings while unclear which. Also, the classical SAM model detects some buildings halfway. On the other hand, in the improved YOLOv5-SAM method, the more accurate the building bounding box value is, the more accurate the result. Since the bounding boxes of the buildings that the YOLOv5 model detects are good, the segmentation results of the improved YOLOv5-SAM method are also good.

Segmentation result of DETR-SAM
Examining Fig. 10 showing the results of the improved DETR-SAM method in the proposed BBD approach, Fig. 10(a) shows the object detection achievement of the improved DETR method. The improved DETR model detected only 2 building objects. The bounding box values of these detected building objects are also presented as inputs to the SAM, respectively. The polygon boundary results detected by the SAM model are presented in Figs. 10(b) and 10(c), respectively. When the segmentation results of the improved DETR-SAM method are compared with the classical SAM model, the DETR-SAM method finds the polygon of the detected buildings. However, the improved DETR-SAM method is not as successful as the improved YOLOv5-SAM method since the DETR model that provides input to the DETR-SAM method can detect a small number of buildings. Because the improved DETR-SAM can detect a small number of large buildings, the average detection area is high while the overall detection area is low.

Segmentation result of YOLO-NAS-SAM
Examining Fig. 11 showing the results of the improved YOLO-NAS-SAM method in the proposed BBD approach, Fig. 11(a) shows the object detection achievement of the improved YOLO-NAS method. The improved YOLO-NAS model detected 2 buildings that were difficult to distinguish and 7 buildings that were clearly distinguishable in the picture. The bounding box values of these detected building objects are also presented as inputs to the SAM, respectively. The polygon boundary results detected by the SAM model are respectively Figs. 11(b), 11(c), 11(d), 11(e), 11(f), 11(g), 11(h), 11(i) and 11(j). When the segmentation results of the improved YOLO-NAS-SAM method are compared with the classical SAM model, the YOLO-NAS method finds the polygon of the detected buildings. In addition, the improved YOLO-NAS method detects structures that the improved YOLOv5 and DETR methods cannot detect. Since the bounding box values of these detected buildings are presented as input to the SAM model, the YOLO-NAS-SAM method can draw the boundaries of more buildings than the YOLOv5-SAM and DETR-SAM models. On the other hand, since the proposed YOLO-NAS-SAM method can segment buildings with tiny dimensions, the total polygon area determined by the method is higher than the entire polygon areas detected by the YOLOv5-SAM and DETR-SAM methods. The reason for the small average polygon area of the proposed YOLO-NAS-SAM method is that it detects a large number of buildings, some of which are small. The proposed YOLO-NAS-SAM method performs better in determining the polygon boundaries of structures and buildings than other methods.
Figure 12 shows the segmentation results of the RefineNet method using the images produced by the proposed TileCache. The method detected 9 buildings in the image, but also identified non-house objects as houses. The RefineNet method is not entirely successful in accurately detecting houses due to this issue.

Polygon result by RefineNet
5.2.4 Geographical Location of the Building Boundaries
One of the most critical features of the BBD method proposed in the context of this research is that it determines the building and building boundaries and their geolocations. In the proposed BBD approach, the deep learning model also takes the geolocation (x/y/z.jpg) of the image it receives as input. In this way, it automatically detects the location of the house and its borders on the Earth using the Algorithm 4. The geolocations of the segmentation areas determined by YOLOv5-SAM, DETR-SAM, YOLO-NAS-SAM, and RefineNet are presented in Fig. 13.

Detection of Building Locations through Segmentation Techniques
Upon examining the geographical locations presented in Fig. 13, it is evident that YOLO-NAS-SAM detects a higher density of buildings compared to other methods. This is due to the superior true positive building detection provided by YOLO-NAS-SAM. Furthermore, the image also displays the building area on a pixel basis. When examining the areas of the building detected by the methods at the same point, they are identical in Fig. 13(a), 13(b), and 13(c), with a value of 1579.12. The boundaries of the objects detected by YOLOv5, DETR, and YOLO-NAS are presented as input to the SAM method. When using the SAM method to detect an object within the coordinates, it identifies the most prominent object in the region. As all three methods detect the same object, the area remains the same. In contrast, the RefineNet method performs direct segmentation, meaning it does not provide data flow to any other method. As shown in Fig. 13(d), the RefineNet method identified 1329.73 building areas on a pixel basis. The value produced by BBD methods is higher than the value obtained from RefineNet IoU. This is due to the lower IoU value of RefineNet.
The BBD approach can detect building boundaries and their locations at a high rate. However, the detection of buildings and boundaries is dependent on the object detection performance of the deep learning method in the first stage. If the object detection method in the first stage fails to detect a building, the proposed BBD approach will not be able to detect its boundaries.
6 Conclusion
In this study, we introduced a novel approach, BBD, for detecting architectural objects from large-scale satellite imagery, utilizing remote sensing techniques along with geolocations. Our proposed BBD method employs open-source GeoServer and TileCache software to process extensive satellite imagery data, which cannot be efficiently handled by traditional data processing methods alone. We employed state-of-the-art deep learning models, including YOLOv5, DETR, YOLO-NAS, and RefineNet, for building detection and segmentation within the BBD framework.
The YOLOv5, DETR, and YOLO-NAS models achieved F1 scores of 0.744, 0.615, and 0.869, respectively, for building detection on images generated by classic TileCache. Notably, the RefineNet model, focusing on direct building segmentation, attained an F1 score of 0.826.
However, challenges arose due to the excessive partitioning of images by classic TileCache, hindering holistic building detection. To address this, we performed fine-tuning-based optimization, significantly enhancing the performance of all models. With our proposed fine-tuning, the modified YOLOv5, DETR, YOLO-NAS, and RefineNet models achieved remarkable F1 scores of 0.883, 0.772, 0.975, and 0.932, respectively.
Among the object detection methods, the modified YOLO-NAS approach stood out, exhibiting the highest object detection rate with an F1 score of 0.975. Moreover, our YOLO-NAS-SAM approach excelled in accurately delineating building boundaries, achieving an IoU value of 0.912.
The BBD approach demonstrates high efficiency in detecting building boundaries and their spatial locations. However, the effectiveness of building and boundary detection hinges on the initial object detection performance of the employed deep learning method.
In future studies, it is aimed to increase the object detection performance of the BBD method and to determine the spatial boundaries of buildings for geographical information systems.
Data availability
Data sharing is not applicable to this article as the data used in this study belong to Kayseri Metropolitan Municipality. Therefore, data sharing does not apply to this article as the data owner does not allow it.
References
Jing H, Sun X, Wang Z, Chen K, Diao W, Fu K (2021) Fine building segmentation in high-resolution sar images via selective pyramid dilated network. IEEE J Sel Top Appl Earth Obs Remote Sens 14:6608–6623
Zheng C, Peng B, Chen B, Liu M, Yu W, He Y, Ren D (2022) Multiscale fusion network for rural newly constructed building detection in unmanned aerial vehicle imagery. IEEE J Sel Top Appl Earth Obs Remote Sens 15:9160–9173
Xu Y, Dong J, Zhang B, Xu D (2016) Background modeling methods in video analysis: A review and comparative evaluation. CAAI Trans Intell Technol 1(1):43–60
Abdulhussain SH, Ramli AR, Saripan MI, Mahmmod BM, Al-Haddad SAR, Jassim WA (2018) Methods and challenges in shot boundary detection: a review. Entropy 20(4):214
Jung H, Choi H-S, Kang M (2021) Boundary enhancement semantic segmentation for building extraction from remote sensed image. IEEE Trans Geosci Remote Sens 60:1–12
Cheng G, Xie X, Han J, Guo L, Xia G-S (2020) Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J Sel Top Appl Earth Obs Remote Sens 13:3735–3756
Zhu B, Zhou L, Pu S, Fan J, Ye Y (2023) Advances and challenges in multimodal remote sensing image registration. IEEE J Miniaturization for Air and Space Syst
Zhang D, Shafiq M, Wang L, Srivastava G, Yin S (2023) Privacy-preserving remote sensing images recognition based on limited visual cryptography. CAAI Trans Intell Technol
Zhang J, Ye G, Tu Z, Qin Y, Qin Q, Zhang J, Liu J (2022) A spatial attentive and temporal dilated (satd) gcn for skeleton-based action recognition. CAAI Trans Intell Technol 7(1):46–55
Yuan X, Xu X, Wang X, Zhang K, Liao L, Wang Z, Lin C-W (2023) Osap-loss: Efficient optimization of average precision via involving samples after positive ones towards remote sensing image retrieval. CAAI Trans Intell Technol
Chen J, Sun J, Li Y, Hou C (2022) Object detection in remote sensing images based on deep transfer learning. Multimed Tools Appl, pp 1–17
Al-Khafajiy M, Baker T, Chalmers C, Asim M, Kolivand H, Fahim M, Waraich A (2019) Remote health monitoring of elderly through wearable sensors. Multimed Tools Appl 78(17):24681–24706
Karim S, Zhang Y, Yin S, Laghari AA, Brohi AA (2019) Impact of compressed and down-scaled training images on vehicle detection in remote sensing imagery. Multimed Tools Appl 78:32565–32583
Soni PK, Rajpal N, Mehta R, Mishra VK (2021) Urban land cover and land use classification using multispectral sentinal-2 imagery. Multimed Tools Appl pp 1–15
Zhang W, Yang Y, Wu Q.J, Wang T, Zhang H (2022) Multimodal moore–penrose inverse-based recomputation framework for big data analysis. IEEE Trans Neural Netw Learn Syst
Upadhyay S, Lincy RB, Jeyavathana RB, Gopatoti A et al (2022) Big data analytics with deep learning based intracranial haemorrhage diagnosis and classification model. In: 2022 International conference on augmented intelligence and sustainable systems (ICAISS), IEEE, pp 877–883
Faaique M (2024) Overview of big data analytics in modern astronomy. Int J Math Stat Comput Sci 2:96–113
Kastanakis B (2016) Mapbox Cookbook. Packt Publishing Ltd
Linwood J, Linwood J (2020) Using offline maps with mapbox. Build Location Apps on iOS with Swift: Use Apple Maps, Google Maps, and Mapbox to Code Location Aware Mobile Apps pp 235–247
Taşyürek M (2021) Regenerating large volume vector layers with a denormalization-based method. In: 2021 6th International conference on computer science and engineering (UBMK), IEEE, pp 124–128
Wang W, Yao X, Chen J (2022) A map tile data access model based on the jump consistent hash algorithm. ISPRS Int J Geo Inf 11(12):608
Kang J, Tariq S, Oh H, Woo SS (2022) A survey of deep learning-based object detection methods and datasets for overhead imagery. IEEE Access 10:20118–20134
Turay T, Vladimirova T (2022) Toward performing image classification and object detection with convolutional neural networks in autonomous driving systems: A survey. IEEE Access 10:14076–14119
Khalid MM, Karan O (2024) Deep learning for plant disease detection. Int J Math Stat Comput Sci 2:75–84
Sohail A, Nawaz NA, Shah AA, Rasheed S, Ilyas S, Ehsan MK (2022) A systematic literature review on machine learning and deep learning methods for semantic segmentation. IEEE Access
Chen X, Chen W, Su L, Li T (2023) Slender flexible object segmentation based on object correlation module and loss function optimization. IEEE Access 11:29684–29697
Taşyürek M, Öztürk C (2022) Ddl: A new deep learning based approach for multiple house numbers detection and clustering. J Fac Eng Archit Gazi Univ 37(2)
Öztürk C, Taşyürek M, Türkdamar MU (2023) Transfer learning and fine-tuned transfer learning methods’ effectiveness analyse in the cnn-based deep learning models. Concurrency Comput Pract Experience 35(4):7542
Konstantinidis D, Argyriou V, Stathaki T, Grammalidis N (2020) A modular cnn-based building detector for remote sensing images. Comput Netw 168:107034
Han Q, Yin Q, Zheng X, Chen Z (2021) Remote sensing image building detection method based on mask r-cnn. Complex Intell Syst pp 1–9
Zhao G, Zhang Y, Ge M, Yu M (2023) Bilateral u-net semantic segmentation with spatial attention mechanism. CAAI Trans Intell Technol 8(2):297–307
Xue W, Yang Y, Li L, Huang Z, Wang X, Han J, Zhang D (2023) Weakly supervised point cloud segmentation via deep morphological semantic information embedding. CAAI Trans Intell Technol
Tasyurek M (2024) Sdph: A new technique for spatial detection of path holes from huge volume high-resolution raster images in near real-time. J Real-Time Image Process Accepted 21(70)
Jocher G, Nishimura K, Mineeva T, Vilariño R (2023) Yolov5. https://github.com/ultralytics/yolov5 Accessed 21 May 2022
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: European conference on computer vision, Springer, pp 213–229
Deci-AI: YOLO-NAS. https://github.com/Deci-AI/super-gradients/blob/master/YOLONAS.md Accessed 12 Aug 2023
Kirillov A, Mintun E, Ravi N, Mao H, Rolland C, Gustafson L, Xiao T, Whitehead S, Berg AC, Lo W-Y et al (2023) Segment anything. arXiv preprint arXiv:2304.02643
Palnak FA (2024) Building-footprint-segmentation. https://github.com/fuzailpalnak/building-footprint-segmentation Accessed 25 March 2024
Arslan RS, Tasyurek M (2022) Amd-cnn: Android malware detection via feature graph and convolutional neural networks. Concurr Comput Pract Experience 34(23):7180
Tasyurek M, Arslan RS (2023) Rt-droid: a novel approach for real-time android application analysis with transfer learning-based cnn models. J Real-Time Image Proc 20(3):1–17
Taşyürek M (2023) Odrp: a new approach for spatial street sign detection from exif using deep learning-based object detection, distance estimation, rotation and projection system. Vis Comput pp 1–21
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and Pattern Recognition, pp 580–587
Girshick R: Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 1440–1448 (2015)
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: Towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28:91–99
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 779–788
Terven J, Cordova-Esparza D (2023) A comprehensive review of yolo: From yolov1 to yolov8 and beyond. arXiv preprint arXiv:2304.00501
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) Ssd: Single shot multibox detector. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, pp 21–37
He K, Gkioxari G, Dollár P, Girshick R (2017) Mask r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 2961–2969
Ma H, Liu Y, Ren Y, Yu J (2019) Detection of collapsed buildings in post-earthquake remote sensing images based on the improved yolov3. Remote Sensing 12(1):44
Liu Y, Pang C, Zhan Z, Zhang X, Yang X (2020) Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci Remote Sens Lett 18(5):811–815
Gao J, Chen Y, Wei Y, Li J (2021) Detection of specific building in remote sensing images using a novel yolo-s-ciou model. case: gas station identification. Sensors 21(4):1375
Chen F, Wang N, Yu B, Wang L (2022) Res2-unet, a new deep architecture for building detection from high spatial resolution images. IEEE J Sel Top Appl Earth Obs Remote Sens 15:1494–1501
Tasyurek M, Turkdamar MU, Ozturk C (2024) Dshfs: A new hybrid approach that detects structures with their spatial location from large volume satellite images using cnn, geoserver and tilecache. Neural Comput Appl 36(3):1237–1259
Nurkarim W, Wijayanto AW (2023) Building footprint extraction and counting on very high-resolution satellite imagery using object detection deep learning framework. Earth Sci Inform 16(1):515–532
Jain G, Singh D.P, Choudhary J (2023) Flynet–neural network model for automatic building detection from satellite images. J Indian Soc Remote Sens pp 1–16
Mei J, Zheng Y-B, Cheng M-M (2023) D2anet: Difference-aware attention network for multi-level change detection from satellite imagery. Comput Vis Media 9(3):563–579
Chen S, Ogawa Y, Zhao C, Sekimoto Y (2023) Large-scale individual building extraction from open-source satellite imagery via super-resolution-based instance segmentation approach. ISPRS J Photogramm Remote Sens 195:129–152
Deng S, Wu S, Bian A, Zhang J, Di B, Nienkötter A, Deng T, Feng T (2023) Scattered mountainous area building extraction from an open satellite imagery dataset. IEEE Geosci Remote Sens Lett 20:1–5
Holail S, Saleh T, Xiao X, Li D (2023) Afde-net: Building change detection using attention-based feature differential enhancement for satellite imagery. IEEE Geosci Remote Sens Lett
He L, Shan J, Aliaga D (2023) Generative building feature estimation from satellite images. IEEE Trans Geosci Remote Sens 61:1–13
Hazaymeh K, Almagbile A et al (2023) A cascaded data fusion approach for extracting the rooftops of buildings in heterogeneous urban fabric using high spatial resolution satellite imagery and elevation data. Egyptian J Remote Sens Space Sci 26(1):245–252
Youngblood B (2013) GeoServer Beginner’s Guide. Packt Publishing Ltd
Haklay M, Singleton A, Parker C (2008) Web mapping 2.0: The neogeography of the geoweb. Geogr Comp 2(6):2011–2039
MetaCarta (2023) TileCache – Web Map Tile Caching. http://tilecache.org/#tilecacheconfig Accessed 11 Aug 2023
Tasyurek M, Celik M (2022) 4d-gwr: geographically, altitudinal, and temporally weighted regression. Neural Comput Appl 34(17):14777–14791
Tasyurek M, Celik M (2021) Fastgtwr: A fast geographically and temporally weighted regression approach. J Fac Eng Archit Gazi University 36(2):715–726
Xu D, Yuan Z, Yu T, Xie D, Zheng F, Zheng G (2012) The research of remote sensing image segmentation and release which are based on tile map service. In: 2012 International Symposium on Geomatics for Integrated Water Resource Management, IEEE, pp 1–4
Stefanakis E (2017) Web mercator and raster tile maps: two cornerstones of online map service providers. Geomatica 71(2):100–109
Sarkar D, Gunturi SK (2021) Online health status monitoring of high voltage insulators using deep learning model. The Visual Computer, pp 1–12
Du J (2018) Understanding of object detection based on cnn family and yolo. In: Journal of physics: conference series, vol 1004, pp 012029. IOP Publishing
Redmon J, Farhadi A (2017) Yolo9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7263–7271
Bochkovskiy A, Wang C-Y, Liao H-YM (2020) Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934
Jiang P, Ergu D, Liu F, Cai Y, Ma B (2022) A review of yolo algorithm developments. Procedia Comput Sci 199:1066–1073
Fang Y, Guo X, Chen K, Zhou Z, Ye Q (2021) Accurate and automated detection of surface knots on sawn timbers using yolo-v5 model. BioResources 16(3)
Aharon S, Louis-Dupont Ofri Masad, Yurkova K, Fridman Lotem, Lkdci Khvedchenya E, Rubin R, Bagrov N, Tymchenko B, Keren T, Zhilko A, Eran-Deci, (2021) Super-Gradients. GitHub
Singh V (2023) Meet YOLO-NAS: New YOLO Object Detection Model Beats YOLOv6 and YOLOv8. https://learnopencv.com/yolo-nas/ Accessed 11 Aug 2023
Kumar A, Singh S.K, Dubey SR (2023) Target detection using transformer: A study using detr. In: Computer vision and machine intelligence: proceedings of CVMI 2022, Springer, pp 747–759
Ban C-G, Park D, Hwang Y (2022) Image classification using detr based object-level feature. In: 2022 22nd International conference on control, automation and systems (ICCAS), IEEE, pp 1297–1300
Gupta A, Narayan S, Joseph K, Khan S, Khan FS, Shah M (2022) Ow-detr: Open-world detection transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9235–9244
Zhang G, Luo Z, Cui K, Lu S, Xing EP (2022) Meta-detr: Image-level few-shot detection with inter-class correlation exploitation. IEEE Trans Pattern Anal Mach Intell
Wan H, Gao L, Yuan Z, Qu H, Sun Q, Cheng H, Wang R (2022) A novel transformer model for surface damage detection and cognition of concrete bridges. Expert Syst Appl pp 119019
Hong D, Han Z, Yao J, Gao L, Zhang B, Plaza A, Chanussot J (2021) Spectralformer: Rethinking hyperspectral image classification with transformers. IEEE Trans Geosci Remote Sens 60:1–15
Bhojanapalli S, Chakrabarti A, Glasner D, Li D, Unterthiner T, Veit A (2021) Understanding robustness of transformers for image classification. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 10231–10241
Skalski P (2023) How to Use the Segment Anything Model (SAM). https://blog.roboflow.com/how-to-use-segment-anything-model-sam/ Accessed 15 Aug 2023
Solawetz J (2023) What Is Segment Anything Model (SAM)? A Breakdown. https://blog.roboflow.com/segment-anything-breakdown/ Accessed 16 Aug 2023
Wiki: Slippy Map Tilenames. https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames Accessed 2023-09-26
Stackexchange : Calculate Lat Lon Bounds for Individual Tile Generated from Gdal2tiles. https://gis.stackexchange.com/questions/17278/calculate-lat-lon-bounds-for-individual-tile-generated-from-gdal2tiles Accessed 2023-05-18
Adnan M, Habib A, Ashraf J, Mussadiq S, Raza AA, Abid M, Bashir M, Khan SU (2021) Predicting at-risk students at different percentages of course length for early intervention using machine learning models. Ieee Access 9:7519–7539
Tzutalin D (2015) Labelimg. GitHub Repository 6
Kurilyak S (2024) Get Random Image from a Folder. https://gist.github.com/slavakurilyak/d3418446179f98cde5b7d6b53eefa09d Accessed 01 March 2024
Acknowledgements
We express our gratitude to the Kayseri Metropolitan Municipality for generously providing large-scale satellite imagery.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). This research receives support from the Scientific and Technical Research Council of Turkey under the Career Development Program (3501), Project No: 122E315.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tasyurek, M. BBD: a new hybrid method for geospatial building boundary detection from huge size satellite imagery. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-19279-5
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-19279-5