
Abstract
The present study uses machine learning and time series spectral analysis to develop a novel technique to forecast the sunspot number (SN) in both hemispheres for the remainder of Solar Cycle 25 and Solar Cycle 26. This enables us to offer predictions for hemispheric SN until January 2038 (using the 13-month running average). For the Northern hemisphere, we find maximum peak values for Solar Cycles 25 and 26 of 58.5 in April 2023 and 51.5 in November 2033, respectively (root mean square error of 6.1). For the Southern hemisphere, the predicted maximum peak values for Solar Cycles 25 and 26 are 77.0 in September 2024 and 70.1 in November 2034, respectively (root mean square error of 6.8). In this sense, the results presented here predict a Southern hemisphere prevalence over the Northern hemisphere, in terms of SN, for Solar Cycles 25 and 26, thus continuing a trend that began around 1980, after the last period of Northern hemisphere prevalence (which, in turn, started around 1900). On the other hand, for both hemispheres, our findings predict lower maxima for Solar Cycles 25 and 26 than the preceding cycles. This fact implies that, when predicting the total SN as the sum of the two hemispheric forecasts, Solar Cycles 24 – 26 may be part of a centennial Gleissberg cycle’s minimum, as was the case in the final years of the 19th century and the start of the 20th century (Solar Cycles 12, 13, and 14).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Research on solar activity is key to comprehending our Sun’s dynamic processes, with the observation of sunspots being particularly crucial (Vaquero 2007). With some few records first being made with the naked eye two millennia ago (Clark and Stephenson 1978; Wittmann and Xu 1987), systematic sunspot observations using telescopes, which started in 1610 (Arlt and Vaquero 2020; Vokhmyanin, Arlt, and Zolotova 2020; Carrasco et al. 2022), represent the longest continuous direct indicators of solar activity, providing rich insights into our star’s behavior and how this affects the conditions of the solar-terrestrial environment. Sunspots, discernible as dark areas temporarily appearing on the photosphere, have a strong magnetic activity that causes them to be cooler than their surroundings. They arise from the differential rotation of the solar plasma, which compresses and fractures field lines, chaotically releasing energy and mass, producing cooler areas (Forgács-Dajka, Dobos, and Ballai 2021). These areas, with a temperature of about 4000 K, are in stark contrast to the surrounding solar photosphere, with its average temperature of 5700 K, leading to a visible dark appearance (Li et al. 2013; Khomenko and Collados 2015).
The research on the knowledge of sunspots has advanced considerably in the last few centuries. In the 17th century, Galileo revolutionized the understanding of solar dynamics by using a telescope to show that they were indeed solar phenomena (Galilei and Scheiner 2010; Vaquero and Vázquez 2009). This understanding was strengthened by Schwabe’s revelation of the existence of the cyclic nature of solar activity over 11 years (Schwabe 1844; Hathaway 2015). Hence, observational data sets showing the sunspot number over the long term are crucial for research on solar behavior, especially when predicting solar dynamics (Owens 2013; Muñoz-Jaramillo and Vaquero 2019; Usoskin 2023). Thanks to the long history of sunspot observations, a trove of information is available, with the sunspot number (SN) as a crucial index for measuring solar activity. First defined in the middle of the 19th century by Wolf (1880), the index has been revised and enhanced multiple times, enriching our knowledge of solar dynamics (Wolf 1880; Hoyt and Schatten 1998; Clette et al. 2014; Svalgaard and Schatten 2016; Vaquero et al. 2016). The World Data Center Sunspot Index and Long-term Solar Observations (WDC-SILSO) keeps the SN index, which has been crucial to research in this field as it provides a standardized approach to assessing the long-term trends in solar activity (Clette et al. 2007; Clette and Lefèvre 2016; Clette et al. 2023).
The North-South (N-S) hemispheric asymmetry, as represented by sunspots, is a noticeable facet of solar activity. Research on this phenomenon, which was first recorded by Carrington in the mid-19th century (Carrington 1858) and subsequently reaffirmed by Spörer and Maunder a few decades later (Spörer 1889; Maunder 1904), has demonstrated that, in general, sunspots tend to exist preferentially in one of the Sun’s hemispheres, alternating this prevalence between hemispheres in the form of cycles (Hathaway 2015). Utilizing several indicators of solar activity (e.g., faculae, prominences, sunspots, and coronal brightness), Waldmeier (1971) further substantiated that one hemisphere dominates over the other. This asymmetry is a consistent feature, not only in sunspots but also in the flare index, solar x-ray flares, solar filament number, coronal mass ejections, and other indicators (Ataç and Özgüç 1996; Temmer et al. 2001; Joshi and Joshi 2004; Joshi et al. 2015; Deng et al. 2019; Roy et al. 2020; Prasad et al. 2021; Aparicio et al. 2022; Carrasco et al. 2023; Javaraiah 2023). This N-S asymmetry is not merely an observational curiosity, and its study, as part of comprehensive research on solar activity, is a critical research area in solar physics. The reason for this hemispheric asymmetry lies in the solar dynamo (Schüssler and Cameron 2018; Charbonneau 2020). Applying modern analytical techniques to the abovementioned historical observations allows us to enrich the field with in-depth insights into solar dynamics, including the intricate interactions and how these drive the long-term behavior of the Sun and the solar-terrestrial environment.
Research on solar activity has shown that such asymmetries between the hemispheres rarely exceed 20%; however, in certain periods the sunspots are mostly concentrated in one of the hemispheres, such as the Maunder minimum (Ribes and Nesme-Ribes 1993; Sokoloff and Nesme-Ribes 1994; Norton, Charbonneau, and Passos 2015). The asymmetries can occur in terms of the start time, amplitude, rise and fall pattern, and cycle duration in both hemispheres, with considerable implications for the knowledge of solar variability (Chowdhury, Choudhary, and Gosain 2013). In this sense, the work presented by Zolotova et al. (2010) reveals a long-standing, systematic difference in the course of solar activity between the hemispheres, characterized by a consistent but variable phase lead of one hemisphere over the other that is inversely related to the latitudinal position of sunspots. This way, such pattern, which probably corresponds to the Gleissberg cycle (Gleissberg, 1939, 1945), is not random, but shows long-term persistence, challenging the view that hemispheric phase differences are merely stochastic phenomena.
At present, these asymmetries are investigated using advanced methodologies, such as fractal analysis, wavelet transform, and visibility graphs. Taking their point of departure from the field of nonlinear dynamics, these approaches offer a novel way to comprehend the activity cycle and complex behavior of the Sun (Carbonell, Oliver, and Ballester 1993; Donner and Thiel 2007; Zou et al. 2014; Xu et al. 2021). However, when tackling non-Gaussian probability distributions, these methods can be less effective, which has raised interest in alternative techniques (De Freitas and De Medeiros 2009; Javaraiah 2022).
With respect to the prediction of hemispheric solar activity for the current Solar Cycle 25, different published works have addressed this issue by employing different methodologies. Using an advective flux transport code, Hathaway and Upton (2016) predicted that the Southern hemisphere would be more active than the Northern hemisphere. Meanwhile, Gopalswamy et al. (2018) also forecasted a prevalence of the Southern hemisphere over the Northern hemisphere in terms of solar activity, using a precursor method based on microwave brightness enhancement. In this way, they predicted, for Solar Cycle 25, maximum smoothed sunspot numbers in the Southern and Northern hemispheres of 89 and 59, respectively. In contrast, Labonville, Charbonneau, and Lemerle (2019) predicted that the Northern hemisphere would be 20% more active than the Southern hemisphere, based on a data-driven version of the solar cycle model of Lemerle and Charbonneau (2017). However, Werner and Guineva (2020) again predicted, using autoregressive models, higher solar activity in the Southern hemisphere than in the Northern hemisphere, with peaks of 72 and 49, respectively. In the same line, Pishkalo (2021) predicted a prevalence of the Southern hemisphere versus the Northern hemisphere, with maximum values of 83 ± 21 and 66 ± 17, respectively. For this, the absolute value of the polar magnetic field near the cycle minimum was used as a precursor. On the other hand, Javaraiah (2021) first predicted higher activity in the Northern hemisphere compared to the Southern hemisphere, with peaks of 39 ± 4 and 31 ± 6, respectively. In this case, such researcher exploited correlations between the sum of the areas of sunspot groups in the southern hemisphere’s near-equatorial band during a brief period just after the maximum epoch of a solar cycle and the amplitude of the next solar cycle. However, a year later, the same author predicted that the Southern hemisphere would be dominant compared to the Northern hemisphere (Javaraiah 2022). Here, such work used the variations between cycles in the 13-month smoothed monthly mean sunspot-group area for the Northern hemisphere, the Southern hemisphere and entire solar disk. Finally, two recent papers have predicted slightly higher solar activity in the Northern hemisphere compared to the Southern hemisphere. First, Du (2022) predicted maximum values of 84.8 ± 24.3 and 81.4 ± 17.4 for the Northern and Southern hemispheres, respectively, utilizing the correlation between the solar cycle’s maximum amplitude and the hemispheric SN. Secondly, Prasad, Roy, and Sarkar (2024) have predicted peak values for Northern and Southern hemispheres of 56 ± 5 and 54 ± 4, respectively, employing a deep-learning method that is grounded in a Long Short-Term Memory (LSTM) approach. Table 1 shows a summary of the cited works together with the predictions made.
Therefore, based on the above, although a narrow majority of papers have predicted a sunspot number prevalence of the Southern hemisphere over the Northern hemisphere in Solar Cycle 25, they differ in the forecasted peak values. On the other hand, some studies have predicted the opposite prevalence. Hence, there is still a clear challenge in generating a reliable prediction of how hemispheric SN will evolve, both specifically during the remainder of the current solar cycle and more generally in future cycles. Moreover, against this backdrop, to the best of the authors’ knowledge, no hemispheric SN predictions have yet been published for Solar Cycle 26.
In line with the above, by integrating two separate approaches, we herein present an innovative technique for predicting hemispheric SN until January 2038 (the remainder of Solar Cycle 25 and Solar Cycle 26). We begin by performing a spectral analysis of the considered time series to pinpoint periodicities through which we can lag the series, thus creating new attributes that we can apply in our prediction model as predictors; finally, we utilize univariate machine learning (ML) algorithms. Our aim is to introduce a technique that builds on the strengths of the two methods mentioned above, thereby benefitting from these two distinct approaches. This technique is expected to provide well-grounded predictions for hemispheric SN cycles, which will build on previous research and contribute to increasing the body of knowledge on the long-term behavior of the solar dynamo.
This document is organized as follows: Section 2 explains the data and methodology used in this study. The results obtained and our analysis are presented in Section 3. Section 4 presents the main conclusions drawn from this work.
2 Methodology
2.1 Data Description
We take our data from the extended hemispheric SN index held by the World Data Center SILSO (Clette and Lefèvre 2016) at the Royal Observatory of Belgium (ROB), Brussels (https://www.sidc.be/silso/datafiles). This dataset comprises a catalog of reconstructed hemispheric SN for the 1874 – 2020 period, thereby extending the base international hemispheric SN series, which start in 1992. Hemispheric values are based on hemispheric SN from the Kanzelhöhe and Skalnate-Pleso Observatories back until 1945, and on total sunspot areas from the Greenwich photographic catalogue back until 1874 (Veronig et al. 2021).
2.2 Data Processing
We first consider the monthly averages of the series as we are aiming to predict the evolution of the solar cycle in the long term, i.e., the SN values for both hemispheres until the maximum amplitude of Solar Cycle 26 and thereafter. Then, we calculate 13-month running averages for the time series under consideration with a smoothing function with weights = 1 for all the elements of the average, except for the first and last ones (−6 and \(+6\) months) with weights = 0.5. In this sense, note that smoothed values for the first six and the last six months of the series cannot be obtained. This will permit a simple and straightforward comparison of our results with those of other studies, strengthening the collaborative advancement of knowledge in this field. Finally, by using an average (the 13-month running mean in our case) to process the data –along with the avoidance of an overly complex model– we manage to avoid the problem of overfitting in the ML algorithms. This can occur when the model has a too-good fit with the training data and is unable to properly generalize to new data that were excluded from the training (which, among other causes, can be due to noise in the training data).
The hemispheric SN time series (Northern and Southern) can be seen in Figure 1, wherein the 13-month running average has been applied. In this sense, the period considered and number of records for both series after the application of the 13-month running average are October 1874 – May 2020 and 1748, respectively.

The considered hemispheric SN time series after application of the 13-month running average.
2.3 Time Series Fourier Transform Analysis
By using Fourier-transform-based spectral analysis, we may extract specific features of a time series, improving the predictive performance of ML algorithms (Koç and Koç 2022). Thus, we apply fast Fourier transform (FFT) to both 13-month smoothed data series. Our aim is to identify periodicities with which to lag these series (by a number of positions that are identical to these periods or multiples thereof) as long as the series have data. The resulting lagged series can then provide novel attributes or predictors that can be integrated into the dataset acting as input for the univariate predictive ML algorithms applied to each hemispheric SN series. Specifically, by examining the behavior of the time series at times lagged by a time equivalent to the identified periods (or their multiples), we may derive useful information with which to predict these series’ future behavior. In line with this, Figure 2 presents the periodograms for the two considered series, revealing the different peaks that highlight the periodicities identified here. Table 2, meanwhile, offers the values of the main periodicities as well as the number of positions in terms of the displacement of these series.

Periodograms of both series considered here (Northern hemisphere, left; Southern hemisphere, right).
2.4 ML Algorithm Implementation, Selection, and Application
We use Python (scikit-learn library) to implement the various ML models used in our approach to predicting hemispheric SN. Specifically, we employ linear regression (LR), random forest (RF), support vector machines (SVM) and Gaussian processes (GP). A comprehensive explanation of these algorithms is available in Shmueli and Lichtendahl (2016) for LR, Vapnik (2013) for SVM, Oshiro, Perez, and Baranauskas (2012) for RF, and Seeger (2004) for GP. In any case, a brief description of each of the algorithms considered in this work is provided below.
LR is a relatively simple technique for estimating the model parameters, whereby the aim is a minimization of the sum of the squared errors (Shmueli and Lichtendahl 2016). With modification, it can also incorporate partial least squares/penalized models, including ridge regression or least absolute shrinkage and selection operator (LASSO). The suitability of these models is attributed to their easy interpretation. Moreover, the calculation of the coefficients showing the relationships is straightforward, enabling the use of several features. Notably, in terms of performance, these models are somewhat limited (Faloutsos et al. 2018); however, good results are possible because the predictor/response relationship is located on a hyperplane. Nonetheless, such models may be less capable of describing nonlinear relationships if these are higher-order (e.g., cubic or quadratic), necessitating a different approach (Kalekar 2004).
Other models can be used to understand non-linear trends, whereby precise knowledge of the nonlinearity type is not required before building the model. The widely used SVM employs dual learning algorithms that calculate the data’s dot-products during processing (Vapnik 2013). A kernel function can hereby be incorporated to make sure that the dot-products are calculated correctly under variable rates (Schölkopf and Smola 2003). Consequently, SVM can indicate the hyperplane separating the examples as far as the maximum extent (maximum margin). As the max-margin criterion is used during optimization, this can prevent model overfitting while still providing solid generalization performance. In addition, due to its corresponding convex optimization formulation, SVM converges onto a global optimum, which is in contrast to other solutions, which only offer local optima (Kuhn and Johnson 2013).
Significant attention has recently been paid to a set of modeling algorithms known as Regression Trees. These models use if/then statements to pinpoint predictors that enable data partitioning; subsequently, within each subset, a model is used to forecast outcomes (Fierrez et al. 2018). Statistically speaking, it is possible to minimize any correlations between the predictors by incorporating randomness in the tree’s construction, such as in RF (Liaw and Wiener 2002). The models produced for a given set can subsequently be utilized to make forecasts based on new datasets, with the final prediction acting as the average forecast. RF models can reduce the variance by selecting robust complex learners that have low bias; this minimizes errors and allows noisy responses to be removed (Oshiro, Perez, and Baranauskas 2012).
Based on comparative strategies like Radial Basis Function Kernels (RBF: Blomqvist, Kaski, and Heinonen 2002), GP can provide good consistency overall in addition to unrestricted basic functions. In general, GP begins by deriving discernible reactions from a set of training data points (function values), and then models these as multivariate standard random features (Seeger 2004); hence, it is non-parametric. By assuming a priority distribution for the function data values, the function’s smooth operation is assured. The function values correlate closely when the compared vectors are close in terms of sensitivity and separation, and divergence creates decay. Hence, to make estimations on the unpredicted function data’s distribution, we can formulate assumptions, utilizing basic probability manipulation.
These represent diverse strategies through which we may conduct univariate analyses on time series data that contain both cyclical and nonlinear patterns, which is the case with the hemispheric SN series. In the test phase, we estimate the Root Mean Square Error (RMSE) to evaluate each algorithm’s goodness of fit. The algorithm offering the best performance is then used to provide the hemispheric SN prediction.
As previously stated, the predictive time horizon of the series is January 2038. This means that the prediction period for the Northern hemisphere SN will be from June 2020 to January 2038 (212 records) and that of the Southern hemisphere SN will be also from June 2020 to January 2038 (212 records). Hereby, we assume that the number of records reserved for the test phase in each case is identical to the number of records to be predicted from known data up until January 2038. In other words, 212 records for the Northern hemisphere SN (which, in the test phase, means from October 2002 to May 2020), and 212 for the Southern hemisphere SN (also from October 2002 to May 2020). The remaining data (after removing the data designated for the test phase) in each series (\(T = 1748-212 = 1536\) records) is dedicated to training and validation. In these phases, to adjust the hyperparameters, we employ a 3-split expanding window cross-validation (walk-forward). A fixed validation window is hereby formed by the same number of records (\(v = 212\)) as that of the test, as well as a training dataset consisting of round[\(i/3\cdot (T-v)\)] records (where \(i\) is the number of splits/iterations –from 1 to 3–). Figure 3 illustrates the expanding window cross-validation explained above and Table 3 shows the initialization parameters for the different ML algorithms carried out in this work.

Illustration of the expanding window cross-validation (walk-forward) carried out.
3 Results and Discussion
3.1 Univariate Prediction Model Construction
For the SN time series of both hemispheres, we make a prediction until the January 2038 time horizon. As described above, we assume that the series are predictors of themselves, lagged by a number of positions that is equal to their periodicities (Table 2).
Let us consider the possibility of expressing the records of each hemispheric SN series (HSN) by \(HSN_{t}^{t '}\), whereby \(t\) is the records’ time position in the original series before lagging and \(t'\) is their absolute time position (date). This way, the series under consideration for constructing each hemispheric univariate prediction model are those presented in Table 4.
Hence, we may express each hemispheric univariate prediction model as:
where \(t'\) is the present time (for each series), \(\delta \) is the predictive horizon, \(L\) is the total series length, [\(p_{1}, p_{2}, \dots , p_{k}\)] are each series’ considered periodicities (lag positions), and [\(n_{1}, n_{2}, \dots , n_{k}\)] are the maximum number of complete periods (for each periodicity) throughout the entire length \(L\) of the series. Table 5 gives the values of the above parameters for both hemispheric series.
It should be highlighted the importance of the spectral analysis of the series – with which the relevant periodicities are identified – in the construction of the ML models. Notably, as shown in Tables 4 and 5, with the lagged series considered as inputs, the univariate prediction of SN corresponding to the Northern hemisphere is obtained by taking into account the information provided by a total of \(28+18+14+7+4= 71\) predictor series (together with the original series). Meanwhile, the univariate prediction of SN for the Southern hemisphere is derived by considering the information supplied by a total of \(27+18+14+5+3= 67\) predictor series (along with the original one).
We use the four ML algorithms outlined above to perform the univariate prediction of each hemispheric SN time series, namely RF, LR, GP and SVM. In Table 6, the RMSE values of each algorithm applied in each univariate prediction model’s test phase for both hemispheric SN series are presented (the lowest RMSE value produced by the four algorithms for each series is highlighted in bold). Moreover, the table also gives the number of records used in the test phase for each case. It becomes clear that, for the two hemispheric series, the best prediction based on RMSE is due to the RF technique.
Figure 4 (top and bottom panels, for the Northern and Southern hemispheres, respectively) compare the known values based on observed data (black line) with the predictions from our model for the testing phase (red line) –which ranges from October 2002 to May 2020–. The curves present a good fit regarding the series behavior, especially in terms of the maximum amplitudes. The main discrepancies between both curves can be seen in the solar minima, the initial part of the rising phase of Solar Cycle 24 in the Northern hemisphere, and the final part of the declining phase in the Southern hemisphere.

Comparison of known (observed) data with data predicted for the testing phase of the Northern Hemisphere SN univariate prediction model (212 records) based on the RF algorithm (top panel) and the Southern Hemisphere SN univariate prediction model (212 records) based on the RF algorithm (bottom panel).
Figure 5 (top and bottom panels, for the Northern and Southern hemispheres, respectively) displays comparisons of the modeled and observed data in a training phase time slot using RF (depicted only since 1970 –as it is only an example to illustrate the model’s goodness of fit during training– and up to September 2002, which is where the records reserved for the test phase start).

Exemplified comparison of known (observed) data with modeled data for a Northern Hemisphere SN univariate prediction model’s training phase time slot (after 1970 and up to September 2002) based on RF (top panel) and a Southern Hemisphere SN univariate prediction model’s training phase slot (after 1970 and up to September 2002) based on RF (bottom panel).
The agreement is excellent, as demonstrated by this phase’s RMSE values of 1.35 for the Northern hemisphere and 1.55 for the Southern hemisphere.
3.2 Predicting Hemispheric SN for the Remainder of Solar Cycle 25 and Cycle 26
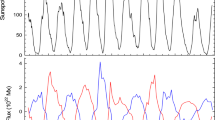
For both hemispheric SN series, Figure 6 gives the prediction curves (until January 2038) derived using the algorithm that gave the lowest value of RMSE (RF). For the Northern hemisphere, observed data are in blue and predictions are in light blue; for the Southern hemisphere, observed data are in red and predictions are in pink.

Final prediction curves for both hemispheric SN series considered here as far as January 2038. The crosses and circles mark the dates of the maximum SN values for Solar Cycles 25 and 26, respectively.
As per Figure 6, the model predicts a maximum SN of 58.5 ± 6.1 (April 2023) for Solar Cycle 25 and 51.5 ± 6.1 (November 2033) for Solar Cycle 26 for the Northern hemisphere. Regarding the Southern Hemisphere, the model predicts a maximum SN of 77.0 ± 6.8 (September 2024) for Solar Cycle 25 and 70.1 ± 6.8 (November 2034) for Solar Cycle 26 for the Southern hemisphere. Based on these results, we predict a prevalence, in terms of SN, of the Southern over the Northern hemisphere for Solar Cycles 25 and 26, which represents a continuation of the trend started in 1980, which followed the prevalence of the Northern hemisphere beginning around 1900. This fact is in agreement with most existing studies on hemispheric solar activity prediction, as indicated in the Introduction section (Hathaway and Upton 2016; Gopalswamy et al. 2018; Werner and Guineva 2020; Pishkalo 2021; Javaraiah 2022). On the other hand, the peak values obtained in the present study for Solar Cycle 25 in both solar hemispheres (North: 58.5 ± 6.1 – South: 77.0 ± 6.8) are similar to those predicted in some of the abovementioned works (Gopalswamy et al. 2018: North: 59 – South: 89; Werner and Guineva 2020: North: 49 – South: 72; Pishkalo 2021: North: 66 ± 17 – South: 83 ± 21). However, we find relevant differences with the values obtained by Prasad, Roy, and Sarkar (2024) –the work in Table1 which also used ML for Cycle 25 hemispheric SN prediction– since, although they predicted a value for the SN peak of the Northern hemisphere (56 ± 5) which is similar to the one proposed in the present manuscript, a significant lower value in the case of the Southern hemisphere (53 ± 4) was forecasted. In this sense, it should be noted that although Prasad, Roy, and Sarkar (2024) used the same smoothed sunspot number series provided by the World Data Center SILSO, that work differs from our proposal, among other aspects, in the ML method used (LSTM) and the number of splits considered for the expanding window cross-validation (5).
On the other hand, Figure 7 shows the prediction of the total SN for Solar Cycles 25 and 26 (based on adding the predicted values for both hemispheres shown previously). First, it is worth noting that, as Figure 7 shows, the estimated ascent phase for the total SN of Cycle 25 – obtained from the two hemispheric predictions previously made – coincides quite well with the already known observed values of the total SN in that phase.

Total SN prediction until January 2038 after adding the predicted values for both hemispheres. The cross and circle mark the dates of the maximum SN values for Solar Cycles 25 and 26, respectively.
On the other hand, based on our findings, we make the prediction that, for Solar Cycle 25, the total SN will reach a maximum of 127.6 ± 12.9 in September 2024 and, for Solar Cycle 26, a maximum of 117.3 ± 12.9 in November 2034. The predicted amplitude for Solar Cycle 25 is below average (of the amplitudes of Solar Cycles 1 – 24), and while it is dissimilar to the predictions from prior studies (Han and Yin 2019; McIntosh et al. 2020; McIntosh, Leamon, and Egeland 2023), it fits with the majority of the predictions listed in Nandy (2021). In a similar vein, Solar Cycle 26’s predicted maximum is slightly lower than the maximum of Solar Cycle 25 and in line with that of Solar Cycle 24 (116.4). This suggests that Solar Cycles 24, 25, and 26 could represent a minimum in the centennial Gleissberg cycle (Gleissberg, 1939, 1945), similar to Cycles 12, 13, and 14 in the final years of the 19th century and at the start of the 20th century. It should be noted that Solar Cycles 12 – 14 had an average maximum amplitude of 126.0, while our results indicate 120.4 for Solar Cycles 24 – 26. Our findings concur with the findings of Feynman and Ruzmaikin (2012, 2014) which suggested that Solar Cycles 23 and 24 could represent a Gleissberg cycle minimum.
4 Conclusions
This study develops and introduces an innovative and novel approach to predict the solar cycle regarding hemispheric SN through the use of spectral analysis with FFT and ML techniques. The lowest RMSE in the testing phase was produced by the RF algorithm for both the Northern hemisphere (6.1) and the Southern hemisphere (6.8). Based on this, we offer the following predictions for Solar Cycles 25 and 26 in terms of hemispheric SN: for the Northern hemisphere, maxima of 58.5 ± 6.1 in April 2023 and 51.5 ± 6.1 in November 2033; for the Southern hemisphere, maxima of 77.0 ± 6.8 in September 2024 and 70.1 ± 6.8 in November 2034. Thus, our results predict that, for both Solar Cycles 25 and 26, the Southern hemisphere will prevail over the Northern hemisphere regarding SN; this is in line with most of the published work offering predictions of hemispheric solar activity. Furthermore, our findings regarding the peak values in both hemispheres for Solar Cycle 25 are quite well aligned with the predictions of prior studies. In addition, we also offer a prediction regarding the total SN for Solar Cycles 25 and 26 on the basis of summing both hemispheres’ forecasted values, predicting a maximum SN in September 2024 of 127.6 ± 12.9 for Solar Cycle 25 and a maximum SN in November 2034 of 117.3 ± 12.9 for Solar Cycle 26. These findings indicate that the maximum of Solar Cycle 25 will be below average, and Solar Cycle 26 will have an even lower maximum. Based on this, we may surmise that we are approaching a minimum of the centennial Gleissberg cycle.
Data Availability
The sources of the data used in this paper are provided within the manuscript.
References
Aparicio, A.J.P., Carrasco, V.M.S., Gallego, M.C., Vaquero, J.M.: 2022, Hemispheric sunspot number from the Madrid Astronomical Observatory for the period 1935 – 1986. Astrophys. J. 931(1), 52.
Arlt, R., Vaquero, J.M.: 2020, Historical sunspot records. Living Rev. Solar Phys. 17, 1. DOI.
Ataç, T., Özgüç, A.: 1996, North-South asymmetry in the solar flare index. Solar Phys. 166, 201.
Blomqvist, K., Kaski, S., Heinonen, M.: 2002, Deep convolutional Gaussian processes. In: Proceedings of the Mining Data for Financial Applications, Ghent, Belgium, 14 – 18 September 2020, 582.
Carbonell, M., Oliver, R., Ballester, J.L.: 1993, On the asymmetry of solar activity. Astron. Astrophys. 274, 497.
Carrasco, V.M.S., Muñoz-Jaramillo, A., Gallego, M.C., Vaquero, J.M.: 2022, Revisiting Christoph Scheiner’s sunspot records: a new perspective on solar activity of the early telescopic era. Astrophys. J. 927(2), 193.
Carrasco, V.M.S., Aparicio, A.J.P., Gallego, M.C., et al.: 2023, Hemispheric sunspot numbers from the Astronomical Observatory of the University of Valencia (1940 – 1956). Solar Phys. 298, 51. DOI.
Carrington, R.C.: 1858, On the distribution of the solar spots in latitudes since the beginning of the year 1854, with a map. Mon. Not. Roy. Astron. Soc. 19, 1.
Charbonneau, P.: 2020, Dynamo models of the solar cycle. Living Rev. Solar Phys. 17, 4. DOI.
Chowdhury, P., Choudhary, D.P., Gosain, S.: 2013, A study of the hemispheric asymmetry of sunspot area during solar cycles 23 and 24. Astrophys. J. 768(2), 188. DOI.
Clark, D.H., Stephenson, F.R.: 1978, An interpretation of the pre-telescopic sunspot records from the orient. Q. J. Roy. Astron. Soc. 19, 387.
Clette, F., Lefèvre, L.: 2016, The new sunspot number: assembling all corrections. Solar Phys. 291, 2629. DOI.
Clette, F., Berghmans, D., Vanlommel, P., Van der Linden, R.A., Koeckelenbergh, A., Wauters, L.: 2007, From the wolf number to the international sunspot index: 25 years of SIDC. Adv. Space Res. 40(7), 919. DOI.
Clette, F., Svalgaard, L., Vaquero, J.M., Cliver, E.W.: 2014, Revisiting the sunspot number. A 400-year perspective on the solar cycle. Space Sci. Rev. 186, 35. DOI.
Clette, F., Lefèvre, L., Chatzistergos, T., Hayakawa, H., Carrasco, V.M.S., et al.: 2023, Re-calibration of the sunspot number: status report. Solar Phys. 298, 44. DOI.
De Freitas, D.B., De Medeiros, J.R.: 2009, Nonextensivity in the solar magnetic activity during the increasing phase of solar cycle 23. Europhys. Lett. 88(1), 19001. DOI.
Deng, L.H., Zhang, X.J., Li, G.Y., Deng, H., Wang, F.: 2019, Phase and amplitude asymmetry in the quasi-biennial oscillation of solar H\(\alpha \) flare activity. Mon. Not. Roy. Astron. Soc. 488(1), 111. DOI.
Donner, R., Thiel, M.: 2007, Scale-resolved phase coherence analysis of hemispheric sunspot activity: a new look at the North-South asymmetry. Astron. Astrophys. 475(3), L33. DOI.
Du, Z.: 2022, Evolution of the correlation between the amplitude of the solar cycle and the sunspot number since the previous declining phase in both hemispheres. Solar Phys. 297(9), 117. DOI.
Faloutsos, C., Gasthaus, J., Januschowski, T., Wang, Y.: 2018, Forecasting big time series: old and new. Proc. VLDB Endow. 11, 2102.
Feynman, J., Ruzmaikin, A.: 2012, The Centennial Gleissberg Cycle in Space Weather, AIP Conference Proceedings. 1500, American Institute of Physics, New York, 44. DOI.
Feynman, J., Ruzmaikin, A.: 2014, The centennial Gleissberg cycle and its association with extended minima. J. Geophys. Res. Space Phys. 119(8), 6027. DOI.
Fierrez, J., Morales, A., Vera-Rodriguez, R., Camacho, D.: 2018, Multiple classifiers in biometrics. Part 1: fundamentals and review. Inf. Fusion 44, 57. DOI.
Forgács-Dajka, E., Dobos, L., Ballai, I.: 2021, Time-dependent properties of sunspot groups – I. Lifetime and asymmetric evolution. Astron. Astrophys. 653, A50. DOI.
Galilei, G., Scheiner, C.: 2010, On Sunspots, University of Chicago Press, Chicago.
Gleissberg, W.: 1939, A long-periodic fluctuation of the sun-spot numbers. Observatory 62, 158.
Gleissberg, W.: 1945, Evidence for a long solar cycle. Observatory 66, 123.
Gopalswamy, N., Mäkelä, P., Yashiro, S., Akiyama, S.: 2018, Long-term solar activity studies using microwave imaging observations and prediction for cycle 25. J. Atmos. Solar-Terr. Phys. 176, 26. DOI.
Han, Y.B., Yin, Z.Q.: 2019, A decline phase modeling for the prediction of solar cycle 25. Solar Phys. 294, 107. DOI.
Hathaway, D.H.: 2015, The solar cycle. Living Rev. Solar Phys. 12, 1.
Hathaway, D.H., Upton, L.A.: 2016, Predicting the amplitude and hemispheric asymmetry of solar cycle 25 with surface flux transport. J. Geophys. Res. Space Phys. 121(11), 10. DOI.
Hoyt, D.V., Schatten, K.H.: 1998, Group sunspot numbers: a new solar activity reconstruction. Solar Phys. 179, 189. DOI.
Javaraiah, J.: 2021, North–South asymmetry in solar activity and solar cycle prediction, v: prediction for the North–South asymmetry in the amplitude of solar cycle 25. Astrophys. Space Sci. 366(1), 16. DOI.
Javaraiah, J.: 2022, Long-term variations in solar activity: predictions for amplitude and North–South asymmetry of solar cycle 25. Solar Phys. 297(3), 33. DOI.
Javaraiah, J.: 2023, Dependence of North–South difference in the slope of Joy’s law on the amplitude of solar cycle. Solar Phys. 298, 106. DOI.
Joshi, B., Joshi, A.: 2004, The North—South asymmetry of soft X-ray flare index during solar cycles 21, 22 and 23. Solar Phys. 219(2), 343. DOI.
Joshi, B., Bhattacharyya, R., Pandey, K.K., Kushwaha, U., Moon, Y.J.: 2015, Evolutionary aspects and North-South asymmetry of soft X-ray flare index during solar cycles 21, 22, and 23. Astron. Astrophys. 582, A4. DOI.
Kalekar, P.S.: 2004, Time Series Forecasting Using Holt-Winters Exponential Smoothing. Kanwal Rekhi School of Information Technology: Powai, Mumbai, 1 – 13.
Khomenko, E., Collados, M.: 2015, Oscillations and waves in sunspots. Living Rev. Solar Phys. 12, 6. DOI.
Koç, E., Koç, A.: 2022, Fractional Fourier transform in time series prediction. IEEE Signal Process. Lett. 9, 2542. DOI.
Kuhn, M., Johnson, K.: 2013, Applied Predictive Modeling, 1st edn. Springer, New York ISBN 978-1-4614-6848-6.
Labonville, F., Charbonneau, P., Lemerle, A.: 2019, A dynamo-based forecast of solar cycle 25. Solar Phys. 294, 82. DOI.
Lemerle, A., Charbonneau, P.: 2017, A coupled 2 × 2D Babcock-Leighton solar dynamo model. II. Reference dynamo solutions. Astrophys. J. 834(2), 133. DOI.
Li, K.J., Shi, X.J., Xie, J.L., Gao, P.X., Liang, H.F., Zhan, L.S., Feng, W.: 2013, Solar-cycle-related variation of solar differential rotation. Mon. Not. Roy. Astron. Soc. 433, 521. DOI.
Liaw, A., Wiener, M.: 2002, Classification and regression by random forest. R News 2, 18.
Maunder, E.W.: 1904, Note on the distribution of sun-spots in heliographic latitude, 1874-1902. Mon. Not. Roy. Astron. Soc. 64, 747. DOI.
McIntosh, S.W., Leamon, R.J., Egeland, R.: 2023, Deciphering solar magnetic activity: the (solar) Hale cycle terminator of 2021. Front. Astron. Space Sci. 10, 1050523. DOI.
McIntosh, S.W., Chapman, S., Leamon, R.J., Egeland, R., Watkins, N.W.: 2020, Overlapping magnetic activity cycles and the sunspot number: forecasting sunspot cycle 25 amplitude. Solar Phys. 295, 163. DOI.
Muñoz-Jaramillo, A., Vaquero, J.M.: 2019, Visualization of the challenges and limitations of the long-term sunspot number record. Nat. Astron. 3(3), 205. DOI.
Nandy, D.: 2021, Progress in solar cycle predictions: sunspot cycles 24-25 in perspective. Solar Phys. 296, 54. DOI.
Norton, A.A., Charbonneau, P., Passos, D.: 2015, Hemispheric coupling: comparing dynamo simulations and observations. Space Sci. Rev. 186, 251. DOI.
Oshiro, T.M., Perez, P.S., Baranauskas, J.A.: 2012, How Many Trees in a Random Forest? International Workshop on Machine Learning and Data Mining in Pattern Recognition, Springer, Berlin, 154.
Owens, B.: 2013, Long-term research: slow science. Nature 495, 300. DOI.
Pishkalo, M.I.: 2021, Prediction of solar cycle 25: maximum in the N-and S-hemispheres. Kinemat. Phys. Celest. Bodies 37, 27. DOI.
Prasad, A., Roy, S., Sarkar, A.: 2024, Hemispheric prediction of solar cycle 25 based on a deep learning technique. Adv. Space Res. 73(3), 2119. DOI.
Prasad, A., Roy, S., Ghosh, K., Panja, S.C., Patra, S.N.: 2021, Investigation of hemispherical variations of soft X-ray solar flares during solar cycles 21 to 24. Solar Syst. Res. 55, 169. DOI.
Ribes, J.C., Nesme-Ribes, E.: 1993, The solar sunspot cycle in the Maunder minimum AD1645 to AD1715. Astron. Astrophys. 276, 549.
Roy, S., Prasad, A., Ghosh, K., Panja, S.C., Patra, S.N.: 2020, Investigation of the hemispheric asymmetry in solar flare index during solar cycle 21 – 24 from the Kandilli Observatory. Solar Phys. 295, 1. DOI.
Schölkopf, B., Smola, A.J.: 2003, A short introduction to learning with kernels. In: Advanced Lectures on Machine Learning, Springer, Berlin, 41.
Schüssler, M., Cameron, R.H.: 2018, Origin of the hemispheric asymmetry of solar activity. Astron. Astrophys. 618, A89.
Schwabe, H.: 1844, Sonnenbeobachtungen im Jahre 1843. Von Herrn Hofrath Schwabe in Dessau. Astron. Nachr. 21, 233. DOI.
Seeger, M.: 2004, Gaussian processes for machine learning. Int. J. Neural Syst. 14(02), 69.
Shmueli, G., Lichtendahl, K.C. Jr.: 2016, Practical Time Series Forecasting with R: A Hands-on Guide, Axelrod Schnall Publishers, Green Cove Springs.
Sokoloff, D., Nesme-Ribes, E.: 1994, The Maunder minimum: a mixed-parity dynamo mode? Astron. Astrophys. 288(1), 293.
Spörer, G.: 1889, Sur les différences que présentent l’hémisphère nord et l’hémisphère sud du soleil. Bull. Astron. Obs. Paris 6(1), 60.
Svalgaard, L., Schatten, K.H.: 2016, Reconstruction of the sunspot group number: the backbone method. Solar Phys. 291, 2653. DOI.
Temmer, M., Veronig, A., Hanslmeier, A., Otruba, W., Messerotti, M.: 2001, Statistical analysis of solar H flares. Astron. Astrophys. 375(3), 1049. DOI.
Usoskin, I.G.: 2023, A history of solar activity over millennia. Living Rev. Solar Phys. 20, 2. DOI.
Vapnik, V.: 2013, The Nature of Statistical Learning Theory, Springer, Berlin.
Vaquero, J.M.: 2007, Historical sunspot observations: a review. Adv. Space Res. 40, 929. DOI.
Vaquero, J.M., Vázquez, M.: 2009, The Sun Recorded Through History, Springer, Berlin. DOI.
Vaquero, J.M., Svalgaard, L., Carrasco, V.M.S., Clette, F., Lefèvre, L., Gallego, M.C., Arlt, R., Aparicio, A.J.P., Richard, J.-G., Howe, R.: 2016, A revised collection of sunspot group numbers. Solar Phys. 291, 3061. DOI.
Veronig, A.M., Jain, S., Podladchikova, T., Pötzi, W., Clette, F.: 2021, Hemispheric sunspot numbers 1874 – 2020. Astron. Astrophys. 652, A56. DOI.
Vokhmyanin, M., Arlt, R., Zolotova, N.: 2020, Sunspot positions and areas from observations by Thomas Harriot. Solar Phys. 295, 39. DOI.
Waldmeier, M.: 1971, The asymmetry of solar activity in the years 1959 – 1969. Solar Phys. 20, 332.
Werner, R., Guineva, V.: 2020, Forecasting sunspot numbers for solar cycle 25 using autoregressive models for both hemispheres of the Sun. Dokl. Bolg. Akad. Nauk 73(1), 82. DOI.
Wittmann, A.D., Xu, Z.T.: 1987, A catalogue of sunspot observations from 165 BC to AD 1684. Astron. Astrophys. Suppl. Ser. 70, 83. DOI.
Wolf, R.: 1880, Astronomische Mittheilungen L. Astron. Mitt. Eidgenöss. Sternwarte Zür. 5, 269.
Xu, H., Fei, Y., Li, C., Liang, J., Tian, X., Wan, Z.: 2021, The North–South asymmetry of sunspot relative numbers based on complex network technique. Symmetry 13(11), 2228. DOI.
Zolotova, N.V., Ponyavin, D.I., Arlt, R., Tuominen, I.: 2010, Secular variation of hemispheric phase differences in the solar cycle. Astron. Nachr. 331(8), 765.
Zou, Y., Donner, R.V., Marwan, N., Small, M., Kurths, J.: 2014, Long-term changes in the North–South asymmetry of solar activity: a nonlinear dynamics characterization using visibility graphs. Nonlinear Process. Geophys. 21, 1113. DOI.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. A.J.P.A. thanks Universidad de Extremadura and Ministerio de Universidades of the Spanish Government for the award of a postdoctoral fellowship “Margarita Salas para la formación de jóvenes doctores (MS-11)”.
Author information
Authors and Affiliations
Contributions
J.-V.R., V.-M.S-C., and I.R.-R. had the idea of the manuscript. J.-V.R. made the calculations included in the manuscript and wrote the manuscript. All the authors discussed the results and revised the document, proposing improvements and providing enriching opinions.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rodríguez, JV., Sánchez Carrasco, V.M., Rodríguez-Rodríguez, I. et al. Hemispheric Sunspot Number Prediction for Solar Cycles 25 and 26 Using Spectral Analysis and Machine Learning Techniques. Sol Phys 299, 116 (2024). https://doi.org/10.1007/s11207-024-02363-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11207-024-02363-2