
Abstract
DNA carries more than the list of biochemical instructions that drive the basic functions of living systems. The sequence of base pairs includes a multitude of structural and energetic signals that determine the degree to which the long, threadlike molecule moves and how it responds to proteins and other molecules involved in its processing and packaging. The arrangements of successive base pairs in high-resolution protein-DNA crystal structures provide useful benchmarks for atomic-level simulations of double-helical DNA as well as information potentially useful in interpreting the properties of specific DNA sequences. The set of currently available structures has enough examples to characterize the conformational preferences of the DNA base-pair steps within the context of their immediate neighbors, i.e., in the context of tetramers, and reveals surprising effects of certain neighbors on local chain properties. The proteins in contact with DNA present various microenvironments that sense and/or induce the observed spatial forms. The cumulative buildup of amino-acid atoms in different protein-DNA complexes produces a binding cloud around the double helix with subtle sequence-dependent features. While the microenvironment presented by each protein to DNA is highly unique, the overall composition of amino-acid atoms within close range of DNA in a broad collection of structures is fairly uniform. The buildup of protein atoms of different types around the DNA provides new information for the improvement of nucleic acid force fields and fresh ideas for the exploration of the properties of DNA in solution.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The DNA double helix must deform in order to fit and function inside the tight confines of a cell. For example, the 2 m of DNA found in most human cells must be folded to fit in a nucleus of ~ 6 µm diameter (Alberts et al. 2022), and the base pairs must open to reveal the genetic instructions encoded along their hydrogen-bonded edges. The folding of overall structure entails large-scale bending of the double helix, and the separation of base pairs necessitates unwinding and displacement of the paired DNA strands.
The unique spatial arrangements of the double helix and the patterns of molecular association found in the ever-growing number of high-resolution DNA structures provide valuable insights into the molecular features that govern the processing and organization of the genetic material. Moreover, the sequence of bases dictates the degree to which the long, threadlike molecule deforms (Young et al. 2022) and how the duplex contacts and responds to the proteins and other molecules involved in its activity and packaging (Olson et al. 2022).
The vast majority of experimentally determined structures of DNA occur in the context of protein-DNA assemblies. The proteins impose widely different responses in the DNA, with the distortions introduced by a broad variety of proteins thought to reveal the natural rest states and conformational responses of the double helix (Olson et al. 1998). These features hint of pathways that may lead to extreme structural changes, such as atypical bending, twisting, and/or stretching and “melted” states with disrupted base pairing. The persistence of structural features within the same sequence context in numerous protein-DNA systems points to the underlying roles played by individual nucleotides in the organization and recognition of the double helix.
The spatial information in the observed structures also provides useful benchmarks for checking the state-of-the-art, atomic-level simulations increasingly employed in the treatment of DNA. The simulated structures are highly sensitive to the force fields that are applied to the individual nucleotides and are thus subject to the limitations of these treatments. DNA is difficult to deal with in that its double-helical structure is determined by both the local base-pair context and the long-range electrostatics of the sugar-phosphate backbone. Moreover, the sequence-dependent fine structure of the double helix is subtle and especially challenging to reproduce. For example, only in recent years, following improved representations of the sugar ring and its chemical links to the base and phosphate (Zgarbová et al. 2015; Ivani et al. 2016), has popular simulation software been able to bring the predicted twist-angles of individual base-pair steps into reasonable agreement with the average values of twist collected from well-resolved protein-DNA complexes (Todolli et al. 2017).
The need for reliable benchmarks increases as the technical barriers to atomic-level simulations of DNA are surmounted and studies of larger systems over longer and longer time periods become feasible. The credibility of the computed structures depends upon the extent to which the predictions match critical data. This article presents new standards gathered from the growing database of high-resolution X-ray crystallographic and cryogenic electron microscopy structures of protein-bound DNA. There is enough information now to characterize the configurational preferences of the DNA base-pair steps within the context of their immediate neighbors (Young et al. 2022) and to compare previously predicted effects of sequence context (Fujii et al. 2007; Pasi et al. 2014) with these findings. The crystallographic data also reveal a sequence-dependent buildup of different types of amino-acid atoms around the DNA bases (Olson et al. 2022) that potentially influences the observed configurations and recognition of DNA. State-of-the-art molecular simulations should aim to account for these properties as well.
Early signs of sequence-dependent DNA structure
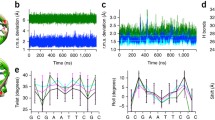
Although anticipated by the variety of helical models used to interpret the early X-ray fiber diffraction patterns of different synthetic polynucleotides (Chandrasekaran and Arnott 1989), the contributions of nucleotide sequence to DNA structure did not become clear until the determination of the first high-resolution crystal structure of the d(CGCGAATTCGCG)2 double helix, the so-called Dickerson-Drew dodecamer (Dickerson and Drew 1981). The gentle curve in the overall structure and the deformations of individual base pairs are visible to the eye in the derived atomic model (Fig. 1). Furthermore, unlike the regular models of fibrous DNA with identical arrangements of successive nucleotides, each base-pair step in the dodecamer adopts a different spatial state, both along the backbone and within the base pairs. Of particular note is the penultimate GC step along each of the self-complementary strands, which adopts a different helical form, termed BII DNA. The chain backbone undergoes large-scale conformational rearrangements at these steps along with changes in the twisting, bending, and lateral displacement of the attached base pairs.

a Molecular representations of the 1.5-Å structure of the d(CGCGAATTCGCG)2 Dickerson-Drew DNA dodecamer (Sines et al. 2000). Images of Protein Data Bank file 1fq2 (Berman et al. 2000) rendered with the NGL viewer (Rose and Hildebrand 2015; Rose et al. 2018). GC dinucleotide steps found in the unusual BII form noted by arrows. b Pictorial representations of the six rigid-body parameters used to describe the orientation and displacement of successive base pairs. Images illustrate positive values of the designated parameters, with the sequence-bearing strand on the left and the minor-groove edge (gold) facing the reader
The BII steps, noted by arrows in the illustration of one of the best-resolved dodecamer structures (Sines et al. 2000) (Fig. 1a), are overtwisted compared to the remaining steps of the molecule, and the base pairs do not align above one another in a perfectly parallel, overlapped fashion. The precise arrangement of the base pairs is described in terms of six rigid-body parameters (Fig. 1b)—three angles specifying the orientation of successive base-pair planes and the three components of the displacement vector joining successive base-pair centers (Dickerson et al. 1989; Olson et al. 2001; Lu and Olson 2003). The perturbed GC steps in the dodecamer stand out from the steps in the remainder of the molecule, with notably high values of Twist, negative values of Roll, and positive values of Slide—distortions attributed to intermolecular packing forces in the crystal lattice (Larsen et al. 1991). As noted below, the same type of large base-pair deformation occurs in the presence of proteins.
Update on DNA sequence-dependent deformations
The observed spread of DNA base-pair step parameters in high-resolution protein structures provides one of the best available estimates of the natural, sequence-dependent structure and deformability of the double-helical molecule (Olson et al. 1998).Footnote 1 The rigid-body parameters of the ten unique base-pair steps cluster in distinctive, quasi-normal distributions consistent with harmonic behavior (see representative examples in Fig. 2a). The average values are suggestive of the rest state preferred by each dimer, and the pairwise covariance of variables—i.e., the differences between the mean squares and the squares of the means of all pairs of step parameters—shows how the configurations spread over the six parameters. This statistical perspective yields a smooth landscape that connects the many distinct structural examples and offers information about the likely overall motions of neighboring base pairs.

a Comparative scatter plots of the values of Slide and Twist found in a random sample of CA·TG and AC·GT base-pair steps taken from a recently curated set of non-redundant, high-resolution protein-DNA structures (Young et al. 2022). Ellipses are projections of the six rigid-body parameters on the Slide-Twist plane at 1σ, 2σ, and 3σ “energy” levels corresponding respectively to deviations of one, two, and three standard deviations from the average configuration. b Stacking diagrams, created with 3DNA (Li et al. 2019), illustrating the overlap and hydrogen-bonding patterns (dotted lines) in the corresponding base-pair steps. Base pairs fixed in ideal Watson–Crick arrangements (Olson et al. 2001), positioned in average configurations (Table 1), and linked by the optimized backbones generated with the software. Nucleotides color-coded by identity—A red, T blue, G green, C yellow—with the 5′-nucleotide on the leading strand and the 3′-nucleotide on the complementary strand in lighter hues. See text for additional details
The average sequence-dependent twisting of base-pair steps found in a large, recently curated dataset of non-redundant protein-DNA structures (Young et al. 2022) follows the same order uncovered in early collections of DNA crystal structures (Gorin et al. 1995), with the twist of pyrimidine-purine, purine-purine, and purine-pyrimidine steps respectively increasing in the order CG < CA < TA, AG < GG < AA < GA, and AT < AC < GC (Table 1). These trends, which also occur in gels and in solution (Peck and Wang 1981; Kabsch et al. 1982; Tullius and Dombroski 1985), reflect clashes between the exocyclic atoms on the exposed edges of adjacent base pairs in combination with conformational restrictions on the sugar-phosphate backbone, namely the tendency of DNA to conserve the C1′ ⋅⋅⋅C1′ distances between the points of attachment of successive sugars to the base side groups (Calladine 1982; Gorin et al. 1995). As noted above for the Dickerson dodecamer, the twisting of base pairs is strongly correlated with Slide and Roll. One of the sources of these correlations lies in the apparent rigidity of the sugar-phosphate backbone. Changes in Twist, which directly alter the C1′⋅⋅⋅C1′ distance, must be tied to other base-pair step parameters to preserve the backbone constraints. An increase of Twist accordingly leads to a decrease in Roll and an increase in Slide. Thus, the values of Twist imply the values of other rigid-body parameters, as exemplified by the mean rigid-body parameters of the DNA base-pair steps in ~ 3900 X-ray crystallographic and cryogenic electron microscopic protein-DNA structures of 3.0 Å or better resolution (Table 1).
The correlated variations in base-pair step parameters become even clearer in scatter plots of representative data, here the values of Twist and Slide for 512 CA and 512 AC steps randomly selected from the aforementioned set of structures (Fig. 2a). The plotted data include 32 examples of each dimer in all 16 unique tetramer settings, i.e., with each dimer surrounded by all possible neighboring base pairs. The subset of data, corresponding to ~15% of the collected CA and AC steps, scatter in relatively random distributions around the mean values of Twist and Slide determined for the complete dataset (Table 1). Note the negative values of Slide that accompany the lower values of Twist in AC vs. CA steps. The most likely deformations of structure lie along the longest principal axes of the plotted data, i.e., along the long axes of the depicted ellipses. The contours of the ellipses correspond to 1σ, 2σ, and 3σ states deformed respectively by one, two, and three standard deviations from the average Twist and Slide values. The slopes of the axes reflect the sign of the correlation, e.g., the positive correlation of Twist with Slide in CA and AC steps. The magnitude of the slope reflects the strength of the correlations, e.g., more pronounced coupling of parameters for CA than AC steps. The natural deformations are a composite of all six rigid-body parameters based on the directions of the principal axes of the observed data. For example, each 1-Å increase in Slide along the largest principal axis of the depicted CA steps leads to a 0.2° decrease in Tilt, a 14.8° decrease in Roll, a 12.0° increase in Twist, a 0.11-Å decrease in Shift, and a 0.05-Å increase in Rise.
The average structures, constructed from the mean parameters of each base-pair step (Fig. 2b), highlight the differences in base overlap and twist associated with the reversal of pyrimidines and purines in dinucleotide sequences. The total overlap areas of the depicted base pairs increase from 2.7 to 10.8 Å2 with the switch from CA to AC steps. The leading CA- and AC-bearing strands, on the left side of each image, point out of the plane of the page and the complementary TG- and GT-bearing strands, on the right side, into the plane. The greater twist of the CA steps over the AC steps is evident from the greater angle between the sets of dotted lines depicting the hydrogen bonds on successive base pairs. The wider range of CA vs. AC deformations follows from the lesser overlap, i.e., weaker stacking interactions (Ornstein and Fresco 1983) of the pyrimidine-purine compared to the purine-pyrimidine dimer. Many of the large positive values of CA Twist and Slide depicted in Fig. 2b occur in concert with BII DNA backbone states, such as the kink-and-slide deformations found in the nucleosome core particle structure (Olson and Zhurkin 2011). Whereas the CA step appears to fluctuate with fairly comparable ease between under- and overtwisted states, the AC step rarely adopts overtwisted states (Fig. 2a).
Effects of sequence context on DNA structure and deformability
The large number of high-resolution protein-DNA structures in the updated dataset makes it possible to characterize the configurational preferences of DNA base-pair steps within the context of their immediate neighbors (Young et al. 2022). The data include 130–472 examples of CA steps, depending on tetrameric setting, and 148–382 such examples of AC steps. The flanking base pairs have relatively limited effects on the average configuration of the central dimers. For example, the CA step is overtwisted on average relative to the 10.6-bp repeat of mixed-sequence DNA in most settings, the exceptions being the average twist values of CA in TCAA and TCAT tetramers, which are only slightly (< 1°) lower than that of a duplex with a 10.6-bp repeat (Table 2). The AC steps, by contrast, are consistently undertwisted relative to mixed-sequence DNA. Interestingly, the AC dimers within AACT sequences are among the least undertwisted AC steps, with an average value of Twist comparable to that of the CA steps in the reversed TCAA sequence. The average twist of CA in other CA-bearing sequences exceeds that of the AC in the sequence-reversed counterpart, i.e., xCAy vs. yACx, where x and y = A, G, C, T.
The characteristic deformability of different base-pair steps also persists in most tetrameric settings, with the range of CA deformations in Twist-Roll-Slide space fairly similar in all contexts save for those within GCAT tetramers (Fig. 3a). The area of Twist-Slide space spanned by the CA steps in the latter setting is less than half that spanned by the CA steps in most other sequence contexts. The range of occupied Roll-Slide space similarly drops in GCAT tetramers compared to the ranges found within other sequences. By contrast, the typically stiff AC step becomes more flexible within TACG sequences (Fig. 3b)—the reverse of the GCAT sequence that stiffens CA steps. These differences in deformability give rise to the variation in the areas of the 3σ-ellipses enclosing the values of Slide, Twist, and Roll adopted by CA and AC dimers in each tetrameric setting, e.g., the much smaller areas occupied by CA dimers within GCAT tetramers compared to those of CA dimers in other settings and the relatively larger area filled by AC dimers in TACG settings. Here, the values of Twist and Roll adopted by the central dimer in each tetrameric sequence are plotted vs. Slide, enclosed within a pair of 3σ-ellipses on the individual grids, and placed in a higher-order 4 × 4 array such that the grids along each row share a common 5′-neighbor and those in each column a common 3′-neighbor.

Scatter-plot arrays of the Slide, Roll, and Twist values adopted by a CA·TG and b AC·GT base-pair steps in all tetrameric contexts. Observed values of Roll and Twist respectively enclosed within solid and dashed contours at the 3σ level. Values observed in each tetrameric context placed in a higher-order 4 × 4 array such that the grids along each row share a common 5′-neighbor and those in each column a common 3′-neighbor. Data taken from (Young et al. 2022)
Some of the data clusters in small distinct regions significantly displaced from the elliptical centroids, observations suggestive of highly stable states or even two-state behavior. Note, for example, the apparent local preference of CA steps to adopt undertwisted states in GCAG settings and overtwisted states in CCAT settings and the apparent bimodality of CA steps in TCAT settings. The latter step appears to jump between under- and overtwisted states near 30° and 40° Twist with concomitant changes in Slide and Roll.
The set of images also reveals changes in rigid-body coupling that accompany changes in dimer deformability. The correlations of Twist, Roll, and Slide, for example, become weaker as the CA steps stiffen within a GCAT sequence and stronger as the steps become more flexible in other settings. Note the reorientation of the 3σ-ellipses, where the slope of the longest principal axis approaches zero as the ellipses decrease in area and becomes more positive or negative as the ellipses broaden. The degree of coupling is less regular for AC steps. The differences in average rigid-body parameters among the different tetramer settings give rise to the slightly shifted positions of the ellipses on the different scatter plots.
Sequence-dependent DNA “solvation”
The examination of high-resolution protein-DNA structures further suggests that the nucleotides may contribute to the distribution of solvent molecules in the surrounding microenvironment. From the perspective of DNA, a bound protein is simply an entity presenting polar atoms capable of forming hydrogen bonds, charged atoms resembling free cations and anions, and nonpolar atoms with hydrophobic properties. When considered in such terms, a DNA-bound protein reduces to a highly ordered solvent molecule containing different types of relatively rigidly placed atomic species. In other words, the protein acts as a solvent cage fixed in place through association with DNA and limited in movement through its polypeptide chemical architecture.
Although the microenvironment presented by each protein around DNA is highly unique, the placement of different types of amino-acid atoms within close range of DNA in a small collection of non-redundant, high-resolution protein-DNA structures shows clear sequence dependence (Olson et al. 2022). The different chemical environments mirror the electronic properties of the base pairs, which, although electronically neutral, show a distinct buildup of charge around electronegative atoms and a reduction of charge around electropositive atoms (Srinivasan et al. 2009). The different placement of atoms on the four bases generates sequence-dependent electrostatic signatures that seemingly guide the accumulation of surrounding atomic species. For example, cationic atoms, such as the ammonium nitrogen on lysine, cluster in the vicinity of more electronegative sites and anionic atoms, such as the carboxylic oxygen of glutamic or aspartic acid, near more electropositive sites (Fig. 4a). Moreover, the greatest buildup of cations (blue dots) occurs in the vicinity of recognition sites with greatest negative (yellow) electrostatic potential and the greatest buildup of anions (red dots) in regions of greatest positive (green) electrostatic potential, most notably along the major-groove edges of G⋅C pairs near the electronegative O6 and N7 atoms of guanine and the electropositive N4 and C5 atoms of cytosine.

a Local ionic environment around C·G (left) and A·T (right) base pairs in high-resolution protein-DNA complexes superimposed on electrostatic potential surfaces of the base pairs (Srinivasan et al. 2009). Protein atoms within 4 Å of atoms in the base-pair fragments colored-coded by chemical type: cationic (blue) and anionic (red). View looking perpendicular to the base-pair plane with major- and minor-groove atoms located respectively on the top and bottom. White wireframe models of base pairs superimposed on solvent-excluded potential surfaces, with areas of greatest negative potential in yellow, greatest positive potential in green, and intermediate regions in red, white, and blue, respectively. b Major-groove views of the buildup of charged amino-acid atoms between the planes of successive C·G and A·T base pairs. Sugar-phosphate linkages of untwisted CA·TG (left) and AC·GT (right) steps depicted by arrows running from 5′- to 3′-nucleotides. Images taken from the video provided by (Olson et al. 2022)
While most of the amino-acid atoms in contact with the bases lie on the outer edges of the base pairs, a sizable fraction occupy “intercalation” sites between the planes of successive base pairs. A large number of these examples involve cationic atoms in the vicinity of pyrimidine C5 atoms above the upper, or so-called primary (Lavery et al. 1992), faces of cytosine and thymine, and immediately below the next nucleotide. A number of out-of-plane contacts also occur above the upper faces of purines, albeit closer on average to the base-pair plane. The different accumulation of binding sites leads, in turn, to differences in the buildup of amino-acid atoms between the planes of pyrimidine-purine vs. purine-pyrimidine base-pair steps (Fig. 4b), here illustrated by the stacking of the ion clouds found within 4 Å of individual C⋅G and A⋅T base pairs. The base pairs are shown edge-on, with the atoms in the major groove facing outward toward the reader and the sugar-phosphate linkages depicted by arrows running from the 5′- to 3′-nucleotides on each strand. The contacts on the upper faces of C and T fill the middle of a CA⋅TG step but lie on the exterior of an AC⋅GT step (Fig. 4b, left vs. right). The sites of atomic uptake within the CA and TG steps may help to fill some of the empty space between the non-overlapped C⋅G and A⋅T base pairs.
These findings, based on 233 protein-DNA structures of 2.5 Å or better resolution, are consistent with observations found in larger structural datasets (Yu et al. 2019; Biedermannová et al. 2022). Understanding how the contact patterns might be tied to sequence-dependent structural features of DNA or to different types of proteins—e.g., the extent to which solvation patterns might contribute to base-pair overlap and deformability—requires additional information, both additional structural examples and insights from reliable molecular simulations.
Prediction vs. observation
The physics-based force fields used in atomic-level simulations of DNA have the potential to uncover the forces that give rise to the sequence-dependent structural features found in high-resolution structures, such as why the CA base-pair step appears to stiffen in the context of a GCAT tetramer or seemingly to jump between under- and overtwisted forms within TCAT sequences. Simulations of small DNA duplexes initiated over 20 years ago pointed out the potential influence of sequence context on the local structure and deformability of DNA (Beveridge et al. 2004; Dixit et al. 2005). The simulations of collective atomic movements—performed over increasingly longer time periods within a surrounding cloud of water, potassium cations, and chloride anions (Fujii et al. 2007; Lavery et al. 2010; Pasi et al. 2014)—have reached the point where one can investigate the features of individual base-pair steps within a hexameric context (Balaceanu et al. 2019), i.e., examine the contributions of flanking dimers on the properties of a central base-pair step. Data are routinely collected over microsecond time periods, generating enormous numbers of configurational snapshots and sampling states outside the bounds typically imposed in analyses of high-resolution data, such as highly deformed base pairs and base-pair steps (Olson et al. 1998; Young et al. 2022).
Given that most of the aforementioned simulations were performed prior to the force-field improvements that take reasonable account of the observed sequence-dependent variation in dinucleotide Twist (Zgarbová et al. 2015; Ivani et al. 2016), many of the predictions do not match the observations reported herein. The systematically predicted undertwisting of pyrimidine-purine steps compared to experiment along with differences in simulation conditions may contribute to some of the predicted differences in the relative deformability of base-pair steps in different tetrameric contexts. For example, the CA base-pair steps generated in a series of 10-ns simulations of dodecamers are stiffened in the context of CCAA and CCAG tetramers (Fujii et al. 2007) whereas those produced within 18-mers over 100–1000-ns simulations are stiffened in the context of ACAT and ACAA tetramers (Lavery et al. 2010; Pasi et al. 2014). Neither the former prediction, based on the volumes of configuration space occupied by the simulated dimer steps, nor the latter prediction, estimated from the reported variances in Twist and Slide values, match the experimentally observed stiffening of CA steps in the context of GCAT tetramers. On the other hand, a number of the simulations draw attention to the bimodality of pyrimidine-purine base-pair steps, particularly the conformational interchange between canonical (BI) DNA and the BII form. The predicted examples include CA steps flanked by two pyrimidines (Lavery et al. 2010; Pasi et al. 2014) of the type suggested by the bimodal distributions of Twist, Roll, and Slide in TCAT sequences. The predicted frequency of occurrence of BII forms of CA steps, however, is much lower than that of AC steps, contrary to the observed distributions of base-pair step parameters in high-resolution structures.
The collection of experimental structures does not include the large proportion of undertwisted base-pair steps found to occur within particular nucleotide sequence contexts in simulations based on recent-generation DNA force fields (Zgarbová et al. 2017; Dans et al. 2019; Walther et al. 2020; Liebl and Zacharias 2021; Dohnalová and Lankaš 2022). Low-twisted states tend to occur in combination with base-pair “melting” in the observed protein-bound DNA structures. That is, one or more of the rigid-body parameters describing the orientation and displacement of complementary bases at untwisted base-pair steps—so-called buckle, propeller twist, opening, shear, slide, and stagger (Dickerson et al. 1989) — tend to lie three or more standard deviations from the mean values found for all base pairs. The violations of these limits exclude the vast majority of experimentally observed examples of DNA untwisting and thereby remove low-twist “bumps” of the type seen in the distributions of twist reported in many simulated structures.
The fact that the distributions of complementary base-pair parameters in the simulated structures span ranges of the same or lesser magnitude than those found in the culled experimental dataset (Dans et al. 2019; Dohnalová and Lankaš 2022) suggests that the untwisted steps in the simulated structures are not melted. The very low level of hydrogen-bond loss, or fraying, of Watson–Crick base pairs in these structures (Dans et al. 2019) supports this premise. The forces used to enforce hydrogen bonding, i.e., the choice of partial atomic charges, may be too strong in the simulated DNA structures. The set of partial atomic charges on the DNA bases is typically compared against quantum mechanical models of base separation along the long axis of an ideal Watson–Crick base pair, e.g., (Liebl and Zacharias 2023), as opposed to the range of base-pair deformations observed experimentally. In addition, there are C-H⋅⋅⋅O bonds that stabilize simulated, overtwisted BII states (Balaceanu et al. 2017), which, if too strong, would place too much weight on high-twist states. On the other hand, some have argued recently that hydrogen-bonding forces may not be strong enough in simulations of RNA (Kührová et al. 2019). The role, if any, of bound proteins in the “melting” of DNA base-pair steps found experimentally remains to be determined.
It should be noted that the algorithm used to obtain base-pair step parameters in the current work differs from that used to describe DNA in a number of simulations (Beveridge et al. 2004; Dixit et al. 2005; Lavery et al. 2010; Pasi et al. 2014; Dans et al. 2019; Walther et al. 2020; Liebl and Zacharias 2021). The differences lie in the approaches used to describe the rotations of base-pair reference frames. The data reported herein follow the engineering/physics-based perspective (El Hassan and Calladine 1995) implemented in the 3DNA software (Lu and Olson 2003). The description of base-pair geometry in many simulated structures follows the mathematical perspective implemented in the Curves + software (Lavery et al. 2009). Rotations are described with abstract coordinates involved in the Euler-Rodrigues formula, that obey the symmetry relations of the Cambridge convention (Dickerson et al. 1989) and have qualitative correspondence to conventional angles (Lankas et al. 2009). The values of Twist determined with Curves + differ from the values reported herein, with the differences increasing in magnitude as the DNA undergoes large deformations—e.g., differences in Twist of ~ 1° in steps resembling canonical (10.4–10.7 bp/turn) helical structures and 2–3° in overtwisted, kink-and-slide states of the type found in the nucleosome core particle (Olson and Zhurkin 2011).
Many DNA simulations have focused on the movement and accumulation of solvent molecules within and around the double-helical structure, with longer, more recent studies making it possible to examine the buildup of cations around specific oligonucleotide sequences and in different sequence contexts (Lavery et al. 2014; Pasi et al. 2015; Savelyev and MacKerell Jr 2015; Kolesnikov et al. 2021). The simulations capture the same patterns of cationic positioning seen in high-resolution structures, i.e., near the major-groove atoms of guanine and the minor-groove atoms of adenine, but have yet to keep track of the anions found to cluster around the amino groups of cytosine and adenine in high-resolution structures. Like the predictions of sequence-dependent structure and deformability, predictions of groove occupancy depend upon the simulation scheme—e.g., solvent model, DNA force field, and simulation time—along with the criteria used to define the presence of water, cations, and anions.
The observed patterns of protein-atom buildup in high-resolution structures provide useful new benchmarks for detailed atomic-level simulations of DNA, such as the relative populations of polar vs. charged atoms, i.e., water vs. cations, near different parts of DNA and the sites of preferential solvent accumulation. Recent progress in DNA force field development has taken advantage of the experimentally observed sequence-dependent double-helical structure in the validation of simulations (Zgarbová et al. 2015; Ivani et al. 2016), but not the apparent organization of different solvent species around DNA. The sites of atomic buildup, described in standard coordinate frames on the bases, can be compared with the locations of solvent atoms in similar frames on simulated structures. Future simulations that take account of both the known sequence-dependent structural features of DNA and the distribution of solvent molecules in the local microenvironment hold promise for deciphering the forces that stabilize and destabilize the double-helical molecule as it folds and functions in biological settings.
Data availability
Not applicable. This article is a review article.
Notes
There are not sufficient data to address the sequence-dependent deformability of ligand-free DNA. Crystallographic structures are limited to a relatively small number of sequences and few space groups, and there are no well-resolved cryo-electron microscopic examples to date.
References
Alberts B, Heald R, Johnson A, Morgan D, Raff M, Roberts K, Walter P, Wilson J, Hunt T (2022) Molecular Biology of the Cell (W. W. Norton & Company, New York) Seventh edition pp 1552
Balaceanu A, Buitrago D, Walther J, Hospital A, Dans PD, Orozco M (2019) Modulation of the helical properties of DNA: next-to-nearest neighbour effects and beyond. Nucleic Acids Res 47(9):4418–4430. https://doi.org/10.1093/nar/gkz255I
Balaceanu A, Pasi M, Dans PD, Hospital A, Lavery R, Orozco M (2017) The role of unconventional hydrogen bonds in determining BII propensities in B-DNA. J Phys Chem Lett 8(1):21–28. https://doi.org/10.1021/acs.jpclett.6b02451I
Berman HM, Westbrook J, Feng Z, Gilliland G, Bhat TN, Weissig H, Shindyalov IN, Bourne PE (2000) The Protein Data Bank. Nucleic Acids Res 28(1):235–242. https://doi.org/10.1093/nar/28.1.235I
Beveridge DL, Barreiro G, Byun KS, Case DA, Cheatham TE 3rd, Dixit SB, Giudice E, Lankas F, Lavery R, Maddocks JH, Osman R, Seibert E, Sklenar H, Stoll G, Thayer KM, Varnai P, Young MA (2004) Molecular dynamics simulations of the 136 unique tetranucleotide sequences of DNA oligonucleotides. I. Research design and results on d(CpG) steps. Biophys J 87(6):3799–3813. https://doi.org/10.1529/biophysj.104.045252I
Biedermannová L, Černý J, Malý M, Nekardová M, Schneider B (2022) Knowledge-based prediction of DNA hydration using hydrated dinucleotides as building blocks. Acta Crystallogr D Struct Biol D78(Pt 8):1032–1045. https://doi.org/10.1107/S2059798322006234I
Calladine CR (1982) Mechanics of sequence-dependent stacking of bases in B-DNA. J Mol Biol 161(2):343–352. https://doi.org/10.1016/0022-2836(82)90157-7I
Chandrasekaran R, Arnott S (1989) The structures of DNA and RNA helices in oriented fibers. Landolt-Börnstein Numerical Data and Functional Relationships in Science and Technology, Group VII/1b, Nucleic Acids, ed Saenger W (Springer-Verlag, Berlin), pp 31–170
Dans PD, Balaceanu A, Pasi M, Patelli AS, Petkevičiūtė D, Walther J, Hospital A, Bayarri G, Lavery R, Maddocks JH, Orozco M (2019) The static and dynamic structural heterogeneities of B-DNA: extending Calladine-Dickerson rules. Nucleic Acids Res 47(21):11090–11102. https://doi.org/10.1093/nar/gkz905I
Dickerson RE, Bansal M, Calladine CR, Diekmann S, Hunter WN, Kennard O, von Kitzing E, Lavery R, Nelson HCM, Olson WK, Saenger W, Shakked Z, Sklenar H, Soumpasis DM, Tung C-S, Wang AH-J, Zhurkin VB (1989) Definitions and nomenclature of nucleic acid structure parameters. Nucleic Acids Res 17(5):1797–1803. https://doi.org/10.1093/nar/17.5.1797I
Dickerson RE, Drew HR (1981) Structure of a B-DNA dodecamer. II. Influence of base sequence on helix structure. J Mol Biol 149(4):761–786. https://doi.org/10.1016/0022-2836(81)90357-0I
Dixit SB, Beveridge DL, Case DA, Cheatham TE 3rd, Giudice E, Lankas F, Lavery R, Maddocks JH, Osman R, Sklenar H, Thayer KM, Varnai P (2005) Molecular dynamics simulations of the 136 unique tetranucleotide sequences of DNA oligonucleotides. II: Sequence context effects on the dynamical structures of the 10 unique dinucleotide steps. Biophys J 89(6):3721–3740. https://doi.org/10.1529/biophysj.105.067397I
Dohnalová H, Lankaš F (2022) Deciphering the mechanical properties of B-DNA duplex. WIRES Comp Mol Sci 12:e1575. https://doi.org/10.1002/wcms.1575I
El Hassan MA, Calladine CR (1995) The assessment of the geometry of dinucleotide steps in double-helical DNA: a new local calculation scheme. J Mol Biol 251(5):648–664. https://doi.org/10.1006/jmbi.1995.0462I
Fujii S, Kono H, Takenaka S, Go N, Sarai A (2007) Sequence-dependent DNA deformability studied using molecular dynamics simulations. Nucleic Acids Res 35(18):6063–6074. https://doi.org/10.1093/nar/gkm627I
Gorin AA, Zhurkin VB, Olson WK (1995) B-DNA twisting correlates with base-pair morphology. J Mol Biol 247(1):34–48. https://doi.org/10.1006/jmbi.1994.0120I
Ivani I, Dans PD, Noy A, Pérez A, Faustino I, Hospital A, Walther J, Andrio P, Goñi R, Balaceanu A, Portella G, Battistini F, Gelpí JL, González C, Vendruscolo M, Laughton CA, Harris SA, Case DA, Orozco M (2016) Parmbsc1: a refined force field for DNA simulations. Nat Methods 13(1):55–58. https://doi.org/10.1038/nmeth.3658I
Kabsch W, Sander C, Trifonov EN (1982) The ten helical twist angles of B-DNA. Nucleic Acids Res 10(3):1097–1104. https://doi.org/10.1093/nar/10.3.1097I
Kolesnikov ES, Gushchin IY, Zhilyaev PA, Onufriev AV (2021) Similarities and differences between Na+ and K+ distributions around DNA obtained with three popular water models. J Chem Theory Comput 17(11):7246–7259. https://doi.org/10.1021/acs.jctc.1c00332I
Kührová P, Mlýnský V, Zgarbová M, Krepl M, Bussi G, Best RB, Otyepka M, Šponer J, Banáš P (2019) Improving the performance of the Amber RNA force field by tuning the hydrogen-bonding interactions. J Chem Theory Comput 15(5):3288–3305. https://doi.org/10.1021/acs.jctc.8b00955I
Lankas F, Gonzalez O, Heffler LM, Stoll G, Moakher M, Maddocks JH (2009) On the parameterization of rigid base and basepair models of DNA from molecular dynamics simulations. Phys Chem Chem Phys 11(45):10565–10588. https://doi.org/10.1039/b919565nI
Larsen TA, Kopka ML, Dickerson RE (1991) Crystal structure analysis of the B-DNA dodecamer CGTGAATTCACG. Biochemistry 30(18):4443–4449. https://doi.org/10.1021/bi00232a010I
Lavery R, Maddocks JH, Pasi M, Zakrzewska K (2014) Analyzing ion distributions around DNA. Nucleic Acids Res 42(12):8138–8149. https://doi.org/10.1093/nar/gku504I
Lavery R, Moakher M, Maddocks JH, Petkeviciute D, Zakrzewska K (2009) Conformational analysis of nucleic acids revisted: Curves+. Nucleic Acids Res 37(17):5917–5929. https://doi.org/10.1093/nar/gkp608I
Lavery R, Zakrzewska K, Beveridge D, Bishop TC, Case DA, Cheatham TE 3rd, Dixit S, Jayaram B, Lankas F, Laughton C, Maddocks JH, Michon A, Osman R, Orozco M, Perez A, Singh T, Spackova N, Sponer J (2010) A systematic molecular dynamics study of nearest-neighbor effects on base pair and base pair step conformations and fluctuations in B-DNA. Nucleic Acids Res 38(1):299–313. https://doi.org/10.1093/nar/gkp834I
Lavery R, Zakrzewska K, Sun J-S, Harvey SC (1992) A comprehensive classification of nucleic acid structural families based on strand direction and base pairing. Nucleic Acids Res 20(19):5011–5016. https://doi.org/10.1093/nar/20.19.5011I
Li S, Olson WK, Lu X-J (2019) Web 3DNA 2.0 for the analysis, visualization, and modeling of 3D nucleic acid structures. Nucleic Acids Res 47(W1):W26–W34. https://doi.org/10.1093/nar/gkz394I
Liebl K, Zacharias M (2021) Accurate modeling of DNA conformational flexibility by a multivariate Ising model. Proc Natl Acad Sci, USA 118(15):e2021263118. https://doi.org/10.1073/pnas.2021263118.I
Liebl K, Zacharias M (2023) The development of nucleic acids force fields: from an unchallenged past to a competitive future. Biophys J 122(14):2841–2851. https://doi.org/10.1016/j.bpj.2022.12.022I
Lu X-J, Olson WK (2003) 3DNA: a software package for the analysis, rebuilding, and visualization of three-dimensional nucleic acid structures. Nucleic Acids Res 31(17):5108–5121. https://doi.org/10.1093/nar/gkg680I
Olson WK, Bansal M, Burley SK, Dickerson RE, Gerstein M, Harvey SC, Heinemann U, Lu X-J, Neidle S, Shakked Z, Sklenar H, Suzuki M, Tung C-S, Westhof E, Wolberger C, Berman HM (2001) A standard reference frame for the description of nucleic acid base-pair geometry. J Mol Biol 313(1):229–237. https://doi.org/10.1006/jmbi.2001.4987I
Olson WK, Gorin AA, Lu X-J, Hock LM, Zhurkin VB (1998) DNA sequence-dependent deformability deduced from protein-DNA crystal complexes. Proc Natl Acad Sci, USA 95(19):11163–11168. https://doi.org/10.1073/pnas.95.19.11163I
Olson WK, Li Y, Fenley MO (2022) Insights into DNA solvation found in protein-DNA structures. Biophys J 121(24):4749–4758. https://doi.org/10.1016/j.bpj.2022.11.019I
Olson WK, Zhurkin VB (2011) Working the kinks out of nucleosomal DNA. Curr Opin Struct Biol 21(3):348–357. https://doi.org/10.1016/j.sbi.2011.03.006I
Ornstein RL, Fresco JR (1983) Correlation of Tm and sequence of DNA duplexes with ∆H computed by an improved empirical potential method. Biopolymers 22(8):1979–2000. https://doi.org/10.1002/bip.360220811I
Pasi M, Maddocks JH, Beveridge D, Bishop TC, Case DA, Cheatham T 3rd, Dans PD, Jayaram B, Lankas F, Laughton C, Mitchell J, Osman R, Orozco M, Pérez A, Petkevičiūtė D, Spackova N, Sponer J, Zakrzewska K, Lavery R (2014) μABC: a systematic microsecond molecular dynamics study of tetranucleotide sequence effects in B-DNA. Nucleic Acids Res 42(19):12272–12283. https://doi.org/10.1093/nar/gku855I
Pasi M, Maddocks JH, Lavery R (2015) Analyzing ion distributions around DNA: sequence-dependence of potassium ion distributions from microsecond molecular dynamics. Nucleic Acids Res 43(4):2412–2423. https://doi.org/10.1093/nar/gkv080I
Peck LJ, Wang JC (1981) Sequence dependence of the helical repeat of DNA in solution. Nature 292(5821):375–378. https://doi.org/10.1038/292375a0I
Rose AS, Bradley AR, Valasatava Y, Duarte JM, Prlic A, Rose PW (2018) NGL viewer: web-based molecular graphics for large complexes. Bioinformatics 34(21):3755–3758. https://doi.org/10.1093/bioinformatics/bty419I
Rose AS, Hildebrand PW (2015) NGL Viewer: a web application for molecular visualization. Nucleic Acids Res 43(W1):W576–W579. https://doi.org/10.1093/nar/gkv402I
Savelyev A, MacKerell AD Jr (2015) Differential deformability of the DNA minor groove and altered BI/BII backbone conformational equilibrium by the monovalent ions Li+, Na+, K+, and Rb+ via water-mediated hydrogen bonding. J Chem Theory Comput 11(9):4473–4485. https://doi.org/10.1021/acs.jctc.5b00508I
Sines CC, McFail-Isom L, Howerton SB, VanDerveer D, Williams LD (2000) Cations mediate B-DNA conformational heterogeneity. J Am Chem Soc 122(45):11048–11056. https://doi.org/10.1021/bi973073cI
Srinivasan AR, Sauers RR, Fenley MO, Boschitsch AH, Matsumoto A, Colasanti AV, Olson WK (2009) Properties of the nucleic-acid bases in free and Watson-Crick hydrogen-bonded states: computational insights into the sequence-dependent features of double-helical DNA. Biophys Rev 1(1):13–20. https://doi.org/10.1007/s12551-008-0003-2I
Todolli S, Perez PJ, Clauvelin N, Olson WK (2017) Contributions of sequence to the higher-order structures of DNA. Biophys J 112(3):416–426. https://doi.org/10.1016/j.bpj.2016.11.017I
Tullius TD, Dombroski BA (1985) Iron(II) EDTA used to measure the helical twist along any DNA molecule. Science 230(4726):679–681. https://doi.org/10.1126/science.2996145I
Walther J, Dans PD, Balaceanu A, Hospital A, Bayarri G, Orozco M (2020) A multi-modal coarse grained model of DNA flexibility mappable to the atomistic level. Nucleic Acids Res 48(5):e29. https://doi.org/10.1093/nar/gkaa015I
Young RT, Czapla L, Wefers ZO, Cohen BM, Olson WK (2022) Revisiting DNA sequence-dependent deformability in high-resolution structures: effects of flanking base pairs on dinucleotide morphology and global chain configuration. Life (basel) 12(5):759. https://doi.org/10.3390/life12050759I
Yu B, Pettitt BM, Iwahara J (2019) Experimental evidence of solvent-separated ion pairs as metastable states in electrostatic interactions of biological macromolecules. J Phys Chem Lett 10(24):7937–7941. https://doi.org/10.1021/acs.jpclett.9b03084I
Zgarbová M, Jurečka P, Lankaš F, Cheatham TE 3rd, Šponer J, Otyepka M (2017) Influence of BII backbone substates on DNA twist: a unified view and comparison of simulation and experiment for all 136 distinct tetranucleotide sequences. J Chem Inf Model 57(2):275–287. https://doi.org/10.1021/acs.jcim.6b00621I
Zgarbová M, Šponer J, Otyepka M, Cheatham TE 3rd, Galindo-Murillo R, Jurečka P (2015) Refinement of the sugar-phosphate backbone torsion beta for AMBER force fields improves the description of Z- and B-DNA. J Chem Theory Comput 11(12):5723–5736. https://doi.org/10.1021/acs.jctc.5b00716I
Funding
This work was generously supported by the U.S. Public Health Service under research grant GM34809.
Author information
Authors and Affiliations
Contributions
WKO conceived the ideas for the article, wrote the text, and prepared figures. RTY made substantial contributions to the conception or design of the work, prepared figures, and reviewed the text. LC made substantial contributions to the conception or design of the work and reviewed the text. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Olson, W.K., Young, R.T. & Czapla, L. DNA simulation benchmarks revealed with the accumulation of high-resolution structures. Biophys Rev 16, 275–284 (2024). https://doi.org/10.1007/s12551-024-01198-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12551-024-01198-2