
Abstract
Objective
The United States Medical Licensing Examination (USMLE) assesses physicians' competency. Passing this exam is required to practice medicine in the U.S. With the emergence of large language models (LLMs) like ChatGPT and GPT-4, understanding their performance on these exams illuminates their potential in medical education and healthcare.
Materials and methods
A PubMed literature search following the 2020 PRISMA guidelines was conducted, focusing on studies using official USMLE questions and GPT models.
Results
Six relevant studies were found out of 19 screened, with GPT-4 showcasing the highest accuracy rates of 80–100% on the USMLE. Open-ended prompts typically outperformed multiple-choice ones, with 5-shot prompting slightly edging out zero-shot.
Conclusion
LLMs, especially GPT-4, display proficiency in tackling USMLE questions. As AI integrates further into healthcare, ongoing assessments against trusted benchmarks are essential.
Article Highlights
-
(1)
GPT-4 showed accuracy rates of 80–90% on the USMLE, outperforming previous GPT models.
-
(2)
Model performance is influenced more by its inherent capabilities than by prompting methods or media elements inclusion.
-
(3)
Further assessments against trusted benchmarks are essential for the effective integration of LLM into healthcare.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The United States Medical Licensing Examination (USMLE) is mandatory to practice medicine in the United States. It is a thorough assessment of physicians' knowledge and skills, providing a standardized measure of competence for both domestic and international medical graduates[1,2,3,4]. As such, the USMLE has become a critical benchmark for medical education and is increasingly used in research as a standard for testing the capabilities of various healthcare-focused artificial intelligence (AI) tools.
Advancements in natural language processing (NLP), have led to the development of large language models (LLMs) like GPT-3 and GPT-4. These models can generate human-like text and perform various complex NLP tasks. LLMs are increasingly studied in healthcare for different applications, including aiding diagnosis, streamlining administrative tasks, and enhancing medical education [5,6,7,8]. It is critical to assess the performance of these models in a standardized manner, specifically in specialized fields like medicine [6, 9].
Research has extensively assessed the performance of LLMs, particularly GPT, across a variety of medical examinations. For instance, studies have evaluated these models on specialty exams such as the American Board of Family Medicine annual In-Training Exam (ITE) [10], as well as American Board exams in a variety of specialties such as cardiothoracic surgery [11], rhinology [12], anesthesiology [13] and orthopedics [14]. In each of these contexts, GPT-4 has demonstrated impressive results, often achieving high accuracy rates comparable to those of human test-takers.
Beyond the United States, LLMs have been evaluated in various international contexts. In the United Kingdom, GPT models were evaluated against the Membership of the Royal Colleges of Physicians (MRCP) written exams, where they showed potential in clinical decision-making [15, 16]. Studies in Germany [17], China [18], and Japan [19, 20] have similarly tested these models against respective national medical licensing exams, with findings often indicating that LLMs can perform at or near the level of medical students, further emphasizing their global applicability and effectiveness.
Additionally, GPT models have been explored for their ability to generate medical exam questions, a testament to their adaptability and the broad spectrum of their applicational potential in medical education [21, 22].
Given the important role of the USMLE in assessing medical competence, understanding LLMs abilities on this test offers valuable insights into their clinical reasoning, potential applications, and limitations in healthcare. Thus, the aim of our study was to systematically review the literature on the performance of GPT on official USMLE questions, analyze its clinical reasoning capabilities, and determine the impact of various prompting methodologies on outcomes.
In the following sections, we first outline the materials and methods used in this systematic review, detailing our literature search strategy and eligibility criteria. Next, we present the results, highlighting the accuracy of different GPT models across various USMLE steps. We then discuss the implications of these findings, considering the potential applications of GPT models in medical education and practice. Finally, we address the limitations of our study and propose directions for future research.
2 Materials and methods
2.1 Literature search
A systematic literature search was conducted for studies on GPT models’ performance on the USMLE.
We searched PubMed/MEDLINE database for articles published up to December 2023. Search keywords included “USMLE”, “United Stated Medical License Examination”, “ChatGPT”, “Large language models” and “OpenAI”. We also searched the references lists of relevant studies for any additional relevant studies. Figure 1 presents a flow diagram of the screening and inclusion process.

Flow diagram of the search and inclusion process in the study. The study followed the Preferred Reporting Items for Systematic Review and Meta-Analyses (PRISMA) guidelines. USMLE = United States Medical Licensing Examination. LLMs = Large Language Models
2.2 Eligibility criteria
We included full publications in English that evaluated the performance of GPT models on USMLE questions. We excluded papers that evaluate unofficial sources of USMLE-like questions (e.g., MedQA).
2.3 Data sets
The USMLE is a three-step exam composed of multiple-choice questions, designed to assess a physician’s knowledge and skills required for medical practice. Step 1 evaluates the examinee's understanding of basic science principles related to health, disease, and therapeutic mechanisms, with questions requiring data interpretation, including pathology and pharmacotherapy. Step 2 Clinical Knowledge (CK) assesses the application of medical knowledge and clinical science in patient care, with a focus on disease prevention and health promotion. Step 3 tests the ability to apply medical and clinical knowledge in the unsupervised practice of medicine, particularly in patient management in ambulatory settings [1].
There are two official sources for USMLE questions—USMLE Sample exam, which is freely available [23], and the NBME Self-Assessment, available for purchase at the NBME website [24]. Both include questions for Step 1, 2CK and 3. The USMLE sample exam includes 119, 120 and 137 questions for Step 1, 2CK and 3, respectively. The NMBE Self-Assessment includes 1197, 800 and 176 questions for Steps 1, 2CK and 3 [25].
2.4 Large language models
The large language models included in this study were all developed by OpenAI [26].
GPT-3 is an autoregressive model known for its ability to handle a variety of language tasks without extensive fine-tuning. GPT-3.5, a subsequent version, serves as the foundation for both ChatGPT and InstructGPT. ChatGPT is tailored to generate responses across diverse topics, while InstructGPT is designed to provide detailed answers to specific user prompts.
Both models, although sharing a foundational architecture, have been fine-tuned using different methodologies and datasets to cater to their respective purposes. GPT-4, though specifics are not fully disclosed, is recognized to have a larger scale than its predecessor GPT-3.5, indicating improvements in model parameters and training data scope [27,28,29].
2.5 Screening and synthesis
This review was reported according to the 2020 Preferred Reporting Items for Systematic Reviews and Meta-Analysis (PRISMA) guidelines [30].
3 Results
Data were extracted from six publications that evaluated the performance of GPT models on USMLE questions. The parameters evaluated in each publication are described in Table 1.
3.1 Large language models
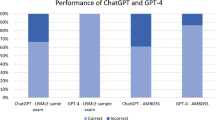
When evaluated on USMLE questions, GPT-4 outperformed all other models with accuracy rates of 80–88%, 81–89% and 81–90% in Step1, Step2CK and Step3, respectively. When tested on 21 soft skills questions from the 3 Steps together, it had 100% accuracy rate [31]. ChatGPT also had relatively good results, outperforming GPT-3, InstructGPT and GPT-3.5 with accuracy rates of 41–75%, 49–75% and 46–68% in Step1, Step2CK and Step3, respectively (Tables 2, 3 and 4). On soft skills questions, ChatGPT had accuracy of 66.6%.
3.2 Questions with media elements
Some of the USMLE questions use media elements such as graphs, images, and charts (14.4% and 13% of questions in the Self-assessment and Sample exam, accordingly) [25]. While most studies excluded these questions [27, 32, 33], two studies included them in the evaluation. A collaboration research between Microsoft and OpenAI [25], found that while GPT-4 performs best on text-only questions, it still performs well on questions with media elements, with 68–79% accuracy, despite not being able to see the relevant images. This research was conducted before the release of multimodal GPT-4 (GPT-4v), that can receive and analyze visual input [34]. It is reasonable to assume that the results might improve with GPT-4v. Another study reported similar pattern with ChatGPT, showing better accuracy with text-only items compared to items with non-text components [35].
3.3 Prompting methods
Different prompting methods were used to test the performance of the LLMs. Examples of prompts are shown in Fig. 2.

Prompt templates used to assess USMLE questions. Elements between < > are replaced with question-specific data. USMLE = United States Medical Licensing Examination
Kung et al.[32] tested three prompting options. In the Open-Ended format, answer choices were eliminated, and variable lead-in interrogative phrases were incorporated to mirror natural user queries. In the Multiple-Choice Single Answer without Forced Justification format, USMLE questions were reproduced exactly. The third format, Multiple Choice Single Answer with Forced Justification, required ChatGPT to provide rationales for each answer choice.
Nori et al.[25] also used multiple choice questions but tested both zero-shot and few-shot prompting. Zero-shot prompting requires a model to complete tasks without any prior examples, utilizing only the knowledge gained from pre-training. On the other hand, few-shot prompting provides the model with limited examples of the task at hand before execution. The model is expected to generalize from these examples and accurately perform the task.
Overall, the performance of the models was slightly affected by the prompting method, with open-ended prompting showing better results than multiple choice, and 5-shot prompting giving better results than zero-shot.
3.4 Performance assessment
All papers assessed accuracy of the models in answering USMLE questions. Two studies also included qualitative assessment of the answers and explanations provided by the LLMs. Gilson et al.[27] assessed each answer for logical reasoning (identification of the logic in the answer selection), use of information internal to the question (information that is directly provided within the question itself), and use of information external to the question (information that is not contained within the question). ChatGPT was reported to use information internal to the question in 97% of questions. The use of information external to the question was higher in correct (90–93%) answers than incorrect answers (48–63%).
In addition, every incorrect answer was labeled for the reason of the error: logical error (the response uses the pertinent information but does not translate it to the correct answer), information error (did not identify the key information needed) or statistical error (an arithmetic mistake).
Logical errors were the most common, found in 42% of incorrect answers [27]. Kung et al.[32] evaluated each output for concordance and insight, by two physician reviewers. A high concordance of 94.6% was found across ChatGPT’s answers. ChatGPT produced at least one significant insight in 88.9% of questions. The density of insight contained within the explanations provided by ChatGPT was significantly higher in questions answered accurately than in incorrect answers.
3.5 Content-based evaluation
Two studies discussed performance in questions involving specific topics. Yaneva et al.[35] found that ChatGPT performed significantly worse on items relating to practice-based learning, including biostatistics, epidemiology, research ethics and regulatory issues.
Brin et al.[31] tested only questions including communication skills, professionalism, legal and ethical issues, and reported superiority of GPT-4 in these topics.
3.6 Consistency
Various studies have examined the aspect of response consistency. Yaneva et al. reported intra-item inconsistencies in ChatGPT, with a variation noted in 20% of the USMLE sample items upon thrice replicating each question [35].
Brin et al. explored the model's tendency for self-revision, when asked “are you sure” after each response and discovered a significant alteration rate (82.5%) in initial responses of ChatGPT. GPT-4, however, showed 0% change rate [31].Mihalache et al. used two different internet browsers to input questions and observed consistent GPT-4 performance [33].
4 Discussion
This review provides a comparative analysis of GPT models performance on USMLE questions. While GPT-4 secured accuracy rates within the 80–90% range, ChatGPT demonstrated competent results, outpacing the capabilities of previous models, GPT-3, InstructGPT, and GPT-3.5.
The results of this review show that the main factor that affects performance, is the inherent capabilities of the LLM. Other factors, including various prompting methods, incorporation of questions that include media, and variability in question sets had secondary roles.
This observation emphasizes the priority of advancing core AI model development to ensure better accuracy in complex sectors like healthcare.
Prompting is considered to hold a significant role in shaping the performance of LLMs when answering queries [36, 37]. This review demonstrates that the way questions are structured can subtly influence the responses generated by these models. Notably, open-ended prompting has a slight edge over the standard multiple-choice format. This suggests that LLMs might have a subtle preference when processing information based on the context they're provided. Moreover, the marginally better outcomes with 5-shot prompting compared to zero-shot hint at the LLMs' capacity to adjust and produce informed answers when given a few guiding examples. Though these differences are subtle and may not dramatically change the overall performance, they provide insights into the optimization of interactions with LLMs.
The evaluation of AI consistency in medical knowledge assessment, as reflected in these studies, raises important discussions about the reliability and application of AI in medical education and practice. The variability in ChatGPT's responses, as seen in Yaneva et al.’s study [35], and its tendency to revise answers, noted by Brin et al.[31], point to inconsistency in AI-generated responses. Despite this inconsistency, Yaneva et al. notes that ChatGPT appears equally confident whether its answer is correct or incorrect, limiting its use as a learning aid for medical students [35].
When looking into accuracy rates for Step1 sample exam questions, the accuracy rate of ChatGPT is 36.1–69.6% [27, 32, 35]. The low accuracy rate of 36.1%, which is below the passing level of 60%, is reported when calculated with indeterminate responses included (described by the authors as responses in which the output is not an answer choice, or that determine that not enough information is available) [32]. It is noteworthy that different articles considered different number of questions as text-only items, which affected the results. When tested on the same set of questions, there is less variability (66.7–69.9% accuracy for Step1, only-text items, multiple choice prompting) [35]. Meanwhile, GPT-4 showed higher consistency [31] and a stable performance across different platforms [33]. For the same conditions described above, the accuracy rate of GPT-4 is 80.7–88% [33, 35]. These insights emphasis the importance of continuous evaluation and improvement of AI tools to ensure not just accuracy, but also stability and reliability, which are vital for their effective integration into medical training and assessment.
Two sets of formal USMLE questions were utilized in the studies reviewed. Both GPT-3.5 and GPT-4 exhibited superior performance on the Sample exam compared to the Self-assessment. While the Sample exam is publicly accessible, the Self-assessment can only be obtained through purchase. This raises the possibility that the higher accuracy is derived from previous encounters of the models with questions from the Sample exam. Nori et al.[25] developed an algorithm to detect potential signs of data leakage or memorization effects. This algorithm is designed to ascertain if specific data was likely incorporated into a model's training set. Notably, this method did not detect any evidence of training data memorization in the official USMLE datasets, which include both the Self-assessment and the Sample exam. However, it is important to note that while the algorithm demonstrates high precision (positive predictive value, PPV), its recall (sensitivity) remains undetermined. Therefore, the extent to which these models might have been exposed to the questions during their training remains inconclusive.
The proficiency of LLMs on a foundational examination such as the USMLE provides an indication of these models’ potential role in the medical domain. GPT-4's ability to achieve high accuracy levels signifies the progression of AI's capabilities in deciphering complex medical knowledge. Such advancements could be central in assisting healthcare professionals, improving diagnostic accuracy, and facilitating medical education. For medical students, LLMs could serve as supplementary tools for studying and understanding complex medical topics [38]. These models can provide instant feedback on medical practice questions and foster a deeper understanding through personalized learning experiences. By presenting varied question formats and explanations, LLMs can help students identify knowledge gaps and reinforce learning. While LLMs can offer interactive experiences that textbooks cannot, it's important to recognize their limitations and use them in addition to traditional studying methods, rather than as a replacement [39,40,41,42]. LLMs apparent proficiency in clinical knowledge raises the question of to what extent these models could be integrated into the clinical setting and replace conventional point of care tools. Currently, LLMs like GPT-4 are not reliable enough to replace existing clinical decision-making processes. However they can augment existing tools and methods by providing preliminary insights, secondary opinion and possible diagnoses [43,44,45,46,47,48]. As for patients, the publicly available LLMs can provide immediate information regarding health-related questions. This introduces both opportunities and challenges, due to the risk of misinformation [49,50,51,52]. The integration of LLMs in medical practices should be approached with caution. The USMLE's textual nature might not encompass the entire scope of clinical expertise, where skills like patient interaction [53], hands-on procedures, and ethical considerations play an important role.
In surveying the expansive literature on the application of LLMs in healthcare, only three studies are directly comparable in their use of formal question sets. This observation highlights the potential disparity in evaluation methods and emphasizes the need for standardized benchmarks in assessing LLMs' medical proficiency. The USMLE stands as a primary metric for evaluating medical students and residents in the U.S., and its role as a benchmark for LLMs warrants careful consideration. While it offers a structured and recognized platform, it is crucial to contemplate whether such standardized tests can fully encapsulate the depth and breadth of LLMs' capabilities in medical knowledge. Future research should explore alternative testing mechanisms, ensuring a comprehensive and multidimensional evaluation of LLMs in healthcare.
4.1 Limitations
This systematic review has several limitations. First, the studies reviewed primarily focused on multiple choice questions, which, although a prevalent format in the USMLE and an accepted method for assessing medical knowledge among students and clinicians, may not fully capture the complexity of real-world medical scenarios. Actual clinical cases often present with complexities and subtleties that might not strictly align with textbook descriptions. Hence, when contemplating the applicability of LLMs in a clinical setting, it is vital to recognize and account for this disparity. Secondly, our review intentionally excluded studies that examined other datasets used for USMLE preparation, such as MedQA. This decision was made to maintain consistency in the comparison of question sets. However, there is a wide array of research that evaluates various other LLMs using diverse question sets that mimic USMLE questions and measure medical proficiency. We also excluded studies that tested other LLMs, such as Med-PaLM. The exclusion of these studies potentially limits the comprehensiveness of our insights into the capabilities of LLMs in the medical domain.
5 Conclusion
This systematic review aimed to assess the performance of GPT models on the USMLE, the official exam of medical students and residents in the US. The six papers included in the review evaluated the performance of several GPT models, based on two official USMLE question sets. We found that both ChatGPT and GPT-4 achieved a passing rate, with GPT-4 outperforming its predecessors and achieving accuracy rates of 80–90%. The analysis showed that while prompting methods, such as open-ended formats, can slightly influence performance, the model’s inherent capabilities remain the primary determinant of success. This review highlights the continuous improvement in performance with newer GPT models. While all included papers used the same question sets, LLM evaluation varied due to differences in prompting methods, inclusion or exclusion of media elements, and the approach to answer analysis. The proficiency of GPT-4 in tackling USMLE questions suggests its potential use in both medical education and clinical practice. However, as this review is limited by the small number of published papers, further research is required, and ongoing assessments of LLMs against trusted benchmarks are essential to ensure their safe and effective integration into healthcare.
Data availability
No datasets were generated or analysed during the current study.
References
About the USMLE | USMLE [Internet]. [cited 2023 Aug 2]. Available from: https://www.usmle.org/about-usmle
Lombardi CV, Chidiac NT, Record BC, Laukka JJ. USMLE step 1 and step 2 CK as indicators of resident performance. BMC Med Educ. 2023;23:543.
Ozair A, Bhat V, Detchou DKE. The US residency selection process after the United states medical licensing examination step 1 pass/fail change: overview for applicants and educators. JMIR Med Educ. 2023;9: e37069.
Chaudhry HJ, Katsufrakis PJ, Tallia AF. The USMLE Step 1 decision: an opportunity for medical education and training. JAMA. 2020;323:2017–8.
Grunhut J, Marques O, Wyatt ATM. Needs, challenges, and applications of artificial intelligence in medical education curriculum. JMIR Med Educ. 2022;8: e35587.
Li R, Kumar A, Chen JH. How chatbots and large language model artificial intelligence systems will reshape modern medicine: fountain of creativity or pandora’s box? JAMA Intern Med. 2023;183:596.
Sahni NR, Carrus B. Artificial Intelligence in U.S. Health Care Delivery. In Drazen JM, Kohane IS, Leong TY, (eds.) N Engl J Med. 2023;389:348–58.
Jiang LY, Liu XC, Nejatian NP, Nasir-Moin M, Wang D, Abidin A, et al. Health system-scale language models are all-purpose prediction engines. Nature. 2023;619:357–62.
Meskó B, Topol EJ. The imperative for regulatory oversight of large language models (or generative AI) in healthcare. Npj Digit Med. 2023;6:1–6.
Hanna RE, Smith LR, Mhaskar R, Hanna K. Performance of language models on the family medicine in-training exam. Fam Med. 2024.
Khalpey Z, Kumar U, King N, Abraham A, Khalpey AH. Large language models take on cardiothoracic surgery: a comparative analysis of the performance of four models on American board of thoracic surgery exam questions in 2023. Cureus. 2024;16: e65083.
Patel EA, Fleischer L, Filip P, Eggerstedt M, Hutz M, Michaelides E, et al. Comparative performance of ChatGPT 3.5 and GPT4 on rhinology standardized board examination questions. OTO Open. 2024;8:e164
Khan AA, Yunus R, Sohail M, Rehman TA, Saeed S, Bu Y, et al. Artificial intelligence for anesthesiology board-style examination questions: role of large language models. J Cardiothorac Vasc Anesth. 2024;38:1251–9.
Isleem UN, Zaidat B, Ren R, Geng EA, Burapachaisri A, Tang JE, et al. Can generative artificial intelligence pass the orthopaedic board examination? J Orthop. 2024;53:27–33.
Vij O, Calver H, Myall N, Dey M, Kouranloo K. Evaluating the competency of ChatGPT in MRCP Part 1 and a systematic literature review of its capabilities in postgraduate medical assessments. PLoS ONE. 2024;19: e0307372.
Maitland A, Fowkes R, Maitland S. Can ChatGPT pass the MRCP (UK) written examinations? Analysis of performance and errors using a clinical decision-reasoning framework. BMJ Open. 2024;14: e080558.
Meyer A, Riese J, Streichert T. Comparison of the performance of GPT-3.5 and GPT-4 With that of medical students on the written german medical licensing examination: observational study. JMIR Med Educ. 2024;10:e50965.
Ming S, Guo Q, Cheng W, Lei B. Influence of model evolution and system roles on ChatGPT’s performance in Chinese medical licensing exams: comparative study. JMIR Med Educ. 2024;10: e52784.
Nakao T, Miki S, Nakamura Y, Kikuchi T, Nomura Y, Hanaoka S, et al. Capability of GPT-4V(ision) in the Japanese national medical licensing examination: evaluation study. JMIR Med Educ. 2024;10: e54393.
Takagi S, Watari T, Erabi A, Sakaguchi K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: Comparison Study. JMIR Med Educ. 2023;9:e48002.
Mistry NP, Saeed H, Rafique S, Le T, Obaid H, Adams SJ. Large language models as tools to generate radiology board-style multiple-choice questions. Acad Radiol. 2024;S1076–6332(24)00432-X.
Artsi Y, Sorin V, Konen E, Glicksberg BS, Nadkarni G, Klang E. Large language models for generating medical examinations: systematic review. BMC Med Educ. 2024;24:354.
Prepare for Your Exam | USMLE [Internet]. [cited 2023 Aug 7]. Available from: https://www.usmle.org/prepare-your-exam.
Taking a Self-Assessment | NBME [Internet]. [cited 2023 Aug 7]. Available from: https://www.nbme.org/examinees/self-assessments.
Nori H, King N, McKinney SM, Carignan D, Horvitz E. Capabilities of gpt-4 on medical challenge problems. ArXiv Prepr ArXiv230313375. 2023.
OpenAI Platform [Internet]. [cited 2023 Aug 2]. Available from: https://platform.openai.com.
Gilson A, Safranek CW, Huang T, Socrates V, Chi L, Taylor RA, et al. How Does ChatGPT perform on the United States medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med Educ. 2023;9: e45312.
Introducing ChatGPT [Internet]. [cited 2023 Aug 7]. Available from: https://openai.com/blog/chatgpt.
OpenAI. GPT-4 Technical Report [Internet]. arXiv; 2023 [cited 2023 Sep 5]. Available from: http://arxiv.org/abs/2303.08774.
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372: n71.
Brin D, Sorin V, Vaid A, Soroush A, Glicksberg BS, Charney AW, et al. Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments. Sci Rep. 2023;13:16492.
Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepaño C, et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digit Health. 2023;2: e0000198.
Mihalache A, Huang RS, Popovic MM, Muni RH. ChatGPT-4: An assessment of an upgraded artificial intelligence chatbot in the United States Medical Licensing Examination. Med Teach. 2023;1–7.
Yan Z, Zhang K, Zhou R, He L, Li X, Sun L. Multimodal ChatGPT for Medical Applications: an Experimental Study of GPT-4V [Internet]. arXiv; 2023 [cited 2023 Nov 17]. Available from: http://arxiv.org/abs/2310.19061.
Yaneva V, Baldwin P, Jurich DP, Swygert K, Clauser BE. Examining ChatGPT Performance on USMLE Sample Items and Implications for Assessment. Acad Med J Assoc Am Med Coll. 2023.
Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW, et al. Large language models encode clinical knowledge. Nature. 2023;1–9.
Wei J, Wang X, Schuurmans D, Bosma M, Ichter B, Xia F, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [Internet]. arXiv; 2023 [cited 2023 Aug 7]. Available from: http://arxiv.org/abs/2201.11903.
Hadi A, Tran E, Nagarajan B, Kirpalani A. Evaluation of ChatGPT as a diagnostic tool for medical learners and clinicians. PLoS ONE. 2024;19: e0307383.
Skryd A, Lawrence K. ChatGPT as a tool for medical education and clinical decision-making on the wards: case study. JMIR Form Res. 2024;8: e51346.
Mehta S, Mehta N. Embracing the illusion of explanatory depth: a strategic framework for using iterative prompting for integrating large language models in healthcare education. Med Teach. 2024;1–4.
Cherif H, Moussa C, Missaoui AM, Salouage I, Mokaddem S, Dhahri B. Appraisal of ChatGPT’s aptitude for medical education: comparative analysis with third-year medical students in a pulmonology examination. JMIR Med Educ. 2024;10: e52818.
Kang K, Yang Y, Wu Y, Luo R. Integrating large language models in bioinformatics education for medical students: opportunities and challenges. Ann Biomed Eng. 2024.
Glicksberg BS, Timsina P, Patel D, Sawant A, Vaid A, Raut G, et al. Evaluating the accuracy of a state-of-the-art large language model for prediction of admissions from the emergency room. J Am Med Inform Assoc JAMIA. 2024;ocae103.
Preiksaitis C, Ashenburg N, Bunney G, Chu A, Kabeer R, Riley F, et al. The role of large language models in transforming emergency medicine: scoping review. JMIR Med Inform. 2024;12: e53787.
Sorin V, Klang E, Sklair-Levy M, Cohen I, Zippel DB, Balint Lahat N, et al. Large language model (ChatGPT) as a support tool for breast tumor board. Npj Breast Cancer. 2023;9:44.
Barash Y, Klang E, Konen E, Sorin V. ChatGPT-4 assistance in optimizing emergency department radiology referrals and imaging selection. J Am Coll Radiol. 2023;20:998–1003.
Griewing S, Knitza J, Boekhoff J, Hillen C, Lechner F, Wagner U, et al. Evolution of publicly available large language models for complex decision-making in breast cancer care. Arch Gynecol Obstet. 2024;310:537–50.
Lahat A, Sharif K, Zoabi N, Shneor Patt Y, Sharif Y, Fisher L, et al. Assessing Generative Pretrained Transformers (GPT) in Clinical Decision-Making: Comparative Analysis of GPT-3.5 and GPT-4. J Med Internet Res. 2024;26:e54571.
Dagli MM, Oettl FC, Gujral J, Malhotra K, Ghenbot Y, Yoon JW, et al. Clinical accuracy, relevance, clarity, and emotional sensitivity of large language models to surgical patient questions: cross-sectional study. JMIR Form Res. 2024;8: e56165.
Pompili D, Richa Y, Collins P, Richards H, Hennessey DB. Using artificial intelligence to generate medical literature for urology patients: a comparison of three different large language models. World J Urol. 2024;42:455.
Girton MR, Greene DN, Messerlian G, Keren DF, Yu M. ChatGPT vs medical professional: analyzing responses to laboratory medicine questions on social media. Clin Chem. 2024;hvae093.
Lim B, Seth I, Cuomo R, Kenney PS, Ross RJ, Sofiadellis F, et al. Can AI answer my questions? utilizing artificial intelligence in the perioperative assessment for abdominoplasty patients. Aesthetic Plast Surg. 2024.
Sorin V, Brin D, Barash Y, Konen E, Charney A, Nadkarni G, et al. Large language models (LLMs) and empathy—a systematic review. medRxiv; 2023 [cited 2023 Aug 10]. p. 2023.08.07.23293769. Available from: https://doi.org/10.1101/2023.08.07.23293769v1.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
D.B. and E.Kl. conceptualized the study and developed the methodology. D.B. and E.Kl were responsible for literature search and screening. D.B wrote the initial manuscript. V.S. and E.Kl. contributed to writing the manuscript, with E.Kl. also providing supervision throughout the study. E.Ko., B.S.G., and G.N. were involved in critically reviewing and editing the manuscript. All authors approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Brin, D., Sorin, V., Konen, E. et al. How GPT models perform on the United States medical licensing examination: a systematic review. Discov Appl Sci 6, 500 (2024). https://doi.org/10.1007/s42452-024-06194-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-024-06194-5