
Abstract
During urban fire incidents, real-time videos and images are vital for emergency responders and decision-makers, facilitating efficient decision-making and resource allocation in smart city fire monitoring systems. However, real-time videos and images require simple and embeddable models in small computer systems with highly accurate fire detection ratios. YOLOv5s has a relatively small model size and fast processing time with limited accuracy. The aim of this study is to propose a method that employs a YOLOv5s network with a squeeze-and-excitation module for image filtering and classification to meet the urgent need for rapid and accurate real-time screening of irrelevant data. In this study, over 3000 internet images were used for crawling and annotating to construct a dataset. Furthermore, the YOLOv5, YOLOv5x and YOLOv5s models were developed to train and test the dataset. Comparative analysis revealed that the proposed YOLOv5s model achieved 98.2% accuracy, 92.5% recall, and 95.4% average accuracy, with a remarkable processing speed of 0.009 s per image and 0.19 s for a 35 frames-per-second video. This surpasses the performance of other models, demonstrating the efficacy of the proposed YOLOv5s for real-time screening and classification in smart city fire monitoring systems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Emergency response decision-making for urban fires necessitates careful consideration of numerous factors, especially with the increasing urbanization in China and the growing complexity of buildings and construction [1]. Obtaining timely information about emergencies or fire management is crucial for enhancing the efficiency of emergency decision-making and rationalizing the allocation of rescue resources [2]. The challenges of high operation and maintenance costs, limited usability, information lag, and incomplete coverage associated with traditional fire information collection methods underscore the need for a more advanced approach [3]. In contrast, a real-time monitoring system for fire information has proven invaluable for urban fire response and decision-making planning, incorporating real-time resource path suggestions [4,5,6]. A real-time monitoring system with integrated deep learning for fire classification contributes to more effective and timely responses to urban fire incidents, overcoming the limitations of traditional methods [4, 5].
In recent years, rapid developments in computer vision and deep learning algorithms have led to the categorization of commonly used detection algorithms into two main types. One category is the two-stage object detection network, exemplified by R-CNN (region-based neural network) [7], fast R-CNN [8], mask R-CNN [9], and similar algorithms [10]. This approach involves extracting depth features from the input image in the first stage, followed by generating and classifying candidate areas. While this method achieves low misdetection and recognition rates, its speed is relatively slow, making it unsuitable for real-time detection scenarios. The other category is the one-stage target detection network, represented by algorithms such as YOLO (you only look once) [11] and SSD (single shot multibox detector) [12]. Unlike the two-stage approach, the YOLO method directly generates target location coordinates and categories without generating candidate areas [11]. Although it has higher mismatch and missing recognition rates, it is faster and more suitable for real-time detection scenarios. An improved R-CNN network structure was proposed for fire detection and location, achieving an impressive accuracy of 94.5% and a recall rate of 97% [13]. However, the limited frames per second (fps) at 25 render is unsuitable for real-time detection scenes [13]. Conversely, a study utilized the SSD network structure with principal component analysis (PCA) for forest fire detection, achieving an accuracy of 88.2% and a faster identification speed of 46 FPS [14]. Recent studies of smart city development with automatic fire detection systems using YOLOv6 achieved 93.48% accuracy [15]. In addition, smoke and fire detection methods were proposed using YOLOv5n with 89.3% accuracy [16] and YOLOv8 with 95.7% accuracy [4]. Although the proposed models have new features for smoke detection, real-time systems have not been used in these recent studies. Therefore, training and testing of YOLO models, including real-time applications such as YOLOv3 with 0.24 s at 1 fps, are needed [17].
In urban fire scenarios, decision-makers require timely and accurate information to make informed decisions [2]. However, the vast number of images and videos in the monitoring system, including unrelated information unrelated to fires, imposes strict demands on the accuracy and speed of image screening [5, 18]. First, the YOLO method achieves nearly double the speed of the R-CNN network, although the recognition accuracy might not be optimal [19]. Second, numerous studies have successfully applied YOLO to real-time detection scenarios across diverse fields, yielding positive forest [18] and city [5, 20] fire detection outcomes. Third, the YOLO network performs target category determination and positioning in a single step, comprising only convolution layers and the input image [19]. Therefore, this approach results in an exceptionally rapid recognition speed, making it suitable for real-time detection scenarios. In this study, YOLOv5, the fifth version of the YOLO network model, surpassed its predecessors by enabling faster and more accurate detection by integrating Darknet into PyTorch [21].
In an environment without a CPU, the YOLOv5s algorithm achieved an average detection speed of 35 fps, displaying excellent detection results with a 1.1% increase in accuracy compared to YOLOv5. For instance, it achieved a model accuracy of 91.8% in construction site helmet-wearing detection [22]. While R-CNN has demonstrated functionality in detecting objects, the YOLOv2 network achieved a higher processing time and accuracy in fire and smoke detection in the fast R-CNN and R-CNN algorithms [19]. The accuracy of object detection is a primary concern in this study, and the YOLOv5 network achieves very good results, particularly in implementation, making it suitable for embedded systems on real-time monitoring systems. The development of YOLOv5 with feature fusion and extraction capabilities for remote-sensing object detection resulted in a 0.6% improvement in overall performance compared to R-CNN [23]. Previous studies have consistently highlighted that the YOLOv5 network achieves outstanding performance and processing time in object detection, making its integration into real-time fire monitoring systems promising.
In the official algorithm of YOLOv5, three versions of network models, YOLOv5s, YOLOv5x, and YOLOv5, were used in this study. The size of each YOLOv5 model mainly differs in the width and depth of the networks [24]. The testing performances and complexities of the four variants of network YOLOv5 models are shown in Fig. 1. YOLOv5 can be used for small object detection with low accuracy and is difficult to deploy in real-time platforms [25]. In YOLOv5, the neck architecture includes different modules to help find the spatial and channel-wise relationships in the features extracted by the body [26]. Furthermore, YOLOv5x can process multiple times quickly and can achieve a high level of precision on benchmark datasets [27]. YOLOv5x uses cross-stage partial (CSP) in the neck architecture to enhance the efficiency of deep neural networks (DNNs) [27]. With the deepening and widening of the network depth and width of the other models, the accuracy of AP continues to improve, but the speed consumption also continues to increase. Thus, the YOLOv5 model has the smallest width and depth, and the YOLOv5s network has the fastest speed, but the average precision (AP) accuracy is relatively low. It could be suitable for real-time target detection scenarios based on large targets with extra attention mechanism modules to enhance its AP accuracy.

Comparisons between YOLOv5m, YOLOv5l, YOLOv5x and YOLOv5s from https://github.com/ultralytics/yolov5
The YOLOv5 network model can incorporate the spatial pyramid pooling fusion (SPPF) module [18] but not the squeeze-and-excitation network (SE) module. The SPPF module represents an optimized version of spatial pyramid pooling, allowing for the detection of multiscale representations in the input feature maps, particularly for objects of varying sizes [28]. In addition, the SE module facilitates dynamic channel-wise feature recalibration, enhancing the overall performance [29]. The benefits of incorporating the SE and SPPF modules could improve real-time monitoring systems for fire detection and classification.
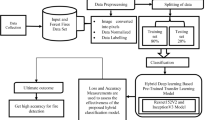
In this study, the YOLOv5s model with SE and SPPF modules and three types of YOLOv5 models (YOLOv5s, YOLOv5, and YOLOv5x) were compared and implemented for real-time fire detection. Annotated images from the internet were used to train and test the proposed model. In addition, the fire scenarios were classified into four different categories: car/vehicle, building, industrial, and normal. This categorization would facilitate distinct responses and planning for fires, as well as the allocation of manpower. Subsequently, the trained model was integrated into a real-time fire monitoring system to evaluate the real-time video processing time. Figure 2 illustrates the real-time fire monitoring system with rescue path responses. The main contributions of this study are as follows:
-
1)
The aim of this study is to demonstrate the feasibility of incorporating an attention mechanism that is crucial for enhancing the performances of the SE and SPPF modules in the YOLOv5s model.
-
2)
The performances of YOLOv5s, YOLOv5, and YOLOv5x and the proposed model on the YOLOv5s model are compared with those of the SE and SPPF modules.
-
3)
The proposed YOLOv5s model is known for its speed and ability to perform real-time fire detection. The proposed approach is suitable for smart city systems integrated with quick and timely detection of fires and responses.

Screenshots of the real-time smart city fire monitoring system: A displayed on the main screen, B showcasing secure routes and C, D promoting fire detection screens
This study presents the proposed YOLOv5 design with the SE module in Methods section. In Results section, the experimental evolution of the proposed YOLOv5 model is compared with that of YOLOv5s, YOLOv5, and YOLOv5x. The proposed YOLOv5 model was also integrated into smart city systems, and its real-time fire detection performance was demonstrated. Finally, the results are compared with those of a recent study to show the contributions in Discussion section.
2 Methods
YOLOv5s employs 12 convolutional kernels to transform the original 608 × 608 × 3 image into a 304 × 304 × 12 feature map. These configurations involve nuanced modifications to the depth and width of the feature graph, with YOLOv5s characterized by the most modest width and depth. The augmentation of residual components and convolutional kernels is a continuous process that contributes to the refinement of detection accuracy. However, this enhancement is counterbalanced by an escalated demand for computational speed. YOLOv5 comprises four similar network structures: YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x [30]. The visual representation distinctly reveals that the YOLOv5s network exhibits superior speed, albeit at the expense of the lowest AP accuracy. This attribute renders it well suited for real-time target detection scenarios, particularly those involving substantial targets.
The YOLOv5 model proposed in this study is structured into distinct components, as illustrated in Fig. 3: the input, backbone, neck, and prediction architectures. The key modules contributing to the architecture include focus, Conv-Bn-Leakyrelu (CBL), CSP, and the SPPF module. The CBL module integrates convolutional layers, batch normalization layers, and hard-wish activation functions. In the YOLOv5 model, two CSP modules known as CSP1_x and CSP2_x are employed. The CSP1_x module, combined with x residual connection units in the CSL module, enhances the ability to capture and propagate features in the backbone architecture. In the neck architecture, the CSP includes x CSL modules, which are called the CSP2_x module. Furthermore, the SPPF module is integrated into the backbone architecture to increase the pooling performance with a limited amount of program computing. The SPPF module performs max pooling with varying kernel sizes and consolidates the obtained features by concatenating them. First, the SPPF module features three MaxPool convolution layers with a size of 5 × 5 on the data serially transferred from the convolutional normalization activation function, which is convolution + batch normalization + SiLU (CBS). After that, concatenation splicing occurred on the outputs from CBS and the three MaxPools to extract richer feature information. Finally, a CBS module was used to compile the results. Through parallel pooling procedures with varying sized convolutional kernels, the spatial pyramid pooling (SPP) structure increases program computation at the expense of decreased performance [31]. Therefore, the proposed model employs the SPPF module.

Proposed YOLOv5 design with the squeeze-and-excitation network (SE) module
The backbone architecture of the YOLOv5 model is designed with the inclusion of the BottleneckCSP and Focus modules [32,33,34]. The Focus module, which is unique to the YOLOv5 model, plays a crucial role in downsampling the original 608 × 608 × 3 image to a 304 × 304 × 12 input map. This also involves passing the input maps through a convolution operation with 32 kernels, resulting in an input map of size 304 × 304 × 32.
The BottleneckCSP module functions in performing feature extraction on input maps. Based on the cross-stage partial network (CSPNet) structure, the BottleneckCSP module addresses the issue of redundancy in gradient information within the model. It integrates gradient variations into the input maps to balance the speed and accuracy trade-offs while minimizing the model size. The distinctions between YOLOv5s, YOLOv5m, YOLOv5, and YOLOv5x stem from adjustments made to the depth, width, and residual components of the BottleneckCSP module.
The proposed model incorporates an attention mechanism crucial for enhancing its performance. The attention mechanisms in this study are primarily categorized into spatial and channel attention methods. Spatial attention is dedicated to the pixel position in the image and its spatial relationships with neighboring pixels. In contrast, channel attention emphasizes the relationships between different color channels of each pixel, such as the red, green, and blue channels, in RGB images.
Integrating the SE-ResNet module with channel attention methods aims to achieve improved accuracy [29]. The SE module is applied to enhance image features through a loss function, adjusting the feature weights of valid images and reducing those of invalid images during the model training process. This strategy takes into account the typically low resolution of input maps and potential variations in target sizes. In the proposed model, the SE module is strategically placed at the end of the backbone architecture to enhance the accuracy of urban fire detection systems, as depicted by the red box in Fig. 3.
The objective of the Neck architecture is to enhance the model’s capacity to effectively detect objects across various scales, allowing it to recognize the same object at different sizes and scales. This architecture comprises two components: a feature pyramid network (FPN) [35] and a path aggregation network (PAN) [36]. The FPN adopts a top-down approach, employing upsampling to fuse feature information and generate final maps. In contrast, the PAN algorithm follows a bottom-up design, facilitating the fusion of feature information twice. The synergy of the FPN and PAN strengthens the model’s feature fusion capabilities, as illustrated in Fig. 3. The neck architecture involves three feature fusion layers, which produce new feature maps at three distinct scales: 76 × 76 × 255, 38 × 38 × 255, and 19 × 19 × 255, each with 255 channels. Notably, as the target object size decreases in the feature map, the corresponding grid unit increases in size. This finding implies that the 19 × 19 × 255 feature map is suitable for detecting large objects, while the 76 × 76 × 255 feature map is optimal for detecting small objects.
The prediction architecture serves the purpose of predicting image features, generating boundary boxes, predicting and classifying the target into its category, and calculating the associated loss. The boundary box comprises parameters such as x, y, W, H, and confidence. x and y represent the relative coordinates of the center of the boundary box within the grid. W and H represent the width and height of the bounding box, respectively, in proportion to the overall image. The confidence indicates whether the grid contains objects and the accuracy of the boundary box coordinate predictions. Equation 1 illustrates the confidence calculation, where \({\text{IOU}}_{\text{pred}}^{\text{truth}}\) represents the intersection over union (IOU) between the predicted boundary box and the true area of the object. The variable \({P}_{\text{r}}\left(\text{Object}\right)\) equals 1 if the grid contains an object and 0 if it does not:
Equation 2 defines \({\text{IOU}}_{\text{pred}}^{\text{truth}}\) as the ratio of the intersection between the predicted boundary box and the true region of the target to the union of their areas. A denotes the area of the predicted boundary box, and B denotes the area of the true region of the target:
In the prediction architecture, three types of loss functions are computed: classified loss (cls_loss), positioning loss (box_loss), and confidence loss (obj_loss). The binary cross-entropy loss function (BCE_loss), as presented in Eq. 3, is utilized for computing the classification loss. In this equation, N represents the total number of samples, yi denotes the category to which the sample belongs, and pi signifies the predicted confidence of the sample. A lower BCE_loss value indicates a higher accuracy in target classification. In other words, a reduced BCE_loss value signifies more accurate target classification. Equation 3 expresses the calculation of BCE_loss:
The positioning loss is computed using the GIOU_loss function according to Eq. 4. GIOU_loss effectively addresses the issue of distance information loss between the predicted frame and the real frame when they do not intersect. A smaller GIoU loss indicates a more accurate prediction box. Ac is the smallest convex hull that encloses both the predicted and true frames.
Equation 5 refers to the formula for the BCE Logits_loss calculation, in which the sigmoid layer was combined with the loss calculation in a multilabel classification. The BCE Logits_loss calculation could trade off the recall and precision by adding the weights to positive samples. In Eq. 5, n is the total number of samples in the batch, and c is the number of categories. When c is greater than 1, multilabel binary classification is performed. When c is equal to 1, single-label binary classification is performed. \({p}_{\text{c}}\) is the weight of the positive examples of target c. For \({p}_{\text{c}}\) greater than 1, the recall rate increases. The precision increases when \({p}_{\text{c}}\) is less than 1. Finally, the smaller the BCE Logits_loss values obtained, the more accurately the regions of detection are:
3 Materials
3724 urban fire images were obtained through web crawling, capturing a diverse range of fire types related to urban incidents, including flames unrelated to urban fires. Colabeler software (version 2.0.3, MacGenius, Blaze Software, CA, USA) was utilized for annotating target objects and categories. The labeled categories encompass various aspects of urban fires, such as building fires, industrial fires, vehicle/car fires, normal fires, and images of flames unrelated to urban fires. The labeled information is stored in text files corresponding to each image, where each line in the label file denotes target information within the image, specifying the category of the target along with the center coordinates of the detection frame and the length and width information in sequence. The proposed YOLOv5 model was chosen for training on images with a resolution of 608 × 608, which is the best resolution for the proposed model. However, the resolution of the input images was 640 × 640. Therefore, the OpenCV framework was employed in this study to resize the input images to 608 × 608. In this study, the target dataset was divided into a training set and a test set at a ratio of 9:1. The model configuration was adjusted to 4 as the number of classes (NC) parameter, the number of iterations was set to 300, and the batch size was 16. Finally, the YOLOv5 model trained on the urban fire dataset was integrated into a monitoring system for accurate and efficient data analysis. The proposed YOLOv5 model was developed in a Linux operating system with a Python 3.7 environment. The train.py file was modified to set the dataset and model weight. Table 1 provides details on the specific hardware configuration and development environment.
4 Results
Figure 4 shows the simple feature extraction results for building fire images on the proposed YOLOv5s and YOLOv5s models after training. The results obtained from the proposed model achieve 0.84% precision, but YOLOv5s achieves only 0.65% precision. Moreover, the training matrix results of the proposed YOLOv5s model are visualized using the TensorBoard tool, as shown in Fig. 5. The matrix diagram displays the declining function loss values for the forecast box, objective function, and classification function, showing notable stabilization after 180 iterations. The precision and recall exhibit a gradual increase during the iterations, reaching stability towards the conclusion of the training process.

Training feature extraction images on the proposed YOLOv5s and YOLOv5s models

Matrix diagram of the training results on the proposed YOLOv5s model
Figure 6 presents the corresponding confusion matrix of the training model. The confusion matrix obtained results indicating 87% accuracy in detecting industrial fires in the proposed YOLOv5s model, demonstrating an accuracy of 12% for falsely identified irrelevant fires. For building fires, the detection accuracy reached 94%, with 6% mistakenly identified as unrelated fires. The accuracy in detecting vehicle fires is 98%, and the detection accuracy for unrelated fires is 100%. Among the images that did not align with the prediction results, 50% were identified as building fires, and the remaining 50% were detected as unrelated normal fires.

Confusion matrix of the training results on the proposed YOLOv5s model
The proposed YOLOv5s, YOLOv5s, YOLOv5, and YOLOv5x models were trained on 3351 images and tested on 373 images. Figure 7 shows the loss results for training and validation on the proposed target and boundary results. The results are consistent with each other. Figure 8 presents the training accuracy, recall rate, mAP@0.5, and mAP@0.5:0.95 results for each model. The accuracy of the proposed YOLOv5s model is 5.3% higher than that of YOLOv5s and 1.8% higher than that of YOLOv5. However, YOLOv5x outperforms the proposed YOLOv5s with a 2.6% higher accuracy. Regarding the recall rate and mAP@0.5:0.95, the proposed YOLOv5s demonstrates similar performance to YOLOv5. Notably, the proposed YOLOv5s exhibits an 8.3% increase in the recall rate and an 8.1% increase in the mAP of 0.5:0.95 compared to both the proposed YOLOv5s and YOLOv5x.

The loss calculation plots for A training and target features, B training and feature extraction boundary regions, C validation and target features, and D validation and feature extraction boundary regions on the corresponding proposed YOLOv5s, YOLOv5s, YOLOv5, and YOLOv5x models

Plots of A precision, B recall rate, C mAP@0.5, and D mAP@0.5:0.95 for the corresponding proposed YOLOv5s, YOLOv5s, YOLOv5, and YOLOv5x models
The evaluation metrics used for assessing the trained model include \(\text{Precision}\), recall, average precision (mAP), and F1 score (F1 score). Precision is the probability of actual positive samples among all the samples predicted to be positive. The formula is shown in Eq. 6:
TP represents true-positive samples, FN represents false-negative samples, and FP represents false-positive samples. TP is a positive sample correctly detected as positive, FN is a positive sample incorrectly detected as negative, and FP is a negative sample incorrectly detected as positive. Recall is the probability of being predicted as a positive sample among samples with a positive recall rate. The formula is shown in Eq. 7:
The average precision (mAP) is the average precision across multiple validation set instances, and the formula is shown in Eq. 8. Precision and recall often have a “dilemma” relationship. The F1 score (F1 score) can be used to effectively assess the performance of two metrics and identify points that are balanced between precision and recall. The formula is shown in Eq. 9. TP (true positive) is a positive sample and is detected as a positive sample; FN (false negative) is a positive sample and is incorrectly detected as a negative sample; and FP (false positive) is a negative sample and is incorrectly detected as a positive sample:
Figure 9 displays the identified images with precision results, showcasing the boundary regions for the respective YOLO models in scenarios involving car/vehicle fires, building fires, industrial fires, and normal fires. Multiple boundary regions are obtained for industrial fires using the proposed YOLOv5s model, a feature not observed in the other models. In addition, the precision results of the proposed YOLOv5s are higher than those of the other models in this study. In Fig. 10, the results of vehicle fire detection demonstrate that both the proposed YOLOv5s and YOLOv5x models exhibit similar performances, achieving an accuracy of approximately 98%. In contrast, YOLOv5 shows the lowest detection accuracy at 92.6%. Moreover, YOLOv5s and YOLOv5 demonstrate comparable accuracy outcomes in building fire detection, achieving the accuracies of 89.3% and 90.1%, respectively. The proposed YOLOv5s surpasses the other three algorithms, attaining an accuracy of 94.3%, reflecting a 1.2% improvement compared to YOLOv5x. For industrial fire detection, the proposed YOLOv5s and YOLOv5s exhibit similar accuracies of 87.2% and 85.6%, respectively. Conversely, YOLOv5x achieved the highest detection rate for industrial fires, reaching 92.9%. In terms of irrelevant fire detection, YOLOv5s, YOLOv5, and YOLOv5x display comparable accuracies of 95.4%, 96.3%, and 94.1%, respectively. YOLOv5s exhibits a slightly lower accuracy of 89.1%. These findings provide a comprehensive overview of the model’s performance across different fire detection categories.

The recognized images with precision results and feature extraction boundary regions are presented for the corresponding YOLO models in scenarios A car/vehicle fires, B building fires, C industrial fires, and D normal fires

The bar chart illustrates the overall precision results of the proposed YOLOv5s, YOLOv5, YOLOv5x, and YOLOv5s models across scenarios, including car/vehicle fires, building fires, industrial fires, and normal fires
The precision, recall rate, average precision (mAP@0.5), and F1 score are calculated based on the true positive (TP), true negative (TN), false positive (FP), and false negative (FN) results, as shown in Table 2. YOLOv5m exhibits the lowest precision rate, recall rate, average precision, and F1 score among the four algorithms. The accuracy of the proposed YOLOv5s is comparable to that of YOLOv5, while YOLOv5x achieves the highest accuracy. This discrepancy can be attributed to the fact that accuracy is influenced only by TP and FP. However, the recall rate of YOLOv5s outperforms that of YOLOv5x, as the recall rate is dependent not only on the TP but also on the FN. YOLOv5x exhibits lower accuracy, recall rate, average precision, and F1 score than YOLOv5s, primarily due to the smaller number of underlying feature convolution layers in YOLOv5x, resulting in lower recognition accuracy for small objects. In comparison to YOLOv5x, the proposed YOLOv5s achieves an increase of 8.3% in the recall rate, 8.1% in the average precision, and 2.5% in the F1 score.
Consequently, compared with the other three algorithms, the proposed YOLOv5s provides useful results in urban fire detection. In addition, the processing time of the proposed YOLOv5s is significantly shorter, at 0.009 s per image and 0.19 s for a 35 fps video.
5 Discussion
This study conducted a comparative test on three models, namely YOLOv5s, YOLOv5, and YOLOv5x, using the same dataset in a hardware and development environment identical to that of the proposed YOLOv5s model. The proposed model not only accurately classifies flame images unrelated to fire scenes found on social platforms but also effectively detects various fire types in relevant fire scene images, marking their confidence levels. The results indicate that the effectiveness of the model increases with increasing depth and width. The proposed YOLOv5s outperforms the other three models in terms of detection speed on both images and videos at 35 fps. The results of the proposed YOLOv5s consistently indicate superior performance compared to previous fire detection studies that implemented the YOLOv3 model [29, 37]. Moreover, the outcomes show improved performance compared to previous fire detection studies that utilized Faster R-CNN for flame detection [38, 39]. In terms of efficient forest fire detection, the proposed YOLOv5 model achieves an average accuracy of 0.86 for identifying various forest fires with a processing time of 0.015 s per frame [18].
The quantitative results of fire detection are shown in Table 3, and recent results on the performance of fire detection are compared. The proposed YOLOv5s model obtains results comparable to those of new versions of YOLO, such as YOLOv8 [4]. The benefits of the attention mechanism have been demonstrated accurately. However, the recall rate is lower than that of the new version of YOLO. New versions of models might include more object detection modules to increase the complexity and improve the recall rate. Furthermore, the new version is able to detect smoke and fire at the same time, which could not be tested in the proposed model. In addition, the accuracy of automatically moving labeled bounded boxes using YOLOv3 is similar to that of the proposed model [17]. The automatic motion-labeled bounded box mechanism is designed for microchip systems with limited accuracy on blurred images, which is a limitation [17]. Another recent study also obtained similar results in which only three layers were used [5]. Therefore, the proposed YOLOv5s model could balance the trade-off between YOLO model complexity and design to maintain the precision of fire detection.
The remarkable results achieved in the proposed YOLOv5 model can be attributed to the inclusion of the SPPF and SE modules. A recent research study also reported performance improvements in YOLOv5 with SPPF modules, aligning with our findings [18]. The results indicate that multiple recognized boundary regions were detected in the proposed YOLOv5 model and overcome the limitation of detecting small objects [4, 15]. This outcome could be attributed to the incorporation of SE modules, which have demonstrated enhanced performance primarily due to the introduction of attention mechanisms. This improvement is evident in the superior capture of objects in the feature maps, addressing the challenge of small object detection. The incorporation of fire alerts into monitoring systems during the early stages of a fire enhances the ability to respond promptly, minimizing damage to human life and property. Placing the SE module at the end of the backbone architecture has proven to be beneficial for fire detection, further optimizing the model’s capabilities.
The data analysis of the experimental results revealed challenges in identifying distant car/vehicle fires. This is attributed to the YOLOv5s network compressing the image, causing the pixels representing distant car/vehicle fires to be too small for effective feature extraction, resulting in diminished recognition performance. It is crucial to address this recognition performance issue, especially as electric bikes and small cars become more commonly available on streets. Fire control of car/vehicle fires could be performed quickly and simply enough using fire extinguishers rather than firefighters. To overcome this limitation, it may be beneficial to consider increasing the width and depth of the YOLOv5s network appropriately. This adjustment can enhance its detection capabilities for distant targets, improving overall performance.
The proposed YOLOv5s model demonstrates suboptimal performance in identifying industrial fires. This limitation can be attributed to the infrequent occurrence of industrial fires compared to vehicle fires and building fires. The challenge in distinguishing between building and industrial fires arises from the similarity in the background and target object characteristics. In addition, the training dataset contains a relatively low number of images related to industrial fires, resulting in an unsatisfactory training effect and lower accuracy. To address this issue, a potential solution could involve collecting more images related to industrial fires for training to enhance the accuracy of identifying industrial fires. This approach could address the real-time allocation of manpower and firefighting equipment, leading to a more efficient response to fires.
6 Future Work
In this study, the results show that the attention mechanism could enhance the model performance. However, this approach is limited to the YOLOv5s model. For this reason, a comprehensive study could be continued to further test and validate the attention mechanism with or without other mechanisms in different versions of the YOLO model. This could further provide more research data on processing time and the performance and robustness of models for use in real-world applications, for example, smoke and/or fire detection. In addition, the proposed YOLOv5s model was trained and tested for bushfires. Bushfires can cost thousands of lives and damage millions of people, but a recent study achieved reasonable accuracy in forest fire detection [18]. A real-time monitoring system could be a good solution to protect lives and damage. Therefore, the proposed YOLOv5s model could also incorporate an additional function for bush fire detection.
While there is a technological trend to integrate fire detection functions into the cloud or Internet of Things (IoT) using advanced models such as YOLOv8 [4], there remains a preference for simple, portable, and high-performance solutions with fast processing speeds, especially in remote-sensing applications. Many devices in such scenarios may lack powerful GPUs and processing capabilities due to the need for portability and energy efficiency. In this context, the proposed YOLOv5s model proves to be a suitable choice for meeting the demand for efficient fire detection within reasonable budget constraints.
Finally, real-time fire detection requires fast and accurate methods related to model performance. As a result, the fire detection model could be integrated into microchips for bushfire or forest fire applications. The small and single microchip could be developed as a device and set up inside the national park or forest for real-time fire detection. Moreover, the autopiloted drone could be the other application of the proposed YOLOv5s model for automatic fire detection and fighting for bush fires or forest fires. However, the integration of the proposed YOLOv5s model into a single processing microchip requires funding and researchers from different research areas to achieve successful results.
7 Limitations
The results do not include images or videos with artifacts in the proposed model, as obtaining fire images with various artifacts is challenging. In addition, the use of high-resolution cameras in monitoring systems may introduce artifacts, but these artifacts can be considered negligible. Moreover, the proposed model integrates modules that are capable of detecting small objects, contributing to its effectiveness. Second, the dataset could encompass various fire scenarios, including not only vehicle and building fires but also water and forest fires. The superior accuracy in vehicle fire detection may be attributed to the greater proportion of vehicle fire images in the training set, while the lower accuracy in industrial fire detection across all algorithms is linked to the scarcity of industrial fire images in the training set, coupled with the similarity of industrial fires to building fires. Finally, the detection speed is dependent on the complexity of the proposed model and hardware. It is suggested that the proposed model should be integrated into a workstation rather than a PC computer, as the overall efficiency results on a PC computer were not obtained in this study.
8 Conclusion
This study integrates the SE module into the YOLOv5 model and conducts tests using a fire imaging library sourced from the internet with varying image resolutions. The dataset is manually annotated, and images are classified into different fire categories, thereby expanding the application scope of this method for detecting both rural and urban fires. The proposed YOLOv5 network not only improves the recognition of target images, achieving faster and more accurate results but also facilitates the classification of fires for informed decision-making during accidents. This research underscores the importance of rapidly and in real-time detecting fire accidents at their early stages to enhance safety and support effective decision-making in the event of accidents. Although the new versions of YOLO models can detect smoke and fire concurrently by increasing complexity, simple, fast and accurate fire detection YOLO models are required in real-time surveillance systems. Therefore, this capability allows the YOLOv5 network to meet the demands of real-world applications, including surveillance systems for fire detection. In future work, the system could be integrated with the IoT and/or microchips to kill fires.
Availability of Data and Materials
All the data included in this paper are available upon request.
Abbreviations
- CPU:
-
Central processing unit
- CSPNet:
-
Cross-stage partial network
- FPS:
-
Frames per second
- GPU:
-
Graphical processing units
- OS:
-
Operating system
- PCA:
-
Principal component analysis
- R-CNN:
-
Regions with convolutional neural networks
- SSD:
-
Single-shot detector
- YOLO:
-
You only look once
References
Liu, J., Ma, R., Song, Y., Dong, C.: Developing the urban fire safety co-management system in china based on public participation. Fire 6(10), 400 (2023). https://doi.org/10.3390/fire6100400
Jayawardene, V., Huggins, T.J., Prasanna, R., Fakhruddin, B.: The role of data and information quality during disaster response decision-making. Prog. Disaster Sci. 12, 100202 (2021). https://doi.org/10.1016/j.pdisas.2021.100202
Sharma, A., Kumar, R., Kansal, I., Popli, R., Khullar, V., Verma, J., Kumar, S.: Fire detection in urban areas using multimodal data and federated learning. Fire 7(4), 104 (2024). https://doi.org/10.3390/fire7040104
Talaat, Z.H.F.M.: An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 35(6), 20939–20954 (2023). https://doi.org/10.1007/s00521-023-08809-1
Avazov, K., Mukhiddinov, M., Makhmudov, F., Cho, Y.I.: Fire detection method in smart city environments using a deep-learning-based approach. Electronics 11(1), 73 (2022). https://doi.org/10.3390/electronics11010073
Chou, J.-S., Cheng, M.-Y., Hsieh, Y.-M., Yang, I.T., Hsu, H.-T.: Optimal path planning in real time for dynamic building fire rescue operations using wireless sensors and visual guidance. Autom. Constr. 99, 1–17 (2019). https://doi.org/10.1016/j.autcon.2018.11.020
Girshick, R.: Fast R-CNN. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp. 1440–1448. IEEE, Chile (2015). https://doi.org/10.1109/ICCV.2015.169
Alam, M.K., Ahmed, A., Salih, R., Al Asmari, A.F.S., Khan, M.A., Mustafa, N., Mursaleen, M., Islam, S.: Faster RCNN based robust vehicle detection algorithm for identifying and classifying vehicles. J. Real-Time Image Process. 20(5), 93 (2023). https://doi.org/10.1007/s11554-023-01344-1
Liu, Z., Yang, C., Huang, J., Liu, S., Zhuo, Y., Lu, X.: Deep learning framework based on integration of S-Mask R-CNN and Inception-v3 for ultrasound image-aided diagnosis of prostate cancer. Futur. Gener. Comput. Syst. 114, 358–367 (2021). https://doi.org/10.1016/j.future.2020.08.015
Zaidi, S.S.A., Ansari, M.S., Aslam, A., Kanwal, N., Asghar, M., Lee, B.: A survey of modern deep learning based object detection models. Digital Signal Process. 126, 103514 (2022). https://doi.org/10.1016/j.dsp.2022.103514
Bochkovskiy, A., Wang, C.-Y., Liao, H.-Y.M.: YOLOv4 Optimal speed and accuracy of object detection. arXiv (2020). https://doi.org/10.48550/arXiv.2004.10934
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., Berg, A.C.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision—ECCV 2016, pp. 21–37. Springer, Cham (2016)
Muhammad, K., Ahmad, J., Lv, Z., Bellavista, P., Yang, P., Baik, S.W.: Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 49(7), 1419–1434 (2019). https://doi.org/10.1109/TSMC.2018.2830099
Wu, S., Guo, C., Yang, J.: Using PCA and one-stage detectors for real-time forest fire detection. J. Eng. 13, 383–387 (2020). https://doi.org/10.1049/joe.2019.1145
Norkobil Saydirasulovich, S., Abdusalomov, A., Jamil, M.K., Nasimov, R., Kozhamzharova, D., Cho, Y.-I.: A YOLOv6-based improved fire detection approach for smart city environments. Sensors 23(6), 3161 (2023). https://doi.org/10.3390/s23063161
Geng, X., Su, Y., Cao, X., Li, H., Liu, L.: YOLOFM: an improved fire and smoke object detection algorithm based on YOLOv5n. Sci. Rep. 14(1), 4543 (2024). https://doi.org/10.1038/s41598-024-55232-0
Abdusalomov, A., Baratov, N., Kutlimuratov, A., Whangbo, T.K.: An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 21(19), 6519 (2021). https://doi.org/10.3390/s21196519
Li, J., Xu, R., Liu, Y.: An improved forest fire and smoke detection model based on YOLOv5. Forests 14(4), 833 (2023). https://doi.org/10.3390/f14040833
Saponara, S., Elhanashi, A., Gagliardi, A.: Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 18(24), 889–900 (2021). https://doi.org/10.1007/s11554-020-01044-0
Abdusalomov, A.B., Mukhiddinov, M., Kutlimuratov, A., Whangbo, T.K.: Improved real-time fire warning system based on advanced technologies for visually impaired people. Sensors 22(19), 7305 (2022). https://doi.org/10.3390/s22197305
Sirisha, U., Praveen, S.P., Srinivasu, P.N., Barsocchi, P., Bhoi, A.K.: Statistical analysis of design aspects of various YOLO-based deep learning models for object detection. Int. J. Comput. Intell. Syst. 16(1), 126 (2023). https://doi.org/10.1007/s44196-023-00302-w
Zhang, Y.-J., Xiao, F.-S., Lu, Z.-M.: Helmet wearing state detection based on improved YOLOv5s. Sensors 22(24), 9843 (2022). https://doi.org/10.3390/s22249843
Chen, H., Tan, S., Xie, Z., Liu, Z.: A new method based on YOLOv5 for remote sensing object detection. In: 2022 China Automation Congress (CAC),The Institute of Electrical and Electronics Engineers, US pp. 605–661 (2022). https://doi.org/10.1109/CAC57257.2022.10055729
Ren, Z., Zhang, H., Li, Z.: Improved YOLOv5 network for real-time object detection in vehicle-mounted camera capture scenarios. Sensors 23(10), 4589 (2023). https://doi.org/10.3390/s23104589
Deng, L., Bi, L., Li, H., Chen, H., Duan, X., Lou, H., Zhang, H., Bi, J., Liu, H.: Lightweight aerial image object detection algorithm based on improved YOLOv5s. Sci. Rep. 13(1), 7817 (2023). https://doi.org/10.1038/s41598-023-34892-4
Baidya, R., Jeong, H.: YOLOv5 with ConvMixer prediction heads for precise object detection in drone imagery. Sensors 22(21), 8424 (2022). https://doi.org/10.3390/s22218424
Kumar, M., Pilania, U., Thakur, S., Bhayana, T.: YOLOv5x-based brain tumor detection for healthcare applications. Proc. Comp. Sci. 233, 950–959 (2024). https://doi.org/10.1016/j.procs.2024.03.284
Chen, H., Chen, Z., Yu, H.: Enhanced yolov5: an efficient road object detection method. Sensors (2023). https://doi.org/10.3390/s23208355
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, The Institute of Electrical and Electronics Engineers, US pp. 7132–7141 (2018). https://doi.org/10.1109/CVPR.2018.00745
Ngoc-Thoan, N., Bui, D.-Q.T., Tran, C.N.N., Tran, D.-H.: Improved detection network model based on YOLOv5 for warning safety in construction sites. Int. J. Constr. Manag. (2023). https://doi.org/10.1080/15623599.2023.2171836
Zhang, M., Gao, F., Yang, W., Zhang, H.: Wildlife object detection method applying segmentation gradient flow and feature dimensionality reduction. Electronics 12(2), 377 (2023). https://doi.org/10.3390/electronics12020377
AlDahoul, N., Abdul Karim, H., Lye Abdullah, M.H., Ahmad Fauzi, M.F., Ba Wazir, A.S., Mansor, S., See, J.: Transfer detection of yolo to focus CNN’s attention on nude regions for adult content detection. Symmetry (2021). https://doi.org/10.3390/sym13010026
Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. In: 2017 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, The Institute of Electrical and Electronics Engineers, US pp. 7263–7271 (2017). https://doi.org/10.1109/CVPR.2017.690
Cheng, G., Si, Y., Hong, H., Yao, X., Guo, L.: Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 18(3), 431–435 (2021). https://doi.org/10.1109/LGRS.2020.2975541
Liu, S., Qi, L., Qin, H., Shi, J., Jia, J.: Path aggregation network for instance segmentation. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, The Institute of Electrical and Electronics Engineers, US pp. 8759–8768 (2018). https://doi.org/10.1109/CVPR.2018.00913
Kumar, M., Bhatia, R., Rattan, D.: A survey of web crawlers for information retrieval. WIREs Data Min. Knowl. Discov. 7(6), 1218 (2017). https://doi.org/10.1002/widm.1218
Li, Y., Shen, Z., Li, J., Xu, Z.: A deep learning method based on SRN-YOLO for forest fire detection. In: 2022 5th International Symposium on Autonomous Systems (ISAS), The Institute of Electrical and Electronics Engineers, US pp. 1–6 (2022). https://doi.org/10.1109/ISAS55863.2022.9757300
Barmpoutis, P., Dimitropoulos, K., Kaza, K., Grammalidis, N.: Fire detection from images using faster R-CNN and multidimensional texture analysis. In: ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), The Institute of Electrical and Electronics Engineers, US pp. 8301–8305 (2019)
Chaoxia, C., Shang, W., Zhang, F.: Information-guided flame detection based on faster R-CNN. IEEE Access 8, 58923–58932 (2020). https://doi.org/10.1109/ACCESS.2020.2982994
Acknowledgements
The authors would like to thank the anonymous reviewers and editor for their insightful comments.
Funding
This research work was supported by the 2023 Shaanxi Province “Innovation Driven Development Strategy for Higher Education Services” research project (2023HZ1337) and the Open Project Funding Project of the Key Laboratory of Modern Teaching Technology of the Ministry of Education of China (2023KF05).
Author information
Authors and Affiliations
Contributions
All the authors conceived the ideas, drafted the paper, implemented the algorithm, conducted the analyses, and wrote the manuscript. WY and YW contributed to the data analysis of the algorithm results, and the results were obtained for comparison. All the authors participated in reading and approving the final manuscript.
Corresponding author
Ethics declarations
Conflicts of Interest
The authors declare that they have no conflicts of interest.
Ethical Approval
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, W., Wu, Y. & Chow, S.K.K. Deep Learning Method for Real-Time Fire Detection System for Urban Fire Monitoring and Control. Int J Comput Intell Syst 17, 216 (2024). https://doi.org/10.1007/s44196-024-00592-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00592-8