
Abstract
Currently, the field of neurobiology of language is based on data from only a few Indo-European languages. The majority of this data comes from younger adults neglecting other age groups. Here we present a multimodal database which consists of task-based and resting state fMRI, structural MRI, and EEG data while participants over 65 years old listened to sections of the story The Little Prince in Cantonese. We also provide data on participants’ language history, lifetime experiences, linguistic and cognitive skills. Audio and text annotations, including time-aligned speech segmentation and prosodic information, as well as word-by-word predictors such as frequency and part-of-speech tagging derived from natural language processing (NLP) tools are included in this database. Both MRI and EEG data diagnostics revealed that the data has good quality. This multimodal database could advance our understanding of spatiotemporal dynamics of language comprehension in the older population and help us study the effects of healthy aging on the relationship between brain and behaviour.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background & Summary
Language comprehension in daily life is a process which does not happen in a vacuum; the environment could be noisy, people have different speaking rates (some speak faster than others), and sociocultural variables such as social class might influence what variety of language people speak. Most of the research in the neurobiology of language is done on linguistic processes which are not representative of the language used in natural contexts. There is, however, an increasing interest in doing research using more naturalistic tasks (See Table S1 for a list of published databases on naturalistic language). Naturalistic data could be more reliable and ecologically valid because such data is representative of what the brain does in real life1. Using naturalistic data, researchers can study language at different levels of language (word, phrase, sentence, and discourse) at the same time and investigate how these levels interact with each other2.
Language comprehension is usually studied using techniques such as fMRI and M/EEG. fMRI has an advantage in spatial resolution showing where exactly in the brain a mental process happens. However, in studying language temporal dynamics are as important as spatial correlates. MEG and EEG have great temporal resolution making them valuable tools for studies of language comprehension. Almost all previous naturalistic databases have used fMRI neglecting to cater for questions about temporal dynamics of language3 (see Table S1). There is a need for naturalistic studies which provide data on spatiotemporal dynamics of language.
Research shows that the majority of previous studies in psycholinguistics (85%) are done in only 10 languages with English accounting for 30% of the published studies4. Most Indo-European languages are very similar in terms of morpho-syntactic properties and script. More research needs to be done on understudied languages which have different properties. This could accommodate more diversity in the research on neurobiology of language and help the findings be more representative of the world’s population.
One issue with prior naturalistic research is that they have only provided data on healthy younger adults (See Table S1) neglecting other populations such as children and older adults. The World Population Aging Report5 shows that the population of seniors aged 65 years and over will double in the next three decades. This means that all stakeholders need to be ready to embrace this population shift. It will be, therefore, very important to study how healthy aging could influence the relation between brain and behavior, particularly in naturalistic settings where the cognitive demands could be higher for older people.
We know that healthy aging is usually accompanied by individual differences in cognitive decline6. Any database on language in older adults should also provide information about key cognitive skills which are involved in language comprehension if resources are available. Without data on cognitive functions, it will be difficult to document the role of individual differences in language comprehension in healthy aging. Only one database (see1) has provided such data.
In this study, we present a database which includes 52 Cantonese speakers (over 65 years old) listening to 20 minutes of the story The Little Prince. We collected both fMRI (task based and resting state) and EEG data from the same participants. Data on language history and lifetime experiences as well as behavioural data about linguistic skills and cognitive functions such as inhibition, short-term memory, processing speed, verbal fluency, and picture naming speed were collected. We think this is the first naturalistic database on older people which provides both fMRI and EEG data as well as extensive cognitive data for each participant. This valuable contribution aligns with our vision for the LPP database expansion7, incorporating diverse modalities, languages, and annotations to foster interdisciplinary research in psycho- and neurolinguistics.
Methods
Participants
We recruited 52 healthy, right-handed older Cantonese participants (40 females, mean age = 69.12, SD = 3.52) from Hong Kong for the experiment, which consists of an fMRI and an EEG session. In both sessions, participants listened to the same sections of The Little Prince in Cantonese for approximately 20 minutes. We made sure each participant was right-handed and a native Cantonese speaker using the Language History Questionnaire8 (LHQ3). Additionally, participants reported normal or corrected normal hearing. They confirmed they had no cognitive decline. Two participants did not take part in the fMRI session and an additional 4 participants’ fMRI data were removed due to excessive head movement, resulting in a total of 46 participants (39 females, mean age = 69.08 yrs, SD = 3.58) for the fMRI session and 52 participants (40 females, mean age = 69.12 yrs, SD = 3.52) for the EEG session. Table S2 shows participants’ demographic information and quiz response accuracy. Prior to the experiment, all participants were provided with written informed consent. All participants received monetary compensation after each session. Ethical approval was obtained from the Human Subjects Ethics Application Committee at the Hong Kong Polytechnic University (application number HSEARS20210302001). This study was performed in accordance with the Declaration of Helsinki and all other regulations set by the Ethics Committee.
Procedures
The study consisted of an fMRI session and an EEG session. The order of the EEG and fMRI sessions was counterbalanced across all participants, and a minimum two-week interval was maintained between sessions (See Fig. 1 for an overview).

Schematic overview of the LPPHK data collection procedures, preprocessing, technical validation and annotation. During data collection (blue), neural imaging signals were measured while participants listened to 4 sections of the audiobook. The sessions were counterbalanced with half of the participants starting with fMRI and the other half with EEG. The sequence for fMRI data collection always commenced with anatomical MRI, followed by functional and resting-state MRI. After preprocessing the data (green), behavioral and overall data quality were assessed (light red). Audio and text annotations were extracted using NLP tools (dark red).
fMRI experiment
Before the scanning day, an MRI safety screening form was sent to the participants to make sure MRI scanning was safe for them. We also sent them simple readings and videos about MRI scanning so that they could have an idea of what it would be like to be in a scanner. On the day of scanning, participants were initially introduced to the MRI facility and comfortably positioned inside the scanner, with their heads securely supported using paddings. An MRI-safe headphone (Sinorad package) was provided for participants to wear inside the head coil. The audio volume for the listening task was adjusted to ensure audibility for each participant. A mirror attached to the head coil allowed participants to view the stimuli presented on a screen. Participants were instructed to stay focused on the visual fixation sign while listening to the audiobook.
The scanning session commenced with the acquisition of structural (T1-weighted) scans. Subsequently, participants engaged in the listening task concurrently with fMRI scanning. The task-based fMRI experiment was divided into four runs, each corresponding to a section of the audiobook. Comprehension was assessed by a series of 5 yes/no questions (20 questions in total, see Table S2) on the content they had listened to. These questions were presented on the screen, with participants indicating their answers by pressing a button. The session concluded with the collection of resting-state fMRI data.
Cognitive tasks
Four cognitive tasks were selected to assess participants’ cognitive abilities in various domains, including the forward digit span task, picture naming task, verbal fluency task, and Flanker task (see Fig. 2). These tasks were delivered after the fMRI session in a separate soundproof booth.

Behavioral cognitive tasks procedure and Language History Questionnaire (LHQ) score distribution. (a) Forward digit span task. (b) Picture naming task. (c) Verbal fluency task. (d) Flanker task. (e) Language History Questionnaire (LHQ) provides scores for proficiency, immersion, and dominance for the languages participants reported. All the participants can speak Cantonese.
The forward digit span task9 measured the span of short-term memory. Participants were presented with audible random sequences of digits 0–9 in Cantonese and were instructed to verbally recall them in the same order (see Fig. 2a). The participants had a chance to practice before the main task started. The span ranged from 4 digits to 14 digits. For scoring, we gave partial credit (0.5) if participants could answer 1 item correctly and full credit (1) for 2–3 correct answers (See Table S3).
In the picture-naming task, participants were required to quickly and accurately name objects and actions using line drawings from the Object and Action Naming Battery10 (ONAB). This battery has been normed across multiple languages, including Cantonese11 (see Fig. 2b). Participants had a brief practice session before the main task started. Average picture naming latency is reported in Table S3 for each participant.
The verbal fluency task9 involved participants generating as many words as possible within 60 seconds that fit into four randomized test categories (mammals, non-mammals, fruits, electronic appliances). Verbal responses were recorded and later scored by independent judges (see Fig. 2c). The score is the average score among all four categories (See Table S3).
The Flanker task12 assessed response inhibition and processing speed. Participants were asked to identify the direction of a central target arrow while disregarding four flanking arrows (see Fig. 2d). The score for inhibition is usually calculated as a difference score where the latency in the congruent condition is subtracted from the latency in the incongruent condition. We presented raw RT for each condition in Table S3 so that researchers could use them flexibly based on their research questions. We considered participants’ average reaction time in neutral conditions as an indication of processing speed (see Table S3). In the neutral condition, there are no conflicting or facilitating cues which makes it a good measurement for processing speed13.
EEG experiment
During the EEG experiment, participants were seated comfortably in a quiet room and standard procedures were followed for electrode placement and EEG cap preparation. Participants were instructed to focus on a fixation sign displayed on a monitor. The EEG recording was then initiated, with participants listening to the audiobook. The audio volume was adapted to each participant’s hearing ability before the recording using a different set of stimuli. We used Foam Ear Inserts (Medium 14 mm). Similar to the fMRI experiment, participants listened to four sections of the audiobook, each lasting approximately 5 minutes. After each run, participants were asked to answer a total of 20 yes/no questions, with 5 questions assigned to each run. They indicated their answers by pressing a button. The EEG recording was conducted continuously throughout all four runs until their completion.
Questionnaires
We administered LHQ3 and the Lifetime of Experiences Questionnaire14 (LEQ) during EEG cap preparation. The participants did not need to move or fill in these questionnaires themselves; a research assistant asked the questions one by one in Cantonese and input the responses in an online Google form. LHQ is designed to document language history by producing aggregate scores for language proficiency, exposure, and dominance in all the languages spoken by the participants (See Fig. 2e). LEQ is a tool to document what sorts of activities (e.g. sports, music, education, profession, etc) participants engage in over their lifetime. It measures lifetime experiences in three periods of life: from 13 to 30 (young adulthood), from 30 to 65 (midlife), and after 65 (late life). LEQ produces a total score (see participants.tsv in the OpenNeuro) which is an indication of cognitive activity. Collecting data using these two questionnaires allowed us to have a thicker description of our participants’ linguistic, social, and cognitive experiences.
Stimuli
The experimental stimuli utilized in both the EEG and fMRI consisted of approximately 20 minutes of the story The Little Prince in Cantonese audiobook. It was translated and narrated in Cantonese by a native male speaker. The stimuli consist of a total of 4,473 words and 535 sentences. To facilitate data analysis and participant engagement, the stimuli were further segmented into four distinct sections, each spanning nearly five minutes. To assess listening comprehension, participants were presented with five yes/no questions after completing each section, resulting in a total of 20 questions throughout the experiment (see Table S4). To make sure the speed of story narration was normal for the participants, we asked a few people who were different from the participants in this study to judge the speed and comprehensibility. They all reported the speed was normal, neither so slow nor so fast.
Data acquisition
The MRI data were collected at the University Research Facility in Behavioral and Systems Neuroscience (UBSN) at The Hong Kong Polytechnic University. EEG data was collected at the Speech and Language Sciences Laboratory within the Department of Chinese and Bilingual Studies at the same university.
fMRI data
MRI imaging data were acquired using a 3 T Siemens MAGNETOM Prisma system MRI scanner with a 20-channel coil. Structural MRI was acquired for each participant using a T1-weighted sequence with the following parameters: repetition time (TR) = 2,500 ms, echo time (TE) = 2.22 ms, inversion time (TI) = 1,120 ms, flip angle α (FA) = 8°, field of view (FOV) = 240 × 256 × 167 mm, resolution = 0.8 mm isotropic, acquisition time = 4 min and 32 s. The acquisition parameters for echo planar T2-weighted imaging (EPI) were as follows: 60 oblique axial slices, TR = 2000 ms, TE = 22 ms, FA = 80°, FOV = 204 × 204 × 165 mm, 2.5 mm isotropic, and acceleration factor 3. E-Prime 2.0 (Psychology Software Tools) was used to present the stimuli.
EEG data
A gel-based 64-channel Neuroscan system on a 10–20 electrode template was used for data acquisition, sampling at a rate of 1000 Hz. To mark the onset of each sentence, triggers were set at the beginning of each sentence. STIM2 software (Compumedics Neuroscan) was used for stimulus presentation.
Preprocessing
All MRI data were preprocessed using the NeuroScholar cloud platform (http://www.humanbrain.cn, Beijing Intelligent Brain Cloud, Inc.), provided by The Hong Kong Polytechnic University. This platform uses an enhanced pipeline based on fMRIPrep15,16 20.2.6 (RRID: SCR_016216) and supported by Nipype17 1.7.0 (RRID: SCR_002502). Then we used the pydeface (https://github.com/poldracklab/pydeface) package to remove the voxels corresponding to the faces from both anatomical and preprocessed data to anonymize participants’ facial information.
Anatomical
The structural MRI data underwent intensity non-uniformity correction18, skull-stripping, and brain tissue segmentation of cerebrospinal fluid (CSF), white matter (WM), and gray matter (GM) based on the reference T1w image. The resulting anatomical images were nonlinearly aligned to the ICBM 152 Nonlinear Asymmetrical template version 2009c (MNI152NLin2009cAsym) template brain. Radiological reviews were performed on MRI images by a medical specialist in the lab. Incidental findings were noticed for participants sub-HK031 and sub-HK049. There was a sub-centimeter (0.7 cm) blooming artefact in the right putamen, likely a cavernoma for participant sub-HK031. For participant sub-HK049, there was a left thalamic (0.7 cm) oval-shaped susceptibility artefact and a 2.6 cm cystic collection in the right posterior fossa.
Functional
The preprocessing of both resting and functional MRI data included the following steps: (1) skull-stripping, (2) slice-timing correction with the temporal realignment of slices according to the reference slice, (3) BOLD time-series co-registration to the T1w reference image, (4) head-motion estimations and spatial realignment to adjust for linear head motion, (5) applying parameters from structural images to spatially normalize functional images into Montreal Neurological Institute (MNI) template, and (6) smoothing by a 6 mm FWHM (full-width half-maximum) Gaussian kernel.
EEG
The pre-processing was carried out using EEGLAB19 and in-house MATLAB functions. The preprocessing of EEG data included the following steps: (1) a cutoff frequency filter with 1 Hz high pass and 40.0 Hz low pass cut-off was applied followed by a notch filter at 50 Hz to reduce electrical line noise, (2) use of kurtosis measure to identify and remove bad channels, (3) application of the RUNICA algorithm (from EEGLab toolbox, 2023 version), a machine learning algorithm that evaluates ICA-derived components, for automated rejection of artifacts, including signal noise from eye and muscle, high-amplitude artifacts (e.g., blinks), and signal discontinuities (e.g., electrodes losing contact with the scalp), (4) interpolating data for bad channels using spherical splines for each segment. (5) re-referencing the data by using both electrodes M1 and M2 as the reference for all channels and (6) down-sampling all the data to 250 Hz.
Annotations
We present audio and text annotations, including time-aligned speech segmentation and prosodic information, as well as word-by-word predictors derived from natural language processing (NLP) tools. These predictors include aspects of lexical semantic information, such as part-of-speech (POS) tagging and word frequency. An overview of our annotations is presented in Fig. 3. These annotations can also be accessed on OpenNeuro (see the Data Records section for details).

Annotation information for the stimuli. (a) Word boundaries in the audio files, included in files: lppHK_word_information.txt. (b) f0 and RMS intensity for every 10 ms of the audios, included in files: wav_acoustic.csv (c) Tokenization, POS tagging, and log-transformed word frequency in files: lppHK_word_information.txt.
Prosodic information
We extracted the root mean square intensity and the fundamental frequency (f0) from every 10 ms interval of the audio segments by utilizing the Voicebox toolbox (http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html). Peak RMS intensity and peak f0 for each word in the naturalistic stimuli were used to represent the intensity and pitch information for each word.
Word frequency
Word segmentation was performed manually by two native Cantonese speakers. The log-transformed frequency of each word was also estimated using PyCantonese20, Version 3.4.0 (https://pycantonese.org/). The built-in corpus in PyCantonese is the Hong Kong Cantonese Corpus21 (HKCancor), collected from transcribed conversations between March 1997 and August 1998.
Part-of-speech tagging
Part-of-speech (POS) tagging for each word in the stimuli was extracted using the PyCantonese20, Version 3.4.0 (https://pycantonese.org/). Following the manual segmentation of words, we input these segments into the Cantonese-exclusive NLP tool PyCantonese, which then provided POS tags for each word according to the Universal Dependencies v2 tagset22 (UDv2).
Data Records
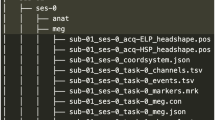
We have anonymized all records by removing information and anatomical data that could potentially identify the participants. Result files are available from the OpenNeuro repository (https://doi.org/10.18112/openneuro.ds004718.v1.0.8)23. For a visual representation of the data collection structure, refer to Fig. 4. A comprehensive description of the available content is provided in the README file on the repository. The scripts utilized for this research paper are accessible both on the repository and GitHub at https://github.com/jixing-li/lpp_data.

Organization of the data collection. (a) General overview of directory structure. (b) Content of subject-specific directories for raw data, including EEG, structural, resting-state, and functional MRI data. (c) Content of subject-specific directories of preprocessed data for both EEG and fMRI data. (d) Content of the experimental stimuli directory. (e) Content of the annotation file directory. (f) Content of the quiz and cognitive behavioral task results directories.
Participant responses
Location participants.json, participants.tsv.
File format tab-separated value.
Participants’ sex, age, and accuracy of quiz questions for each fMRI and EEG experiment in tab-separated value (tsv) files. Data is structured as one line per participant.
Audio files. Location stimuli/task-lppHK_run-1[2–4].wav.
File format wav.
The 4-section audiobook from The Little Prince in Cantonese.
Anatomical data files. Location sub-HK < ID > /anat/sub-HK < ID > _T1w.nii.gz
File format NIfTI, gzip-compressed.
The raw high-resolution anatomical image after defacing.
Functional data files
Location sub-HK < ID > /func/sub-HK < ID > _task-lppHK_run-1[2–4]_bold.nii.gz
File format NIfTI, gzip-compressed.
Sequence protocol
sub-HK < ID > /func/sub-HK < ID > _task-lppHK_run-1[2–4]_bold.json.
The preprocessed data are also available as:
derivatives/sub-HK < ID > /func/sub-HK < ID > _task-lppHK_run-1[2–4]_desc-preprocessed_bold.nii.gz
Resting-state MRI data files
Location sub-HK < ID > /func/sub-HK < ID > _task-rest_bold.nii.gz
File format NIfTI, gzip-compressed.
Sequence protocol
sub-HK < ID > /func/sub-HK < ID > _task-rest_bold.json.
The preprocessed data are also available as
derivatives/sub-HK < ID > /func/sub-HK < ID > _rest_bold.nii.gz.
EEG data files
Location sub-HK < ID > /eeg/sub-HK < ID > _task-lppHK_eeg.set
File format set (a type of MATLAB file, with a file in the .fdt extension containing raw data)
The preprocessed data are also available as:
derivatives/sub-HK < ID > /eeg/sub-HK < ID > _task-lppHK_eeg.set (together with a file in the .fdt extension containing raw data)
Annotations. Location annotation/snts.txt, annotation/lppHK_word_information.txt, annotation/wav_acoustic.csv
File format comma-separated value.
Annotation of speech and linguistic features for the audio and text of the stimuli.
Quiz questions. Location quiz/lppHK_quiz_questions.csv
File format comma-separated value.
The 20 yes/no quiz questions were employed in both the fMRI and EEG experiments.
Technical Validation
To ensure adequate comprehension, we calculated participants’ response accuracy of the quiz questions during the EEG and fMRI experiments. Quality assessment for EEG data was focused on the bad channel portions and the highest amplitude of epoched data. The quality of fMRI scans was evaluated using the MRI Quality Control tool24 (MRIQC). Moreover, three whole-brain functional analyses were conducted utilizing pitch (f0), intensity and word rate annotations. These analyses serve to showcase the high data quality similar to prior research, while substantiating the precise timing accuracy between fMRI time-series for each participant25,26.
Behavioral results
In both the EEG and fMRI experiments, participants were presented with the same set of 20 yes/no quiz questions in total. The average accuracy across participants was 66.25% (SD = 0.13) for the EEG experiment and 59.24% (SD = 0.12) for the fMRI experiment. The observed lower accuracy compared to a previous database25 could potentially be attributed to the advanced age range of our participants, as age-related memory decline may influence their performance, as well as education level. One sample question is shown below.
Example
Question: 小王子是否從另一個星球來到地球?
(Did the Little Prince come to Earth from another planet?)
Answer: 是
(Yes)
Quality assessment for EEG data
The quality assessment was conducted after preprocessing of EEG data. An overview of both qualitative and quantitative measurements for the signal quality is shown in Fig. 5.

EEG Data quality assessment. (a) Number of interpolated channels per participant. (b) Number of epochs that survived from thresholded for each participant. (c) Sensor layout of the EEG system (64 channels, Neuroscan). (d) Intersubject correlation (ISC) results for the EEG data. The average response across 50 trials for both lexical words (e) and functional words (f).
Number of Bad channel removals
By using the kurtosis measure, we identified bad channels and computed the number of interpolated channels, which is presented in Table S5 and Fig. 5a. It is shown that only 15 out of 50 participants had bad channels during data acquisition which accounts for lower than 10% of all the channels.
High amplitudes of Epochs
Epochs with amplitudes of above + 150 mV and below −150 mV in any of the 60 channels were excluded from averaging. Under the threshold of 150 mv, more than half of event epochs were rejected for four participants (incl. sub-HK005, sub-HK019, sub-HK029 and sub-HK037). We adjusted different thresholds for these participants for further analyses, with 300 mV for sub-HK005, 200 mV for both sub-HK019 and sub-HK037, and 350 mV for sub-HK029. The epochs that survived from the threshold are counted and shown in Table S5 and Fig. 5b.
Intersubject correlation (ISC)
To examine the consistency of the EEG responses across subjects, we performed an ISC analysis on the EEG data epoched from 0–600 ms after each word onset for all subjects (See26). We then examined the statistical significance of the ISC results using a one-sample one-tailed t-test with a cluster-based permutation test27 involving 10,000 permutations. Our results showed significant activation in the left and right temporal lobes (see Fig. 5d), suggesting greater consistency in the auditory regions.
Event-related potentials (ERPs)
ERPs refer to brain activities that are elicited in response to specific stimuli. To obtain ERPs, we first segmented the continuous EEG signals into distinct epochs, locking at the onset of each word and extending 600 ms thereafter. This process resulted in a total of 4473 event-based epochs. Subsequently, we separately selected 50 trials out of 2924 trials for lexical words and 50 trials out of 1549 trials for functional words and calculated the average responses across all participants and all 64 channels over the epoch period (600 ms), resulting in two event-based evoked data (Fig. 5e,f).
MRI Data quality assessment
We utilized the MRIQC to evaluate MRI data quality based on the evaluation reports of generated image-quality metrics (IQMs). We visually checked the assessment reports for each participant and plotted the group-level IQMs for both anatomical and functional data (Fig. 6a,b). These metrics demonstrate the high quality of both anatomical and functional data, characterized by low head motion and artifact, stable spatial and temporal brain signals, and minimal outliers.

MRI data quality assessment. (a) Group-level image-quality metrics (IQMs) of anatomical data. (b) Group-level IQMs of functional data.
Anatomical data
Low values of the coefficient of joint variation of gray matter and white matter (CJV) and the entropy-focus criterion (EFC) indicate minimal head motion and artifacts. High values of the contrast-to-noise ratio (CNR) and the foreground-background energy ratio (FBER) suggest clear tissue distribution and a reasonable image energy distribution. Additionally, the white matter to maximum intensity ratio (WM2MAX) shows that the white matter intensity is appropriate, as it falls within the optimal range. The signal-to-noise ratio (SNR) of both gray matter and white matter demonstrates good quality.
Functional data
High temporal signal-to-noise ratio (tSNR) and low temporal derivative of time courses of root mean square over voxels (DVARS) indicate strong temporal stability. Low averaged framewise displacement (FD) and AFNI’s outlier ratio (AOR) show well-controlled head motion and artifacts. Furthermore, low mean full width at half maximum (FWHM) and AFNI’s quality index (AQI) reflect strong spatial distribution of image intensity. Low values of global correction (GOR) and the number of dummy scans indicate appropriate correction and a stable initial scan state.
Neural labeling
The general linear model (GLM) method was employed to derive the prosody- and word-relevant regions using our pitch and word annotations. We calculated the f0 and intensity for every 10 ms of the audio and marked the onset of each word in the audio (word rate). We then convolved the f0, intensity, and word rate annotations with a canonical hemodynamic response function and regressed them against the preprocessed fMRI timecourses using GLMs. At the group level, the contrast images for the f0, intensity and word rate regressors were examined by a one-sample t-test. Statistical significance was held at p < 0.05 FWE and the true positive was estimated by all-resolution inference28 (ARI). Figure 7 illustrates the GLM methods to localize the f0, intensity, and word rate regions. To illustrate the precise anatomical correspondence of our results with prior data, we overlaid fMRI term-based meta-analysis from Neurosynth (Retrieved October 2023) for the “pitch” areas (https://neurosynth.org/analyses/terms/pitch/; from 102 studies), the “acoustic” areas (https://neurosynth.org/analyses/terms/acoustic/; from 171 studies) and the “words” areas (https://neurosynth.org/analyses/terms/words/; from 948 studies). Our results are consistent with prior literature (see Fig. 8). Significant clusters from our GLM analysis and their statistics are shown in Table S6.

General linear model (GLM) analyses to localize the f0, intensity and word rate regressors. (a) Onset timepoints, f0 and intensity of each word in the audiobook were extracted and marked as 1 to be convolved with the canonical hemodynamic response function, separately. (b) At the first level, the time course of each voxel’s BOLD signals was modeled using the design matrix, including word rate, f0 and intensity as regressors. For the second-level analysis, a one-sample t-test was conducted on the distribution of the beta values for the included regressors across subjects at each voxel. The threshold of statistical significance was set at p < 0.05 FWE, k cluster > 50.

General linear model (GLM) results. The GLM results show the significant clusters for the (a) word, (b) intensity and (c) pitch regions using word rate, intensity and f0 annotations as regressors. In the second column of the 3D brain images, the light-colored areas represent related clusters obtained from meta-analyses of the word, acoustic, and pitch regions in Neurosynth. To determine statistical significance, a threshold of p < 0.05 FWE, k > 50 was applied.
Usage Notes
The LPPHK fMRI-EEG dataset can advance our understanding of speech and language processing in the human brain, especially for older speakers, during naturalistic listening. However, there are several limitations and usage bottlenecks including annotations and analyses. We think discussing these limitations here can help others use the data more efficiently.
Annotation bottleneck
Most linguistic annotations in our study were generated automatically utilizing the NLP tool, PyCantonese. However, a portion of the annotations required manual input from native Cantonese speakers. This manual aspect could lead to inconsistencies, potentially affecting subsequent annotations. Specifically, word segmentation tasks were conducted manually by two native speakers of Cantonese. Their manually segmented results were then used to ascertain word frequencies within the reference corpus, namely the Hong Kong Cantonese Corpus (HKCanCor). Notably, discrepancies between human and NLP-segmented results were observed, resulting in several words—707 out of 4473 total stimuli—exhibiting a zero frequency in the corpus.
Analysis bottleneck
Although the GLM is widely employed in fMRI data analysis, there is a noticeable shift towards the adoption of encoding models in naturalistic paradigms. Nonetheless, there is still a need for accurate and systematic approaches to analyze complex, high-dimensional naturalistic fMRI data. Recent progress in machine learning-based methods and the integration of existing computational models has shown promise in improving compatibility with the intricate patterns of neural activity. Hence, we strongly encourage the development of advanced analysis approaches that take into account the various parameters of naturalistic stimuli. This will facilitate a more comprehensive exploration of the LPPHK fMRI-EEG dataset.
Multi-functional analyses
LPPHK fMRI-EEG dataset is a valuable neuroscience resource since it combines neural data from two different modalities. We would like to propose several feasible research possibilities using this dataset. Firstly, owing to its remarkable spatial and temporal resolution, this dataset has the potential to elucidate the complex neural information processing and how it maps across various brain regions. As one part of the current proposed M/EEG-fMRI fusion analytical framework, this dataset can serve as a template for exploring further research possibilities. Secondly, as a dataset featuring an older age group, it offers a valuable resource for comparisons with other age groups, or even populations with specific clinical disorders. Finally, this database provides opportunities for a cross-linguistic analysis. For example, since Cantonese contains abundant inverted sentences and flexible word order, it provides valuable data which could be compared with previous databases such as LPPC-fMRI25.
Code availability
The data for the LPPHK is publicly available at the OpenNeuro repository (https://openneuro.org/datasets/ds004718). The scripts can be accessed through GitHub (https://github.com/jixing-li/lpp_data).
References
Aliko, S., Huang, J., Gheorghiu, F., Meliss, S. & Skipper, J. I. A naturalistic neuroimaging database for understanding the brain using ecological stimuli. Scientific Data 7, https://doi.org/10.1038/s41597-020-00680-2 (2020).
Kandylaki, K. D. & Bornkessel-Schlesewsky, I. From story comprehension to the neurobiology of language. Language, Cognition and Neuroscience 34, 405–410, https://doi.org/10.1080/23273798.2019.1584679 (2019).
Alday, P. M. M/EEG analysis of naturalistic stories: a review from speech to language processing. Language, Cognition and Neuroscience 34, 457–473, https://doi.org/10.1080/23273798.2018.1546882 (2019).
Anand, P., Chung, S. & Wagers, M. W. Widening the Net: Challenges for Gathering Linguistic Data in the Digital Age. (2010).
Division, U. N. P. World population ageing, 2019: highlights. (2019).
Cabeza, R. et al. Maintenance, reserve and compensation: the cognitive neuroscience of healthy ageing. Nat Rev Neurosci 19, 701–710, https://doi.org/10.1038/s41583-018-0068-2 (2018).
Stehwien, S., Henke, L., Hale, J., Brennan, J. & Meyer, L. in Second Workshop on Linguistic and Neurocognitive Resources. 43–49.
Li, P., Zhang, F., Yu, A. & Zhao, X. Language History Questionnaire (LHQ3): An enhanced tool for assessing multilingual experience. Bilingualism: Language and Cognition 23, 938–944, https://doi.org/10.1017/s1366728918001153 (2020).
Fong, M. C.-M. et al. Foreign Language Learning in Older Adults: Anatomical and Cognitive Markers of Vocabulary Learning Success. Frontiers in Human Neuroscience 16, https://doi.org/10.3389/fnhum.2022.787413 (2022).
Druks, J. & Masterson, J. An object and action naming battery. Philadelphia, PA: Psychology Press (2000).
Momenian, M., Bakhtiar, M., Chan, Y. K., Cheung, S. L. & Weekes, B. S. Picture naming in bilingual and monolingual Chinese speakers: Capturing similarity and variability. Behavior Research Methods, https://doi.org/10.3758/s13428-020-01521-1 (2021).
Ong, G., Sewell, D. K., Weekes, B., McKague, M. & Abutalebi, J. A diffusion model approach to analysing the bilingual advantage for the Flanker task: The role of attentional control processes. Journal of Neurolinguistics 43, 28–38, https://doi.org/10.1016/j.jneuroling.2016.08.002 (2017).
Privitera, A. J., Zhou, Y. & Xie, X. Inhibitory control as a significant predictor of academic performance in Chinese high schoolers. Child Neuropsychol 29, 457–473, https://doi.org/10.1080/09297049.2022.2098941 (2023).
Valenzuela, M. J. & Sachdev, P. Assessment of complex mental activity across the lifespan: development of the Lifetime of Experiences Questionnaire (LEQ). Psychological Medicine 37, 1015–1025, https://doi.org/10.1017/s003329170600938x (2007).
Esteban, O. et al. Analysis of task-based functional MRI data preprocessed with fMRIPrep. Nat Protoc 15, 2186–2202, https://doi.org/10.1038/s41596-020-0327-3 (2020).
Esteban, O. et al. fMRIPrep: a robust preprocessing pipeline for functional MRI. Nat Methods 16, 111–116, https://doi.org/10.1038/s41592-018-0235-4 (2019).
Gorgolewski, K. et al. Nipype: a flexible, lightweight and extensible neuroimaging data processing framework in python. Front Neuroinform 5, 13, https://doi.org/10.3389/fninf.2011.00013 (2011).
Tustison, N. J. et al. N4ITK: improved N3 bias correction. IEEE Trans Med Imaging 29, 1310–1320, https://doi.org/10.1109/tmi.2010.2046908 (2010).
Delorme, A. & Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J Neurosci Methods 134, 9–21, https://doi.org/10.1016/j.jneumeth.2003.10.009 (2004).
Lee, J., Chen, L., Lam, C., Ming Lau, C. & Tsui, T. in Thirteenth Language Resources and Evaluation Conference. (ed Frédéric Béchet Nicoletta Calzolari, Philippe Blache,Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Jan Odijk, Stelios Piperidis) 6607–6611.
Luke, K. K. & Wong, M. L. Y. The Hong Kong Cantonese Corpus: Design and Uses. Journal of Chinese Linguistics Monograph Series, 312–333 (2015).
Nivre, J. et al. in International Conference on Language Resources and Evaluation.
Momenian, M., Ma, Z., Wu, S., Wang, C. & Li, J. Le Petit Prince Hong Kong: Naturalistic fMRI and EEG dataset from older Cantonese speakers. OpenNeuro https://doi.org/10.18112/openneuro.ds004718.v1.1.0 (2024).
Esteban, O. et al. MRIQC: Advancing the automatic prediction of image quality in MRI from unseen sites. PLoS One 12, e0184661, https://doi.org/10.1371/journal.pone.0184661 (2017).
Li, J. et al. Le Petit Prince multilingual naturalistic fMRI corpus. Scientific Data 9, 530, https://doi.org/10.1038/s41597-022-01625-7 (2022).
Wang, S., Zhang, X., Zhang, J. & Zong, C. A synchronized multimodal neuroimaging dataset for studying brain language processing. Scientific Data 9 https://doi.org/10.1038/s41597-022-01708-5 (2022).
Maris, E. & Oostenveld, R. Nonparametric statistical testing of EEG- and MEG-data. J Neurosci Methods 164, 177–190, https://doi.org/10.1016/j.jneumeth.2007.03.024 (2007).
Rosenblatt, J. D., Finos, L., Weeda, W. D., Solari, A. & Goeman, J. J. All-Resolutions Inference for brain imaging. NeuroImage 181, 786–796, https://doi.org/10.1016/j.neuroimage.2018.07.060 (2018).
Acknowledgements
We want to thank Chou Man Jun, Chan Ka Man, Fung Wai Sze, Chun Wing Chan, and Ka Keung Lee for their help with data collection. We also want to thank PolyU Institute of Active Aging (now called the Research Centre for Gerontology and Family Studies) for helping us recruit participants. The staff at the University Research Facility in Behavioral and Systems Neuroscience (UBSN) and the Speech and Language Sciences Laboratory at the Hong Kong Polytechnic University were very helpful during data collection. Special thanks to Dr. Polly Barr for providing us with the R script and rubrics for LEQ scoring. This work was supported by a Hong Kong Polytechnic University Start-up Fund (A0035856) given to MM and a City University of Hong Kong Start-up Grant (7200747) given to JL.
Author information
Authors and Affiliations
Contributions
M.M., J.B., J.H. and L.M. designed the research, M.M. performed the research, M.M., Z.M., S.W., C.W. and J.L. analyzed the data, M.M., Z.M., S.W., C.W. and J.L. wrote the first draft, M.M., J.B., J.H., L.M. and J.L. edited the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Momenian, M., Ma, Z., Wu, S. et al. Le Petit Prince Hong Kong (LPPHK): Naturalistic fMRI and EEG data from older Cantonese speakers. Sci Data 11, 992 (2024). https://doi.org/10.1038/s41597-024-03745-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03745-8
- Springer Nature Limited