
Abstract
Quantum computing and neural networks show great promise for the future of information processing. In this paper we study a quantum reservoir computer (QRC), a framework harnessing quantum dynamics and designed for fast and efficient solving of temporal machine learning tasks such as speech recognition, time series prediction and natural language processing. Specifically, we study memory capacity and accuracy of a quantum reservoir computer based on the fully connected transverse field Ising model by investigating different forms of inter-spin interactions and computing timescales. We show that variation in inter-spin interactions leads to a better memory capacity in general, by engineering the type of interactions the capacity can be greatly enhanced and there exists an optimal timescale at which the capacity is maximized. To connect computational capabilities to physical properties of the underlaying system, we also study the out-of-time-ordered correlator and find that its faster decay implies a more accurate memory. Furthermore, as an example application on real world data, we use QRC to predict stock values.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Partly due to the increase in available data and computational speed, machine learning models based on neural and deep neural network architectures have recently been remarkably successful1,2,3,4. Recurrent neural networks, which are designed for modeling problems with temporal aspects, have been successful in various end-to-end systems such as machine translation, speech interpretation/generation and time series prediction5,6,7. Traditionally the neural networks have been trained using back propagation through time algorithm, in which the network is trained against loss function by gradient descent in parameter space8.
In this paper we consider an alternative way of utilizing recurrent neural networks, the framework of reservoir computing9,10,11,12. Unlike in the common back propagation approach, in reservoir computing the recurrent part of the network (reservoir) is fixed during the training and only the readout weights are optimized. The reservoir networks can be directly implemented to physical systems allowing extremely fast state-of-the-art information processing13,14,15,16,17,18. Here we consider a quantum reservoir computer, where the network dynamics are governed by rich quantum mechanical dynamics. Specifically, we consider a model based on fully connected transverse Ising model, introduced in Ref.19. The potential advantage of quantum systems in the context of temporal modeling is the capability to encode extremely large dimensional data. The downside is the challenging physical implementation of a well controlled quantum system.
While quantum reservoir computing has demonstrated its computational capability in principle, it is still unknown how to enhance its computational power by engineering the underlying physical properties. Here we focus on engineering the variation of magnetic coupling, inter-spin interaction and input intervals. The results provide useful information in how future networks should be configured for use in reservoir computing applications. In this work, we engineer quantum reservoirs which allow up to 50\(\%\) memory performance boost compared to the previous setups. We note that the aim is not to build an universal quantum computer and run algorithms on it, rather we are interested in a solver for recurrent neural networks which takes the advantage of rich quantum mechanical dynamics and exponentially scaling Hilbert spaces.
One of key attributes of recurrent neural networks is the memory performance which determines the applicability of the network for various tasks20. We measure the memory performance with the long short term memory test and show that the memory accuracy and length of a quantum reservoir computer can be optimized by choosing an optimal timescale for the process or altering the inter-spin interactions. In addition, to better understand the underlying dynamics and its relation to the memory performance, we investigate the speed of information encoding from the inputs to the internal state of the quantum reservoir computer by using the out-of-time-ordered correlator (OTOC)21.
Setup
We start by describing the standard protocol of recurrent neural networks and reservoir computing. Given the discrete splitting of time \(\{t_i\}\), values of the input nodes \({\bar{u}} (t_i)=\{u_j(t_i)\}_{j=0}^{n_u}\), the network nodes \({\bar{x}} (t_i)=\{x_j(t_i)\}_{j=0}^{n_x}\) and the output nodes \({\bar{y}} (_it)=\{y_j(t_i)\}_{j=0}^{n_y}\), the update equation for a simple recurrent neural network is given by
where f is some nonlinear differentiable function such as sigmoid function, \(W^{\mathbf{in }}\), \(W^{\mathbf{int} }\) are the transition weights from the input nodes and hidden nodes, and \(n_u\), \(n_x\) and \(n_y\) are the number of input, hidden and output nodes, respectively. A simple recurrent neural network is depicted in Fig. 1a. The network outputs are given by
where we assume that the readout signals are gathered from a subset \(\{z_i\} \in \{x_i\} \) of size \(n_{out}< n_x\) from hidden nodes. In general the output \(y_i(t_{i+1})\) could have contribution from last inputs \({\bar{u}}(t_i)\) and outputs \({\bar{y}}(t_i)\) or the nodes itself could have more complex design22.
Given the values of input nodes \({\bar{u}} (t_i)\) (input sequence), the training goal is to find a set of weights \(W^{\mathbf{out }}\), which minimize the error \({\mathscr {E}}=\sum _{i} \Vert {\bar{y}}^{\mathbf{targ }}(t_i)-{\bar{y}}(t_i) \Vert \), where \(y^{\mathbf{targ }}(t)\) is the target sequence and \(\Vert \dot{\Vert }\) denotes a differentiable distance function, such as the mean square distance or cross entropy between distributions. The standard method of back propagation for optimizing typically millions of parameters is to evaluate and numerically descend along the gradients \(d {\mathscr {E}} / dW\) for all elements in \(W^{\mathbf{in }}\) and \(W^{\mathbf{int }}\). Reservoir computing seeks to optimize the task with less computational power by training the output weights \(W^{\mathbf{out }}\) alone. In the case of the mean square error the task reduces to the standard linear regression task, and the optimal configuration of weights, \(W^{\mathbf{out }}_{opt}=\arg \min _{W^{\mathbf{out} }} \sum _{i} ( {\bar{y}}^{\mathbf{targ }}(t_i)-{\bar{y}}(t_i))^2\), is given by
where \({\mathscr {Y}}_{i,j}=y^{\mathbf{targ }}_j(t_i)\) and \({\mathscr {Z}}^{-1}\) denotes the Moore–Penrose pseudo inverse of matrix \({\mathscr {Z}}_{i,j}=z_j(t_i)\). Since in reservoir computing the inter network optimization is not necessary during the training, a physical system can drive the network dynamics directly.
The memory of the network is measured by the short term memory (STM) task defined as a task to remember the input d steps ago:
The memory accuracy is defined as the correlation between the prediction and the target function:
where \(\text {cov}\) denotes covariance and \(\sigma ^2\) variance. The memory capacity \({\mathscr {C}}\) is defined as \({\mathscr {C}}=\sum _{d=1}^{d_c} {\mathscr {R}}(d)\), where \(d_c\) is a cut off distance, which we set to 100.

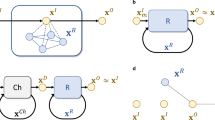
(a) In reservoir computing the input data is fed from the input nodes \({\bar{u}}\) with weights \(W^{\mathbf{in }}\) to the network hidden nodes \({\bar{x}}\). The internal immutable dynamics are governed by \(W^{\mathbf{in }}\). Outputs are obtained by weighting the readout nodes \({\bar{z}}\), corresponding to \(\langle Z_i \rangle =\text {Tr}[Z_i \rho ]\) in our setup, with the readout weights \(W^{\mathbf{out }}\). (b) In quantum reservoir computing an input \(s_i\) is fed to a spin by setting its state to \(|\Psi _{s_i} \rangle = \sqrt{1-s_i}|0\rangle + \sqrt{s_i} | 1 \rangle \). After free time evolution the readout node values are obtained as the ensemble averages of the spins \(\langle Z \rangle \).
For efficient usage, reservoir computing requires complex dynamics, large network sizes and bounded dynamics. These requirements are naturally met by interacting quantum mechanical spin systems, whose state space scales exponentially with respect to the number of spins and the dynamics are governed by complex unitary dynamics. The notation here follows the standard quantum mechanics notation. The state of a spin is a two-dimensional complex vector spanned by the eigenstates of the Pauli Z operator, \(\{ | 0 \rangle , | 1 \rangle \}\). The total state space of \( N\) qubits is a tensor product space of the two-dimensional individual spin spaces. The total (pure) state of the system is represented by a \(2^N\)-dimensional vector \(| \Psi \rangle \). A statistical mixture of pure states can be described by \(2^N \times 2^N\)-dimensional density matrix \(\rho \). For a closed quantum system, the time evolution is governed by the time independent Schrödinger equation, which for the density matrix can be written as
where H is a \(2^N \times 2^N\)-dimensional hermitian matrix, the Hamiltonian of the system, which defines the system dynamics. Here we consider an extensively studied model, the fully connected transverse field Ising model, whose Hamiltonian is given by
where \(X_i\) and \(Z_i\) are the Pauli X and Z operators at site i. In this model all the spins interact with each other in x-direction and are coupled to an external magnetic field in z-direction.
We consider one-dimensional inputs \({\bar{s}}(t_i)=s_i\) and outputs \({\bar{y}}(t_i)=y_i\). At time \(t_i\) the input \(s_i\) is fed to the system by setting the state of the first spin to \(\left| \Psi _{s_i} \right\rangle =\sqrt{1-s_i}\left| 0\right\rangle +\sqrt{s_i}\left| 1\right\rangle \). The density matrix of the system then becomes \(\rho \mapsto \left| \Psi _{s_i}\right\rangle \left\langle \Psi _{s_i} \right| \bigotimes \text {Tr} _1 [\rho ] \), where \(\text {Tr}_1\) denotes the trace over the first spin degree of freedom.
After the input is set, the system continues evolving itself for time \(\Delta t\). During this time the dynamics are governed by Eq. (6) and the information encoded in the first spin will spread through the system. During \([t_i,t_{i+1}]\) we measure the average spin values in the z-direction, \(\langle Z_i \rangle =\text {Tr}[Z_i \rho ]\), which corresponds to the readout nodes in our setup. After gathering a sufficient amount of input-output signal pairs, the readout weights \(W^{\mathbf{out }}\) are trained according to Eq. (3) and the corresponding outputs and the future predicted outputs are obtained from Eq. (2). The input-readout loop is illustrated in Fig. 1b.
Since the number of spins in our setup, \(N_{s}\), is fairly small, we also gather the readout signals from intermediate times between \([t,t+\Delta t]\). The input timescale \(\Delta t\) is divided into \(N_v\) time steps and thus the intermediate times are given by \(t_i^k=t_i+k \Delta t /N_v\), where \(k=1,..,N_v\). The readout signals are gathered as \(\text {Tr}[Z_j \rho (t_i^k)]\) for all the spins \(j=1,\ldots ,N_{s}\) and the intermediate times \(t_i^k\). Thus the total number of the output signals is \(N_{spins}N_v\).
We note that an experimental realization of the setup requires multiple copies of the same system in order to make the effect of measurement back-action irrelevant. This is feasible by using nuclear magnetic resonance systems, where a huge ensemble of identical molecules can be utilized. Further details on the input-readout loop with practical implementation considerations are available in Ref.19.
Results
We set the number of spins and intermediate times to \(N_{s}=6\) and \(N_v=10\), respectively, which gives a relatively good performance at reasonable computational cost19. The input sequences were random binary inputs, \(s_i=\{0,1\}\), sampled for each simulation separately. Initial state was set to the maximally entangled state, where all the possible states \(|\Psi \rangle \) appear with the same probability \(1/2^{N_{s}}\). All of the simulations consisted of an initial equilibration phase of 2,000 time steps during which the inputs were injected but no training was done. During following 3,000 time steps the input and readout signals were gathered and the output weights were trained according to Eq. (3). The testing was done by generating a new set of 1,000 data points. The network output prediction of Eq. (2) was then compared to the target output of Eq. (4).
We considered various values of magnetic coupling h, inter-spin interactions J (Eq. (7)) and input intervals \(\Delta t\). Values for both h and J were sampled from 0.5 centered uniform distribution \({\mathscr {U}}[0.5-h_s/J_s,0.5+h_s/J_s]\). The scale parameters \(h_s\) and \(J_s\) simulated were \(h_s, J_s \in \{0.01, 0.1, 0.25, 0.50, 2, 3\}\) and the number of simulations for each setup was 25. We also sampled J from Beta-distribution with values \((\alpha , \beta ) = \{(0.1, 0.1), (0.7, 0.7), (0.9, 0.9), (1.1), (2, 2),(9, 9), (100, 100)\}\) while keeping the value of \(h=0.5\) fixed (see Supplementary Fig. S1 online). Figure 2 shows the memory capacity as a function of the input timescale \(\Delta t\) for selected scale parameters \(h_s\) and \(J_s\). For all the parameters tested, larger deviation in J, corresponding to larger scale values of \(J_s\) and smaller values of \((\alpha , \beta )\), resulted in larger maximum capacity. However, the given boost in performance saturated around \(J_s=0.5\) and \((\alpha , \beta )=(1,1)\), corresponding to uniform [0, 1] sampling. Within the parameters sampled, the values of h did not have considerable effect on the memory capacity.
In all setups there existed an optimal input timescale \(\Delta t_{\text {opt}}\) at which the memory capacity is maximized as shown in Fig. 2. The STM task measures how well the past input signals can be decoded from readout signals \(\{\langle Z_i\rangle \}_{i=1}^6\) during time window \([t_i,t_{i+1}]=[t_i,t_i+\Delta t]\), using the simple linear map of Eq. (2). On too short timescales the dynamics are almost linear at \(t \in [t_i,t_{i+1}]\) and thus there is no prediction power outside the linear signal regime. On too long timescales the signals are too chaotic during \(t\in [t_i,t_{i+1}]\) giving rise to sub-optimal performance. Thus at optimal timescales the dynamics are not completely linear but not yet too chaotic either. Signals at different timescales are illustrated in the lower panel of Fig. 2.

(a) Memory capacity shown as a function of the input timescale \(\Delta t\). The values for h and J are sampled from \({\mathscr {U}}[0.5-h_s,0.5+h_s]\) and \({\mathscr {U}}[0.5-J_s,0.5+J_s]\), respectively. Deviation in J leads to better performance but the deviation in h is less important. Furthermore, for all parameters simulated, there exists an optimal timescale for \(\Delta t\), which maximizes the capacity. (b) Readout signals Tr\([Z_i \rho (t)]\) for three different time windows \([t_i,t_i+\Delta t]\) for parameters \(h_s=0.01\), \(J_s=0.5\). The leftmost, center and the rightmost panels corresponds to timescales shorter, equal and longer than the optimal timescale \(\Delta t_{\text {opt}}\), respectively.
Instead of sampling J and h from a distribution, we considered engineered forms of J while keeping the value of h fixed to 0.5. The coupling between the spins was set to
where i and j are the spin indexes, k is a scaling parameter and \(c_k=\sum _{i,j}2N_s^2(i+j)^k\) is a k-dependent constant which ensures comparable energy scales between setups with the mean interaction \(\mathbf{E }[J^k]=0.5\). In addition to the fixed mean, the form of \(J^k\) above has the benefit of inducing deviation in J with simple parametrization k without additional noise induced by random sampling. Furthermore, all the spins have different average couplings to the other spins, \(\sum _j J^k_{i,j} < \sum _j J^k_{i+1,j}\), \( i \in {1,2,\ldots ,5}\). We expect that this in general results into more rich and divergent signals increasing the prediction power of Eq. (2). In fact, compared to the random sampled J, the memory capacity can be increased up to 50% by using \(J^k\), as shown in Fig. 3. Maximum memory capacity has a non-monotonic dependence on k and the best performance is obtained with \(k=4\). Furthermore, the larger the k, the larger the optimal input interval \(\Delta t_{\text {opt}}\). The number of simulations was 10 for each of the value \(k \in \{1,2,4,6,8\}\).
For practical purposes, the memory accuracy \({\mathscr {R}}(d)\) (Eq. (5)) may be more important than the overall capacity. Figure 3 shows the memory accuracy as a function of the delay d for selected values of k and input intervals \(\Delta t\). On short \(\Delta t\) the memory extends up to delays 100 but is inaccurate throughout the delay range. On the contrary at long intervals \(\Delta t\) the memory is shorter but more accurate. As the capacity \({\mathscr {C}}=\sum _d {\mathscr {R}}(d)\) measures the sum of accuracies over memory length, the largest \({\mathscr {C}}\) is obtained somewhere in the intermediate timescales where the correlation is relatively good over all the delays up to the cutoff delay.
It is also interesting to compare the memory type to the signals given in the lower panel of Fig. 2. On longer intervals \(\Delta t\) the time window seems to give a good view of the last couple of time windows but the prediction power cannot extend far due to the chaotic nature of the signals, corresponding to the short but accurate memory in the STM test. Vice versa, at shorter intervals \(\Delta t\) the linear prediction extends longer in the past but it is never quite accurate.
When comparing the different \(J^k\) at the same input intervals, the larger k exhibits the longer but less accurate memory and smaller k values are associated with the shorter but more accurate memory. Thus, like in the case of the input interval \(\Delta t\), also the intermediate k value results in the highest memory capacity (Fig. 3). We note that the short but accurate type of memory associated with timescales \(\Delta t > \Delta t_{\text {opt}}\) and lower values of k might be preferred for practical applications where a high enough accuracy is needed.

(a) Memory capacity for different inter-spin couplings \(J^k_{i,j}=(i+j)^k/c_k\). The maximum capacity has a non-monotonic behaviour in k, while the location of the maximum shifts towards larger \(\Delta t\) in increasing k. (b) Memory accuracy at the short time interval. The interval \(\Delta \) is too short for \(k=6\) while the other setups exhibit the long but inaccurate memory. (c) At long time intervals the setups exhibit the short but accurate memory. Higher k values result into a longer but inaccurate of memory.
In order to investigate the information spreading from the input spin to the other spins, we studied the out-of-time-ordered correlator (OTOC) defined as:
The OTOC measures delocalization of information and is previously used in the context of fast scrambling of black hole and thermalization of closed quantum systems21,23. We ran 60 simulations, each consisting of an initial washout phase of 20,000 time steps with time step \(\Delta \tau =0.05\). Figure 4 shows the OTOC for different \(J^k\) couplings and the case that J is sampled from \({\mathscr {U}} [0,1]\). The larger the value of k is, the slower the OTOC decays, signaling slower decay of information from the first spin to the other spins. This is in agreement with the notion that the average interaction of spin 1 to the others, \(\sum _j J_{1,j}/N_s=\sum (1+j)^k/ (c_k N_s)\), is a decreasing function in k. Larger values of k means that the first spin is more weakly coupled to the other spins resulting into a slower decay of information.
Comparison of the memory capacity and the OTOC, Figs. 3 and 4, shows that the slower decay of OTOC implies a larger optimal timescale for the STM task. Thus the system needs more time for effective distribution of information (encoding) to the other spins. These systems exhibit the long but inaccurate type of memory. The encoding takes time and the encoded information can be decoded back after a long time, but the decoding is never particularly efficient. In contrary, the random sampled and low k setups are able to encode the information to the other spins fast and the decoding is efficient, but the memory does not extend as far. We can further synthesize desired memory properties by spatially multiplexing distinct quantum reservoirs24.

The OTOC between the input spin (site \(i=1\)) and the other spins for different couplings \(J^k_{i,j}=(i+j)^k/c_k\). The larger the k, the slower the information decays from the input spin. This is in agreement with the notion that the input spin is more weakly coupled to the other spins with higher values of k.
In order to demonstrate the real world applicability of the quantum reservoir computer, we used future stock value prediction as an example task. As an example dataset we used the Standard and Poor’s (S&P) 500 companies stock values from February 8th 2013 to December 29th 201725. We took the sum of daily closing values of the 500 companies as our daily time series data of 1,232 data points shown in Fig. 5.
The task was to predict the time series 14 days ahead using the past data, i.e. to predict \([x_i,\ldots ,x_{i+13}]\) given \([x_1,\ldots ,x_{i-1}]\). We measured the accuracy for each future day ahead using mean squared error. Since the data is noisy and the accuracy highly depends on the starting date (time index i), we repeated the task for 100 different starting days \(i \in [1{,}100,\ldots ,1{,}199]\). We compared the QRC’s performance with other widely used time series forecasting methods, namely an auto regressive integrated moving average (ARIMA) model and a recurrent neural network based long short term memory (LSTM) model22,26. The results shown in Fig. 5 indicate that the QRC performs well compared to the other models within the selected parameters.
We did not perform an exhaustive parameter search, rather the focus was on demonstrating that the QRC can be applied to real world data. In the initial washout phase we fed the training data through the QRC once without collecting any signals. At the training phase we fed the data, collected the readout node values and trained the output matrix \(W^{\mathbf{out }}\) against the target output according to the Eq. (4). We set the number of qubits to 6, inter spin interactions to Eq. (8) with \(k=2\) and the magnetic field was sampled from random uniform (0,1) distribution. The number of virtual nodes \(N_v\) was set to 2 and we also accumulated the node values from the last 4 data injection points to our readout node values. That is to say, prediction for data points \([x_i,\ldots ,x_{i+13}]\) was done using readout node values \(\text {Tr}[Z_j \rho (t_{i-k}-l \Delta t /2)]\), where \(j \in [1,\ldots ,6]\), \(k \in [0,\ldots ,4]\) and \(l \in [0,1]\). The data input timescale was set to \(\Delta t=0.6\), corresponding to the time scale 0.3 between the virtual nodes. This timescale corresponds to \(\Delta t=3\) with 10 virtual nodes, a time scale which resulted into an accurate memory on shorter delays as shown in the right panel of Fig. 3.
The parameters p, q and d in ARIMA(p, d, q) correspond to the number of lagged time series points used for predictions, the number of differencing operations on the data and the number of lagged forecast errors used for the predictions, respectively. The model was implemented using the Python statsmodels package27. The LSTM model consisted of 64 LSTM units, which were trained for 30 epochs using “Adam” optimizer with learning rate of 0.001, and implemented using Keras framework28. Furthermore, due to computational limitations, the LSTM model was not trained for each prediction starting point \(x_i\) using data up to \(x_{i-1}\). Instead the LSTM model was only trained once on data \([x_1,\ldots ,x_{1{,}099}]\) using delay of 30 timesteps, which partly explains the lower accuracy.

(a) The time series data of daily closing values of S&P 500 stocks by date. (b) Mean absolute error for different prediction models as a function of how many days ahead the prediction date is. The results are averages over 100 different starting dates.
Summary
We studied the memory capacity and accuracy of a quantum reservoir computer based on the fully connected transverse field Ising model. We observed that the input data interval \(\Delta t\) has a system dependent optimal value \(\Delta t_{\text {opt}}\) which leads to the maximum capacity. Furthermore, our results suggest that the deviation in inter-spin interaction strengths leads to improved memory capacity up to some limit. While the maximum capacity is a sign of performance, in practical applications we may be interested in the memory accuracy, which is in general improved by using a slightly longer input time interval than \(\Delta t_{\text {opt}}\). In addition, our results suggest that the fast decay of the OTOC is a sign of fast encoding of information from the input spins to the others. These setups exhibit the accurate memory at the cost of memory length. Furthermore, as a real world example application, we predicted stock prices using the quantum reservoir computer. Possible future research directions include more advanced data input-output strategies, which could implement e.g., multi-dimensional inputs and outputs, mixture of multiple readout timescales and efficient strategies for determining optimal timescales for given tasks.
References
William, C., Navdeep, J., Quoc, V. & Oriol, V. Listen, attend and spell: a neural network for large vocabulary conversational speech recognition. In ICASSP (2016).
Hirschberg, J. & Manning, C. Advances in natural language processing. Science 349, 261–266 (2015).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436 (2015).
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529 (2015).
Chung, J. et. al. A recurrent latent variable model for sequential data. In NIPS, Vol. 28, 2980–2988 (2015).
Mikolov, T. et. al. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, INTERSPEECH 2010, Vol. 2, 1045–1048 (2010).
Sutskever, I., Vinyals, O. & Le, Q. V. Sequence to sequence learning with neural networks. NIPS 27, 3104–3112 (2014).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533 (1986).
Jaeger, H. & Haas, H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304, 78 (2004).
Maass, W., Natschlanger, T. & Markram, H. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531 (2002).
Verstraeten, D., Schrauwen, B. & D’Haene, M. S. D. An experimental unification of reservoir computing methods. Neural Netw. 20, 391 (2007).
Lukoševičius, M. & Jaeger, H. Reservoir computing approaches to recurrent neural network training. Comput. Sci. Rev. 3, 127–149 (2009).
Laurent, L. et al. High-speed photonic reservoir computing using a time-delay-based architecture: Million words per second classification. Phys. Rev. X 7, 011015 (2017).
Dambre, J. et al. Information processing capacity of dynamical systems. Sci. Rep. 2, 514 (2012).
Woods, D. & Naughton, T. Photonic neural networks. Nat. Phys. 8, 257 (2012).
Brunner, D. Parallel photonic information processing at gigabyte per second data rates using transient states. Nat. Commun. 4, 1364 (2013).
Vandoorne, K. et al. Experimental demonstration of reservoir computing on a silicon photonics chip. Nat. Commun. 5, 3541 (2014).
Chao, D. et al. Reservoir computing using dynamic memristors for temporal information processing. Nat. Commun. 8, 2204 (2017).
Fujii, K. & Nakajima, K. Harnessing disordered-ensemble quantum dynamics for machine learning. Phys. Rev. Appl. 8, 024030 (2017).
Nakajima, K. et al. Exploiting short-term memory in soft body dynamics as a computational resource. J. R. Soc. Interface 11, 20140437 (2014).
Ruihua, F., Pengfei, Z., Huitao, S. & Hui, Z. Out-of-time-order correlation for many-body localization. Sci. Bull. 62, 707–711 (2017).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–80 (1997).
Maldacena, J., Shenker, S. H. & Stanford, D. A bound on chaos. J. High Energy Phys. 2016, 106 (2016).
Nakajima, K., Fujii, K., Negoro, M., Mitarai, K. & Kitagawa, M. Boosting computational power through spatial multiplexing in quantum reservoir computing. Phys. Rev. Appl. 11, 034021 (2019).
S&p 500 stock data (2020).
Ho, S. & Xie, M. The use of ARIMA models for reliability forecasting and analysis. Comput. Ind. Eng. 35, 213–216 (1998).
Introduction—statsmodels (2020).
Keras: the python deep learning api (2020).
Acknowledgements
A.K. is supported by Jenny and Antti Wihuri Foundation through Council of Finnish Foundations’ Post Doc Pool, T.S. by JSPS KAKENHI Grant Number JP16H02211 and JP19H05796, and K.F. by JST PRESTO Grant Number JPMJPR1668, JST ERATO Grant Number JPMJER1601, and JST CREST Grant Number JPMJCR1673. We thank Eiki Iyoda for useful discussions.
Author information
Authors and Affiliations
Contributions
A.K. conducted the simulations and wrote the first draft of the manuscript. A.K., T.S. and K.F. analyzed the results and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kutvonen, A., Fujii, K. & Sagawa, T. Optimizing a quantum reservoir computer for time series prediction. Sci Rep 10, 14687 (2020). https://doi.org/10.1038/s41598-020-71673-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-71673-9
- Springer Nature Limited
This article is cited by
-
Quantum next generation reservoir computing: an efficient quantum algorithm for forecasting quantum dynamics
Quantum Machine Intelligence (2024)
-
Binding affinity predictions with hybrid quantum-classical convolutional neural networks
Scientific Reports (2023)
-
Online quantum time series processing with random oscillator networks
Scientific Reports (2023)
-
Taking advantage of noise in quantum reservoir computing
Scientific Reports (2023)
-
Potential and limitations of quantum extreme learning machines
Communications Physics (2023)