
Abstract
Rock elastic properties such as Poisson’s ratio influence wellbore stability, in-situ stresses estimation, drilling performance, and hydraulic fracturing design. Conventionally, Poisson’s ratio estimation requires either laboratory experiments or derived from sonic logs, the main concerns of these methods are the data and samples availability, costs, and time-consumption. In this paper, an alternative real-time technique utilizing drilling parameters and machine learning was presented. The main added value of this approach is that the drilling parameters are more likely to be available and could be collected in real-time during drilling operation without additional cost. These parameters include weight on bit, penetration rate, pump rate, standpipe pressure, and torque. Two machine learning algorithms were used, artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS). To train and test the models, 2905 data points from one well were used, while 2912 data points from a different well were used for model validation. The lithology of both wells contains carbonate, sandstone, and shale. Optimization on different tuning parameters in the algorithm was conducted to ensure the best prediction was achieved. A good match between the actual and predicted Poisson’s ratio was achieved in both methods with correlation coefficients between 0.98 and 0.99 using ANN and between 0.97 and 0.98 using ANFIS. The average absolute percentage error values were between 1 and 2% in ANN predictions and around 2% when ANFIS was used. Based on these results, the employment of drilling data and machine learning is a strong tool for real-time prediction of geomechanical properties without additional cost.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Rock elasticity is a major identifier for rock mechanical properties and reflects the ability of the rock to recover from a deformation caused by external forces. Two main properties are used to define rock elasticity, Young’s modulus, and Poisson’s ratio. These geomechanical properties show the relationship between the forces and the resulted deformation1. Young’s modulus (E) is a stiffness measure and defined by the ratio between the strain and the stress. While Poisson’s ratio (ν) is the ratio between lateral and longitudinal strain (ε). Rock elastic properties influence hydraulic fracturing design, drilling performance, in-situ stresses estimation, and wellbore stability2,3,4,5.
In order to estimate Poisson’s ratio, there are two options, using core samples or well logs. The Poisson’s ratio determined by compressional tests on core plug samples is called static Poisson’s ratio, while the dynamic Poisson’s ratio is derived from shear and compressional acoustic wave velocities logs6 using the following equation.
where \(\upnu _{{{\text{dyn}}}}\) is the dynamic Poisson’s ratio, VS and VP are the shear and compressional wave velocities respectively.
The advantage of \(\upnu _{{{\text{dyn}}}}\) over \(\upnu _{{{\text{static}}}}\), is that it can provide a continuous profile, In addition, getting core samples are expensive and time-consuming. To overcome the fact that static and dynamic values for Poisson’s ratio are usually different from each other, many researchers presented empirical correlations between static and dynamic Poisson’s ratio based on linear regression7,8,9. However, some of these correlations are developed using limited samples and for a specific type of formation as summarized in Table 1.
While \({\upnu}_{\mathrm{st}}\) is the static Poisson’s ratio, \({{\upnu }}_{\mathrm{dyn}}\) is the dynamic Poisson’s ratio, \({\mathrm{V}}_{\mathrm{p}}\) and \({\mathrm{V}}_{\mathrm{s}}\) are the compressional and shear wave velocities respectively.
Artificial intelligence (AI) has a wide range of engineering, medical and industrial applications10,11,12. The use of machine learning in the oil industry is fast growing in various sectors. These applications include but are not limited to estimation and optimization of drilling parameters13,14,15,16,17,18, drilling fluid properties19,20,21, reservoir fluid properties22,23,24,25,26,27, petrophysical properties28,29,30,31,32, and geomechanical properties33,34,35,36. Different models between static and dynamic Poisson’s ratio were developed using different machine learning methods such as an artificial neural network (ANN), Fuzzy Logic (FL), Functional Network (FN), and Alternating Conditional Expectation (ACE) as presented in Table 2.
Even though these presented models give good correlations between predicted and actual static Poisson’s ratio, but they still require the availability of the shear and compressional velocities, which are used to estimate dynamic Poison’s ratio, and may not always be available. Therefore, correlating between Poison’s ratio and drilling parameters, which are available from the first encounter to the well, will be extremely beneficial. Moreover, successful applications of using the drilling data to obtain information that usually requires logs have been reported, namely bulk density and sonic velocity logs44,45. Furthermore, the use of drilling data in the estimation of formation pressure and abnormal pressure zones detection is an old technique46,47.
The approach presented in this paper is based on the idea that drilling data are always available, easier and earlier to obtain compared to conventional well logs and core samples. The use of drilling parameters for real-time estimation of Poisson’s ratio using different AI techniques is investigated and presented in this paper.
Data and methods
In order to predict Poisson’s Ratio from the drilling parameters, the following steps have been followed. Data for drilling parameters and Young’s modulus have been gathered for two wells. Data from one well, has been used to build the model using several machine learning techniques. The dataset from the second well has been hidden from the algorithms and not used later to validate the built model. Figure 1 summarizes the methodology used for efficient young’s modulus prediction.

Flow chart for the methodology used to generate AI-model.
Data description
The collected data for this study were gathered from drilling phase activities in the Middle East. The data covered the drilling parameters and the relevant Poisson’s ratio values during drilling the intermediate section for 12.25″ hole size for vertical profile wells. As shown in Fig. 2, the complex lithology of the drilled formations through Well-1 covered four formation types (shale, sandstone, and carbonate rocks).

Lithology column for Well-1.
Well-1 has a total of 2905 data points used to build the model with 70% of the data points for training and 30% for testing the model. 2912 data points from well-2 were hidden from the AI algorithms and used later to validate the built model. Besides the PR that is set as targeted output, each data point contains six drilling parameters used as inputs. The drilling parameters, listed below, were obtained from field measurements and used in building this model:
-
Weight on bit WOB in klb
-
Torque in kft.lbf
-
Standpipe pressure SPP in psi
-
Rotary speed RPM (1/min)
-
Drilling rate of penetration ROP in ft/h
-
Drilling fluid flow Rate in gpm
Data analysis
Before running the data into the machine learning algorithms, the datasets were cleaned from noise and outliers using Matlab code. Statistical analysis of the dataset used to build the models is presented in Table 3.
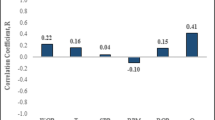
The correlation coefficients between PR and different drilling parameters are given in Fig. 3. It shows relatively strong correlations between PR and some drilling parameters such as WOB, torque, and pump flow rate. Lower correlation coefficients for other parameters don’t necessarily imply the absence of relation between these inputs and PR, but rather means that the linear equation doesn’t describe the relationship between the inputs and the output.

The correlation coefficient of drilling parameters with Poisson’s ratio.
Machine learning algorithms
For the purpose of constructing the models between Poisson’s ratio and drilling parameters, two machine-learning methods were used separately, artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS). ANN is a very common machine-learning tool that is inspired by biological neurons in brains48. ANN could function as supervised or unsupervised machine learning in regression, classification, and clustering problems49. ANN is composed of different components such as neurons, transfer functions, training functions, learning functions, and hidden layers37. In literature, there are many reported successful applications of ANN in the oil and gas industry32,35,36,50,51.
Adaptive neuro-fuzzy inference system (ANFIS) was developed in the 1990s and integrates the principles of neural networks and fuzzy logic (FL)52,53. In this method, ANN is used to set the fuzzy rules in FL54. This integration of the two methods provides an improved performance55. Similar to ANN, ANFIS has various reported applications in the oil industry56,57,58,59.
Models evaluation
ANN and ANFIS were used for models' construction. These algorithms use 70% of the dataset from well-1 to build the model and 30% of the data to test it internally for several iterations and chose the best fit. After having the model, data from well-2 were used as an external validation set for the models. To evaluate all models' trials, two statistical parameters were used, correlation coefficient (R) and average absolute percentage error (AAPE). R and AAPE are calculated using Eqs. (2) and Eq. (3):
where \({\nu }_{given}\) and \({\nu }_{Predicted}\) are the available and the predicted Poisson’s ratio respectively, and N is the total number of data points.
Sensitivity and optimization
Different runs were done in each method to determine the best tuning parameters inside the algorithms. This has been done by running the two machine learning methods inside multiple for-loops containing the range of tested parameters. In ANN models, a different number of neurons, network functions, training functions, and transfer functions were used. In ANFIS, different cluster radiuses and the number of iterations were used. Table 4 shows the total range of parameters used to get the best models.
Results and discussion
Avoiding overfitting
Overfitting is a very troublesome problem in machine learning, in which the model fits very well in training data and performs poorly in validation and testing. Overfitting results in a model that is limited only to the training data and could not be generalized for data from different sources. In this work, overfitting has been overcome by different methods.
In machine learning, when the number of parameters used to optimize the fitting, such as weights and biases, is too much compared to the number of data points, this will increase the chances of overfitting. As indicated in the data description section, more than 2000 data points were used to train the model, which is relatively a high number. This data quantity helped to improve model generalization. Moreover, the models were built to be as simple as possible. For instance, in ANN one layer of neurons was used and the number of neurons was chosen to be as less as possible without significantly affecting the fitting performance.
Additionally, the used algorithms have an early stopping feature to avoid overfitting. In this feature, part of training data is separated and will not be used to build the model instead it will be used as an early validation. The fitting performance for training and validation is estimated at each iteration. For each iteration in Fig. 4, both training and validation error is reducing till point A, after which the model starts to overfit and the validation error starts to increase. Due to the early stopping feature, point A parameters will be used in the model instead of point B, even though it has less error in training.

Early stopping to avoid overfitting.
Artificial neural network
Sensitivity
To ensure the best results from ANN, a different number of neurons, network functions, training functions, and transfer functions were used. Figures 5, 6, 7 and 8 present the sensitivity analysis on these parameters. Increasing the number of neurons results in better results, however, the computational time increases as well. In addition, there is no significant increase in correlation coefficients when more than 25 neurons were used as shown in Fig. 5. Except for one case, there were no significant variations when different network functions were used as demonstrated in Fig. 6. Sensitivity analyses on training and transfer functions showed the most variations with correlations coefficient ranging between 0.75 and 0.99 as illustrated in Figs. 7 and 8.

Sensitivity analysis on the number of neurons.

Sensitivity analysis on different network functions.

Sensitivity analysis on different training functions.

Sensitivity analysis of different transfer functions.
Validation
The dataset from well-1 was used to build the model and to perform the sensitivity analysis. After the model has been built, data from well-2 have been used to validate the model. Good results have been achieved in both wells even though the algorithm only trained and test the model using the first well data. The correlation coefficients were 0.992, 0.988 and 0.980 for training, testing, and validation respectively, and the AAPE values were all in the range between 1 and 2%. Figure 9. Shows a comparison between actual and ANN predicted Poisson’s ratio for well-1 and well-2.

Actual and ANN predicted Poisson’s ratio for (a) training (b) testing and (c) validation.
Adaptive neuro-fuzzy inference system
Sensitivity
Using ANFIS, different cluster radiuses and number of iterations were used. Sensitivity analysis of these two parameters is presented in Figs. 10 and 11. Increasing the cluster radius from 0.3 to 0.9 resulted in a decrease in correlation coefficients from 0.97 to 0.88 in training and from 0.97 to 0.86 in testing. On the other hand, increasing the number of iterations enhanced the results.

Sensitivity analysis on cluster radius.

Sensitivity analysis on the number of iterations.
Validation
The same procedure used in ANN has been used in the ANFIS model's building and validations. The data set from Well-1 have been used to train and test the model using different parameters and Well-2 dataset was used to validate the built model. Even though all correlation coefficients were higher than 0.97 and the AAPE values were less than 2.2%, the ANN results presented earlier are better. The actual Poisson’s ratio in comparison with the predicted Poisson’s ratio with ANFIS is presented in Fig. 12.

Actual and ANFIS predicted Poisson’s ratio for (a) training, (b) testing and (c) validation.
Computational cost
Besides the key performance indices (correlation coefficient and average absolute percentage error), the computational cost is considered a very essential factor used to compare the different methods utilized. The calculation times (in seconds) were determined in each run for the two models in order to compare the calculation efficiency. As shown the Fig. 13, ANN outperformed the ANFIS model with 90% of the runs took less than 4.32 s while in ANFIS this value was more than 300 s.

The ascending probability of computational time for the two methods.
Model
Different parameters' combinations have been tested to ensure optimum fit. Table 5 displays ANN and ANFIS parameters that yielded the best matches between the predictions and given values.
The best fit was obtained using ANN with a correlation coefficient around 0.99 in training and testing and 0.98 in the validation process and AAPE between 1 and 2%. The generated model is expressed by Eq. 4, while Table 6 shows the weight and biases that are used in the model.
Conclusions
Conventionally, Poisson’s ratio is estimated from sonic logs data, which may not always be available. An alternative real-time prediction of Poisson’s ratio from drilling data has been proposed in this paper by employing different machine learning tools. In the light of the presented outcomes, the following statements could be used to conclude the study:
-
Compared to other means used to predict Poisson’s ratio, drilling data is more likely to be available at an early stage of the well's life without additional cost and time. Therefore, the prediction of Poisson’s ratio from drilling data will be very beneficial.
-
Two machine learning methods were investigated and both yielded a good match, however, a slightly better prediction of Poisson’s ratio was achieved using ANN. The sensitivity and optimization of different parameters used in the algorithms have been presented and the best results were reported.
-
The correlation coefficient between the actual and predicted values ranged between 0.97 and 0.99, while the average errors were all less than 2.2%. The best model was presented as a white-box to allow using other datasets.
Recommendations
Supported by the outcomes presented in this paper that confirm the ability to obtain good predictions of Poisson’s ratio from drilling data, it is recommended to investigated other machine learning methods. Moreover, the use of drilling data in the prediction of other geomechanical properties could be investigated using a similar approach. It is also worthy to mention that the data used in this study are from the same field, therefore, to generate general model data from different sources could be combined and used altogether.
SI Metric Conversion Factors
1 ft = 0.3048 m.
1 lb = 0.453592 kg.
1 lbf = 4.44822 N.
1 psi = 6894.76 Pa.
1 gal = 0.00378541 m3.
References
Fjar, E., Holt, R. M., Raaen, A. M. & Horsrud, P. Petroleum Related Rock Mechanics Vol. 53 (Elsevier, 2008).
Hammah, R., Curran, J. & Yacoub, T. The influence of Young’s modulus on stress modelling results. In Golden Rocks 2006, The 41st U.S. Symposium on Rock Mechanics (USRMS) 5 (2006).
Kumar, J. The effect of Poisson’s ratio on rock properties. In SPE Annual Fall Technical Conference and Exhibition 12 (1976). https://doi.org/10.2118/6094-MS.
Labudovic, V. The effect of Poisson’s ratio on fracture height. J. Pet. Technol. 36, 287–290. https://doi.org/10.2118/10307-PA (1984).
Nes, O.-M., Fjær, E., Tronvoll, J., Kristiansen, T. G. & Horsrud, P. Drilling time reduction through an integrated rock mechanics analysis. In SPE/IADC Drilling Conference 7 (2005). https://doi.org/10.2118/92531-MS.
Barree, R. D., Gilbert, J. V. & Conway, M. Stress and rock property profiling for unconventional reservoir stimulation. In SPE Hydraulic Fracturing Technology Conference 18 (2009). https://doi.org/10.2118/118703-MS.
Christaras, B., Auger, F. & Mosse, E. Determination of the moduli of elasticity of rocks. Comparison of the ultrasonic velocity and mechanical resonance frequency methods with direct static methods. Mater. Struct. 27, 222–228. https://doi.org/10.1007/BF02473036 (1994).
Wang, Q., Ji, S., Sun, S. & Marcotte, D. Correlations between compressional and shear wave velocities and corresponding Poisson’s ratios for some common rocks and sulfide ores. Tectonophysics 469, 61–72. https://doi.org/10.1016/j.tecto.2009.01.025 (2009).
Feng, C. et al. A new empirical method based on piecewise linear model to predict static Poisson’s ratio via well logs. J. Pet. Sci. Eng. 175, 1–8. https://doi.org/10.1016/j.petrol.2018.11.062 (2019).
Rajaei, P. et al. VIRMOTIF: A user-friendly tool for viral sequence analysis. Genes 12, 186. https://doi.org/10.3390/genes12020186 (2021).
Shamshirband, S. et al. Computational intelligence intrusion detection techniques in mobile cloud computing environments: Review, taxonomy, and open research issues. J. Inf. Secur. Appl. 55, 102582. https://doi.org/10.1016/j.jisa.2020.102582 (2020).
Shamshirband, S., Fathi, M., Dehzangi, A., Chronopoulos, A. T. & Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 113, 103627. https://doi.org/10.1016/j.jbi.2020.103627 (2021).
Ahmed, A., Ali, A., Elkatatny, S. & Abdulraheem, A. New artificial neural networks model for predicting rate of penetration in deep shale formation. Sustainability 11, 6527. https://doi.org/10.3390/su11226527 (2019).
Al-abduljabbar, A. et al. Prediction of the rate of penetration while drilling horizontal carbonate reservoirs using the self-adaptive artificial neural networks technique. Sustainability 12, 1376. https://doi.org/10.3390/su12041376 (2020).
Elkatatny, S. Real-time prediction of rate of penetration in S-shape well profile using artificial intelligence models. Sensors 20, 3506. https://doi.org/10.3390/s20123506 (2020).
Hassan, A., Al-Majed, A., Mahmoud, M., Elkatatny, S. & Abdulraheem, A. Improved Predictions in Oil Operations Using Artificial Intelligent Techniques. In SPE Middle East Oil Gas Show Conference 9 (2019). https://doi.org/10.2118/194994-MS.
Abdelgawad, K. Z. et al. New approach to evaluate the equivalent circulating density (ECD) using artificial intelligence techniques. J. Pet. Explor. Prod. Technol. 9, 1569–1578. https://doi.org/10.1007/s13202-018-0572-y (2019).
Elzenary, M. et al. New technology to evaluate equivalent circulating density while drilling using artificial intelligence. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition 14 (2018). https://doi.org/10.2118/192282-MS.
Abdelgawad, K., Elkatatny, S., Moussa, T., Mahmoud, M. & Patil, S. Real-time determination of rheological properties of spud drilling fluids using a hybrid artificial intelligence technique. J. Energy Resour. Technol. 141, 032908. https://doi.org/10.2118/192257-MS (2019).
Al-azani, K., Elkatatny, S., Abdulraheem, A., Mahmoud, M. & Al-Shehri, D. Real time prediction of the rheological properties of oil-based drilling fluids using artificial neural networks. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition 17 (2018). https://doi.org/10.2118/192199-MS.
Elkatatny, S. Real-time prediction of the rheological properties of water-based drill-in fluid using artificial neural networks. Sustainability 11, 5008. https://doi.org/10.3390/su11185008 (2019).
Ahmadi, M. A., Pournik, M., Shadizadeh, S. R., Ali, M. & Reza, S. Toward connectionist model for predicting bubble point pressure of crude oils: Application of artificial intelligence. Petroleum 1, 307–317. https://doi.org/10.1016/j.petlm.2015.08.003 (2015).
Alakbari, F. S., Elkatatny, S. & Baarimah, S. O. Prediction of bubble point pressure using artificial intelligence AI techniques. In SPE Middle East Artificial Lift Conference and Exhibition 9 (2016). https://doi.org/10.2118/184208-MS.
Wood, D. A. & Choubineh, A. Transparent open-box learning network and artificial neural network predictions of bubble-point pressure compared. Petroleum https://doi.org/10.1016/j.petlm.2018.12.001 (2018).
Mahdiani, M. R. & Norouzi, M. A new heuristic model for estimating the oil formation volume factor. Petroleum 4, 300–308. https://doi.org/10.1016/j.petlm.2018.03.006 (2018).
Oloso, M. A., Hassan, M. G., Bader-El-Den, M. B. & Buick, J. M. Hybrid functional networks for oil reservoir PVT characterisation. Expert Syst. Appl. 87, 363–369. https://doi.org/10.1016/j.eswa.2017.06.014 (2017).
Elkatatny, S., Moussa, T., Abdulraheem, A. & Mahmoud, M. A self-adaptive artificial intelligence technique to predict oil pressure volume temperature properties. Energies 11, 3490. https://doi.org/10.3390/en11123490 (2018).
Al-AbdulJabbar, A., Al-Azani, K. & Elkatatny, S. Estimation of reservoir porosity from drilling parameters using artificial neural networks. Petrophys. SPWLA J. Form. Eval. Reserv. Descr. 61, 318–330. https://doi.org/10.30632/PJV61N3-2020a5 (2020).
Ali, A., Aïfa, T. & Baddari, K. Prediction of natural fracture porosity from well log data by means of fuzzy ranking and an artificial neural network in Hassi Messaoud oil field, Algeria. J. Pet. Sci. Eng. 115, 78–89. https://doi.org/10.1016/j.petrol.2014.01.011 (2014).
Wood, D. A. Predicting porosity, permeability and water saturation applying an optimized nearest-neighbour, machine-learning and data-mining network of well-log data. J. Pet. Sci. Eng. 184, 106587. https://doi.org/10.1016/j.petrol.2019.106587 (2020).
Al Khalifah, H., Glover, P. W. J. & Lorinczi, P. Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar. Pet. Geol. 112, 104096. https://doi.org/10.1016/j.marpetgeo.2019.104096 (2020).
Shokooh Saljooghi, B. & Hezarkhani, A. A new approach to improve permeability prediction of petroleum reservoirs using neural network adaptive wavelet (wavenet). J. Pet. Sci. Eng. 133, 851–861. https://doi.org/10.1016/j.petrol.2015.04.002 (2015).
Alloush, R. M. et al. Estimation of geomechanical failure parameters from well logs using artificial intelligence techniques. In SPE Kuwait Oil and Gas Show and Conference 13 (2017). https://doi.org/10.2118/187625-MS.
Tariq, Z., Elkatatny, S., Mahmoud, M., Ali, A. Z. & Abdulraheem, A. A new technique to develop rock strength correlation using artificial intelligence tools. In SPE Reservoir Characterisation and Simulation Conference and Exhibition 14 (2017). https://doi.org/10.2118/186062-MS.
Elkatatny, S., Tariq, Z., Mahmoud, M., Abdulazeez, A. & Mohamed, I. M. Application of artificial intelligent techniques to determine sonic time from well logs. In 50th U.S. Rock Mechanics/Geomechanics Symposium 11 (2016).
Tariq, Z., Elkatatny, S., Mahmoud, M., Abdulraheem, A. & Fahd, K. A new artificial intelligence based empirical correlation to predict sonic travel time. In International Petroleum Technology Conference 19 (2016). https://doi.org/10.2523/IPTC-19005-MS.
Abdulraheem, A., Ahmed, M., Vantala, A. & Parvez, T. Prediction of rock mechanical parameters for hydrocarbon reservoirs using different artificial intelligence techniques. In SPE Saudi Arabia Section Technical Symposium 11 (2009). https://doi.org/10.2118/126094-MS.
Al-anazi, B. D., Algarni, M. T., Tale, M. & Almushiqeh, I. Prediction of Poisson’s ratio and Young’s modulus for hydrocarbon reservoirs using alternating conditional expectation algorithm. In SPE Middle East Oil and Gas Show and Conference 9 (2011). https://doi.org/10.2118/138841-MS.
Tariq, Z. et al. Estimation of rock mechanical parameters using artificial intelligence tools. In 51st U.S. Rock Mechanics/Geomechanics Symposium 11 (2017).
Elkatatny, S. et al. An artificial intelligent approach to predict static Poisson’s ratio. In 51st U.S. Rock Mechanics/Geomechanics Symposium 7 (2017).
Abdulraheem, A. Prediction of Poisson’s ratio for carbonate rocks using ANN and fuzzy logic type-2 approaches. In International Petroleum Technology Conference 9 (2019). https://doi.org/10.2523/IPTC-19365-MS.
Gowida, A., Moussa, T., Elkatatny, S. & Ali, A. A hybrid artificial intelligence model to predict the elastic behavior of sandstone rocks. Sustainability 11, 5283. https://doi.org/10.3390/su11195283 (2019).
Tariq, Z., Abdulraheem, A., Mahmoud, M. & Ahmed, A. A rigorous data-driven approach to predict Poisson’s ratio of carbonate rocks using a functional network. Petrophysics 59, 761–777 (2018).
Gowida, A. & Elkatatny, S. Prediction of sonic wave transit times from drilling parameters while horizontal drilling in carbonate rocks using neural networks. Petrophysics 61, 482–494 (2020).
Gowida, A., Elkatatny, S., Al-afnan, S. & Abdulraheem, A. New computational artificial intelligence models for generating synthetic formation bulk density logs while drilling. Sustainability 12, 686. https://doi.org/10.3390/su12020686 (2020).
Jorden, J. R. & Shirley, O. J. Application of drilling performance data to overpressure detection. J. Pet. Technol. 18, 1387–1394. https://doi.org/10.2118/1407-PA (1966).
Rehm, B. & McClendon, R. Measurement of formation pressure from drilling data. In Fall Meeting of the Society of Petroleum Engineers of AIME 11 (1971). https://doi.org/10.2118/3601-MS.
Chen, Y.-Y., Lin, Y.-H., Kung, C.-C., Chung, M.-H. & Yen, I.-H. Design and implementation of cloud analytics-assisted smart power meters considering advanced artificial intelligence as edge analytics in demand-side management for smart homes. Sensors 19, 2047. https://doi.org/10.3390/s19092047 (2019).
Aggarwal, A. & Agarwal, S. ANN powered virtual well testing. In Offshore Technology Conference-Asia 9 (2014). https://doi.org/10.4043/24981-MS.
Field, A., Abdulaziz, A. M., Mahdi, H. A. & Sayyouh, M. H. Prediction of reservoir quality using well logs and seismic attributes analysis with an artificial neural network: A case study from Farrud. J. Appl. Geophys. 161, 239–254. https://doi.org/10.1016/j.jappgeo.2018.09.013 (2019).
Elkatatny, S., Tariq, Z., Mahmoud, M. A. & Al-AbdulJabbar, A. Optimization of rate of penetration using artificial intelligent techniques. In 51st U.S. Rock Mechanics/Geomechanics Symposium 8 (2017).
Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man. Cybern. 23, 665–685 (1993).
Jang, J.-S. R. Fuzzy modeling using generalized neural networks and Kalman filter algorithm. In Proceedings of the 9th National Conference on Artificial Intelligence 762–767 (1991). https://doi.org/10.1109/21.256541.
Tahmasebi, P. & Hezarkhani, A. A hybrid neural networks-fuzzy logic-genetic algorithm for grade estimation. Comput. Geosci. 42, 18–27. https://doi.org/10.1016/j.cageo.2012.02.004 (2012).
Abraham, A. Adaptation of fuzzy inference system using neural learning. In Fuzzy Systems Engineering (eds Nedjah, N. & de Macedo Mourelle, L.) 53–83 (Springer, Berlin, 2005). https://doi.org/10.1007/11339366_3.
Tariq, Z., Mahmoud, M. & Abdulraheem, A. method for estimating permeability in carbonate reservoirs from typical logging parameters using functional network. In 53rd U.S. Rock Mechanics/Geomechanics Symposium 6 (2019).
Elkatatny, S. & Mahmoud, M. Development of a new correlation for bubble point pressure in oil reservoirs using artificial intelligent technique. Arab. J. Sci. Eng. 43, 2491–2500. https://doi.org/10.1007/s13369-017-2589-9 (2018).
Elkatatny, S. & Mahmoud, M. Development of new correlations for the oil formation volume factor in oil reservoirs using artificial intelligent white box technique. Petroleum 4, 178–186. https://doi.org/10.1016/j.petlm.2017.09.009 (2018).
Shahriar, K. & Owladeghaffari, H. Analysis of permeability using BPF, ANFIS & SOM. In 1st Canada–U.S. Rock Mechanics Symposium 5 (2007).
Author information
Authors and Affiliations
Contributions
S.E. conceived the idea and collected the required data and participated in the methodology design. O.S. and H.G. conducted the data analysis, designed the methodology, run the algorithms and performed the sensitivity and optimization of the results. A.A. also participated in methodology design, results validation and supervising. The original manuscript was written by O.S. and all authors participated in the manuscript revision and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Siddig, O., Gamal, H., Elkatatny, S. et al. Real-time prediction of Poisson’s ratio from drilling parameters using machine learning tools. Sci Rep 11, 12611 (2021). https://doi.org/10.1038/s41598-021-92082-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-92082-6
- Springer Nature Limited
This article is cited by
-
Robust Machine Learning Predictive Models for Real-Time Determination of Confined Compressive Strength of Rock Using Mudlogging Data
Rock Mechanics and Rock Engineering (2024)
-
State-of-the-art review on the use of AI-enhanced computational mechanics in geotechnical engineering
Artificial Intelligence Review (2024)
-
A novel data-driven model for real-time prediction of static Young's modulus applying mud-logging data
Earth Science Informatics (2024)
-
Estimation of rocks’ failure parameters from drilling data by using artificial neural network
Scientific Reports (2023)
-
Estimating electrical resistivity from logging data for oil wells using machine learning
Journal of Petroleum Exploration and Production Technology (2023)