
Abstract
Heart failure (HF) is a leading cause of morbidity, healthcare costs, and mortality. Guideline based segmentation of HF into distinct subtypes is coarse and unlikely to reflect the heterogeneity of etiologies and disease trajectories of patients. While analyses of electronic health records show promise in expanding our understanding of complex syndromes like HF in an evidence-driven way, limitations in data quality have presented challenges for large-scale EHR-based insight generation and decision-making. We present a hypothesis-free approach to generating real-world characteristics and progression patterns of HF. Patient disease state snapshots are extracted from the complaints mentioned in unstructured clinical notes. Typical disease states are generated by clustering and characterized in terms of their distinguishing features, temporal relationships, and risk of important clinical events. Our analysis generates a comprehensive “disease phenome” of real-world patients computed from large, noisy, secondary-use EHR datasets created in a routine clinical setting.
Similar content being viewed by others


Introduction
Heart failure (HF) is a major contributor to global disease burden, having a worldwide estimated prevalence of 64 million patients and staggering associated health and financial costs of 10 million years lost due to disability (YLDs) and $350 billion US in expenditure1. Despite recent innovations in pharmaceutical interventions and clinical management strategies, HF continues to be difficult to treat, as HF patients are often medically complex and present with diverse phenotypes characterized by a variety of pathophysiological mechanisms, clinical measurements, biomarkers, lifestyle factors, comorbidities, and treatment responses2,3. This complexity poses a challenge for defining precise HF classifications that can serve as the basis for HF research and treatment standards. Current guidelines for the diagnosis and treatment of HF have highlighted the fact that there is no single agreed upon classification system for causes of HF, with significant overlap across diverse etiologies4. Moreover, the myriad ways in which HF evolves are poorly understood, with many patients showing only mild or no clinical symptoms as underlying disease worsens5, and so it can be particularly challenging to identify which HF patients are at high risk for progression and poor prognosis6,7.
Unfortunately, the constellation of current top-down HF classification and risk stratification systems based on biomarkers such as lab values8,9 and left ventricular ejection fraction (LVEF)10 or functional assessments such as the New York Heart Association (NYHA) classification11 oversimplify the complexity of HF and do not adequately represent the diversity of disease states and how they progress over time10,11. These limitations have left the pharmaceutical community struggling to develop effective risk-enrichment strategies for clinical trials and to determine the appropriate timing for therapeutic interventions without limiting future drug labels to small sub-populations with limited relevance12. Currently it is standard practice to retrospectively analyze failed or successful phase III trials in order to identify patient groups that would benefit from specific treatments. The investigation of the atrial fibrillation (AF) patient subcohort in the failed TOPCAT trial for HF with preserved ejection fraction (HFpEF) is just one example. Patients with a history of AF or AF at enrollment showed increased risk of cardiovascular morbidity and mortality, but no modified response to treatment13. Even if successful, such retrospective analyses can only generate hypotheses for secondary pivotal trials following primary phase III trials, thus requiring massive additional investment in time, money, and patient lives. The gaps in understanding of HF subtypes have also made it difficult for healthcare providers to find optimal treatments for HF patients with comorbid conditions that complicate management. For example, chronic kidney disease (CKD) affects 40–60% of HF patients and is a significant predictor of poor outcomes14,15 yet is underrepresented in general HF studies, leading to insufficient evidence regarding benefits and harms of HF drugs for patients with advanced CKD16. An improved understanding of clinically meaningful HF phenotypic differences and the patterns of HF disease state progression could lead to more targeted and subpopulation-specific therapeutic strategies, as well as earlier identification of patients at high risk for worsening HF, enabling the initiation of preemptive treatments to avoid or slow progression to irreversible end-stage disease HF17,18,19.
Data-driven approaches using data generated outside of a randomized controlled trials (RCTs), known as real-world data (RWD), have the potential to transform practice-based observations into evidence that can aid in bridging the gap between clinical science and practice20. Importantly, electronic health records (EHRs) are becoming increasingly popular as the source for data-driven and machine learning approaches to address many problems in healthcare21, including models for predicting risk in HF22,23,24,25,26. At the same time, there is a growing acknowledgement that patient-centric, data-driven methods to uncover latent patterns within patient populations offer advantages over disease-centric, bottom-up, or simple predictive frameworks for disease understanding and care personalization at a higher level, particularly within complex and multimorbid patient populations27,28 such as those found in HF. With this in mind, a growing body of work has utilized hypothesis-free, data-driven approaches identify groups of similar patients and disease trajectories using targeted clinical markers or data elements from curated registry or EHR data in a variety of disease areas29,30,31,32,33. However, most of these studies have relied on structured data elements; advancements in natural language processing have made it possible to increasingly utilize EHR clinical notes, which contain detailed information that reflects the clinician’s view of a patient’s disease state and severity beyond structured data and lead to additional insights or increased performance in a variety of use cases21,34,35,36,37,38.
We have previously demonstrated that unsupervised clustering of HF patients’ disease and symptom-related concepts derived from natural language processing (NLP) of unstructured notes from the entirety of their longitudinal EHR can reveal the etiology, defining characteristics, and hierarchical relationships of HF phenotypes39. Based on these results, we hypothesized that clustering of clinical concepts from discrete “snapshots” that represent the patients’ disease states over time would reveal a comprehensive picture of the variety of HF manifestations and patterns of evolution dynamics across the population, leading to a data-driven picture of HF that captures the nuance of symptom expression and disease severity. In this study, we developed a hypothesis-free approach to elucidating the diversity of HF manifestation and progression patterns in a cohort of over 25 thousand HF patients treated at a single health center. We used unsupervised clustering to group 30-day patient snapshots into similar HF disease states and identified mathematically stable HF disease state clusters that revealed the dominant patterns of HF clinical manifestations, etiologies, and healthcare consumption at discrete points in the HF disease timeline. To reveal the dynamics of disease progression, healthcare utilization, and clinically important events within the HF population, we statistically analyzed disease state transitions within patient timelines to reveal common temporal networks of HF progression. Significantly, we found that the present and future probability of important clinical events of interest (e.g., ischemic stroke, acute decompensation, and in-hospital mortality) was enriched within certain disease states corresponding to atrial fibrillation, dilated cardiomyopathy, and advanced heart failure, automatically identifying subpopulations in high-risk disease trajectories and providing a roadmap of disease state signatures as potential intervention points to mitigate progression.
In contrast to top-down HF classifications based on limited observations such as functional scores and lab values, such data-driven approaches have the potential to more accurately reflect the disease manifestation and progression patterns of HF patients in the real world. Together, these results demonstrate an approach to generate a hypothesis-free, “at a glance” understanding of large HF populations that captures the diversity of clinical presentations and progression and can be computed on large datasets at scale, which represents a step toward building a more comprehensive heart failure phenome for understanding the disease manifestation of real-world HF patients. This approach utilizes routinely collected EHR data that reflect the population and practices of a specific healthcare center. In particular, the utilization of NLP-based classification of disease and symptom-related concepts in unstructured clinical notes captures the 360-degree physician’s view of patient problems, providing a more complete and nuanced picture of disease severity and manifestation without the need for expensive, time-consuming data abstraction. Such an approach has the potential to deliver real-world insights tuned to the particular needs of clinicians and their patients at the point of care. Additionally, breaking down the HF disease landscape into clinically similar subgroups in time allows for the quantification of risk for various clinical events, which can be used to power alternative risk-enrichment strategies for RCTs that better reflect disease manifestation in the real-world.
Results
Clustering longitudinal EHRs into data-driven HF disease states
To build a patient-centric, data-driven understanding of HF, we utilized a clustering approach to infer HF disease states based on complaints mentioned in a de-identified, longitudinal EHR dataset. Clinical notes were chosen as the data source for discovering HF disease states, since these unstructured narratives contain detailed information about a patient’s complaints (diagnoses, comorbidities, disease severity, symptoms, findings, etc.) that are frequently missing from structured data elements that are used for administrative and financial purposes35,36. By grouping discrete time windows across many HF patient timelines based on the similarity of complaints, we can discover the dominant patterns of disease manifestation over time in a large, real-world HF population.
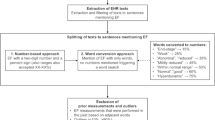
Analysis was carried out on an EHR dataset from Western Russia39. First, a cohort of HF patients was identified (Fig. 1b) and the HF patient trajectories (EHRs) were segmented into 30-day time windows representing the sequence of clinical periods in the longitudinal disease history across the HF cohort. We chose 30 days to represent a clinically relevant time resolution, since a HF patient’s disease state can change significantly month-to-month. The data snapshot for each clinical period consisted of free-text patient complaints, which were extracted using a Russian-language clinical named entity recognition (NER) system36,39 from the totality of the unstructured notes in patient EHRs. Complaints detected by the NLP system with negative polarity were removed from analysis (e.g., “No evidence of heart failure”). NLP-derived complaint mentions were aggregated within 30-day time bins to create monthlong snapshots of the problems experienced by each HF patient (Fig. 1a). The HF cohort included patients with an ICD-10 code for heart failure (I50, I11.0, I13.0, I13.2) or cardiomyopathy (I42). Patients that had less than 10 complaint mentions in any of their snapshots were excluded, resulting in a final study population of 25,861 patients (Fig. 1b). Descriptive statistics for the final study cohort is provided in Table 1.

Workflow diagram for converting HF patient EHRs to disease state snapshot clusters. (a) Natural language processing was used to extract complaints from all the unstructured notes in each patient’s EHR. Complaints were aggregated within 30 day time bins (clinical state “snapshots”). The snapshots of the entire HF cohort were used as input to a clustering algorithm, which finds groups of similar patient snapshots and produces disease state clusters. (b) Inclusion/exclusion criteria and corpus statistics for the final HF cohort.
The snapshots for each patient in the HF cohort were vectorized using term frequency-inverse document frequency (TF-IDF)40. We then defined HF disease states by grouping aggregated complaint snapshot vectors into clusters using K-means clustering41. The resultant clusters contain monthlong snapshots of HF patient timelines grouped by similar patterns of complaints, symptoms, and comorbidities, which can then be interpreted as HF disease states. After clustering, each snapshot data point is labeled as belonging to a single disease state via cluster assignment. Clustering for \(K\in [\mathrm{2,3},...,30]\) revealed stable clusters for \(K=[\mathrm{2,3},4,\mathrm{5,7},\mathrm{11,13,23}]\) via cluster bootstrapping42 (values of K marked with green corridors in Supplementary Fig. S1), which can be understood as the hierarchy of reproducible, data-driven HF disease states.
Characterizing complaints-driven HF disease states
In the following analyses, we focus on building a data-driven picture of HF using 23 disease states (\(K=23\)), the largest value of K investigated that resulted in stable clusters and thus providing the highest level of granularity into HF. To interpret each of the 23 disease states, a right-sided rank sum test was used to find significantly overrepresented input feature complaints (top ten by p-value in Table 2; full list in Supplementary Table S2). We further characterized each cluster by displaying the most common structured diagnosis codes and visit types occurring within the input snapshots (Table 2). Using this information, a clinically interpretable name was assigned to each disease state. We also visualized the HF dataset using t-Distributed Stochastic Neighbor Embedding (t-SNE)43 (Fig. 2a). Each point represents a single HF snapshot; the color indicates the cluster assignment for \(K=23\). From this, we can visualize the relative distance between individual snapshots across the HF cohort.

(a) Exemplary 2D visualization of the relative distances between all clinical snapshots EHRs in the heart failure cohort using t-SNE. Colors show cluster assignment using K-means clustering (K = 23). (b) Visualization of cluster centroids (K = 23) for a subset of complaint features (x-axis). Centroids are sorted by hierarchical clustering and reflect the similarity phenotypes at different values of K. Branches are labeled using a clinical interpretation of the hierarchical structure of the clusters. Each cluster is shown with an interpretable name defining the heart failure phenotype.
Examining Table 2 and Fig. 2a, it is apparent that the snapshots of HF patients are grouped into clusters with shared clinical characteristics. Qualitatively, we observe that some clusters appear more similar to each other than others. For example, clusters for Ischemic heart disease, Acute coronary syndrome, and CAD & HTN, male are grouped closely together. To quantify and visualize the natural hierarchy of heart failure disease states within the cohort, we constructed a dendrogram for \(K=23\) using hierarchical clustering (Fig. 2b, right). The stable clusters used in constructing the dendrogram were \(K=[\mathrm{2,3},\mathrm{4,5},\mathrm{7,11,13,23}]\) (marked with green corridors in Supplementary Fig. S1). All snapshots are aggregated at the right side of the dendrogram; each successive branch point shows the value of K at which a cluster splits into two smaller clusters. Branch points further to the left on the dendrogram represent clusters that are more similar to each other as quantified by their Jaccard index (see Supplementary Methods). The feature values of fifty common complaint features are shown for \(K=23\), sorted by the order in the dendrogram (Fig. 2b, left).
Finally, to further characterize HF disease states, we aggregated input feature complaints into grouped complaint phenotypes. For example, the phenotype Myocardial infarction aggregates the more specific complaints “Myocardial infarction,” “Acute myocardial infarction”, “Subendocardial myocardial infarction”, “History of myocardial infarction”, “Post-myocardial infarction syndrome”, and “Recent myocardial infarction” (Supplementary Table S3). Doing so allows us to visualize the prevalence and specificity of meaningful clinical phenotypes for each disease state (selected clusters shown in Fig. 3a). We also characterized these disease states in terms of number of patients/snapshots falling within the cluster, sex distribution, age, body mass index (BMI), and in-hospital mortality (Fig. 3b).

(a) The prevalence of various grouped complaints per cluster disease state. Traces in red show the prevalence (%) of the grouped complaints within the cluster, while the dotted gray line shows the prevalence in the entire cohort. Gray bars indicate the odds ratio of the grouped complaint occurring within the cluster. Complaint groups with an odds ratio > 2 within the disease state cluster are marked with a red circle and the text of the complaint. Complaint groups with an odds ratio < 2 but a prevalence > 50% within the disease state cluster are shown with a black circle and the text of the complaint. (b) Clinical characteristics of disease state clusters.
We show that a hypothesis-free, high dimensional approach using unstructured data can successfully segment temporal snapshots of HF into meaningful groups without the need for any time-consuming, top-down data structuring approaches. In the next section, a detailed clinical interpretation of HF disease states is presented based on these results.
Clinical interpretation of HF disease states
From Fig. 2b, we observe that HF disease states can be interpreted hierarchically. We use this hierarchy and disease state characteristics as a framework to provide a clinical description of each HF disease state (Table 3). The first major split in HF occurs between ischemic and non-ischemic heart disease. Ischemic heart disease then splits into subgroups corresponding to disease states dominated by metabolic, vascular, and heart valve disease (Diabetic complications, CAD with arteriosclerosis, Lipid disorders, Aortic stenosis, Cerebrovascular disease, and General vascular disease) and those with acute coronary syndrome, aneurysm, and cardiac surgery (Aneurysm, CAD with myocardial ischemia, CAD with cerebral involvement, Cardiac surgery, Acute coronary syndrome, and CAD, high acuity).
The first split within the non-ischemic heart disease branch contains infants and children with congenital heart disease (Congenital heart defects and Neonatal intensive care (NICU)). The next branch contains disease states dominated by cardiac diagnostic modalities (Echocardiography, Electrocardiography, and Electrocardiography with apnea). Finally, at higher values of K, the non-ischemic branch culminates in two further subgroups; the first contains patients with various types of cardiomyopathies (Hypertrophic cardiomyopathy and Pediatric cardiomyopathy) and various non-cardiac complaints (Non-cardiovascular (CV) encounters), while the second contains patients with advanced heart failure and high-risk comorbidities (Atrial fibrillation, Dilated cardiomyopathy, and Advanced & decompensated HF).
Table 3 provides a brief clinical description of each disease state (based on information in Table 2, Fig. 3, Supplementary Table S4). A more in-depth description of each disease state can be found in the supplementary appendix.
Quantifying HF patients at risk
Understanding risk in patient populations is central to healthcare, from therapy development to clinical decision making. HF patients in particular are at significantly higher risk of morbidity and mortality4. From the previous section, we can observe that the HF disease states represent differential levels of disease severity, and that there are complaints associated with certain states that correspond to poor outcomes (e.g., “decompensation” in Advanced & decompensated HF). To quantify the risk within the HF cohort, we defined clinical events of interest, including patient encounter type (hospitalization, ICU admission), in-hospital mortality, acute conditions (ischemic stroke, acute kidney injury, decompensation, pulmonary embolism, aneurysm), and procedures (CABG, angioplasty, septal defect correction, aneurysm repair, valve repair & prosthesis, pacemaker implantation, and heart transplant). We then labeled each data point in the dataset with binary labels that indicate whether or not each clinical event occurred within the 30-day snapshot window. Additionally, to quantify the future risk of an event, we labeled snapshots that occurred before snapshots containing the event.
Using these labels, the prevalence of clinical events in present and future snapshots can be visualized over the entire HF cohort using kernel density estimation (Fig. 4a). For example, in-hospital mortality is concentrated within Advanced & decompensated HF, NICU, and a concentrated area of snapshots in Cardiac surgery. We also observe that snapshots within the Aortic valve disease cluster show relative enrichment for risk for mortality in a future snapshot. Similarly, although CABG occurs primarily within the Cardiac surgery disease state, we observe that patients in CAD, high acuity, CAD with myocardial ischemia, Cerebral ischemia, and Aneurysm are most at risk for a future CABG. Similarly, although hemorrhagic and ischemic strokes are both concentrated within the Cerebrovascular disease state, risk enrichment differs for these two events; for hemorrhagic stroke, patients in Aneurysm, Dilated cardiomyopathy, Advanced & decompensated HF, and Aortic stenosis are most at risk, while for ischemic stroke, patients in Diabetic complications, Atrial fibrillation, Aortic stenosis, General vascular disease and Aneurysm were most at risk.

Current and future risk enrichment for clinical events in HF disease states. (a) Kernel density estimate of clinical events overlaid over HF disease states for six events: hospitalization, in-hospital mortality, and coronary artery bypass graft, hemorrhagic stroke, ischemic stroke, and acute kidney injury. Red density shows the density of snapshots in which the clinical event occurs (N clinical events). Blue density shows the density of snapshots before the first occurrence of the event (N snapshots before event). (b) Prevalence of clinical events (%) for the patient population in each disease state cluster in (a).
We also quantified risk of present and future events over all events (Fig. 4b). Using this framework, we can gain insight into the probability of near-term and future events associated with HF subpopulation disease states. For example, in Lipid disorders patients, the prevalence of stroke is very low (0.5%) but risk for a future stroke is relatively high (3.0%), uncovering the well-studied association between elevated lipid levels and stroke4,44,45,46 without relying on lipid level measurements as an explicit biomarker. Similarly, we observe that patients in the Dilated cardiomyopathy state have a relatively high risk of future in-hospital mortality (2.4%), indicating that patients within this group are likely to suffer adverse outcomes and present a large expense to health systems. This approach to comprehensive risk assessment provides an at-a-glance, high-level understanding of risks of adverse outcomes and patterns of hospital resource consumption across HF disease states which could benefit targeted strategies for risk mitigation in HF subpopulations.
Building a temporal progression map of HF disease states
Understanding the patterns of disease progression is vital in chronic, slowly progressing diseases like heart failure. Here, we develop an approach to understand the temporal progression of HF disease states within patient timelines. HF typically manifests as the end stage of another disease process and as a result, HF patients typically experience a large number of comorbidities and clinical states over the course of their disease. To illustrate how multiple disease state clusters manifest during HF progression, Fig. 5a shows an exemplary case study from a patient in the HF cohort. The patient was first referred to a cardiologist at the health system used in our study for worsening symptoms on a background of coronary artery disease and heart failure, at which time the complaints mentioned in the patient’s clinical notes led the disease state to be classified as CAD with arteriosclerosis. At the patient’s next snapshot, labeled as Echocardiography, they received an echocardiogram, which revealed newly diagnosed atrial fibrillation. Finally, in their last snapshot, the patient was hospitalized with acutely decompensated heart failure and was assigned the state Advanced & decompensated HF.

(a) Example timeline of a patient in the heart failure cohort. Visits have been aggregated into time bins and a clinical summary of the visits is provided. The disease state (cluster assignment) of each snapshot is shown. (b) Schematic illustrating the construction of a cluster co-occurrence matrix and cluster order count matrix using eight patient timelines from the HF cohort. The first timeline (P1) is expanded in (a). (c) Odds ratio of clusters co-occurring within HF patients for a selected subset of clusters, computed over all patients. Values greater than 1 (blue) indicate a positive association, while values less than 1 (red) indicate a negative association. Odds ratios falling outside of a 95% confidence interval are masked. (d) For selected cluster pairs, probability of the first cluster (y-axis) coming before the second cluster (x-axis) in patients in which both clusters co-occur across the entire HF population.
To understand the dominant patterns of disease state progression over time across the entire HF cohort, we employ a twofold approach that first finds significantly co-occurring disease state pairs within patient timelines and then determines the probability of each disease state occurring first or second within a patient timeline. To do so, we count the number of patients in which each disease state pair co-occurs, then compute the odds ratio of the two states co-occurring. A positive and statistically significant odds ratio quantifies the association between pairs of disease states. Next, for each disease state pair \({S}_{i}\) and \({S}_{j}\), we count the number of times that \({S}_{i}\) occurs before \({S}_{j}\) in patients in which both disease states occur. From this, we can compute the probability of \({S}_{i}\) preceding \({S}_{j}\) across the entire HF cohort, revealing the order in which positively associated disease state pairs tend to occur. The process of computing cluster co-occurrence and temporal ordering is shown for eight exemplary HF patient timelines in Fig. 5b. Statistically significant cluster co-occurrence odds ratios and cluster order probabilities for ten disease state clusters are shown in Fig. 5c,d (results for all clusters are shown in Supplementary Figs. S4 & S6).
Using the odds ratio computed from disease state co-occurrence between all clusters, we can construct a temporal network of HF disease states (Fig. 6a, odds ratio ≥ 1.33). The directionality of network edges reflects the disease state order probability in Fig. 5d, where probabilities in the range [0.45, 0.55] are shown as bidirectional arrows. The median time to transition between two disease states is overlaid on each edge. In this representation, we can observe disease states with only outgoing arrows, which we labeled as “start” states, and disease states with only incoming arrows, which we labeled as “end” states. We also observed a set of partially overlapping HF disease state “subnetworks” that contain both “start” and “end” states and a network of high-frequency state transition pathways, which are shown with transparent overlays. To aid in the interpretation and clinical insights of this network, demographic information (Fig. 6b), grouped complaint phenotypes (Fig. 6c), and clinical events (Fig. 6d) are shown overlaid on the network.

(a) Temporal patterns of HF evolution. Network diagram showing connections between positively associated clusters (odds ratio > 1.33). Node size is proportional to the number of snapshots with the corresponding cluster assignment. Arrow thickness is proportional to the odds ratio in Fig. 5c. Arrow direction is derived from Fig. 4b; probabilities in the range [0.45, 0.55] are shown as bidirectional arrows. The median number of 30 days bins (months) for patients to transition between disease states is overlaid on the arrows. When arrows are bidirectional, the mean of the two values is shown. Disease states with only outgoing arrows are as labeled as “start” states, whereas disease states with only incoming arrows are labeled as “end” states. HF disease state subnetworks are shown with transparent overlays. (b) The prevalence of demographics (age, sex), (c) comorbidities (grouped complaints), and (d) clinical events overlaid on the network in (a).
Visualizing demographics, grouped complaint phenotypes, and clinical events on top of this network provides a unique framework for hypothesis-free and scalable insight generation within a health system. Some example subnetworks are highlighted below.
Juvenile HF
The youngest patients are concentrated in the subnetwork containing NICU, Congenital heart disease, and Pediatric cardiomyopathy (Fig. 6b, orange overlay). The disease state NICU serves as an entry point for HF for infants with congenital heart disease; those who survive the ICU (Fig. 6d) transition to the more stable states of Congenital heart disease and Pediatric cardiomyopathy.
Coronary artery disease, male-dominated
Another subnetwork we observed contains disease states pertaining to ischemic heart disease (Fig. 6a, blue overlay). In this subnetwork, Acute coronary syndrome serves as an entry point into further disease states, which supports the understanding of myocardial infarction as a driver of HF4. Within this male-dominated subnetwork (Fig. 6b), patients then progress to disease states CAD with myocardial ischemia and CAD, high acuity. Because they have HF stemming from an ischemic etiology, patients within this subnetwork frequently reach advanced disease end states of Cardiac surgery (CABG), Cerebrovascular disease, and Diabetic complications.
Coronary artery disease, female-dominated
In this subnetwork, we observe that Lipid disorders, which contains obese patients with hyperlipidemia and hypertension, is also an entry point to HF (Fig. 6a, yellow overlay). This state is commonly followed by CAD with cerebral involvement, which contains similar complaints as Lipid disorders but also contains additional comorbidities indicative of a more advanced disease state, (e.g., higher rates of atherosclerosis and angina, Fig. 3a). These patients then commonly progress to Diabetic complications and Cerebrovascular disease. Within the HF network, this subnetwork exhibits the highest prevalence of females (Fig. 6b), corroborating findings of distinct and separate progression patterns for males and females with HF47.
High-risk HF
We observe another subnetwork (Fig. 6a, red overlay) in which patients with snapshots in the Atrial fibrillation, Dilated cardiomyopathy, and CAD with arteriosclerosis clusters are likely to also experience Advanced & decompensated HF, the end state for this subnetwork and the state with the highest adult morality (Fig. 6d) and rates of other indicators of poor outcomes, including thromboembolism (Fig. 6d), respiratory failure, and decompensation (Fig. 3a). Although CAD with arteriosclerosis has complaints that are similar to the other disease states of ischemic heart disease, it also contains several complaints that distinguish it from the other groups, including higher rates of cardiomegaly (Fig. 3a) and thyroid disorders (Fig. 6c), which may point to potential factors for differential risk identification within HF subpopulations. In fact, thyroid disorders have a uniformly high prevalence in the subnetwork with advanced HF and within the Diabetic complications state, identifying correlates of poor outcomes and potentially identifying patients in need of alternative treatment strategies48. Similarly, the prevalence of CKD is highest in Advanced & decompensated HF and Diabetic complications (Fig. 6c), two of the most advanced disease states within the HF network, matching previous findings of CKD as a risk factor for poor outcomes47.
Taken together, these results highlight the typical progression patterns of HF disease states within a single health system. Importantly, we show that there are several subnetworks of disease states, which contain patients with similar clinical manifestations and progression pathways of HF.
Discussion
Understanding real-world disease manifestation and progression is a crucial step in developing and implementing effective interventions49. Historically this has been challenging in practice, especially in multifaceted syndromes such as HF where patients are elderly, highly complex, and have a range of lifestyle factors that vary widely across populations and play a large role in disease development and progression4,50. Disease-specific guidelines derived from results of RCTs with narrow inclusion/exclusion criteria, enrollment biases, and highly protocolized care may not be generalizable to large segments of the population across diverse geographies, sociodemographic categories, or health systems49. Additionally, such guidelines typically rely heavily on biomarkers and functional classifications, which may not reflect the nuance of disease presentation and severity that may be necessary to drive more targeted intervention strategies10,11. As a result, pharmaceutical companies and healthcare providers do not have an accurate and complete map of the HF disease landscape that is inclusive of all manifestations, progression patterns, and treatment responses across the full spectrum of HF patients that can be used to guide development of better interventions and management strategies. Generating practice-based evidence from RWD has emerged as a potential solution to these problems20, but challenges in data quality and methodological limitations to take noisiness into account have limited the applications of RWD51,52,53. Much research has focused on supervised predictive models that use limited variables or curated data for specific use cases22,23,24,25,26, but these approaches do not offer a more top-down view of disease that can be used in higher-level decision making.
In this study, we present an alternative approach to understanding the real-world manifestation and progression of HF by using a data-driven methodology for identifying HF disease states and common trajectories. In contrast to top-down approaches that use predefined criteria to classify HF disease states, the unsupervised, hypothesis-free approach presented in this study requires no high-level data structuring or top-down definitions. Instead, we utilized free-text mentions of complaints extracted from clinical notes, which contain the rich descriptors of patient disease that are not found elsewhere in RCTs or other secondary use datasets. The resultant HF disease states are clinically meaningful in terms of HF etiology, comorbid conditions, symptoms, disease severity, and care utilization patterns, and have the potential to provide a richer and more complete picture of patient disease states at both an individual and population level compared to top-down classifications. Characterizing these HF states over time reveals a more differentiated picture of HF presentation and evolution dynamics across a large population, which begins to characterize a comprehensive HF phenome that can be computed on large datasets at scale to capture the patterns of clinical presentation of HF patients based on real-world clinical practice.
We demonstrate the utility of the HF phenome in a large HF population in Western Russia. By revealing how patients with similar disease states typically progress into more severe disease states over time, our approach allows us to identify differential risk patterns for future undesirable events in high-risk HF disease states. For example, by identifying the disease states in which thromboembolisms (Fig. 6c) or ischemic strokes (Fig. 6d) are most prevalent, the patients on the pathways that lead to these higher-risk states can be specifically targeted for early intervention. We also observe HF disease states (for example, those corresponding to outpatient CAD) that appear very similar in terms of complaints and patient characteristics but that have very different risk profiles and progression pathways, which may not be differentiated using a limited set of top-down criteria (such as trial inclusion/exclusion criteria). This intriguing finding that similar-looking patient subgroups can experience dramatically different progression pathways further supports the assertion that current classification schemes do not adequately represent real world HF disease trajectories and warrants further research into the factors leading to disparate outcomes across HF subpopulations. This breakdown of the HF disease landscape into clinically-similar disease states over time allows for the quantification of risk of various endpoints within more precisely defined subpopulations, which can help providers decide which populations to focus on within resource-constrained care settings. At the same time, for the pharmaceutical industry there is also potential to enable risk-enrichment strategies in RCTs that more reliably reflect disease progression in the real world. EHR-derived progression phenotypes could also provide evidence for alternative clinical endpoints that truly reflect the disease burden and medical need under standard of care conditions. This can be particularly valuable when population-specific guidance from RCTs are limited, unreliable, or unavailable.
An additional advantage of the data-driven approach employed in this work is that the insights into HF manifestation and progression are generated in a scalable manner on routinely collected EHR data and can thus serve as the basis for a highly tailored and localized landscape of disease that reflects the population and practices specific to targeted subpopulations, including those found in individual healthcare systems. Using a single unified approach, we find that we are able to replicate many well-established etiologies, risk factors, and progression patterns of HF. At the same time, our approach also surfaces patterns localized to the specific study population that may not be apparent via top-down methods. For example, in the Russian EHR dataset used for this study, we found a high prevalence of younger males with alcoholic cardiomyopathy54 and high prevalence of structural valve changes and complications due to rheumatism55, two groups which would likely still be present but likely at much lower numbers in a US dataset. Localized HF landscapes could serve as the foundation for data-driven personalized medicine, with the potential to deliver real-world insights tuned to the particular needs of clinicians and their patients at the point of care. Given that large portions of real-world HF populations are still underrepresented in clinical research, especially older patients, women, minorities56, and patients living outside specific geographies that are typically targeted for RCTs, this approach may be of particular value for risk-bearing healthcare entities to better understand outcomes and treatment performance more accurately and completely across diverse populations. Periodic regeneration and assessment of localized HF landscapes within healthcare systems over time could also help providers understand the impact of changes in HF management strategies and the local patient population on outcomes and provide a feedback system for further hypothesis generation and optimization of care programs.
Limitations and future directions
In this study, we utilize clinical notes from a single health system to generate an unsupervised, hypothesis-free understanding of HF disease states and progression pathways. A potential limitation of our study is that although a large number of HF patients were used in the analysis (N = 25,861), it remains to be determined whether the HF disease states presented in this work will remain stable across larger patient populations and geographies. Additionally, in this work we defined HF disease states using only complaints extracted from clinical narratives in the EHR without using any structured data (e.g., diagnostic codes) or structured or unstructured data corresponding to clinical interventions (e.g., medications, procedures) or measurements (e.g., vitals, labs, diagnostics). Future avenues of research can explore utilizing additional sources of information in the EHR as data sources for HF subtyping, as well as additional healthcare data sources such as administrative data and claims.
The clustering methodology used in this study assigns one disease state per data point. A future direction of study could utilize multi-assignment clustering models, which may be explored in an attempt to explicitly model multimorbidity. Furthermore, we observe patients with similar complaints (i.e., CAD disease states) that ultimately experience very different progression pathways and outcomes; future research could explicitly model longer term disease state trajectories rather than the pairwise approach taken in this work to understand more complex, nuanced relationships between disease progression and outcomes.
We demonstrate the ability to generate a high-level understanding of the real-world manifestation of HF within a health system using only unstructured data. A natural extension of this work would be to further analyze these HF subgroups using interventions, outcomes, and other covariates. For example, future research could analyze how covariates such as age, sex, comorbidities or other complaints, or even traditional biomarkers such as LVEF may correlate with or serve as drivers of disease progression between the HF disease states identified in this study. Additionally, because the methodology developed in this study groups patients together by similarity of disease manifestation at a particular point in time, future research could characterize the treatment response of different HF subgroups, potentially identifying treatments with differential impact on disease progression and critical outcome measures across different stages and etiologies of HF. Such an approach can thus serve as the basis for comparative efficacy studies and potentially serve as a supplement or alternative to other population matching methods such as propensity scoring.
Methods
Description of dataset
In this study, we analyzed de-identified secondary healthcare data that was extracted from the EHR system of a national medical research center located in Western Russia39. The center provides the full cycle of medical services, including inpatient and outpatient departments, imaging, rehabilitation services, perinatal care (including pediatric intensive care and surgery), and dentistry. Inpatient services are spread across various institutes and departments, and include, among others, internal medicine, functional diagnostics, intensive care units (ICU), including neonatal ICU (NICU), surgery (including cardiovascular, oncology, neurology, robotic surgery, etc.), clinical pharmacology, and chemotherapy. The longitudinal records used in this study were collected over a 10-year time span (2008–2018). Use of de-identified data for research purposes was approved by the institution. The study was verified IRB exempt as non-human subjects research not requiring informed consent according to 45CFR46.104(d) (Solutions IRB). All research was performed in accordance with relevant guidelines and regulations.
A Russian-language clinical NER system36,39 was used to extract free-text complaints from the totality of the unstructured notes in patient EHRs. The NER system (Droice Flamingo) extracts mentions of clinical concepts from several clinically relevant ontologies included in the Unified Medical Language System57 (UMLS) and maps them to a concept unique identifier (CUI), which allows different strings to be matched to the same normalized entity (e.g., “Type 2 diabetes” and “DM2” will both be assigned the same CUI). In this study, we extracted entities in SNOMED CT and represented each entity by its normalized CUI. Within UMLS, each CUI has one or more semantic types. We limited our analysis to entities corresponding to patient complaints (e.g., diseases, signs, symptoms, conditions; for a full list of UMLS semantic types, see Supplementary Table S1) and discarded entities corresponding to interventions (e.g., medications, procedures) and anatomy. We also removed from the analysis all entities with negative polarity (e.g., “Patient denies headache”).
Clustering complaint feature vectors
We utilized a cluster-based approach to construct HF disease states. The HF disease state clusters used as the basis of this study are constructed from a large dataset (> 100,000 examples) and underwent extensive clinical interpretation; we thus chose K-means as the clustering algorithm because of the inherent interpretability of the resultant cluster centroids and its ability to scale well to large datasets. We aggregated all positively mentioned complaints for each patient over the entirety of the EHR timeline to generate a vector of counts of each complaint for each patient, which was used as the input to K-means clustering. The vector of counts of complaints of each patient was transformed using term frequency-inverse document frequency41 (TF-IDF). Templated forms and copy and pasting are common phenomena in clinical text and become even more prevalent in patients with longer records. To reduce the contribution of repeated text chunks and normalize term counts over patients with different timeline lengths, we utilized a logarithmic term frequency, followed by an L2 normalization of each patient vector.
The relative frequency of complaints in the dataset follows a power law distribution. To limit the dimensionality of the representation and to exclude rare terms, we restricted the complaints vocabulary \(V\) to 99% the most frequent complaints, which reduced the vocabulary size from 9,375 to 1,276. Vectorization of the entire heart failure cohort results in a two-dimensional matrix of the form \(P=({p}_{i,j})\epsilon {R}^{N\times V}\). Here, N denotes the number of snapshots in the cohort (N = 103,833).
Evaluation of clustering models
We hypothesized that clustering with different \(K\) values (numbers of clusters) would group HF snapshots by different levels of disease hierarchy (i.e., small values of K would result in cohorts grouped by broad disease features, whereas a large values of \(K\) would results in cohorts grouped by more granular disease features). To determine which values of \(K\) yield stable clusters for the HF dataset, we quantified cluster stability for each value of \(K\) with a bootstrapping strategy42. For values of K that represent true clusters in the underlying dataset, these clusters should be re-identifiable in randomly subsampled portions of the original dataset.
First, for \(K\epsilon [\mathrm{2,3},\dots ,30]\), we clustered data points via K-means clustering to obtain reference clustering results \([{C}_{K=1}^{ref}, {C}_{K=2}^{ref}, ..., {C}_{K=30}^{ref}]\). Then for each reference clustering result for each value of K, we utilized a cluster bootstrapping strategy in which we 1) subsampled a fixed fraction of the original dataset \({f}_{d}\) then 2) clustered again to generate a bootstrapped clustering result \({C}_{K=k}^{{f}_{d}}\). We repeated the bootstrapping for varying fractions of data \({f}_{d}\epsilon [0.5, 0.25, ..., 0.0078125]\) to investigate whether the size of the available dataset would limit the level of accuracy and robustness of the cluster identification. This procedure was repeated 1000 times for each value of \(K\) and each fraction of data.
To evaluate the stability of clustering results, we compared the similarity of each bootstrapped clustering result to the corresponding reference clustering at each value of \(K\). The Jaccard index characterizes how robust the grouping of patients within a cluster is to changes in the specific population of patients through random subsampling of the data set. Similarity was thus calculated using the Jaccard index across the reference and bootstrapped clustering results:
Here \(N\) denotes the number of data points used in both clustering models, \({n}_{ij}\) is the number of datapoints present in cluster \(i\) from reference clustering \({C}_{K=k}^{ref}\) and cluster \(j\) from bootstrapped clustering \({C}_{K=k}^{{f}_{d}}\). \({J}_{ij}\) is the Jaccard index between in clusters \(i\) and \(j\):
For each value of \(K\) and each fraction of data, this analysis yields a distribution of 1000 values of \(J\), which can be used to quantitatively compare the stability of clustering across different values of \(K\). In this formulation, a value of \(J=1\) means that the data has been partitioned identically in the reference and bootstrapped clustering (perfect stability). As less data is sampled for bootstrapping (lower values of \({f}_{d}\)), we can empirically test the amount of data at which the clustering result breaks down.
To test the stability of the medical concepts characterizing the different patient clusters, we utilized a semantic similarity measure based on a modification of the Jaccard index. Semantic similarity S quantifies the similarity of the significant complaints associated with each cluster between the reference and bootstrapped clustering results:
As before, \(N\) denotes the number of datapoints used in both clustering models, \({n}_{ij}\) is the number of datapoints present in cluster \(i\) from reference clustering \({C}_{K=k}^{ref}\) and cluster \(j\) from bootstrapped clustering \({C}_{K=k}^{{f}_{d}}\). \({S}_{ij}\) is the semantic similarity index between in clusters \(i\) and \(j\), and quantifies the overlap of the significantly associated complaints vocabularies between the two clusters:
As with the Jaccard index bootstrapping, we repeated the bootstrapping for varying fractions of data \({f}_{d}\epsilon [\mathrm{0.5,0.25},...,0.0078125]\). Robust identification of local maxima in \({J}_{ij}\) and \({S}_{ij}\) across increasingly diminishing fractions of the data provides the basis for selection of stable clusters.
Selection of K and constructing disease state hierarchies
To select the valid values of \(K\) that can be considered HF disease states at differing levels of hierarchy, we considered local maxima when sampling 50% of data (\({f}_{d}=0.5\)) resulting in \(m\) values of \(K\epsilon [{k}_{max}^{1},{k}_{max}^{2},\dots ,{k}_{max}^{m}]\). After choosing to analyze a set of clusters satisfying both local maximum criteria at a given value of \(K\), which we denote \({m}^{*}\), we aimed to visualize the hierarchical structure of the clustering result. Doing so allows us to understand which disease states are more similar to each other and thus frame the results at various levels of hierarchy. To do so, we computed the Jaccard index between the clustering results \({C}_{max}^{m*}\) and the clustering result for all local maxima for values of \(K\) less than \({m}^{*}\) \({C}_{max}^{m}\), \(m \epsilon [{m}^{*}-1,{m}^{*}-2,\dots ,1]\). This results in a Jaccard similarity matrix of size \([{m}^{*} \times m]\); we then computed the pairwise distance between each cluster in \({C}_{max}^{m*}\). We repeated this for each value of \(m\), computed the average, then use the resulting combined distance matrix to create a dendrogram using hierarchical clustering (complete linkage). The resulting HF disease state dendrogram allows us to understand the hierarchical relationship between clusters at different values of \(K\) and provides a visualization that can be understood as a phylogenetic tree of complaints and symptoms.
Statistical testing for identification of distinctive features of disease states clusters
To interpret clusters of patients discovered via K-means clustering, we utilized statistical testing to find complaints that were significantly overrepresented within the cluster as compared to the rest of the heart failure population. Doing so allows us to determine the distinguishing features (medical complaints) of each cluster. More specifically, for each cluster \(i\) we break the patient matrix \(P\) into two submatrices, \({P}_{i}\) and \({P}_{j}\), where \({P}_{i}\) contains the data points of all patients from cluster \(i\) (\(k=i\)) and \({P}_{j}\), contains the data points from all other clusters (\(k\ne i\)). For each feature \(f\), we then use a right-sided t-test to test the null hypothesis that the mean of the TF-IDF features in \({P}_{i}^{f}\) are equal to \({P}_{j}^{f}.\) Rejection of the null hypothesis for feature \(f\) means that this complaint is overrepresented in cluster \(i\) and can be interpreted as a distinguishing characteristic of the cluster. Performing this test for each complaint within a cluster yields a vocabulary of significantly associated complaints \({V}_{s}\). We employed Bonferroni correction for multiple comparisons. Samples were tested to confirm to be normally distributed.
Grouping complaint features into clinical phenotypes
The complaint features used in this study were extracted from clinical text and mapped to SNOMED CT, which has a hierarchical structure. As a result, there are terms in the feature vector that are more specific than others. For example, there are features that correspond to anemia, a more general term, as well as iron-deficiency anemia, hemolytic anemia, and hypochromic anemia, which are more specific types of anemia. To summarize these hierarchical relationships between disease state features, we defined 50 high-level complaints and utilized a keyword-based search to group input complaint features into these grouped complaint clinical phenotypes (Supplementary Table S3).
Calculating clinical characteristics for HF disease states
In addition to analyzing the NLP-derived concepts, each HF disease state was further characterized by the sex distribution (% female), median age, median BMI, and prevalence of in-hospital mortality. The sex of each patient and in-hospital mortality were derived directly from structured fields within the EHR. For each data element in the de-identified analysis dataset, age was calculated as the difference between the element timestamp and the patient’s date of birth (days), with ages above 90 years set to 90 years (32,872 days); the age used to compute the median age of the disease state snapshot was the age of the patient when they first entered the snapshot, converted to years. The BMI of the patient at each disease state was taken as the average of all BMI measurements taken within the 30 day window. Because BMI is not measured at all visits, for each disease state, the fraction of data points used in the calculation of median BMI is provided in Supplementary Fig. S2.
Clinical summary of HF disease states
Each HF disease state cluster can be understood as HF patient timeline segments grouped by similar patterns of complaints, symptoms, and comorbidities; disease states are complex and typically multimorbid. Although it is difficult to summarize such complex patterns succinctly, to facilitate communication of results and interpretation of figures, each disease state was given a clinically interpretable name and concise description by the authors (Table 3). The cluster names and descriptions were based on interpretation of Table 2, Supplementary Table S2, and Figs. 2 & 3.
Defining temporal progression between HF disease states
Once we characterized HF disease states based on complaints over 30-day time windows, we sought to quantify the temporal relationship between these states to understand HF disease evolution. This was accomplished using a two-step process.
Quantifying the association between disease states
First, we quantified the likelihood that each disease state (cluster) pair co-occur within a patient’s timeline over the entire HF population. This was done by computing a cluster-wise co-occurrence matrix (Fig. 5b), then computing the odds ratio between each cluster pair58 (Fig. 5c). For disease states i and j, the odds ratio would be computed as \({OR}_{ij}=\frac{{n}_{i,j}{n}_{\neg i,\neg j}}{{n}_{i,\neg j}{n}_{\neg i,j}}\), where \({n}_{i,j}\) is the number of times disease states i and j cooccur across the HF cohort, \({n}_{i,\neg j}\) is the number of times disease state i occurs with any disease state that is not disease state j, \({n}_{\neg i,j}\) is the number of times disease state j occurs with any disease state that is not disease state i, and \({n}_{\neg i,\neg j}\) is the number of disease state co-occurrences across all disease states that are not i or j. Statistically significant cluster pairs with odds ratios > 1 were considered positively correlated.
Temporally ordering disease states
Next, for each cluster pair \({c}_{i}\) and \({c}_{j}\), we computed a count matrix that counts which cluster comes first in patients where both clusters occur (Fig. 5b). Normalizing these counts into probabilities yields the probability that \({c}_{i}\) occurs before \({c}_{j}\) over the entire HF dataset (Fig. 5d).
Combining steps 1 & 2 for each cluster pair, we can both quantify the strength of the association between the clusters and assign a temporal directionality to positively associated disease state clusters. These relationships can be visualized as a graph, which describes the temporal relationship between HF disease states (Fig. 6). To emphasize stronger associations, statistically significant odds ratios > 1.33 were used as edges in the graph. The direction of edges was computed using the temporal ordering of clusters, where probabilities in the range [0.45, 0.55] are shown as bidirectional arrows.
Statistical package versions
TF-IDF vectorization, K-means clustering, and t-SNE were implemented using Python’s Scikit-learn (0.19.1). Statistical tests were implemented using Scipy (1.3.0).
Data availability
The patient-level electronic health record dataset was made available for this study with permission from the originating health system. The de-identified analysis dataset that supports the findings of this study may be made available to qualified investigators upon request with appropriate institutional review board approval and execution of a data use agreement with Droice Labs. For requests for access to the data, interested researchers should contact data-requests@droicelabs.com.
References
Lippi, G. & Sanchis-Gomar, F. Global epidemiology and future trends of heart failure. AME Med. J. 5, 15–15 (2020).
Chioncel, O. et al. Epidemiology and one-year outcomes in patients with chronic heart failure and preserved, mid-range and reduced ejection fraction: An analysis of the ESC Heart Failure Long-Term Registry. Eur. J. Heart Fail. 19, 1574–1585 (2017).
Tromp, J. et al. Biomarker profiles in heart failure patients with preserved and reduced ejection fraction. J. Am. Heart Assoc. https://doi.org/10.1161/JAHA.116.003989 (2017).
Ponikowski, P. et al. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure. Eur. Heart J. 37, 2129–2200m (2016).
Sabbah, H. N. Silent disease progression in clinically stable heart failure. Eur. J. Heart Fail. 19, 469–478 (2017).
Kosiborod, M. et al. Identifying heart failure patients at high risk for near-term cardiovascular events with serial health status assessments. Circulation 115, 1975–1981 (2007).
O’Connor, C. et al. Clinical factors related to morbidity and mortality in high-risk heart failure patients: The GUIDE-IT predictive model and risk score. Eur. J. Heart Fail. 21, 770–778 (2019).
Ibrahim, N. E., Gaggin, H. K., Konstam, M. A. & Januzzi, J. L. Established and emerging roles of biomarkers in heart failure clinical trials. Circ. Hear. Fail. https://doi.org/10.1161/CIRCHEARTFAILURE.115.002528 (2016).
Savarese, G. et al. Utilizing NT-proBNP for Eligibility and Enrichment in Trials in HFpEF, HFmrEF, and HFrEF. JACC Hear. Fail. 6, 246–256 (2018).
Triposkiadis, F. et al. The continuous heart failure spectrum: Moving beyond an ejection fraction classification. Eur. Heart J. 40, 2155-2163B (2019).
Papadimitriou, L., Moore, C. K., Butler, J. & Long, R. C. The limitations of symptom-based heart failure management. Card. Fail. Rev. 5, 74–77 (2019).
U.S. Department of Health and Human Services, Food and Drug Administration, Center for Drug Evaluation and Research (CDER) & Center for Biologics Evaluation and Research (CBER). Enrichment strategies for clinical trials to support determination of effectiveness of human drugs and biological products: Guidance for Industry. https://www.fda.gov/Drugs/GuidanceComplianceRegulatoryInformation/Guidances/default.htmand/or https://www.fda.gov/BiologicsBloodVaccines/GuidanceComplianceRegulatoryInformation/Guidances/default.htm (2019).
Cikes, M. et al. Atrial fibrillation in heart failure with preserved ejection fraction: The TOPCAT trial. JACC Hear. Fail. 6, 689–697 (2018).
Grande, D., Gioia, M. I., Terlizzese, P. & Iacoviello, M. Heart failure and kidney disease. in Advances in Experimental Medicine and Biology vol. 1067 219–238 (Springer New York LLC, 2018).
Shiba, N. & Shimokawa, H. Chronic kidney disease and heart failure-Bidirectional close link and common therapeutic goal. J. Cardiol. 57, 8–17 (2011).
Lunney, M. et al. Pharmacological interventions for heart failure in people with chronic kidney disease. Cochrane Database Syste. Rev. https://doi.org/10.1002/14651858.CD012466.pub2 (2020).
Neill, D. B. & Heinz, H. J. Subtyping: What It Is and Its Role in Precision Medicine. www.computer.org/intelligent (2015).
Boland, M. R., Hripcsak, G., Shen, Y., Chung, W. K. & Weng, C. Defining a comprehensive verotype using electronic health records for personalized medicine. J. Am. Med. Inform. Assoc. https://doi.org/10.1136/amiajnl-2013-001932 (2013).
Lawson, C. A. et al. Risk factors for heart failure: 20-year population-based trends by sex, socioeconomic status, and ethnicity. Circ.: Heart Fail. https://doi.org/10.1161/CIRCHEARTFAILURE.119.006472 (2020).
Corrigan-Curay, J., Sacks, L. & Woodcock, J. Real-world evidence and real-world data for evaluating drug safety and effectiveness. JAMA – J. Am. Med. Assoc. 320, 867–868 (2018).
Shickel, B., Tighe, P. J., Bihorac, A. & Rashidi, P. Deep EHR: A survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J. Biomed. Heal. Inform. 22, 1589–1604 (2018).
Chen, R., Stewart, W. F., Sun, J., Ng, K. & Yan, X. Recurrent neural networks for early detection of heart failure from longitudinal electronic health record data: Implications for temporal modeling with respect to time before diagnosis, data density, data quantity, and data type. Circ. Cardiovasc. Qual. Outcomes 12, e005114 (2019).
Chicco, D. & Jurman, G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med. Inform. Decis. Mak. https://doi.org/10.1186/s12911-020-1023-5 (2020).
Desai, R. J., Wang, S. V., Vaduganathan, M., Evers, T. & Schneeweiss, S. Comparison of machine learning methods with traditional models for use of administrative claims with electronic medical records to predict heart failure outcomes. JAMA Netw. Open https://doi.org/10.1001/jamanetworkopen.2019.18962 (2020).
Choi, E., Schuetz, A., Stewart, W. F. & Sun, J. Medical concept representation learning from electronic health records and its application on heart failure prediction. arXiv. https://doi.org/10.48550/arXiv.1602.03686 (2016).
Vijayakrishnan, R. et al. Prevalence of heart failure signs and symptoms in a large primary care population identified through the use of text and data mining of the electronic health record. J. Card. Fail. 20, 459–464 (2014).
Vetrano, D. L. et al. Twelve-year clinical trajectories of multimorbidity in a population of older adults. Nat. Commun. https://doi.org/10.1038/s41467-020-16780-x (2020).
Giannoula, A., Gutierrez-Sacristán, A., Bravo, Á., Sanz, F. & Furlong, L. I. Identifying temporal patterns in patient disease trajectories using dynamic time warping: A population-based study. Sci. Rep. https://doi.org/10.1038/s41598-018-22578-1 (2018).
Choi, E., Du, N., Chen, R., Song, L. & Sun, J. Constructing disease network and temporal progression model via context-sensitive hawkes process. In Proceedings - IEEE International Conference on Data Mining, ICDM vols 2016-January 721–726 (Institute of Electrical and Electronics Engineers Inc., 2016).
Tang, Z., Yu, Y., Ng, K., Sow, D., Hu, J. & Mei, J. Disease network delineates the disease progression profile of cardiovascular diseases. J. Biomed. Inform. https://doi.org/10.1016/j.jbi.2021.103686 115 (2021).
Liu, C., Wang, F., Hu, J. & Xiong, H. Temporal phenotyping from longitudinal Electronic Health Records: A graph based framework. In Proceedings of the ACM SIGKDD international conference on knowledge discovery and data mining vols 2015-Augus 705–714 (Association for Computing Machinery, 2015).
Futoma, J., Senak, M., Cameron, C. B. & Heller, K. Predicting disease progression with a model for multivariate longitudinal clinical data. In Proceedings of the 1st Machine Learning for Healthcare Conference, PMLR 56, 42–54, (2016).
Schulam, P. & Arora, R. Disease trajectory maps. arXiv https://doi.org/10.48550/arXiv.1606.09184 (2016).
Huang, K., Altosaar, J. & Ranganath, R. ClinicalBERT: Modeling clinical notes and predicting hospital readmission. arXiv. https://doi.org/10.48550/arXiv.1904.05342 (2019).
Wei, W. Q. et al. Combining billing codes, clinical notes, and medications from electronic health records provides superior phenotyping performance. J. Am. Med. Inform. Assoc. 23, 20–27 (2016).
Nagamine, T., Gillette, B., Kahoun, J. & Saxena, M. Utilizing electronic health records to estimate disease burden: a large-scale, multimodal computational phenotyping approach (in preparation).
Sheikhalishahi, S. et al. Natural language processing of clinical notes on chronic diseases: Systematic review. JMIR Med. Inform. 7, e12239 (2019).
Miotto, R., Li, L., Kidd, B. A. & Dudley, J. T. Deep patient: An unsupervised representation to predict the future of patients from the electronic health records. Sci. Rep. https://doi.org/10.1038/srep26094 (2016).
Nagamine, T. et al. Multiscale classification of heart failure phenotypes by unsupervised clustering of unstructured electronic medical record data. Sci. Rep. 10, 21340 (2020).
Ramos, J. Using TF-IDF to determine word relevance in document queries. In ICML (2003).
Lloyd, S. P. Least squares quantization in PCM. IEEE Trans. Inf. Theory 28, 129–137 (1982).
Hennig, C. Cluster-wise assessment of cluster stability. Comput. Stat. Data Anal. 52, 258–271 (2007).
Van Der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 11 (2008).
Bowman, T. S. et al. Cholesterol and the risk of ischemic stroke. Stroke 34, 2930–2934 (2003).
Willey, J. Z., Xu, Q., Boden-Albala, B., Myunghee, D. ; & Paik, C. Lipid Profile Components and Risk of Ischemic Stroke The Northern Manhattan Study (NOMAS). Arch Neurol vol. 66 https://jamanetwork.com/ (2009).
Menet, R., Bernard, M. & ElAli, A. Hyperlipidemia in stroke pathobiology and therapy: Insights and perspectives. Front. Physiol. https://doi.org/10.3389/fphys.2018.00488 (2018).
Bui, A. L., Horwich, T. B. & Fonarow, G. C. Epidemiology and risk profile of heart failure. Nat. Rev. Cardiol. 8, 30–41 (2011).
Klein, I. & Danzi, S. Thyroid disease and the heart. Circulation 116, 1725–1735 (2007).
Maggioni, A. P. et al. The real-world evidence of heart failure: Findings from 41 413 patients of the ARNO database. Eur. J. Heart Fail. 18, 402–410 (2016).
Rossignol, P., Hernandez, A. F., Solomon, S. D. & Zannad, F. Heart failure drug treatment. www.thelancet.com vol. 393 www.thelancet.com (2019).
Weiskopf, N. G., Bakken, S., Hripcsak, G. & Weng, C. A data quality assessment guideline for electronic health record data reuse. EGEMS (Wash DC) https://doi.org/10.5334/egems.218 (2017).
Johnson, S. G., Speedie, S., Simon, G., Kumar, V. & Westra, B. L. A data quality ontology for the secondary use of EHR data. AMIA Annu Symp Proc. 1937–1946 (2015).
Hernandez-Boussard, T., Monda, K. L., Crespo, B. C. & Riskin, D. Real world evidence in cardiovascular medicine: Ensuring data validity in electronic health record-based studies. J. Am. Med. Inform. Assoc. 26, 1189–1194 (2019).
Leon, D. A., Shkolnikov, V. M., McKee, M., Kiryanov, N. & Andreev, E. Alcohol increases circulatory disease mortality in Russia: Acute and chronic effects or misattribution of cause? Int. J. Epidemiol. 39, 1279–1290 (2010).
Augestad, K. M., Martyshova, K., Martyshov, S., Foederov, B. & Lie, M. Rheumatic fever and rheumatic heart disease in North-West Russia. Tidsskr. den Nor. Laegeforen. 119, 1456–1459 (1999).
Tahhan, A. S. et al. Enrollment of older patients, women, and racial and ethnic minorities in contemporary heart failure clinical trials: A systematic review. JAMA Cardiol. 3, 1011–1019 (2018).
Bethesda (MD): National Library of Medicine (US). UMLS® Reference Manual [Internet]. https://www.ncbi.nlm.nih.gov/books/NBK9676/ (2009).
Tenny, S. & Hoffman, M. R. Odds Ratio. In StatPearls (StatPearls Publishing, 2020).
Author information
Authors and Affiliations
Contributions
T.N., R.B., J.L., M.S. designed the study; T.N., B.G., R.B., J.L., M.S. designed and validated analysis methods; T.N., B.G. performed data characterization analysis; T.N., B.G., J.K. provided clinical validation and interpretation; T.N., B.G., J.L., M.S. wrote the paper. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nagamine, T., Gillette, B., Kahoun, J. et al. Data-driven identification of heart failure disease states and progression pathways using electronic health records. Sci Rep 12, 17871 (2022). https://doi.org/10.1038/s41598-022-22398-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-22398-4
- Springer Nature Limited
This article is cited by
-
An open-source framework for end-to-end analysis of electronic health record data
Nature Medicine (2024)
-
Evolution of economic burden of heart failure by ejection fraction in newly diagnosed patients in Spain
BMC Health Services Research (2023)