
Abstract
A set of nine unique tobacco extract samples was analyzed using a self-developed electronic nose (E-nose) system, a commercial E-nose, and gas chromatography-mass spectrometry (GC–MS). The evaluation employed principal component analysis, statistical quality control, and soft independent modeling of class analogies (SIMCA). These multifaceted statistical methods scrutinized the collected data. Subsequently, a quality control model was devised to assess the stability of the sample quality. The results showed that the custom E-nose system could successfully distinguish between tobacco extracts with similar odors. After further training and the development of a quality control model for accepted tobacco extracts, it was possible to identify samples with normal and abnormal quality. To further validate our E-nose and extend its use within the tobacco industry, we collected and accurately classified the flavors of different tobacco leaf positions, with a remarkable accuracy rate of 0.9744. This finding facilitates the practical application of our E-nose system for the efficient identification of tobacco leaf positions.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Tobacco extract, integral to the aroma resources used in cigarette blending, holds a significant role in the fragrance industry due to its production complexity and raw material formulation1. It has been instrumental in brand establishment and growth within the tobacco industry. Historically, the quality control of this extract by tobacco companies primarily relied on physical and chemical parameters along with sensory evaluation. Nonetheless, methods such as infrared detection or gas chromatography, burdened by sophisticated pretreatment steps, extensive analysis hours, and high costs, have proven unsuitable for immediate evaluation of tobacco extracts, particularly in the analysis of complex aromas1,2,3,4,5,6. Sensory evaluation, once practical, has now become obsolete due to its subjective nature and high costs. The wide range and complexity of aromatic components in tobacco extracts necessitate an efficient, objective, and affordable method to ensure extract quality6,7,8,9,10.
Electronic nose (E-nose) technology, developed in the 90 s, has brought a declarative shift in the analysis, identification, and detection of complex gases11,12. Consisting of a complex set of gas-sensitive sensors, signal preprocessing, and pattern recognition, E-nose exhibits excellent responsiveness to a multitude of complex components. The technology can distinguish between aroma molecules and undertake quality analysis and evaluations using intelligent algorithms and data processing techniques13,14. E-nose’s attributes exceed those of traditional methods, with faster response time, lower detection limits, expanded detection range, affordability and eliminating human sensory errors while assuring impressive repeatability15.
Numerous studies have taken advantage of E-nose technology. For instance, Xiao et al. utilized E-nose to investigate the aroma changes in tobacco extracts subjected to different physical states, aroma characteristics, and production batches16. Nonetheless, without integrating intelligent algorithms like neural networks, the model’s overall performance was weak and couldn’t provide stable judgments at a reasonable rate for real application needs16. Cunxiao et al. established a multivariate quality control model combining gas chromatography fingerprint spectra, liquid chromatography fingerprint spectra, and E-nose odor fingerprint spectra17. However, deploying a commercial E-nose, which couldn’t optimize for the specific test, resulted in poor detection performance, despite the model’s superior fragrance quality control.
Studies by Zhai et al.18 and Zhu et al.19 were devised to detect and predict the presence of mildew in stored tobacco leaves and sliced cigarettes, demonstrating the capabilities of E-nose to promptly and accurately pinpoint potential mildew issues. Such capacity is pivotal in averting economic losses and safeguarding consumer safety. Zhai et al., in particular, established an E-nose monitoring system adept at identifying mildew in stored tobacco leaves by applying a Back Propagation (BP) neural network18. Despite their contributions, both studies faced limitations—Zhai’s model with complex data handling and Zhu’s model not accounting for industrial complexities18,19.
In response to the abovementioned challenges, we introduced an E-nose system, thereby providing a reliable basis for establishing an efficient assessment method for tobacco extract quality control20. We performed a comparative study using the Portable Electronic Nose 3 (PEN-3) and Gas Chromatography-Mass Spectrometry (GC–MS) on nine different tobacco extracts, validating our E-nose system’s reliability to manage tobacco extract quality consistency20.
We coupled E-nose and machine learning to formulate a unique method for tobacco part classification21,22,23. We utilized seven algorithms—Adaboost, Random Forest (RF), K Nearest Neighbors (KNN), Support Vector Machines (SVM) using a linear kernel function (SVM-L), SVM using RBF kernel function (SVM-R), Extreme Learning Machine (ELM), and Improved Ensemble Learning-Extreme Learning Machine (EL-ELM) for this task21,22,23. The performance of the self-developed E-nose in tobacco part tests validated the applicability of uniting E-nose technology and machine learning in tobacco part classification21,22,23.
Materials and methods
Materials
The source of American tobacco leaves was courtesy of Henan Zhongyan Industrial Co., Ltd., and the leaf classification included the upper tobacco (B2F), middle tobacco (C2F), and lower tobacco (C3F). We used nitrogen gas during the process, and Analytical grade ethanol procured from China National Pharmaceutical Group Chemical Reagent Co., Ltd. of which we prepared with distilled water. Generally, upper leaves tend to be of a higher quality due to greater exposure to sunlight and contain more sugars and nicotine, giving them a stronger flavor. Middle leaves have moderate levels of these compounds, and lower leaves are usually lighter in flavor and less potent.
Preparation of tobacco extract samples
Ensuring the accuracy of the measurements, we weighed five portions of 20 g crushed American tobacco and placed them into individual 250 ml flasks. Each portion was then fully immersed in a 200 g solution of 60% ethanol. The flasks underwent heated reflux ranging from 4 to 12 h based on increments of 2 h. Following extraction, filtration and vacuum concentration were applied to the extracts to obtain the American tobacco extracts labeled as samples 1–5.
We then placed a 50 kg volume of crushed American tobacco into a 1-ton extraction tank and added 500 kg of 60% ethanol/water solution. The blend underwent heated reflux for 12 h. This reflux process was repeated three times under identical conditions resulting in samples 6–8.
From sample 6, we extracted 50 g and mixed it with 500 g of 95% ethanol, then heated the solution at 80 °C for 1 h until it dissolved. Post-dissolution, the mixture was frozen at − 18 °C for 24 h, followed by a filtration and vacuum concentration process to isolate the pure tobacco oil extracted from American tobacco. We labeled this sample as number 9.
Before conducting the experiment, we prepared samples 1–9 as follows: We accurately weighed 10 ml of American tobacco extract or tobacco oil and transferred it into a 500 ml volumetric flask, the flask was then left at room temperature for 4 h, allowing the gaseous components of the sample to fully evaporate. We repeated this procedure nine times for each sample to confirm the stability of the sample.
Preparation of tobacco leaf position
The upper, middle, and lower tobacco leaves of the tobacco plant are separately roasted and air-dried to produce B2F, C2F, and C3F respectively, for subsequent experiments.We selected 10 g each from B2F, C2F, and C3F tobacco leaf samples and individually placed them in respective 500 ml glass injection vials, allowing them to settle overnight for complete evaporation. This process was repeated 40 times for each leaf position sample.
Instruments
For flavor analysis of tobacco extracts, we set the baseline acquisition, post-baseline, thermal desorption system cleaning, and sensor array cleaning parameters. We also adjusted the mass flow controller (MFC) parameter setting to an integer with a flow rate range of 0–500 mL/min. The default system values for air baseline acquisition settings were; 2 min duration, 500 mL/min flow rate, and 30 °C; air post-baseline had a 1 min duration, 40 mL/min flow rate, and 30 °C; the sample introduction set to 6 min, 40 mL/min flow rate, and 270 °C; the sensor array cleaning duration was set to 5 min, 500 mL/min flow rate, and 30 °C. The sampling frequency of the E-nose was set to 1 Hz for all samples.
For identification of tobacco leaf position, we used a gas pump to inject the sample gas into the gas chamber at a 40 ml/min flow rate. The sampling time was set to 6 min, with the sensor array cleaning duration set at 5 min.
We used a Shimadzu Corporation (Japan) produced GC–MS instrument. A 10 mL sample was accurately transferred to a test tube and placed on a nitrogen blower (water temperature set at 60 °C). Blowing continued until the volume reduced to 3–5 mL before cooling to room temperature. After a minute of full vortex mixer mixing, the sample was allowed to settle, and the top layer was drawn for GC–MS analysis.
The PEN-3 E-Nose was procured from Airsense Co., Ltd. The sampling frequency (sample interval) was typically set at 1.0 Hz, flush time at 20 s, zero point trim time at 20 s, pre-sampling time at 5 s, and the measurement time at 30 s. The sensor flow (chamber flow) was set at the 400 mL/min default value, and the initial injection flow was set to either 100 mL/min or 200 mL/min.
Data processing
Through a specially engineered sensor array, we successfully collected the odor emitted by the tobacco extract samples and derived the corresponding sensor signal curve. A dedicated tobacco extract sample database was established, with data extracted utilizing a PCA algorithm for feature extraction and data dimensionality reduction. We then subjected the condensed data to intelligent algorithm processing, such as SQC and SIMCA, and compared it with the confidence interval of standard stable tobacco extract samples. Tobacco essence samples that fall within this range were considered relatively stable, enabling us to classify and grade the quality stability of the examined tobacco samples.
For the purpose of tobacco leaf position identification, we applied an array of algorithms, including Adaboost, RF, KNN, SVM-L, SVM-R, ELM, and EL-ELM. Our first step involved analyzing each sensor’s response signal to extract its features. These features were then horizontally combined, treating them as a single sample. Multiple samples thus resulted in multiple rows of combined features, forming a feature matrix useful for further algorithmic processing.
Each sample garnered from testing has a dimension of 300 × 40. By conducting multiple experiments, we can effectively boost the dimensional scope of the dataset.We utilized a five-fold cross-validation technique, dividing the data into five equal parts. The first fold functioned as a test set while the remaining folds (2–5) served as the training set to obtain initial accuracy. This entire process was repeated 20 times using the five-fold cross-validation to derive an average accuracy, which represented the final accuracy of our model.
In our pursuit of the most optimal hyperparameters for all models, we conducted grid searches. For Adaboost, the number of learning cycles (Nlearn) was set to 121, and the weak learning algorithm (Learners) as Tree. For RF, 59 trees (nTree) were used, and for KNN, 37 was the selected number of nearest neighbors (K). For SVM-L, the SVM type (s) was set to 0, with a linear kernel function (t also set as 0), and the penalty factor (C) was set at 0.1. As for SVM-R, the SVM type (s) was set to 0, with a polynomial kernel function (t set at 1), and the penalty factor (C) at 0.01. For ELM, the number of hidden layers (nHidden) was set to 45, and for EL-ELM, the number of ELMs was set at 7.
Plant guideline statement
Experimental research and field studies on plants (either cultivated or wild), including the collection of plant material, must comply with relevant institutional, national, and international guidelines and legislation.
Results and discussion
Analysis based on homemade E-nose
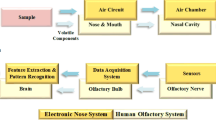
The interior construct of our homemade E-nose system deployed in this study is exhibited in Fig. 1a,b, meanwhile, Fig. 1c offers a physical perspective of the same.

Homemade E-nose includes the following components: (a) schematic diagram of the configuration, (b) system architecture diagram, (c) photograph of the prototype, (d) schematic diagram of the sensing principle of gas sensors, and (e) sensor array board and gas chamber diagram.
The gas sensors function based on the principle of resistance change (RS) when interacting with different gases, and they utilize a heating resistor (RH) to maintain the sensor at a stable operating temperature, enabling the sensor to detect a variety of gases. Considering that the RS allies in a series with a load resistor (RL), the relative voltage of the RS alters, inducing a voltage division across RL. Greater depth on this subject is available in the Supporting Information (SI), Section S124.
The ensuing voltage across RL is harvested by the data acquisition card as shown in Fig. 1d, and consequently transmitted to the computer system. The sensor array board and the gas chamber pertaining to the homemade E-nose are portrayed in Fig. 1e 25.
Designed with comprehensive inclusivity, our homemade E-nose entails an array for detecting odors, a unit each for sampling gases, detection, and control, an optional preconcentration unit along with a software upgrading interface26.
The said system incorporates standard pattern recognition algorithms and odor measurement techniques of E-noses such as Principal Component Analysis (PCA)24, Linear Discriminant Analysis (LDA)25, Back Propagation Artificial Neural Network (ANN)26, SVM27, KNN28, Decision Trees29, Transfer Learning30, Reinforced Learning31, and various other intelligent algorithms.
This judicious blend facilitates a convenient mode for differentiating and analyzing diverse gases, thus aiding processes like air quality assessment, disease diagnosis, bedside monitoring, discerning traditional Chinese medicine, classifying tobacco, alcohol, and tea, controlling food quality, and automation in production.
Our homemade E-nose system flaunts an array of more than 40 diverse sensor types, as exhibited in Table 1. The procedure of selecting the right sensors for VOC detection involves choosing ones with high sensitivity and compatible detection ranges. Ideally, broadly apt sensors capable of detecting multiple VOCs are enlisted, but specific olfactory expectations necessitate a degree of unique response traits. By opting for a variety of sensor types, the limitations associated with single-type sensors can be efficiently counteracted. The efficiency and application settings serve as guiding attributes for multi-type sensor selection.
The detection spectrum of our system is impressively wide, and its unique sensor array optimization algorithm effortlessly permits customizing the sensor array in accordance to the actual application background. This permits users with customized E-noses, tailored for specific applications in a budget-friendly manner. It not only cuts down on the time-to-market but also empowers research and development efforts.
The system is equipped with an auto calibration algorithm module designed to counter the daunting issue of sensor drift prevalent in E-noses, thereby achieving high-precision gas recognition and detection. The design of a specialized sensor chamber drastically enhances the efficiency of gas preconcentration and detection limit.
In this investigation, we conducted trials on nine tobacco extracts using our home-grown E-nose system. Our focus was to examine the effects exerted by the duration of ethanol heating reflux on the composition of flavor constituents, the sensory effects, and extraction rates found in the tobacco extracts.
We employed the response surface analysis methodology to hone the extraction process parameters and achieve an optimal extraction process parameter set. Concurrent analysis of the extraction end-products at various degree of each factor brought to light the reasons behind the sensory quality variances.
Since each single signal spectrum—represented as a 300 × 40 matrix—is laden with a massive array of redundant data, the enormous computational magnitude is adverse to the stable classification of the tobacco extract quality. The 300 × 40 matrix refers to the fact that the 300 data points are collected at a sampling rate of 1 Hz during the 300 s of the sampling phase, accumulating 300 individual voltage values. The data dimension for a single sensor is a 300 × 1 matrix, therefore for 40 sensors, it becomes a 300 × 40 matrix. We extracted features from the post-test data according to Table 2, and used the PCA algorithm for feature extraction. Afterwards, the SQC algorithm and SIMCA were applied to the feature-extracted data to judge the stability fluctuations in tobacco extraction.
In our study, we initially used the PCA (Principal Component Analysis) method to analyze the nine samples post the feature extraction phase. PCA is able to extract the most important features from the original data and remove redundant information, i.e., components that do not contribute much to the variability in the dataset.
Relying on the PCA algorithm, we reduced the sensor signal spectra of samples 1–9 into two dimensions. The resultant scatter plot can be seen in Fig. 2a. Here, we observed that samples 1 and 9 are significantly distanced from the rest of the samples and exhibit excellent differentiation. Despite a minor overlap, samples 2 and 3 still demonstrate identifiable uniqueness. While samples 4–8 are closely intertwined, sample 4 is discernibly set apart from samples 5–8. Samples 5–8, owing to considerable overlap, are less distinguishable.

PCA analysis of the Samples (a) 1–9, (b) 2–3, (c) 4–8 and SQC analysis of the Samples, (d) 1–9 based on self-made E-nose.
Applying the PCA refines distinction within samples with overlapping regions. When samples 2 and 3 were subjected to individual PCA examination, Applying the PCA refines distinction within samples with overlapping regions. When samples 2 and 3 were subjected to individual PCA examination, We choose to subject these samples to individual PCA analysis, with the intention of examining their attribute distribution in independent scenarios. Figure 2b demonstrated zero overlap, proving that the homemade E-nose system could efficiently differentiate between samples 2 and 3. When samples 4–8 were scrutinized by separate PCA analysis, Fig. 2c showed that sample 4 is easily distinguished from the others,whereas samples 5 to 8 still presented challenges in differentiation.
The PCA results aligned with the actual scenario: given that the heating reflux times varied for samples 1–5, each possessed unique odor characteristics, and each showcased independent clustering in PCA analysis, resulting in excellent distinction. In contrast, samples 5–8, which had a similar heating reflux time of 12 h and originated from different batches, exuded similar odors and exhibited more overlap, thus difficult to differentiate. Sample 9, purely extracted tobacco oil from American tobacco, varies fundamentally in odor from samples 1–8, hence it is the farthest distanced from all the others.
Readers can refer to the original response curves in Section S2 in the Supplementary Information.
In our study, we utilized the SQC (Statistical Quality Control) algorithm to analyze samples 1–9. SQC, a frequently employed methodology for assessing sample quality stability32, assumes that sample data adheres to a normal distribution and calculates the 95% confidence interval for standard tobacco extract sample data. When evaluating quality stability, the confidence of any unknown tobacco extract sample is calculated first, and the resultant confidence is compared with the standard sample data’s 95% confidence interval. Samples falling within this confidence interval are classified as stable quality samples.
In this work, sample 5, having a reflux time of 12 h, served as the standard sample. As depicted in Fig. 2d, samples 1–4, falling outside the confidence interval, are deemed unstable. As the reflux time escalates, samples 1–4 progressively move closer to the confidence interval. All scatter points of Samples 5–8 lie within the 95% confidence interval and are thus defined as stable. Sample 9 lies the farthest from the confidence interval. The SQC analytical results mirror the actual situation.
Next, we conducted a Soft Independent Modeling of Class Analogy (SIMCA) analysis on samples 1–9. SIMCA is a multivariate statistical analysis technique that selects useful principal components from a high-dimensional feature space and maps them onto a subspace. Here, samples of different classes form their respective clusters in the subspace, and an unknown sample is classified by calculating its distance to the center of each cluster. This method is especially beneficial for managing complex datasets and providing insights into their inherent structures33.
In our study, we applied SIMCA to match and categorize a given unknown tobacco extract sample within these groups. This classification was based on a specific threshold—if the distance is greater than the threshold, the sample falls into a fitted category. Conversely, if the distance is less than a certain threshold, it does not fall under that class. Any errors that occur when the distance exceeds or falls short of the threshold help in determining the quality stability of the tobacco taste.As shown in Fig. 3, SIMCA results largely align with the SQC findings (Fig. 2d). Samples 5–8 have a 95% confidence interval. The remaining samples, especially Sample 9, which is farthest, lie outside this confidence interval. Sample 9 is an American cleaner that deviates significantly in odor from Samples 1–8, which are tobacco extracts. This distinction coincides with the actual odors.

Analysis diagram of self-made E-nose SIMCA algorithm.
Concludingly, the response spectrum of the self-constructed E-nose system aligns with the actual process of tobacco extract production and the resulting odor, substantiating the E-nose’s capacity to discern subtle variances in smell amongst diverse flavors, thereby distinguishing different preparation states of tobacco extracts. The accuracy of this detection supersedes human nasal capabilities, making it more objective and precise.
In Figs. 2d and 3, the majority of scatter points of samples 5–8 fall within the 95% confidence interval (the area within the colored box), while most of the points of other samples sit outside this range. This pattern establishes the E-nose’s perception of samples 5 to 8 as having similar odors while characterizing a considerable difference in the odor of samples 1, 2, 3, 4, and 9. Such a distinction aligns with the actual scenario. Moreover, according to the analysis results of SQC and SIMCA for the signals from the electronic nose, samples from different batches processed by the same technique would have similar signals. However, even within the same batches, samples treated with different processing methods may also have significant differences in their signals. These two characteristics are consistent with the inference of the color and odor of the actual samples. These observations underscore the E-nose system’s potential for determining and managing the stability of tobacco quality.
Analysis based on GC–MS and PEN-3 E-nose
In an attempt to compare and spotlight the effectiveness of our custom-built E-nose, we analyzed the tobacco extract samples utilizing both GC–MS (Gas Chromatography-Mass Spectrometry) and a commercial PEN-3 E-nose. In the PCA (Principal Component Analysis), as demonstrated in Fig. 4a, each tobacco extract sample’s scatter points when analyzed through GC–MS stand relatively far apart. This distance indicates a degree of correlation with reality and a good differentiation ability amongst the nine test samples.

PCA analysis of the Samples 1–9 based on (a) GC–MS and (b) PEN-3 E-nose.
However, an anomaly appears with samples 5–8, all stemming from the same production batch, meaning they theoretically should have highly similar odors. Consequently, their PCA scatter points should be closer, but Fig. 4a does not depict this.
In contrast, Fig. 4b presents the PEN-3 E-nose PCA analysis, where samples 1–4 are relatively distant from each other, whilst samples 5–8 are difficult to distinguish due to their proximity. This pattern mirrors the analysis of our custom E-nose system. Interestingly, on the horizontal PC1 axis, sample 9 is closer to samples 5–8, which signifies the primary odor feature. This suggests that samples 9 and 5–8 have similar odors, a scenario inconsistent with reality since sample 9 is an American cleaner, thereby featuring notably different odors from the tobacco extracts.
While both GC–MS and PEN-3 prove effective in differentiating tobacco extract odors, they showcase some inconsistencies with reality. Uniquely, our custom E-nose system’s results correspond with the overall results of GC–MS and PEN-3, thereby validating the custom E-nose system’s practicality and feasibility in distinguishing tobacco extract samples.
The self-made electronic system includes both data acquisition hardware and a gas path. The data acquisition hardware primarily consists of a sensor array that manages signals using a conditioning circuit board and processes the Analog-to-Digital Conversion (ADC) via a multi-channel data acquisition card, transmitting the data to the Ethernet port linked to the computer. The gas path primarily integrates a three-way valve, Mass Flow Controller (MFC), and an air pump to precisely control the intake of gas. The total cost for the custom-built electronic nose is approximately $7,000, compared to the retail price of the PEN-3 electronic nose which is around $83,000 and the value of GC–MS is approximately $70,000. Importantly, the GC–MS and PEN-3 come at a higher cost than our tailor-made E-nose system. Additionally, the GC–MS method involves a high manual workload and complex functionalities, rendering it less suitable for large-scale progress and application. Our custom E-nose system compensates for these limitations with greater cost-effectiveness and suitability for large-scale, rapid, and economical determinations of tobacco extract stability.
Overall, the PEN-3 E-nose is one of the most advanced commercial E-nose currently available, designed for general odor detection and classification. It is equipped with a pre-defined sensor array, designed to be broadly applicable to various types of samples without the need for sensor optimization specific analysis, reflecting a typical usage preset in actual scenarios where there may not be expert knowledge or resources for customizing sensor arrays. GC–MS offers high precision in chemical analysis, but its effectiveness is limited in cases involving compounds that are thermo-degradable, high boiling, or have poor volatility34. In contrast, the E-nose with comprehensive sensing capabilities can detect components including those minor elements that GC–MS may overlook. This allows the E-nose to capture a complete olfactory profile of tobacco samples, including those that may have a significant influence on odor perception but are low in concentration35. The observed variations in the tobacco sample extracts underline the complementary advantages of using GC–MS and electronic nose technology for a more comprehensive odor analysis of tobacco. GC–MS offers a detailed breakdown of the sample’s chemical composition, while the electronic nose supplements this with a more extensive olfactory profile, striving to capture subtle differences that GC–MS might overlook. Consequently, conducting a stability evaluation of tobacco extracts using these two standard devices compared to our homemade E-nose system aims to present a practical and accessible assessment achievable using standard equipment and methods.
Tobacco leaf position identification
We utilized our custom E-nose system to test distinct parts of tobacco, specifically B2F, C2F, and C3F. Each was tested 40 times, resulting in a single sample test yielding data dimensions of 300 × 40, thus forming a sample set. Testing each sample 40 times is sufficient for the classification model in the paper, and it is not a repeat measurement. This set was then analyzed using the PCA (Principal Component Analysis) algorithm. As exhibited in Fig. 5a and 5b, the distance between the regions constituted by B2F and those formed by C2F and C3F is significant, whereas the scatter points within regions composed of C2F and C3F show proximity. This observation aligns with reality.

Tobacco part self-made E-nose (a) two-dimensional scatter plot, (b) three-dimensional scatter plot, (c) classification confusion matrix, (d) accuracy box plot.
Next, the sample set was used to train and test seven algorithms—Adaboost36, RF37, KNN, SVM-L, SVM-R, ELM38, and EL-ELM39. The mentioned accuracy figure is derived from the internal validation results using our homemade E-nose system with the algorithm. The selection of machine learning models in our study was aimed at balancing complexity, interpretability, and predictive performance specific to our dataset. Table 3 displays each classification algorithm’s accuracy. Among them, Adaboost achieves the lowest accuracy of 0.7244 ± 0.0855, followed by ELM, RF, SVM-L, and SVM-R, with accuracy successively increasing to 0.8139 ± 0.0951, 0.8319 ± 0.0762, 0.8570 ± 0.0733, and 0.8783 ± 0.0923, correspondingly. EL-ELM delivers the highest accuracy, reaching 0.9744 ± 0.0385.
Figure 5c depicts the EL-ELM algorithm’s confusion matrix for tobacco part classification. For B2F, the EL-ELM algorithm accurately classified 98.77% of the samples, misclassifying 1.23% as C2F. In the case of C2F, it correctly classified 96.04% of the samples and misclassified 3.96% as C3F. For C3F, 97.51% were correctly classified, with 2.49% misclassified as C2F.
Figure 5d presents a boxplot demonstrating the accuracy of the seven algorithms. Adaboost possesses the lowest accuracy, while RF, KNN, SVM-L, SVM-R, and ELM reside in a higher and fairly similar range compared to Adaboost. EL-ELM offers the highest accuracy, peaking at 0.9744 ± 0.0385.
These EL-ELM discernment outcomes were attained after optimizing the sensor array using PCA (as detailed in Section S3 in the Supplementary Information)40,41,42,43,44.
Typically, leaves from various positions on the tobacco plant exhibit distinct flavors and are thus handled differently during processing. This classification hence carries significant importance for both quality control and product development within the tobacco industry. As for the differentiation between tobacco leaves and extracts, the rationale lies in the need to understand both the raw material and its processed form. Tobacco extracts can be regarded as a concentrated source of the plant’s chemical constituents, and studying them enables us to evaluate the potential outcomes of further processing.
This paper presents a methodology utilizing the EL-ELM algorithm, demonstrating superior accuracy in tobacco leaf classification and significantly outperforming conventional algorithms with an unparalleled accuracy of 0.9744 ± 0.0385. The innovative use of a custom-developed electronic nose (E-nose) device for detecting tobacco aromas, when combined with advanced machine learning algorithms, distinguishes our work from traditional approaches. Furthermore, the EL-ELM algorithm enhances data processing efficiency, markedly reducing the required training and testing times, which is essential for large-scale applications. The adaptability and scalability of our approach render it suitable for a wide array of applications beyond tobacco classification, extending into various industries where aroma analysis is key. Comprehensive validation of our methodology against several classic algorithms reinforces the reliability and superiority of our method, underscoring its potential to revolutionize aroma-based classification processes.
Our E-nose system introduces direct benefits for tobacco quality control, including rapid, non-destructive testing that notably reduces waste and operational costs, surpassing traditional quality assessment techniques. By leveraging E-nose technology coupled with machine learning for classification, we propose a standardized quality assessment protocol, potentially elevating product consistency and consumer satisfaction across the industry. Furthermore, our approach’s scalability and the E-nose technology’s cost-efficiency make it ideal for on-site, in-line testing during various stages of tobacco processing, enhancing adaptability for industrial applications. Ultimately, the adoption of our system could lead to improved product grading and more selective raw material usage, aiding producers and manufacturers in achieving higher product quality and better positioning in the competitive market. The study has certain limitations, including a small sample size for the models. In the future, it will be necessary to collect a larger number of samples to ensure the stability of the model.
Conclusions
In our investigation, we employed a custom-built E-nose system alongside intelligent algorithms such as PCA, SQC, and SIMCA to analyze and identify the odor characteristics of nine distinct tobacco extracts. The findings were compared with those derived from GC–MS and a commercially available PEN-3 E-nose.
Our proprietary E-nose system, which encompasses a variety of sensors45,46,47,48,49,50, pattern recognition algorithms, and a robust collection and processing system, is primed to swiftly and accurately capture odor profiles of differing samples. Post the extraction of features and algorithmic analysis, it was possible to distinguish between tobacco extracts, prepared under varying conditions, based on odor characteristics. Furthermore, it facilitated the acquisition of stable confidence intervals for a quantitative assessment of sample quality stability.
The results indicated that the analysis outcomes delivered by our custom E-nose system were consistent with the actual conditions, mirroring those from GC–MS and the PEN-3 E-nose. However, there were occasional inconsistencies in the judgment outcomes, ultimately attesting to the proposed new method’s feasibility for tobacco extract type identification and quality stability evaluation.
Additionally, the integration of the E-nose with seven machine learning algorithms resulted in highly accurate discrimination of tobacco parts, with an impressive accuracy rate of 0.9744. The custom E-nose system also holds a significant cost advantage when compared to GC–MS and PEN-3 E-nose.
Thus, the E-nose system and analysis methods put forth in this study are well-suited for large-scale, low-cost, swift and precise identification of tobacco extracts and classification of tobacco parts. They hold significant potential to enhance the quality stability and accuracy of products within the tobacco industry.
In conclusion, this preliminary exploration uncovers the untapped potential of gas sensor arrays and E-nose systems in the sector of tobacco.
Data availability
The data supporting the main findings of this study are available from the corresponding authors upon reasonable request.
References
Naidu, S. K. Tobacco: Production, chemistry and technology. Crop Sci. 41, 255–255. https://doi.org/10.2135/cropsci2001.411255x (2001).
Barbera, S., Biolatti, B., Divari, S. & Cannizzo, F. T. Meat quality traits and canonical discriminant analysis to identify the use of illicit growth promoters in Charolais bulls. Food Chem. 300, 125173. https://doi.org/10.1016/j.foodchem.2019.125173 (2019).
Cai, W. et al. Effects of pretreatment methods and leaching methods on jujube wine quality detected by electronic senses and HS-SPME–GC–MS. Food Chem. 330, 127330. https://doi.org/10.1016/j.foodchem.2020.127330 (2020).
Centonze, V. et al. Discrimination of geographical origin of oranges (Citrus sinensis L. Osbeck) by mass spectrometry-based electronic nose and characterization of volatile compounds. Food Chem. 277, 25–30. https://doi.org/10.1016/j.foodchem.2018.10.105 (2019).
Chacón, I., Roales, J., Lopes-Costa, T. & Pedrosa, J. M. Analyzing the organoleptic quality of commercial extra virgin olive oils: IOC recognized panel tests versus electronic nose. Foods 11, 1477. https://doi.org/10.3390/foods11101477 (2022).
Chen, Y. et al. Characterization of traditional chinese sesame oil by using headspace solid-phase microextraction/gas chromatography-mass spectrometry, electronic nose, sensory evaluation, and rapidoxy. Foods 11, 3555. https://doi.org/10.3390/foods11223555 (2022).
Wei, M. et al. Characterization of volatile profiles and correlated contributing compounds in pan-fried steaks from different chinese yellow cattle breeds through GC-Q-orbitrap, E-nose, and sensory evaluation. Molecules 27, 100371. https://doi.org/10.3390/molecules27113593 (2022).
Sabilla, S. I., Sarno, R., Triyana, K. & Hayashi, K. Deep learning in a sensor array system based on the distribution of volatile compounds from meat cuts using GC–MS analysis. Sens. Bio-Sens. Res. 29, 100371. https://doi.org/10.1016/j.sbsr.2020.100371 (2020).
Sun, L. et al. Comparative analysis of acanthopanacis cortex and periplocae cortex using an electronic nose and gas chromatography-mass spectrometry coupled with multivariate statistical analysis. Molecules 27, 8964. https://doi.org/10.3390/molecules27248964 (2022).
Wang, S., Zhao, F., Wu, W., Wang, P. & Ye, N. Comparison of volatiles in different jasmine tea grade samples using electronic nose and automatic thermal desorption-gas chromatography-mass spectrometry followed by multivariate statistical analysis. Molecules 25, 380. https://doi.org/10.3390/molecules25020380 (2020).
Wilson, A. D. & Baietto, M. Applications and advances in electronic-nose technologies. Sensors 9, 5099–5148. https://doi.org/10.3390/s90705099 (2009).
Di Natale, C. et al. An electronic nose for food analysis. Sens. Actuators B-Chem. 44, 521–526. https://doi.org/10.1016/s0925-4005(97)00175-5 (1997).
Rock, F., Barsan, N. & Weimar, U. Electronic nose: Current status and future trends. Chem. Rev. 108, 705–725. https://doi.org/10.1021/cr068121q (2008).
Scott, S. M., James, D. & Ali, Z. Data analysis for electronic nose systems. Microchim. Acta 156, 183–207. https://doi.org/10.1007/s00604-006-0623-9 (2006).
Hidayat, S. N. et al. The electronic nose coupled with chemometric tools for discriminating the quality of black tea samples in situ. Chemosensors 7, 29. https://doi.org/10.3390/chemosensors7030029 (2019).
Mahmodi, K., Mostafaei, M. & Mirzaee-Ghaleh, E. Detection and classification of diesel-biodiesel blends by LDA, QDA and SVM approaches using an electronic nose. Fuel 258, 116114. https://doi.org/10.1016/j.fuel.2019.116114 (2019).
Gancarz, M. et al. Detection and measurement of aroma compounds with the electronic nose and a novel method for MOS sensor signal analysis during the wheat bread making process. Food Bioprod. Process. 127, 90–98. https://doi.org/10.1016/j.fbp.2021.02.011 (2021).
Zhao, G., Rui, K., Dou, S. X. & Sun, W. Heterostructures for electrochemical hydrogen evolution reaction: A review. Adv. Funct. Mater. 28, 1803291 (2018).
Zhu, C., Huang, K., Yuan, F. & Xie, C. Quantitative detection of molds counts in cigarette cut tobacco at early stages by an electronic nose. Sens. Lett. 12, 56–63. https://doi.org/10.1166/SL.2014.3226 (2014).
Shen, H. et al. Discrimination of five brands of instant vermicelli seasonings by HS-SPME/GC–MS and electronic nose. J. Food Sci. Technol. 57, 4160–4170. https://doi.org/10.1007/s13197-020-04454-x (2020).
Liu, T. et al. Characterization of tobacco leaves by near-infrared reflectance spectroscopy and electronic nose with support vector machine. Anal. Lett. 51, 1935–1943. https://doi.org/10.1080/00032719.2017.1395034 (2018).
Brudzewski, K., Osowski, S. & Golembiecka, A. Differential electronic nose and support vector machine for fast recognition of tobacco. Expert Syst. Appl. 39, 9886–9891. https://doi.org/10.1016/j.eswa.2012.02.163 (2012).
Esteves, C. H. A. et al. Identification of tobacco types and cigarette brands using an electronic nose based on conductive polymer/porphyrin composite sensors. Acs Omega 3, 6476–6482. https://doi.org/10.1021/acsomega.8b00403 (2018).
Abdi, H. & Williams, L. J. Principal component analysis. WIREs Comput. Stat. 2, 433–459. https://doi.org/10.1002/wics.101 (2010).
Xanthopoulos, P., Pardalos, P. M. & Trafalis, T. B. Linear discriminant analysis. Robust Data Min., 27–33 (2013). https://doi.org/10.1007/978-1-4419-9878-1
Buscema, M. Back propagation neural networks. Subst Use Misuse 33, 233–270. https://doi.org/10.3109/10826089809115863 (1998).
Hearst, M. A., Dumais, S. T., Osuna, E., Platt, J. & Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl 13, 18–28. https://doi.org/10.1109/5254.708428 (1998).
Kramer, O. K-nearest neighbors. Dimensionality reduction with unsupervised nearest neighbors, 13–23 (2013). https://doi.org/10.48550/arXiv.1107.3600
Kingsford, C. & Salzberg, S. L. What are decision trees?. Nat. Biotechnol. 26, 1011–1013. https://doi.org/10.1038/nbt0908-1011 (2008).
Gorban, A. N. & Zinovyev, A. Y. Elastic principal graphs and manifolds and their practical applications. Computing 75, 359–379. https://doi.org/10.1007/s00607-005-0122-6 (2007).
Sutton, R. S. & Barto, A. G. Reinforcement learning: An introduction 2nd edn. (The MIT Press, 2018).
Bissell, D. Introduction to statistical quality control. J. R. Stat. Soc.: Ser. D (The Statistician) 35, 81–82. https://doi.org/10.2307/2988304 (1986).
Chen, Z. & de Boves Harrington, P. Automatic soft independent modeling for class analogies. Anal. Chim. Acta 1090, 47–56. https://doi.org/10.1016/j.aca.2019.09.035 (2019).
Garcia, A. & Barbas, C. in Metabolic Profiling: Methods and Protocols (ed Thomas O. Metz) 191–204 (Humana Press, 2011). https://doi.org/10.1007/978-1-61737-985-7
Farraia, M. V. et al. The electronic nose technology in clinical diagnosis: A systematic review. Porto Biomed. J. 4, e42. https://doi.org/10.1097/j.pbj.0000000000000042 (2019).
Schapire, R. Explaining AdaBoost, 37–52 (2013). Explaining AdaBoost. https://doi.org/10.1007/978-3-642-41136-6_5.
Biau, G. & Scornet, E. A random forest guided tour. TEST 25, 197–227. https://doi.org/10.1007/s11749-016-0481-7 (2015).
Huang, G.-B., Zhu, Q.-Y. & Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 70, 489–501. https://doi.org/10.1016/j.neucom.2005.12.126 (2006).
Nan, L. & Han, W. Ensemble based extreme learning machine. IEEE Signal Process. Lett. 17, 754–757. https://doi.org/10.1109/lsp.2010.2053356 (2010).
Lv, Y., Yang, L., Bu, F. Y. & Yang, J. X. Optimization of sensor array for detection of abalone freshness based on electronic tongue. J. New Mater. Electrochem. Syst. 26, 94–100 (2023).
Peng, Z. et al. A comprehensive evaluation model for optimizing the sensor array of electronic nose. Appl. Sci.-Basel 13, 2338. https://doi.org/10.3390/app13042338 (2023).
Qian, J. H., Lu, M. C., Tian, F. C., Zhao, L. L. & Zhang, A. L. Array optimization based on weighted and hilbert-schmidt schemes of multisensor detection system. IEEE Trans. Ind. Inform. 19, 7044–7054. https://doi.org/10.1109/tii.2022.3209238 (2023).
Qian, J. H., Lu, M. C., Xu, P., Liu, Z. Y. & Lu, Y. Y. Multiple-sensor detection system design for tea identification based on mutual information array optimization scheme. IEEE Sens. J. 23, 13751–13761. https://doi.org/10.1109/jsen.2023.3275378 (2023).
Qian, J. H., Lu, Y. Y., Lu, M. C., Liu, Z. Y. & Xu, P. Enhancement of array optimization algorithm via information theory for a novel multisensor detection system. IEEE Trans. Instrum. Meas. https://doi.org/10.1109/tim.2023.3290313 (2023).
Chen, C. et al. Ni-Co-P hollow nanobricks enabled humidity sensor for respiratory analysis and human-machine interfacing. Sens. Actuators B Chem. 370, 132441. https://doi.org/10.1016/j.snb.2022.132441 (2022).
Li, J. et al. Enhancing photodegradation of Methyl Orange by coupling piezo-phototronic effect and localized surface plasmon resonance. Nano Energy 108, 108234. https://doi.org/10.1016/j.nanoen.2023.108234 (2023).
Pan, H. et al. Biodegradable cotton fiber-based piezoresistive textiles for wearable biomonitoring. Biosens. Bioelectron. 222, 114999. https://doi.org/10.1016/j.bios.2022.114999 (2023).
Su, Y. et al. Maxwell displacement current induced wireless self-powered gas sensor array. Mater. Today Phys. 30, 100951. https://doi.org/10.1016/j.mtphys.2022.100951 (2023).
Su, Y. et al. High-performance piezoelectric composites via β phase programming. Nat. Commun. 13, 4867. https://doi.org/10.1038/s41467-022-32518-3 (2022).
Su, Y. et al. Sensing–transducing coupled piezoelectric textiles for self-powered humidity detection and wearable biomonitoring. Mater. Horizons 10, 842–851. https://doi.org/10.1039/d2mh01466a (2023).
Lopez, E. et al. The importance of choosing a proper validation strategy in predictive models. A tutorial with real examples. Anal. Chim. Acta 1275, 341532 (2023).
Funding
This work was supported by Henan Tobacco Industry Co., Ltd. Science and Technology Project (Grant No. AW202107), and Open Project of State Key Laboratory for Supramolecular Structure and Materials (SKLSSM 202301).
Author information
Authors and Affiliations
Contributions
Conceptualization, Shengtao Ma, Bin Ai and Gaolei Xi; Data curation, Hao Li and Qiuling Wang; Formal analysis, Hao Li; Funding acquisition, Shengtao Ma, Bin Ai and Gaolei Xi; Investigation, Genfa Wang and Qing Wang; Methodology, Hao Li and Qiuling Wang; Project administration, Shengtao Ma, Bin Ai and Gaolei Xi; Resources, Genfa Wang and Qing Wang; Software, Hao Li and Qiuling Wang; Supervision, Shengtao Ma, Bin Ai and Gaolei Xi; Validation, Lu Han and Zhifei Chen; Visualization, Hao Li and Bin Ai; Writing—original draft, Hao Li and Bin Ai; Writing—review & editing, Shengtao Ma and Gaolei Xi.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, H., Wang, Q., Han, L. et al. Quality characterization of tobacco flavor and tobacco leaf position identification based on homemade electronic nose. Sci Rep 14, 19229 (2024). https://doi.org/10.1038/s41598-024-70180-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-70180-5
- Springer Nature Limited