
Abstract
Background
Both in-hospital cardiac arrest (IHCA) and out-of-hospital cardiac arrest (OHCA) have higher incidence and lower survival rates. Predictors of in-hospital mortality for intensive care unit (ICU) admitted cardiac arrest (CA) patients remain unclear.
Methods
The Medical Information Mart for Intensive Care IV (MIMIC-IV) database was used to perform a retrospective study. Patients meeting the inclusion criteria were identified from the MIMIC-IV database and randomly divided into training set (n = 1206, 70%) and validation set (n = 516, 30%). Candidate predictors consisted of the demographics, comorbidity, vital signs, laboratory test results, scoring systems, and treatment information on the first day of ICU admission. Independent risk factors for in-hospital mortality were screened using the least absolute shrinkage and selection operator (LASSO) regression model and the extreme gradient boosting (XGBoost) in the training set. Multivariate logistic regression analysis was used to build prediction models in training set, and then validated in validation set. Discrimination, calibration and clinical utility of these models were compared using the area under the curve (AUC) of the receiver operating characteristic (ROC) curves, calibration curves and decision curve analysis (DCA). After pairwise comparison, the best performing model was chosen to build a nomogram.
Results
Among the 1722 patients, in-hospital mortality was 53.95%. In both sets, the LASSO, XGBoost,the logistic regression(LR) model and the National Early Warning Score 2 (NEWS 2) models showed acceptable discrimination. In pairwise comparison, the prediction effectiveness was higher with the LASSO,XGBoost and LR models than the NEWS 2 model (p < 0.001). The LASSO,XGBoost and LR models also showed good calibration. The LASSO model was chosen as our final model for its higher net benefit and wider threshold range. And the LASSO model was presented as the nomogram.
Conclusions
The LASSO model enabled good prediction of in-hospital mortality in ICU admission CA patients, which may be widely used in clinical decision-making.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Background
The morbidity and mortality surrounding CA remained a global challenge. In the United States, more than 350,000 people experience an OHCA every year, and about 10.8% of them survive to hospital discharge [1]. The in-hospital survival rate of OHCA patients was 26.4% [2]. IHCA occurs in over 290,000 adults each year in the United States [3]. The 30 day survival rate of patients with IHCA was 27.8%, and the one-year survival rate was 20% [4]. Despite increasing attention to CA, the prognosis of patients with CA was still unsatisfactory.
Most patients with CA died in acute events. There were also some deaths in patients with CA that occur after successful resuscitation, which can be attributed to the development of post CA syndrome, including neurological dysfunction and other types of organ dysfunction. For patients with successful resuscitation, they will generally be sent to the intensive care unit (ICU) for advanced life support treatment. About one third of patients admitted to the ICU survive to discharge, but there are considerable differences in the treatment and prognosis of patients after CA between different institutions [5,6,7]. Given the high hospital mortality rate, identifying high-risk factors and accurately predicting prognosis in the early stages of hospitalization may have greater benefits for patients with cardiac arrest admitted to the ICU. Although there were several models for predicting mortality in hospitalized patients with CA available, the accuracy of these methods was not satisfactory (the sample size was less than 1000 or the C-statistic was not calculated), so they had not been widely used [8,9,10].
Machine learning (ML) belongs to the category of artificial intelligence [11]. Different from the traditional prediction model that uses selected variables for calculation, ML can not only easily combine a large number of variables with computers to improve the accuracy of prediction, but also screen variables by a variety of methods when selecting variables to improve the accuracy and efficiency of the model [12].
By using ML to screen variables and establish prediction models, adverse factors for patients with CA can be identified at the early stage of admission to the ICU, and corrected as soon as possible to improve the prognosis of patients. The purpose of this study was to develop and validate a predictive model for in-hospital mortality of patients with CA admitted to ICU using data from MIMIC-IV database.
Materials and methods
Study design and data source
We conducted a retrospective analysis using all the relevant data extracted from the MIMIC-IV database.
The MIMIC-IV database is an open and publicly available database that contains high-quality data between 2008 and 2019 constructed by Institutional Review Boards of the Massachusetts Institute of Technology (MIT, Cambridge, MA, America) and Beth Israel Deaconess Medical Center. To access the database, we passed the National Institutes of Health Protecting Human Research Participants web-based training course and we obtained approval to extract data from the MIMIC-IV for research purposes (Certification Number: 50778029).
Study patients
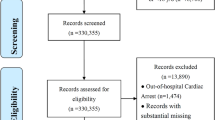
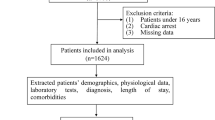
Patients with a diagnosis of CA, defined as ICD-9 codes of 4275 or ICD-10 codes of I46, I462, I468 and I469. Patients were ≥ 18 years old at the time of ICU admission were included in the study; Patients without an ICU record were excluded from the study. The flow chart showed the selection of patients into the study (Fig. 1A). Patients with a diagnosis of CA were screened and 1722 adult patients were included in this study.

A Flowchart of patient selection (n = 1722). ICD-9/10, 9/10th revision of the International Classification of Diseases; ICU, intensive care unit; MIMIC-IV, Medical Information Mart for Intensive Care IV. B Model development flowchart. LASSO, least absolute shrinkage and selection operator; XGBoost, extreme gradient boosting
Data extraction and processing
Demographics, vital signs, laboratory tests, scoring systems, relevant treatment information, and others were extracted from the MIMIC-IV database using structured query language with PostgreSQL (version 14, www.postgresql.org). The prediction model only included the clinical and laboratory variables on the first day of ICU admission. If the patient received more than one vital sign measurement or laboratory tests on the first day of admission, the average values were used for subsequent analysis. Comorbidities were identified using ICD-9/10 code. Based on previous research [8, 9, 13, 14], clinical relevance, and general availability, the following data were extracted: demographic characteristics (age at the time of hospital admission, sex); vital signs (heart rate (HR), systolic blood pressure (SBP), diastolic blood pressure (DBP), mean blood pressure(MBP), respiratory rate(RR), body temperature, saturation pulse oxygen (SPO2); comorbidities (hypertension, congestive heart failure(CHF), myocardial infarction, diabetes mellitus(DM), and chronic obstructive pulmonary disease (COPD)) and laboratory variables (hematocrit(HCT), hemoglobin(HB), platelet count, white blood cells(WBC), prothrombin time (PT), international normalized ratio (INR), creatinine, blood urea nitrogen (BUN), glucose, potassium, sodium, calcium, chloride, the anion gap, bicarbonate, lactate, hydrogen ion concentration (pH); treatment information(ventilation, epinephrine, dopamine); marking system: sequential organ failure assessment(SOFA), simplified acute physiology score III (SAPS III), Glasgow coma scale (GCS). The primary outcome of the study was in-hospital mortality, defined as the vital status of the patient at discharge.
Missing data handling
Variables with missing data are common in the MIMIC-IV, and directly eliminating patients with missing values or analyzing variables with missing values will cause bias. we excluded variables with more than 25% of missing values.
For variables with missing proportion < 5%, the continuous variables with normal distribution, the missing values were replaced with the mean for the patient group; The skewed distributions with continuous variables, missing values were replaced with their median [15]. Multiple imputation can impute each missing value with multiple plausible possible values. This method takes into account uncertainty behind the missing value and can produce several datasets from which parameters can be estimated, and these coefficients are combined to give an effective estimate of the coefficients [16,17,18,19]. For variables with missing proportion > 5%, we used multiple imputation to handle the data by R software ('mice' package). (Missing value details in Supplementary Table 1).
Statistical analysis
Values were presented as total numbers with percentages for categorical variables and the means with standard deviations (SD) (if normal) or medians with inter quartile ranges (IQR) (if non normal) for continuous variables. Proportions were compared using χ2 test or Fisher exact tests. For all continuous variables, we used a two-sided one-way analysis of variance or Wilcoxon rank-sum tests when comparing the two groups. P < 0.05 was statistically significant.
The flow chart demonstrates the methodology for developing the predictive model (Fig. 1B). According to previous research [20], the data were divided at random, with 70% utilized for training and 30% for validating. Table 1 summarized the predictor variables and statistics.
Two ML methods were used to select the most important predictors of the in-hospital mortality prediction model from the training set. First, we used the LASSO method, which was conducted via a continuous shrinking operation and minimizing regression coefficients, in order to reduce the likelihood of overfitting. And, LASSO can shrink the sum of the absolute value of regression coefficients, forcing and producing coefficients that are exactly 0 [21, 22]. Variables with non-zero coefficients were selected for the next logical regression analysis. This enhanced the prediction accuracy and interpretation ability of the prediction model, and which was suitable for high-dimensional data processing.
Second, we used XGBoost, which was an efficient and scalable ML classifier. XGBoost can achieve high prediction accuracy and low computational costs in various practical applications [23]. Gradient boosting decision tree is the original model of XGBoost, which combines multiple decision trees in boosting way. XGBoost used the number of boosts, learning rate, subsampling ratio, and maximum tree depth to control overfitting and enhance the better performance. Moreover, XGBoost optimized the target of the function, the size of the tree, and the size of the weight through regularization [24].
To investigate the independent risk factors of in-hospital mortality, the variables screened by two methods were used in the training set of univariate logistic regression analysis to evaluate the significance of variables. In the univariate logistic regression analysis, the variables significantly related to the in-hospital mortality will be further analyzed by multivariate logistic regression analysis. Prediction models were evaluated in terms of discrimination and calibration. Discrimination was assessed by calculating the area under the curve (AUC) of the receiver operating characteristic (ROC) curve and C-statistic testing. Decision curve analysis (DCA) was used to compare the clinical net benefit associated with the use of these models [25].
The model with the highest AUC and the highest clinical net benefit was identified as the final model, and a nomogram was drawn to predict in-hospital mortality. The nomogram was a visualization of the results of the regression equation by calculating the probability of occurrence by using some disjoint segments.
The National Early Warning Score 2(NEWS2) was a modification of NEWS and a simple aggregate scoring system. In the early stage of disease deterioration, the NEWS2 can detect the potential disease changes in patients early and provide preventive measures for disease deterioration, which has important clinical implications to improve the survival rate of patients with CA in ICU [26,27,28,29,30]. Because the final calculation was a score, we performed subsequent analysis after translating it into a univariate predict model, to analyze C-index and estimate differences in the discrimination between the models.
Meanwhile, we used a stepwise method to construct a prediction model in logical regression(LR model).
All analyses were performed by the statistical software packages R version 4.2.2 (http://www.R-project.org, The R Foundation). P < 0.05 (two-sided test) were considered statistically significant.
Result
Baseline characteristics
As shown in Fig. 1A, a total of 1722 patients diagnosed as CA were included in our study. According to the research method of the previous study, we randomly divided all patients into training set (1206 people, 70%) and validation group (516 people, 30%). In the whole study population, the in-hospital mortality rate of CA patients was 53.95% (793 survivors and 929 non-survivors). Table 1 showed the comparison of demographics and variables between the training set and the validation set, as well as the comparison of dead patients and survivors during hospitalization. SBP, DBP, MBP values were lower in the training set. The proportion of dopamine use and in-hospital mortality were lower in the validation set. There were no significant differences in other selected variables between the training set and validation set. Patients who died also had lower SBP, DBP, MBP, temperature, SPO2, HCT, HB, platelet, bicarbonate, calcium, pH, GCS score, the proportion of man, CHF and myocardial infarction. However, age, SOFA score and SAPS III score, epinephrine use, dopamine use, HR, RR, WBC, anion gap, BUN, creatinine, glucose, sodium, potassium, INR, PT and lactate levels in patients who died during their hospital stay were significantly increased. There was no significant difference in terms of whether they had DM, hypertension, ventilation and chloride levels, between the surviving and non-surviving patients.
Selected variables
In the training set, we conducted the regularization process of LASSO. The binomial deviance was computed for the test data as measures of the predictive performance of the fitted models. The binomial deviance curve was plotted versus log (λ) using tenfold cross-validation via minimum criteria, where λ was a tuning hyperparameter. The dotted vertical lines were drawn at optimal values by using the minimum criteria and within one standard error range of the minimum criteria. We chose the latter criteria (λ = 0.01944) as it results in stricter penalty allowing us to reduce the number of covariates even further than the minimum criteria (λ = 0.00332) (Fig. 2A, B). Finally, 17 nonzero coefficients were resulted in LASSO regression (Fig. 3A). Meanwhile, XGboost was also used to analyze the patients who died in the training set, ranked the predictive importance of all included variables, and selected the top 17 variables (Fig. 3B).

A Cross validation plot for the penalty term. 17 potential prediction variables were selected. B A coefficient profile plot was produced against the Log Lambda sequence

Predictor variables selection. A Predictor variables selected by LASSO. B Importance ranking of the predictor variables selected by XGBoost algorithm. BUN, blood urea nitrogen; CHF, congestive heart failure; DBP, diastolic blood pressure; GCS, Glasgow coma scale; HB, hemoglobin; HR, heart rate; LASSO, least absolute shrinkage and selection operator; MBP, mean blood pressure; PT, prothrombin time; RR, respiratory rate; SAPS III, simplified acute physiology score; SPO2, saturation pulse oxygen; WBC, white blood cells; XGBoost, extreme gradient boosting
Model development
In the training set, 17 variables respectively screened by LASSO and XGboost were used to conduct univariate logistic regression with the in-hospital mortality, and variables with statistically significance in univariate logistic regression were used to conduct multivariate logistic regression. Tables 2 and 3 showed the variables selected in the univariate and multivariate analysis by LASSO and XGBoost. Among the variables screened using LASSO, multivariate logistic regression identified age, SAPS III, HR, MBP, RR, temperature, SPO2, GCS, man, bicarbonate, PT as the most significant mortality risk predictors; Among the XGBoost selected variables, SAPS III, RR, bicarbonate, SPO2, temperature, age, HR, GCS, HB as the most significant mortality risk predictors.
We established an in-hospital mortality prediction algorithm using LASSO selected variables as follows: log odds of mortality = 18.746877 + 0.013344 × age + 0.010997 × SAPS III + 0.019006 × HR- 0.017839 × MBP + 0.048912 × RR- 0.286264 × temperature- 0.080727 × SPO2- 0.142085 × GCS- 0.258837 × man- 0.064604 × bicarbonate + 0.021723 × PT.
The variance inflation factors for these variables were 1.1, 1.2, 1.3, 1.1, 1.3, 1.2, 1.1, 1.0, 1.0, 1.1 and 1.0, respectively.
Based on XGBoost, the selected variables for the in-hospital mortality prediction algorithm were as follows: log odds of mortality = 20.258476 + 0.011845 × SAPS III + 0.052959 × RR- 0.071588 × bicarbonate- 0.099384 × SPO2- 0.279351 × temperature + 0.013794 × age + 0.018419 × HR- 0.138026 × GCS- 0.102837 × HB.
The variance inflation factors for these variables were 1.2, 1.3, 1.1, 1.1, 1.2, 1.1, 1.3, 1.0 and 1.1, respectively.
Based on stepwise logistic regression, the selected variables for the in-hospital mortality prediction algorithm were as follows: log odds of mortality = 16.287329 + 0.013572 × age- 0.447131 × CHF + 0.010371 × SAPSIII + 0.018552 × HR- 0.016852 × MBP + 0.049526 × RR- 0.286100 × temperature- 0.086035 × SPO2- 0.135393 × GCS- 0.530986 × COPD + 0.137646 × HCT- 0.461777 × HB- 0.067713 × bicarbonate + 0.007738 × BUN + 0.025168 × sodium.
The variance inflation factors for these variables were 1.2, 1.2, 1.3, 1.3, 1.2, 1.3, 1.2, 1.1, 1.0, 1.1, 13.4, 13.8, 1.2, 1.2 and 1.1, respectively.
Model validation
The discrimination and calibration of the LASSO model and the XGBoost model in the training set and validation set were shown in Figs. 4A-C and 5A-C, respectively. In the training set, the AUC of LASSO model and XGBoost model were 0.7879 (0.7627–0.8132) and 0.7854 (0.7599–0.8109) respectively. In the validation set, the AUC of LASSO model and XGBoost model were 0.7994 (0.7618–0.8369) and 0.7941 (0.7560–0.8321), respectively. As shown in Figs. 4B, C, and 5B, C, in the calibration curves of the training set and the validation set of the same model, it can be seen that the prediction models had a strong concordance performance in both sets.

The discrimination and calibration performance of LASSO model. Plot (A) showed the ROC curves of the LASSO model in the training set and validation set, respectively (AUC = 0.7879 versus 0.7994). Calibration curves of the LASSO model in the training set (B) and validation set (C). Calibration curves depicted the calibration of the LASSO model in terms of the agreement between the predicted risk of in-hospital mortality and observed in-hospital mortality. The 45° dotted line represents a perfect prediction, and the blue lines represent the predictive performance of the LASSO model. The closer the violet line fit is to the ideal line, the better the predictive accuracy of the LASSO model is. AUC, area under the curve; LASSO, least absolute shrinkage and selection operator; ROC, receiver operating characteristic

The discrimination and calibration performance of the XGBoost model. Plot (A) showed the ROC curves of the XGBoost model in the training set and validation set, respectively (AUC = 0.7854 versus 0.7941). Calibration curves of the XGBoost model in the training set (B) and validation set (C). AUC, area under the curve; ROC, receiver operating characteristic. XGBoost, extreme gradient boosting
The NEWS 2 based on RR, SPO2, SBP, pulse rate, level of consciousness or new confusion, temperature to predict the risk of in-hospital mortality for patients in ICU with CA. We calculated the NEWS 2 for all study patients. The ROC curve and calibration curve of NEWS 2 in the training set and verification set were shown in Fig. 6A-C. The AUC of the training set and verification set were 0.6944 (0.6651–0.7237) and 0.7030 (0.6588–0.7472), respectively.

The discrimination and calibration performance of NEWS 2 model. Plot (A) showed the ROC curves of the NEWS 2 model in the training set and validation set, respectively (AUC = 0.6944 versus 0.7030). Calibration curves of the NEWS 2 model in the training set (B) and validation set (C). AUC, area under the curve; NEWS 2, the national early warning score 2; ROC, receiver operating characteristic
The ROC curve and calibration curve of LR model in the training set and verification set were shown in Fig. 7A-C. The AUC of the training set and verification set were 0.7992 (0.7746–0.8238) and 0.7970 (0.7592–0.8348), respectively.

The discrimination and calibration performance of LR model. Plot (A) showed the ROC curves of the LR model in the training set and validation set, respectively (AUC = 0.7992 versus 0.7970). Calibration curves of the LR model in the training set (B) and validation set (C). AUC, area under the curve; LR, logistic regression; ROC, receiver operating characteristic
The DCA for the LASSO model, the XGBoost model, LR model and the NEWS 2 model were presented in Fig. 8A. It can be seen that when the threshold probability was 0.18 to 0.86 in the four models, the models added more net benefit than the ‘All’ or ‘None’ scheme.

A Decision curve analysis for LASSO model, XGBoost model, LR model and NEWS 2 model. The y-axis measures the net benefit. The red line represents the LASSO model. The green line represents the XGBoost model. The yellow line represents the LR model. The blue line represents the NEWS 2 model. The grey line represents the assumption that all patients die in the hospital. The black line represents the assumption that no patients die in the hospital. B The comparison of ROC curves for LASSO model, XGBoost model, LR model and NEWS 2 model. LASSO, least absolute shrinkage and selection operator; LR, logistic regression; NEWS 2, the national early warning score 2; ROC, receiver operating characteristic; XGBoost, extreme gradient boosting
Model comparison
We compared the AUC of the LASSO, XGBoost, LRand NEWS 2 model in our total study population to assess the predictive effectiveness of the four models. Figure 8B showed that the AUC for the LASSO model, XGBoost model, LR model and NEWS 2 model were 0.7912(0.7703–0.8122), 0.7892(0.7681–0.8103), 0.7979(0.7773–0.8185) and 0.6969 (0.6725–0.7212), respectively, which were confirmed to be 0.7873, 0.7845, 0.7921 and 0.6969 via bootstrapping validation(repeat = 1000). By comparing the AUC values, the predictive effectiveness of the LASSO model,the XGBoost model and LR model were both significantly better than the NEWS 2 model (p < 0.001). And there was no statistical significance difference between the LASSO model, the XGBoost model and LR model (p > 0.05) (Table 4).
In the LASSO model, 11 variables were included, and there were 9 variables in the XGBoost model, while there were 15 variables in the LR model. LR model had more variables and a smaller threshold range compared to XGboost model and LASSO model. Although the XGboost model was more concise, the net benefit of the LASSO model was higher than the XGBoost model within the threshold range of 0.6–1.0. We believed that higher net benefit was more beneficial for patients with CA. Therefore, we chose the LASSO model as the final model, and represented by the nomograph in Fig. 9. The nomograph used some parallel lines with scales to estimate the probability of occurrence of each risk factor. The score of each risk factor can be calculated, and then the probability of occurrence to the total score of all risk factors can be calculated, which is the probability of occurrence of this event.

Predict in-hospital mortality nomogram. GCS, Glasgow coma scale; HR, heart rate; MBP, mean blood pressure; PT, prothrombin time; RR, respiratory rate; SAPS III, simplified acute physiology score; SPO2, saturation pulse oxygen
Discussion
CA is a major public health event with a high mortality rate. Early and accurate prediction of in-hospital mortality of patients with CA can give clinicians more time to provide individualized treatment strategies, and play an important role in rational planning of medical resources and personnel scheduling. Many studies had analyzed the short-term and long-term survival rates of OHCA and IHCA respectively. Recently, more and more studies established prediction models for in-hospital patients with CA [31,32,33].
With the advancement of electronic medical records and artificial intelligence, ML algorithms have become more widely utilized in individualized medicine to assist clinical decision-making. Therefore, we used the data from MIMIC-IV database to screen the independent risk factors of in-hospital mortality with CA patients by ML algorithm, and then obtained a predictive nomograph by logistic regression analysis.
In our study, the in-hospital mortality is 52.4%, which is significantly lower than other study population [2, 4, 34]. The lower mortality rate may be related to the small sample size and the location of CA. The age, HR, RR, bicarbonate, SPO2, temperature, SAPS III score and GCS score were included in the XGBoost and LASSO multiple regression equations. The HB were included in the XGBoost multiple regression equation; Meanwhile, the man, PT and MBP were included in the LASSO multiple regression equation. Consistent with previous studies, our study also took age, man, HR, SPO2, and lower MBP values as independent predictors [32, 35, 36].
After CA, the occurrence of tissue ischemia and hypoxia will lead to the decrease of pH value and increase of lactate value. In OHCA patients, the pH value was related to the neurological state of the patient at discharge, which may help predict the adverse neurological state of the patient at discharge [37, 38]. However, some studies had shown that dynamic monitoring of pH may be more meaningful for the prognosis of the nervous system [39]. Moreover, the prognosis of the nervous system was not consistent with the in-hospital survival rate. Lactate was also an indicator that can affect the prognosis of CA patients [40]. However, some studies had pointed out that in addition to the absolute value of lactate, the change rate of early lactate value also had important prognostic significance [41, 42]. In our study, pH and lactate were not included in the final model due to the inconsistent sample collection time of all patients and the possible bias caused by the longtime span of the database.
Several prognostic scoring systems had been developed to predict the in-hospital mortality of ICU patients [43]. SAPS III was a more modern mortality prediction model that used a larger cohort that included the first from outside North America and Europe and utilized new computer-intensive analysis methods [44]. One study showed that the SAPS III did not predict mortality in patients admitted to ICU after CA [45]. SAPS III was also considered as a reliable, simple and easy to use prognostic model in clinical practice [46]. In our study, SAPS III was included in the final model as an independent predictor.
Targeted temperature management is the sole intervention for improving neurological outcomes in the post return of spontaneous circulation phase of care, which has been considered a standard of care treatment for over almost two decades and has been included in the International Post-Cardiac Arrest Guidelines [47, 48]. However, in our study, the effect of temperature was opposite to targeted temperature management, which may be because low body temperature was due to poor peripheral circulation, rather than hypothermia treatment.
During CA, metabolic acidosis is caused by hypoxia-induced anaerobic metabolism and decreased metabolic acid excretion due to renal insufficiency [49]. The lower the bicarbonate, the more serious the metabolic acidosis. In our study, bicarbonate was included in our model as an independent predictor.
PT shows the status of exogenous coagulation system. PT prolongation was prevalent in critically ill patients and was independently associated with higher ICU mortality [50]. In other studies, prolonged PT was also associated with increased mortality [51, 52]. In our study, PT was an independent predictor of in-hospital mortality in patients with CA.
NEWS 2 has clinically significant in predicting the incidence of CA within 24 h, ICU occupancy and mortality [53, 54]. Compared with the NEWS 2 model, XGBoost model,LASSO model and LR model showed the advantages of prediction effect in our study. The three models showed good discrimination and calibration abilities in the training set and validation set. To obtain a wider threshold range and a greater net benefit, we selected the LASSO model to develop our predict nomogram.
A lot of variables were reported to correlate with mortality in CA patients, such as hypertension, DM, the use of vasopressor [13, 40, 55, 56]. Nevertheless, our study showed that hypertension, DM and the use of epinephrine and dopamine were not predictors of in-hospital mortality of ICU-admitted CA patients, which may be attributed to our relatively small sample size, and the difference in amount and duration of use vasopressors.
Our study had several limitations. Firstly, as this was a retrospective study, we were unable to avoid selection bias. Secondly, as a single center study with the earliest cases from almost 20 years ago, the treatment and care of CA had been inconsistent with current standards, which requires a multicenter registration and prospective study to verify. Thirdly, our cases were all adult CA patients in ICU. Whether the results of this study can be applied to other populations needs further research on more patients in different clinical environments to confirm our results. Fourthly, limited by the contents of the MIMIC-IV database, incomplete recorded data was not included in the analysis, moreover, we cannot distinguish the source of patients in this study was IHCA or OHCA. Fifth, due to the small number of patients with CA, in order to ensure the accuracy of the model, we used survival rate as an outcome indicator rather than neurological prognosis. In the future, it may be more meaningful to study neurological prognosis as an outcome when the sample size is sufficient.
Conclusion
We developed a predictive nomogram for in-hospital mortality of CA patients in ICU, which included variables that can be routinely collected during hospitalization in ICU. With a high AUC of 0.7912 (95% CI 0.7703–0.8122), a wide net benefit threshold range (0.2–1.0) and high net benefit, this nomogram may be widely used in clinical decision-making.
Availability of data and materials
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- AUC:
-
Area under curves
- BUN:
-
Blood urea nitrogen
- CA:
-
Cardiac arrest
- COPD:
-
Chronic obstructive pulmonary disease
- CHF:
-
Congestive heart failure
- DCA:
-
Decision curve analysis
- DM:
-
Diabetes mellitus
- DBP:
-
Diastolic blood pressure
- XGBoost:
-
Extreme gradient boosting
- GCS:
-
Glasgow Coma Scale
- HR:
-
Heart rate
- HCT:
-
Hematocrit
- HB:
-
Hemoglobin
- pH:
-
Hydrogen ion concentration
- IHCA:
-
In-hospital cardiac arrest
- ICU:
-
Intensive care unit
- IQR:
-
Inter quartile ranges
- INR:
-
International normalized ratio
- LASSO:
-
Least absolute shrinkage and selection operator
- LR:
-
Logistic regression
- ML:
-
Machine learning
- MBP:
-
Mean blood pressure
- MIMIC-IV:
-
Medical Information Mart for Intensive Care IV
- NEWS 2:
-
National Early Warning Score 2
- OHCA:
-
Out-of-hospital cardiac arrest
- PT:
-
Prothrombin time
- RR:
-
Respiratory rate
- ROC:
-
Receiver operating characteristic
- SPO2 :
-
Saturation pulse oxygen
- SOFA:
-
Sequential Organ Failure Assessment
- SAPS III:
-
Simplified Acute Physiology Score III
- SBP:
-
Systolic blood pressure
- WBC:
-
White blood cells
References
Benjamin EJ, Virani SS, Callaway CW, Chamberlain AM, Chang AR, Cheng S, et al. Heart disease and stroke statistics-2018 update: a report from the American heart association. Circulation. 2018;137(12):e67–492.
Gräsner JT, Wnent J, Herlitz J, Perkins GD, Lefering R, Tjelmeland I, et al. Survival after out-of-hospital cardiac arrest in Europe - results of the EuReCa TWO study. Resuscitation. 2020;148:218–26.
Holmberg MJ, Ross CE, Fitzmaurice GM, Chan PS, Duval-Arnould J, Grossestreuer AV, et al. Annual incidence of adult and pediatric in-hospital cardiac arrest in the United States. Circ Cardiovasc Qual Outcomes. 2019;12(7): e005580.
Andersen LW, Holmberg MJ, Løfgren B, Kirkegaard H, Granfeldt A. Adult in-hospital cardiac arrest in Denmark. Resuscitation. 2019;140:31–6.
Nolan JP, Laver SR, Welch CA, Harrison DA, Gupta V, Rowan K. Outcome following admission to UK intensive care units after cardiac arrest: a secondary analysis of the ICNARC Case Mix programme database. Anaesthesia. 2007;62(12):1207–16.
Carr BG, Goyal M, Band RA, Gaieski DF, Abella BS, Merchant RM, et al. A national analysis of the relationship between hospital factors and post-cardiac arrest mortality. Intensive Care Med. 2009;35(3):505–11.
Carr BG, Kahn JM, Merchant RM, Kramer AA, Neumar RW. Inter-hospital variability in post-cardiac arrest mortality. Resuscitation. 2009;80(1):30–4.
Shih HM, Chen YC, Chen CY, Huang FW, Chang SS, Yu SH, et al. Derivation and validation of the SWAP score for very early prediction of neurologic outcome in patients with out-of-hospital cardiac arrest. Ann Emerg Med. 2019;73(6):578–88.
Dutta A, Alirhayim Z, Masmoudi Y, Azizian J, McDonald L, Jogu HR, et al. Brain natriuretic peptide as a marker of adverse neurological outcomes among survivors of cardiac arrest. J Intensive Care Med. 2022;37(6):803–9.
Andersson P, Johnsson J, Björnsson O, Cronberg T, Hassager C, Zetterberg H, et al. Predicting neurological outcome after out-of-hospital cardiac arrest with cumulative information; development and internal validation of an artificial neural network algorithm. Crit Care. 2021;25(1):83.
Choy G, Khalilzadeh O, Michalski M, Do S, Samir AE, Pianykh OS, et al. Current applications and future impact of machine learning in radiology. Radiology. 2018;288(2):318–28.
Heo J, Yoon JG, Park H, Kim YD, Nam HS, Heo JH. Machine learning-based model for prediction of outcomes in acute stroke. Stroke. 2019;50(5):1263–5.
Park JH, Shin SD, Song KJ, Hong KJ, Ro YS, Choi JW, et al. Prediction of good neurological recovery after out-of-hospital cardiac arrest: a machine learning analysis. Resuscitation. 2019;142:127–35.
Andersen LW, Holmberg MJ, Berg KM, Donnino MW, Granfeldt A. In-hospital cardiac arrest: a review. JAMA. 2019;321(12):1200–10.
Zhang Z. Missing data imputation: focusing on single imputation. Annals of translational medicine. 2016;4(1):9.
Lee KJ, Simpson JA. Introduction to multiple imputation for dealing with missing data. Respirology (Carlton, Vic). 2014;19(2):162–7.
Sterne JA, White IR, Carlin JB, Spratt M, Royston P, Kenward MG, et al. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ (Clinical research ed). 2009;338: b2393.
Pedersen AB, Mikkelsen EM, Cronin-Fenton D, Kristensen NR, Pham TM, Pedersen L, et al. Missing data and multiple imputation in clinical epidemiological research. Clin Epidemiol. 2017;9:157–66.
Buuren Sv. Flexible Imputation of Missing Data. Chapman and Hall/CRC; 2012. https://doi.org/10.1201/b11826.
Peterson PN, Rumsfeld JS, Liang L, Albert NM, Hernandez AF, Peterson ED, et al. A validated risk score for in-hospital mortality in patients with heart failure from the American Heart Association get with the guidelines program. Circ Cardiovasc Qual Outcomes. 2010;3(1):25–32.
Sauerbrei W, Royston P, Binder H. Selection of important variables and determination of functional form for continuous predictors in multivariable model building. Stat Med. 2007;26(30):5512–28.
McEligot AJ, Poynor V, Sharma R, Panangadan A. Logistic LASSO Regression for Dietary Intakes and Breast Cancer. Nutrients. 2020;12(9):2652.
Zou Y, Shi Y, Sun F, Liu J, Guo Y, Zhang H, et al. Extreme gradient boosting model to assess risk of central cervical lymph node metastasis in patients with papillary thyroid carcinoma: Individual prediction using SHapley Additive exPlanations. Comput Methods Programs Biomed. 2022;225: 107038.
Davagdorj K, Pham VH, Theera-Umpon N, Ryu KH. XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction. Int J Environ Res Public Health. 2020;17(18):6513.
Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Medical decision making : an international journal of the Society for Medical Decision Making. 2006;26(6):565–74.
Hydes TJ, Meredith P, Schmidt PE, Smith GB, Prytherch DR, Aspinall RJ. National early warning score accurately discriminates the risk of serious adverse events in patients with liver disease. Clinical gastroenterology and hepatology : the official clinical practice journal of the American Gastroenterological Association. 2018;16(10):1657-66.e10.
Pimentel MAF, Redfern OC, Gerry S, Collins GS, Malycha J, Prytherch D, et al. A comparison of the ability of the national early warning score and the national early warning score 2 to identify patients at risk of in-hospital mortality: a multi-centre database study. Resuscitation. 2019;134:147–56.
Scott LJ, Redmond NM, Tavaré A, Little H, Srivastava S, Pullyblank A. Association between National Early Warning Scores in primary care and clinical outcomes: an observational study in UK primary and secondary care. The British journal of general practice : the journal of the Royal College of General Practitioners. 2020;70(695):e374–80.
Kim I, Song H, Kim HJ, Park KN, Kim SH, Oh SH, et al. Use of the national early warning score for predicting in-hospital mortality in older adults admitted to the emergency department. Clinical and experimental emergency medicine. 2020;7(1):61–6.
Royal College of Physicians National Early Warning Score (NEWS) 2: Standardising the assessment of acute-illness severity in the NHS. Updated report of a working party. London: RCP; 2017.
Seki T, Tamura T, Suzuki M. Outcome prediction of out-of-hospital cardiac arrest with presumed cardiac aetiology using an advanced machine learning technique. Resuscitation. 2019;141:128–35.
Pareek N, Kordis P, Beckley-Hoelscher N, Pimenta D, Kocjancic ST, Jazbec A, et al. A practical risk score for early prediction of neurological outcome after out-of-hospital cardiac arrest: MIRACLE2. Eur Heart J. 2020;41(47):4508–17.
Chi CY, Ao S, Winkler A, Fu KC, Xu J, Ho YL, et al. Predicting the mortality and readmission of in-hospital cardiac arrest patients with electronic health records: a machine learning approach. J Med Internet Res. 2021;23(9): e27798.
Tran S, Deacon N, Minokadeh A, Malhotra A, Davis DP, Villanueva S, et al. Frequency and survival pattern of in-hospital cardiac arrests: the impacts of etiology and timing. Resuscitation. 2016;107:13–8.
Chen SH, Cheng YY, Lin CH. An Early Predictive Scoring Model for In-Hospital Cardiac Arrest of Emergent Hemodialysis Patients. J Clin Med. 2021;10(15):3241.
Li Z, Zhou D, Zhang S, Wu L, Shi G. Association between mean arterial pressure and survival in patients after cardiac arrest with vasopressor support: a retrospective study. European journal of emergency medicine : official journal of the European Society for Emergency Medicine. 2021;28(4):277–84.
Yang D, Ha SG, Ryoo E, Choi JY, Kim HJ. Multimodal assessment using early brain CT and blood pH improve prediction of neurologic outcomes after pediatric cardiac arrest. Resuscitation. 2019;137:7–13.
Al Assil R, Singer J, Heidet M, Fordyce CB, Scheuermeyer F, Diepen SV, et al. The association of pH values during the first 24 h with neurological status at hospital discharge and futility among patients with out-of-hospital cardiac arrest. Resuscitation. 2021;159:105–14.
Nolan JP, Soar J, Cariou A, Cronberg T, Moulaert VR, Deakin CD, et al. European resuscitation council and European society of intensive care medicine 2015 guidelines for post-resuscitation care. Intensive Care Med. 2015;41(12):2039–56.
Issa MS, Grossestreuer AV, Patel H, Ntshinga L, Coker A, Yankama T, et al. Lactate and hypotension as predictors of mortality after in-hospital cardiac arrest. Resuscitation. 2021;158:208–14.
Donnino MW, Andersen LW, Giberson T, Gaieski DF, Abella BS, Peberdy MA, et al. Initial lactate and lactate change in post-cardiac arrest: a multicenter validation study. Crit Care Med. 2014;42(8):1804–11.
Lonsain WS, De Lausnay L, Wauters L, Desruelles D, Dewolf P. The prognostic value of early lactate clearance for survival after out-of-hospital cardiac arrest. Am J Emerg Med. 2021;46:56–62.
Schluep M, Rijkenberg S, Stolker RJ, Hoeks S, Endeman H. One-year mortality of patients admitted to the intensive care unit after in-hospital cardiac arrest: a retrospective study. J Crit Care. 2018;48:345–51.
Metnitz PG, Moreno RP, Almeida E, Jordan B, Bauer P, Campos RA, et al. SAPS 3–From evaluation of the patient to evaluation of the intensive care unit part 1: objectives, methods and cohort description. Intensive Care Med. 2005;31(10):1336–44.
Bisbal M, Jouve E, Papazian L, de Bourmont S, Perrin G, Eon B, et al. Effectiveness of SAPS III to predict hospital mortality for post-cardiac arrest patients. Resuscitation. 2014;85(7):939–44.
Nassar AP, Malbouisson LM, Moreno R. Evaluation of simplified acute physiology score 3 performance: a systematic review of external validation studies. Crit Care. 2014;18(3):R117.
Taccone FS, Picetti E, Vincent JL. High quality Targeted Temperature Management (TTM) after cardiac arrest. Crit Care. 2020;24(1):6.
Sandroni C, Cavallaro F. The 2005 European Guidelines for cardiopulmonary resuscitation: major changes and rationale. Minerva Anestesiol. 2008;74(4):137–43.
Ushay HM, Notterman DA. Pharmacology of pediatric resuscitation. Pediatr Clin North Am. 1997;44(1):207–33.
Walsh TS, Stanworth SJ, Prescott RJ, Lee RJ, Watson DM, Wyncoll D. Prevalence, management, and outcomes of critically ill patients with prothrombin time prolongation in United Kingdom intensive care units. Crit Care Med. 2010;38(10):1939–46.
Zhao H, Xu L, Dong H, Hu J, Gao H, Yang M, et al. Correlations between clinical features and mortality in patients with vibrio vulnificus infection. PLoS ONE. 2015;10(8): e0136019.
Hochart A, Momal R, Garrigue-Huet D, Drumez E, Susen S, Bijok B. Prothrombin time ratio can predict mortality in severe pediatric trauma: study in a French trauma center level 1. Am J Emerg Med. 2020;38(10):2041–4.
Badriyah T, Briggs JS, Meredith P, Jarvis SW, Schmidt PE, Featherstone PI, et al. Decision-tree early warning score (DTEWS) validates the design of the National Early Warning Score (NEWS). Resuscitation. 2014;85(3):418–23.
Smith GB, Prytherch DR, Meredith P, Schmidt PE, Featherstone PI. The ability of the National Early Warning Score (NEWS) to discriminate patients at risk of early cardiac arrest, unanticipated intensive care unit admission, and death. Resuscitation. 2013;84(4):465–70.
Heo JH, Kim T, Shin J, Suh GJ, Kim J, Jung YS, et al. Prediction of neurological outcomes in out-of-hospital cardiac arrest survivors immediately after return of spontaneous circulation: ensemble technique with four machine learning models. J Korean Med Sci. 2021;36(28): e187.
Bougouin W, Slimani K, Renaudier M, Binois Y, Paul M, Dumas F, et al. Epinephrine versus norepinephrine in cardiac arrest patients with post-resuscitation shock. Intensive Care Med. 2022;48(3):300–10.
Acknowledgements
Not applicable.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
Conception and design: YWS, ZYH, JR; Data collection and analysis: YWS, ZYH, YFW; Drafting the manuscript: YWS. All authors have read, edited, and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The Institutional Review Boards (IRBs) at both Massachusetts Institute of Technology and the Beth Israel Deaconess Medical Center approved the use of the data for research. The MIMIC-IV (https://mimic-iv.mit.edu) database can be accessed by certified researchers, so no additional informed consent of the patient and ethic approvement are required. The certified researcher of this study is Yiwu Sun (Certification Number: 50778029). All methods of this article were performed in accordance with the relevant guidelines and regulations.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Sun, Y., He, Z., Ren, J. et al. Prediction model of in-hospital mortality in intensive care unit patients with cardiac arrest: a retrospective analysis of MIMIC -IV database based on machine learning. BMC Anesthesiol 23, 178 (2023). https://doi.org/10.1186/s12871-023-02138-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12871-023-02138-5