
Abstract
Background
Pulmonary tuberculosis (PTB) is a prevalent chronic disease associated with a significant economic burden on patients. Using machine learning to predict hospitalization costs can allocate medical resources effectively and optimize the cost structure rationally, so as to control the hospitalization costs of patients better.
Methods
This research analyzed data (2020–2022) from a Kashgar pulmonary hospital’s information system, involving 9570 eligible PTB patients. SPSS 26.0 was used for multiple regression analysis, while Python 3.7 was used for random forest regression (RFR) and MLP. The training set included data from 2020 and 2021, while the test set included data from 2022. The models predicted seven various costs related to PTB patients, including diagnostic cost, medical service cost, material cost, treatment cost, drug cost, other cost, and total hospitalization cost. The model’s predictive performance was evaluated using R-square (R2), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE) metrics.
Results
Among the 9570 PTB patients included in the study, the median and quartile of total hospitalization cost were 13,150.45 (9891.34, 19,648.48) yuan. Nine factors, including age, marital status, admission condition, length of hospital stay, initial treatment, presence of other diseases, transfer, drug resistance, and admission department, significantly influenced hospitalization costs for PTB patients. Overall, MLP demonstrated superior performance in most cost predictions, outperforming RFR and multiple regression; The performance of RFR is between MLP and multiple regression; The predictive performance of multiple regression is the lowest, but it shows the best results for Other costs.
Conclusion
The MLP can effectively leverage patient information and accurately predict various hospitalization costs, achieving a rationalized structure of hospitalization costs by adjusting higher-cost inpatient items and balancing different cost categories. The insights of this predictive model also hold relevance for research in other medical conditions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Background
Pulmonary tuberculosis (PTB) is a highly infectious disease caused by Mycobacterium tuberculosis (MTB) infection that poses a significant threat to human life and health. It has been referred to as “phthisis” in ancient Chinese folk medicine. This disease has been historically associated with large-scale epidemics and high mortality rates, resulting in the name “white plague” [1]. Global data from the World Health Organization (WHO) reveal that approximately 1.7 billion people worldwide have latent PTB infection, accounting for 23% of the global population. China is among the 30 countries with a high prevalence of PTB, with 780,000 new cases reported in 2021, representing 7.4% of the total global new cases and ranking third worldwide [2]. In Kashgar, epidemiological surveys have shown a high incidence of PTB, reaching 315.50 per 100,000 people, which is 5.21 times the national average [3].
PTB is characterized by a long course and long treatment duration, often lasting approximately six months or longer. This imposes a significant economic burden on patients and their families, impacting employment opportunities and worsening financial hardships. According to WHO data, tuberculosis is the seventh leading cause of death in low- and middle-income countries and ranks seventh in terms of the overall economic burden of disease worldwide [4]. Among more than thirty countries with a high burden of tuberculosis worldwide, China ranks second in terms of new tuberculosis cases and cases of multidrug-resistant tuberculosis. While China has made progress in tuberculosis control through the implementation of the DOTS strategy, the country still faces challenges in tuberculosis prevention and control, with the incidence of PTB decreasing by approximately 61% from 2000 to 2010. However, this reduction has not significantly changed the situation in high-burden tuberculosis countries, highlighting the ongoing severity of the disease. The healthcare costs associated with tuberculosis in China have been continuously increasing. From 2006 to 2018, the total healthcare costs and average cost per patient for tuberculosis increased, with a budget of 7.19 million US dollars allocated for tuberculosis healthcare costs in 2019. Despite China’s implementation of a free service policy for tuberculosis, patients still need to allocate a significant portion of their annual income to treatment costs. This has earned tuberculosis, the reputation of being a “disease of poverty,” pushing many families into or back into financial hardship.
With the development of machine learning algorithms, predictive models have been widely applied in fields such as education, finance, and healthcare. Recently, there has been a growing interest in predictive models targeting high-cost patients to reduce healthcare expenditures compared to interventions targeting the entire population [5]. Existing “medical cost prediction models” can be broadly classified into two categories [6]: rule-based prediction models and supervised machine learning models. Rule-based models utilize traditional algorithms based on predefined cost rules. However, these models require substantial domain knowledge and may struggle to adapt to complex data in practical scenarios. On the other hand, supervised machine learning models, such as random forests and support vector machines, can capture relationships between data. However, these models require extensive feature engineering for different characteristics and may not adapt well to high-dimensional data. Despite these drawbacks, both types of models have shown good prediction performance in various domains, including house price prediction and the prediction of diagnosis and treatment costs for chronic diseases such as hepatitis B and coronary heart disease. For example, Taloba et al. [7] utilized linear regression analysis, the naive bayes classifier, and random forest models to predict medical costs related to spinal fusion, highlighting the good prediction performance of linear regression models based on the MAPE and R2. Similarly, Gowd et al. [8] employed logistic regression, K nearest neighbor, random forest, naive Bayes, decision tree, gradient elevation tree, and other models to predict total medical costs after total shoulder arthroplasty, revealing that the random forest gradient elevation tree performed the best by comparing accuracy and the area under the receiver operating characteristic curve.
However, the abovementioned models are often considered incapable of adequately detecting complex patterns in large-scale population data [9]. Fortunately, rapidly developing deep learning techniques, including the latest deep neural network structures and quantitative methods, have shown promise in overcoming these challenges. Recent studies have demonstrated the success of deep learning in various medical applications, such as helping dermatologists examine skin cancer [10], predicting patient outcomes using medical text data [11], and as a clinical diagnostic to streamline the triaging of patients and facilitate the clinical decision-making process [12]. The early perceptron model was limited to simple binary classification problems and failed to solve complex nonlinear problems. However, the introduction of hidden layers and activation functions allowed the multilayer perceptron (MLP), also known as multilayer neural network, to be widely used in data mining, pattern recognition, machine learning, and other fields [13,14,15]. Introducing skip-layer connections in feedforward neural networks allows for the full utilization of input information to supplement the parts of the original feature information lost during the network training compression process. The predictive performance has been validated and proven effective, MA Morid et al. [16] attempted to improve the performance of healthcare cost prediction methods by leveraging the feature learning power of convolutional neural networks for temporal pattern detection. P Drewe-Boss et al. [17] have shown that neural networks compare favorably to several baseline methods and that tools such as integrated gradients can be used to explain predictions of population health costs. A Al Bataineh et al. [18] proposed an MLP neural network trained with PSO for heart disease detection. The findings demonstrated that the MLP-PSO model can assist healthcare providers in more accurately diagnosing patients and recommending better treatments. Therefore, given the limited complexity of multiple regression and random forest regression (RFR), we selected the MLP model in our manuscript to validate the results and compare the three models.
In China, there have been few studies on healthcare cost prediction due to the public welfare and nonprofit nature of healthcare services. Therefore, the innovative analysis of the introduction of the MLP model provides insights into the future application of artificial intelligence in the medical field. By utilizing the MLP model to predict hospitalization costs, we can potentially provide more intelligent economic management tools for medical institutions and offer more personalized and economically reasonable medical services for patients. This has significant social and economic implications for promoting the coordinated development of the “artificial intelligence + medicine” field and improving the quality and efficiency of medical services.
Method
Data
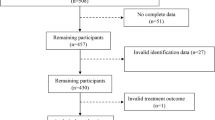
This study aimed to investigate patients with PTB (coded as A15-A16 according to the ICD-10) who were admitted to Kashgar Pulmonary Hospital between 2020 and 2022 and subsequently discharged. The data are derived from the hospital information system of a pulmonary hospital in Kashgar. Medical professionals record and organize patient medical records within 24 h and promptly upload them to the hospital information system. Additionally, data within the system are independently collected and organized by two individuals, followed by cross-checking to ensure the accuracy and completeness of the date within the system. Patients with missing data and inability to verify cost were excluded from the study, a total of 9,570 eligible patients with PTB were included as subjects for this study (Fig. 1).

This figure shows the patient inclusion and exclusion process
Total hospitalization cost
The costs were categorized according to the cost items listed on the first page of the latest version of the medical records in 2017. Similar cost items were combined, resulting in six categories, namely, diagnosis cost (including pathological diagnosis, laboratory diagnosis, imaging diagnosis, clinical diagnosis items, etc.), medical service cost (including general medical services, general treatment operations, nursing cost, etc.), material cost (including examination, treatment, surgical disposable medical materials, etc.), treatment cost (including nonsurgical treatment items, surgical treatment cost, etc.), drug cost (including western medicine, Chinese patent medicine, Chinese herbal medicine, etc.), and other cost (including rehabilitation cost, traditional Chinese medicine cost, blood and blood product cost, etc.).
Sociological data
Sociological data such as gender, age, marital status, and payment method were collected. Disease Characteristics Data: Information related to the admission condition, length of hospital stay, initial treatment, presence of other diseases, transfer, allergy, drug resistance, and admission department were also collected.
It is important to note that this study obtained approval from the hospital ethics committee, and all patient information used in the research was completely anonymous.
Statistical methods
A comprehensive database was created using SPSS 26.0, and the data were collated and cleaned. Descriptive analysis was conducted on the hospitalization cost data, sociological data, and disease characteristic data of all patients with PTB. Categorical data was described using frequencies and constituent ratios, while medians and interquartile ranges were used to describe the central tendency and dispersion tendency of continuous data with a skewed distribution.
In univariate analysis, Mann–Whitney U test was used for pairwise comparisons, including 6 factors such as gender, initial treatment, presence of other diseases, transfer, allergy, and drug resistance; Kruskal–Wallis H test was used for multiple-group comparisons, including 6 factors such as age, marital status, payment method, admission condition, length of hospital stay, and admission department. After the results of the univariate analysis, multiple stepwise regression analysis was performed to analyze the main factors influencing the total hospitalization cost. P < 0.05 indicated a statistically significant difference.
Based on the collected data, multiple regression, RFR and MLP prediction models were established to predict the diagnosis cost, medical service cost, material cost, treatment cost, drug cost, other cost, and total hospitalization cost of patients with PTB. The prediction efficacy of the three models was compared using R-square (R2), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE). R2 reflects the proportion of variation explained by the model and is usually used to evaluate the predictive ability of the model. A higher R2 value indicates a better fit of the model to the data. The RMSE is considered to measure the average error that a model produces when predicting an observation. The lower the RMSE is, the better the predictive ability of the model. Like the RMSE, the MAE measures prediction errors but is less sensitive to outliers; the lower the MAE is, the better the model. An essential use of predictive models is identifying key data features and their impact on predictions. We leveraged Permutation Importance to assess the best model’s feature importance.
Predictive model build
All the data were divided into a training set (2020–2021) and a test set (2022) according to the year. In terms of feature processing, multicategory variables were transformed into dummy variables; for binary variables, they were converted into 0 and 1; and the predictive costs were transformed using the logarithm. The numerical variables such as age and length of stay, were divided into ordinal categories by interval. The variable assignments were detailed in Appendix Table.
Seven multiple regression models were separately established for diagnosis cost, medical service cost, material cost, treatment cost, drug cost, other cost and total hospitalization cost. The forward method was employed to select the optimal variables.
With sklearn package in Python 3.7, seven RFR models also were separately established. In order to select the optimal hyper-parameters, a fivefold cross-validation method with grid search was used to tune below parameters, n_estimators (5 ~ 100), max_features ([‘auto’, ‘sqrt’, ‘log2’]), max_depth (2 ~ 12), min_samples_split (5 ~ 150), and min_samples_leaf (5 ~ 50). By systematically exploring the parameter space through this comprehensive tuning strategy, we aimed to identify the optimal hyper-parameter configuration for each RFR model, ensuring optimal performance and generalization ability.
The model architecture adopted in this study was different from the traditional multilayer perceptron. MLP encompasses an input layer, one or multiple hidden layers, and an output layer. Neurons in a layer are fully connected to those in the subsequent layer, enabling information transmission through weighted connections and biases. In our model’s design,the original input was connected to the hidden vector in the last hidden layer and fed to the output layer. This setup permitted the network to harness both simple input–output relationships and residuals from complex deep learning architectures. Then, the final seven target costs including diagnosis cost, medical service cost, material cost, treatment cost, drug cost, other cost, and total hospitalization cost were predicted. The model was built and optimized by the Keras package in Python 3.7. To select the optimal hyperparameters, a fivefold cross-validation method with grid search was used to tune the number of hidden layers (3 ~ 10), the number of neurons per layer (10 ~ 50), the dropout (0.25, 0.5) and the learning rate (0.001, 0.01). Besides, Rectified Linear Units (ReLU) was applied as the activation function, the Adam optimizer for parameter optimization.
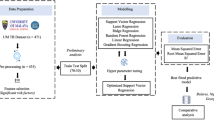
In the fivefold cross-validation, 300 epochs were used for each training, and to prevent overfitting, the early stopping mechanism was used, indicating that training would be halted if the loss in the validation set did not decrease for 10 consecutive epochs. We used the Adam optimizer and the mean squared error as the loss function. The optimal model was evaluated with an average of 5 loss results. An overview of inference and analysis framework was illustrated in Fig. 2.

This is an overview of Inference and Analysis Framework
Results
Description of general feature
Among the 9,570 patients with PTB, the proportion of female patients (53.77%) was higher. The median and quartile of patient age were 67.00 (55.00, 74.00) years. The majority of patients were married (91.41%). Most patients (81.04%) used urban and rural residents’ medical insurance as the payment method. The majority of patients were admitted as general patients (53.11%). The median and quartile length of hospital stay for patients were 14.00 (11.00, 21.00) days, and 79.51% of patients were newly diagnosed with PTB. A total of 61.78% of patients had comorbidities. A total of 95.17% of patients were not transferred to another department. A total of 98.51% of patients had no allergies. A total of 97.77% of patients did not have resistance to medications. The proportion of PTB patients admitted to the respiratory department was the largest (17.46%).
Univariate analysis revealed significant differences in the total hospitalization cost among the 11 factors except allergy (P = 0.358), including gender, age, marital status, payment method, admission condition, length of hospital stay, initial treatment, presence of other diseases, transfer, drug resistance, and admission department (P < 0.05) (Table 1).
The hospitalization costs of various categories of PTB patients exhibited a skewed distribution, the median total hospitalization cost was 13,150.45 yuan, with an interquartile range between 9,891.34 yuan and 19,648.48 yuan. According to the analysis of hospitalization costs, material costs accounted for the greatest proportion of patients with PTB, followed by drug costs (Table 2).
Multiple regression analysis revealed that the F value was 1377.916, indicating a highly significant relationship (P < 0.001). The R2 was 0.760, suggesting that the regression model explained 76.0% of the total variation. The RMSE was 0.130, indicating a relatively small average difference between the predicted and actual values. Additionally, the coefficient of variance expansion (VIF) for all independent variables was less than 5, indicating the absence of multicollinearity among the variables included in the analysis.
The analysis revealed nine statistically significant factors (age, marital status, admission condition, length of hospital stay, initial treatment, presence of other diseases, transfer, drug resistance and admission department) that were the main factors influencing the hospitalization costs of patients with PTB (P < 0.05) (Table 3).
Modeling Results
The seven multiple regression models were developed using the forward method, with varying characteristics included for cost prediction. Age and length of hospital stay were used in all models; Admission condition, initial treatment, transfer and admission department were effective variables for most models; Less used in the model were marital status, presence of other diseases and drug resistance (Table 4).
As to RFR, the best parameters were different in 7 cost prediction models. In total hospitalization cost prediction model, the optimal parameter were ‘max_depth’ = 8, ‘max_features’ = ‘auto’, ‘min_samples_leaf’ = 10, ‘min_samples_split’ = 10, ‘n_estimators’ = 10.
Figure 3 showed the relationship between the number of trees and RMSE when using the RFR algorithm to predict total hospitalization cost, with the RMSE being minimal near 10 trees. While figure (b) showed that the optimal max_depth was 8.

This diagram shows training process of the RFR
Based on the average loss results from fivefold cross-validation, the optimal parameter combination for the MLP model was determined(number of hidden layers = 3, number of neurons per layer = 50, dropout rate = 0.25, and learning rate = 0.001). With the optimal parameter combination, the validation set loss was minimized at the 18th epoch and did not decrease further after 10 epochs (Fig. 4). Figure 5 shows the true and predicted values of the MLP in the training and test sets, the scatter plot highlights the great predictive performance of the MLP. Figure 6 showed the ranking of feature importance for the model, with admission department and length of hospital stay ranking highly.

This graph shows the loss curve of train and validation set of the MLP under the optimal parameter combination

This picture shows the scatter plot of the true and predicted values of seven hospitalization costs in MLP model. Shown in (a, c, e, g, i, k, m) are the training while shown in (b, d, f, h, j, l, n) are testing sets

This picture shows the ranking of feature importance for the model
Table 5 showed the evaluation results of the three modeling methods. Overall, MLP demonstrated the superior performance in most cost predictions, outperforming RFR and multiple regression. For instance, as to the prediction of total hospitalization cost, both in the training set and the test set, MLP achieved the highest R2 values (0.817 and 0.832, respectively), surpassing RFR’s R2 (0.758 and 0.809, respectively) and multiple regression’s R2 (0.707 and 0.777, respectively); Additionally, MLP had the lowest RMSE (0.103 and 0.114, respectively) and MAE (0.078 and 0.086, respectively), lower than the RMSE (0.118 and 0.122, respectively) and MAE (0.086 and 0.091, respectively) of RFR and the RMSE (0.130 and 0.132, respectively) and MAE (0.098 and 0.099, respectively) of multiple regression. However, in the prediction of diagnostic cost, RFR exhibited the best performance in the test set, with an R2 of 0.629, RMSE of 0.231, and MAE of 0.167, better than MLP (0.609, 0.237 and 0.163, respectively) and multiple regression (0.518, 0.264 and 0.175, respectively). Despite multiple regression showed low performance across all models, in the prediction of other cost, multiple regression revealed the best results in the test set, with an R2 of 0.352, RMSE of 0.792, and MAE of 0.627, better than MLP (0.313, 0.816 and 0.611, respectively) and RFR (0.342, 0.799 and 0.619, respectively).
Discuss
The combined results of univariate analysis and multivariate linear regression analysis revealed that the main factors affecting the hospitalization costs of PTB patients were, age, marital status, admission condition, length of hospital stay, initial treatment, presence of other diseases, transfer, drug resistance and admission department. Length of hospital stay, initial treatment and age were important factors affecting the hospitalization costs of PTB patients, with standard regression coefficients of 0.657, 0.200 and 0.107, respectively. Notably, younger patients tend to demonstrate better physical fitness and fewer underlying health conditions, which contributes to more favorable treatment outcomes and, consequently, lower hospitalization costs. With increasing age, the patient’s own immunity will decrease, which will have a certain impact on the therapeutic effect, resulting in increased hospitalization costs; widowed patients need to bear the economic productivity of the entire family alone, and various external pressures may also cause psychological and physical double pressures, so the patient’s physical health will be adversely affected, indirectly leading to an increase in the total hospitalization cost; critically ill patients face a large number of treatment costs and examination costs, which may require shortening the length of hospital stay as much as possible during the diagnosis and treatment period, strengthening the intensity of treatment, and avoiding unnecessary treatment items, examination items and drugs as much as possible, leading to lower per capita hospitalization costs; the longer the length of hospital stay is, the greater the number of medical and health resources, such as examination costs, medical costs and bed costs, and thus, it is bound to increase the total hospitalization costs [19,20,21]. Multiple treatment, combined with other diseases, transfer, drug resistance, and PTB patients in ICU departments may be more complex and correspondingly more difficult to treat, usually accompanied by more health resource consumption, which invisibly leads to an increase in the total hospitalization cost [22,23,24]. The above influencing factors suggest that relevant medical insurance policies should be improved, standardized diagnosis, treatment and management models should be improved, and popular science awareness of PTB prevention and control should be promoted to optimize the structure of hospitalization costs and reasonably control the increase in medical costs.
The results of our study showed that the MLP model had better predictive performance for hospitalization costs than did the multiple regression and RFR, which was similar to the findings of previous studies. [25,26,27]. Traditional models such as multiple regression and RFR might not be able to identify complex relationships among variables, leading to suboptimal fitting performance. However, the MLP model has the characteristics of large-scale parallel processing, high fault tolerance, self-organization, self-adaptive ability and an association function [28]. This approach necessitated a less restrictive specification of independent variables and could effectively solve highly complex classification problems. It was suitable for processing information that involves considering numerous factors and conditions simultaneously, especially in situations that are imprecise and fuzzy [29]; high nonlinear global action, automatic extraction of “reasonable” solution rules, and certain promotion and generalization ability were also the advantages of the MLP model. Chen Y et al. [30] proposed a new LPR-MLP hybrid model, which uses LBP, PCA, and Relief F to process image data and meteorological mechanics data, respectively, and then uses MLP to predict its health level, thus solving the challenge of predicting the health status of transmission lines under high-dimension, multimode, nonlinear, and heterogeneous data. The experimental results have shown that the LPR-MLP model has high prediction accuracy and performance.
Recently, the success of deep learning has led to a resurgence of interest in MLP. MLP, which is regarded as a standard supervised learning algorithm in the field of pattern recognition and continues to become a subject of research in the field of computational neurology and parallel distributed processing, is often used as a back propagation algorithm for learning [31]. At present, the MLP has been proven to be a general functional approximation method that can be used to fit complex functions or solve classification problems. Compared with other prediction models, MLP models have shown unique advantages, and their popularity and application are wider [32]. The utilization of the MLP model for predicting hospitalization costs positively impacts medical cost management, aiding in the rational allocation of medical resources by diverse healthcare institutions and balancing various hospitalization costs through adjustments to high-cost items. This ultimately achieves the goal of controlling patients’ medical costs and alleviating their economic burden.
At present, there is limited research on predicting medical costs. The introduction of the MLP model for hospitalization cost prediction holds significant social and economic importance in enhancing the quality and efficiency of medical services. The MLP model is currently capable of effectively addressing more complex problems, but it also exhibits notable shortcomings, such as the challenging task of determining the appropriate number of hidden nodes in the network, potential inadequacies in learning, and lengthy training times. Consequently, future research on MLP models should further expand the research sample and include more influencing factors and comparative models.
This study was constrained by the limitations of its data source, as patient data ware derived from a single center, and its generalizability may be restricted. Furthermore, as a retrospective study, the cases were sourced from the hospital information systems, limiting access to additional variables that may impact hospitalization costs. Therefore, a multicenter study with a greater number of variables is required.
Conclusion
In general, the MLP model has demonstrated significant advantages over the traditional multiple regression models in terms of prediction efficacy. It enabled the utilization of comprehensive patient information and effectively predicted hospitalization costs, thereby facilitating the rationalization of cost structures and reducing the economic burden on patients. Furthermore, the insights gained from the MLP model hold considerable reference value for research on other diseases, highlighting its broader applicability in the field of healthcare economics.
Availability of data and materials
The data underlying this manuscript cannot be shared publicly due to the privacy of individuals in the study. These data are stored in a protected information system at a pulmonary hospital in Kashgar, Xinjiang, China. The datasets manipulated or generated in our research are available from the corresponding author upon reasonable request.
Abbreviations
- PTB:
-
Pulmonary Tuberculosis
- WHO:
-
World Health Organization
- MLP:
-
Multilayer Perceptron
- R2 :
-
R-square
- RMSE:
-
Root Mean Squared Error
- MAE:
-
Mean Absolute Error
- RFR:
-
Random Forest Regression
- ReLU:
-
Rectified Linear Units
References
Chakaya J, Khan M, Ntoumi F, Aklillu E, Fatima R, Mwaba P, et al. Global Tuberculosis Report 2020–Reflections on the Global TB burden, treatment and prevention efforts. Int J Infect Dis. 2021;113:S7–12.
Philippe G, Katherine F, Mario R. Iconography: global epidemiology of tuberculosis. Seminars Respir Crit Care Med. 2018;39(03):271–85.
Chen W, Zhang H, Du X, Li T, Zhao Y. Characteristics and Morbidity of the Tuberculosis Epidemic-China, 2019. China CDC Weekly. 2020;2(12):181–4.
World Health Organization. World health statistics 2021: monitoring health for the SDGs, sustainable development goals. World Health Organ. 2021;2021:1–136.
Osawa I, Goto T, Yamamoto Y, Tsugawa Y. Machine-learning-based prediction models for high-need high-cost patients using nationwide clinical and claims data. NPJ Digit Med. 2020;3(1):148.
Desai RJ, Wang SV, Vaduganathan M. Comparison of machine learning methods with traditional models for use of administrative claims with electronic medical records to predict heart failure outcomes. JAMA Netw Open. 2020;3(1):e1918962.
Taloba AI, El-Aziz A, Rasha M, El-Bagoury AAH. Estimation and prediction of hospitalization and medical care costs using regression in machine learning. J Healthc Eng. 2022;2022:7969220.
Gowd AK, Agarwalla A, Beck EC, Rosas S, Waterman BR, Romeo AA, et al. Prediction of total healthcare cost following total shoulder arthroplasty utilizing machine learning. J Shoulder Elbow Surg. 2022;31(12):2449–56.
Tang A, Tam R, Cadrin-Chênevert A, Guest W, Chong J, Barfett J, et al. Canadian association of radiolo-gists white paper on artificial intelligence in radiology. Can Assoc Radiol J. 2018;69(2):120–35.
Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, et al. Der-matologist-level classification of skin cancer with deep neural networks. Nature. 2017;542(7639):115.
Rajkomar A, Oren E, Chen K, Dai AM, Hajaj N, Hardt M, et al. Scalable and accurate deep learning with electronic health records. NPJ Dig Med. 2018;1(1):18.
Zhou HY, Yu Y, Wang C, Zhang S, Gao Y, Pan J, et al. A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics. Nat Biomed Eng. 2023;7(6):743–55.
Desai M, Shah M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin eHealth. 2021;4:1–11.
Mishra S, Tripathy HK, Mallick PK, Bhoi AK, Barsocchi P. EAGA-MLP—an enhanced and adaptive hybrid classification model for diabetes diagnosis. Sensors. 2020;20(14):4036.
Poongodi M, Malviya M, Kumar C, Hamdi M, Vijayakumar V, Nebhen J, et al. New York City taxi trip duration prediction using MLP and XGBoost. Int J Syst Assurance Eng Manage. 2022;1:1–12.
Morid MA, Sheng ORL, Kawamoto K, Abdelrahman S. Learning hidden patterns from patient multivariate time series data using convolutional neural networks: A case study of healthcare cost prediction. J Biomed Inform. 2020;111:103565.
Drewe-Boss P, Enders D, Walker J, Ohler U. Deep learning for prediction of population health costs. BMC Med Inform Decis Mak. 2022;22(1):32.
Al Bataineh A, Manacek S. MLP-PSO hybrid algorithm for heart disease prediction. J Personal Med. 2022;12(8):1208.
Moreira ASR, Kritski AL, Carvalho ACC. Social determinants of health and catastrophic costs associated with the diagnosis and treatment of tuberculosis. J Bras Pneumol. 2020;46:e20200015.
Samuel R, Natesan S, Bangera MK. Quality of life and associating factors in pulmonary tuberculosis patients. Indian Journal of Tuberculosis. 2023;70(2):214–21.
Assebe LF, Negussie EK, Jbaily A, Tolla MTT. Financial burden of HIV and TB among patients in Ethiopia: a cross-sectional survey. BMJ Open. 2020;10(6):e036892.
Li XZ, Jin F, Zhang JG, Deng YF, Shu W, Qin JM, et al. Treatment of coronavirus disease 2019 in Shandong, China: a cost and affordability analysis. Infect Dis Poverty. 2020;9(03):31–8.
Oga-Omenka C, Tseja-Akinrin A, Sen P. Factors influencing diagnosis and treatment initiation for multidrug-resistant/rifampicin-resistant tuberculosis in six sub-Saharan African countries: a mixed-methods systematic review. BMJ Global Health. 2020;5(7):e002280.
Wang Y, McNeil EB, Huang Z, Chen L, Lu X, Wang C. Household financial burden among multidrug-resistant tuberculosis patients in Guizhou province, China: a cross-sectional study. Medicine. 2020;99(28):e21023.
Gopukumar D, Ghoshal A, Zhao H. Predicting readmission charges billed by hospitals: machine learning approach. JMIR Med Inform. 2022;10(8):e37578.
Theerthagiri P. Forecasting hyponatremia in hospitalized patients using multilayer perceptron and multivariate linear regression techniques. Concurr Comput: Pract Exp. 2021;33(16):e6248.
Chen M, Wu X, Zhang J, Dong E. Prediction of total hospital expenses of patients undergoing breast cancer surgery in Shanghai, China by comparing three models. BMC Health Serv Res. 2021;21(1):1–9.
Miranda AC, Santana JCC, Yamamura CLK, Rosa JM, Tambourgi EB, Ho LL, et al. Application of neural network to simulate the behavior of hospitalizations and their costs under the effects of various polluting gases in the city of São Paulo. Air Qual Atmos Health. 2021;1:1–9.
Karnuta JM, Navarro SM, Haeberle HS, Helm JM, Kamath AF, Schaffer JL, et al. Predicting inpatient payments prior to lower extremity arthroplasty using deep learning: which model architecture is best? J Arthroplasty. 2019;34(10):2235–41.
Chen Y, Chen S, Zhang N, Liu H, Jing H, Min G. LPR-MLP: A novel health prediction model for transmission lines in grid sensor networks. Complexity. 2021;2021(1):8867190.
Car-Pusic D, Petruseva S, Zileska Pancovska V, Zafirovski Z. Neural network-based model for predicting preliminary construction cost as part of cost predicting system. Adv Civil Eng. 2020;2020:1–13.
Al-Taie RRK, Saleh BJ, Saedi AYF, Salman LA. Analysis of WEKA data mining algorithms Bayes net, random forest, MLP and SMO for heart disease prediction system: a case study in Iraq. Int J Electr Comput Eng. 2021;11(6):5229.
Acknowledgements
We thank the patients and their family for their consent to participate in this study. We also appreciate all medical staff’s cooperation and care of the patient.
Funding
The project was funded from two sources. One is the Tianshan Innovation Team Program of Autonomous Region (Grant number 2022D14007). The other is the Health Kashgar National Regional Medical Center Talent Cultivation Demonstration Base (KSRC-2022001).
Author information
Authors and Affiliations
Contributions
(I) Conception and design: Shiyu Fan, Abudoukeyoumujiang Abulizi, Yasen Yimit. (II) Administrative support: Xiaoguang Zou, Mayidili Nijiati. (III) Provision of study materials or patients: Abudoukeyoumujiang Abulizi, Mayidili Nijiati. (IV) Collection and assembly of data: Shiyu Fan, Yasen Yimit, Qiange Li. (V) Data analysis and interpretation:.Yi You, Chencui Huang. (VI) Manuscript writing: All authors. (VII) Final approval of manuscript: All authors.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
The 1964 Declaration of Helsinki and its later amendments or equivalent ethical standards were followed in all procedures carried out in studies involving human subjects. This retrospective study was approved by the Ethics Committee of The First People’ s Hospital of Kashi (Kashgar) Prefecture 2023–60, which waived the need for written informed consent from the patients.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fan, S., Abulizi, A., You, Y. et al. Predicting hospitalization costs for pulmonary tuberculosis patients based on machine learning. BMC Infect Dis 24, 875 (2024). https://doi.org/10.1186/s12879-024-09771-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12879-024-09771-6