
Abstract
Background
In cancer survival analyses using population-based data, researchers face the challenge of ascertaining the timing of recurrence. We previously developed algorithms to identify recurrence of breast cancer. This is a follow-up study to detect the timing of recurrence.
Methods
Health events that signified recurrence and timing were obtained from routinely collected administrative data. The timing of recurrence was estimated by finding the timing of key indicator events using three different algorithms, respectively. For validation, we compared algorithm-estimated timing of recurrence with that obtained from chart-reviewed data. We further compared the results of cox regressions models (modeling recurrence-free survival) based on the algorithms versus chart review.
Results
In total, 598 breast cancer patients were included. 121 (20.2%) had recurrence after a median follow-up of 4 years. Based on the high accuracy algorithm for identifying the presence of recurrence (with 94.2% sensitivity and 79.2% positive predictive value), the majority (64.5%) of the algorithm-estimated recurrence dates fell within 3 months of the corresponding chart review determined recurrence dates. The algorithm estimated and chart-reviewed data generated Kaplan–Meier (K-M) curves and Cox regression results for recurrence-free survival (hazard ratios and P-values) were very similar.
Conclusion
The proposed algorithms for identifying the timing of breast cancer recurrence achieved similar results to the chart review data and were potentially useful in survival analysis.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Background
Breast cancer is the second most common cancer among Canadian women [1] and 5-year breast cancer-specific survival is about 88% overall and higher for those with stage 0 and 1 disease [2]. While breast cancer incidence and mortality are carefully tracked by provincial registries, cases of recurrent disease (local–regional and/or distant metastases) are not systematically captured. Recurrence is a much more common event compared with breast cancer mortality and hence, recurrence-free survival (RFS) is an important outcome to study. RFS analyses based on large scale real-world data enable efficient evaluation of the impact of new surgical, radiation, and systemic treatments; identification of regional gaps in care; benchmarking progress across jurisdictions; and better planning of resources and clinical trials for those with relapsed disease. However, studying population-based outcomes for early breast cancer, and breast cancer that has relapsed, is challenging as it requires chart review which is time consuming and costly [3].
Recurrence of breast cancer is an event which usually requires intensive health care resources such as advanced diagnostic imaging, biopsy, re-operation, and additional radiation and systemic therapies. This is often characterized by a sudden increase in frequency of medical encounters such as surgical oncologist or cancer center visits, or a new round of treatments. In a universal health system, the routinely collected population-based real-world health data, which capture the entire disease trajectory of a patient, provides a potential source to determine these changes in pattern of care. Further, these identified changes in care can be used to develop methods to determine whether and when the cancer has recurred. Thus, this offers a possibility to develop an algorithm that relies on the pattern of cancer care using population-based health data to identify breast cancer recurrence and its timing.
Although several studies (mainly in the United States) have used procedure and diagnostic codes to detect and identify cancer recurrence status [4,5,6,7,8,9,10,11,12], most of these algorithms were not developed to identify timing of cancer recurrence. A few studies [5, 10,11,12] addressed the challenge of identifying timing of breast cancer recurrence, however, due to differences in study cohorts, health systems (universal vs. mixed market system), and data coding standards (e.g. the Current Procedural Terminology is only used in the United States data) between their data and ours, these previously developed algorithms are not applicable to be implemented in our data. Thus, we developed a set of algorithms to identify the status of recurrence of breast cancer in our previous study [13]. However, with the lack of timing of recurrence, conducting the time-to-event RFS analysis is impossible, therefore, developing methods to identify the timing of recurrence is needed. This study aimed to develop and validate the methods for identifying timing of recurrence and then the length of RFS using real-world data from a health system with universal insurance coverage.
Methods
Data sources and study cohort
We used the data from two previously chart-reviewed cohorts with known high breast cancer recurrence rates [14, 15]. The young women cohort consisted of patients who were under the age of 41 and were diagnosed with breast cancer between 2007 and 2010. The neoadjuvant chemotherapy cohort consisted of neoadjuvant chemotherapy patients who were diagnosed with breast cancer between 2007 and 2014. Both cohorts were limited to those who were diagnosed in Alberta, Canada during the specified time periods. Patients who did not have an Alberta health care number, moved out of province within 1 year of surgery, had more than one type of tumor (i.e. second primary cancer), or had stage IV breast cancer were excluded from the study.
Our study cohorts were obtained from the Alberta Cancer Registry (ACR). The ACR is a population-based registry operated by the Alberta Health Service (AHS)—Cancer Care that records and maintains information of all cancer patients in the province such as patient name, sex, age, type of tumor, tumor characteristics (e.g., tumor stage, histology and biomarker subtypes), date of cancer diagnosis/primary treatment. Follow-up information was derived from multiple other provincial datasets. These datasets included the provincial wide cancer center electronic medical record (EMR), physician claims and vital statistics from Cancer Care Alberta and the Department of Analytics of AHS. The cancer center EMR includes the type and date of cancer center visits (e.g., chemotherapy, radiation therapy, oncologist consultation). The physician claims data records the type and dates of any procedures (e.g., diagnostic imaging, biopsy, and surgery) delivered to the patients. The vital statistics data records death and cause of death (e.g., breast cancer-related death). All available real-world health care data was linked to depict the entire care trajectory of each patient. We used the linked data to acquire patient’s treatment information such as the dates of the episode of chemotherapy and radiation therapy, the dates of outpatient/inpatient visits and the cause of death.
The patient’s recurrence status (i.e., no recurrence, local or distant recurrence) and recurrence date were ascertained by chart review and these served as gold standards to validate our developed algorithms. Chart review and abstraction were performed by MLQ and a general surgery fellow. MLQ is an experienced general surgeon and researcher, who trained the surgery fellow to conduct the chart review. Then the surgery fellow worked independently. Cases where data were unclear or ambiguous at the time of primary data entry were reviewed by both MLQ and the fellow with outcomes agreed upon by consensus. The chart review covered from patient’s initial curative-intent treatment to first recurrence, or death, or the last follow-up date (i.e., September 1, 2017). The individual patient’s follow-up time frame considered in the algorithm was the same as the one in the chart review.
Definition of breast cancer RFS
For chart review, we defined the recurrence as the development of in-situ or invasive tumors in the breast, lymph nodes or at a distant site occurring after 180 days or more from the definitive surgical date. Patients who developed second primary cancer (e.g., contralateral breast cancer) after the primary treatment determined by chart review were excluded to increase the applicability of our study.
The study outcome was RFS (i.e., recurrence and timing of recurrence) of breast cancer. Whether the recurrence status was estimated by the algorithm or derived from the chart review, patients who were regarded as having recurrence were coded as “Yes”. All the other patients including the dead patients who did not experience recurrence were coded as value “No”. Using the date (either chart review determined or algorithms estimated) of the recurrence and the date of surgery, the RFS was defined as the period between the surgery date and the recurrence date.
Indicators of recurrence
We assumed that a second cluster of clinical visits and post-primary treatments occurring at least 6 months after the definitive surgical date were potential indicators of recurrence. Since primary treatment completion generally took longer than 6 months, we also tested the algorithm using other time intervals including 12 months and 18 months after the definitive surgical date. The clinical visits and post-primary treatments considered included: diagnostic imaging tests (e.g., mammography), biopsy, surgery (e.g., mastectomy or BCS), radiation, chemotherapy, and hormonal therapy. We observed patients’ trajectories from their primary definitive surgical date and created separate indicator variables coded as ‘yes’ or ‘no’ for whether the number of patient’s clinical visits exceeded a prespecified value (e.g. 3 times), whether the patient went through another set of diagnostic procedures (imaging, biopsy), whether the patient went through another set of local or regional treatments (breast surgery, radiation), and whether the patient underwent more than two chemotherapy cycles. We also included living or deceased status of a patient, cause of death, and stage of tumor as indicators of recurrence in the developed algorithms. All the codes and data sources used for defining the study variables were presented in the Additional file Table 1.
Identifying the date of recurrence and length of recurrence-free survival
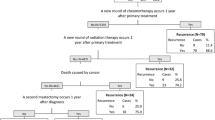
Similar with other studies [4], our previously developed recurrence identification algorithms were classification and regression tree (CART)-based decision trees [16, 17] which incorporated the indicators described above. Each indicator was a node in the tree and split the cohort into recurrent (i.e. meet the indicator) and non-recurrent cases (i.e. failed to meet the indicator). For instance, if the patient had second chemotherapy 1 year after the primary surgery (indicator), then the patient was classified as breast cancer recurrence case, otherwise not. Patients who were classified as non-recurrent cases would then be further classified using another indicator (or node). Similarly, this node split the cohort into a recurrent case or a non-recurrent case. Carrying on in the same fashion, the patient would be triaged into a non-recurrent or current case until the bottom of the decision tree. The CART decision trees were optimized by choosing a splitting node (indicator) that minimized the Gini index that is the most commonly used index for classification problems.
We also validated the decision trees accepting the chart review data as the reference. The detailed description of the development of the decision trees can be found in our previously published paper [13]. Considering different utilizations of the recurrence algorithms, we developed a set of algorithms (i.e., decision trees) including the high sensitivity algorithm (i.e., identifying as many true recurrent cases as possible), high positive predictive value (PPV) algorithm (i.e., ensuring as many identified recurrent cases are true cases as possible), and high overall accuracy algorithm (i.e., balancing sensitivity and positive predictive value). The high sensitivity algorithm reached 94.2% sensitivity, 93.7% specificity, 79.2% PPV, and 98.5% negative predictive value (NPV). The high PPV algorithm achieved 75.2% sensitivity, 98.3% specificity, 91.9% PPV, and 94% NPV. The high accuracy algorithm for identifying recurrence reached 85.1% sensitivity, 97.3% specificity, 88.8% PPV, 96.3% NPV, and 94.8% overall accuracy. The details of the decision trees including the construction of each indicator (code and definition) were presented in our published paper [13] and also in Additional files 2, 3, and 4.
Based on each of the three algorithms (high sensitivity, high Positive Predictive Value (PPV) and high overall accuracy), we estimated the timing of breast cancer recurrence. Our algorithms estimated a patient as a recurrent case when the patient met one of the indicators (i.e. nodes) in the decision tree. Some of the indicators in the decision tree have a specific date (e.g. the second surgery), thus, its date was used to estimate the date of the recurrence for the patients who met the indicator. For the indicators that did have a specific date but contain a time frame (e.g. a new cluster of cancer center visits), we estimated the date of recurrence as the middle point of the time frame if the patients met the indicator. Using the algorithm-estimated recurrence date and the primary surgery date, we calculated the length of RFS. For the five patients (0.8%) who had no surgery, the diagnosis date was used for RFS calculation. Those who were defined as non-recurrent cases by the algorithm were considered censored at their last known date in the survival analyses.
After we applied each of the three algorithms, we obtained three groups of recurrent patients (with corresponding non-recurrent patients). This also generated three sets of data (i.e. patient/tumor characteristics, treatments, and outcomes) based on each recurrent groups determined by one specific algorithm. For the purpose of validation, we compared the algorithm estimated length of RFS with that of chart review at the individual patient level. In addition, to conceptualize how the algorithms perform in real applications, we also investigated the agreement between each algorithm estimated group with the chart review group (reference) in terms of the patient characteristics and the results of survival analyses.
Statistical analysis
The descriptive analysis was performed to compare the characteristics (e.g. age, tumor characteristics, and treatment received) of the group of chart-review determined recurrent patients with that of the non-recurrent patients. These comparisons were also conducted between the chart review determined and the algorithm estimated recurrence cohort (Table 1). Using the T-test for the continuous variable (or Wilcoxon test when data was not normally distributed), and the Chi-squared or Fisher exact test for the categorical variables, we tested the differences between recurrent and non-recurrent patients. The similar comparison was conducted between the algorithm-estimated recurrent patients and non-recurrent patients (Table 1).
To assess the validity of the estimated date of recurrence, we compared the algorithm-estimated recurrence date with the real recurrence date (i.e. the chart review defined) for each patient. Similar with previous study [10,11,12], taking the difference between the estimated and real recurrence date, we then classified the absolute difference (in months) into the corresponding interval (e.g. 0–1, 1–2, 2–3, 3–6, or > 6 months) and constructed a frequency table to examine the agreement between the estimated and real recurrence date. In addition, using the recurrence date and primary surgery date we calculated the length or RFS then compared the estimated with the real length of RFS using Wilcoxon test given the skewed distribution of the length of RFS.
To further assess the agreement of the survival analysis between the algorithm-estimated and the real recurrence and timing, we created Kaplan-Meyer (K-M) curves of RFS using the algorithm-estimated and the chart review data accordingly. In addition, separate Cox regressions (modeling recurrence-free survival) were performed to compare the hazard ratio and the p-value of each independent variable between the estimated data and chart review data.
All analyses were made using SAS 9.4 (SAS Institute Inc., Cary, NC). The statistical significance was set at 5% level (two-sided).
Results
A total of 598 patients with stage 0 to III breast cancer were included and analyzed in our study. The entire cohort was composed of 282 (47.2%) young patients (less than 41 years) and 316 (52.8%) neoadjuvant chemotherapy patients. Among these patients, breast cancer recurred for 121 (20.2%) patients during a median follow-up of 4 (Interquartile Ratio (IQR) 3–5) years. The univariate analysis showed statistically significant differences between recurrent and non-recurrent patients in stage of tumor, tumor grade, human epidermal growth factor receptor-2 (HER2) status, surgery type (e.g. breast-conserving surgery (BCS), mastectomy), cancer specific death and overall death. On the contrary, tumor characteristics such as histology subtype and hormone receptor (HR) status, and patient/treatment characteristics such as age, adjuvant therapies, and follow-up length were not significantly different between recurrent and non-recurrent patients. All the three algorithm-estimated recurrence cohorts were similar to the chart review determined recurrence cohort in terms of the patient, tumor and treatment characteristics, except for the tumor grade (Table 1).
As shown in Table 2, the majority of the algorithm-estimated recurrence dates fell within 3 months of the corresponding chart review determined recurrence dates. Specifically, the proportions of patients with the difference between the algorithm-estimated and chart review date of recurrence among the 121 recurrent patients falling within 3 months were 71.1% (86) for high sensitivity algorithm, 60.3% (73) for high PPV algorithm, and 64.5% (78) for high accuracy algorithm, respectively. The Wilcoxon test showed that there was no significant difference between the chart review and algorithm-estimated length of RFS, the p-value was 0.205 for high sensitivity algorithms (vs. chart review), 0.608 for high PPV algorithms, 0.429 for high-accuracy algorithm, respectively. In addition, when only considering the 121 recurrent (determined by chart review) patients, there was also no significant difference between the algorithm-estimated and chart review determined length of RFS.
There was also high agreement between the estimated and chart review generated K-M curves (Fig.1). There were no significant differences in 5-year RFS between the chart review (76.7, 95% CI: 74.7–78.8 months) and algorithm-estimated data with 72.4 (70.3–74.5) months for the high sensitivity algorithm, 79.8 (77.8–81.8) months for the high PPV algorithm, and 77.0 (75.0–79.0) months for the high accuracy algorithm. Beyond 5 years, slight divergence between algorithm-estimated and chart review K-M curves was observed, which was more apparent in the comparison between the high PPV algorithm and Chart-review curves. For the chart-review data, 477 (79.8%) patients were censored, of which there were 92 all-cause deaths (including 76 cancer-caused deaths). The number of censored patients was 482 (80.6%), 454 (75.9%), and 499 (83.4%), for the high-accuracy, high-sensitivity, and high-PPV algorithm, respectively.

The comparison between estimated and chart review derived K-M curves for RFS. A shows the comparison of K-M curves between the high sensitivity algorithm estimated and chart review data with logrank p-value = 0.117; B shows the comparison of K-M curves between the high PPV algorithm estimated and chart review data with logrank p-value = 0.111; C shows the comparison of K-M curves between the high accuracy algorithm estimated and chart review data with logrank p-value = 0.729
The results of Cox regression of RFS (Table 3) showed high similarities between the estimated and chart review data in terms of the hazard ratio and the p-value of the independent variables. For the majority of the independent variables (e.g. age, year of diagnosis, HR status, HER2 status tumor grade, stage of tumor, histology, chemotherapy), the hazard ratio was consistent between chart review and algorithm-estimated data. Specifically, the hazard ratios with value of > 1.0 in the chart review data was still > 1.0 in the algorithm-estimated data, and the hazard ratios with value of < 1.0 in the chart review data remained < 1.0 in the algorithm-estimated data, except for ‘hormone therapy’ and ‘radiotherapy’ (both had a 95% CI crossing 1.0).
In addition, most of the corresponding p-values of the hazard ratios of the variables were consistent between the chart review data and the algorithm-estimated data (Table 3). Except for the high-sensitivity algorithm-estimated ‘chemotherapy’, all the statistically significant (P < 0.05) hazard ratios derived from chart review data remained significant in algorithm-estimated data, and all statistically non-significant hazard ratios remained non-significant.
Discussion
In the present study, we established new methods to identify the length of RFS of breast cancer patients using population-based real-world health data from a universal single-payer health system. Compared with the reference (chart review) data, the length of RFS determined by the developed algorithms achieved similar results, with the majority of the algorithm-estimated recurrence dates falling within 3 months of the real (i.e. chart review) recurrence dates. Moreover, the survival analyses created by both algorithm-estimated and chart review data showed high levels of correlation. This provides us with confidence to apply the developed algorithms in real RFS analyses. The developed methods have the potential to facilitate numerous down-stream research such as healthcare quality assessment, treatment efficacy comparisons, and decision-making support for patients with breast cancer. The method also provides a framework for constructing similar algorithms for identifying RFS of other cancers.
Previous studies [4,5,6,7,8,9,10,11,12] attempting to identify breast cancer recurrence and timing of recurrence vary by method and data used. The majority of these studies focused on identifying the recurrence status but not the timing of cancer recurrence. A few studies [5, 10,11,12] addressed the issue of determining the timing of recurrence by applying a prediction-model based methodology which incorporates a list of recurrence indicator variables to assign a probability of recurrence to each patient, then set a cutoff for the probability to classify recurrence vs. non-recurrence. Ritzwoller et al. [10] developed recurrence identification algorithms based on multivariable logistic regression models using data derived from several distinct but integrated health care delivery settings in the U.S., and reported 60–70% estimated dates of recurrence falling within ± 6 months of the true date of recurrence. This result is lower than in our study which found 80% of estimated dates falling within 6 months of chart review recurrence dates. Chubak et al. [5] developed a set of rule-based recurrence identification algorithms for breast cancer based on the Surveillance, Epidemiology and End Results (SEER) program cancer registry data and claims data, and reported a higher accuracy in terms of the date of recurrence estimation with 80% within ± 60 days of true recurrence date. One Danish study conducted by Rasmussen et al. developed rule-based algorithms based on the data from four Danish national registries. The authors reported better performed algorithms than the U.S. studies, but the superior performance that the author explained can be attributed to the inclusion of pathology codes and dates which is relatively specific to their data and not applicable in our population-based datasets.
Instead of developing new algorithms, we intended to validate the previously developed United States algorithms; however, a number of key differences in data impeded their application in our data. In addition to the United States specific coding systems including the Current Procedural Terminology (CPT) and Healthcare Common Procedure Coding System (HCPCS), one extremely contributable variable in the developed United States algorithms was the ‘second malignant diagnosis codes/records’ which was limited or not used in our data. In our data a ‘breast cancer diagnosis code’ (which is the same as the primary instance of cancer) was more commonly used instead of a ‘secondary malignant breast cancer code’ if the patient was previously diagnosed with breast cancer. Therefore, the inherent ability to identify cancer recurrence directly is not possible in most Canadian population-based datasets. Therefore, we decided to develop new algorithms to address this issue and others that have hindered analysis with these datasets previously.
Generally, the K-M curves generated using chart review and algorithm estimated data were very similar. While before 5-year follow-up, the high-accuracy algorithm generated K-M curve was highly consistent with that of chart-review, a slightly higher RFS rate was observed in the high-accuracy algorithm curve after 5-years follow-up. This may be due to that the high-accuracy algorithm estimated a delayed recurrence date for some patients, or missed some patients who had a recurrence after 5-year follow-up. This also explains the higher RFS in the high-PPV algorithm K-M curve than that of chart-review curve, given that high-PPV algorithm tended to miss recurrence to ensure the high PPV. Conversely, to ensure high sensitivity, the high-sensitivity algorithm tended to identify more false recurrent cases at the early years of follow-up, thus, a lower RFS rate was observed as compared to chart review K-M curve.
In addition to directly comparing the estimated RFS and chart review RFS, we also conducted comparisons between them by assessing the similarities in survival analyses between the estimated RFS and chart review RFS. Because the main application of the developed algorithm is enabling the RFS analysis, our comparison results demonstrated that the high accuracy algorithm and high PPV algorithm-estimated RFS data were reliable data for RFS analysis given that all the hazard ratios of independent variables were consistent with that of the chart review data. Worthy to note, only one variable’s hazard ratio (chemotherapy) based on the high sensitivity algorithm was not consistent with the chart review. The potential reason for this may be due to the fact that the majority (91.5%) of the patients had chemotherapy and only 10 patients had no chemotherapy among the patients with recurrence. Thus, a subtle misclassification of the algorithm can lead to a disproportional change between the recurrent and non-recurrent groups in terms of the number of patients undergoing chemotherapy, and then produced a high impact on the hazard ratio of chemotherapy. In the utility of RFS analysis, we recommend the high-accuracy algorithm which demonstrated the most similar results with that of the chart review data.
There were several limitations in our study which need to be considered. First, we used data from two previously chart reviewed cohorts who were deemed to have a high risk of breast cancer recurrence. Since the proposed algorithms were not validated in a random sample of our overall breast cancer population, we cannot guarantee that the proposed algorithm performances will be similar for other breast cancer cohorts. However, the pattern of medical encounter of the recurrent breast cancer patients in our cohort is generalizable to other breast cancer patient cohorts, thus the developed algorithms should be applicable to other breast cancer cohorts. Second, the proposed algorithms were not designed to differentiate between second primary breast cancer and breast cancer recurrence. Therefore, some of the recurrences identified by the proposed algorithm may have been second primary breast cancers. However, many cancer outcome studies consider both second primary breast cancer and breast cancer recurrence as the same event. Third, the proposed algorithm does not differentiate types of recurrence (e.g., non-invasive, local–regional, metastatic). Chart review would still be required if such information is needed; however, the algorithms will have significantly narrowed the task. Finally, the algorithms were only internally validated using our cohort. The performance of the algorithms is unclear when applied to external data. Thus, external validation using data from other provinces or nations with a universal health system is needed.
Conclusion
By using widely available real-world health data, the proposed algorithm attained similar results to that of chart review in identifying the timing of recurrence among breast cancer patients in a universal health system. Furthermore, the algorithm estimated data generated similar results of RFS analysis with the chart review. This implies that the developed algorithms have the potential to replace chart review in real population-based RFS analyses. Additional work on external validation is necessary in the future.
Previous presentations
Some preliminary results of the work have been presented at the 2019 Canadian Association of Health Services and Policy Research Annual Conference, Halifax, Canada; and the abstract was available online: https://cahspr.ca/wp-content/uploads/2020/11/Book-of-Abstracts-CAHSPR-2019.pdf.
Availability of data and materials
The datasets generated during and analyzed during the current study are available in this article and in the supplemental materials.
Abbreviations
- ACR:
-
Alberta Cancer Registry
- AHS:
-
Alberta Health Services
- BCS:
-
Breast-conserving Surgery
- CART:
-
Classification and Regression Tree
- CCCR:
-
Calgary Centre for Clinical Research
- CPT:
-
Current Procedural Terminology
- EMR:
-
Electronic Medical Record
- HER2:
-
Human Epidermal Growth Factor Receptor-2
- HR:
-
Hormone Receptor
- HCPCS:
-
Healthcare Common Procedure Coding System
- IQR:
-
Interquartile Ratio
- K-M:
-
Kaplan-Meyer
- PPV:
-
Positive Predictive Value
- RFS:
-
Recurrence-free Survival
- SEER:
-
Surveillance, Epidemiology and End Results
References
Government of Canada. “Public Health Agency of Canada - Breast Cancer.” https://www.canada.ca/en/public-health/services/chronic-diseases/cancer/breast-cancer.htm. Accessed 4 April. 2020.
Canadian Cancer Society. “Survival Statistics for Breast Cancer.” www.cancer.ca/en/cancer-information/cancer-type/breast/prognosis-and-survival/survival-statistics/?region=on. Accessed 4 Apr. 2020.
Warren JL, Yabroff KR. Challenges and opportunities in measuring cancer recurrence in the United States. J Natl Cancer Inst. 2015;107(8):djv134.
Chubak J, Yu O, Pocobelli G, et al. Administrative data algorithms to identify second breast cancer events following early-stage invasive breast cancer. J Natl Cancer Inst. 2012;104:931–40.
Chubak J, Onega T, Zhu W, Buist DSM, Hubbard RA. An Electronic Health Record-based Algorithm to Ascertain the Date of Second Breast Cancer Events. Med Care. 2017;55:e81–7.
Haque R, Shi J, Schottinger JE, et al. A hybrid approach to identify subsequent breast cancer using pathology and automated health information data. Med Care. 2015;53:380–5.
Carrell DS, Halgrim S, Tran DT, et al. Using natural language processing to improve efficiency of manual chart abstraction in research: the case of breast cancer recurrence. Am J Epidemiol. 2014;179:749–58.
Lamont EB, Herndon JE 2nd, Weeks JC, et al. Measuring disease-free survival and cancer relapse using Medicare claims from CALGB breast cancer trial participants (companion to 9344). J Natl Cancer Inst. 2006;98:1335–8.
Kroenke CH, Chubak J, Johnson L, Castillo A, Weltzien E, Caan BJ. Enhancing breast cancer recurrence algorithms through selective use of medical record data. J Natl Cancer Inst. 2016;108(3):djv336.
Ritzwoller DP, Hassett MJ, Uno H, et al. Development, validation, and dissemination of a breast cancer recurrence detection and timing informatics algorithm. J Natl Cancer Inst. 2018;110:273–81.
Aagaard Rasmussen L, Jensen H, Flytkjaer Virgilsen L, Jellesmark Thorsen LB, Vrou Offersen B, Vedsted P. A validated algorithm for register-based identification of patients with recurrence of breast cancer-Based on Danish Breast Cancer Group (DBCG) data. Cancer Epidemiol. 2019;59:129–34.
A’Mar T, Beatty JD, Fedorenko C, et al. Incorporating breast cancer recurrence events into population-based cancer registries using medical claims: cohort study. JMIR Cancer. 2020;6:e18143.
Xu Y, Kong S, Cheung WY, et al. Development and validation of case-finding algorithms for recurrence of breast cancer using routinely collected administrative data. BMC Cancer. 2019;19:210.
Quan ML, Austin J, Lam N, Quinn R. Diagnostic delay in young women with breast cancer: a population-based analysis. J Clin Oncol. 2014;32:92.
Graham PJ, Brar MS, Foster T, et al. Neoadjuvant chemotherapy for breast cancer, is practice changing? a population-based review of current surgical trends. Ann Surg Oncol. 2015;22:3376–82.
Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and regression trees. London: CRC Press; 1984.
LeBlanc MR. Combining estimates in regression and classification. J Am Stat Assoc. 1996;91:1641–50.
Acknowledgements
Not applicable.
Funding
The study is supported by the funding from Calgary Center for Clinical Research (CCCR). CCCR has no role in the design of the study and collection, analysis, and interpretation of data and in writing the manuscript should be declared.
Author information
Authors and Affiliations
Contributions
YX, HJ, MLQ, WYC, SL and ML contributed to the study design and conceptualization. YX, WYC, ML, HJ, SL and MLQ contributed to the development of the algorithms. YF, SK and YX analyzed the data. YX, SK, WYC, YF, ML, HJ, SL and MLQ interpreted the data. HJ and YX drafted the first version of the manuscript and all authors contributed to the revision and modification of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was approved by our local research ethics board: Health Research Ethics Board of Alberta—Cancer Committee (HREBA.CC-17–0183). Because this study only used the secondary data of patients, the consent to participate was not required by the ethics review committee.
Because this study only used the secondary data and limited information (i.e., the date of chemotherapy, radiotherapy, cancer center visit) from the backend dataset of cancer center electronic information system, which are structured data with patient identifications being removed before analyses. In addition, due to the retrospective nature of the study, our local research ethics board approved waiver of patient consent.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Table 1.
The codes used for defining the study variables
Additional file 2: Fig. 1.
The algorithm with high sensitivity for identifying recurrence of breast cancer
Additional file 3: Fig. 2.
The algorithm with high positive predictive value for identifying recurrence of breast cancer
Additional file 4: Fig. 3.
The algorithm with high overall accuracy for identifying recurrence of breast cancer
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Jung, H., Lu, M., Quan, M.L. et al. New method for determining breast cancer recurrence-free survival using routinely collected real-world health data. BMC Cancer 22, 281 (2022). https://doi.org/10.1186/s12885-022-09333-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12885-022-09333-6