
Abstract
Background
The purpose of the study was to use Machine Learning (ML) to construct a risk calculator for patients who undergo Total Joint Arthroplasty (TJA) on the basis of New York State Statewide Planning and Research Cooperative System (SPARCS) data and externally validate the calculator on a single TJA center.
Methods
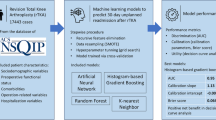
Seven ML algorithms, i.e., logistic regression, adaptive boosting, gradient boosting (Xg Boost), random forest (RF) classifier, support vector machine, and single and a five-layered neural network were trained on the derivation cohort. Models were trained on 68% of data, validated on 15%, tested on 15%, and externally validated on 2% of the data from a single arthroplasty center.
Results
Validation of the models showed that the RF classifier performed best in terms of 30-d mortality AUROC (Area Under the Receiver Operating Characteristic) 0.78, 30-d readmission (AUROC 0.61) and 90-d composite complications (AUROC 0.73) amongst the test set. Additionally, Xg Boost was found to be the best predicting model for 90-d readmission and 90-d composite complications (AUC 0.73). External validation demonstrated that models achieved similar AUROCs to the test set although variation occurred in top model performance for 90-d composite complications and readmissions between our test and external validation set.
Conclusion
This was the first study to investigate the use of ML to create a predictive risk calculator from state-wide data and then externally validate it with data from a single arthroplasty center. Discrimination between best performing ML models and between the test set and the external validation set are comparable.
Level of Evidence
III.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
Orthopaedic procedures involving total hip and knee replacement categorically account for the largest annual expenditures by Medicare by specialty and procedures, respectively [1,2,3]. Consequently, the Centers for Medicare and Medicaid Services (CMS) instituted the Comprehensive Care for Joint Replacement (CJR) model. CJR reduced costs and readmissions while potentially exacerbating disparities in the access to total joint arthroplasty (TJA) in some but not all centers [4,5,6]. The potential disparities in TJA access may have arisen, in part, due to an aversion to certain high-risk patient populations by some centers participating in the CJR model [7]. High-risk TJA patients are associated with increased resource demands, increased costs, and decreased reimbursement [8,9,10]. Therefore, the ability to identify patients who may be at a higher risk of poor outcomes following TJA may allow for resource reallocation to reduce this risk.
Artificial intelligence (AI) and machine learning (ML) algorithms can pattern the interactions of variables within datasets to create predictive models [11, 12]. Machine learning in medicine and orthopaedics has begun to take hold in the past five years, as manifested by publications specifically related to ML in TJA [13]. Successful creation of accurate preoperative risk calculators using ML algorithms would let providers preoperatively identify patients who may be at increased risk for poor outcomes following TJA. The ability to preoperatively predict increased risk would provide two potential opportunities. The first is the optimization of modifiable risk factors that may lower the cost of care [14]. The second is the ability to risk stratify reimbursement and reconcile current disparities in TJA access.
The performance of ML prediction models is directly proportional to the degree of data quality and quantity. Previous ML studies in TJA prediction models have been conducted using both “big” national databases and single center registries to predict outcomes, including discharge disposition, complications, mortality, satisfaction, and minimally important clinical differences following TJA [15,16,17,18]. While utilization of “big” databases provides ML algorithms access to the large patient volumes and variables necessary for ML algorithm training and model accuracy, these datasets present challenges. A specific challenge with “big” datasets is that variables, such as population diversity, changes in medical practice patterns, healthcare policy differences between states, and geographic data used to train the ML algorithms, create models that to date are of questionable clinical utility when applied to any specific patient. This point was highlighted by Harris et al., who concluded that “models previously developed with VASQIP (Veterans Affairs Surgical Quality Improvement Program) data had poor accuracy when externally validated with NSQIP (National Surgical Quality Improvement Program) data, suggesting that they should not be used outside the context of the Veterans Health Administration” [17]. Single center registries are a potential alternative to train ML algorithms using datasets that more closely represent the TJA patients who will prospectively undergo risk factor stratification with the trained model. While single-center registries overcome the limitations associated with “big” datasets, they may not contain the necessary patient volumes required to train ML algorithms, ultimately leading to models suffering from the same questionable clinical utility as those derived from “big” data. As a case in point, many authors do not achieve an AUROC > 0.8. and we are aware of only one attempt to externally validate a model [17].
Therefore, to overcome some of the limitations previously mentioned in both single center registries and many “big” datasets, we aimed to use the New York State (NYS) Statewide Planning and Research Cooperative System (SPARCS) all-payer administrative database to train ML models for 30- and 90-day readmissions and 90-day composite complications following TJA. For this particular study, the SPARCS dataset stands out as a superior resource among large healthcare datasets due to its comprehensive and consistent data collection methodology. Unlike other datasets that rely on random sampling or limited enrollment, SPARCS mandates that every healthcare facility (inpatient and outpatient) within NYS consistently contribute its data. This approach ensures the inclusion of the entirety of NYS’s healthcare landscape, a crucial factor for research and analysis conducted within the geographic region of our center [17]. One of the key strengths of SPARCS lies in its ability to capture the entire population. By encompassing data from all healthcare facilities in the state, it minimizes the risk of sampling bias that can be introduced by random sampling or enrollment-based datasets (e.g., a patient receiving surgery in hospital A is included in the database but is readmitted to hospital B not included in the database). The potential for substantial demographic differences across states is a concern often encountered when working with datasets that exclude certain hospitals or regions. NYS SPARCS effectively mitigates this concern, as it offers a comprehensive snapshot of the healthcare experiences and outcomes within the entire New York State population. Because SPARCS has coded individual hospitals within its all-payer dataset, we would identify and externally validate 90-day complications, 30-day mortality, and 30- & 90-day readmissions of our primary single arthroplasty center, against a model trained from SPARCS data. We hypothesized that externally validated models from our primary arthroplasty center (PAC) would demonstrate similar performance compared to internally validated models.
Methods
Data source
This study was a retrospective review of the NYS SPARCS database. Developed in 1979, the SPARCS database is a de-identified, all-payer, patient-specific database maintained by the NYS Department of Health. State legislature requires that all NYS hospitals, ambulatory surgery centers, emergency departments, outpatient hospital-extension clinics, as well as diagnostic and treatment centers should periodically report data to compile the extensive database. Information reported includes patient-level data on characteristics (e.g., demographics, BMI, etc.), diagnostic and surgical codes, services provided, charges incurred and hospital as well as provider identifiers. By assigning each patient a unique identifier, the database can provide reliable data with a high degree of continuity of an individual patient’s care across hospital systems statewide (e.g., readmissions). More information can be found at https://www.health.ny.gov/statistics/sparcs/.
Study population
Following approval by our Institutional Review Board, the SPARCS database was queried for all patients who underwent elective total hip or knee arthroplasty between 1 January 2012 and 31 December 2016. We used the Centers for Medicare and Medicaid Services (CMS) algorithm and ICD-9 and ICD-10 procedure codes for identifying the cohort of interest [18]. We employed ICD-9 and ICD-10 diagnosis and procedure codes specified by CMS to exclude patients undergoing joint replacements for fractures, revision/resurfacing/removal of implanted devices or prostheses, mechanical complications, malignant neoplasms, and partial hip replacements. The benefit of the SPARCS database is the comprehensive catchment of all cases performed in New York State regardless of payer. Additionally, each patient has a unique identifier allowing the patient to be tracked across hospital readmissions at different institutions within the state. Patient-level data were linked to the American Hospital Association (AHA) Annual Survey database to obtain hospital characteristics (community or teaching hospital, hospital size, urban/rural, geographic location, and hospital ownership) for inclusion in the models.
Explanatory variables/predictors
Baseline demographics were collected, including age, sex, race, ethnicity, zip code, anatomic site (hip or knee), hospital identifier, admission source, diagnosis code, discharge destination, payer source (Medicare versus commercial insurance), year of surgery, and method of anesthesia. Comorbidity indicators were defined using the Elixhauser’s Comorbidity Index (Table 1).
Outcomes
Primary outcomes of interest included 90-day complications, 30-day mortality, and 30- & 90-day all-cause readmissions following total hip and knee arthroplasty. Complications were defined by the following criteria: (1) acute myocardial infarction, pneumonia, or sepsis/septic shock occurring during the index admission or within a subsequent admission occurring within 7 days of the beginning of the index admission, (2) surgical site bleeding or pulmonary embolism during the index or subsequent admission taking place within 30 days of the start of the first admission (3) death during the index admission or within 30 days from index admission, (4) or mechanical complication, periprosthetic joint or surgical wound complication occurring within the index or subsequent admission occurring within 90 days from the start of the index admission.
Statistical analysis
The dataset encompassing data from 3 January 2012 and 30 September 2016 was subdivided randomly, without replacement, into training (68%) validation (15%) and testing (15%) data sets. Finally, for external validation, n = 6000 (2%) TJA patients were identified within the SPARCS database from our PAC, using the hospital identifier, between 3 January 2012 and 30 September 2016. Normalization of continuous variables and one-hot encoding of categorical variables was performed after exclusively assigning each observation to a data set. The seven ML algorithms included: logistic regression (LR), adaptive boosting (AB), gradient boosting (Xg Boost), random forest (RF) classifier, support vector machine (SVM), a 1-layer neural network (NN), and a 5-layered NN. For the training data, the negative outcome observations (e.g., did not have a readmission) were randomly assigned to subsets equal to the number of positive outcome observations. For each preparation instance, parameters were optimized using a 5-fold cross-validated grid-search method to reduce over-fitting and enhance the generalizability of each model instance (Fig. 1). Each classifier was then validated on raw data, and classifier weights were readjusted upon calibration. Model weights were then fixed for each classifier variable and tested on the remaining non-trained SPARCS data. Finally, we externally validated the models with patient information from our PAC.

The negative outcome observations (e.g., did not have readmission) were randomly assigned to subsets equal to the number of positive outcome observations to address low incidence rates and technical limitations. Each negative outcome subset was combined with the positive outcome observations and used to one model instance
Model evaluation
Discrimination refers to a model’s ability to distinguish between cases and non-cases and this is typically expressed in terms of accuracy, recall, precision, and AUROC. Accuracy is the number of correct model predictions and overall predictions [19]. The recall (sensitivity) of a model refers to its ability to correctly predict positive values out of the total number of all positive values (true positives and false negatives) in the dataset. The precision of a model measures the positive predictive value, essentially determining which outcomes are truly positive when compared against all predicted positives (true positives and false positives) [20]. The AUROC demonstrates the relationship between recall and the false positive rate (FPR). The FPR is defined as the number of incorrectly predicted positive outcomes overall outcomes that are actually negative (true negatives and false positives) [21, 22]. For a binary classification, such as a complication, each point’s location on the AUROC is found by assessing a variety of thresholds for sorting of yi in the positive or negative class. The top left corner of the curve is an ideal case with 100% of positive values correctly classified and 0% of positive values incorrectly predicted at 0. The goal for models, therefore, is to maximize the true positive rate while minimizing the FPR, the larger the area under the AUROC the better the model. Predictive modeling development and testing were performed under guidelines set forth by Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) guidelines and the Guidelines for Developing and Reporting Machine Learning Models in Biomedical Research were followed for this analysis [19, 20].
Results
Baseline characteristics
A total of 247,875 patients were included in the cohort. The average age of the group was 65.4 ± 10.7 years and 60% of patients were female (Table 1). The complications included pulmonary embolism (0.56%), mechanical complication (0.49%) and pneumonia (0.39%) (Table 2). In reference to the entirety of the data set, 168,555 (68.0%) were segmented for training, 37,182 (15.0%) for validation and calibration, 37,182 (15.0%) for testing, and 6000 (2.00%) patients were included in the external validation set from our PAC.
Data balancing
The incidence rates of our test set for 90-day composite complications, 30-day mortality, and 30- & 90-day readmission, were 1.88%, 0.10%, 3.07%, and 5.15%, respectively. These rates were nearly identical for the training, validation and test set out to the hundredth decimal point. As for our PAC, the percentages for 90-day composite complications, and 30-day mortality, 30- & 90-day readmission were 1.33%, 0.13%, 2.94%, and 0.41% respectively. The negative outcome observations (e.g., did not have readmission) were randomly assigned to subsets equal to the number of positive outcome observations to address low incidence rates and technical limitations. Each negative outcome subset was combined with the positive outcome observations and used to one model instance.
Testing data
After training and validating the models (Tables 3 and 4), testing on the untrained data (Table 5) showed RF classifier established the highest level of discrimination for 90-day complications (AUROC 0.73, 95CI 0.73–0.74), 30-day mortality (AUROC 0.78; 95CI 0.77–0.78), and 30-day readmission (AUROC 0.61; 95CI 0.60–0.61). Xg Boost demonstrated the best performance for 90-day hospital readmission (AUROC 0.73; 95CI 0.72–0.73).
External validation
External validation of model performance at our primary arthroplasty center showed the Adaptive Boost had the greatest performance for 90-day composite complications (AUROC 0.69; 95CI 0.68–0.69) (Table 6). Random Forest classifier was best at predicting 30-day mortality (AUROC 0.72; 95CI 0.72–0.73) and 30-day readmission (AUROC 0.68; 95 CI 0.67–0.68). Additionally, the Adaptive Boost classifier was the strongest model for the prediction of 90-day readmission (AUROC 0.72; 95 CI 0.72–0.73).
Explanatory variables
Feature importance was assessed for the top 3 variables that contributed the strongest weight to the top-performing model. Model predictors for 30-day mortality were found to be consistent between the test and external validation set demonstrating patient age, diseases of the circulatory system, and length of hospitalization to be the most important attributes for the RF classifier. Additionally, the prediction of 30-day readmission found that age, length of hospital stay, and the Elixhauser Comorbidity Index were the strongest contributors for the random forest classifier for models in both subsets.
As there was a discrepancy between classifier performance for 90-day composite complications and 90-day readmissions between the test and external validation, both model aspects were described. For composite complications and 90-day readmissions, our test set demonstrated that RF classifier performed best, with hospital stay, patient age, and Elixhauser Comorbidity Index being the top features for both outcomes. However, upon external validation, the Adaptive Boost classifier had the strongest discriminative performance for 90-day-composite complications and readmission, with age, surgical blood loss, and hospital length of stay being the top predictors for model output.
Discussion
The purpose of this study was to leverage the benefits of a relatively large and accurate SPARCS dataset to train ML models capable of achieving good discrimination (AUROC > 0.80) on an externally validated dataset representing our PAC. Specifically, our outcomes focused on 90-day complications, 30-day mortality, and 30- & 90-day readmissions. If successful, the study would demonstrate the ability to use “big” data to effectively predict single hospital system-level complications, mortality, and readmissions. This would not only benefit our hospital system but also other hospital systems in NYS. While the results showed that no ML model achieved an AUROC > 0.80, overall model performance was on par with similar studies and model performance doesn’t discredit relevant findings. Our results showed that the RF classifier had the strongest discriminative performance for 30-day mortality (AUROC = 0.72) and readmissions (30-day AUROC = 0.68) on our external validation set. For 90-day composite complication and 90-day readmissions, the Adaptive Boost classifier was the best predictor in our external validation set (AUROC = 0.69 and 0.72, respectively). While no ML model in the testing dataset achieved an AUROC > 0.78, the drop in performance between the best-performing ML model in the testing dataset and best-performing model in the external validation dataset was no more than 0.06 points on an AUROC. This finding is important as it speaks to the potential generalizability of the SPARCS dataset to any arthroplasty center located within NYS. To the best of our knowledge, this study represents the most rigorous ML analysis of the SPARCS database for potential use in TJA care.
Mohammed et al. used the National Inpatient Service (NIS) administrative database to internally validate four ML algorithms (LR, Xg Boost, RF classifier, and NN) to perform predictive modeling for discharge disposition, composite post-surgical complications, and the need for blood transfusion after TJA [16]. The group found that the Xg Boost was capable of predicting outcomes, with an AUROC of 0.80–0.87. While an impressive proof of concept, the lack of external validation of their NIS model leaves questions about the potential clinical utility of the NIS dataset at any given arthroplasty center. The NIS, although advantageous due to its quantity of data, was created to assess national trends and correlation and not to be used to potentially direct care at a statewide level. The database randomly samples 20% of hospitals nationwide, thus potentially leading to significant unintended bias as to where information is collected [21, 23]. Furthermore, there are no weights or classifiers applied to each state to account for the difference in the number of metrics collected [22]. Devana et al. investigated the use of the California Office of Statewide Health Planning and Development state dataset (OSHPD) to train and test ML algorithms to predict complications following TKA [24]. The group trained ML models (LR, Xg Boost, Adaptive Boost, RF classifier, and ensemble) on 156,750 TKA patients and demonstrated that Adaptive Boost had the best discriminative performance with an AUROC of 0.68, being congruent to the findings of our external validation model. It is important to note that both studies, by Mohammed et al. and Devana et al., relied on internal validation of their respective datasets. Therefore, while the results of these studies provide valuable insights into the potential predictive capabilities of ML algorithms for TJA outcomes, external validation on diverse datasets is essential to the establishment of the reliability and applicability of these models in real-world clinical settings. External validation helps mitigate the concerns of dataset-specific biases and increases confidence in the generalizability of the findings, thus enhancing the overall clinical utility of the developed models.
Several studies have assessed differences in the model prediction of neural networks in comparison to more traditional ML algorithms [25, 26]. They tried to answer the question: “Would these more complex ML algorithms outperform their less advanced counterparts”. However, most of these studies failed to incorporate crucial detail as to the layer of models used in their neural network. In fact, few studies have assessed whether a neural network with an increased number of hidden layers would improve model performance [27, 28]. A neural network at its most basic form has just one layer of inputs, one layer of active units, and one layer of outputs. The outputs do not interact, so a network with “n” outputs can be treated as “n” separate single-output networks. Therefore, a single-layer neural network can only be used to represent linearly separable functions. However, multi-layer networks can learn to develop interconnections and unforeseen associations around examples in some high-dimensional space that can separate and classify them, thereby overcoming the limitation of linear separability. Our study found that the 1- and 5-layer neural networks were nearly identical in their performance regarding AUROC and were inferior to the other models when predicting the TJA outcomes of interest. The reasons for decreased performance of our NN are not entirely clear but it does provide evidence that highly complex ML algorithms do not necessarily confer improved performance in the SPARCS dataset. Total joint arthroplasty has witnessed a notable shift towards value-based care, which emphasizes the delivery of high-quality, cost-effective, and patient-centered healthcare [10, 28]. This shift has been driven by the need to improve patient outcomes, control healthcare costs, and enhance overall value in the TJA field. Risk calculators through ML algorithms may accurately predict factors that may pose a higher risk for poor outcomes following TJA. These calculators have the potential to be utilized through a spectrum of preoperative care to the point of discharge from the site of surgical service. However, it is important to validate these models externally to assess their generalizability to other healthcare centers. Therefore, future studies in machine learning should prioritize external validation of ML models to ensure their reliability and effectiveness. One of the primary goals of this study was to ensure external validation of the models which is frequently missing in orthopaedic literature assessing ML model performance. The failure of external validation of such models may lead to misleading conclusions. For example, our results showed a discrepancy in model performance between the test and external validation sets. Xg Boost was the best performing model for predicting 90-day readmission in our test set, while the AB model performed better for our PAC data. Given the implications of wrong predictions in patient care, there must be continued emphasis on external validation for future AI-based investigations.
This study is not without limitations and the limitations are primarily present in the dataset. SPARCS does have the limitation of being a payor-based dataset which, to some extent, limits the validity of the clinical markers (e.g., identification of acute and chronic conditions). However, one needs to trade that off with its many strengths as previously mentioned. Another possible limitation may be due to the possible unique separation in population demographics of New York City when compared to the rest of NYS. As such, risk calculators created by SPARCS-trained data may not execute consistently on a PAC center. Further research should be conducted to identify the predictive value that ML can have on assessing TJA in New York City patients when trained with an NYS statewide dataset. Finally, the SPARCS dataset included the years 2012 through 2016, which contained the evolution of practice pattern changes driven by the CJR model and other bundled payments. These bundle payments are known to be associated with decreased complications and readmissions. Future studies with more recent data may affect future model performance and conclusions.
Conclusions
This study was the first to investigate the use of ML to create a predictive risk calculator from a highly validated statewide database and externally validate it to a single PAC within the same geographic region. All models showed low to moderate discrimination on an AUROC, which is consistent with recent model performance in the TJA literature. However, this study included external validation performance which is lacking in many prior studies. Furthermore, the external validation performance was of moderate discrimination on an AUROC. More advanced NN models did not perform better than less sophisticated ML models. The importance of detailing the dataset, model construction, and model validation cannot be overstated. The unique composition of New York City and its subsequent influence on future ML risk calculators created through SPARCS is a potential area of investigation.
Availability of data and materials
Our application to acquire NYS SPARCS data does not allow sharing of data to those outside of the IRB.
References
Singh JA, et al. Rates of total joint replacement in the United States: Future projections to 2020–2040 using the national inpatient sample. J Rheumatol. 2019;46(9):1134–40.
Mayfield CK, et al. Medicare reimbursement for hip and knee arthroplasty from 2000 to 2019: an unsustainable trend. J Arthroplasty. 2020;35(5):1174–8.
Kaye DR, et al. Understanding the costs associated with surgical care delivery in the Medicare population. Ann Surg. 2020;271(1):23–8.
Thirukumaran CP, et al. Association of the comprehensive care for joint replacement model with disparities in the use of total hip and total knee replacement. JAMA Netw Open. 2021;4(5):e2111858.
Ko H, et al. Patient selection in the comprehensive care for joint replacement model. Health Serv Res. 2022;57(1):72–90.
Plate JF, et al. No changes in patient selection and value-based metrics for total hip arthroplasty after comprehensive care for joint replacement bundle implementation at a single center. J Arthroplasty. 2019;34(8):1581–4.
Yates AJ Jr, et al. Perception of risk: a poll of American Association of hip and knee surgeons members. J Arthroplasty. 2021;36(5):1471–7.
Grobaty L, Lajam C, Hutzler L. Impact of value-based reimbursement on health-care disparities for total joint arthroplasty candidates. JBJS Rev. 2020;8(11):e2000073.
Rosas SS, et al. Dually insured medicare/medicaid patients undergoing primary TJA have more comorbidities, higher complication rates, and lower reimbursements compared to privately insured patients. J Arthroplasty. 2022;37(8S):S748–52.
Cairns MA, et al. Are Medicare’s “comprehensive care for joint replacement” bundled payments stratifying risk adequately? J Arthroplasty. 2018;33(9):2722–7.
Davenport T, Kalakota R. The potential for artificial intelligence in healthcare. Future Healthc J. 2019;6(2):94–8.
Myers TG, et al. Artificial intelligence and orthopaedics: an introduction for clinicians. J Bone Joint Surg Am. 2020;102(9):830–40.
Alsoof D, et al. Machine learning for the orthopaedic surgeon: uses and limitations. J Bone Joint Surg Am. 2022;104(17):1586–94.
Johns WL, et al. Preoperative risk factor screening protocols in total joint arthroplasty: a systematic review. J Arthroplasty. 2020;35(11):3353–63.
Abraham VM, et al. Machine-learning models predict 30-day mortality, cardiovascular complications, and respiratory complications after aseptic revision total joint arthroplasty. Clin Orthop Relat Res. 2022;480(11):2137–45.
Mohammed H, et al. Utilization of machine learning methods for predicting surgical outcomes after total knee arthroplasty. PLoS One. 2022;17(3):e0263897.
Harris AHS, et al. Can machine learning methods produce accurate and easy-to-use prediction models of 30-day complications and mortality after knee or hip arthroplasty? Clin Orthop Relat Res. 2019;477(2):452–60.
Fontana MA, et al. Can machine learning algorithms predict which patients will achieve minimally clinically important differences from total joint arthroplasty? Clin Orthop Relat Res. 2019;477(6):1267–79.
Luo W, et al. Guidelines for developing and reporting machine learning predictive models in biomedical research: a multidisciplinary View. J Med Internet Res. 2016;18(12):e323.
Collins GS, et al. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): the TRIPOD statement. Br J Surg. 2015;102(3):148–58.
Khera R, Krumholz HM. With great power comes great responsibility: big data research from the national inpatient sample. Circ Cardiovasc Qual Outcomes. 2017;10(7):e003846.
Kaulfus A, et al. The inherent challenges of using large data sets in healthcare research: experiences of an interdisciplinary team. Comput Inform Nurs. 2017;35(5):221–5.
McClelland S 3rd, et al. Limitations of using population-based databases to assess trends in spinal stereotactic radiosurgery. J Radiosurg SBRT. 2016;4(3):177–80.
Devana SK, et al. A novel, potentially universal machine learning algorithm to predict complications in total knee arthroplasty. Arthroplast Today. 2021;10:135–43.
Kunze KN, et al. Development of machine learning algorithms to predict patient dissatisfaction after primary total knee arthroplasty. J Arthroplasty. 2020;35(11):3117–22.
El-Galaly A, et al. Can machine-learning algorithms predict early revision TKA in the Danish knee arthroplasty registry? Clin Orthop Relat Res. 2020;478(9):2088–101.
Navarro SM, et al. Machine learning and primary total knee arthroplasty: patient forecasting for a patient-specific payment model. J Arthroplasty. 2018;33(12):3617–23.
Ramkumar PN, et al. Development and validation of a machine learning algorithm after primary total hip arthroplasty: applications to length of stay and payment models. J Arthroplasty. 2019;34(4):632–7.
Acknowledgements
Not applicable.
NYS SPARCS Disclaimer
This publication was produced from raw data purchased from or provided by the New York State Department of Health (NYSDOH). However, the conclusions derived, and views expressed herein are those of the author(s) and do not reflect the conclusions or views of NYSDOH. NYSDOH, its employees, officers, and agents make no representation, warranty, or guarantee as to the accuracy, completeness, currency, or suitability of the information provided here.
Funding
No funding to declare.
Author information
Authors and Affiliations
Contributions
H.J.F.S.: writing and editing, conception, M.B.: writing and editing, G.R.: statistical analysis, writing and editing, C.P.T.: statistical analysis, data curation, B.R: writing and editing, T.G.M.: conception, writing and editing. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Institutional Review Board Approval was received by the University of Rochester Institutional Review Board and was deemed exempt from receiving study participant approval given the retrospective nature and de-identification of data collection provided by the New York Statewide Planning and Research Cooperative System.
Consent for publication
As data within NYS SPARCS are deidentified, study participant consent for study approval was not needed as deemed by the IRB.
Competing interests
No conflict of interests to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shaikh, H.J.F., Botros, M., Ramirez, G. et al. Comparable performance of machine learning algorithms in predicting readmission and complications following total joint arthroplasty with external validation. Arthroplasty 5, 58 (2023). https://doi.org/10.1186/s42836-023-00208-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42836-023-00208-0