
Abstract
We study the asymptotic behaviour of a gradient system in a regime in which the driving energy becomes singular. For this system gradient-system convergence concepts are ineffective. We characterize the limiting behaviour in a different way, by proving \(\Gamma \)-convergence of the so-called energy-dissipation functional, which combines the gradient-system components of energy and dissipation in a single functional. The \(\Gamma \)-limit of these functionals again characterizes a variational evolution, but this limit functional is not the energy-dissipation functional of any gradient system. The system in question describes the diffusion of a particle in a one-dimensional double-well energy landscape, in the limit of small noise. The wells have different depth, and in the small-noise limit the process converges to a Markov process on a two-state system, in which jumps only happen from the higher to the lower well. This transmutation of a gradient system into a variational evolution of non-gradient type is a model for how many one-directional chemical reactions emerge as limit of reversible ones. The \(\Gamma \)-convergence proved in this paper both identifies the ‘fate’ of the gradient system for these reactions and the variational structure of the limiting irreversible reactions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Diffusion in an asymmetric potential landscape
Our interest in this paper is the limit \(\varepsilon \rightarrow 0\) in the family of Fokker–Planck equations in one dimension defined by
Here we take an asymmetric double-well potential \(V:{\mathbb {R}}\rightarrow {\mathbb {R}}\) as depicted in Fig. 1.

A typical asymmetric potential V(x)
A typical solution \(\rho _\varepsilon (t,x)\) is displayed in Fig. 2, showing mass flowing from left to right. There are two parameters, \(\varepsilon >0\) and \(\tau _\varepsilon >0\). The first parameter \(\varepsilon \) controls how fast mass can move between the potential wells, where smaller values of \(\varepsilon \) correspond to larger transition times. The second parameter \(\tau _\varepsilon \) sets the global time scale, and is chosen such that typical transition times from the local minimum \(x_a\) to the global minimum \(x_b\) are of order one as \(\varepsilon \rightarrow 0\) (see Eq. (3) below).

The time evolution of a solution \(\rho _\varepsilon (t,x)\) to (1) whose initial distribution is supported on the left. Time increases from left to right. At the final time, the solution is close to the equilibrium distribution, which is proportional to \(\exp \{-V(x)/\varepsilon \}\). The smaller the value of \(\varepsilon \), the sharper the equilibrium distribution concentrates around the global minimum \(x_b\)
The small-\(\varepsilon \) limit in the PDE (1) is known as the high activation energy limit in the context of chemical reactions. In this setting, the PDE can be derived from the stochastic evolution of a chemical system, modelled by a one-dimensional diffusion process \(Y^\varepsilon _t = Y^\varepsilon (t)\) in \({\mathbb {R}}\), satisfying
where \(B_t\) is a standard Brownian motion. For example, consider a particle starting in the left minimum \(x_a\) and propagating from left to right. This propagation models a reaction event in which a molecule’s state changes from a low-energy state \(x_a\) via a high-energy state \(x_0\) to another low-energy state \(x_b\). The assumption of asymmetry of the potential V corresponds to modelling a reaction in which the final energy is lower than the initial energy. The energy barrier that the particle has to overcome, \(V(x_0)-V(x_a)\), is the activation energy of the reaction.
Hendrik Antony Kramers was the first to translate the question of determining the rate of a chemical reaction into properties of PDEs such as (1) [20, 21]. Decreasing \(\varepsilon \) reduces the noise level in comparison to the potential energy barrier, and a transition from \(x_a\) to \(x_b\) becomes more unlikely, and hence the average time until a transition \(x_a\rightsquigarrow x_b\) increases. Kramers derived an asymptotic expression for this average time:
which now is known as the Kramers formula. It shows that the average transition time scales exponentially with respect to the ratio of the energy barrier \(V(x_0)-V(x_a)\) to the diffusion coefficient \(\varepsilon \). For further details and background on this model, we refer to the monographs of Bovier and den Hollander [3], and of Berglund and Gentz [5].
We are interested in the limit \(\varepsilon \rightarrow 0\) in the Eq. (1). In this limit we expect the solution \(\rho _\varepsilon \) to concentrate at the minima \(x_a\) and \(x_b\). Furthermore, transitions from left to right face a lower energy barrier than from right to left, and because of the exponential scaling in the energy barrier in (2), we expect that in the limit \(\varepsilon \rightarrow 0\) transitions occur much more often from left to right than from right to left.
Since we want to follow left-to-right transitions, we choose the global time-scale parameter \(\tau _\varepsilon \) approximately equal to the left-to-right transition time:
Speeding up the process \(Y^\varepsilon (t)\) by \(\tau _\varepsilon \) as \(X^\varepsilon (t):= Y^\varepsilon (\tau _\varepsilon t)\), the accelerated process \(X^\varepsilon \) satisfies the SDE
and the Eq. (1) is the Fokker-Planck equation for the transition probabilities \(\rho _\varepsilon (t,\mathrm {d}x) := {\mathbb {P}}\left( X^\varepsilon _t \in \mathrm {d}x\right) \).
In the rescaled Eq. (1) we therefore expect the limiting dynamics to be characterized by mass being transferred at rate one from the local minimum \(x_a\) to the global minimum \(x_b\), and to see no mass move in the opposite direction. In terms of the solution \(\rho _\varepsilon \), we expect that
where the density \(z=z(t)\) of particles at \(x_a\) satisfies \(\partial _t z = - z\), corresponding to left-to-right transitions happening at rate 1. The time evolution of the limiting density is depicted in Fig. 3.

The time evolution of \(\rho _0\), defined as the \(\varepsilon \rightarrow 0\) limit of the solution \(\rho _\varepsilon (t,x)\) to (1). The initial distribution is supported solely on the left. Mass flows only from left to right, with rate one
The main results of this paper imply the convergence (5), but they provide more information: they describe the fate of the gradient-system, variational-evolutionary structure satisfied by (1). We describe this next.
1.2 Gradient systems and convergence
Both the convergence of stochastic processes and the convergence of PDEs are classical problems, and the particular case of the small-noise or high-activation-energy limit is very well studied; see the monographs of Berglund–Gentz and Bovier–Den Hollander that we already mentioned for much more on this topic [3, 5].
In this paper, however, our main interest in the \(\varepsilon \rightarrow 0\) limit of Eq. (1) is the relation with convergence of gradient systems. One of the main points of this paper is that while the \(\varepsilon >0\) systems are of gradient type, there is no reasonable convergence that remains within the class of gradient systems. Instead we prove a convergence result to a more general variational evolution that is not of gradient type.
In this paper we focus on gradient systems in the space of probability measures on \({\mathbb {R}}\) with a continuity-equation structure. Eq. (1) is of this form; it can be written as the triplet of equations
For pairs \((\rho _\varepsilon ,j_\varepsilon )\) satisfying (6a), the second Eq. (6b) can formally be written as
in terms of the trivially nonnegative functional \({\mathcal {I}}_\varepsilon \),
By expanding the square in \({\mathcal {I}}_\varepsilon \) (see Lemma 2.2 for details) one finds the equivalent form of (7),
In (9a) the functional \(E_\varepsilon \) is given as
and \({\mathcal {H}}(\mu |\nu )\) is the relative entropy of \(\mu \) with respect to \(\nu \). The dual pair \((R_\varepsilon ,R_\varepsilon ^*)\) of dissipation potentials is formally defined as
The inequality (9a) is known as the EDP-formulation of the gradient system defined by \(E_\varepsilon \), \(R_\varepsilon \), and the continuity equation; see e.g. [1, 28, 32] for a general discussion of gradient systems, and [35] for a specific treatment of gradient systems with continuity-equation structure. The dissipation potential \(R_\varepsilon ^*\) in (9c) and its dual \(R_\varepsilon \) can be interpreted as infinitesimal versions of the Wasserstein metric, and for this reason system (6) or equivalently Eq. (1) is known as a Wasserstein gradient flow [1, 32, 39].
The EDP-formulation (9) can be used not only to define gradient-system solutions, but also to define convergence of a sequence of gradient systems to a limiting gradient system. Although this method will not be directly of use to us for the proofs in this paper, since the limiting system of this paper will not be of gradient-system type, we will use a number of elements of this method. In addition, it is useful to contrast the method of this paper with this convergence concept.
Definition 1.1
(EDP-convergence) A sequence \((E_\varepsilon ,R_\varepsilon )\) EDP-converges to a limiting gradient system \((E_0,R_0)\) if
-
1.
\(E_\varepsilon {\mathop {\longrightarrow }\limits ^{\Gamma }}E_0\),
-
2.
\({\mathcal {D}}_\varepsilon ^T {\mathop {\longrightarrow }\limits ^{\Gamma }}{\mathcal {D}}_0^T\) for all T, and
-
3.
the limit functional \({\mathcal {D}}_0^T\) can again be written in terms of the limiting functional \(E_0\) and a dissipation potential \(R_0\) as
$$\begin{aligned} {\mathcal {D}}_0^T(\rho ,j) = \int _0^T \bigl [R_0(\rho ,j) + R_0^*(\rho ,-\mathrm DE_0(\rho ))\bigr ]\, dt. \end{aligned}$$(10)
EDP-convergence implies convergence of solutions: If \((\rho _\varepsilon ,j_\varepsilon )\) is a sequence of solutions of (1) or equivalently of (9) that converges to a limit \((\rho _0,j_0)\), and if the initial state \(\rho _\varepsilon (0)\) satisfies the well-preparedness condition
then the limit \((\rho _0,j_0)\) is a solution of the gradient flow associated with \((E_0,R_0)\). See [28, 29] for an in-depth discussion of EDP-convergence.
1.3 (Non-)convergence as \(\varepsilon \rightarrow 0\) in the Kramers problem
For symmetric potentials V, EDP-convergence of the gradient systems \((E_\varepsilon ,R_\varepsilon )\) of (9b–9c) has been proved in [2, 24]. For non-symmetric potentials as in this paper, however, we claim that the sequence \((E_\varepsilon ,R_\varepsilon )\) can not converge in this sense, and we now explain this.
1. The functional \(E_\varepsilon \) blows up The first argument for non-convergence follows from the singular behaviour of the driving functional \(E_\varepsilon \). We can rewrite this functional as
Since the normalization constant \(Z_\varepsilon \) is chosen such that \(\gamma _\varepsilon \) has mass one, the term in parentheses converges to \(+\infty \) at all x except for the global minimizer \(x=x_b\) (this follows from Lemma 4.4). Therefore \(E_\varepsilon \) \(\Gamma \)-converges to the singular limit functional
This implies that if \(\rho _\varepsilon (0)\) retains any mass in the higher well around \(x_a\) as \(\varepsilon \rightarrow 0\), then \(E_\varepsilon (\rho _\varepsilon (0))\rightarrow \infty \). The ‘well-preparedness condition’ (11) therefore can only be satisfied in a trivial way, with the initial mass being ‘already’ in the lower of the two wells. Indeed, a gradient system driven by \(E_0\) admits only constants as solutions, and does not allow us to follow transitions from \(x_a\) to \(x_b\).
2. Other scalings of \(E_\varepsilon \) also fail One could mitigate the blow-up of \(E_\varepsilon \) by choosing a different scaling of \(E_\varepsilon \),
which \(\Gamma \)-converges to the functional \(\rho \mapsto \int \rho V\). With this scaling the well-preparedness condition (11) is simple to satisfy, and by general compactness arguments (e.g. [13, Ch. 10]) the correspondingly rescaled functionals \(\widetilde{\mathcal {D}}_\varepsilon ^T := \varepsilon {\mathcal {D}}_\varepsilon ^T\) also \(\Gamma \)-converge to a limit \(\widetilde{\mathcal {D}}_0^T\). However, this limit functional \(\widetilde{\mathcal {D}}_0^T\) fails to characterize an evolution; we prove this in Sect. 1.6.4 below. Other rescaling choices suffer from similar problems.
3. EDP-convergence should fail There also is a more abstract argument why EDP-convergence should fail, and in fact why any gradient-system convergence should fail. In the limit \(\varepsilon \rightarrow 0\) the ratio of forward to reverse transitions diverges, leading to a situation in which motion becomes one-directional. On the other hand, in gradient systems motion can be reversed by appropriate tilting of the driving functional. Therefore the one-directionality is incompatible with a gradient structure.
Note that the limiting equation itself, \(\dot{z} = -z\) (see Sect. 1.5), can be given a gradient structure, even many different gradient structures; one example is
Our claim here is the following: although the limiting equation can in fact be given a multitude of gradient structures, none of these structures can be found as the limit of the Wasserstein gradient structure of Eq. (1). The simplest proof of this statement is the \(\Gamma \)-convergence theorem that we prove in this paper (Theorem 1.3), which identifies the limit functional; this functional does not generate a gradient structure.
Summarizing, although for each \(\varepsilon >0\) the Eq. (1) is a Wasserstein gradient flow with components \(E_\varepsilon \) and \(R_\varepsilon \), these components diverge in the limit \(\varepsilon \rightarrow 0\), and only trivial gradient-system convergence is possible.
On the other hand, the functional \({\mathcal {I}}_\varepsilon \) combines the components \(E_\varepsilon \), \(R_\varepsilon \), and \(R_\varepsilon ^*\) in such a way that their divergences compensate each other; in the case of solutions of (1), \({\mathcal {I}}_\varepsilon \) even is zero for all \(\varepsilon \). This suggests that \({\mathcal {I}}_\varepsilon \) is a better candidate for a variational convergence analysis, and the rest of this paper is devoted to this. Indeed we find below that the limit of \({\mathcal {I}}_\varepsilon \) is not of gradient-flow structure, confirming the earlier suggestion that the sequence leaves the class of gradient systems.
Remark 1.2
In [36, 37] one of us developed convergence results for this same limit \(\varepsilon \rightarrow 0\) for the case of a symmetric potential V, using a functional framework based on \(L^2\)-spaces that are weighted with the invariant measure \(\gamma _\varepsilon \). This approach suffers from a similar problem as the Wasserstein-based approach above. The limiting state space is the space \(L^2\), weighted by the limiting invariant measure \(\delta _b\), which is a one-dimensional function space; in combination with the constraint of unit mass, the effective state space is a singleton. Consequently the limiting evolution would be trivial.
1.4 Main result—\(\Gamma \)-convergence of \({\mathcal {I}}_\varepsilon \)
In the previous section we introduced the functional \({\mathcal {I}}_\varepsilon \) of a pair \((\rho ,j)\) with the property that solutions of the Eq. (1) are minimizers of \({\mathcal {I}}_\varepsilon \) at value zero. As for gradient structures, we can therefore reformulate the question of convergence as \(\varepsilon \rightarrow 0\) in terms of \(\Gamma \)-convergence of these functionals. The main questions then are:
-
(i)
Compactness For a family of pairs \((\rho _\varepsilon ',j_\varepsilon ')\) depending on \(\varepsilon \), does boundedness of \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ',j_\varepsilon ')\) imply the existence of a subsequence of \((\rho _\varepsilon ',j_\varepsilon ')\) that converges in a certain topology \({\mathcal {T}}\)?
-
(ii)
Convergence along sequences Is there a limit functional \({\mathcal {I}}_0\) such that
$$\begin{aligned} \Gamma -\lim _{\varepsilon \rightarrow 0}{\mathcal {I}}_\varepsilon = {\mathcal {I}}_0\, ? \end{aligned}$$ -
(iii)
Limit equation Does the equation \({\mathcal {I}}_0(\rho ,j)=0\) characterize the evolution of \((\rho ,j)\)?
We answer the first question in Theorem 4.7, which establishes that sequences \((\rho _\varepsilon ',j_\varepsilon ')\) such that \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ',j_\varepsilon ')\) remains bounded are compact in a certain topology.
The second question is answered by Theorems 4.7 (liminf bound) and Theorem 5.4 (limsup bound), which together establish a limit of \({\mathcal {I}}_\varepsilon \) in the sense of \(\Gamma \)-convergence. Here, we give a short version that combines these theorems into one statement. For convenience we collect pairs \((\rho ,j)\) that satisfy the continuity Eq. (6a) in a set \({\mathrm {CE}}(0,T;{\mathbb {R}})\); convergence in this set is defined in a distributional sense (see Definitions 3.1 and 3.2 ). The following theorem summarizes Theorems 4.7 and 5.4 .
Theorem 1.3
(Main result) Let V satisfy Assumption 4.1. Then
-
1.
Sequences \((\rho _\varepsilon ,j_\varepsilon )\) for which there exists a constant C such that
$$\begin{aligned} {\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon ) \le C \qquad \text {and}\qquad E_\varepsilon (\rho _\varepsilon (0))\le \frac{C}{\varepsilon }\end{aligned}$$(13)are sequentially compact in \({\mathrm {CE}}(0,T)\);
-
2.
Along sequences \((\rho _\varepsilon ,j_\varepsilon )\) satisfying
 (14)
(14)the functional \({\mathcal {I}}_\varepsilon \) \(\Gamma \)-converges to a limit \({\mathcal {I}}_0\).

In the next section we define the limit functional \({\mathcal {I}}_0\) and show that it characterizes the limit evolution as \( z' = -z\).
Remark 1.4
The condition (14) can be interpreted as a well-preparedness property: it states that the initial datum converges to a measure of the same structure as the subsequent evolution (see (17a) below). The bound (13) on the initial energy provides a second type of control on the initial data.
1.5 The limiting functional \({\mathcal {I}}_0\)
Introduce the function \(S:{\mathbb {R}}^2 \rightarrow [0,\infty ]\),
The map \({\mathcal {I}}_0:{\mathrm {CE}}(0,T)\rightarrow [0,\infty ]\) is defined by
whenever
Otherwise, we set \({\mathcal {I}}_0(\rho ,j) = +\infty \).
Lemma 1.5
(See Lemma 4.11) If \({\mathcal {I}}_0(\rho ,j)<\infty \), then
-
1.
The function z in (17a) is absolutely continuous and non-increasing,
-
2.
The function j(t) in (17c) satisfies \(j(t) = -z'(t)\) for almost all t.
For all \((\rho ,j)\), \({\mathcal {I}}_0(\rho ,j)\ge 0\); if \({\mathcal {I}}_0(\rho ,j) =0\), then z satisfies \(z'(t) = -z(t)\) for all t.
The final part of this lemma allows us to characterize any limit of solutions \((\rho _\varepsilon ,j_\varepsilon )\) of (6). Such solutions satisfy \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon )=0\); therefore any limit \((\rho _0,j_0)\) along a subsequence \(\varepsilon _k\rightarrow 0\) satisfies
and therefore \(\rho _0\) has the structure (17a) and the corresponding function z satisfies \(z'=-z\). Since the limit is unique, in fact any sequence \((\rho _{\varepsilon _\ell },j_{\varepsilon _\ell })\) converges. The evolution of such a function \(\rho _0\) is depicted in Fig. 3.
Remark 1.6
(\({\mathcal {I}}_0\) does not define a gradient structure) While the limiting equation \(z'=-z\) has multiple gradient structures (see Sect. 1.3), the limiting functional \({\mathcal {I}}_0\) does not define any gradient structure. This example therefore is another illustration of how convergence of gradient structures is a stronger property than convergence of the equations (see [28] for more discussion on this topic).
To see that \({\mathcal {I}}_0\) does not define a gradient system, at least formally, assume for the moment that there exist \({{\mathsf {E}}}\) and \({{\mathsf {R}}}\) such that
By taking a short-time limit we deduce that
and by differentiating with respect to v we find
Part of the definition of a gradient system is the requirement that \({{\mathsf {R}}}(z,\cdot )\) is minimal at \(v=0\) for each z (see the discussion in [30, p. 1296]), and the expression for the derivative \(\mathrm D {{\mathsf {R}}}(z,v)\) above shows that this can not be the case. This mathematical argument backs up the more philosophical arguments in Sect. 1.3 that that \({\mathcal {I}}_0\) does not define a gradient system.
1.6 Discussion
1.6.1 Main conclusions
The main mathematical question in this paper is to understand the ‘fate’ of a gradient structure in a limit in which this gradient structure itself must break down. What we find can be summarized as follows:
-
1.
Although the energy \(E_\varepsilon \) and the dissipation potentials \(R_\varepsilon \) and \(R_\varepsilon ^*\) diverge, the single functional \({\mathcal {I}}_\varepsilon \) that captures the Energy-Dissipation-Principle persists;
-
2.
This functional \({\mathcal {I}}_\varepsilon \) provides sufficient control for a proof of compactness and \(\Gamma \)-convergence;
-
3.
The limiting functional \({\mathcal {I}}_0\) defines a ‘variational-evolution’ system, but not a gradient system;
-
4.
Both the EDP functional \({\mathcal {I}}_\varepsilon \) and its limit \({\mathcal {I}}_0\) have a clear connection to large deviations (see below).
Although the convergence proved in Theorem 1.3 is not a gradient-system convergence and the energies \(E_\varepsilon \) do not converge, we do use a small component of the typical gradient-system evolutionary-convergence proof. We need some control on the initial data; this is visible in the bound on \(E_\varepsilon \) in (13), which stipulates that \(E_\varepsilon (\rho _\varepsilon (t=0))\) is allowed to diverge, but not too fast. In fact, the requirement in the proof of Theorem 4.7 is that \(E_\varepsilon (\rho _\varepsilon (t=0))\) diverges more slowly than exponentially.
1.6.2 Connection to large-deviation principles
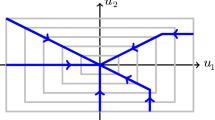
Both the pre-limit functionals \({\mathcal {I}}_\varepsilon \) and the limit functional \({\mathcal {I}}_0\) have a clear interpretation as large-deviation rate functions of stochastic processes. In addition, the main result of this paper makes the diagram in Fig. 4 into a commuting diagram. We now explain this.

The top row corresponds to the empirical flux-density pairs (19) stemming from i.i.d. copies of the reversible diffusion process \(X^\varepsilon _i(t)\) from (4), whose Fokker-Planck equation is (1). The bottom row corresponds similarly to a jump process defined on two states \(\{a,b\}\), with jumps only from a to b. We prove the right arrow by Theorem 1.3, and the left arrow also follows from this result. More explanation is given in the text
Let \(X_i^\varepsilon (t)\) be independent copies of the upscaled diffusion process satisfying (4), and define formally the empirical flux-density pair \((\rho _{\varepsilon ,n},j_{\varepsilon ,n})\) by
The functional \({\mathcal {I}}_\varepsilon \) characterizes the large deviations of \((\rho _{\varepsilon ,n},j_{\varepsilon ,n})\) in the limit \(n\rightarrow \infty \) for fixed \(\varepsilon \) [10, 16] (see also [4, (1.3) and (2.8)])
This is the top arrow in Fig. 4.
The limit functional \({\mathcal {I}}_0\), on the other hand, similarly characterizes the \(n\rightarrow \infty \) large deviations of flux-density pairs of n independent particles jumping between two points \(x_a\) and \(x_b\), with jump rates given by \(r_{a\rightarrow b}=1\) and \(r_{b\rightarrow a}=0\) (see e.g. [22, 38]). This is the bottom arrow in Fig. 4.
The right-hand arrow in Fig. 4 is the main result of this paper, Theorem 1.3, which establishes the \(\Gamma \)-convergence of \({\mathcal {I}}_\varepsilon \) to \({\mathcal {I}}_0\) in the limit \(\varepsilon \rightarrow 0\).
In the case at hand, in which the n particles constituting the stochastic processes on the left-hand side of the diagram are independent, the left-hand arrow also follows from the results of this paper: The zero sets of \({\mathcal {I}}_\varepsilon \) and \({\mathcal {I}}_0\) are the forward Kolmogorov equations for the corresponding single-particle stochastic processes, for which the \(\Gamma \)-convergence implies convergence of solutions to solutions; in turn, this implies that the stochastic processes converge.
In conclusion, with the results of this paper we see that the diagram of Fig. 4 commutes.
A close connection between Gamma-convergence of rate functions and convergence of processes is observed more broadly; see [7, 11, 27].
1.6.3 Connections to chemical reactions
There is a strong connection between the philosophy of this paper and results in the chemical literature on the appearance of irreversible chemical reactions as limits of reversible reactions, for instance using mass-action laws to describe the dynamics. Gorban, Mirkes, and Yablonksy [18] perform an extensive analysis of such limits and the corresponding behaviour of thermodynamic potentials. Although the gradient-system description of (1) has a clear thermodynamic interpretation (see e.g. [32, Ch. 4–5]), the current paper is different in that the starting point is a diffusion problem, not a discrete reaction system. However, the connections between these two approaches do merit deeper study.
1.6.4 The renormalized gradient system \((\widetilde{E}_\varepsilon ,\widetilde{R}_\varepsilon )\) also does not converge
As we remarked in Sect. 1.3, the functionals \(E_\varepsilon \) diverge as \(\varepsilon \rightarrow 0\), but the rescaled functionals \(\widetilde{E}_\varepsilon := \varepsilon E_\varepsilon \) \(\Gamma \)-converge to a well-defined limit \(\widetilde{E}_0(\rho ) := \int \rho V\). It is a natural question whether switching to the rescaled gradient system \((\widetilde{E}_\varepsilon ,\widetilde{R}_\varepsilon )\) might solve the singularity problems described in Sect. 1.3. Here the rescaled potentials are defined by
and EDP-convergence of \((\widetilde{E}_\varepsilon ,\widetilde{R}_\varepsilon )\) would follow from the \(\Gamma \)-convergence of
Even if \((\widetilde{E}_\varepsilon ,\widetilde{R}_\varepsilon )\) does converge in the EDP sense to \((\widetilde{E}_0,\widetilde{R}_0)\), for some dissipation potential \(\widetilde{R}_0\), then this limiting gradient system \((\widetilde{E}_0,\widetilde{R}_0)\) admits a very wide class of curves as ‘solutions’. This can be recognized as follows.
Let \(z\in C^1([0,T])\) with \(z'\le 0\), and define \((\rho _0,j_0)\) according to (17); since \(z'\) is bounded we have \({\mathcal {I}}_0(\rho _0,j_0)<\infty \). By the recovery-sequence Theorem 5.9 there exists a sequence \((\rho _\varepsilon ,j_\varepsilon )\) converging to \((\rho _0,j_0)\) such that \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon )\rightarrow {\mathcal {I}}_0(\rho _0,j_0)\) and \(\liminf _{\varepsilon \rightarrow 0} \widetilde{E}_\varepsilon (\rho _\varepsilon (t=0))\ge \widetilde{E}_0(\rho _0(t=0))\). We then calculate
It follows that \((\rho _0,j_0)\) is a solution of the gradient system \((\widetilde{E}_0,\widetilde{R}_0)\). This shows that any decreasing function z generates a solution of the gradient system \((\widetilde{E}_0,\widetilde{R}_0)\); this explains our claim that it is too degenerate to be of any use.
1.7 Notation
\({\mathrm {CE}}(0,T)\) | set of pairs \((\rho ,j)\) satisfying the continuity equation | Def. 3.1 |
\(C^{n,m}(X{\times } Y)\) | space of functions that are n times differentiable on \(X\!\!\!\) and m times on Y | |
\(\gamma _\varepsilon \) | invariant measure normalized to one | Eq. (9b) |
\(\gamma _\varepsilon ^\ell \) | left-normalized invariant measure | Sec. 4.2 |
\(E_\varepsilon \) | energy | Eq. (9b) |
\({{\hat{E}}}_\varepsilon , {\hat{{\mathcal {I}}}}_\varepsilon , {\hat{{\mathcal {I}}}}_0\) | rescaled functionals | Def. 5.1 |
\({\mathcal {E}}(\mu |\nu ,A)\) | localized relative entropy | Sec. 4.1 |
\({\mathcal {I}}_\varepsilon \) | functional for pre-limit variational formulation | Def. 20 |
\({\mathcal {I}}_0\) | functional for limit variational formulation | Eq. (16) |
\({\hat{\jmath }}_\varepsilon \) | flux transformed under \(y_\varepsilon \) | |
\({\mathcal {M}}(\Omega )\), \({\mathcal {P}}(\Omega )\) | signed Borel and probability measures | Sec. 3.1 |
\({\mathcal {M}}_{\ge 0}(\Omega )\) | non-negative Borel measures | Sec. 3.1 |
\({Q_T}\), \({Q_{T}^0}\) | \({Q_T}= [0,T]\times {\mathbb {R}}\) and \({Q_{T}^0}= [0,T]\times [-1/2,1/2]\). | |
\({\mathcal {R}}(\mu |\nu ,A)\) | localized relative Fisher-information | Sec. 4.1 |
\({\hat{\rho }}_\varepsilon , {\hat{\gamma }}_\varepsilon ^\ell \) | measures transformed under \(y_\varepsilon \) | Eq. (39a) |
S(a|b) | function in limit functional \({\mathcal {I}}_0\) | Eq. (15) |
\(\tau _\varepsilon \) | exponential time-scale parameter | Eq. (3) |
\({{\hat{u}}}_\varepsilon ^\ell \) | density transformed under \(y_\varepsilon \) | Eq. (39b) |
\({{\hat{u}}}_0\) | limit density | Eq. (47) |
V | potential/energy landscape | Ass. 4.1 |
\(y_\varepsilon ,\phi _\varepsilon \) | auxiliary functions | Sec. 4.3 |
2 Elements of the proofs
The proofs of compactness and \(\Gamma \)-convergence hinge on a number of ingredients.
Dual form of the functional \({\mathcal {I}}_\varepsilon \) The definition of \({\mathcal {I}}_\varepsilon \) given in (8) is formal, since it only makes sense for sufficiently smooth measures \(\rho _\varepsilon \) and \(j_\varepsilon \). The dual formulation that arises naturally from the large-deviation context (see Sect. 1.6.2) solves this definition problem:
Definition 2.1
The functional \({\mathcal {I}}_\varepsilon :{\mathrm {CE}}(0,T)\rightarrow [0,\infty ]\) is defined by
Note how this dual form of \({\mathcal {I}}_\varepsilon \) remains singular in multiple ways: the factor \(\varepsilon \tau _\varepsilon \rho \) is exponentially large in any region where \(\rho \) has O(1) mass, and it is small near the saddle \(x_0\) where \(\rho \) is expected to behave as \(\gamma _\varepsilon \).
The following lemma makes the connection rigorous between \({\mathcal {I}}_\varepsilon \) and the \((E_\varepsilon ,R_\varepsilon )\) gradient system.
Lemma 2.2
Let \((\rho ,j)\in {\mathrm {CE}}(0,T)\) satisfy \(E_\varepsilon (\rho (0))<\infty \). Then
Here the integral in (21) should be considered equal to \(+\infty \) unless the following are satisfied:
-
1.
j is absolutely continuous with respect to \(\rho \) on \({Q_T}\), with density \(v := \mathrm {d}j/\mathrm {d}\rho \);
-
2.
\(\rho \) is Lebesgue-absolutely continuous on \({Q_T}\), with density \(u := \mathrm {d}\rho /\mathrm {d}\gamma _\varepsilon \);
-
3.
\(\partial _x u\in L^1_{\mathrm {loc}}({Q_T})\).
This type of reformulation is fairly standard, but we did not find an explicit proof for this case; we provide a proof in Appendix A.4. In (21) we place \(R^*_\varepsilon \bigl (\rho _\varepsilon (t),-\mathrm DE(\rho _\varepsilon (t))\bigr )\) between quotes, since this expression is only formal; in fact, the expression above the brace could be considered a rigorous interpretation of \(R^*_\varepsilon \bigl (\rho _\varepsilon (t),-\mathrm DE(\rho _\varepsilon (t))\bigr )\).
Forcing concentration onto the two points \(x_a\) and \(x_b\) The starting point of the proofs of compactness and the lower bound in Theorem 4.7 is the ‘fundamental estimate’ of every \(\Gamma \)-convergence and compactness proof,
Restricting in (20) to functions b supported in [0, t], and taking into account the divergence of \(E_\varepsilon (\rho _\varepsilon (0))\) as \(C/\varepsilon \) (see Sect. 1.3) and the bound on \({\mathcal {I}}_\varepsilon \), we obtain for each \(t\in [0,T]\) the estimate
Since the integral is non-negative and the constant C is independent of t, there are constants \(C_1,C_2\) such that for every \(t\in [0,T]\),
Hence
The divergence of the right-hand side in (22) has consequences for compactness:
-
1.
Because of the growth of V at \(\pm \infty \), the divergence at rate \(C/\varepsilon \) of \(E_\varepsilon (\rho _\varepsilon (t))\) suffices to prove tightness of \(\rho _\varepsilon (t)\);
-
2.
However, to prove concentration onto the two points \(x_a\) and \(x_b\), we need to use the polynomial divergence of the ‘Fisher information’ integral that is guaranteed by (22). By applying Logarithmic Sobolev inequalities localized to each of the wells, this divergence is sufficiently slow to force concentration onto \(\{x_a,x_b\}\). This does require us to assume uniform convexity of each of the two wells separately.
The details are given in Sect. 4.
The form of the limit functional \({\mathcal {I}}_0\) One can understand how the limiting functional \({\mathcal {I}}_0\) appears in at least three different ways. The first is by observing that \({\mathcal {I}}_0\) is the rate function for the Sanov large-deviation principle of a two-point jump process; see Sect. 1.6.2 above.
The second understanding of the structure of \({\mathcal {I}}_0\) follows from the proof of the lower bound. This bound follows from making a specific choice for the function b in the dual formulation (20), of the form \(b(t,x) = -2f(t)\delta ^\varepsilon _{x_0}(x)\), where \( \delta ^\varepsilon _{x_0}\) indicates an appropriately rescaled derivative of the classical committor function (see Sect. 4.3); in the limit \(\delta ^\varepsilon _{x_0}\) converges to a Dirac measure at the saddle \(x_0\). With this choice we find the lower bound (Theorem 4.7)
The supremum of the right-hand side over functions f equals the functional \({\mathcal {I}}_0\), expressed in terms of z. This argument is explained in detail in Sect. 4.
The third way to understand the form of \({\mathcal {I}}_0\) is through the construction of the recovery sequence. This sequence is obtained by first applying a spatial transformation \(x \mapsto y = y_\varepsilon (x)\), where the mapping \(y_\varepsilon \) is similar to the mapping \({{\hat{s}}}\) used in [2, Sec. 2.1]. The choice of \(y_\varepsilon \) and \(\tau _\varepsilon \) leads to a desingularization of \({\mathcal {I}}_\varepsilon \), which takes the formal form
Here \({\hat{\rho }}\) and \({\hat{\jmath }}\) are transformed versions of \(\rho \) and j that again satisfy the continuity equation, and \({{\hat{u}}}^\ell \) is the density of \({\hat{\rho }}\) with respect to the ‘left-rescaled invariant measure’; see Sect. 5 for details.
The remarkable aspect of this rescaling is that the expression (23) no longer contains any singular parameters. The recovery sequence is constructed by solving an auxiliary PDE for \({{\hat{u}}}^\ell \), based on (23), which then is transformed back to a pair \((\rho _\varepsilon ,j_\varepsilon )\).
After transformation to the coordinate y, the left well at \(x_a\) and the right well interval \([x_{b-},x_{b+}]\) (see Fig. 1) are mapped to \(-1/2\) and 1/2. From (23) one then finds an alternative expression for the function S of (15) in terms of functions \({{\hat{u}}}(y)\) (see Lemma A.4):
This formula is closely related to the expression for the limiting rate functional in [2, Eq. (1.30)]; see also [24, App. A].
3 Rigorous setup
3.1 Preliminary remarks
Throughout this paper we use the following conventions and notation. We write \({Q_T}\) for the time-space domain \([0,T]\times {\mathbb {R}}\). \(C^{n,m}_b({Q_T})\) is the space of functions \(f:{Q_T}\rightarrow {\mathbb {R}}\) that are n times differentiable in t and m times differentiable in x, and these derivatives are continuous and bounded. (In the uses below we will require no mixed derivatives). \({\mathcal {M}}({Q_T})\) and \({\mathcal {M}}({\mathbb {R}})\) are the sets of finite signed Borel measures on \({Q_T}\) and \({\mathbb {R}}\). We will use two topologies for measures:
-
The narrow topology, generated by duality with continuous and bounded functions; and
-
The wide topology, generated by duality with continuous functions with compact support.
The sets \({\mathcal {M}}_{\ge 0}({\mathbb {R}})\) and \({\mathcal {P}}({\mathbb {R}})\) are the subsets of non-negative measures and probability measures with the same topology.
For a measure \(\mu \in {\mathcal {M}}({\mathbb {R}})\) that is absolutely continuous with respect to the Lebesgue measure, we write \(\mu (dx)\) for the measure and \(\mu (x)\) for the density, so that \(\mu (dx) = \mu (x) dx\). The push-forward measure of a measure \(\mu \in {\mathcal {M}}({\mathbb {R}})\) under a map \(T:{\mathbb {R}}\rightarrow {\mathbb {R}}\) is given by
or equivalently
3.2 Full definition of the continuity equation
The functionals \({\mathcal {I}}_\varepsilon \) are defined on pairs of measures \((\rho ,j)\) satisfying the continuity equation \(\partial _t\rho + \partial _x j = 0\) in the following sense.
Definition 3.1
(Continuity Equation) We say that a pair \((\rho (t,\cdot ),j(t,\cdot ))\) of time-dependent Borel measures on \({\mathbb {R}}\) satisfies the continuity equation if:
-
(i)
For each \(t\in [0,T]\), \(\rho (t,\cdot )\) is a probability measure on \({\mathbb {R}}\). The map \(t\mapsto \rho (t,\cdot )\in {\mathcal {P}}({\mathbb {R}})\) is continuous with respect to the narrow topology on \({\mathcal {P}}({\mathbb {R}})\).
-
(ii)
For each \(t\in [0,T]\), \(j(t,\cdot )\) is a locally finite Borel measure on \({\mathbb {R}}\). The map \(t\mapsto j(t,\cdot )\in {\mathcal {M}}({\mathbb {R}})\) is measurable with respect to the wide topology on \({\mathcal {M}}({\mathbb {R}})\), and the joint measure on \({Q_T}=[0,T]\times {\mathbb {R}}\) given by
$$\begin{aligned} \int _{t\in A} |j(t,B)|\, \mathrm {d}t \qquad \text {for }A\subset [0,T], \ B\subset {\mathbb {R}}\text { bounded,} \end{aligned}$$is locally finite on \({Q_T}\).
-
(iii)
The pair solves \(\partial _t\rho + \partial _x j = 0\) in the sense that for any test function \(\varphi \in C_c^1({Q_T})\) with \(\varphi = 0\) at \(t=T\), we have
$$\begin{aligned}&\int _0^T\int _{\mathbb {R}} \left[ \rho (t,\mathrm {d}x)\, \partial _t \varphi (t,x) +j(t,\mathrm {d}x)\, \partial _x \varphi (t,x) \right] \,\mathrm {d}t + \int _{\mathbb {R}}\rho (0,\mathrm {d}x) \varphi (0,x)= 0.\nonumber \\ \end{aligned}$$(24)
We denote by \({\mathrm {CE}}(0,T)\) the set of all pairs \((\rho ,j)\) satisfying the continuity equation. \(\square \)
This definition gives rise to a corresponding concept of convergence.
Definition 3.2
(Convergence in \({\mathrm {CE}}\)) We say that \((\rho _\varepsilon ,j_\varepsilon )\) converges in \({\mathrm {CE}}(0,T)\) to \((\rho _0,j_0)\in {\mathrm {CE}}(0,T)\) if
-
1.
\(\rho _\varepsilon (0,\cdot )\) converges narrowly to \(\rho _0(0,\cdot )\) on \({\mathbb {R}}\);
-
2.
\(\rho _\varepsilon \) converges narrowly to \(\rho _0\) on \({Q_T}\);
-
3.
for all \(\varphi \in C_c^1({Q_T})\) with \(\varphi = 0\) at \(t=T\),
$$\begin{aligned} \lim _{\varepsilon \rightarrow 0} \int _0^T\int _{\mathbb {R}} j_\varepsilon (t,\mathrm {d}x)\, \partial _x \varphi (t,x)\,\mathrm {d}t =\int _0^T\int _{\mathbb {R}} j_0(t,\mathrm {d}x)\, \partial _x \varphi (t,x)\,\mathrm {d}t. \end{aligned}$$(25)
Note that then the identity (24) for \((\rho _\varepsilon ,j_\varepsilon )\) passes to the limit.
Remark 3.3
(The convergence arises from a metric) The narrow convergence of \(\rho _\varepsilon \) is generated by well-known metrics such as the Lévy–Prokhorov or Bounded-Lipschitz metrics [14, Sec. 11.3]. Since \(C_c({\mathbb {R}})\) is separable, a metric can also be constructed for the wide topology in the usual way.
Remark 3.4
(Other definitions of the continuity equation) Definition 3.1 is weaker than the common continuity-equation concept for Wasserstein-continuous curves [1, Sec. 8.1], in which j is of the form \(j=v\rho \) with \(\iint \rho |v|^2<\infty \). While for curves \((\rho _\varepsilon ,j_\varepsilon )\) with \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon )<\infty \) the flux \(j_\varepsilon \) indeed has this structure (see (21)), in the limit j no longer is absolutely continuous with respect to \(\rho \) (see the characterization of finite \({\mathcal {I}}_0\) in (17c)).
In addition, we choose to incorporate the initial datum in the distributional definition of the continuity Eq. (24), as is common in the theory of parabolic equations with weak time regularity (see e.g. [25, Sec. I.3]). The explicit initial datum is used below in proving that the limit of \(\rho _\varepsilon \) connects continuously to the limiting initial datum; see steps 3 and 4 of the proof of Theorem 4.7.
Remark 3.5
(Different topologies for \(\rho \) and j) It may seem odd that for \(\rho \) we require narrow continuity in Definition 3.1 and narrow convergence in Definition 3.2, but for j we require only wide convergence in Definition 3.2.
This difference arises from the following considerations. For \(j_\varepsilon \), convergence of the weak form (25) is what we obtain in the proof of the compactness (Theorem 4.7) and of the convergence of the recovery sequence (Theorem 5.9). In both cases it is not clear whether \(j_\varepsilon \) converges in a stronger manner than widely.
For \(\rho _\varepsilon \), however, it is important that in the limit no mass is lost at infinity; this requires narrow convergence. In the setup above, this narrow convergence follows from the wide convergence of \(j_\varepsilon \) on \([0,T]\times {\mathbb {R}}\), which also implies wide convergence for \(\rho _\varepsilon \) on the same space; since the limit \(\rho (t,\cdot )\) is again required to be a probability measure for all t, no mass escapes to infinity, and the convergence of \(\rho _\varepsilon \) in fact is narrow.
The narrow continuity of \(t\mapsto \rho (t,\cdot )\) in Definition 3.1 follows from the the conditions on j: the local bounds on j imply wide continuity of \(\rho \), and the requirement that \(\rho \) is a probability measure at all t upgrades this continuity to narrow.
4 Compactness
The limit \(\varepsilon \rightarrow 0\) is accompanied by the concentration of \(\rho _\varepsilon \) onto the two minima of the wells, at \(x_a\) and \(x_b\). This concentration is essential for the further analysis of the functionals \({\mathcal {I}}_\varepsilon \) and their \(\Gamma \)-limits; if \(\rho _\varepsilon \) would maintain mass at other points in \({\mathbb {R}}\), then the main statement and the corresponding analysis of the functionals \({\mathcal {I}}_\varepsilon \) both would fail.
In the case of a potential V with wells of equal depth (as in [2, 24]), a constant bound on the initial energy \(E_\varepsilon (\rho _\varepsilon (t=0))\) leads to a similar bound on later energies \(E_\varepsilon (\rho _e(t))\), which in turn leads to concentration onto \(\{x_a,x_b\}\). In the unequal-well case of this paper, as we discussed in the introduction, we are forced to allow for divergent \(E_\varepsilon \); consequently the concentration onto \(\{x_a,x_b\}\) has to come from different arguments.
Here we choose to obtain this concentration from the ‘Fisher-information’ or ‘local-slope term’; this is the second term in \({\mathcal {D}}_\varepsilon ^T\) in (9a), or equivalently the second half of the integral in (21). This requires imposing conditions on the convexity of the wells, which we do in part 5 of the following set of assumptions on V.

Illustration of Assumption 4.1
Assumption 4.1
Let \(V\in C^2({\mathbb {R}})\) and let the special x-values
satisfy the following:
-
1.
Two wells, the left well at value zero: \(\{V\le 0\} = \{x_a\}\cup [x_{b-},x_{b+}]\);
-
2.
\(x_b\) is the bottom of the right well: \(V(x_b) = \min _{\mathbb {R}}V < 0\);
-
3.
\(x_0\) is the saddle, and the intermediate range lies below it: \(V(x)\le V(x_0)\) for \(x_a<x<x_b\), with \(V(x)< V(x_0)\) unless \(x=x_0\);
-
4.
The saddle is non-degenerate: \(V''(x_0)<0\);
-
5.
Uniform convexity away from the saddle: there exist \(A, \alpha >0\) such that \(A \ge V''\ge \alpha > 0\) on \((-\infty , x_{c\ell }]\) and \([x_{cr},\infty )\).
We also choose two open intervals \(B_a\) and \(B_b\) containing \(x_a\) and \([x_{b-},x_{b+}]\), respectively, and such that \(\sup _{B_a\cup B_b}V<V(x_0)\). The set \(B_0\) is defined as the set separating \(B_a\) and \(B_b\). Figure 5 illustrates these features.
Assumptions 1–4 encode the basic geometry of a two-well potential with unequal wells. Condition number 5 is added to rule out concentration at different points than \(x_a\) and \(x_b\). The following two examples illustrate how concentration at different points may happen if this convexity condition is not imposed.
Failure type I: A hilly right well Since the energy barrier is lower for transitions from left to right than vice versa, it is natural to assume that in the limit all mass travels from left to right. Indeed, this is true under weak assumptions, but the mass that arrives in the right well \([x_{b-},x_{b+}]\) need not all end up in \(x_b\). Figure 6 shows why: if the right well has a ‘sub-well’ (say \(x_d\)) such that the transition \(x_d\rightsquigarrow x_b\) has a higher energy barrier than the transition \(x_a\rightsquigarrow x_d\), then the mass leaving \(x_a\) will be held back at \(x_d\), with further transitions to \(x_b\) happening at an exponentially longer time scale. If we start with all mass concentrated at \(x_a\), then the limiting evolution will be concentrated on \(\{x_a,x_d\}\) instead of on \(\{x_a,x_b\}\).

Example of a potential V that is excluded by Assumption 4.1 (failure of ‘type I’ in the text). If the deeper well has internal energy barriers that are larger than the barrier \(V(x_0)-V(x_a)\) for escape from \(x_a\), then mass may collect in intermediary valleys instead of at \(x_b\). In this example the mass will concentrate onto \(\{ x_a, x_d, x_b\}\), with no mass moving from \(x_d\) to \(x_b\)
Failure type II: Hills at high energy levels Something similar can happen in the ‘wings’ of the energy landscape, as illustrated by Fig. 7. If valleys exist outside of the region \(\{x:V(x)<V(x_0)\}\) with energy barriers larger than the \(x_a\rightsquigarrow x_b\) barrier, then the slowness of transitions between such valleys again will prevent concentration into the sub-zero zone \(\{x:V(x)\le 0\}\).

Second example of a potential V that is excluded by Assumption 4.1 (failure of ‘type II’ in the text). If energy barriers exist outside of the range \([x_a,x_b]\) that are larger than the barrier \(V(x_0)-V(x_a)\) of the escape from \(x_a\), then these will prevent mass from moving to \(x_a\) (and then also from transitioning to \(x_b\)). In this example the mass will concentrate onto \(\{x_e, x_a, x_b\}\), with no mass moving from \(x_e\) to \(x_a\) or \(x_b\)
4.1 Logarithmic Sobolev inequalties
We use logarithmic Sobolev inequalities to capitalize on the uniform convexity bounds in part 5 of Assumption 4.1. Such inequalities are usually formulated for reference measures with unit mass, but in our case it will be convenient to generalize to all finite positive measures, and also allow for localization to subsets of \({\mathbb {R}}\).
For \(A\subset {\mathbb {R}}\) and \(\mu ,\nu \in {\mathcal {M}}_{\ge 0}({\mathbb {R}})\), we set
With these definitions, the energy \(E_\varepsilon \) and the ‘slope’ \(R_\varepsilon ^*(\rho ,-\mathrm D E_\varepsilon (\rho ))\) (see (9b)) can be written as
The identity \((*)\) can also be seen as a rigorous definition of the left-hand side \(R_\varepsilon ^*(\rho ,-\mathrm D E_\varepsilon (\rho ))\) in terms of the right-hand side \({\mathcal {R}}(\rho |\gamma _\varepsilon ,{\mathbb {R}})\): this right-hand side is well defined for all \(\rho \), and in addition Lemma 2.2 shows that this is the term that appears in the reformulation of \({\mathcal {I}}_\varepsilon \) in gradient-system form.
Note that the functions \({\mathcal {E}}\) and \({\mathcal {R}}\) are (1, 0)-homogeneous in the pair \((\mu ,\nu )\), i.e. for each \(\mu ,\nu \in {\mathcal {M}}_{\ge 0}({\mathbb {R}})\) and \(a,b>0\),
The following Lemma generalizes classical Logarithmic Sobolev inequalities based on uniform convexity bounds to the homogeneous functionals \({\mathcal {E}}\) and \({\mathcal {R}}\) and the restriction to subsets \(A\subset {\mathbb {R}}\).
Lemma 4.2
(Logarithmic Sobolev inequality) Let \(A\subset {\mathbb {R}}\) be an interval. If \(W\in C^2(A)\) with \(W''\ge \alpha >0\) on A, then
Proof
By e.g. [6, Cor. 5.7.2] or [9, Cor. 1], if \(W\in C^2({\mathbb {R}})\) with \(W''\ge \alpha >0\) on \({\mathbb {R}}\), then the inequality (27) holds for \(A={\mathbb {R}}\) and for all \(\mu \in {\mathcal {P}}({\mathbb {R}})\). By the homogeneity of \({\mathcal {E}}\) and \({\mathcal {R}}\) the same applies to all \(\mu \in {\mathcal {M}}_{\ge 0}({\mathbb {R}})\).
To generalize to the case of \(A\subsetneqq {\mathbb {R}}\) and a given potential \(W\in C^2(A)\) with \(W''\ge \alpha \) on A, first smoothly extend W to the whole of \({\mathbb {R}}\) in such a way that \(W''\ge \alpha \) on \({\mathbb {R}}\) and \(\int _{\mathbb {R}}e^{-W}<\infty \). Next define the sequence of \(C^2\) potentials
As \(k\rightarrow \infty \) the measures \(e^{-W_k(x)}\mathrm {d}x\) converge narrowly on \({\mathbb {R}}\) to \(e^{-W(x)}\mathbb {1}_{A}(x)\mathrm {d}x\). Each \(W_k\) satisfies \(W_k''\ge \alpha \) on \({\mathbb {R}}\), and it follows that for any \(\mu \in {\mathcal {M}}_{\ge 0}({\mathbb {R}})\) with \(\mu ({\mathbb {R}}\setminus A) = 0\),

This proves the claim (27). \(\square \)
Bounds on the entropy give rise to concentration estimates of the underlying measure.
Lemma 4.3
(Concentration estimates based on \({\mathcal {E}}\)) Let \(A_1\subset A_2\subset {\mathbb {R}}\), and let \(\mu ,\nu \in {\mathcal {M}}_{\ge 0}(A_2)\) with \(\nu (A_1)>0\). Then
Proof
By homogeneity of \({\mathcal {E}}\) it is sufficient to prove the inequality for the case \(\mu (A_2) = \nu (A_2) = 1\). We can also assume that \(\mu \ll \nu \), and we set \(\mu = f\nu \).
Applying Young’s inequality with the dual pair \(\eta (s) = s\log s -s + 1\) and \(\eta ^*(t) = e^t-1\), we find for any \(a>0\) that
Choosing \(a = |\log \nu (A_1)| = -\log \nu (A_1)\) we find
which is (28) for the case \(\mu (A_2) = \nu (A_2) = 1\). \(\square \)
4.2 Invariant measures and their normalizations
In the introduction we defined the invariant measure
The measure \(\gamma _\varepsilon \) is normalized in the usual manner, and is therefore a probability measure on \({\mathbb {R}}\). Since V has a single global minimum at \(x_b\), the measures \(\gamma _\varepsilon \) converge to \(\delta _{x_b}\); therefore the mass of \(\gamma _\varepsilon \) around \(x_a\) vanishes. It will also be useful to have a differently normalized measure \(\gamma _\varepsilon ^\ell \) in which the mass around \(x_a\) does not vanish. For this reason we also define the left-normalized measures \(\gamma _\varepsilon ^\ell \) by
Figure 8 illustrates the behaviour of \(\gamma _\varepsilon ^\ell \) and \(\gamma _\varepsilon \) as \(\varepsilon \rightarrow 0\). The following lemma characterizes some of their behaviour in precise form.

Behavior of the left-normalized invariant measure \(\gamma _\varepsilon ^\ell \) and the fully-normalized measure \(\gamma _\varepsilon \) for small values of \(\varepsilon \)
Lemma 4.4
Let V satisfy Assumption 4.1.
-
1.
\(\gamma _\varepsilon \) and \(\gamma ^\ell _\varepsilon \) are well-defined, and in the limit \(\varepsilon \rightarrow 0\),
$$\begin{aligned} Z_\varepsilon =[1+o(1)] \sqrt{\frac{2\pi \varepsilon }{V''(x_b)}} e^{-V(x_b)/\varepsilon }, \qquad Z_\varepsilon ^\ell =[1+o(1)] \sqrt{\frac{2\pi \varepsilon }{V''(x_a)}} . \end{aligned}$$(29) -
2.
If \({{\tilde{x}}}>x_0\) and \(V<V(x_0)\) on \((x_0,{{\tilde{x}}}]\), then
$$\begin{aligned} \frac{Z_\varepsilon ^\ell }{\varepsilon \tau _\varepsilon } \int _{x_0}^{{{\tilde{x}}}} e^{V/\varepsilon } \longrightarrow \frac{1}{2} \qquad \text {as }\varepsilon \rightarrow 0. \end{aligned}$$ -
3.
For any \(\delta > 0\), \( \lim _{\varepsilon \rightarrow 0}\gamma _\varepsilon ^\ell (\{V>\delta \}) = 0\).
-
4.
For any \(x_a<c<x_0< x_{b-}< d\), the sequence \(\gamma ^\ell _\varepsilon \lfloor (-\infty ,c)\) converges as measures to \(\delta _{x_a}\), and \(\gamma ^\ell _\varepsilon ((c,d)) \rightarrow \infty \).
Part 3 above expresses the property that the left-normalized measures concentrate in the limit \(\varepsilon \rightarrow 0\) onto the set \(\{V\le 0\}=\{x_a\}\cup [x_{b-},x_{b+}]\). Part 4 expresses the fact that the ‘left-hand’ part of \(\gamma ^\ell _\varepsilon \) has a well-behaved limit \(\delta _{x_a}\), while the right-hand part of \(\gamma ^\ell _\varepsilon \) has unbounded mass.
Proof
For part 1, the superquadratic growth of V towards \(\pm \infty \) that follows from uniform convexity implies that \(Z_\varepsilon \) and \(Z^\ell _\varepsilon \) are finite for each \(\varepsilon \); the scaling of \(Z_\varepsilon \) and \(Z_\varepsilon ^\ell \) then follow directly from Laplace’s method (Lemma A.2). The same holds for part 2, and the convergence of \(\gamma ^\ell _\varepsilon \lfloor (-\infty ,c)\) to \(\delta _{x_a}\) (part 4).
For part 3, we estimate using the superquadratic growth of V that
This proves the claim.
Finally, to show that \(\gamma ^\ell _\varepsilon ((c,d))\rightarrow \infty \) (part 4), note that \(V(x)\le -\mu <0\) for some constant \(\mu >0\) on an open interval \((x_{b-}+\delta ,x_{b-}+2\delta )\subset (c,d)\); from this the divergence follows. \(\square \)
4.3 Auxiliary functions \(\phi _\varepsilon \) and \(y_\varepsilon \)
To desingularize the functional \({\mathcal {I}}_\varepsilon \) we will need an auxiliary function \(\phi _\varepsilon \) that is adapted to the singular structure of this system and distinguishes the two wells, in the sense of having constant, but different, values there. For the recovery sequence we will need a related function \(y_\varepsilon \), and we define it here at the same time, and study the properties of \(\phi _\varepsilon \) and \(y_\varepsilon \) together.
Fix two smooth functions \(\chi _a,\chi _b\in C^\infty _c({\mathbb {R}})\) with \(\chi _{a,b}\ge 0\), \({{\,\mathrm{supp}\,}}\chi _a\subset B_a\) and \({{\,\mathrm{supp}\,}}\chi _b\subset B_b\), and \(\chi _a(x_a) = 1 = \chi _b(x_b)\). Set
The function \(M_\varepsilon \) has the following properties:
-
1.
\(0\le M_\varepsilon \le 1\);
-
2.
\(M_\varepsilon \) is equal to 1 on \(B_0\) and equal to zero outside of \(B_a\cup B_0\cup B_b\), and converges in \(L^1\) to \(\mathbb {1}_{[x_a,x_b]}\);
Define \(\phi _\varepsilon \in C^2_b({\mathbb {R}})\) and \(y_\varepsilon \in C^2({\mathbb {R}})\) by

Comparison of the functions \(\phi _\varepsilon \) and \(y_\varepsilon \). Note how the two functions are very similar in the region between and around the two wells; towards \(\pm \infty \), however, \(y_\varepsilon \) is unbounded, while the range of \(\phi _\varepsilon \) is bounded
The functions \(y_\varepsilon \) and \(\phi _\varepsilon \) are shown in Fig. 9. The definition of \(\phi _\varepsilon \) is a minor modification of [15, Lemma 3.6] and is nearly the same as the committor function, known from potential theory [3] and Transition-Path Theory [42]; see also [26] for a discussion of its use in coarse-graining, which is similar to its function here. The following lemma describes in different ways how \(\phi _\varepsilon \) approximates the function \(x\mapsto {{\,\mathrm{sign}\,}}(x)/2\).
Lemma 4.5
The function \(\phi _\varepsilon \) satisfies
-
1.
\(\phi _\varepsilon \) is non-decreasing on \({\mathbb {R}}\);
-
2.
There exists \(C>0\) such that \(|\phi _\varepsilon |\le C\) for sufficiently small \(\varepsilon \), \(\lim _{\varepsilon \rightarrow 0} \phi _\varepsilon (-\infty ) = -1/2\), and \(\lim _{\varepsilon \rightarrow 0} \phi _\varepsilon (+\infty ) = 1/2\);
-
3.
\(\phi _\varepsilon \) converges uniformly to \(-1/2\) on \(B_a\) and to 1/2 on \(B_b\).
-
4.
\(Z_\varepsilon ^\ell e^{V/\varepsilon } \mu _\varepsilon \) converges uniformly on \({\mathbb {R}}\) to \(-\chi _a\).
Proof
The non-negativity of \(M_\varepsilon \) proves the monotonicity of \(\phi _\varepsilon \). The bound on \(\phi _\varepsilon \) and the convergence of the limit values follow from remarking that
Since on \({{\,\mathrm{supp}\,}}M_\varepsilon \subset B_a\cup B_0\cup B_b\) the potential V takes its maximum at the saddle \(x_0\), and since \(M_\varepsilon \) is equal to one around the saddle, the integral converges to 1/2 by part 2 of Lemma 4.4. The behaviour at \(-\infty \) is proved in the same way.
Since the expression \(Z_\varepsilon ^\ell e^{V/\varepsilon }/\varepsilon \tau _\varepsilon \) converges to zero uniformly on \(B_a\) and \(B_b\), Eq. (30) implies that \(\phi _\varepsilon \) becomes constant on \(B_a\) and \(B_b\) and converges uniformly on those sets to its limit values, which are \(-1/2\) and 1/2, respectively.
Finally,
The first term vanishes uniformly since the scalar \(\alpha _{\varepsilon ,b}\) equals \(Z_\varepsilon ^\ell /\int e^{-V/\varepsilon }\chi _b \sim e^{V(x_b)/\varepsilon } \rightarrow 0\). The second term converges to \(-\chi _a\), since
The function \(y_\varepsilon \) is very similar to \(\phi _\varepsilon \), but differs in the tails, and will be used as a coordinate transformation in Section 5.
Lemma 4.6
-
1.
The function \(y_\varepsilon \) is strictly increasing and bijective.
-
2.
For any \(x<x_0\) such that \(V(x) < V(x_0)\), we have \(y_\varepsilon (x) \rightarrow -\frac{1}{2}\) as \(\varepsilon \rightarrow 0\).
-
3.
For any \(x>x_0\) such that \(V(x) < V(x_0)\), we have \(y_\varepsilon (x) \rightarrow +\frac{1}{2}\) as \(\varepsilon \rightarrow 0\).
-
4.
\(\phi _\varepsilon \circ y_\varepsilon ^{-1}\) converges uniformly on \({\mathbb {R}}\) to the truncated identity function \({\mathrm {id}}_{1/2}\), defined by
$$\begin{aligned} {\mathrm {id}}_{1/2}(x) := {\left\{ \begin{array}{ll} -1/2 &{} \text {if }x\le -1/2\\ x&{} \text {if } -1/2\le x\le 1/2\\ 1/2 &{} \text {if }x\ge 1/2. \end{array}\right. } \end{aligned}$$

The structure of the map \(y_\varepsilon \) of (31). Points to the left of \(x_0\) with \(V(x)<V(x_0)\) are mapped to \(-1/2\), and similarly, points to the right of \(x_0\) are mapped to \(+1/2\). The smaller the value of \(\varepsilon \), the sharper is the concentration effect. As \(\varepsilon \rightarrow 0\), points far to the left of \(x_a\) and far to the right of \(x_b\) are mapped to \({\mp }\infty \), respectively
Proof
Since \(y_\varepsilon '(x) > 0\) for any \(x \in {\mathbb {R}}\) and \(y_\varepsilon (x) \rightarrow \pm \infty \) as \(x \rightarrow \pm \infty \), the map \(y_\varepsilon \) is strictly increasing and bijective. For \(x < x_0\) satisfying \(V(x) < V(x_0)\), we obtain
by using (29) and applying Lemma A.2(b) to the integral. The argument for the case \(x>x_0\) is similar.
To show that \(\phi _\varepsilon \circ y_\varepsilon ^{-1}\) converges uniformly on \({\mathbb {R}}\) to \({\mathrm {id}}_{1/2}\), first note that
The function \(M_\varepsilon \circ y_\varepsilon ^{-1}\) converges in \(L^1({\mathbb {R}})\) to \(\mathbb {1}_{[-1/2,1/2]}\); this can be recognized from the fact that \(y_\varepsilon ^{-1}(y)\) converges to 0 for any \(-1/2<y<1/2\), to \(+\infty \) for \(y>1/2\), and to \(-\infty \) for \(y< -1/2\). The uniform convergence of \(\phi _\varepsilon \circ y_\varepsilon ^{-1}\) then follows by integration. \(\square \)
4.4 Compactness and lower bound
Having defined the auxiliary function \(\phi _\varepsilon \) we can state and prove the main compactness theorem, which includes a lower bound on \({\mathcal {I}}_\varepsilon \).
Theorem 4.7
(Compactness and lower bound) Let V satisfy Assumption 4.1. Let \((\rho _\varepsilon ,j_\varepsilon )\in {\mathrm {CE}}(0,T)\) satisfy
and assume that \(\rho _\varepsilon (0)\) satisfies the narrow convergence

Then there exists a \((\rho _0,j_0)\in {\mathrm {CE}}(0,T)\) and a subsequence along which
-
1.
 narrowly in \({\mathcal {M}}([0,T]\times {\mathbb {R}})\), where \(\rho _0\in {\mathcal {M}}([0,T]\times {\mathbb {R}})\) has the structure $$\begin{aligned} \rho _0(\mathrm {d}t\mathrm {d}x) = \rho _0(t,\mathrm {d}x)\mathrm {d}t := z(t)\delta _{x_a}(\mathrm {d}x) \mathrm {d}t + (1-z(t))\delta _{x_b}(\mathrm {d}x)\mathrm {d}t, \end{aligned}$$(34)
narrowly in \({\mathcal {M}}([0,T]\times {\mathbb {R}})\), where \(\rho _0\in {\mathcal {M}}([0,T]\times {\mathbb {R}})\) has the structure $$\begin{aligned} \rho _0(\mathrm {d}t\mathrm {d}x) = \rho _0(t,\mathrm {d}x)\mathrm {d}t := z(t)\delta _{x_a}(\mathrm {d}x) \mathrm {d}t + (1-z(t))\delta _{x_b}(\mathrm {d}x)\mathrm {d}t, \end{aligned}$$(34)and \(z:[0,T]\rightarrow [0,1]\) is absolutely continuous.
-
2.
\(j_\varepsilon \) converges in duality with \(C_c^{1,0}([0,T)\times {\mathbb {R}})\) to
$$\begin{aligned} j_0(\mathrm {d}t \mathrm {d}x) := j(t)\mathbb {1}_{[x_a,x_b]}(x) \mathrm {d}x\mathrm {d}t, \end{aligned}$$where \(j(t) = -z'(t)\) for almost all \(t\in [0,T]\).
-
3.
\(\liminf _{\varepsilon \rightarrow 0} {\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon )\ge {\mathcal {I}}_0(\rho _0,j_0)\).
 narrowly in
narrowly in Remark 4.8
Note that the two assumptions on the initial data, the convergence (33) and the boundedness \(E_\varepsilon (\rho _\varepsilon (0))\le C/\varepsilon \) of (32), are closely related, but independent: it is possible to satisfy one but not the other.
Proof
Recall from the discussion in Sect. 2 that by the assumption (32) on the initial data we have the ‘fundamental estimate’
Here \(u_\varepsilon \) is the density of \(\rho _\varepsilon \) with respect to the invariant measure \(\gamma _\varepsilon \).
Step 1: Concentration for the case of the outer half-lines Set \(O_\ell := (-\infty , x_{c\ell }]\). Recall that \(V''\ge \alpha >0\) on \(O_\ell \); by Lemma 4.2 we therefore have
Then
Therefore, if \(A\subset O_\ell \) with \({{\,\mathrm{dist}\,}}(A,\{x_a\})>0\), then by Lemma 4.3,
It follows that \(\rho _\varepsilon \mathbb {1}_{O_\ell }\) concentrates onto \([0,T]\times \{x_a\}\). By a similar argument \(\rho _\varepsilon \mathbb {1}_{[x_{cr},\infty )}\) concentrates onto \([0,T]\times \{x_b\}\). This also implies that \(\rho _\varepsilon \) is tight on \([0,T]\times {\mathbb {R}}\).
Step 2: Concentration for the case of the whole domain \({\mathbb {R}}\) We have proved concentration of \(\rho _\varepsilon \mathbb {1}_{(-\infty ,x_{c\ell }]}\) onto \([0,T]\times \{x_a\}\) and of \(\rho _\varepsilon \mathbb {1}_{[x_{cr}, \infty )}\) onto \([0,T]\times \{x_b\}\). What remains is to bridge the gap between \(x_{c\ell }\) and \(x_{cr}\).
We write \(u^\ell _\varepsilon \) for the density of \(\rho _\varepsilon \) with respect to the left-normalized invariant measure \(\gamma _\varepsilon ^\ell \), i.e. \({{\hat{u}}}_\varepsilon ^\ell = u_\varepsilon Z_\varepsilon /Z_\varepsilon ^\ell \). We then estimate
Since \(V\le V(x_0)\) on \([x_a,x_{b+}]\) it follows that
Applying the generlized Poincaré inequality of Lemma A.1 to \(f(t,x) = \sqrt{u^\ell _\varepsilon }\) on \([x_a,x_{b+}]\) we find
To prove concentration, take an interval A such that \([x_{c\ell },x_{cr}]\subset A\subset \{V\ge \delta \}\) for some \(\delta >0\). Then
Therefore \(\rho _\varepsilon \) does not charge the region \([0,T]\times A\) in the limit.
Concluding, \(\rho _\varepsilon \) concentrates onto \([0,T]\times \{x_a,x_b\}\) as \(\varepsilon \rightarrow 0\). It follows that the limit \(\rho _0\) has support contained in \([0,T]\times \{x_a,x_b\}\), and for almost every \(t\in [0,T]\), \(\rho _0(t,\cdot )\) has mass one on \({\mathbb {R}}\). This establishes the structure (34), except for the continuity of z; at this stage we only know that \(z\in L^\infty (0,T)\) with \(0\le z\le 1\), and the absolute continuity of z will follow in Step 4 below.
Remark 4.9
After completing the proof of compactness outlined in the previous two steps, André Schlichting pointed out that by using the Muckenhoupt criterion it is possible to replace the assumption of convex wells by two monotonicity assumptions, one for each well; see Theorem 3.19 in [40] for an example.
Step 3: Lower bound on \({\mathcal {I}}_\varepsilon \) From Definition 2.1 and the bound (32) we have for any \(b\in C_c^{0,1}({Q_T})\) the estimate
Fix \(\psi \in C^1([0,T])\) with \(\inf \psi > -1\) and \(\psi (T)=0\). Define \(F_\varepsilon :[0,T]\times {\mathbb {R}}\rightarrow {\mathbb {R}}\) by
Lemma 4.10
\(F_\varepsilon \) and \(\widetilde{\phi }_\varepsilon \) have the following properties:
-
1.
\(F_\varepsilon \in C^1_b({Q_T})\) and \(\partial _x F_\varepsilon \in C^1_c({Q_T})\);
-
2.
\(F_\varepsilon (T,x) = 0\) for all \(x\in {\mathbb {R}}\);
-
3.
\(\sup _{\varepsilon ,t,x} |F_\varepsilon (t,x)| \le \max \{ \log (1+\sup \psi ), -\log (1+\inf \psi )\}\);
-
4.
\(\widetilde{\phi }_\varepsilon \) converges uniformly on \([0,T]\times B_a\) to 1 and on \([0,T]\times B_b\) to zero;
-
5.
\(F_\varepsilon \) converges uniformly on \([0,T]\times B_a\) to \(\log (1+\psi (t))\) and on \([0,T]\times B_b\) to zero.
These follow directly from Lemma 4.6.
We now set \(b_\varepsilon (t,x) = 2\partial _x F_\varepsilon (t,x)= 2\psi (t){\widetilde{\phi }_\varepsilon }'(x)/(1+\psi (t)\widetilde{\phi }_\varepsilon (x))\) and find that the expression in brackets in (36) equals

By Lemma 4.5 and the concentration of \(\rho _\varepsilon \) we therefore find that
We now turn to the first term in (36). Applying the Definition 3.1 of \({\mathrm {CE}}\), and the assumption (33) on the convergence of the initial data, we find
Writing \(f(t) := -\log (1+\psi (t))\) we have \(f(T) =0\); combining (37) and (38), and observing that \(\psi /(1+\psi ) = e^f-1\), we find
with
Lemma 4.11
Let \(z\in L^\infty (0,T)\) with \(z\ge 0\), and let \(z^\circ \ge 0\). Then \({\mathcal {J}}_0(z) = {\mathcal {K}}_0(z)\), where
If \({\mathcal {K}}_0(z) = 0\), then \(z(t) = z^\circ e^{-t}\) for almost all \(0\le t\le T\).
We prove this lemma below, and first finish the proof of Theorem 4.7. Note that since \({\mathcal {J}}_0(z) = {\mathcal {K}}_0(z)<\infty \), the function z has an absolutely continuous representative and \(z(0) = z^\circ \); this concludes the proof of part 1 of the theorem.
Step 4 of the proof of Theorem 4.7: Convergence of \(j_\varepsilon \) Choose any \(\varphi \in C_c^{1,0}({Q_T})\) with \(\varphi =0\) at \(t=T\), and set \(\Phi (t,x) := \int _0^x \varphi (t,\xi )\, \mathrm {d}\xi \); note that \(\Phi \in C^1_b({Q_T})\) and \(\partial _x\Phi \in C_c({Q_T})\). We calculate

This proves the convergence of part 2. Finally, with this definition of the limit \(j_0\) of \(j_\varepsilon \), we have
and this concludes the proof of Theorem 4.7. \(\square \)
Proof of Lemma 4.11
A closely related statement and its proof are discussed in [33, Sec. 3]; for completeness we give a standalone proof.
Step 1: If \({\mathcal {J}}_0(z)<\infty \), then z is non-increasing on [0, T] Fix \(\varphi \in C_c^\infty ((0,T))\) with \(\varphi \ge 0\). Applying the definition of \({\mathcal {J}}_0(z)\) to \(f = -\lambda \varphi \) we find
which implies \(\int z\varphi '\ge 0\). Since \(\varphi \in C_c^\infty ((0,T))\) is arbitrary, it follows that the equivalence class \(z\in L^\infty \) has a non-increasing representative, and from now on we write z for this non-increasing representative. We also find that \(-z'\) is a positive measure on (0, T). By the monotonicity of z, the limits of z at \(t=0,T\) exist, and if necessary we redefine z to be continuous at \(t=0,T\). By construction, z now is non-increasing on [0, T] and \(-z'\) is a positive measure on [0, T] without atoms at \(t=0,T\).
Step 2: Reformulation and matching initial data Since \(-z'\) is a finite measure and z is continuous at \(t=0,T\), we can rewrite
By choosing functions f with \(f(0)=\lambda \in {\mathbb {R}}\) and \({{\,\mathrm{supp}\,}}f\) a vanishingly small interval close to \(t=0\) we find \({\mathcal {J}}_0(z) \ge 2\lambda (z^\circ -z(0))\), and by taking limits \(\lambda \rightarrow \pm \infty \) it follows that \(z(0) = z^\circ \).
Step 3: Primal form Still under the assumption that \({\mathcal {J}}_0(z)<\infty \), we recognize \(e^f-1\) as the dual \(\eta ^*(f)\) of the function \(\eta (a) := S(a|1)\) (which is equal to \(a\log a -a + 1\) for \(a>0\)). We then use the well-known duality characterization of convex functions of measures (see e.g. [1, Lemma 9.4.4]) to find, writing \(\mu (\mathrm {d}t) := z(t)\mathrm {d}t\),
and this functional coincides with \({\mathcal {K}}_0\) (see e.g. [35, Lemma 2.3]). The reverse statement, assuming \({\mathcal {K}}_0(z)<\infty \) and showing that \({\mathcal {J}}_0(z) < \infty \), follows directly by Young’s inequality for the pair \((\eta ,\eta ^*)\).
Step 4: Absolute continuity Finally, if \({\mathcal {J}}_0(z)={\mathcal {K}}_0(z)<\infty \), then the superlinearity of \(\eta \) implies that \(z'\in L^1(0,T)\), and therefore z is absolutely continuous.
Step 5: Characterization of minimizers If \({\mathcal {K}}_0(z)=0\), then \({\overline{z}}'(t) =-{\overline{z}}(t)\) for almost all t, implying that \({\overline{z}}(t) = z^\circ e^{-t}\). \(\square \)
5 Recovery sequence
In this section we state and prove Theorem 5.9, which establishes the existence of a recovery sequence for the \(\Gamma \)-convergence of Theorem 1.3.
5.1 Spatial transformation
We start by transforming the system by a nonlinear mapping in space, given by the function \(y_\varepsilon \) defined in Sect. 4.3; this function maps \({\mathbb {R}}\) with variable x to \({\mathbb {R}}\) with variable y, and is inspired by a similar choice in [2]. This mapping desingularizes the system.
We define the transformed versions \({\hat{\rho }}_\varepsilon \) and \({\hat{\gamma }}^\ell _\varepsilon \) of \(\rho _\varepsilon \) and \(\gamma ^\ell _\varepsilon \) by pushing them forward under \(y_ \varepsilon \),
which implies that the transformed density \({{\hat{u}}}^\ell _\varepsilon \) is given by
We transform \(j_\varepsilon \) in such a way that the continuity equation is conserved, which leads to the choice
which has an equivalent formulation in the case of Lebesgue-absolutely-continuous fluxes,
Indeed, if \((\rho ,j)\) satisfies the continuity Eq. (6a), then the transformed pair \(({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) satisfies the corresponding continuity equation in the variables (t, y),
which is defined again as in Definition 3.1, and one can check that \((\rho ,j)\in {\mathrm {CE}}(0,T) \iff ({\hat{\rho }},{\hat{\jmath }})\in {\mathrm {CE}}(0,T)\). Since \(y_\varepsilon \) is a diffeomorphism, there is a one-to-one relationship between \((\rho ,j)\) and \(({\hat{\rho }},{\hat{\jmath }})\).
In terms of \({\hat{\jmath }}_\varepsilon \) and the density \({{\hat{u}}}_\varepsilon ^\ell \) the rate function formally takes the simpler form
Note how the parameters \(\varepsilon \) and \(\tau _\varepsilon \) are absorbed into the density \({\hat{u}}_\varepsilon ^\ell \) and the derivative with respect to the new coordinate y. The coordinate transformation \(y_\varepsilon \) is the almost the same as in [2]; the only difference is that we use the left-normalized stationary measure, whereas in the symmetric case one can use the stationary measure normalized in the usual manner.
This simpler, transformed form is the basis for the construction of the recovery sequence. To make this precise we first define the rescaled versions of \({\mathcal {I}}_\varepsilon \) and \({\mathcal {I}}_0\).
Definition 5.1
(Rescaled functionals) For given \(\rho \) and j, define \({\hat{\rho }}\) and \({\hat{\jmath }}\) as in (39a) and (39c). We define \({{\hat{E}}}_\varepsilon \), \({\widehat{{\mathcal {I}}}}_\varepsilon \), and \({\widehat{{\mathcal {I}}}}_0\) to be the rescaled versions of \(E_\varepsilon \), \({\mathcal {I}}_\varepsilon \), and \({\mathcal {I}}_0\),
The following lemma is a direct consequence of the definition (20), the transformation (39), and part 2 of Lemma 2.2.
Lemma 5.2
(Dual formulation of \({\widehat{{\mathcal {I}}}}_\varepsilon \)) We have
provided \(\hat{\rho }(t,\cdot )\) is absolutely continuous with respect to \(\hat{\gamma }_\varepsilon ^\ell \) with density \({\hat{u}}_\varepsilon ^\ell (t,\cdot )\); otherwise we set \(\widehat{{\mathcal {I}}}_\varepsilon \left( \hat{\rho },\hat{\jmath }\right) =+\infty \).
While the left-normalized stationary measure \(\gamma ^\ell _\varepsilon \) in the original variables concentrates onto the set \(\{x: V(x)\le 0\}=\{x_a\}\cup [x_{b-1},x_{b+}]\), under this transformation the interval \([x_{b-1},x_{b+}]\) collapses onto a point (see also Fig. 10):
Lemma 5.3
(The measures \(\hat{\gamma }_\varepsilon ^\ell \) concentrate onto \(\{\pm 1/2\}\)) Let a measurable set \(A\subset {\mathbb {R}}\) have positive distance to \(\pm 1/2\). Then
Proof
Fix \(0< \delta < V(x_0)\). Since A has positive distance to \(\{\pm 1/2\}\), by Lemma 4.6 we have for sufficiently small \(\varepsilon \) that \(V\ge \delta \) on \(y_\varepsilon ^{-1}(A)\). Therefore
By Lemma 4.4, the right-hand side vanishes in the limit \(\varepsilon \rightarrow 0\). \(\square \)
5.2 Statement and proof for the transformed system
Theorem 5.4
(Upper bound in transformed coordinates) For any \((\hat{\rho }_0,\hat{\jmath }_0)\in {\mathrm {CE}}(0,T)\) such that \(\widehat{{\mathcal {I}}}_0(\hat{\rho }_0,\hat{\jmath }_0)<\infty \), there exist \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\in {\mathrm {CE}}(0,T)\) such that
and that
Proof
Recall that \({Q_T}:= [0,T]\times {\mathbb {R}}\) and set \({Q_{T}^0}:=[0,T]\times [-1/2,+1/2]\). If \({\widehat{{\mathcal {I}}}}_0({\hat{\rho }}_0,{\hat{\jmath }}_0)\) is finite, then by combining Definitions 5.1 and (16) we find that the pair \((\hat{\rho }_0,\hat{\jmath }_0)\) is given by
where \(t\mapsto {\hat{z}}_0(t)\) is absolutely continuous and \(\hat{\jmath }_0\) satisfies \(\hat{\jmath }_0(t)=-\partial _t{\hat{z}}_0(t) \ge 0\). For the later construction of \(({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) we will want to assume that \({{\hat{z}}}_0\) satisfies the following regularity assumption.
Assumption 5.5
The density \({\hat{z}}_0:[0,T]\rightarrow [0,1]\) satisfies
Note that this implies that \({\hat{\jmath }}_0\) is bounded away from zero and of class \(C^1\).
Indeed, we can assume that \({{\hat{z}}}_0\) has this regularity since this set is energy-dense:
Lemma 5.6
(Energy-dense approximations) If \(\widehat{{\mathcal {I}}}_0(\hat{\rho }_0,\hat{\jmath }_0)\) is finite, then there are densities \({\hat{z}}_0^\delta \) satisfying Assumption 5.5 such that the pair \((\hat{\rho }_0^\delta ,\hat{\jmath }_0^\delta )\) defined via \({\hat{z}}_0^\delta \) as in (43) and (44) satisfies
By a standard diagonal argument (e.g. [8, Rem. 1.29]) we can continue under the assumption that \({{\hat{z}}}_0\) satisfies Assumption 5.5. The bound on the energy (41) follows from the \(\delta \)-independent estimate in (51e) below. From now on we therefore assume that Assumption 5.5 is satisfied.
The proof of Theorem 5.4 now consists of three steps.
Step 1: characterization of \(\widehat{{\mathcal {I}}}_0(\hat{\rho }_0,\hat{\jmath }_0)\) By Lemma A.4 the limiting rate function satisfies
where \({\hat{u}}_0:{Q_{T}^0}\rightarrow [0,\infty )\) is the function given by
and \({\hat{b}}_0:{Q_{T}^0}\rightarrow {\mathbb {R}}\) is defined by
The second-order polynomial \({\hat{u}}_0(t,\cdot )\) is either concave (\(\hat{\jmath }_0>{\hat{z}}_0\)), linear (\(\hat{\jmath }_0={\hat{z}}_0\)) or convex (\(\hat{\jmath }_0<{\hat{z}}_0\)). These three cases are sketched in Fig. 11. Note that under Assumption 5.5, \({{\hat{b}}}_0\) and \(\partial _y {{\hat{b}}}_0\) are bounded on \({Q_{T}^0}\).

The polynomial \(y\mapsto {\hat{u}}_0(t,y)\) on \([-1/2,+1/2]\) for the three cases \(\hat{\jmath }_0(t)>{\hat{z}}_0(t)\) (yellow), \(\hat{\jmath }_0(t)={\hat{z}}_0(t)\) (red) and \(\hat{\jmath }_0(t)<{\hat{z}}_0(t)\) (blue). In particular, the function always satisfies \({\hat{u}}_0(t,-1/2) = {\hat{z}}_0(t)\) and \({\hat{u}}_0(t,+1/2)=0\)
Step 2: Solve an auxiliary PDE for \(\varepsilon >0\) We define the function \({\hat{u}}_\varepsilon ^\ell :E\rightarrow [0,\infty )\) as the weak solution to the auxiliary PDE
where \({\hat{g}}_\varepsilon ^\ell \in L^\infty ({\mathbb {R}})\) is the Lebesgue density of the left-stationary measure \(\hat{\gamma }_\varepsilon ^\ell \) from (39a), that is \(\hat{\gamma }_\varepsilon ^\ell (dy) = {\hat{g}}_\varepsilon ^\ell (y)dy\).
This choice is inspired by the observation that if we define the pair \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\) by
then by the characterization of weighted \(L^2\)-norms we have
which is an approximation of \(\widehat{{\mathcal {I}}}_0({\hat{\rho }}_0,{\hat{\jmath }}_0)\) as given by (46).
We choose initial data \({\hat{u}}_\varepsilon ^{\ell ,\circ }\) for (49) that approximate \({\hat{\rho }}_0(t=0)\) in the following sense (see Lemma 5.8 for a proof that such initial data can be found):





The following lemma gives the relevant properties of \({{\hat{u}}}_\varepsilon ^\ell \), \({\hat{\rho }}_\varepsilon \), and \({\hat{\jmath }}_\varepsilon \).
Lemma 5.7
(Auxiliary PDE) Assume Assumption 5.5. For any \(\varepsilon >0\) and any initial condition \({\hat{u}}_\varepsilon ^{\ell ,\circ }\) satisfying (51), there exists a solution \({\hat{u}}_\varepsilon ^\ell \) to the PDE (49) in the following sense: \({\hat{u}}_\varepsilon ^\ell :E\rightarrow [0,\infty )\) is such that
and for any \(\varphi \in C_c ^1({Q_T})\) with \(\varphi = 0\) at \(t=T\),
Define the pair \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\) by (50).
Then we have
-
(i)
\((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\in {\mathrm {CE}}(0,T)\) and
$$\begin{aligned} \widehat{{\mathcal {I}}}_\varepsilon (\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon ) = \frac{1}{2}\int _{{Q_{T}^0}}{\hat{b}}_0^2 {\hat{u}}_\varepsilon ^\ell \, \mathrm {d}y \mathrm {d}t. \end{aligned}$$(53) -
(ii)
\(\sup _{\varepsilon >0} \varepsilon {{\hat{E}}}_\varepsilon ({\hat{\rho }}_\varepsilon (0,\cdot )) \le |V(x_b)| + 1.\)
-
(iii)
The pair \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\) converges to \((\hat{\rho }_0,\hat{\jmath }_0)\) in the sense of Definition 3.2.
-
(iV)
There exists a function \({\hat{u}}_0^\ell \in L^2(0,T;H^1(\Omega ))\) such that
 (54)
(54)

Step 3: Conclude The convergence of \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\) to \((\hat{\rho }_0,\hat{\jmath }_0)\) in \({\mathrm {CE}}(0,T)\) is given by part (iii) of Lemma 5.7. The energy bound (41) is satisfied by part (ii), and note that this bound is independent of the regularity Assumption 5.5.
To prove the limsup-bound (42), we observe that
This concludes the proof of Theorem 5.4. \(\square \)
5.3 Proof of Lemma 5.7
We now prove the main Lemma 5.7 used for the proof of Theorem 5.4.
Step 1: Existence of the solution \({{\hat{u}}}_\varepsilon ^\ell \) Using classical methods such as those in [23] one finds a function \({{\hat{u}}}_\varepsilon ^\ell \) with
that satisfies the \(\varepsilon \)-independent bounds
and solves Eq. (49) in the weak form (52).
To briefly indicate the main steps in this existence proof, define the function \(B(t,y) := \int _{-1/2}^y {{\hat{b}}}_0(t,{{\tilde{y}}})\,d{{\tilde{y}}}\) and observe that the transformed function \({\hat{v}}_\varepsilon ^\ell := e^{-B}{\hat{u}}_\varepsilon ^\ell \) satisfies the equation
Applying the usual method of multiplying by the solution \({{\hat{v}}}_\varepsilon ^\ell \) and integrating we obtain this a priori estimate:

One then constructs by e.g. Galerkin approximation a sequence of approximating solutions of (56) that satisfy (57), for which one can extract a subsequence that converges to a limit. Upon transforming back to the function \({{\hat{u}}}_\varepsilon ^\ell \) one obtains the weak form (52) and the bounds (55b) and (55c).
In order to deduce (55a) from (55b) and (55c) one applies e.g. [41, Th. 5] with the compact embedding \(H^1({Q_{T}^0})\hookrightarrow L^2({Q_{T}^0})\). The missing \(L^2({Q_{T}^0})\)-estimate can be obtained from (55b) by applying the generalized Poincaré inequality of Lemma A.1 to \(\mu = {\hat{\gamma }}_\varepsilon ^\ell \) and observing that \({\hat{\gamma }}_\varepsilon ^\ell ([-1/2,1/2])\rightarrow \infty \) as \(\varepsilon \rightarrow 0\).
By the strong maximum principle and the positivity (51b) of the initial data the solutions \({{\hat{u}}}_\varepsilon ^\ell \) are strictly positive, and since \({\hat{\jmath }}_\varepsilon \in L^2({Q_T})\) the mass of \({\hat{\rho }}_\varepsilon (t) = \gamma _\varepsilon ^\ell {{\hat{u}}}_\varepsilon ^\ell (t)\) equals the mass of the initial data \({\hat{\gamma }}_\varepsilon ^\ell \), which is one by (51c).
Note that by Assumption 5.5 the function B is not only bounded but also independent of \(\varepsilon \), implying that the constants in (55) also are independent of \(\varepsilon \).
Step 2: Part (i), the value of \({\widehat{{\mathcal {I}}}}_\varepsilon ({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) The fact that \((\hat{\rho }_\varepsilon ,\hat{\jmath }_\varepsilon )\in {\mathrm {CE}}(0,T)\) follows from the regularity (55) of \({{\hat{u}}}_\varepsilon ^\ell \) and from the weak form (52) of the equation. The value of \({\widehat{{\mathcal {I}}}}_\varepsilon ({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) was already calculated before Lemma 5.7.
Step 3: Convergence of \(({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) By construction (see (51b)) the initial measures \({\hat{\rho }}_\varepsilon (0,\cdot )\) converge to \({\hat{\rho }}_0(0,\cdot )\). To prove convergence of \(({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) we therefore need to show convergence in the continuity equation.
For any test function \(\varphi \in C_b({Q_T})\),

Hence for any test function with support outside of \([0,T]\times \{\pm 1/2\}\), by Lemma 5.3,
Take any sequence \(\varepsilon _k\rightarrow 0\). By (58) the family of measures \(\hat{\rho }_{\varepsilon _k}\) is tight, and therefore it converges weakly on \([0,T]\times {\mathbb {R}}\), along a subsequence (denoted the same), to a measure \({\overline{\rho }}_0\) that is concentrated on \([0,T]\times \{\pm 1/2\}\), and therefore has the form
for some measurable function \({\overline{z}}_0:[0,T]\rightarrow [0,1]\).
Since the function B is bounded, we find that \(\hat{\jmath }_\varepsilon = -e^{B}\partial _y{\hat{v}}_\varepsilon ^\ell \) is bounded in \(L^2({Q_T})\), because
Hence, taking another subsequence, the flux \({\hat{\jmath }}_{\varepsilon _k}\) converges weakly in \(L^2({Q_T})\) to some \({\overline{\jmath }}_0 \in L^2({Q_T})\).
Combining these convergence statements of \(\hat{\rho }_{\varepsilon _k}\) and \(\hat{\jmath }_{\varepsilon _k}\), we find for any test function \(\varphi \in C^1_c({Q_T})\),
Therefore \(({\hat{\rho }}_{\varepsilon _k},{\hat{\jmath }}_{\varepsilon _k})\) converges to \(({{\overline{\rho }}}_0,{\overline{\jmath }}_0)\) in the sense of \({\mathrm {CE}}(0,T)\).
Finally, since \(\overline{\rho }_0\) is concentrated on \([0,T]\times \{\pm 1/2\}\), the limiting flux \({\overline{\jmath }}_0\) is piecewise constant in y with jumps only at \(\{\pm 1/2\}\), and \({\overline{\jmath }}_0\in L^2({Q_T})\) implies that \({{\overline{\jmath }}}_0\) vanishes outside of \((-1/2,+1/2)\). Therefore, the continuity equation \(0=\partial _t{\overline{\rho }}_0 + \partial _y{\overline{\jmath }}_0\) in the distributional sense implies that the flux is given by
Step 4: The limit \(({{\overline{\rho }}}_0,{{\overline{\jmath }}}_0)\) is equal to \(({\hat{\rho }}_0,{\hat{\jmath }}_0)\) We now show that the limit \({\overline{z}}_0\) obtained above coincides with the function \({{\hat{z}}}_0\) that characterizes \({\hat{\rho }}_0\) (see (43)). This proves that \(({{\overline{\rho }}}_0,{{\overline{\jmath }}}_0) = ({\hat{\rho }}_0,{\hat{\jmath }}_0)\) and \({\overline{u}}_0 = {{\hat{u}}}_0\) on \({Q_{T}^0}\).
By further extracting subsequences we can assume that
By passing to the limit in (50) we find that \({\overline{\jmath }}_0 = -\,\partial _y\overline{u}_0 + {\hat{b}}_0\mathbb {1}_{{Q_{T}^0}}{\overline{u}}_0\) almost everywhere in \({Q_T}\). In combination with (59) this means that for almost every \(t\in [0,T]\), the function \(y\mapsto {\overline{u}}_0(t,y)\) is a weak solution of the ODE
This is a first-order ODE in y on the interval \((-1/2,1/2)\), and we show below that \({{\overline{u}}}\) satisfies not one but two boundary conditions, at \(\pm 1/2\):
The solution of (60) with left boundary condition \({\overline{u}}_0(t,-1/2)= {\overline{z}}_0(t)\) is given by
Since
the second boundary condition \({\overline{u}}_0(t,+1/2)=0\) therefore enforces
Combined with the convergence assumption on the initial condition \(\hat{\rho }_\varepsilon (0,dy)\), which implies \({\overline{z}}_0(0)={\hat{z}}_0(0)\), it follows that \({\overline{z}}_0 = {\hat{z}}_0\). This unique characterization of the limit \(({{\overline{\rho }}},{{\overline{\jmath }}}_0)\) also implies that the convergence holds not only along subsequences but in the sense of a full limit \(\varepsilon \rightarrow 0\).
Step 5: Prove the boundary conditions (61) on \({{\overline{u}}}_0\) To prove the left boundary condition in (61), let \(U_\delta \) be a small neighborhood around \(-1/2\) of length \(2\delta >0\). Since \(\partial _y{\hat{u}}_\varepsilon ^\ell \) is bounded in \(L^2({Q_T})\) by (55b), there is an \(\alpha \in L^2(0,T)\) such that
We can then estimate for any non-negative \(\psi \in C([0,T])\),
For each \(\delta >0\), \(\int _{U_\delta }{\hat{g}}_\varepsilon ^\ell (y)dy\) converges to 1 as \(\varepsilon \rightarrow 0\), and
Therefore,
Noting that \(\delta >0\) is arbitrary and repeating the argument for the reversed inequality, we find that
Since the trace map \(w\in L^2(0,T;H^1({Q_{T}^0}))\mapsto w(\cdot ,-1/2)\in L^2(0,T)\) is weakly continuous, the sequence of functions \(t\mapsto {\hat{u}}_\varepsilon ^\ell (t,-1/2)\) converges weakly in \(L^2(0,T)\) to the limit \({{\overline{u}}}_0(t,-1/2)\). This proves the first boundary condition in (61). The argument for the second boundary condition is similar, using that \(\hat{\gamma }_\varepsilon ^\ell \bigl ((1/2-\delta ,1/2+\delta )\bigr )\rightarrow \infty \) as \(\varepsilon \rightarrow 0\).
This concludes the proof of Lemma 5.7.
5.4 Proof of Lemma 5.6
Approximation results of this type are very common; see e.g. [2, Theorem 6.1] or [34, Lemma 4.7]. Fix a pair \(({\hat{\rho }}_0,{\hat{\jmath }}_0)\) with \({\widehat{{\mathcal {I}}}}_0({\hat{\rho }}_0,{\hat{\jmath }}_0)<\infty \), and write \({\hat{\rho }}_0\) in terms of the absolutely continuous function \({{\hat{z}}}_0\) as in (43).
We first approximate \({{\hat{z}}}_0\) by a sequence of more regular functions \({{\hat{z}}}_\eta \), for \(\eta \rightarrow 0\). We do this by first extending \({{\hat{z}}}_0\) to \({\mathbb {R}}\) by constants:
The extended function \({{\hat{z}}}_0\) again is non-increasing; we then regularize by convolution by setting
where \(\alpha _\eta (s) := \eta ^{-1}\alpha (s/\eta )\) is a regularizing sequence.
Then \({{\hat{z}}}_\eta \rightarrow {{\hat{z}}}_0\) in \(W^{1,1}({\mathbb {R}})\), and therefore the corresponding pair \(({\hat{\rho }}_\eta ,{\hat{\jmath }}_\eta )\) converges in \({\mathrm {CE}}\) to \(({\hat{\rho }}_0,{\hat{\jmath }}_0)\) Since the function S in (15) is jointly convex in its two arguments, we have
Next, define \({{\overline{z}}}(t) := 1/2 -t/{4T}\), and note that \({{\overline{z}}}\) and \(-\,\partial _t {{\overline{z}}}\) are bounded away from zero on [0, T]. For each \(\eta \in (0,1)\), the convex combination
also satisfies \(\inf \widetilde{z}_{\eta }\), \(\inf (-\partial _t \widetilde{z}_{\eta }) > 0\). Again using the convexity of S we find that
Setting \({\hat{\rho }}_0^{\eta } (t) = \widetilde{z}_{\eta }(t)\delta _{-1/2} + (1-\widetilde{z}_{\eta }(t))\delta _{1/2}\) and defining \({\hat{\jmath }}_0^{\eta }\) accordingly, we then have
The sequence \(({\hat{\rho }}_0^{\eta } , {\hat{\jmath }}_0^{\eta })\) therefore satisfies the claim of Lemma 5.6.
5.5 The initial data in (51) can be realized
In the proof of Theorem 5.4 we postulated a choice of initial data with certain properties. The next lemma shows that it possible to construct such initial data.
Lemma 5.8
For any given \(\rho ^\circ = z^\circ \delta _{-1/2} + (1-z^\circ )\delta _{1/2}\) it is possible to choose a sequence \({{\hat{u}}}_\varepsilon ^{\ell ,\circ }\) satisfying the requirements (51).
Proof
For instance one may choose
where \(a_\varepsilon \rightarrow 0\) can be tuned in order to achieve the mass constraint (51c). One can verify that the definitions of \(\gamma _\varepsilon \) and \(\gamma _\varepsilon ^\ell \) imply that \(1-z_0+a_\varepsilon \le 1\), and because \({Z_\varepsilon ^\ell }/{Z_\varepsilon }<1\) we have the bound \(\Vert {{\hat{u}}}_\varepsilon ^{\ell ,\circ }\Vert _\infty \le 1\).
To show (51e) for this choice we can write
Splitting the integral into parts, the integral over \((1/4,\infty )\) equals
The integral over the remaining interval \((-\infty ,1/4)\) can be bounded from above by
5.6 Recovery sequence for the untransformed system
Theorem 5.9
Let V satisfy Assumption 4.1. Let \((\rho _0,j_0)\in {\mathrm {CE}}(0,T)\) satisfy \({\mathcal {I}}_0(\rho _0,j_0)< \infty \). Then there exists a sequence \((\rho _\varepsilon ,j_\varepsilon )\in {\mathrm {CE}}(0,T)\) such that \((\rho _\varepsilon ,j_\varepsilon ){\mathop {\longrightarrow }\limits ^{\mathrm {CE}}}(\rho _0,j_0)\), \(\sup _{\varepsilon >0}\varepsilon E_\varepsilon (\rho _\varepsilon (0))<\infty \), and \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon ) \longrightarrow {\mathcal {I}}_0(\rho _0,j_0)\).
Proof
Since \({\mathcal {I}}_0(\rho _0,j_0)< \infty \), \(\rho _0\) and \(j_0\) have the structure (17) in terms of z and j. Define the corresponding \(({\hat{\rho }}_0,{\hat{\jmath }}_0)\) by
By construction \({\widehat{{\mathcal {I}}}}_0({\hat{\rho }}_0,{\hat{\jmath }}_0) = {\mathcal {I}}_0(\rho _0,j_0)<\infty \), and therefore by Theorem 5.4 there exists a sequence \(({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\) that converges to \(({\hat{\rho }}_0,{\hat{\jmath }}_0)\) with \({\hat{{\mathcal {I}}}}_\varepsilon ({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\longrightarrow {\mathcal {I}}_0(\rho _0,j_0)\).
We define \((\rho _\varepsilon ,j_\varepsilon )\) by back-transforming the relation (39):
By definition then \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon ) = {\widehat{{\mathcal {I}}}}_\varepsilon ({\hat{\rho }}_\varepsilon ,{\hat{\jmath }}_\varepsilon )\longrightarrow {\mathcal {I}}_0(\rho _0,j_0)\). The only remaining fact to check is the convergence \((\rho _\varepsilon ,j_\varepsilon ){\mathop {\longrightarrow }\limits ^{\mathrm {CE}}}(\rho _0,j_0)\).
By Theorem 5.4, \({\mathcal {I}}_\varepsilon (\rho _\varepsilon ,j_\varepsilon )\) and \(\varepsilon E_\varepsilon (\rho _\varepsilon (0))\) are bounded. We next verify the convergence (33) of the initial data. Note that by the properties of push-forwards,
\(\square \)
Lemma 5.10
-
1.
\(u_\varepsilon ^{\ell ,\circ }\) is bounded uniformly in x and \(\varepsilon \);
-
2.
for small \(\varepsilon \), on the interval \((-\infty ,\tfrac{1}{2} (x_a+x_0))\) the function \(u_\varepsilon ^{\ell ,\circ }\) is equal to a constant \(a_\varepsilon \), with \(\lim _{\varepsilon \rightarrow 0} a_\varepsilon = z_0(0)\);
-
3.
for small \(\varepsilon \), on the interval \((\tfrac{1}{2} (x_0+x_{b-}),\infty )\) the function \(u_\varepsilon ^{\ell ,\circ } Z_\varepsilon /Z_\varepsilon ^\ell \) is equal to a constant \(b_\varepsilon \), with \(\lim _{\varepsilon \rightarrow 0} b_\varepsilon = 1-z_0(0)\).
Assuming this lemma for the moment, we calculate for any \(\varphi \in C_b({\mathbb {R}})\) that
Similarly,
Finally, by the uniform boundedness of \(u_\varepsilon ^{\ell ,\circ }\) on \({\mathbb {R}}\),
Therefore \(\rho _\varepsilon (0,\cdot )\) satisfies the convergence condition (33). Theorem 4.7 then implies that up to extraction of a subsequence, \((\rho _\varepsilon ,j_\varepsilon )\) converges to a limit \(({{\overline{\rho }}}_0,{{\overline{\jmath }}}_0)\); the only property to check is that \(({{\overline{\rho }}}_0,{{\overline{\jmath }}}_0) = (\rho _0,j_0)\).
Let \({{\overline{\rho }}}_0(t) = {{\overline{z}}}_0(t) \delta _{x_a} + (1-{{\overline{z}}}_0(t)) \delta _{x_b}\); by (33) we have \({{\overline{z}}}_0(0) = z_0(0)\). Recall from Lemma 4.6 that the function \(\phi _\varepsilon \circ y_\varepsilon ^{-1}\) converges uniformly on \({\mathbb {R}}\) to the function \({\mathrm {id}}_{1/2}\). We then calculate for any \(\psi \in C_b([0,T])\) that
On the other hand, since \(\phi _\varepsilon \) is uniformly bounded and converges to \({\mp } 1/2\) in neighbourhoods of \(x_a\) and \(x_b\), we also have
Since these two should agree for all \(\psi \in C_b([0,T])\), it follows that \({{\overline{z}}}_0 = z_0\) and therefore \({{\overline{\rho }}}_0 = \rho _0\).
Finally, to show that also \({{\overline{\jmath }}}_0 = j_0\), note that both \({{\overline{\jmath }}}_0\) and \(j_0\) are of the form \(j(t) \mathbb {1}_{[x_a,x_b]}\), and since they satisfy the continuity equation with the same measure \(\rho \) we have \(\partial _y({{\overline{\jmath }}}_0-j_0) = 0\) in duality with \(C_c^{1,0}([0,T]\times {\mathbb {R}})\). It follows that \({{\overline{\jmath }}}_0 = j_0\) almost everywhere on \([0,T]\times {\mathbb {R}}\).
We still owe the reader the proof of Lemma 5.10.
Proof of Lemma 5.10
Part 1 follows directly from the boundedness of \({{\hat{u}}}_\varepsilon ^{\ell ,\circ }\) (see (51a)) and the transformation (63). For part 2, recall from (51d) that \({{\hat{u}}}_\varepsilon ^{\ell ,\circ }\) is a constant (say \(a_\varepsilon \)) on the interval \((-\infty ,-1/4)\). Since \({{\hat{u}}}_\varepsilon ^{\ell ,\circ }{\hat{\gamma }}_\varepsilon ^\ell \) converges to \(z_0(0)\delta _{-1/2} + (1-z_0(0))\delta _{1/2}\), the constant \(a_\varepsilon \) converges to \(z_0(0)\). Since \(y=-1/2\) is an interior point of the interval \((-\infty ,-1/4)\), for sufficiently small \(\varepsilon \) the function \(y_\varepsilon \) maps the interval \(\bigl (-\infty , \tfrac{1}{2}(x_a+x_0)\bigr )\) into \((-\infty ,-1/4)\) (see Lemma 4.6) and therefore \(u_\varepsilon ^{\ell ,\circ }\) equals \(a_\varepsilon \) on \(\bigl (-\infty , \tfrac{1}{2}(x_a+x_0)\bigr )\).
For part 3 the argument is very similar, only replacing the left-normalized \({\hat{\gamma }}_\varepsilon ^\ell \) by the standard normalized \({\hat{\gamma }}_\varepsilon \). \(\square \)
References
Ambrosio, L., Gigli, N., Savaré, G.: Gradient Flows: in Metric Spaces and in the Space of Probability Measures. Springer Science & Business Media, (2008)
Arnrich, S., Mielke, A., Peletier, M.A., Savaré, G., Veneroni, M.: Passing to the limit in a Wasserstein gradient flow: from diffusion to reaction. Calc. Var. Part. Differ. Equ. 44(3–4), 419–454 (2012)
Bovier, A., den Hollander, F.: Metastability: A Potential-Theoretic Approach. Springer (2016)
Bertini, L., De Sole, A., Gabrielli, D., Jona-Lasinio, G., Landim, C.: Macroscopic fluctuation theory. Rev. Mod. Phys. 87(2), 593 (2015)
Berglund, N., Gentz, B.: Noise-Induced Phenomena in Slow-Fast Dynamical Systems: A Sample-Paths Approach. Springer Science & Business Media, (2005)
Bakry, D., Gentil, I., Ledoux, M.: Analysis and Geometry of Markov Diffusion Operators, vol. 348. Springer Science & Business Media, (2013)
Bonaschi, G.A., Peletier, M.A.: Quadratic and rate-independent limits for a large-deviations functional. Cont. Mech. Thermodyn. 28, 1191–1219 (2016)
Braides, A.: Gamma-Convergence for Beginners. Oxford University Press (2002)
Cordero-Erausquin, D.: Some applications of mass transport to Gaussian-type inequalities. Arch. Ration. Mech. Anal. 161(3), 257–269 (2002)
Dawson, D.A., Gärtner, J.: Large deviations from the McKean–Vlasov limit for weakly interacting diffusions. Stochastics 20(4), 247–308 (1987)
Dawson, D.A., Gärtner, J.: Multilevel large deviations and interacting diffusions. Probab. Theor. Relat. F. 98(4), 423–487 (1994)
Duong, M.H., Lamacz, A., Peletier, M.A., Sharma, U.: Variational approach to coarse-graining of generalized gradient flows. Calc. Var. Part. Diff. Equ. 56(4), 100 (2017)
Dal Maso, G.: An Introduction to \(\Gamma \)-Convergence. Progress in Nonlinear Differential Equations and Their Applications, vol. 8. Birkhäuser, Boston (1993)
Dudley, R.M.: Real Analysis and Probability. Cambridge University Press (2004)
Evans, L.C., Tabrizian, P.R.: Asymptotics for scaled Kramers-Smoluchowski equations. SIAM J. Math. Anal. 48(4), 2944–2961 (2016)
Feng, J., Kurtz, T.G.: Large Deviations for Stochastic Processes. American Mathematical Society, Mathematical Surveys and Monographs (2006)
Friedman, A.: Partial Differential Equations of Parabolic Type. Prentice-Hall, Englewood Cliffs, New Jersey (1964)
Gorban, A., Mirkes, E., Yablonsky, G.: Thermodynamics in the limit of irreversible reactions. Phys. A: Stat. Mech. Appl. 392(6), 1318–1335 (2013)
Gavish, N., Nyquist, P., Peletier, M.A.: Large deviations and gradient flows for the Brownian one-dimensional hard-rod system (2019). https://doi.org/10.1007/s11118-021-09933-0
Hänggi, P., Talkner, P., Borkovec, M.: Reaction-rate theory: fifty years after Kramers. Rev. Mod. Phys. 62(2), 251–342 (1990)
Kramers, H.A.: Brownian motion in a field of force and the diffusion model of chemical reactions. Physica 7(4), 284–304 (1940)
Kraaij, R.C.: Flux large deviations of weakly interacting jump processes via well-posedness of an associated Hamilton-Jacobi equation (2017). https://doi.org/ 10.3150/20-BEJ1281
Lions, J.L.: Quelques Méthodes de Résolution des Problèmes aux Limites non Linéaires. Dunod, Paris (1969)
Liero, M., Mielke, A., Peletier, M.A., Renger, D.R.M.: On microscopic origins of generalized gradient structures. Discret. Cont. Dyn. Syst.-Ser. S 10(1), 1 (2017)
Ladyženskaja, O.A. Solonnikov, V.A., Ural’ceva, N.N.: Linear and Quasi-linear Equations of Parabolic Type, vol. 23 of Translations of Mathematical Monographs. American Mathematical Society, (1968)
Lu, J., Vanden-Eijnden, E.: Exact dynamical coarse-graining without time-scale separation. J. Chem. Phys. 141(4), 044109 (2014)
Mariani, M.: A Gamma-Convergence Approach to Large Deviations. Ann. Sc. Norm. Super. Pisa Cl. Sci. 18(5), 951–976 (2012)
Mielke, A.: On Evolutionary \(\Gamma \)-convergence for gradient systems. In: Macroscopic and Large Scale Phenomena: Coarse Graining, Mean Field Limits and Ergodicity, pp. 187–249. Springer, (2016)
Mielke, A., Montefusco, A., Peletier, M.A.: Exploring families of energy-dissipation landscapes via tilting-three types of EDP convergence (2020). https://doi.org/10.1007/s00161-020-00932-x
Mielke, A., Peletier, M.A., Renger, D.R.M.: On the relation between gradient flows and the large-deviation principle, with applications to Markov chains and diffusion. Potent. Anal. 41(4), 1293–1327 (2014)
Olver, F.W.J.: Asymptotics and Special Functions. Academic Press (1974)
Peletier, M.A.: Variational modelling: Energies, gradient flows, and large deviations. Arxiv preprint arXiv:1402:1990, (2014)
Patterson, R.I.A., Renger, D.R.M.: Large deviations of jump process fluxes. Math. Phys., Anal. Geom. 22(3), 21 (2019)
Peletier, M.A., Renger, D.R.M.: Fast reaction limits via \(\Gamma \)-convergence of the flux functional (2020). https://doi.org/10.1007/s10884-021-10024-2
Peletier, M.A., Rossi, R., Savaré, G., Tse, G.: Jump processes as generalized gradient flows. arXiv preprint arXiv:2006.10624, (2020)
Peletier, M.A., Savaré, G., Veneroni, M.: From diffusion to reaction via \(\Gamma \)-convergence. SIAM J. Math. Anal. 42(4), 1805–1825 (2010)
Peletier, M.A., Savaré, G., Veneroni, M.: Chemical reactions as \(\Gamma \)-limit of diffusion. SIAM Rev. 54, 327–352 (2012)
Renger, D.: Large Deviations of Specific Empirical Fluxes of Independent Markov Chains, with Implications for Macroscopic Fluctuation Theory. Weierstraß-Institut für Angewandte Analysis und Stochastik, Berlin (2017)
Santambrogio, F.: Optimal Transport for Applied Mathematicians. Birkhäuser (2015)
Schlichting, A.: The Eyring–Kramers formula for Poincaré and logarithmic Sobolev inequalities. PhD thesis, Universität Leipzig, (2012)
Simon, J.: Compact sets in the space \({L}^p(0,{T};{B})\). Ann. Mat. Pura Appl. 146, 65–96 (1987)
Weinan, E., Vanden-Eijnden, E.: Metastability, conformation dynamics, and transition pathways in complex systems. In: Multiscale Modelling and Simulation, pp. 35–68. Springer, (2004)
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funding
The Funding was provided by Nederlandse Organisatie voor Wetenschappelijk Onderzoek (Grant No. 613.001.552)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by A. Mondino.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Auxiliary results
Auxiliary results
1.1 A generalized Poincaré inequality
Lemma A.1
For any \(-\infty<a<b<\infty \) and for all bounded non-negative Borel measures \(\mu \) on [a, b], we have the following inequality:
with a constant \(C>0\) that only depends on a and b.
Proof
By density it suffices to prove the inequality for \(f\in C^1([a,b])\). For \(x,y\in [a,b]\) we have
and therefore
The assertion follows by choosing e.g. \(\alpha = 1/2(b-a)\). \(\square \)
1.2 Laplace’s method
Lemma A.2
(Laplace’s method; see e.g. [31, Sec. 7.2]) Let \(f : [a,b] \rightarrow {\mathbb {R}}\) be twice differentiable.
-
(a)
Suppose that for some \(x_i \in (a,b)\), we have \(f(x_i) = \inf _{[a,b]} f\). Then
$$\begin{aligned} \int _a^b e^{-nf(x)}dx = \left[ 1 + o(1)\right] \sqrt{\frac{2\pi }{n f''(x_i)}} e^{-n f(x_i)} \quad \text {as }n \rightarrow \infty . \end{aligned}$$ -
(b)
If \(x_i = a\) or \(x_i=b\), then
$$\begin{aligned} \int _a^b e^{-nf(x)}dx = \left[ 1 + o(1)\right] \frac{1}{2} \sqrt{\frac{2\pi }{n f''(x_i)}} e^{-n f(x_i)} \quad \text {as } n \rightarrow \infty . \end{aligned}$$
1.3 Duality characterizations
Lemma A.3
(Duality characterization of quadratic entropies) For \(X=[0,T]\times {\mathbb {R}}^d\), \(f,g: X \rightarrow {\mathbb {R}}\) measurable with \(g > 0\), and any nonnegative Borel measure \(\mu \), we have the characterization
A proof is given for instance in [2, Lemma 3.4]. The representation there can be further simplified by setting \(a=-b^2/2\).
Lemma A.4
(Duality characterization of S) The function S defined in (15) has the alternative characterization
where the infimum is taken over smooth functions \(u:[-1/2,+1/2]\rightarrow [0,\infty )\) satisfying the boundary conditions \(u(-1/2)=z\) and \(u(+1/2)=0\) and the positivity requirement \(u'(y)>0\) for all \(y\in (-1/2,1/2)\). The optimal function u is the polynomial
Proof
This result is very similar to that in [24, Prop. A1], which dealt with the slightly different argument \((j^2+{u'}^2)/u\) with strictly positive boundary conditions for u; the sign of j and the degeneracy of u at the boundary \(y=1/2\) require some modifications.
If \(j=0\), then the integral equals \(\int _{-1/2}^{1/2}4 (v')^2\) in terms of \(v=\sqrt{u}\), for which the optimal function v is linear and the corresponding value of the integral equals 4z. This proves the identity (64) for the case \(j=0\).
If \(j<0\), then one can estimate
which establishes the identity (64) for the case \(j<0\). In the case \(j>0\) but \(z=0\), a similar calculation at \(y=-1/2\) yields the same conclusion.
The final case to consider is \(j,z>0\). Following the argument of [24], we set \(f(u,u') = (j+u')^2/4u\), such that the Euler-Lagrange equation is \(-(\partial _{u'} f(u,u'))' + \partial _u f(u,u') = 0\). It follows by differentiating (or applying Noether’s theorem) that the Hamiltonian \(u'\partial _{u'}f(u,u') - f(u,u') = ({u'}^2 - j^2)/4u\) is constant on \([-1/2,1/2]\), say equal to \(\gamma /4\). By differentiating the resulting equation \({u'}^2 = j^2 + \gamma u\) we find that all solutions are second-order polynomials, and by applying the boundary conditions on u we obtain (65) and \(\gamma = 4(z-j)\). The identity (64) then follows from a direct calculation. \(\square \)
1.4 Proof of Lemma 2.2
Results of this type are fairly standard; similar arguments can be found in [12, Th. 2.3] or [19, Lemmas 8.4 and 8.5]. Since we could not find a complete result, we provide a proof here. For the length of this proof we use subscripts t to indicate time slices.
Step 1: Alternative duality estimate We have
One first obtains this inequality for \(f\in C^{1,2}_c({Q_T})\) by substituting \(b=\partial _x f\) in (8) and using the narrow continuity of \(\rho \) with a standard truncation and regularization in time. For general \(f\in C^{1,2}_b({Q_T})\) the inequality follows from a regularized truncation in space, using the finiteness of the measure \(\rho \) on \({Q_T}\).
Step 2: Dual equation Fix \(\varphi \in C_c^{0,1}({Q_T})\) and \(\psi \in C_c^\infty ({\mathbb {R}})\). Define \(g\in C_b^{1,2}({Q_T})\) as the solution of the backward parabolic equation
Such a solution exists by e.g. [17, Th. 1.12]. By calculating the derivative explicitly, we find that
implying that
The function \(f := 2\log g\) is an element of \(C^{1,2}_b({Q_T})\) and satisfies the equation
with final datum \(f_T = \psi \). Substituting in (66) yields
By reorganizing this inequality and applying the Donsker-Varadhan dual characterization of the relative entropy we find
Taking the supremum over \(\psi \in C_c^\infty ({\mathbb {R}})\) and \(\varphi \in C^{1,2}_c({Q_T})\), and applying also the dual formulation of the Fisher Information [16, Lemma D.44], we find
Summarizing, \({\mathcal {I}}_\varepsilon (\rho ,j)<\infty \) implies that \(\rho \) is absolutely continuous on \({Q_T}\) with respect to \(\gamma _\varepsilon (\mathrm {d}x)\mathrm {d}t\), or equivalently to with respect to Lebesgue measure on \({Q_T}\); the density \(u := \mathrm {d}\rho /\mathrm {d}\gamma _\varepsilon \) satisfies \(\partial _x u\in L^1_{\mathrm {loc}}({Q_T})\). This proves parts 2 and 3 of Lemma 2.2.
Step 3: Regularity of j To show that \(j\ll \rho \), we use the regularity of u to rewrite
By the dual characterization of \(L^2({Q_T};\rho )\), finiteness of \({\mathcal {I}}_\varepsilon (\rho ,j)\) implies that there exists \(v\in L^2({Q_T};\rho )\) with \(j = v\rho \), and we have the estimate
Step 4: Rewriting \({\mathcal {I}}_\varepsilon \) Finally, to show the identity (21), we note that \(v\in L^2({Q_T};\rho )\) implies that the curve \(t\mapsto \rho _t\) is absolutely continuous in the Wasserstein sense [1, Th. 8.3.1]. By [1, Th. 10.4.9], the bound on \(\partial _x u_t/u_t\) implies that the global Wasserstein slope \(|\partial E_\varepsilon |(\rho _t)\) is bounded and \(\partial _x u_t/u_t\) is an element of the Fréchet subdifferential. Finally, by the chain rule [1, Sec. 10.1.2], we have
Expanding the square in (68) establishes (21) with an inequality.
Step 5. Inverting the argument The argument up to now can be summarized as “if \({\mathcal {I}}_\varepsilon (\rho ,j)\) is finite, then \(\rho \) and j are regular and identity (21) holds as an inequality”. Vice versa, if the regularity conditions on \(\rho \) and j are satisfied and the right-hand side in (21) is finite, then the calculations can be reversed, and we find that \({\mathcal {I}}_\varepsilon \) is finite and that the inequality is an identity. This concludes the proof.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Peletier, M.A., Schlottke, M.C. Gamma-convergence of a gradient-flow structure to a non-gradient-flow structure. Calc. Var. 61, 103 (2022). https://doi.org/10.1007/s00526-022-02190-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00526-022-02190-y