
Abstract
High loads of suspended sediments in rivers are known to cause detrimental effects to potable water sources, river water quality, irrigation activities, and dam or reservoir operations. For this reason, the study of suspended sediment load (SSL) prediction is important for monitoring and damage mitigation purposes. The present study tests and develops machine learning (ML) models, based on the support vector machine (SVM), artificial neural network (ANN) and long short-term memory (LSTM) algorithms, to predict SSL based on 11 different river data sets comprising of streamflow (SF) and SSL data obtained from the Malaysian Department of Irrigation and Drainage. The main objective of the present study is to propose a single model that is capable of accurately predicting SSLs for any river data set within Peninsular Malaysia. The ANN3 model, based on the ANN algorithm and input scenario 3 (inputs consisting of current-day SF, previous-day SF, and previous-day SSL), is determined as the best model in the present study as it produced the best predictive performance for 5 out of 11 of the tested data sets and obtained the highest average RM with a score of 2.64 when compared to the other tested models, indicating that it has the highest reliability to produce relatively high-accuracy SSL predictions for different data sets. Therefore, the ANN3 model is proposed as a universal model for the prediction of SSL within Peninsular Malaysia.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
The background of the present study is first described in this section. This is followed by descriptions of the literature review, research gap, and contributions of the present study.
Background
The conservation of river water quality is important for human civilization as river water often represents a source of potable water while also being used for irrigation purposes in many regions, including Peninsular Malaysia1,2,3,4. High suspended sediment loads (SSLs), which essentially comprise of tiny clay, silt, and sand particles, are known to have detrimental effects on the quality of river water as the sediments may act as transport mediums for pollutants and bacteria5,6. The pollutants include phosphorus and heavy metals namely zinc, mercury, and manganese. High suspended sediment loads (SSLs) also affect the ecosystems within rivers by reducing the survivability of aquatic plants as less sunlight is able to penetrate through the river water and be utilised for photosynthesis. History shows many instances of pollutions and disasters caused by unmonitored or unregulated SSL in Peninsular Malaysia and around the globe. In 2016, it was reported by Malaysia’s Natural Resources and Environment Minister that a major Malaysian river recorded a Nephelometric Turbidity Unit (NTU) of 6000, indicating a significantly high concentration of suspended sediments causing poor water quality. Recently in 2021, Sungai Pinang was reported to be polluted with sediments consisting of broken-down organic matter, causing the river to have a black appearance. This sediment-based pollution was a source of foul stench affecting a nearby food court and condominium within the vicinity of the Karpal Singh Drive. Also very recently in 2021, 305 lakes and rivers in Minnesota, United States were listed as too polluted to meet the required standards. Among the causes of high pollution were high sediment concentrations, which harmed fish as they struggled to find food due to high bacteria environments and algal blooms caused by eutrophication. Toxic algal blooms caused by sediments richly leached with nutrients such as phosphorus were also reported in 2018 at the St. Lucie River, Florida, United States, causing respiratory problems as well as irritation in the eyes and noses of the locals. Increased SSLs may also have an effect on dam and reservoir operations1,7. Dam inlets and channels can be obstructed by suspended sediments, while reservoir capacity may be reduced due to the settling of suspended sediments caused by relatively slow-moving water in the reservoir vicinity. Therefore, the ability to foresee the SSL within a particular river through predictions is especially important as a means to preserve the quality and supply of river water resources; to minimize or mitigate damages to the environment and hydrological structures namely dams and reservoirs; and to ensure the healthy continuity of hydrology-related activities such as irrigation4,8.
Literature review
Traditionally, the sediment rating curve (SRC), which is a fitted relationship between suspended sediment concentration and river water discharge, has been utilised to assess trends and obtain predictions of SSLs, albeit having long response times and requiring a lot of information. However, a branch of artificial intelligence known as machine learning (ML), has been shown to effectively address these issues5 while producing more accurate SSL predictions compared to SRCs1,2,3,9,10,11. ML and deep learning, which is a more specialized version of ML typically consisting of neural networks, have also been used to solve important prediction problems within various fields. ML algorithms such as the decision tree (DT), random forest (RF), support vector machine (SVM) have been used for short-term water quality prediction to improve water management and pollution control, maize crop-yield prediction, and blockchain financial products earnings prediction to reduce concern of investors towards the risks and returns of financial products blockchain technology-based applications12,13,14; while deep learning algorithms such as the artificial neural network (ANN), long short-term memory (LSTM), and gated recurrent unit (GRU) have lately been utilized to solve more relatively complex problems such as the prediction of points-of-interest for purposes such as monitoring and maintaining public health following the coronavirus diseases (COVID-19), the prediction of greenhouse climate to ensure crop growth stability, and the prediction of health data with privacy reservation to combat the issue of missing data due to healthcare equipment failure and system updates15,16,17,18. In recent years, the artificial neural network (ANN) and support vector machine (SVM) algorithms have been shown to be among the most established and effective algorithms for application in the prediction of SSLs as shown by numerous existing literature3,6,11,19,20,21,22,23,24,25,26,27,28,29,30. Other than the ANN and SVM, other algorithms have also been studied for the purpose of SSL prediction. Meshram et al.9 studied the iterative classifier optimizer-based pace regression (ICO-PR) and iterative classifier optimizer-based random forest (ICO-RF) for SSL prediction in the Seonath River basin, India. It was shown that the ICO-RF is more accurate than the ICO-PR, and stand-alone PR and RF models. The study by Samadianfard et al.31 hybridized RF and multi-layer perceptron (MLP) with genetic algorithm (GA) and stochastic gradient descent (SGD) to produce four suspended sediment concentration (SSC) predictive algorithms namely GA-RF, GA-MLP, SGD-RF, and SGD-MLP. These algorithms were tested using data from the Minnesota and San Joaquin rivers; and it was determined that the GA-RF and GA-MLP models performed the best in predicting SSC for the Minnesota River, while the SGD-RF and SGD-MLP models were the most accurate for the San Joaquin River. Shadkani et al.32 used MLP, MLP-SGD, and gradient boosted tree (GBT), to predict SSL for the St. Louis and Chester stations along the Mississippi River, United States. It was found that the SGD optimization on the MLP resulted in more accurate SSL predictions, hence SGD-MLP was put forward as the most accurate model for SSL prediction. Hazarika et al.5 applied the coiflet wavelet-based large margin distribution machine-based regression (LDMR) and coiflet wavelet-based large margin distribution machine-based extreme learning machine (ELM) to predict SSL in the Tawang Chu River, India. The study showed that the two coiflet wavelet-based models produced better predictions compared to other tested models based on twin support vector regression (SVR), stand-alone LDMR, and stand-alone ELM. AlDahoul et al.2 studied the application of long short-term memory in predicting SSL at the Johor River basin, Malaysia. It was demonstrated that LSTM is capable of outperforming several other ML algorithms namely elastic net linear regression (ENLR), ANN, and extreme gradient boosting (XGB). The prediction of SSL using LSTM was also investigated in the study by Nourani and Behfar33, in which it was found that the LSTM-based models were superior to classical feed-forward neural networks in predicting SSL at the Mississippi River. The adaptive neuro-fuzzy inference system (ANFIS) was trialled with different membership functions to predict SSL for the Cumberland River, United States in the study by Babanezhad et al.34. ANFIS with the trimf membership function was found to produce the best predictive performance among the tested models, including ant colony optimization-based fuzzy inference system (ACOFIS). ANFIS was also hybridized with the bat algorithm (ANFIS-BA) in the study by Ehteram et al.35, in which it was found that ANFIS-BA was more reliable for SSL prediction in the Atrek River, Iran compared to other tested models namely ANFIS hybridized with whale algorithm (ANFIS-WA), and hybridized multi-feedforward neural network (MFNN) models with the BA and WA algorithms (MFNN-BA and MFNN-WA). The study by Azamathulla et al.36 applied genetic expression programming-based (GEP) models to predict SSLs in the Muda River, Langat River, and Kurau River in Malaysia. The GEP-based model was discovered to produce better predictive performances when compared to the other tested models which are ANFIS and a benchmark regression model. The dynamic evolving neural fuzzy inference system was studied by Adnan et al.37 for the prediction of SSL at two locations within China, namely Guangyuan and Beibei. DENFIS was shown to have a higher predictive accuracy compared to the other two models tested, which are ANFIS with fuzzy c-means clustering (ANFIS-FCM) and multivariate adaptive regression splines (MARS). However, in the study by Yilmaz et al.1, MARS was found to be capable of predicting SSL for the Çoruh River basin with the lowest error, compared to models based on the artificial bee colony (ABC) and teaching–learning based optimization. Tao et al.8 applied the radial basis M5Tree (RM5Ttree) to predict SSL for the Trenton hydrological station on the Delaware River, United States8. Results of the study showed that the RM5Tree model produced predictions with enhanced accuracy and outperformed the other tested models based on the response surface method (RSM), ANN and the classical M5Tree. Using the same data set applied in the study by Tao et al.8, Salih et al.7 used M5P, attribute classifier M5P (AS-M5P), M5Rule (M5R) and K Star (KS) models to predict SSL7. Different input scenarios of streamflow (SF) and SSL were used in this study, in which it was found that M5P was superior among the tested models. A hybrid version of the M5P, named bagging-M5P, was utilized by Khosravi et al.38 for SSL prediction in the Estero Morales River, Chile. The study showed bagging-M5P to be superior to the classical M5P, reduced error pruning tree (REPT), instance-based learning (IBK), and hybridized versions of the REPT model. Tabatabaei et al.10 predicted SSL using data from the Ramian hydrological station on the Ghorichay River, Iran by utilizing an SRC model optimized with the non-dominated sorting genetic algorithm II (NSGA-II), which increased prediction efficiency. In the study by Uca et al.4, multiple linear regression (MLR) and ANN were tested to predict SSL for the Jenderam catchment, Malaysia. The results demonstrated the capability of MLR in outperforming ANN with regards to SSL prediction accuracy.
Research gap
A limitation that is present in majority of the aforementioned existing studies on SSL prediction is that most have focused on utilizing ML algorithms to develop predictive models for only one hydrological station or river, which means the models were developed based off of one data set. As the magnitude and behaviour of SSLs for each river is different, the suitability of certain ML algorithms for the task of SSL prediction may vary. Certain ML algorithms may be suitable and produce good SSL predictions for a hydrological station at a particular river but may not perform well in predicting SSLs for a different river, due to variance in anthropogenic and natural factors. In the case study of Peninsular Malaysia, existing studies have utilized ML algorithms, particularly ANN, MLR, LSTM, and GEP, to develop SSL predictive models2,4,27,28,29,36. Apart from the study by Azamathulla et al.36, all studies on SSL prediction within Peninsular Malaysia have focused on developing ML models solely based on data sets from single hydrological stations located in rivers such as Sungai Johor, Johor; Sungai Pari, Perak, Sungai Langat, Selangor, and the Jenderam catchment, Selangor. This creates a noteworthy research gap for the Peninsular Malaysia case study, as it is unknown whether there is a model or algorithm that is capable of producing accurate SSL predictions for multiple different rivers within the region. The present study contributes towards addressing this research gap through the development of predictive models for SSLs based on time series data sets of SF and SSLs from hydrological stations located along 11 different rivers throughout Peninsular Malaysia. The two established algorithms based on existing literature within the current field, namely SVM and ANN, were selected for utilization in the present study. In addition, LSTM was also chosen for the development of predictive models as it has recently been documented to have good ability in accurately predicting SSLs2,33, while also already performing well in other fields relating to flood forecasting, wind turbine fault diagnosis, rainfall-runoff modelling, building energy consumption forecasting, and drought forecasting39,40,41,42,43.
Contributions
The present study was motivated by the aforementioned cases of SSL pollution in the Malaysian and American rivers, such as Sungai Pinang and St. Lucie River. Early anticipation and mitigation measures through the application of ML models could have played a significant role in reducing damages towards the local people and natural habitat. As there are many novel and advanced SSL-predicting models being developed in different study regions and demonstrated in scientific literature, practical adoption of ML predictive models for real-life application hydrological stations may not be straightforward due to the uncertainty of whether a selected ML model is able to replicate its good performance for different rivers with varying SSL behaviour and magnitude due to different anthropogenic and natural factors. Therefore, the scientific novelty of the present study is the selection and proposal of a single predictive model that is capable of producing SSL predictions of good accuracy for different rivers throughout Peninsular Malaysia. The major contribution of the present study is the testing and development of predictive ML models based on 3 different ML algorithms for hydrological stations on 11 different rivers throughout Peninsular Malaysia, in order to determine and propose a single ML model that is capable of predicting SSLs with high accuracy for multiple different rivers. Using time series data of SF and SSL for each river, SVM, ANN, and LSTM are tested to predict SSLs for each river using four different input scenarios. The performance of each model is evaluated using selected performance evaluation measures, namely mean absolute error (MAE), root mean squared error (RMSE) coefficient of determination (R2) and ranking mean (RM). The ML model that produces the best SSL predictions for the most rivers and obtains the best average RM is then proposed as a universal model that may be used for any specific case study within Peninsular Malaysia. The findings obtained in the present study may mainly be of interest to hydrological organizations looking for suitable or proven ML models for practical application within Peninsular Malaysia, as the models have been developed and tested using 11 different river data sets within the selected region. However, audiences from abroad may also take interest in the findings of the present study as the proposed SSL predictive model may possibly produce accurate SSL predictions for case studies in other regions around the world as well. The method of selecting the best SSL predictive ML model in the present study, which is by using performance evaluation measures to determine the model that produces the best SSL predictions for the most rivers and obtains the best average RM, may also be a point of interest for a wider audience regardless of geographic location. The rest of the present study is organized as follows: Sect. 2 describes the materials and methods used to carry out the present study. Section 3 reports and discusses the results of the present study. Section 4 concludes the overall study.
Materials and methods
In this section, the materials and methods employed in the process of predicting SSL for the 11 selected rivers within Peninsular Malaysia are explained. Important information regarding the location and data of case study, model development process, ML algorithms, data pre-processing, and performance evaluation measures are described.
Location and data of case study
Peninsular Malaysia represents the western region of Malaysia comprising of 13 states and 2 federal territories. It encompasses a total area of 132,265 km2, which is about 40% of the total area of Malaysia; and is located just North of the equator. Peninsular Malaysia has approximately 1235 river basins44, with Sungai Pahang representing the longest river in the region at 459 km in length. In the present study, raw data in the form of daily average SF and daily total SSL were obtained from the Water Resources Management and Hydrology Division of the Malaysian Department of Irrigation and Drainage for different rivers within 11 states in Peninsular Malaysia. Based on the volume and continuity of the available data; and the relevance of the rivers to their respective state, one river is selected per state for the purpose of the present study. Information on the selected rivers for each state; identification and location of the hydrological measuring stations; and the duration of data provided by the respective station for each selected river is shown in Table 1.
Model development process
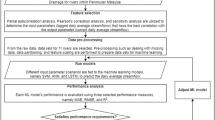
The model development process in the present study consists of raw data collection, data pre-processing, feature selection, model prediction, and performance analysis. This is illustrated as shown in Fig. 1.

The model development process employed in the present study.
Machine learning algorithms
Three ML algorithms were chosen for SSL prediction in the present study, which are SVM, and two deep learning algorithms namely ANN and LSTM. The SVM and ANN algorithms are considered established in the current field as they have been shown to produce good SSL predictions by many existing literature3,6,11,19,20,21,22,23,24,25,26,27,28,29,30, while the LSTM algorithm has recently been found to produce good SSL-predicting performances in recent studies2,33 and has already shown good performances in several other studies within different fields39,40,41,42,43. The Python programming language was selected for the development of SSL predictive models as it easy to comprehend and command, while also having good library support. The system specifications used to develop the predictive models in the present study are detailed in Table 2.
Support vector machine (SVM)
The SVM, also known as the decision support system, was proposed by Vapnik45. It represents a kernel-based algorithm that is abundantly used for pattern classification, function approximation, and also regression analyses24,26, especially in hydrological and time series simulations21. The version of SVM used to solve regression analyses is typically known as support vector regression (SVR), which is utilized to predict SSL in the present study. SVR generally works by estimating the learning data through the definition of a function, and determining the linear separation function to enable realistic results that reflect its statistical learning theory24. SVM is advantageous in the way that it has less tendency to overfit, has good ability to generalize, can simultaneously minimize estimation errors, and linearly separate inputs in a mapped high dimensional feature space26. However, SVM is sensitive to noise, hence its predictive ability reduces when the utilized data set is significantly noisy46,47,48. Its predictive performance also reduces with larger data sets due to an increase in training time48. SVM will also underperform in instances where there are fewer training data samples in comparison to the number of features for each data point. According to Buyukyildiz & Kumcu24, the SVM function is given by:
where \({(\alpha }_{i}-{\alpha }_{i}^{*})\) is the Lagrange multiplier, \(K(x,z)\) is the kernel function inside the multiplier, and \({b}_{i}\) is bias.
The main SVR hyperparameter that is tuned before running the SVR models is the kernel function. According to Himanshu et al.26 and Rahgoshay et al.21, among the four kernel functions that can be utilized namely radial basis functions (RBF), linear, polynomial, and sigmoid, RBF represents the best function to be used because of its good ability in handling complicated parameter space26. Through trial and error, it was indeed found that RBF gave the best results for SSL prediction in the present study. All other unmentioned SVR hyperparameters were left as their default values given that good predictions were obtained. The SVR hyperparameter tuning is shown in Table 3; while the time and space complexity of SVR are as follows:
where n is the number of data points and k is the number of support vectors.
Artificial neural network (ANN)
The ANN is a non-linear data processing mathematical algorithm that is able to connect multiple input variable to produce one or more output variables8,28. It is based on the biological functioning of the neural connections within the human brain19. This algorithm typically comprises of three layers, which are the input layer, hidden layer, and output layer. The hidden layer may consist of either one or multiple layers, and functions to make sense of a multidimensional expansion of the input layer19. The architecture of an ANN is made up of units called neurons, also known as nodes8,19,28. One of the drawbacks of ANN is that this algorithm can be computationally expensive and highly dependent on hardware capability49,50,51. The ANN requires processing power parallel with its structure, hence adequate processors are needed for the models to be trained with realistic and efficient training durations. In addition, there does not exist a specific set of rules to determine the ANN structure during model development or coding. Therefore, a suitable ANN architecture is to be achieved with model development experience and processes of trial-and-error. Other than that, the ANN has a black-box nature that limits its ability to pin-point causal relationships between variables and a particular output; and may overfit during training due to model interaction or non-linearity50,51. According to several studies8,19,28, the mathematical model of an ANN may be represented by:
where \({y}_{i}\) is the output variable, N is the number of neurons, \({\omega }_{ij}\) is the weight connecting the jth neuron and the ith neuron, \({x}_{i}\) is the input vector, bj is the bias of the jth neuron, and f is the activation function.
As mentioned by Mustafa et al.28, there is no certain rule for selecting the number of neurons in the hidden layer. Therefore, this hyperparameter must be selected through trial-and-error. Through testing, it was found that 2 hidden layers with 6 neurons in each layer was good for SSL prediction in the present study as it provided good adaptability in producing good results for the 11 different river data sets. Other than the number of neurons and number of hidden layers, different number of epochs, batch numbers, training algorithms, and activation functions were tested to find the best possible ANN architecture capable of adapting to the 11 different river data sets. The best ANN architecture found is shown in Table 4. Other unmentioned hyperparameters including initialiser, regulariser, and constraints, are remained default as good predictions are obtained. The time and space complexity of the ANN are as follows:
where n is the number of data points, e is the number of epochs, i is the number of input layer neurons, j is the number of second layer neurons, k is the number of third layer neurons, l is the number of output layer neurons, and z is the total number of neurons.
The train and validation loss vs epochs graphs are produced during each of the ANN models’ training process. This is to ensure through graphical observation that the losses reduce and converge, while also to verify that overfitting does not occur during training. As a sample, the losses vs epochs graph for the best performing ANN model (ANN3) for the Johor data set is shown in Fig. 2.

Train and validation loss vs epochs for ANN3 model training process.
Long short-term memory (LSTM)
The LSTM is an advanced version of the recurrent neural networks (RNN) that addresses issues with conventional RNNs relating to gradient vanishing and explosion. This algorithm boasts memory cells and control gates, which together are able to collect and store information2,39. The four control gates are the input gate, update gate, forget gate, and output gate42. They enable the writing, updating, forgetting, and reading of the information forwarded from the memory cells42. Through the operation of the control gates, the LSTM is hence able to minimise errors by retaining relevant information and forgetting irrelevant information as needed. Similar to the ANN and deep learning ML algorithms in general, the LSTM requires high computational power to train and develop predictive models52,53. The high memory-bandwidth needed given the presence of linear layers in each cell may reduce the hardware efficiency of this algorithm. Depending on the LSTM architecture and difficulty of the problem at hand, the LSTM may also take significantly long to train and develop54. Additionally, the LSTM is prone to overfitting55,56, hence needing dropout regularization and early call-back mechanisms to reduce overfitting effects. According to Guo et al.57, the LSTM output is generally computed through function:
where ht is the output, ot is the output gate, \(\odot\) is the Hadamard product, and Ct is the cell status value at time t.
Similar to ANNs, LSTMs also have hidden layers that are occupied by neurons. A trial-and-error process must be carried out to determine an optimal number of hidden layers and neurons in each hidden layer. Through testing, it was determined that 2 hidden layers with 50 neurons in each hidden layer was able to provide the best possible overall SSL predictions for the 11 different river data sets tested in the present study. The number of epochs, step number, batch number, training algorithm, dropout regularization on each hidden layer, activation function, and recurrent activation function were also experimented with in order to determine the best LSTM architecture for the present study, which is detailed in Table 5. Other unmentioned hyperparameters including initialiser, regulariser, and constraints, are remained default as good predictions are obtained. Given that LSTMs are local in time and space58, the overall computational complexity of an LSTM for each time step can be described by:
where w is the number of weights.
The train and validation loss vs epochs graphs are produced during each of the LSTM models’ training process. This is to ensure through graphical observation that the losses reduce and converge, while also to verify that overfitting does not occur during training. As a sample, the losses vs epochs graph for the best performing LSTM model (LSTM3) for the Johor data set is shown in Fig. 3.

Train and validation loss vs epochs for LSTM3 model training process.
Data pre-processing
The pre-processing steps performed on the raw data sets for the selected 11 rivers obtained from the Malaysian Department of Irrigation and Drainage are detailed in this section. The data pre-processing steps include file merging and preparation, imputation of missing data, data partitioning, and feature scaling. These steps are performed to prepare the data sets to be fed to the ML algorithms for training and testing of models.
File merging and preparation
The SSL and SF data sets for each selected river were obtained separately in .txt file format from the Malaysian Department of Irrigation and Drainage. Given that there are 11 selected rivers, a total of 22 .txt files (11 SSL .txt files and 11 SF .txt files) were collected. For each river, a .csv file was then prepared by merging data from the SSL and SF .txt files of each corresponding river. The SF and SSL data in the .csv files were arranged into three columns, headed by ‘Date’, ‘SF(t)’, and ‘SSL(t)’. SF(t) denotes the SF at time t or the current SF, while SSL(t) denotes the SSL at time t or the current SSL. Unimportant information that readily came with the raw data sets were removed.
Missing data
The raw SF and SSL time-series data sets contained missing values which needed to be dealt with before proceeding with model training. This is because most ML algorithms produce errors when they encounter missing values within a data set. In the study field of suspended sediments, it is demonstrated by previous studies that imputation using interpolation has been utilized to fill in for missing or unavailable data values with likely and reasonable values59,60,61,62. The imputeTS package, developed by Moritz & Bartz-Beielstein63 and available in the RStudio environment, was utilized for imputation in the present study. Linear interpolation was adopted to inhabit the sections within the data sets in which values are missing. As a sample, the outcome of the imputation process for missing values in the Johor data set for SF and SSL is shown in Figs. 4 and 5 respectively.

SF imputed values for Johor data set. (SF values in units of m3/s, time step in units of day).

SSL imputed values for Johor data set. (SSL values in units of ton/day, time step in units of day).
Data partitioning
Data partitioning is applied to the data sets to segregate the daily SF and SSL data for each river into a training set and a test set. The training set is utilized to develop and equip the ML models with the ability to make SSL predictions, while the test set is used to evaluate the ability and accuracy of the ML models’ predictions with the help of selected performance measures. With reference to the study by Kannangara et al.64, an optimum ratio for training to testing is found to be 80:20. Existing studies on SSL predictions have also shown to use and produce good results using a training data to testing data ratio of 80:202,19,36. Therefore, in the present study, 80% of each river’s data set is taken for training while the remaining 20% is used for testing. Using this ratio, each river’s data set is partitioned accordingly with similar statistical properties as shown in Table 6. Additionally, it is worth to note that for the deep learning algorithms (ANN, LSTM), 20% of the training set is used for validation.
Feature scaling
Feature scaling is required to be performed on all data sets as both SVM and the deep learning algorithms used in the present study are sensitive to data scales. This data pre-processing step may be carried out through either normalisation or standardisation depending on the type of ML algorithm to be used. Feature scaling ensures that all data variables are accurately weighted to ensure fast convergence and error minimisation during training4,28. In the present study, standardisation is applied on the data sets before training the SVM models, while normalisation is used before training the ANN and LSTM models. Both the input and output data are scaled before training and testing the models, and it is ensured that the ML models’ outputs are inverse transformed back into their original scales before evaluation using the selected performance measures.
Feature selection
Feature selection is essentially the process of selecting input parameters to be used for model training. For the present study, in addition to daily SSL data for the 11 selected rivers, SF data has also been provided. Existing studies have described SF to significantly affect SSL, as larger river discharges enables the transport of sediment through the water body at a higher rate, hence increasing the SSL magnitude65,66,67,68. The present study has hence utilised both daily average SF and daily total SSL data to make SSL predictions, as previous studies have produced good SSL predictions by using these inputs5,11,24,37. A statistical analysis on the daily SF and SSL data for each of the 11 selected rivers is shown in Table 7.
In the present study, the time-series forecasting problem of predicting SSL is re-framed into a supervised learning problem by organising the data sets into a sliding window. This step is performed to enable the application of SVM and ANN for time-series forecasting, as they are traditionally not time-series forecasting algorithms. Before organising the data sets into a sliding window, a partial autocorrelation function (PACF) analysis was performed on all SSL data to determine the lagged SSL data that are most correlated to the current-day SSL data. Based on the PACF analyses in Figs. 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, for most data sets, the 1-day lagged SSL [SSL(t-1)], 2-day lagged SSL [SSL(t-2)], and 3-day lagged SSL [SSL(t-3)] are shown to have a significant correlation with the current-day SSL [SSL(t)].

Partial autocorrelogram for SSL (Sungai Johor, Johor data set).

Partial autocorrelogram for SSL (Sungai Muda, Kedah data set).

Partial autocorrelogram for SSL (Sungai Kelantan, Kelantan data set).

Partial autocorrelogram for SSL (Sungai Melaka, Melaka data set).

Partial autocorrelogram for SSL (Sungai Kepis, Negeri Sembilan data set).

Partial autocorrelogram for SSL (Sungai Pahang, Pahang data set).

Partial autocorrelogram for SSL (Sungai Perak, Perak data set).

Partial autocorrelogram for SSL (Sungai Perlis, Perlis data set).

Partial autocorrelogram for SSL (Sungai Selangor, Selangor data set).

Partial autocorrelogram for SSL (Sungai Dungun, Terengganu data set).

Partial autocorrelogram for SSL (Sungai Klang, Federal Territor y of Kuala Lumpur data set).
Next, Pearson’s correlation coefficient is employed to analyse the correlation between current-day SF data [SF(t)] and SSL(t). Pearson’s correlation coefficient, denoted by \({r}_{xy},\) is defined by:
where \(\overline{x }\),\(\overline{y }\) are respective data means; \({x}_{i},{y}_{i}\) are individual respective data points; and \(n\) is the sample size.
The lagged SSL and SF data are then studied using Pearson’s correlation coefficient to understand the predictive powers of these data as input parameters on SSL(t). Pearson’s correlation coefficient matrix for all the data sets is as shown in Table 8. It can be seen that there is indeed significant correlation between SSL(t-1), SSL(t-2), SSL(t-3), SF(t), SF(t-1), SF(t-2), SF(t-3) and SSL(t) in almost all of the data sets.
Based on the findings from the PACF and Pearson’s correlation coefficient analyses, the SSL(t-1), SSL(t-2), SSL(t-3), SF(t), SF(t-1), SF(t-2), SF(t-3) data are determined to have significant predictive powers over SSL(t), hence are selected as input parameters for the present study. Therefore, in addition to the Date, SSL(t), and SF(t) columns described in Sect. 2.4.1, columns for SSL(t-1), SSL(t-2), SSL(t-3), SF(t-1), SF(t-2), SF(t-3) are also added into the .csv files for each respective river.
Based on these selected input parameters, several input scenarios are formed to train the ML models for SSL prediction. The training of the models using different input scenarios is also performed to test the sensitivity of the models to different input combinations, similar to existing studies2,8,9,23,24,26,35. The designed input parameter scenarios are shown in Table 9. With 4 input parameter scenarios, 3 ML algorithms, and 11 data sets, a total of 132 models were run and evaluated in total.
Performance measures
Four performance measures are selected to evaluate the models’ performances, namely the mean absolute error (MAE), root mean squared error (RMSE), coefficient of determination (R2), and ranking mean (RM). MAE, RMSE, and R2 have been commonly used in SSL prediction studies2,8,9,10,19,21,22,24,37,38,69, while RM was used by Ahmed et al.70 as a method to rank overall model performance.
Mean absolute error (MAE)
The MAE quantifies the average absolute difference between predicted values and actual values. Therefore, a lower MAE is desired. In the present study, the MAE is measured in units of ton/day. The MAE is defined by:
where \({y}_{i}\) is the real value, \(\widehat{{y}_{i}}\) is the predicted value, and \(n\) is the sample size.
Root mean squared error (RMSE)
The RMSE is a good indicator of large errors as it places a relatively high weight to large errors. A lower RMSE is generally desired. The present study measures the RMSE in units of ton/day. The equation for computing the RMSE is as follows:
where \({y}_{i}\) is the real value, \(\widehat{{y}_{i}}\) is the predicted value, and \(n\) is the sample size.
Coefficient of determination (R 2 )
The R2 essentially calculates the correlation between real values and predicted values. R2 scores may lie between − 1 and 1, with a value closer to 1 signalling a higher correlation between real values and predicted values. R2 scores are unitless. To calculate R2, the following equation is used:
where \({y}_{i}\) is real value, \(\widehat{{y}_{i}}\) is predicted value, \(\overline{{y }_{i}}\) is the mean of \({y}_{i}\), and \(n\) is sample size.
Ranking mean (RM)
Each model is first ranked based on the scores of the selected performance measures in the present study, which are MAE, RMSE, and R2. Then, the RM of each model is calculated by averaging the ranks based on the scores of the three performance measures, MAE, RMSE, and R2. The higher the RM, the better the overall performance of a model. The RM is represented by the formula:
where \(n\) is the number of performance analysis measures used, which is 3.
Results and discussion
This section presents and discusses the performances of the developed models for SSL prediction. Comparisons and analyses are then made based on the model performances.
Performance of models based on the Sungai Johor, Johor data set
Model ANN3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Johor, Johor data set.
ANN3 achieved the best MAE, RMSE, and R2 with scores of 13.7489 ton/day, 28.4590 ton/day, and 0.9918 respectively, hence giving it the highest RM of 1.00. The best SVR model was SVR2 (RM = 6.33), while the best LSTM model was LSTM4 (RM = 5.67). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Johor test set is shown in Table 10 and Fig. 17 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Johor test set.
Performance of models based on the Sungai Muda, Kedah data set
Model ANN3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Muda, Kedah data set. ANN3 achieved the best MAE, RMSE, and R2 with scores of 28.3826 ton/day, 76.4909 ton/day, and 0.9548 respectively, hence giving it the highest RM of 1.00. The best SVR model was SVR3 (RM = 3.00), while the best LSTM model was LSTM3 (RM = 8.67). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Muda test set is shown in Table 11 and Fig. 18 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Muda test set.
Performance of models based on the Sungai Kelantan, Kelantan data set
Model ANN3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Kelantan, Kelantan data set. ANN3 achieved the best RMSE and R2 with scores of 126.0058 ton/day and 0.9761 respectively, hence giving it the highest RM of 1.67. SVR3 obtained the best MAE with a score of 53.7383 ton/day. The best SVR model was SVR3 (RM = 2.33), while the best LSTM model was LSTM4 (RM = 9.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Kelantan test set is shown in Table 12 and Fig. 19 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Kelantan test set.
Performance of models based on the Sungai Melaka, Melaka data set
Model SVR3, based on the SVR algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Melaka, Melaka data set. SVR3 achieved the best MAE, RMSE, and R2 with scores of 62.3282 ton/day, 149.6537 ton/day, and 0.7787 respectively, hence giving it the highest RM of 1.00. The best ANN model was ANN4 (RM = 3.00), while the best LSTM model was LSTM3 (RM = 9.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for Sungai Melaka test set is shown in Table 13 and Fig. 20 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Melaka test set.
Performance of models based on the Sungai Kepis, Negeri Sembilan data set
Model ANN3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Kepis, Negeri Sembilan data set. ANN3 achieved the best RMSE and R2 with scores of 170.9490 ton/day and 0.1340 respectively, hence giving it the highest RM of 2.67. LSTM1 obtained the best MAE with a score of 7.0221 ton/day. The best SVR model was SVR4 (RM = 3.67), while the best LSTM model was LSTM1 (RM = 5.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Kepis test set is shown in Table 14 and Fig. 21 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Kepis test set.
Performance of models based on the Sungai Pahang, Pahang data set
Model ANN2, based on the ANN algorithm and input parameter scenario 2, produced the best overall performance in predicting the SSL for Sungai Pahang, Pahang data set. ANN2 achieved the best MAE, RMSE, and R2 with scores of 2.6228 ton/day, 7.6295 ton/day, and 0.9795 respectively, hence giving it the highest RM of 1.00. The best SVR model was SVR1 (RM = 8.33), while the best LSTM model was LSTM2 (RM = 3.33). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for Sungai Pahang test set is shown in Table 15 and Fig. 22 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Pahang test set.
Performance of models based on the Sungai Perak, Perak data set
Model SVR3, based on the SVR algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Perak, Perak data set. SVR3 achieved the best MAE, RMSE, and R2 with scores of 38.0924 ton/day, 82.0057 ton/day, and 0.9817 respectively, hence giving it the highest RM of 1.00. The best ANN model was ANN3 (RM = 3.00), while the best LSTM model was LSTM4 (RM = 7.67). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Perak test set is shown in Table 16 and Fig. 23 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Perak test set.
Performance of models based on the Sungai Arau, Perlis data set
Model ANN3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for the Sungai Arau, Perlis data set. ANN3 achieved the best MAE, RMSE, and R2 with scores of 2.2241 ton/day, 5.3676 ton/day, and 0.9502 respectively, hence giving it the highest RM of 1.00. The best SVR model was SVR3 (RM = 5.67), while the best LSTM model was LSTM4 (RM = 5.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Arau test set is shown in Table 17 and Fig. 24 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Arau test set.
Performance of models based on the Sungai Selangor, Selangor data set
Model ANN4, based on the ANN algorithm and input parameter scenario 4, produced the best overall performance in predicting the SSL for Sungai Selangor data set. ANN4 achieved the best MAE, RMSE, and R2 with scores of 81.7882 ton/day, 209.1255 ton/day, and 0.9425 respectively, hence giving it the highest RM of 1.00. The best SVR model was SVR3 (RM = 3.00), while the best LSTM model was LSTM4 (RM = 9.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for Sungai Selangor test set is shown in Table 18 and Fig. 25 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Selangor test set.
Performance of models based on the Sungai Dungun, Terengganu data set
Model ANN4, based on the ANN algorithm and input parameter scenario 4, produced the best overall performance in predicting the SSL for the Sungai Dungun, Terengganu data set. ANN4 achieved the best RMSE and R2 with scores of 287.5243 ton/day and 0.8674 respectively, hence giving it the highest RM of 1.33. ANN3 obtained the best MAE with a score of 68.8483 ton/day. The best SVR model was SVR4 (RM = 3.67), while the best LSTM model was LSTM4 (RM = 8.00). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for the Sungai Dungun test set is shown in Table 19 and Fig. 26 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Dungun test set.
Performance of models based on the Sungai Klang, Kuala Lumpur data set
Model SVR3, based on the ANN algorithm and input parameter scenario 3, produced the best overall performance in predicting the SSL for Sungai Klang data set. SVR3 achieved the best MAE, RMSE, and R2 with scores 33.8257 ton/day, 65.4953 ton/day, and 0.9721 respectively, hence giving it the highest RM of 1.00. The best ANN model was ANN3 (RM = 2.33), while the best LSTM model was LSTM4 (RM = 7.67). The models’ performance scores and actual vs predicted SSL of best models from each algorithm for Sungai Klang test set is shown in Table 20 and Fig. 27 respectively.

Actual vs predicted SSL of best models based on each algorithm for Sungai Klang test set.
Overall comparison and analysis of model performances
The models’ performances are compared and analysed based on two evaluations, which are the number of times a model produced the best predictive performance for a data set, and the reliability of each model in producing relatively high-accuracy predictions for different data sets. With regards to the number of times a model produced the best predictive performance for a data set, it is found that ANN3 performed the best in 5 out of the 11 tested data sets, which are the Sungai Johor, Sungai Muda, Sungai Kelantan, Sungai Kepis, and Sungai Arau data sets. SVR3 outperformed the other models in 3 of the tested data sets, namely the Sungai Melaka, Sungai Perak, and Sungai Klang data sets. ANN4 produced the best predictive performance in 2 of the tested data sets which are Sungai Selangor and Sungai Dungun, while ANN2 was the best predictive model for 1 data set which is the Sungai Pahang data set. Therefore, ANN3 was the most accurate SSL predictive model for more data sets compared to the other tested models. It is found that the algorithm and the input scenario that produced the best predictive performance for the most data sets are the ANN and input scenario 3 respectively, as both have the best SSL prediction performance for 8 out of 11 data sets. A matrix of most accurate algorithm and input scenario for each data set and the parameters with highest number of best prediction results can be observed in Tables 21 and 22.
Next, the models’ performances are evaluated based on their reliability in producing relatively high-accuracy predictions for different data sets. This evaluation is important to determine the models that are most adaptable and robust to different data sets, which may vary in SSL magnitude and temporal behaviour. It also helps to understand each models’ overall performance on all 11 tested data sets. To quantify the models’ reliability in producing relatively high-accuracy predictions for different data sets, the average of the RM scores obtained by each model for all 11 tested data sets are calculated and compared, as shown in Table 23 and Fig. 28. It is found that ANN3 has the highest average RM with a score of 2.64, hence making it the most reliable model in predicting SSL with relatively high accuracy for different data sets. ANN4 is a close competitor (average RM = 2.91), followed by SVR3 (average RM = 3.85).

Bar chart of average RM for each model based on all data sets.
Based on these comparisons and analyses, it can be deduced that the best model for SSL prediction in the present case study of Peninsular Malaysia is the ANN3 model as it produced the best SSL predictions for more data sets compared to the other models, and it is the most reliable model given that it is robust and adaptable enough to predict SSL with a relatively high accuracy for different data sets compared to the other models, as suggested by its lowest average RM score of 2.64.
As highlighted by Table 21 and Fig. 28, it can be understood that ANN is the most successful algorithm in the present study, followed by SVR. LSTM represents the poorest performing algorithm as it was not able to produce the best predictive performance for any of the tested data sets. The LSTM models also have the lowest average RMs compared to the other models. Generally, LSTMs are effective in predicting based on data sets that have a clear time pattern. As the SSL data in the present study is volatile as it is often going up and down without a clear time pattern, it is probable that LSTM’s effectiveness may have been reduced. Meanwhile, SVR and ANN produced better SSL predictions because they are regression-based methods.
Conclusion
Time series data sets on daily SF and SSL were obtained for 11 different rivers throughout Peninsular Malaysia and used to develop ML models for SSL prediction using three ML algorithms, namely SVM, ANN, and LSTM. Based on quantitative analyses, the ANN3 model, which utilises the ANN algorithm and input scenario 3 (inputs consisting of current day SF, previous day SF, and previous day SSL) is the best performing SSL-predicting model. ANN3 was able to produce the best predictive performance for the most data sets that were tested in the present study, which is 5 out of 11 data sets; and emerged as the most reliable model in predicting SSL with relatively high accuracy for different data sets. Analysis has also shown that the ANN algorithm and input scenario 3 were most successful as they were each able to produce the best predictions for 8 out of 11 data sets.
To conclude, the present study has contributed towards the testing and development of SSL predicting models for multiple rivers within Peninsular Malaysia, given that the development and proposal of predictive models based on multiple river data sets within a single study are scarce. This research gap has been addressed, and the main purpose of the present study which is the proposal of a single model that is capable of producing accurate SSL predictions for rivers within Peninsular Malaysia is achieved. Based on the findings, the present study proposes the ANN3 model as the model that has the best capability of producing accurate SSL predictions for rivers within Peninsular Malaysia. The present study is hoped to contribute towards the respective body of knowledge and help hydrological-related organisations in employing suitable and accurate models for SSL prediction. Future studies may focus on further improving the ANN3 model for SSL prediction in Peninsular Malaysia by hybridizing the model or incorporating more advanced techniques. Additionally, future studies may further study and test the ANN3 model on in other regions around the globe, to determine the effectiveness and accuracy of the ANN3 model on a larger scale. The method of selecting the best SSL predictive ML model in the present study, which involves using performance evaluation measures to determine the model that produces the best SSL predictions for the most rivers and obtains the best average RM, may also be further studied and tested on case studies within other regions.
Data availability
The data that support the findings of this study are available at the Malaysian Department of Irrigation and Drainage.
References
Yilmaz, B., Aras, E., Nacar, S. & Kankal, M. Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Sci. Total Environ. 639, 826–840 (2018).
AlDahoul, N. et al. Suspended sediment load prediction using long short-term memory neural network. Sci. Rep. 11, 1–22 (2021).
Sharghi, E., Nourani, V., Najafi, H. & Gokcekus, H. Conjunction of a newly proposed emotional ANN (EANN) and wavelet transform for suspended sediment load modeling. Water Sci. Technol. Water Supply 19, 1726–1734 (2019).
Uca, et al. Daily suspended sediment discharge prediction using multiple linear regression and artificial neural network. J. Phys. Conf. Ser. 954, 2 (2018).
Hazarika, B. B., Gupta, D. & Berlin, M. A coiflet LDMR and coiflet OB-ELM for river suspended sediment load prediction. Int. J. Environ. Sci. Technol. 18, 2675–2692 (2021).
Khan, M. Y. A., Hasan, F. & Tian, F. Estimation of suspended sediment load using three neural network algorithms in Ramganga River catchment of Ganga Basin, India. Sustain. Water Resour. Manag. 5, 1115–1131 (2019).
Salih, S. Q. et al. River suspended sediment load prediction based on river discharge information: Application of newly developed data mining models. Hydrol. Sci. J. 65, 624–637 (2020).
Tao, H., Keshtegar, B. & Yaseen, Z. M. The feasibility of integrative radial basis M5Tree predictive model for river suspended sediment load simulation. Water Resour. Manag. 33, 4471–4490 (2019).
Meshram, S. G., Safari, M. J. S., Khosravi, K. & Meshram, C. Iterative classifier optimizer-based pace regression and random forest hybrid models for suspended sediment load prediction. Environ. Sci. Pollut. Res. 28, 11637–11649 (2021).
Tabatabaei, M., Salehpour Jam, A. & Hosseini, S. A. Suspended sediment load prediction using non-dominated sorting genetic algorithm II. Int. Soil Water Conserv. Res. 7, 119–129 (2019).
Rezaei, K., Pradhan, B., Vadiati, M. & Nadiri, A. A. Suspended sediment load prediction using artificial intelligence techniques: comparison between four state-of-the-art artificial neural network techniques. Arab. J. Geosci. 14, 215 (2021).
Lu, H. & Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 249, 126169 (2020).
Sivaram, M. et al. An optimal least square support vector machine based earnings prediction of blockchain financial products. IEEE Access 8, 120321–120330 (2020).
Marques Ramos, A. P. et al. A random forest ranking approach to predict yield in maize with uav-based vegetation spectral indices. Comput. Electron. Agric. 178, 105791 (2020).
Liu, Y. et al. Bidirectional GRU networks-based next POI category prediction for healthcare. Int. J. Intell. Syst. https://doi.org/10.1002/int.22710 (2021).
Liu, Y. et al. An attention-based category-aware GRU model for the next POI recommendation. Int. J. Intell. Syst. 36, 3174–3189 (2021).
Liu, Y. et al. A long short-term memory-based model for greenhouse climate prediction. Int. J. Intell. Syst. 37, 135–151 (2021).
Kong, L. et al. LSH-aware multitype health data prediction with privacy preservation in edge environment. World Wide Web https://doi.org/10.1007/s11280-021-00941-z (2021).
Ehteram, M. et al. Design of a hybrid ANN multi-objective whale algorithm for suspended sediment load prediction. Environ. Sci. Pollut. Res. 28, 1596–1611 (2021).
Banadkooki, F. B. et al. Suspended sediment load prediction using artificial neural network and ant lion optimization algorithm. Environ. Sci. Pollut. Res. 27, 38094–38116 (2020).
Rahgoshay, M., Feiznia, S., Arian, M. & Hashemi, S. A. A. Simulation of daily suspended sediment load using an improved model of support vector machine and genetic algorithms and particle swarm. Arab. J. Geosci. 12, 277 (2019).
Rahgoshay, M., Feiznia, S., Arian, M. & Hashemi, S. A. A. Modeling daily suspended sediment load using improved support vector machine model and genetic algorithm. Environ. Sci. Pollut. Res. 25, 35693–35706 (2018).
Moeeni, H. & Bonakdari, H. Impact of normalization and input on ARMAX-ANN model performance in suspended sediment load prediction. Water Resour. Manag. 32, 845–863 (2018).
Buyukyildiz, M. & Kumcu, S. Y. An estimation of the suspended sediment load using adaptive network based fuzzy inference system, support vector machine and artificial neural network models. Water Resour. Manag. 31, 1343–1359 (2017).
Himanshu, S. K., Pandey, A. & Yadav, B. Ensemble wavelet-support vector machine approach for prediction of suspended sediment load using hydrometeorological data. J. Hydrol. Eng. 22, 05017006 (2017).
Himanshu, S. K., Pandey, A. & Yadav, B. Assessing the applicability of TMPA-3B42V7 precipitation dataset in wavelet-support vector machine approach for suspended sediment load prediction. J. Hydrol. 550, 103–117 (2017).
Afan, H. A. et al. ANN based sediment prediction model utilizing different input scenarios. Water Resour. Manag. 29, 1231–1245 (2015).
Mustafa, M. R., Rezaur, R. B., Saiedi, S. & Isa, M. H. River suspended sediment prediction using various multilayer perceptron neural network training algorithms-A case study in Malaysia. Water Resour. Manag. 26, 1879–1897 (2012).
Memarian, H. & Balasundram, S. K. Comparison between multi-layer perceptron and radial basis function networks for sediment load estimation in a tropical watershed. J. Water Resour. Prot. 04, 870–876 (2012).
Adib, A. & Mahmoodi, A. Prediction of suspended sediment load using ANN GA conjunction model with Markov chain approach at flood conditions. KSCE J. Civ. Eng. 21, 447–457 (2017).
Samadianfard, S. et al. Hybrid models for suspended sediment prediction: Optimized random forest and multi-layer perceptron through genetic algorithm and stochastic gradient descent methods. Neural Comput. Appl. https://doi.org/10.1007/s00521-021-06550-1 (2021).
Shadkani, S. et al. Comparative study of multilayer perceptron-stochastic gradient descent and gradient boosted trees for predicting daily suspended sediment load: The case study of the Mississippi River, US. Int. J. Sediment Res. https://doi.org/10.1016/j.ijsrc.2020.10.001 (2020).
Nourani, V. & Behfar, N. Multi-station runoff-sediment modeling using seasonal LSTM models. J. Hydrol. 601, 126672 (2021).
Babanezhad, M., Behroyan, I., Marjani, A. & Shirazian, S. Artificial intelligence simulation of suspended sediment load with different membership functions of ANFIS. Neural Comput. Appl. 33, 6819–6833 (2021).
Ehteram, M. et al. Investigation on the potential to integrate different artificial intelligence models with metaheuristic algorithms for improving river suspended sediment predictions. Appl. Sci. 9, 1–24 (2019).
Azamathulla, H. M., Cuan, Y. C., Ghani, A. A. & Chang, C. K. Suspended sediment load prediction of river systems: GEP approach. Arab. J. Geosci. 6, 3469–3480 (2013).
Adnan, R. M., Liang, Z., El-Shafie, A., Zounemat-Kermani, M. & Kisi, O. Prediction of suspended sediment load using data-driven models. Water 11, 2 (2019).
Khosravi, K., Mao, L., Kisi, O., Yaseen, Z. M. & Shahid, S. Quantifying hourly suspended sediment load using data mining models: Case study of a glacierized Andean catchment in Chile. J. Hydrol. 567, 165–179 (2018).
Le, Ho, Lee, & Jung,. Application of long short-term memory (LSTM) neural network for flood forecasting. Water 11, 1387 (2019).
Lei, J., Liu, C. & Jiang, D. Fault diagnosis of wind turbine based on long short-term memory networks. Renew. Energy 133, 422–432 (2019).
Kratzert, F., Klotz, D., Brenner, C., Schulz, K. & Herrnegger, M. Rainfall–runoff modelling using long short-term memory (LSTM) networks. Hydrol. Earth Syst. Sci. 22, 6005–6022 (2018).
Somu, N. & Ramamritham, K. A hybrid model for building energy consumption forecasting using long short term memory networks. Appl. Energy 261, 114131 (2020).
Dikshit, A., Pradhan, B. & Alamri, A. M. Long lead time drought forecasting using lagged climate variables and a stacked long short-term memory model. Sci. Total Environ. 755, 142638 (2021).
Department of Irrigation and Drainage Malaysia. River Management - Activities. (2017).
Vapnik, V. N. The Nature of Statistical Learning Theory (Springer, 1995). https://doi.org/10.1007/978-1-4757-3264-1.
Singla, M. & Shukla, K. K. Robust statistics-based support vector machine and its variants: A survey. Neural Comput. Appl. 32, 11173–11194 (2020).
Tanveer, M., Tiwari, A., Choudhary, R. & Ganaie, M. A. Large-scale pinball twin support vector machines. Mach. Learn. https://doi.org/10.1007/s10994-021-06061-z (2021).
Ray, S. A Quick Review of Machine Learning Algorithms. in 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon) 35–39 (IEEE, 2019). doi:https://doi.org/10.1109/COMITCon.2019.8862451.
Mijwil, M. M. Artificial neural networks advantages and disadvantages. 1–2 (2018).
Zor, K., Timur, O. & Teke, A. A state-of-the-art review of artificial intelligence techniques for short-term electric load forecasting. in 2017 6th International Youth Conference on Energy (IYCE) 1–7 (IEEE, 2017). doi:https://doi.org/10.1109/IYCE.2017.8003734.
Poblete, T., Ortega-Farías, S., Moreno, M. & Bardeen, M. Artificial neural network to predict vine water status spatial variability using multispectral information obtained from an unmanned aerial vehicle (UAV). Sensors 17, 2488 (2017).
Pan, H., He, X., Tang, S. & Meng, F. An improved bearing fault diagnosis method using one-dimensional CNN and LSTM. J. Mech. Eng. 64, 443–452 (2018).
Belagoune, S., Bali, N., Bakdi, A., Baadji, B. & Atif, K. Deep learning through LSTM classification and regression for transmission line fault detection, diagnosis and location in large-scale multi-machine power systems. Meas. J. Int. Meas. Confed. 177, 109330 (2021).
Choi, S.-H. & Han, M.-K. The Empirical Evaluation of Models Predicting Bike Sharing Demand. in 2020 International Conference on Information and Communication Technology Convergence (ICTC) 1560–1562 (IEEE, 2020). doi:https://doi.org/10.1109/ICTC49870.2020.9289176.
Denkena, B., Bergmann, B. & Stoppel, D. Reconstruction of process forces in a five-axis milling center with a LSTM neural network in comparison to a model-based approach. J. Manuf. Mater. Process. 4, 62 (2020).
Liu, S., Elangovan, V. & Xiang, W. A Vehicular GPS Error Prediction Model Based on Data Smoothing Preprocessed LSTM. in 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall) 1–5 (IEEE, 2019). doi:https://doi.org/10.1109/VTCFall.2019.8891454.
Guo, Y., Cao, X., Liu, B. & Peng, K. E. Niño index prediction using deep learning with ensemble empirical mode decomposition. Symmetry 12, 893 (2020).
Tsironi, E., Barros, P., Weber, C. & Wermter, S. An analysis of convolutional long short-term memory recurrent neural networks for gesture recognition. Neurocomputing 268, 76–86 (2017).
Mesfin, S., Mullu, A. & Kassie, K. Micro-Watershed Hydrological Monitoring and Evaluation. A Case Study at Lake Tana Sub-Basin, Ethiopia. Nile Gd. Ethiop. Renaiss. Dam 493–517 (2021).
Tsyplenkov, A., Vanmaercke, M. & Golosov, V. Contemporary suspended sediment yield of Caucasus mountains. Proc. Int. Assoc. Hydrol. Sci. 381, 87–93 (2019).
Trinh, L. H., Vu, D. T., Le, T. T. & Nguyen, T. T. N. Application of GIS technique for mapping suspended sediment concentration in surface water of the day river. Northern Vietnam. Int. J. Environ. Probl. 3, 2 (2017).
Schulz, K. & Gerkema, T. An inversion of the estuarine circulation by sluice water discharge and its impact on suspended sediment transport Estuar. Coast. Shelf Sci. 200(31), 40 (2018).
Moritz, S. & Bartz-Beielstein, T. imputeTS: Time series missing value imputation in R. R J. 9, 207–218 (2017).
Kannangara, M., Dua, R., Ahmadi, L. & Bensebaa, F. Modeling and prediction of regional municipal solid waste generation and diversion in Canada using machine learning approaches. Waste Manag. 74, 3–15 (2018).
Guo, C. et al. On the cumulative dam impact in the upper Changjiang River: Streamflow and sediment load changes. CATENA 184, 104250 (2020).
Khan, M. Y. A., Tian, F., Hasan, F. & Chakrapani, G. J. Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga, Ganges Basin, India. Int. J. Sediment Res. 34, 95–107 (2019).
Rodríguez-Blanco, M. L., Taboada-Castro, M. M. & Taboada-Castro, M. T. An overview of patterns and dynamics of suspended sediment transport in an agroforest headwater system in humid climate: Results from a long-term monitoring. Sci. Total Environ. 648, 33–43 (2019).
Murphy, J. & Sprague, L. Water-quality trends in US rivers: Exploring effects from streamflow trends and changes in watershed management. Sci. Total Environ. 656, 645–658 (2019).
Hazarika, B. B., Gupta, D. & Berlin, M. Modeling suspended sediment load in a river using extreme learning machine and twin support vector regression with wavelet conjunction. Environ. Earth Sci. 79, 1–16 (2020).
Ahmed, A. N. et al. A comprehensive comparison of recent developed meta-heuristic algorithms for streamflow time series forecasting problem. Appl. Soft Comput. 105, 107282 (2021).
Acknowledgements
This study was funded by Universiti Tunku Abdul Rahman (UTAR), Malaysia, via Project Research Assistantship (PRA) (Project Number: UTARRPS 6251/H03). The authors are grateful for the funding.
Author information
Authors and Affiliations
Contributions
Data curation by A.N.A., Y.F.H., and Y.E. Formal analysis by Y.E. and A.N.A. Methodology by A.N.A., Y.E., and A.H.B. Writing (original manuscript) by Y.E. Writing (review and editing) by A.N.A., Y.F.H., A.H.B., A.S., and Y.E. Funding by Y.F.H.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Essam, Y., Huang, Y.F., Birima, A.H. et al. Predicting suspended sediment load in Peninsular Malaysia using support vector machine and deep learning algorithms. Sci Rep 12, 302 (2022). https://doi.org/10.1038/s41598-021-04419-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-04419-w
- Springer Nature Limited
This article is cited by
-
A comparative survey between cascade correlation neural network (CCNN) and feedforward neural network (FFNN) machine learning models for forecasting suspended sediment concentration
Scientific Reports (2024)
-
Toward coupling of nonlinear support vector regression and crowd intelligence optimization algorithms in estimation of suspended sediment load
Applied Water Science (2024)
-
Applying a machine learning-based method for the prediction of suspended sediment concentration in the Red river basin
Modeling Earth Systems and Environment (2024)
-
Data-driven approaches for estimation of sediment discharge in rivers
Earth Science Informatics (2024)
-
Research progress in water quality prediction based on deep learning technology: a review
Environmental Science and Pollution Research (2024)