
Abstract
In Land Use Cover Change (LUCC) modelling, soft maps are often produced to express the propensity of an area to land use change. These maps are generally prepared in raster format, and have values of between 0 and 1, indicating the propensity of each pixel to change. In the literature, they are referred to as suitability, change potential or change probability maps. These maps are sometimes considered as the final product of a model (e.g. map of deforestation risk), but they can also serve as intermediate products that simulate the changes from which a hard-simulated land use/cover map can later be prepared using, for example, a cellular automaton. In both cases, it is essential to evaluate the soft map’s ability to identify the areas that are most susceptible to change. One way of assessing this ability is to compare the spatial coincidence between the real changes observed on the ground and the values estimated by the soft map. One would expect real change areas to coincide with high change potential values (near 1) and real no-change areas with low change potential values (near 0). This comparison can be made using various statistical approaches including Correlation Coefficient (Sect. 1), the Receiver Operating Characteristic (ROC) (Sect. 2) and the Difference in Potential (DiP) (Sect. 3). Other measures, such as total uncertainty, quantity uncertainty and allocation uncertainty (Sect. 4), are used exclusively in the analysis of soft maps. In this chapter, we describe the fundamental steps involved in these four statistical approaches to validating the soft maps produced by a model. The four sections are illustrated with specific cases: to validate soft maps produced by the model, to validate soft maps produced by the model against a reference map and to validate soft maps produced by various models against a reference map. We use the Ariège database to validate the different soft maps (change potential and suitability maps) produced by the model by comparing them with real land use maps of the Ariège Valley for two dates (CORINE 2012 and 2018). All these validation techniques are carried out using raster data. As commented earlier, the soft maps produced by the model are continuous, ranked variables. We designed exercises using this original format. In other chapters of this book, the soft maps produced by the model are validated after reclassification of the original maps.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
Preliminary QGIS Exercise
Available tools | |
|---|---|
• Semi-Automatic Classification Plugin Tab: Postprocessing Section: Land cover change |
Before beginning the exercises in this chapter, we need to obtain a map of the real transitions that took place between two land use categories (Category 2 to Category 1 and Category 3 to Category 1) between 2012 and 2018. Of all the various tools offered by QGIS (see Sect. 1 in Chapter “Basic and Multiple-Resolution Cross-Tabulation to Validate Land Use Cover Maps”, about basic Cross-Tabulation), in this exercise we will be using Land cover change from the “Semi-Automatic Classification Plugin”.
Exercise 1. To create binary change maps for two transitions
Aim
To create binary change maps for two transitions (2 to 1 and 3 to 1) using CORINE Land Use maps for the years 2012 and 2018. For each transition, each pixel on the map is allocated a value of 1 or 0 depending on whether or not the transition occurred.
Materials
CORINE Land Cover Map Val d’Ariège 2012
CORINE Land Cover Map Val d’Ariège 2018
Requisites
All maps must be raster and have the same resolution, extent and projection.
Execution
Step 1
To create the map of real change, open the “Semi-Automatic Classification Plugin” and, in the tab “Postprocessing”, select the option Land cover change. Then, fill in the required parameters: the earlier map in the reference classification (CORINE 2012) and the more recent map in the new classification (CORINE 2018). Check the option “Report unchanged pixels”.
QGIS then creates an output raster and a table, stored in CSV format, showing all the different combinations observed between the two input maps and the code with which these combinations are represented in the output raster. These combinations (those with 1 or more pixels) and the number of pixels affected by them are presented in Fig. 1.

Results from Exercise 1. Step 1. Combinations observed between two input maps, code in the output raster and number of pixel affected
Step 2
The raster obtained in Step 1 is reclassified twice: (i) to represent the areas in which a change was observed from 2 to 1 and those in which there was no change and (ii) to do the same for the transition from 3 to 1.
To reclassify the raster, open the Reclassify by table tool and allocate a new code 1 to ChangeCode 16 (transition from 2 to 1) and a new code 0 to ChangeCodes 17, 18, 19 and 21 (pixels that belonged to Category 2 in 2012 but did not change to Category 1 in 2018). All these ChangeCodes are highlighted in the Fig. 1 in green. All the other ChangeCodes (i.e. those with a reference class other than 2 which cannot possibly undergo the transition from 2 to 1 and are therefore considered as No Data) must be allocated a new code −99. Save the output raster as TrueChange2to1.
As regards the transition from 3 to 1, allocate a new code 1 to ChangeCode 23 (pixels that were Category 3 in 2012 and changed to Category 1 in 2018) (in bold type) and a new code 0 to ChangeCodes 24, 25, and 26 (pixels that were Category 3 in 2012 but did not change to Category 1 in 2018). All the candidate ChangeCodes are highlighted in orange in the Fig. 1. A new code −99 must be allocated to the remaining ChangeCodes (i.e. those which cannot undergo this transition). Save the output raster as TrueChange3to1.
In Fig. 2, the areas that changed from 2 to 1 are shown in white, the Category 2 areas that did not change to 1 are shown in grey and the non-candidate areas (i.e. those with a reference class other than 2) appear in black. In Fig. 3, the areas that changed from 3 to 1 are shown in white, the Category 3 areas that did not change to 1 in grey and the non-candidate areas in black.

Results from Exercise 1. Binary change map for transition from 2 to 1

Results from Exercise 1. Binary change map for transition from 3 to 1
1 Correlation
Description
Correlation is a statistical measure that evaluates the extent to which two variables are related. This means that when one variable changes in value, the other variable also tends to change. Correlation coefficients are quantitative metrics that measure both the strength and the direction of this tendency of two variables to vary together.
The correlation coefficients range from 1 to −1. A coefficient of 1 shows a perfect positive correlation, while a coefficient close to zero indicates that there is no relationship between the variables. A coefficient of minus 1 indicates a perfect negative correlation, that is, as one variable increases, the other decreases.
The Pearson correlation measures the linear correlation between two variables. Spearman’s correlation is the non-parametric version of the Pearson correlation and is based on the rank order of the variables rather than on their values. Spearman’s correlation is often used to evaluate non-linear relationships or relationships involving ordinal variables.
Utility
Exercises | |
|---|---|
1. To validate soft maps produced by the model against a reference map of changes |
Correlation analysis is useful for making a rapid assessment of a soft map expressing the propensity of an area to change. Assuming that the change map is coded 0 for no change and 1 for change, we would expect a positive value close to 1 if the soft map is successfully attributing high change potential values to change areas and low change potential values to no-change areas. A correlation coefficient of 0 indicates a completely random model. A negative coefficient indicates that the model is making incorrect predictions in that it produces soft maps in which low change potential values are awarded to areas in which changes are in fact taking place (Bonham-Carter 1994; Camacho Olmedo et al. 2013).
We used Pearson and Spearman correlations to assess the correlation between the map showing real changes and its respective change potential map. The correlation between a binary variable and a continuous variable is known as a Point-Biserial Correlation and measures the strength of association between the two.
QGIS Exercise
Available tools | |
|---|---|
• Processing R provider plugin Correlation.rsx R script |
We have created an R script to calculate in QGIS the Pearson and Spearman correlation coefficients. This script performs a sampling of the images and calculates both the Pearson and Spearman correlations.
Exercise 1. To validate soft maps produced by the model against a reference map of changes
Aim
To calculate the correlation between the map showing real change from 2 to 1 and the corresponding map of potential change.
Materials
TrueChange2to1 (calculated in the preliminary QGIS exercise in this chapter)
Transition potential map from agricultural to artificial areas
Requisites
All maps must be in raster format and have the same resolution, extent and projection.
Execution
If necessary, install the Processing R provider plugin and download the Correlation.rsx R script into the R scripts folder (processing/rscripts). For more details, see Chapter “About this Book”.
Initial maps
The initial maps for comparison are the TrueChange2to1 map (see the preliminary QGIS exercise in this chapter) and the map showing the change potential from 2 to 1 (Fig. 4). Values range from 0 (black) to 0.977082 (white), the value for the areas with maximum change potential. The areas with a value of 0 (black) are those in which there is no potential for change.

Exercise 1. Initial map: Change potential map from 2 to 1
Step 1
Run the script and fill in the required parameters (names of the two maps, proportion of pixels to be sampled, Null value) as shown in Fig. 5. The Null value enables us to exclude part of the image from the calculations, for instance, the pixels with no potential for change.

Exercise 1. Step 1. Correlation R script
The script samples the images in order to speed up the computing of the correlation coefficients. It then displays both the Pearson and Spearman correlation coefficients and a scatterplot in the log files (Figs. 6 and 7).

Results from Exercise 1. Pearson and Spearman correlation coefficients

Result from Exercise 1. Scatterplot
Results and Comments
As can be seen in Fig. 6, both maps show a low positive correlation (Pearson = 0.13, Spearman = 0.12), which means that the real changes tend to occur more frequently in the areas with higher change potential values. However, as can be seen in Fig. 7 and by the low value of the coefficients, the difference between the potential values for change and no-change areas is quite small.
2 Receiver Operating Characteristic (ROC)
Description
Receiver Operating Characteristic (ROC) analysis enables users to evaluate binary classifications with continuous output or rank-order values. In spatial modelling, ROC analysis is used to assess soft maps such as probability or suitability maps, which present the sequence in which the model selects cells to determine the occurrence of binary events, such as change versus no change (Camacho et al. 2013). The probability map can be compared with the observed binary event map so as to assess the spatial coincidence between the event and the probability values. An accurate predictive model would produce a probability map in which the highest ranked probabilities coincide with the actual event.
ROC applies thresholds to the probability map to produce a sequence of binary predicted event maps and assess the coincidence between predicted and real events. A curve is obtained in which the horizontal axis represents the false positive rate (proportion of no-event cells modelled as an event) and the vertical axis the true positive rate (proportion of true event cells modelled as an event).
A standard metric based on the ROC curve is the area under the curve (AUC). If the actual events coincide perfectly with the highest ranked probabilities, then the AUC is equal to one. A random probability map produces a curve in which the true positive rate equals the false positive rate at all threshold points, and AUC is therefore 0.5. Probability maps that produce a ROC curve below the diagonal (AUC < 0.5) have less predictive accuracy than a random map (Mas et al. 2013; Pontius and Parmentier 2014).
Utility
Exercises | |
|---|---|
1. To validate soft maps produced by the model against a reference map of changes |
The main application of ROC analysis in spatial modelling is in the assessment of maps that predict events such as land use/cover change, species distribution, disease and disaster risks.
QGIS Exercise
Available tools | |
|---|---|
• Processing R provider plugin • ROCR package ROCAnalysis.rsx R script |
QGIS does not provide any tool for ROC analysis, although R provides several packages to this end. We implemented the ROCAnalysys.rsx R script in QGIS using the QGIS Processing R provider plugin and the ROCR package to plot the ROC curve and calculate the AUC (Sing et al. 2005). This script resamples the images to reduce the number of observations and carry out the standard ROC analysis.
Exercise 1. To validate soft maps produced by the model against a reference map of changes
Aim
To assess the accuracy of a change potential map using ROC analysis.
Materials
TrueChange2to1 (calculated in the preliminary QGIS exercise in this chapter)
Transition potential map from agricultural to artificial areas
Requisites
All maps must be in raster format and have the same resolution, extent and projection.
Execution
If necessary, install the Processing R provider plugin, and download the ROCAnalysis.rsx R script into the R scripts folder (processing/rscripts). For more details, see Chapter “About this Book”.
Step 1
Then run the script and fill in the required parameters (Fig. 8): Probability map is a soft prediction map for the event; Event is a binary map that indicates the occurrence, or not, of the event. This map can have NullValue cells for the areas that are not affected by the prediction.

Exercise 1. Step 1. ROC Analysis R script
The maps have large numbers of both “event” and “non-event” cells, although there are normally more “event” cells than “non-event” cells. The PercentSampled parameter uses random sampling to reduce the number of non-event cells observed.
Results and Comments
The script carries out a sampling of the cells, plots the ROC curve and calculates the AUC. The ROC curve (Fig. 9) is saved, and the AUC value is displayed in the R console.

Results from Exercise 1. The ROC curve
We assessed the change potential map for the transition from Category 2 (agriculture) to Category 1 (built-up) using ROC analysis. An AUC of 0.74 was obtained. We can therefore conclude that this predictive map was reasonably successful at identifying the agricultural areas that were most likely to be converted to built-up over the period 2012–18.
3 Difference in Potential (DiP)
Description
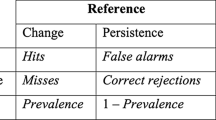
DiP is based on the Peirce Skill Score (PSS):
where H = HITS, i.e. pixels in which both the real maps and the simulation show change and F = FALSE ALARMS, i.e. pixels in which the real maps show persistence but the simulation shows change.
In DiP, proposed by Eastman et al. (2005), the simulation maps are soft (change potential, suitability maps…) rather than hard maps. DiP therefore compares the relative weight of the potential (in a generic sense) that is allocated to areas that changed, i.e. HITS, and the relative weight of the potential allocated to areas that did not change, i.e. FALSE ALARMS. Results are normally between 1.0 (perfect predictor) and 0 (prediction no better than random). Negative values are also possible (prediction systematically incorrect). In other words, DiP is defined as the difference between the mean potential in the change areas and the mean potential in the no-change areas (Pérez-Vega et al. 2012).
Utility
Exercises | |
|---|---|
1. To validate soft maps produced by the model against a reference map of changes 2. To validate soft maps produced by various models against a reference map of changes |
DiP is used as a tool for validating soft maps in a modelling exercise, by assessing their predictive accuracy. Users can validate and compare several soft maps simulated by the same model or several soft maps simulated by different models. Pérez-Vega et al. (2012) validated a map of overall change potential created by superimposing all the potential maps produced by a model.
As these soft maps are rank-order indices, but real land use typically includes a categorical legend, we would expect each real category or transition to be allocated where the values are highest in soft-classified maps, whereas other categories or transitions would be allocated where the values are lower. The validation methods therefore have to compare a rank image with a Boolean image in which the real category or transition is located.
Compared to other assessment techniques such as ROC analysis (see previous section), which is based on a relative threshold, DiP analysis is a measure of absolute threshold. As Eastman et al. (2005) suggested, PSS, DiP and similar procedures could be used in models based on absolute performance, while ROC could be used in models based on relative performance. DiP and ROC present a different picture, in that in DiP the results show greater variability between the potential maps and models.
QGIS Exercise
Available tools | |
|---|---|
• Processing Toolbox Raster Analysis Raster layer zonal statistics • LecoSPlugin Landscape statistics Zonal statistics |
The Difference in Potential is a simple subtraction between average values from two maps. The required functions are related to zonal statistics which is why in these exercises we will be using the Raster layer zonal statistics tool.
Exercise 1. To validate soft maps produced by the model against a reference map of changes
Aim
To validate and compare two change potential maps (soft maps), obtained from the same model, against a reference map-CORINE Land Use map of real changes (from 2012 to 2018).
Materials
TrueChange2to1 (calculated in the preliminary QGIS exercise in this chapter)
TrueChange3to1 (calculated in the preliminary QGIS exercise in this chapter)
Transition potential map from agricultural to artificial areas
Transition potential map from forests to artificial areas
Requisites
All maps must be raster and have the same resolution, extent and projection.
Execution
Initial maps
In this exercise, we will be using the TrueChange2to1 and the TrueChange3to1 maps (see the preliminary QGIS exercise in this chapter), the change potential map from 2 to 1 (see Sect. 1) and the change potential map from 3 to 1 (Fig. 10). Values are from 0 (black) to 0.99753 (white), the latter corresponding to the areas with the maximum potential for change. The areas in which this change is not predicted are allocated a value of 0.

Exercise 1. Initial map: change potential map from 3 to 1
Step 1
We open Raster layer zonal statistics (located in the Processing Toolbox) to extract the mean values from the change potential map from 2 to 1 (Input layer) using the TrueChange2to1 map as the Zones layer (Fig. 11).

Exercise 1. Step 1. Raster layer zonal statistics
Step 2
We then repeat the exercise with the change potential map from 3 to 1 (Input layer) using the TrueChange3to1 map as the Zones layer.
Results and Comments
The mean value for change potential from 2 to 1 in the candidate areas that actually change to Category 1 is 0.43, while in the candidate areas that did not change, the mean value is 0.20. Therefore, the Difference in Potential is 0.23. In spite of the fact that the change potential is twice as high in the areas that changed to Category 1 than in those that did not change, the absolute potential (about 0.43) is quite low.
As regards the change from 3 to 1, the mean value for change potential in the candidate areas that change to Category 1 is 0.31, while in the candidate areas that did not change, the mean value is 0.02. Therefore, the Difference in Potential is 0.29. In spite of the fact that the absolute difference is quite low, it is important to highlight that the change potential value in the candidate areas that did not change is almost zero. From this point of view DiP throws up interesting results.
The fact that these soft maps have similar DiP values means that they have similar predictive capacity. This is slightly higher in the map charting potential change from 3 to 1, although we should also bear in mind that the change from 3 to 1 affects just one small, contiguous area.
Exercise 2. To validate soft maps produced by various models against a reference map of changes
Aim
To validate and compare two soft maps obtained from two different models against a reference map-CORINE Land Use map of real changes (from 2012 to 2018).
Materials
TrueChange2to1 (calculated in the preliminary QGIS exercise of this chapter)
Transition potential map from agricultural to artificial areas
Markovian probability map for artificial areas Ariège Valley
Requisites
All maps must be raster and have the same resolution, extent and projection.
Execution
Initial maps
In this exercise, we will be using the TrueChange2to1 (see the preliminary QGIS exercise in this chapter), the change potential map from 2 to 1 (see Sect. 10.1) and the Markovian probability map for Category 1 (Fig. 12), with values from 0 (black) to 0.997692 (white), the latter corresponding to the areas with the highest probability to be Category 1.

Exercise 2. Initial map: Markovian probability map for Category 1
Step 1
In order to obtain the mean values from the change potential map for the transition from 2 to 1, follow the process set out in Exercise 1 of this section.
Step 2
We now use the Raster layer zonal statistics tool to extract the mean values from the probability map for Category 1 (Input layer) using the TrueChange2to1 map as zones (Zones layer). In other words, in both soft maps (change potential map and probability map) we extract the mean values using the same map as zones.
Results and Comments
As commented in Exercise 1 of this section, the mean value for change potential from 2 to 1 in the candidate areas that did actually change to Category 1 is 0.43; while in the candidate areas that did not change, the mean value is 0.20. This means that the Difference in Potential is 0.23. In spite of the fact that the change potential is twice as high in the areas that changed to Category 1 than in those that did not change, the absolute potential (about 0.43) is quite low.
The mean value for the probability of Category 1 in the candidate areas that did actually change from Category 2 to 1 is 0.013, while in the candidate areas that did not change, the mean value is 0.0098. The Difference in Potential is therefore 0.0032. This very small difference means that the only Markovian-generated probability map has no predictive value.
The two soft maps, each generated by a different model to predict the changes in land use and cover, produce highly varying results: some areas considered to have high change potential by one model are attributed low change potential by the other.
In this case, it is important to remember that we are comparing two quite different change potential maps. Firstly, a change potential map in which only one specific transition is evaluated (in this case from 2 to 1) and therefore only one source category (Category 2) is considered for its potential for change to the target category (Category 1). Secondly, a suitability map, which generates the probability of any part of the study area belonging to a particular target category (in this case Category 1) at the end of the period regardless of its original source category. However, when comparing the outputs of these models, we evaluated the same transition in both soft maps and validated them against the same real change.
The second main difference is that the change potential map is based not only on two LUC maps but also on selected drivers, while the Markov Probability map is computed without additional knowledge (drivers). The conclusion is that when comparing different maps, it is important to bear in mind that the data may have been obtained in different ways.
4 Total Uncertainty, Quantity Uncertainty, Allocation Uncertainty
Description
In an exhaustive state of the art on the accuracy of model outputs, Krüger and Lakes (2016) proposed an uncertainty measurement for probability maps such as soft predictions, which could be considered equivalent to the disagreement indices for hard prediction maps.
These authors proposed a measurement of the probability of predictions being misses (PM) (also called omissions) or false alarms (PF) (also called commissions) for soft prediction maps. They also introduced three uncertainty measures:
where PM = the average for the values less than 0.5 (pixel values equal to or higher than 0.5 are previously set to zero); PF = average of soft prediction map where values less than 0.5 are set to zero while values equal to or higher than 0.5 are converted into their complement to 1 (0.8 becomes 0.2; 0.51 becomes 0.49).
Utility
Exercises | |
|---|---|
1. To validate soft maps produced by the model |
The uncertainty indices proposed by Krüger and Lakes (2016) for probability maps such as soft predictions are equivalent to disagreement indices for hard classified maps such as hard predictions. Theses indices allow us to evaluate the uncertainty of soft predictions by comparing the level of uncertainty in soft prediction outputs with the level of disagreement in hard prediction outputs.
QGIS Exercise
Available tools | |
|---|---|
• Raster Raster Calculator Raster Layer Statistics |
There is not any specific tool implemented in QGIS or R that allows to directly calculate the uncertainty indices proposed by Krüger and Lakes (2016). However, these can be easily obtained through common spatial analysis tools, such as Raster Calculator and Raster Layer Statistics.
Exercise 1. To validate soft maps produced by the model
Aim
To validate the soft map produced by the LCM model for the Ariège Valley case study.
Materials
Soft prediction LCM Val d’Ariège 2018
Requisites
The map must be raster.
Execution
Initial maps
Figure 13 shows the generated soft prediction map (2018) generated by Land Change Modeler (LCM) for Ariège Valley, based on CLC 2000 and CLC 2012 training dates. The map values range from 0, which means minimal probability to change, to 1, which means maximal probability to change.

Exercise 1. Initial map: Soft prediction map
Step 1
To calculate the PM map (probability of being a miss), we use the Raster Calculator twice. First, we generate an intermediate map in which all pixel values less than 0.5 are coded as 1: calculator expression = “CLC_predict_2018_soft_UTM@1” < 0.5. Then, we multiply this mask (intermediate map named “TMP_1”) by the soft prediction map: calculator expression = “TMP_1@1” * “CLC_predict_2018_soft_UTM@1”. As a result, we obtain the PM map (Fig. 14).

Exercise 1. Step 1. PM (probability of being a miss) map
Step 2
To calculate the PF (probability of being a false alarm) map, we need to use the Raster Calculator again. With the calculator, we can first compute an intermediate map in which all pixel values equal to or greater than 0.5 are coded as 1: calculator expression = “CLC_predict_2018_soft_UTM@1” > = 0.5. Then, we subtract the values of the soft prediction map from 1 before multiplying it by the mask (intermediate map, here named “TMP_2”): calculator expression = (1-“CLC_predict_2018_soft_UTM@1”) * “TMP_2@1”. As a result, we obtain the PF map (Fig. 15).

Results from Exercise 1. Step 2. PF (probability of being a false alarm) map
Step 3
Finally, we use the Raster Layer statistics tool to calculate the average PM and PF values from the corresponding maps.
Step 4
Once we have obtained the PM and PF values, we can calculate the Quantity Uncertainty (QU), Allocation Uncertainty (AU) and Total Uncertainty (TU) following the formulas provided by Krüger and Lakes (2016):
Results and Comments
All three uncertainty indices are very low because only a small proportion of the pixels change category. The soft prediction map (Fig. 13) indicates that persistence is the dominant trend and there are very few high-probability soft-predicted changes.
For this dataset, quantity uncertainty is about three times lower than allocation uncertainty. It is important to bear in mind that areas with low rates of change also have lower uncertainty rates, so limiting the significance of these indices.
References
Bonham-Carter GF (1994) Tools for map analysis: map Pairs. In: Bonham-Carter GF (ed) Geographic information systems for geoscientists. Pergamon, pp 221–266. ISBN 9780080418674. https://doi.org/10.1016/B978-0-08-041867-4.50013-8
Camacho Olmedo MT, Paegelow M, Mas J-F (2013) Interest in intermediate soft-classified maps in land change model validation: suitability versus transition potential. Int J Geogr Inf Sci 27(12):2343–2361. https://doi.org/10.1080/13658816.2013.831867
Clarklabs (2021) https://clarklabs.org/terrset/land-change-modeler/
Eastman JR, Van Fossen ME, Solarzano LA (2005) Transition potential modelling for land cover change. In: Maguire D, Goodchild M, Batty M (eds) GIS, spatial analysis and modeling. ESRI Press, Redlands, California
Krüger C, Lakes T (2016) Revealing uncertainties in land change modeling using probabilities. Trans GIS 20:526–546. https://doi.org/10.1111/tgis.12161
Mas J-F, Soares-Filho BS, Pontius RG Jr, Gutiérrez MF, Rodrigues H (2013) A suite of tools for ROC analysis of spatial models. ISPRS Int J Geo Inf 2(3):869–887. https://doi.org/10.3390/ijgi2030869
Pérez-Vega A, Mas JF, Ligmann-Zielinska A (2012) Comparing two approaches to land use/cover change modeling and their implications for the assessment of biodiversity loss in a deciduous tropical forest. Environ Model Softw 29(1):11–23. https://doi.org/10.1016/j.envsoft.2011.09.011
Pontius RG Jr, Parmentier B (2014) Recommendations for using the relative operating characteristic (ROC). Landscape Ecol 29(3):367–382. https://doi.org/10.1007/s10980-013-9984-8
Sing T, Sander O, Beerenwinkel N, Lengauer T (2005) ROCR: visualizing classifier performance in R. Bioinformatics 21(20):7881. https://doi.org/10.1093/bioinformatics/bti623
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Camacho Olmedo, M.T., Mas, JF., Paegelow, M. (2022). Validation of Soft Maps Produced by a Land Use Cover Change Model. In: García-Álvarez, D., Camacho Olmedo, M.T., Paegelow, M., Mas, J.F. (eds) Land Use Cover Datasets and Validation Tools. Springer, Cham. https://doi.org/10.1007/978-3-030-90998-7_10
Download citation
DOI: https://doi.org/10.1007/978-3-030-90998-7_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-90997-0
Online ISBN: 978-3-030-90998-7
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)