
Abstract
In this chapter, we present an approach of enriching photogrammetric point clouds with semantic information extracted from images of digital cameras or smartphones to enable a later automation of BIM modelling with object-oriented models. Based on the DeepLabv3+ architecture, we extract building components and objects of interiors in full 3D. During the photogrammetric reconstruction, we project the segmented categories derived from the images into the point cloud. Based on the semantic information, we align the point cloud, correct the scale and extract further information. The combined extraction of geometric and semantic information yields a high potential for automated BIM model reconstruction.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
The digitalisation of the building sector is progressing steadily. Object-oriented models in BIM (building information modelling) are the central elements and represent the entire life cycle of a building, from planning and operation to demolition. In addition to the 3D component and object geometries, they also contain all relevant semantic information. However, the introduction of BIM is currently taking place almost only in the planning of new buildings (greenfield). Due to the very high complexity of manual data acquisition and processing, the recording of already existing buildings (brownfield) as BIM models has been a minor topic so far. Developing an automatic extraction of the necessary information yields a high potential at simplifying the creation of such “As-Build” or “As-Is” models and thus the possibility to make them widely available. Creating these models requires three-dimensional data. We consider photogrammetry as a very suitable method to not only capture and reconstruct buildings as point clouds of high quality but also to extract further semantic information out of these images. Image information is acquired indoor and outdoor and can be merged with point cloud data from mobile laser scanning devices.
We present our general workflow for modelling interior and exterior parts of a building to derive 3D geometries and semantic information. Then we focus on details of our developed theory and the implemented approach to provide both semantic and geometric information for the case of interior rooms. The results in real-world scenes are analysed and an outlook for further developments is given.
2 Related Work
Building information modelling is a major focus of the digital transformation of the building sector. With the Stufenplan Digitales Planen und Bauen, the Federal Ministry of Transport and Digital Infrastructure gradually introduced the BIM method into the planning processes of public infrastructure (Bramann et al., 2015a). In Germany, its implementation is taking place supported by guidelines and investigation mainly focusing on its introduction and execution in various disciplines, e.g. Egger et al. (2013), Eschenbruch et al. (2014), Kaden et al. (2019) and Bramann et al. (2015b).
A reconstruction of existing buildings as three-dimensional BIM models is possible using measurements of geodetic instruments (Borrmann et al., 2015) or (Clemen and Ehrich, 2014). The increased demand of geometric three-dimensional data and additional semantic information of a BIM model is mostly ignored. In consequence, the acquisition and modelling of measurement data is highly complex and requires a large expenditure of time and money.
The whole field of deep learning has become a major focus of research in recent years. Especially computer vision based on convolutional neural networks progressed a lot since Krizhevsky et al. (2012) were able to achieve great improvements in image classification. Many approaches aim at further development and improvement of reached accuracies, e.g. Szegedy et al. (2015), Simonyan and Zisserman (2015) and Huang et al. (2017). In addition to the pure classification of entire images, the idea of localising the detected class in the image also gained a lot of interest. Two different approaches have emerged for this purpose. Object detection, as presented in Ren et al. (2015), uses bounding boxes to locate and classify objects. Even more precise, the semantic segmentation classifies every pixel of an image. As the resolution of the input images is retained, this method is very well suited to project the extracted semantic information into a point cloud.
One of the first popular networks was by Long et al. (2015), which was named fully convolutional network (FCN). In Obrock and Gülch (2018), our first approach to automatically generate a semantically enriched point cloud from mobile sensors was based on the application of deep learning for segmentation of eight interior building components and objects using an FCN. In Gülch and Obrock (2020), we were able to verify that the combination of photogrammetry and deep learning is a solid approach to generate a semantically enriched point cloud of interiors now using DeepLabv3+ (Chen et al., 2018). In consequence, the components and objects can be differentiated very well in the point cloud.
In this contribution, we relate our recent developments in this approach to our overall designed framework and show updated results with further improved quality.
3 Methodology
3.1 Overview
Images are the main component of our approach because of the massive amount of information contained in them. They are the input for the photogrammetric point cloud generation and the extraction of objects based on deep learning methods. In addition, we include point clouds from low-cost mobile laser scanning devices in interior rooms to provide point cloud information in areas where walls and room parts are very homogeneous and do not allow reliable point cloud derivation from imagery. For exterior parts, we rely on photogrammetry only, as low-cost mobile laser scanning devices have limited range of acquisition. We have developed a strategy as shown in Fig. 17.1 to combine interior and exterior parts of a building to, e.g. estimate wall dimensions. To link exterior and interior, we focus on doors and windows and have developed acquisition strategies for the different building parts using different sensors. We integrate point clouds and align them to get the geometric 3D information. We derive semantic information from imagery and point clouds, and we basically use the same methods for interior and exterior parts; however, the type of classes and thus object parts differ. In this contribution, we will only concentrate on the semantic segmentation of interior rooms.

Methodology to acquire geometric and semantic information for interior and exterior parts of a building using images from cameras and point clouds from mobile laser scanning
3.2 Workflow for Reconstructing Interior Rooms Based on Image Data and Deep Learning
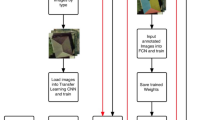
Details of our approach of interior rooms are given in Fig. 17.2. We use DeepLabv3+ as the architecture of our neural network to segment components and objects of interiors visible in the images at pixel level. And network backbone xception 65 is used. The training of the model is conducted using manually segmented ground truth data.

Detailed workflow for semantic and geometric generation of interior rooms
The trained model then is used for inference on the images of an exemplary room. The images also are used to generate a point cloud using photogrammetry. Afterwards, the category information stored in the RGB values of the segmented images is transferred in the point cloud by projection based on the determined camera parameters. Ideally, the result would be a classified point cloud, but because of interpolation, the points cannot be clearly assigned to the categories. Therefore, an additional step is taken to reclassify them. By using the clearly classified point cloud as input for further post-processing, we are able to automatically correct the rotation and scale, as well as extract additional information like floor, ceiling and wall planes.
We are testing our approach on two rooms, an office and a computer laboratory.
4 Semantic Segmentation of Interiors
A comprehensive and high-quality segmentation of all the important building components and objects visible in the images is our basic source of information. It is of essential importance for a complete reconstruction of an existing building. The current object categories include 25 components and objects important for a great variety of interiors (Table 17.1). Because the category “Wall” had to be excluded due to negative effects on the segmentation quality, the model was trained for extracting 24 categories and a “Background” class of unclassified objects.
An extensive training data set was created for training the neural network. It is based on nearly 300 images and the corresponding manually segmented ground truth annotations and was expanded to almost 18,000 unique images using data augmentation.
Based on a pre-trained model, the training was conducted using fine-tuning.
The resulting trained neural network is used for inferencing the images of the two rooms. In an additional post-processing step, some small, random areas, which are partially present in the segmentations but do not relate to any real object, are filtered out.
As shown in Fig. 17.3, we can obtain rather good results, despite the complexity of the categories. Some of the categories, especially the ones covering large areas, have a high consensus. Errors are occurring where objects resemble each other too closely, like the feet of the “Table” and “Chair”. It is also noticeable that unique objects are segmented more precisely than plain and uniform areas like “Ceiling”, in which some holes occur. Small objects like “Light switch” and “Socket” are mostly well segmented depending on the angle and distance at with they are imaged.

Exemplary results of our trained DeepLabv3+ model inferencing the images of the office room (2× upper left) and the laboratory (2× upper right) captured using one camera each. The bottom row shows the segmented categories of each image
5 Classified Point Cloud
With BIM models as our target, we need to transfer the two-dimensional semantic information from the images into three dimensions. Using photogrammetry and digital image matching, the original images of both rooms build the basis to create three-dimensional, semantically enriched point clouds using Agisoft Metashape (Agisoft, 2020).
To project the category information stored in the RGB value combinations of the segmented images into the point clouds, the determined camera position and rotation are used.
The resulting point clouds are proofing the feasibility of our concept of an automatic generation and category projection. Despite the visible noise of the point clouds, the rooms are captured rather good. However, there are missing areas, often at the large and uniform components like walls and especially the ceiling, where the point cloud generation was problematic.
6 Reclassifying the Point Cloud
The colour values of the individual points are derived by interpolation of the overlapping values in the individual images (cf. Fig. 17.4). If their camera orientations in three-dimensional space are inaccurate or if the segmentations do not match, the interpolation results in erroneous values in the generated points (e.g. at the door).

Different views of the generated point clouds after the projection. There is no clear distinction of categories possible, as the colours changed through interpolation
To get a clear assignment of the categories, a reclassification of the point cloud is carried out by looking at the colours of the individual points in three-dimensional space and determining their Euclidean distance to the colour values of the individual categories. Additionally, the distances of the colour values of a point to those colour values are calculated, which result from the interpolation of a category with “Background” points as the most common class. If the distances to one of these are smaller than a threshold value, a direct assignment to the corresponding category is made.
In case that these criteria are not fulfilled, the neighbourhood of the points is examined for the assignment of the categories. If still no categories can be determined by distance and neighbourhood investigations, they are listed as an undefined “Background” point. The point clouds resulting from this step now contain clearly assigned categories for each point as shown in Fig. 17.5.

Different views of the reclassified point clouds. A sharp distinction between categories is now visible
Due to the overlapping of many segmented images, individual segmentation errors rarely influence the final classification of the point cloud. Incorrect category assignments mostly occur if there are systematic errors in the segmented images, the camera positions and rotations are inaccurate or the point cloud has deficiencies.
7 Quality Analysis of the Point Clouds
In Table 17.2 the quality results are shown. They are based on the comparison with manually segmented copies of each point cloud and enable us to extract data about the accuracy (ratio of correctly classified points of each category) and mean intersection over union (mIoU) of the categories present in both rooms. The overall good quality of the classification is confirmed by the mIoU with a value of 54.2%. This also applies for the calculated mean accuracy of 62.3%, which is showing a high consensus of the ground truth points.
Individual IoU numbers range from low values of “Light switch” to high values of “Door”. Especially bigger objects seem to be classified very good. The categories of “Socket” with 19.3% and “Light switch” with 6.5%, which represent very small objects, only achieve a low IoU in the point cloud. Partly contrary to this, the accuracy of “Light switch” is reaching a much better value with 48.9%. This is due to a comparingly high amount of interpolated and then wrongly assigned colours which belonged to points of the floor. Because the number of actual points of “Light switch” is small, these wrongly assigned points have a huge influence on the IoU.
Despite these minor effects, it is clearly visible that through projection and reclassification of the categories in the point clouds, a high quality of classification is reached.
8 Automated Post-processing
To relate our reclassified point clouds to the real world, we need a post-processing step. Since the point cloud was generated fully automatically and without the use of control points, neither its rotation in space nor its scale correspond to the real conditions. Extracting these is, however, possible based on our generated semantic information.
The points segmented as ground are used as basis and incorrectly classified points are filtered out. From the remaining selected points, the ground plane is derived. Then the point cloud is shifted to the origin and rotated in an iterative process until the ground plane is aligned horizontally. Next, the ceiling plane is determined from the corresponding points segmented as ceiling.
Subsequently, wall planes and wall points are extracted from the point cloud as they could not be considered in the segmentation. This is achieved based on a top view heat map created from the unclassified “Background” points of the point cloud, where the pixel values are based on the numbers of existing points of a grid. When viewed in two dimensions, an accumulation of points is to be expected especially on walls, as they are the vertically limiting elements of the rooms (Fig. 17.6).

Derived heat maps of both rooms used to extract the most prominent lines using Hough transform algorithm
The probable angles of the walls are extracted based on the most prominent lines determined by a Hough transform algorithm and then transferred into three-dimensional planes. Previously uncategorised points close to these are classified as wall and their actual best-fit planes are determined.
To achieve a correct scale for the point clouds, the dimensions of an object in the real world and a segmented object in the point cloud have to be adjusted. As an object of comparison, especially doors have proven to be well suited. Because the point clouds are correctly aligned, the height of objects can easily be extracted from its minimum and maximum values and is therefore used for comparison. The resulting scale is used to adjust the point cloud (Fig. 17.7).

Different views of the post-processed final point cloud. Rotation and scale are corrected. Extracted wall point is visible in the point cloud in light grey colour
When using the scaled point cloud for comparison, the extracted distances are matching the measured real distances often pretty well as shown in Table 17.3.
The extracted walls, floor and ceiling planes, automatically derived entirely from data, represent the room geometry in its basic features.
With our investigations and the solutions based on them, we have taken further important steps to enable automated BIM-compliant modelling of existing buildings.
9 Conclusions
In this paper, we present our methodology for automating BIM model generation from images and mobile laser scanning. We were able to verify that the combination of photogrammetry and deep learning is a solid approach to generate semantically enriched point clouds of interiors. The combined extraction of geometric and semantic information based on segmentation with DeepLabv3+ and projection into the photogrammetric point clouds achieves good results. In consequence, the components and objects can be differentiated very well in the point clouds. The reached mIoU of 54.2% for the classified point cloud confirms the good quality of this approach. Additional important information essential for a BIM model can be extracted by analysing and post-processing the point cloud.
As shown in the methodology, it is planned to extend this approach to the combination and joint processing of several rooms as well as including mobile laser scanners. With the methods presented here, we have created a solid basis for the acquisition and modelling of semantic and geometric information of interiors for BIM models towards their automated reconstruction.
References
Agisoft, 2020. Agisoft Metashape. http://www.agisoft.com/ (30 September 2020).
Borrmann, A., König, M. Koch, C., Beetz, J., 2015. Building Information Modeling - Technologische Grundlagen und industrielle Praxis. VDI-Buch, Springer Vieweg, Wiesbaden, 343-361.
Bramann, H., May, I. and planen-bauen 4.0 – Gesellschaft zur Digitalisierung des Planens, Bauens und Betreibens mbH, 2015a. Stufenplan Digitales Planen und Bauen. https://www.bmvi.de/SharedDocs/DE/Publikationen/DG/stufenplan-digitales-bauen.pdf?__blob=publicationFile (31 March 2020).
Bramann, H., May, I. and planen-bauen 4.0 – Gesellschaft zur Digitalisierung des Planens, Bauens und Betreibens mbH, 2015b. Konzept zur schrittweisen Einführung moderner, IT-gestützter Prozesse und Technologien bei Planung, Bau und Betrieb von Bauwerken – Stufenplan zur Einführung von BIM. https://www.bmvi.de/SharedDocs/DE/Anlage/DG/Digitales/bim-stufenplan-endbericht.pdf?__blob=publicationFile (31 March 2020).
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H., 2018. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Proceedings of the European conference on computer vision (ECCV), 801-818.
Clemen, C., Ehrich, R., 2014. Geodesy goes BIM. In: allgemeine vermessungs-nachrichten. (avn) 121 (6). https://gispoint.de/artikelarchiv/avn/2014/avn-ausgabe-62014/2552-geodesy-goes-bim.html (31 March 2020).
Egger, M., Hausknecht, K., Liebich, T., Przybylo, J., 2013. BIM-Leitfaden für Deutschland. https://www.bmvi.de/SharedDocs/DE/Anlage/DG/Digitales/bim-leitfaden-deu.pdf?__blob=publicationFile (31 March 2020).
Eschenbruch, K., Malkwitz, A., Grüner, J., Poloczek, A., Karl, C. K., 2014. Maßnahmenkatalog zur Nutzung von BIM in der öffentlichen Bauverwaltung unter Berücksichtigung der rechtlichen und ordnungspolitischen Rahmenbedingungen – Gutachten zur BIM-Umsetzung –. https://www.bmvi.de/SharedDocs/DE/Anlage/DG/Digitales/bim-massnahmenkatalog.pdf?__blob=publicationFile (31 March 2020).
Gülch, E. and Obrock, L., 2020: Automated semantic modelling of building interiors from images and derived point clouds based on Deep Learning, Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLIII-B2-2020, 421–426, https://doi.org/10.5194/isprs-archives-XLIII-B2-2020-421-2020, 2020.
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K. Q., 2017. Densely Connected Convolutional Networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261-2269.
Kaden, R., Clemen, C., Seuß, R., Blankenbach, J., Becker, R., Eichhorn, A., Donaubauer, A., Kolbe, T. H., Guber, U., DVW – Gesellschaft für Geodäsie, Geoinformation und Landmanagement e. V., Runder Tisch GIS e.V., 2019. Leitfaden Geodäsie und BIM Version 2.0 (2019). https://rundertischgis.de/images/2_publikationen/leitfaeden/GeoundBIM/Leitfaden%20Geod%C3%A4sie%20und%20BIM_Onlineversion.pdf (31 March 2020).
Krizhevsky, A., Sutskever, I., Hinton, G. E., 2012. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems (NIPS 2012), 1097 - 1105.
Long, J., Shelhamer, E., Darrell, T., 2015. Fully Convolutional Networks for Semantic Segmentation. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3431-3440.
Obrock, L. S., Gülch, E., 2018. First Steps to Automated Interior Reconstruction from Semantically Enriched Point Clouds and Imagery. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci., XLII-2, 781-787.
Ren, S., He, K., Girshick, R., Sun, J., 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Advances in Neural Information Processing Systems (NIPS 2015), 91-99.
Simonyan, K., Zisserman, A., 2015 Very Deep Convolutional Networks for Large-Scale Image Recognition. 3rd International Conference on Learning Representations (ICLR2015).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A., 2015. Going deeper with convolutions. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1-9.
Acknowledgements
The project “iCity: BIM-konforme Gebäudeerfassung” is sponsored by the Federal Ministry of Education and Research (BMBF) under the promotion code 13FH9E01IA and supervised by the project executing organisation VDI Technologiezentrum GmbH for the BMBF. The responsibility for the content lies with the authors.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this chapter

Cite this chapter
Obrock, L., Gülch, E. (2022). Deep Learning Methods for Extracting Object-Oriented Models of Building Interiors from Images. In: Coors, V., Pietruschka, D., Zeitler, B. (eds) iCity. Transformative Research for the Livable, Intelligent, and Sustainable City. Springer, Cham. https://doi.org/10.1007/978-3-030-92096-8_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-92096-8_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-92095-1
Online ISBN: 978-3-030-92096-8
eBook Packages: Economics and FinanceEconomics and Finance (R0)