
Abstract
It is an important means to ensure the safe operation of dam to establish accurate and effective deformation monitoring data analysis and prediction model. In view of the complex conditions in dam safety monitoring, there are many unknown or uncertain factors, and they are difficult to have a single model to apply all problems. The optimal weighted combination method is constructed by combining neural network model and support vector machine model, which is used in the deformation monitoring analysis of concrete dam. The research shows that the prediction results of the optimal weighted combination model are highly consistent with the measured results, and have certain feasibility and practicability in the dam deformation monitoring work.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

Keywords
1 Introduction
The analysis and prediction model of deformation monitoring data are significant to dam safety monitoring [1]. At present, statistical model [2], deterministic model [3] and mixed model are usually used to process and analyze dam monitoring data. Different processing methods have different advantages and certain applications in practical engineering, but these methods also have certain limitations. In the actual work of monitoring data analysis, insufficient data samples or complex environmental factors have a great impact on the establishment of the model, and the model may have more errors and poor fitting effect, so the model cannot be applied to the actual work [4].
The paper mainly researches the BP neural network model and support vector machine model (SVM) [5]. These two models are organically combined and applied to the dam deformation analysis example [6]. The results show that the optimal weighted combination model can maximize the information of each monitoring model, reduce the mean square error of the prediction model, and improve the accuracy of dam deformation monitoring [7]. This paper can provide new ideas and reference for dam safety monitoring data analysis and prediction model.
2 BP Neural Network Model
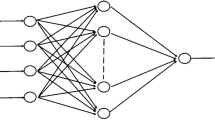
Artificial neural network (Ann) is a kind of distributed parallel information processing algorithm mathematical model which imitates the behavior characteristics of animal neural network [8]. The input signal xi acts on the output node through the intermediate node (Hidden layer point), and the output signal Yk is generated through nonlinear transformation [9]. Each sample of network training including the input vector x and the desired output t, network output value Y and t. By adjusting the wij which means connection strength between the input node and the hidden node, Tjk which means the connection strength between the hidden node and the output node, and the threshold, the error decreases along the gradient direction. After repeated learning and training, the training stops immediately when determining the network parameters (weights and thresholds) corresponding to the minimum error.
In the dam deformation monitoring system, we generally build the BP neural network of multi-layer perceptron composed of input layer, output layer and hidden layer, and determine the number of input layer node n, hidden layer node l, hidden layer excitation function f, and output layer node m. The connection weight wij and hidden layer threshold aj between the input layer and hidden layer are initialized, so that we can determine parameters such as learning rate and activation function. After the sample data is sent to the input node and processed layer by layer through the hidden layer, the following formula is used to calculate the output Hj of the hidden layer.
We initialize wjk which is the weight between the hidden layer and the output layer, and also the output layer threshold bk. Then the BP neural network will predict the output Ok..
According to the network prediction we can output Ok and Yk, and can press the following formula to calculate the network prediction error. This neural network will calculate the error value of each input sample data. If the error is relatively large, the error starts to reverse transmission, and adjust the neural network parameters until the system converges.
Through network training, weights wij and wjk which are updated according to network prediction error.
Next update the network node thresholds aj and bk.
If we determine the weights, we input the data into the model to predict the results.
3 SVM Support Vector Machine Model
Support vector machines are mostly used for classification problems, but they can also be used for regression, which is often referred to as support vector regression models [10]. The final model function is expressed as follows:
W and b are the main coefficients required by the model.
For a given training sample \(D = \{ (x_{1} ,y_{1} ),(x_{2} ,y_{2} ),...,(x_{m} ,y_{m} )\}\), traditional regression models usually calculate losses directly based on the difference between model output and true value, while SVR only calculates the loss when the difference between \(f(x)\) and \(y\) is greater than \({\upvarepsilon }\), and the parameters \({\upvarepsilon }\) is specified by the user. Therefore, according to other theories of support vector machine model, the optimization objective of SVR problem is written as follows.
The C is the loss coefficient, which can be specified by users or optimized by genetic algorithm. \(l\) is \({\upvarepsilon }\)’s insensitive loss function, calculating the loss only if the difference between f(x) and y is greater than \(\varepsilon\).
Considering the relaxation variable \({\upxi }\) and \({\hat{\xi }}_{{\text{i}}}\), the above equation can be rewritten as follows:
To solve the above problems, we first introduce the Lagrange multiplier: \(u_{i} \ge 0,u_{i}^{*} \ge 0,{\upalpha }_{i} \ge 0,{\upalpha }_{i}^{*} \ge 0\)
Construct the Lagrange function:
In order to find the minimum value of this function for \(w,b,{\upxi },{\hat{\xi }}\), the model take the partial derivative of \(w,\,b,\,{\upxi },\,{\hat{\xi }}\) respectively, and let the partial derivative be 0.
So the dual problem corresponding to SVR is follows:
We can solve the dual problem if the KKT condition is satisfied, and the KKT condition is as follows:
After taking partial derivatives, we substitute the various obtained into the dual formula and simplify, then can obtain the simplified dual formula.
SMO (Sequential Minimal Optimization) algorithm can solve the problem. Before solving, a* and ai should be converted into a coefficient, because SMO algorithm aims at the case that sample xi only has one parameter ai. It can be inferred from the first two expressions of the KKT (Karush–Kuhn–Tucker) condition that at least one of ai and a*i is 0. If we assume that \(\lambda_{i} = \alpha_{i} - \alpha_{{_{i} }}^{*}\), we can infer that \(|\lambda_{i} | = {\upalpha }_{i} + {\upalpha }_{{_{i} }}^{*}\). Since the formula continues to be reduced to a form with only one variable, we can calculate through the SMO algorithm. We also can conclude the value of \({\upalpha } - {\upalpha }^{*}\) to calculate the w.
We can figure up that if \(0 < {\upalpha }_{i} < C\) and \({\upalpha }_{i} (f(x_{i} ) - y_{i} - {\upvarepsilon } - {\upxi }_{i} ) = 0\), there will be \({\upxi }_{i} = 0\), so the calculation formula is as follows:
In the concrete implementation, the algorithm calculates all samples that meet the condition \(0 < {\upalpha }_{i} < C\) and takes the average of results.
4 Construction of Optimal Weighted Combination Model
In practice, suppose we construct m single dam deformation model ki(i = 1, 2, …m), and construct a composite model Kq = φ(k1, k2, …kn), n ≤ m and q is the number of model combination.
Let the weight vector of each single model in the combined model be \(p = [p_{1} ,p_{2} , \ldots p_{n} ]\), \(\sum\nolimits_{j = 1}^{n} {p_{j} } = 1\), then the combined prediction model is as follows:
The fitting residual of a single model can be expressed as follows:
Then each single forecast model can form a fitting residual matrix:
The objective function is solved according to the least square principle.
If R = [1, 1, …,1]T, the formula above becomes as follows:
The optimal weight vector is obtained:
By using the optimal weight ratio obtained from the above equation, the combined model prediction can maximize the information of each deformation model and reduce the mean square error of the prediction model, thus improving the accuracy of dam deformation analysis (Fig. 1).

Flow of BP-SVM combination model modeling
5 Analysis of Examples
The paper selects the monitoring data of PL02 measuring point from 2006/5/14 to 2019/12/20 and conducts modeling using the data from 2006 to 2018. Then, we use the 2019 causative data to predict the 2019 effect size data and compare with the measured data to verify the effectiveness of the model.
Factors such as water level, temperature and time mainly affect the displacement and deformation of concrete gravity dams, and Table 1 shows the setting of influencing selection factors.
In order to prove the effectiveness and superiority of the combined model proposed in this paper, the example trains data and predicts result through the combined model, BP model and SVM model. Each model uses the same training samples and test data as control variables. In data processing, the input factor of the model is water level, temperature and aging, and the output factor is the predicted dam displacement.
The correlation coefficient is the fitting accuracy evaluation index in the model analysis and comparison. Table 2 shows the calculation results of the overall modeling accuracy index for each model. It can be seen that the training and prediction correlation coefficients of the combined model are higher than those of other models, indicating its high accuracy and more suitable for dam deformation prediction.
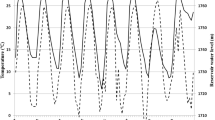
According to the modeling result and process line in Figs. 2 and 3, we can conclude that the monitoring data of PL02 measurement point from 2006 to 2018 are better modeled by the combined model.

Comparison between calculated value of model and measured value

The results of combination model and each sub-model are compared
Table 3 shows that the error of some calculated values in the optimal weighted combination model is larger than other models, the reason may be the influence of some abnormal points in the training process on the calculation results. In general, the calculation accuracy of the optimal weighted combination based on BP + SVM is higher than that of other models.
We can conclude from the above chart, that the fitting accuracy of BP model is lower than the SVM model. The combined model adopts the optimal weighted grouping method to reasonably determine the weight of the two models. Finally, the weight of the SVM model is higher, the BP is lower, and the relative relationship is reasonable. The fitting effect of the combined model is better than that of the sub-model, which indicates that the optimal weighted combination method is effective. It can be seen from Table 3 that the combined model is superior to the statistical model in all indicators of the training and prediction process, indicating that the optimization method adopted by the combined model is effective and further improves the calculation accuracy of the model.
6 Conclusion
Due to the complex dam working conditions and many influencing factors, a single analysis model is insufficient in stability. This paper adopts the optimal weighted combination method and organically combines the BP neural network model with support vector machine model (SVM), and the model can gain better and more stable modeling and prediction results. The model automatically determines the optimal weight, which improves the stability and prediction accuracy of the model and reduces the manual parameter adjustment.
The modeling and prediction results of the model are highly consistent with the measured results, and the overall accuracy of the model training results is good, indicating that the model is effective. From the results, the accuracy of the BP model is relatively low, while the accuracy of the SVM model is higher, and the combined model is better than other models. The optimal weighted combination method uses the best weight combination to ensure the reliability and stability of the final calculation results. When the model factors and options are not set properly, the optimal weighted combination model has stronger robustness and intelligence than the single model, which is helpful to obtain better calculation results.
References
Jiang Z, Xu Z, Wei B (2016) Monitoring model of dam displacement based on wavelet decomposition and support vector machine. J Yangtze River Sci Res Inst 33(1):43–47
Hongbo Y, Zhou B, Lu X et al. (2019) Prediction of dam deformation monitoring data based on EEMD-GA-BP model [J]. J Yangtze River Sci Res Inst. 36(9):6
Zhu M, Zhou X, Wang K (2016) Dam deformation monitoring model based on CS-SVM model [J]. Cryog Constr Technol 38(11):3
Wu Z (2003) Safety monitoring theory and application of hydraulic building [M]. Higher Education Press
Huang Z, Liao M, Zhang H, Zhang J, Ma S (2020) Prediction of surrounding rock deformation based on Incomplete data of SVM-BP Model [J]. Mod Tunn Technol 57(S1):141–150
Qin Z, Yang F, Huang S (2022) Prediction model of dam slope deformation based on GA-BP algorithm [J] (1)
Wang Y, Su H (2020) Prediction of dam deformation based on PCA-GMO-SVM [J]. Yellow River 42(423)(11):134–138
Haiyan X, Lihan Z (2010) Prediction model of dam settlement based on BP neural network [J]. Water Sci Eng Technol 1:3
Hongfei G, Ping J, Fei G et al (2019) Prediction analysis of slope stability based on BP neural network [J]. Coal Geol China 31(A01):3
Su H, Chen Z, Wen Z (2016) Performance improvement method of support vector machine-based model monitoring dam safety[J]. Struct Control Health Monit 23(2):252–266
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 Crown
About this chapter

Cite this chapter
Li, S., Li, Y., Zheng, M., Geng, J., Liu, Z., Shi, B. (2023). Research on Dam Deformation Monitoring Model Based on BP + SVM Optimal Weighted Combination. In: Yang, Y. (eds) Advances in Frontier Research on Engineering Structures. Lecture Notes in Civil Engineering, vol 286. Springer, Singapore. https://doi.org/10.1007/978-981-19-8657-4_28
Download citation
DOI: https://doi.org/10.1007/978-981-19-8657-4_28
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-8656-7
Online ISBN: 978-981-19-8657-4
eBook Packages: EngineeringEngineering (R0)