
Abstract
As a generalization of the fuzzy soft set, interval-valued fuzzy soft set is viewed as a more resilient and powerful tool for dealing with uncertain information. However, the lower or upper membership degree, or both of them, may be missed during the data collection and transmission procedure, which could present challenges for data processing. The existing data filling algorithm for the incomplete interval-valued fuzzy soft sets has low accuracy and the high error rate which leads to wrong filling results and involves subjectivity due to setting the threshold. Therefore, to solve these problems, we propose a KNN data filling algorithm for the incomplete interval-valued fuzzy soft sets. An attribute-based combining rule is first designed to determine whether the data involving incomplete membership degree should be ignored or filled which avoids subjectivity. The incomplete data will be filled according to their K complete nearest neighbors. To verify the validity and feasibility of the method, we conduct the randomized experiments on the real dataset as Shanghai Five-Four Hotel Data set and simulated datasets. The experimental results illustrate that our proposed method outperform the existing method on the average accuracy rate and error rate.
Similar content being viewed by others
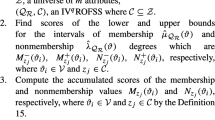

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Data in many real-world issues tend to be ambiguous and imprecise, which presents severe difficulties for effective data-driven decision making [1,2,3,4,5, 42]. To deal with uncertainties, Molodtsov [6] developed the idea of a soft set as a universal mathematical tool, which overcame the weaknesses of the classical mathematical tools for dealing with uncertain data such as probability theory, rough sets, and fuzzy sets so on. Active research [7, 8] has been done to improve the definitions and operations of classical soft sets. Soft set theory has been developed and applied to other fields [9,10,11] to solve practical problems.
The soft set theory has no issues with setting the membership function, which promotes the combination of the soft set with other models. There are many extended models such as fuzzy soft sets [13], bipolar complex fuzzy soft sets [14], hesitant fuzzy soft sets [15, 16], vague soft sets [18,19,20], soft rough sets [17, 21, 22], rough soft sets [23,24,25], and intuitionistic fuzzy soft sets [12, 26] so on. The interval-valued fuzzy soft set (IVFSS) is one of the successful extended models of soft set theory. Yang et al. [27] proposed the concept of IVFSS by combining the soft set and interval-valued fuzzy set models. This model has been effectively utilized in decision-making applications. In [28], Ali et al. established interval-valued fuzzy soft pre-sorting and interval-valued fuzzy soft equivalence and proposed two sets of crisp pre-sorting. A scoring function that depends on the comparison matrix was proposed, which showed good performance when solving multi-group decision problems. Qin et al. [29] proposed a decision-making method based on IVFSS using contrast tables. The objective of parameter reduction is to remove those redundant parameters that have little or no effect on the decision. Ma et al. [30] proposed four heuristic parameter reduction algorithms, which were verified in terms of ease of applicability, finding reduction, exact level for reduction, reduction result, applied situation, and computational complexity. The four algorithms retain certain decision-making abilities while reducing redundant parameters. Ma et al. [31] proposed a decision algorithm that is relatively computationally inexpensive and takes into account added objects. The algorithm has higher scalability and flexibility for large-scale datasets. Pairote [32] integrated IVFSS with semigroups. Nor et al. [33] established an axiomatic definition of entropy based on subsets for IVFSS and introduced an entropy measure, which is used to calculate the degree of fuzziness of a particular interval-valued fuzzy soft set. Zhang et al. [34] proposed an improved decision-making method by introducing operators and using a comparable table of IVFSS.
However, a lot of incomplete information will be involved in the actual application process, which is not conducive to decision-makers making correct decisions. Therefore, it is necessary to deal with incomplete information. Among the methods for dealing with missing data, data filling methods have attracted the attention of researchers. In 2008, Zou et al. [35] proposed data analysis methods of soft sets under incomplete information environment. However, which involved high computational complexity and were difficult to understand. To simplify the method, Kong et al. [36] directly proposed the simplified probability to replace incomplete information and proved the equivalence between the weighted average method [35] of all possible choice values and the simplified probability method. In [37], Xia et al. proposed a new decision-making method based on the soft set theory to solve the MCDM problem with redundant and incomplete information, which can be directly used for the original redundant and incomplete dataset. Kong et al. [38] proposed a new method of data filling based on the probability analysis in the incomplete soft set. It also avoids the influence of subjective factors on the threshold and has good objectivity. In [39], Qin et al. proposed a data analysis method for incomplete interval-valued intuitionistic fuzzy soft sets. This method fully considers and utilizes the characteristics of interval-valued intuitionistic fuzzy soft sets.
Due to the particularity of membership in interval-valued fuzzy soft sets (membership degrees are expressed by interval data), the methods in [35,36,37,38,39] for dealing with incomplete data are not suitable for processing interval-valued fuzzy soft sets with incomplete information. Therefore, it is necessary to study data analysis methods based on the interval-valued fuzzy soft sets under incomplete information. Qin et al. [40] proposed a data analysis method for interval-valued fuzzy soft sets under incomplete information. This method deals with missing data through the relationship between the percentage of missing items and the threshold, which provides a new idea for filling incomplete data. However, the method is subjective in setting the threshold of percentage of missing entries and has the weakness of lower accuracy and higher error rate. To address the problems of this method, we propose a KNN data filling method for IVFSS. This method reasonably fills the missing data by introducing K-nearest neighbors (KNN). The main work of this paper is as follows:
-
(a)
We discover that the filling results by the existing method in [40] have the probability to dissatisfy the constraints of the interval-valued fuzzy soft set as \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\).
-
(b)
We propose a KNN data filling method based on the interval-valued fuzzy soft sets. The experimental results on the Shanghai five-four star hotel dataset and simulated datasets illustrate that our method has a higher accuracy rate and a significantly lower error rate compared with the existing method in [40].
-
(c)
An attribute-based combining rule is proposed to determine whether values containing incomplete data should be ignored or filled which avoids subjectivity.
The rest of the paper is organized as follows. In Sect. 2, we mainly review the basic concepts of this model and the existing data analysis methods based on the incomplete interval value fuzzy soft sets. Section 3 describes the steps of our proposed KNN data filling method based on the incomplete interval-valued fuzzy soft sets. In Sect. 4, experiments are conducted on the Shanghai five-four star hotel datasets and simulated datasets. By comparing with the existing algorithms, the accuracy and feasibility of the method are verified. Section 5 is the conclusion of this paper.
2 Preliminaries and Related Work
In this section, we briefly review some basic definitions of IVFSS. At the same time, the existing data analysis approach of IVFSS under incomplete information is recalled.
2.1 Preliminaries
Let \(U = \{ h_{1} ,h_{2} ,...,h_{n} \}\) be a nonempty initial universe of objects and \(E = \{ e_{1} ,e_{2} ,...e_{m} \}\) be a set of parameters in relation to objects in \(U\) respectively. Let \(P(U)\) be the power set of \(U\), and \(A \subseteq E\). The definition of soft set is given as follows.
Definition 2.1
[1]: A pair \((F,A)\) is called a soft set over U, where \(F\) is a mapping given by F:
Let \(U\) be an initial universe of objects,\(E\) be a set of parameters in relation to objects in U, \(\xi (U)\) be the set of all fuzzy subsets of U. The definition of fuzzy soft set is given as follows.
Definition 2.2
[12]: A pair \((\tilde{F},E)\) is called a fuzzy soft set over \(\zeta (U)\), where \({\tilde{\text{F}}}\) is a mapping given by \({\tilde{\text{F}}}\):
Definition 2.3
[27]: Let \(\hat{X}\) be an interval-valued fuzzy set on a universe \(U\), where \(\hat{X}\) is a mapping such that:
where \(\hat{X} \in \xi (U)\) for every \(x \in U\) and \(\xi (U)\) represents the set of all interval-valued fuzzy sets on U. \(Int([0,1])\) represents the set of all closed subintervals of [0, 1].\(\mu_{{\hat{X}}}^{ - } (x)\) and \(\mu_{{\hat{X}}}^{ + } (x)\) represent the lower and upper degrees of membership \(x\) to \(\hat{X}(0 \le \mu_{{\hat{X}}}^{ - } (x) \le \mu_{{\hat{X}}}^{ + } (x) \le 1)\), respectively.
Definition 2.4
[27]: Let \(U\) be an initial universe of objects and \(E\) be a set of parameters in relation to objects in \(U\). A pair \((\varpi ,E)\) is called an interval-valued fuzzy soft set over \(\tilde{\psi }(U)\), where \(\varpi\) is a mapping given by.
\(\forall \varepsilon \in E,\varpi (\varepsilon )\) is interpreted as the interval fuzzy value set of parameter \(\varepsilon\). It is actually an interval-valued fuzzy set of \(U\), where \(x \in U\) and \(\varepsilon \in E\), which can be written as \(\varpi (\varepsilon ) = \left\{ {\left\langle {x,\mu_{\varpi (\varepsilon )} (x)} \right\rangle :x \in U} \right\}\). Where \(\varpi (\varepsilon )\) is the interval-valued fuzzy membership degree that object \(x\) holds on parameter \(\varepsilon\).
2.2 The Existing Data Filling Methods for Incomplete Interval-Valued Fuzzy Soft Sets
In this section, we briefly introduce the existing data analysis approach of interval-valued fuzzy soft sets under incomplete information. An example is given to illustrate it.
2.2.1 Average Based Data Filling (ADF) Algorithm for Incomplete Interval-Valued Fuzzy Soft Sets [40]
Input: IVFSS \((\tilde{S},E)\), the parameter set \(E\). The threshold of missing entries and weights \(\lambda_{o} = \lambda_{p} = \frac{1}{2}\).
-
1.
For every parameter, if \(Pe{r}_{S({e}_{a})}^{*}>{r}_{p}\) (\(Pe{r}_{S({e}_{a})}^{*}\) is the percentage of missing entries for parameter ea), the corresponding parameter is ignored. For every object, if \(Per_{{S(h{}_{b})}}^{*} > r_{o}\), the corresponding object is ignored.
-
2.
Find \(\mu_{{\tilde{S}(ea)}}^{*} (h_{b} )\) as the missing degree of membership.
-
3.
Compute \(d_{{\tilde{S}(ea)}}^{ - *} (h_{b} )\) and \(d_{{\tilde{S}(ea)}}^{ + *} (h_{b} )\) as predicted membership degrees for \(e_{a}\).
-
4.
Obtain \(p_{{\tilde{S}(ea)}}^{ - *} (h_{b} )\) and \(p_{{\tilde{S}(ea)}}^{ + *} (h_{b} )\) as predicted membership degrees for \(h_{b}\).
-
5.
Fill the missing degree of membership by
$$\mu_{{S(e_{a} )}}^{ - *} (h_{b} ) = \lambda_{d} d_{{S(e_{a} )}}^{ - *} (h_{b} ) + \lambda_{p} p_{{S(e_{a} )}}^{ - *} (h_{b} )$$$$\mu_{{S(e_{a} )}}^{ + *} (h_{b} ) = \lambda_{d} d_{{S(e_{a} )}}^{ + *} (h_{b} ) + \lambda_{p} p_{{S(e_{a} )}}^{ + *} (h_{b} )$$
Output: a complete interval-valued fuzzy soft set.
One Example is given to present the method in [40].
Example 2.1
Suppose that \(U = \{ h_{1} ,h_{2} ,h_{3} ,...,h_{14} \}\) is a set including 14 objects, \(E = \{ e_{1} ,e_{2} ,e_{3} ,e_{4} ,e_{5} ,e_{6} \}\) involving six parameters. The incomplete interval-valued fuzzy soft set as shown in Table 1. Here is a brief filling process.
for parameters and objects as \(r_{p} = r_{o} = 0.8\), and give the weights as \(\lambda_{d} = \lambda_{p} = \frac{1}{2}\). Finally, Table 1 is converted to the complete interval-valued fuzzy soft set shown in Table 2 by the method [40].
Through our observation, it is found that Filling results: \(\mu_{{\tilde{S}(e2)}}^{*} (h_{9} ) = {[0}{\text{.77,}}\,{0}{\text{.75]}}\) and \(\mu_{{\tilde{S}(e4)}}^{*} (h3) = [0.85,0.81]\) do not satisfy the constraints of the interval-valued fuzzy soft set as \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\). That is, there exist filling results that exceed the limit. Meanwhile, the existing data analysis methods based on the interval-valued fuzzy soft sets have disadvantages such as lower accuracy and more subjectivity. To solve these problems, a new KNN data filling algorithm based on the interval-valued fuzzy soft sets is proposed in this paper.
3 The Proposed Data Filling Algorithm
In this section, we first propose some new related definitions. Subsequently, a new KNN data filling method based on the interval-valued fuzzy soft sets is proposed. An attribute-based combining rule is first designed to determine whether the incomplete data should be ignored or filled. For the remaining incomplete data, it will be filled according to its K complete nearest neighbors. This method avoids subjectivity, and the accuracy of filling results is significantly improved.
3.1 The Related Definitions
Definition 3.1
For an interval-valued fuzzy soft set \((\tilde{F},E)\), \(E = \left\{ {e_{1} ,e_{2} ,...,e_{m} } \right\}\) and \(U = \left\{ {h_{1} ,h_{2} ,...,h_{n} } \right\}\).\(\mu_{{\tilde{S}(e{\text{j}})}}^{{ - *}} (h_{i} )\) and \(\mu_{{\tilde{S}(e{\text{j}})}}^{{ + {*}}} (h_{i} )\) represent the incomplete lower degree of membership and upper degree of membership,respectively. To determine whether incomplete data should be ignored or filled, an attribute-based combining rule is proposed, defined as follows.
where \(\mu_{{\tilde{S}(e{\text{j}})}}^{ - } (h_{i} )\) and \(\mu_{{\tilde{S}(e{\text{j}})}}^{ + } (h_{i} )\) represent the lower degree of membership and upper degree of membership, respectively. \(\mu_{{\tilde{S}(e{\text{j}})}}^{ - } (h_{i} )\) and \(\mu_{{\tilde{S}(e{\text{j}})}}^{ + } (h_{i} )\) of incomplete data are set as 0 in above formula.
-
(1)
\(F_{ej} = 0\), ignore filling the incomplete data with attribute \(e_{j}\). (Each object has missing values in the attribute \(e_{j}\)).
-
(2)
\(F_{ej} \ne 0\), fill the incomplete data according to our algorithm. (At least one object has a complete degree of membership on attribute \(e_{j}\)).
When \(\mu_{{\tilde{S}(e{\text{j}})}}^{{ - *}} (h_{i} )\) or \(\mu_{{\tilde{S}(e{\text{j}})}}^{{ + {*}}} (h_{i} )\) as missing data are presented in all elements of an attribute, this means that the original dataset contains incomplete data for each object. In other words, no object for the attribute provides complete and accurate information. To avoid amplifying the uncertainty, the filling of incomplete data under this attribute will be ignored. In addition, this rule does not require setting the threshold of missing items, which is different from the existing method, thus avoiding subjectivity.
Inspried by Qi et al. [41], the definition of distance between the object involving incomplete data and the object with complete data is given as follows.
Definition 3.2
The distance between the object \(h_{a}\) involving incomplete data and the object \(h_{b}\) with complete data is defined as.
\(\mu_{{\tilde{S}(e{\text{j}})}}^{ - } (h_{a} )(\mu_{{\tilde{S}(e{\text{j}})}}^{ - } (h_{b} )\) represents the lower degree of membership of object \(h_{a} (h_{b} )\) and \(\mu_{{\tilde{S}(e{\text{j}})}}^{ + } (h_{a} )(\mu_{{\tilde{S}(e{\text{j}})}}^{ + } (h_{b} )\) represents the upper degree of membership of object \(h_{a} (h_{b} )\).
for j = 1,2,…,m.
3.2 The Proposed Algorithm
Based on the above definitions, we give our algorithm as follows:
Input: Incomplete interval-valued fuzzy soft set \((\tilde{F},E)\) and parameter set \(E\).
Step 1: Determine \(\mu_{{\tilde{S}(ej{)}}}^{{ - *}} (h_{i} )\) and \(\mu_{{\tilde{S}(ej)}}^{{ + {*}}} (h_{i} )\) as the unknown degree of membership of an element \(h_{i}\) to \(\tilde{S}(e_{j} )\).
Step 2: Judge whether the incomplete data needs to be filled or ignored according to the attribute-based combining rules. If \(F_{ej} = 0\), ignore filling the incomplete data with attribute \(e_{j}\). Else, fill the incomplete data with attribute \(e_{j}\).
Step 3: Use the distance formula (6) to calculate the distance between the object that contains incomplete data and the other objects involving complete data, and sort the distance.
Step 4: Find the optimal K value. In detail, extract incomplete object composition U′ as training dataset, and randomly delete data as missing membership degree values in U′ (that is, choose one membership degree value as training data every row in U′). Repeat steps 1–3 to fill the randomly deleted data in order to find the optimal K value which has the highest average accuracy.
Step 5: Fill the incomplete data which can be calculated according to the following formula:
When the incomplete data is the lower degree of membership:
When the missing value is the upper degree of membership:
\(k\) represents the number of K-nearest neighbors which is obtained in the above step. \(\mu_{{\tilde{S}(e{\text{j}})}}^{ - } (h_{i} )\) and \(\mu_{{\tilde{S}(e{\text{j}})}}^{ + } (h_{i} )\) represent the upper and lower degree of membership of K complete nearest neighbors, respectively.
Output: a complete interval-valued fuzzy soft set.
Figure 1 depicts the flowchart of our proposed new method.

Flow chart of KNN data filling method
3.3 Example
The following example is provided to demonstrate this method.
Consider the incomplete interval-valued fuzzy soft set shown in Table 1 and use the KNN data filling method to predict the incomplete data. The prediction steps are as follows.
Input: Incomplete interval-valued fuzzy soft sets, as shown in Table 1.
-
(1) Find
$$[\mu_{{_{{\tilde{S}(e1)}} }}^{ - *} (h_{5} ),\mu_{{_{{\tilde{S}(e1)}} }}^{ + } (h_{5} )] = [*,0.75]\,[\mu_{{_{{\tilde{S}(e2)}} }}^{ - } (h_{9} ),\mu_{{_{{\tilde{S}(e2)}} }}^{ + *} (h_{9} )] = [0.77,*]$$$$[\mu_{{_{{\tilde{S}(e3)}} }}^{ - *} (h_{12} ),\mu_{{_{{\tilde{S}(e3)}} }}^{ + } (h_{12} )] = [*,0.80]\,[\mu_{{_{{\tilde{S}(e4)}} }}^{ - } (h_{3} ),\mu_{{_{{\tilde{S}(e4)}} }}^{ + *} (h_{3} )] = [0.85,*]$$$$[\mu_{{_{{\tilde{S}(e5)}} }}^{ - *} (h_{7} ),\mu_{{_{{\tilde{S}(e5)}} }}^{ + } (h_{7} )] = [*,0.78]\,[\mu_{{_{{\tilde{S}(e6)}} }}^{ - } (h_{2} ),\mu_{{_{{\tilde{S}(e6)}} }}^{ + *} (h_{2} )] = [0.78,*]$$ -
(2) Using the combining rules to judge whether the incomplete data needs to be filled or ignored.
Calculate:
Similarly:
Therefore, no parameter can be ignored. That is, we keep all parameters, and missing data must be filled.
-
(3) Calculate the distance between objects containing incomplete data and other objects which have the complete data. Taking the example of filling the incomplete data \(\mu_{{\tilde{S}(e{1})}}^{{ - *}} (h_{5} )\):
$$\begin{gathered} D_{{{\text{avg}}}} (h_{5} ,h_{1} ) = \sqrt {(|0 - 0.88|^{2} \times 0 + |0.75 - 0.9|^{2} \times 1) + ... + (|0.69 - 0.47|^{2} \times 1 + |0.72 - 0.82|^{2} \times 1)} \hfill \\ \quad \quad \quad \quad \quad = \sqrt {0.1168} \hfill \\ \end{gathered}$$
Similarly,
And sort the distances as:
\(D_{avg} (h_{5} ,h_{13} ) < D_{avg} (h_{5} ,h_{14} ) < D_{avg} (h_{5} ,h_{1} ) < D_{avg} (h_{5} ,h_{8} ) < D_{avg} (h_{5} ,h_{4} ) < D_{avg} (h_{5} ,h_{6} ) < D_{avg} (h_{5} ,h_{10} ) < D_{avg} (h_{5} ,h_{11} )\)
-
(4) Find the optimal K value.
Extract incomplete objects to form a new incomplete interval-valued fuzzy soft set U′ as training dataset shown in Table 3.
In U′, delete one data randomly every row and record it as **. Get a new interval-valued fuzzy soft set U′″, as shown in Table 4
Calculate the distance between objects containing incomplete data and other objects having complete data. Take filling \(\mu_{{\tilde{S}(e{2})}}^{{ - *}} (h_{9} )\) as an example:
Similarly,
Sorting the distances as:
\(D_{avg} (h_{9} ,h_{13} ) < D_{avg} (h_{9} ,h_{14} ) < D_{avg} (h_{9} ,h_{6} ) < D_{avg} (h_{9} ,h_{8} ) < D_{avg} (h_{9} ,h_{4} ) < D_{avg} (h_{9} ,h_{1} ) < D_{avg} (h_{9} ,h_{11} ) < D_{avg} (h_{9} ,h_{10} )\) Select the K-nearest neighbors and fill the randomly deleted data ** with their average values (Table 5).
-
(5) Filling the incomplete data: \(\mu_{{\tilde{S}(e{1})}}^{{ - *}} (h_{5} ) = \frac{{\mu_{{\tilde{S}(e1)}}^{ - } (h_{13} ) + \mu_{{\tilde{S}(e1)}}^{ - } (h_{14} )}}{2} = \frac{0.56 + 0.56}{2}\). Repeat step 3 and step 5 to fill all of the missing data.
Output: complete interval-valued fuzzy soft set shown in Table 6.
We examine the filling results by Average based Data Filling (ADF) Algorithm for incomplete interval-valued fuzzy soft sets [40] in Table 2 and our KNN data filling algorithm in Table 6. It is clear that the algorithm [40] suffers from the error that the filling result does not satisfy the condition \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\), while our method meets this condition. And there is subjectivity in the setting of the threshold value during the filling process in the method [40]. In our newly proposed KNN data filling method, the attribute-based combining rule avoids subjectivity and makes the filling process more reasonable.
4 Experimental Results and Analysis
In this section, we make the comparison between our method and the idea in [40] from the two evaluation indicators as accuracy and error rate. We perform two methods on five groups experiments. Experiment 1, Experiment 2 and Experiment 3 are constructed on the Five-Four star shanghai hotel dataset in order to validate superiority of our method about accuracy. Experiment 4 and Experiment 5 are based on randomly generated datasets for verifying the good performance of our method in reducing the error rate.
4.1 Evaluation Indicators
Firstly, we present the two evaluation indicators as follows.
4.1.1 Accuracy Verification
To measure the accuracy of the filling results, we give the definitions of accuracy and average accuracy.
Accuracy is defined as:
where S0 is the true value and Si is the predicted value.
Average accuracy rate is defined as:
where t is the number of missing value.
4.1.2 Error Rate
During the data filling process, the filling value is possible to exceed the limit. That is, some filled results do not satisfy the constraints of the interval-valued fuzzy soft set as \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\) which is regarded as one error. We use the error rate to measure it.
The error rate is defined as:
where n is the number of data which filled value exceeds the limit and N is the number of all incomplete data in the whole dataset that needs to be filled.
4.2 Accuracy Verification
To verify the accuracy of the KNN data filling method, we use the Five-Four star shanghai hotel dataset in [40]. Through multiple experiments, the average accuracy results of our method and the approach in [40] are compared.
4.2.1 Five-Four Star Shanghai Hotel Data Set (14 × 7)
We apply a dataset of Five-Four star shanghai hotel data set in [40] presented in Table 7.
In this evaluation system, there are 14 candidate hotels. \(U = \{ h_{1} ,h_{2} ,h_{3} ,...,h_{14} \}\) and seven attributes as diverse as “Staff performance”, “Location”, “Hotel condition/cleanliness”, “Value for Money”, “Room comfort/standard”, “Food/Dining” and “Facilities”.
In this experiment, the missing values are randomly selected from the Five-Four star shanghai hotel dataset. We set up three groups of experiments to verify the accuracy of our method.
4.2.1.1 Experiment 1
We randomly select 5 single degrees of membership (Upper or lower degree of membership) from the initial dataset and note them as *. After performing our proposed KNN data filling method and Average based Data Filling (ADF) Algorithm for incomplete interval-valued fuzzy soft sets [40], we obtain the predicted values. Then, the accuracy and the average accuracy are calculated by using the formula (9) and formula (10).
We take one of the randomized experiments as an example:
Applying our proposed KNN data filling method to fill the missing data, we obtain the following predicted values:
After executing the algorithm [40], we obtain the following predicted values:
Applying our proposed KNN data filling method to fill the missing data, the average accuracy of the filling result is 98.65%. By means of ADF, the average accuracy of the filling result is 96.33%, and the missing value \([\mu_{S(e2)}^{ - } (h_{9} ),\mu_{S(e2)}^{ + *} (h_{9} )] = [0.82,\underline{0.78} ]\) does not satisfy the restriction: \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\).
Repeating this random sampling process 15 times, the missing data are filled using ADF [40] and our method. The comparison on the average accuracy between our method and algorithm [40] are shown in Fig. 2.

Average accuracy rate (single degree of membership)
The experimental results show that among 15 groups of randomized experiments: The KNN data filling method has a higher average accuracy in nine groups. ADF [40] has five groups with higher average accuracy and 1 group with equal average accuracy. Overall, the average accuracy of the newly proposed KNN data filling method is 94.35%, and the average accuracy of the algorithm [40] is 91.85%. The KNN data filling method has a higher accuracy rate and the filling results are more reasonable and effective.
4.2.1.2 Experiment 2
We randomly select five data from the initial dataset and note them as [*,*]. After executing our proposed KNN data filling method and ADF [40], we obtain the corresponding predicted values.
Taking one of the randomized experiments as an example, we randomly select the double degree of membership elements as:
After executing our proposed KNN data filling method, we obtain the following predicted values:
After executing ADF, we obtain the following predicted values:
Applying our proposed KNN data filling method to fill the missing data, the average accuracy of the filling result is 96.85%. The average accuracy of the filling result is 96.61% by the method of ADF [40].
Repeating this random sampling process 15 times, experimental results are shown in Fig. 3.

Average accuracy rate (Double degree of membership)
The experimental results showed that the average accuracy of the algorithm [40] is 90.08%, the average accuracy of the KNN data filling method proposed in this paper is 93.82%. When compared with the algorithm [40], the overall performance of KNN data filling method is improved by 3.74%.
4.2.1.3 Experiment 3
We randomly select six data (three double degrees of membership and three single degrees of membership) from the initial dataset noted as * and [*,*]. After executing our proposed KNN data filling method and the algorithm [40], we obtain the corresponding predicted values. Through the true value and the predicted value, the accuracy and average accuracy corresponding to each algorithm are obtained.
Taking one of the randomized experiments as an example, we randomly select unknown degree of membership elements as:
After executing our proposed KNN data filling method, we obtain the following predicted values:
After executing the algorithm [40], we obtain the following predicted values:
The experimental results show that the average accuracy of algorithm [40] is 95.15%. Applying our proposed KNN data filling method to fill the missing data, the average accuracy of the filling result is 97.74%. When compared with algorithm [40], the overall performance of KNN data filling method is improved by 2.59%.
Similarly, the experimental results on fifteen experiments are shown in Fig. 4.

Average accuracy rate (Single and double degree of membership)
The experimental results show that the average accuracy of the newly proposed KNN data filling method is 95.24%. While the average accuracy of the algorithm [40] is 90.89%.
From the above three groups experiments, it is obvious that our method outperforms the method in [40] on the accuracy illustrated in Table 8.
4.2.2 Error Rate Verification
An interval-valued fuzzy soft set is randomly generated and multiple random experiments are performed on this dataset. The lower the error rate, the higher the reliability of the algorithm and the better the filling effect.
4.2.2.1 Experiment 4
A 14×6 interval-valued fuzzy soft set is randomly generated as shown in Table 9. Six data are randomly selected as missing data from this dataset, and the selection results are shown in Table 9.
The missing data are filled using algorithm [40] and our method, respectively. The filling results are shown in Tables 10 and 11.
From the analysis of Table 10, it can be seen that by applying the algorithm [40], the filling results as [0.83, 0.80] and [0.74, 0.71] do not satisfy the constraints of interval-valued fuzzy soft sets: \(0 \le \mu_{{_{{\tilde{S}(ej)}} }}^{ - *} (h_{i} ) \le \mu_{{_{{\tilde{S}(ej)}} }}^{ + } (h_{i} ) \le 1\). The filling results are unreasonable, which can easily lead to decision-makers making wrong decisions.
According to the results in Table 11, the KNN data filling method newly proposed in this paper is used to fill the missing data, and the filling results all satisfy the constraints of the interval-valued fuzzy soft set.
The error rate comparison between our KNN and the method in [40] is show in Table 12.
4.2.2.2 Experiment 5
To verify the reliability of the results, we randomly generate 30×35 interval-valued fuzzy soft sets, where \(U = \left\{ {h_{1} ,h_{2} ,...,h_{30} } \right\}\) and \(E = \left\{ {e_{1} ,e_{2} ,...,e_{35} } \right\}\) 0.15 data are randomly removed from the initial dataset, which are noted as *. The incomplete data are filled with the algorithm [40] and our KNN data filling method, respectively. This random process is repeated 15 times. The filling results are shown in Fig. 5.

Errors rate comparison
Analysis of Fig. 5 shows that using algorithm [40] to fill the missing data, the average error rate of the fill result is 8.89%. By our KNN data filling method to fill the missing data, and the error rate is 2.23% which are shown in Table 13. The lower error rate means that the algorithm is more efficient and reliable.
Therefore through experiments, it is verified that our proposed KNN data filling method is more accurate and reliable when compared with the existing method.
5 Conclusion
The research on decision making and parameter reduction based on complete interval-valued fuzzy soft sets has become very active. However, in the practical application of interval-valued fuzzy soft sets, we have to deal with a large amount of incomplete data. In this paper, we propose a novel KNN data filling method for incomplete interval-valued fuzzy soft sets. When compared with the current filling technique, the advantages of the proposed KNN method include: (1) Attribute-based combining rule is made to evaluate if missing value data should be filled in or ignored, which avoids subjectivity without setting the threshold. (2) Our method has the higher average accuracy rates when compared with the current technique. (3) Our approach involves the lower error rate which assures the reliability of filling results. Therefore, our method outperforms the existing method.
Data Availability
Enquiries about data availability should be directed to the authors.
References
Deng, J., Zhan, J., Xu, Z., Viedma, E.H.: Regret-theoretic multi-attribute decision-making model using three-way framework in multi-scale information systems. IEEE Trans. Cybernet. (2022). https://doi.org/10.1109/TCYB.2022.3173374
Wang, J., Ma, X., Xu, Z., Zhan, J.: Regret theory-based three-way decision model in hesitant fuzzy environments and its application to medical decision. IEEE Trans. Fuzzy Syst. 30(12), 5361–5375 (2022)
Xiao, F., Pedrycz, W.: Negation of the quantum mass function for multisource quantum information fusion with its application to pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. (2022). https://doi.org/10.1109/TPAMI.2022.3167045
Xiao, F., Wen, J., Pedrycz, W.: Generalized divergence-based decision making method with an application to pattern classification. IEEE Trans. Knowl. Data Eng. (2022). https://doi.org/10.1109/TKDE.2022.3177896
Xiao, F., Cao, Z., Lin, C.: A complex weighted discounting multisource information fusion with its application in pattern classification. IEEE Trans. Knowl. Data Eng. (2022). https://doi.org/10.1109/TKDE.2022.3206871
Molodtsov, D.: Soft set theory—first results. Comput. Math. Appl. 37(4), 19–31 (1999). https://doi.org/10.1016/S0898-1221(99)00056-5
Maji, P.K., Biswas, R., Roy, A.R.: Soft set theory. Computers and Mathematics with Appli-cations 45(4), 555–562 (2003). https://doi.org/10.1016/S0898-1221(03)00016-6
Zhan, J., Alcantud, J.C.R.: A survey of parameter reduction of soft sets and corresponding algorithms. Artif. Intell. Rev. 52, 1839–1872 (2019)
Herawan, T., Deris, M.M.: A soft set approach for association rules mining. Knowl. Based Syst. 24(1), 186–195 (2010). https://doi.org/10.1016/j.knosys.2010.08.005
Qin, H., Ma, X., Zain, J.M., et al.: A novel soft set approach in selecting clustering attribute. Knowl. Based Syst. 36, 139–145 (2012). https://doi.org/10.1016/j.knosys.2012.06.001
Orhan, D.: A novel approach to soft set theory in decision-making under uncertainty. Int. J. Comput. Math. 98(10), 1935–1945 (2021). https://doi.org/10.1080/00207160.2020.1868445
Khizar, H., Zalishta, T., Edwin, L., Fahim, A.M.: New aggregation operators on group-based generalized intuitionistic fuzzy soft sets. Soft Comput. 25(21), 1–12 (2021). https://doi.org/10.1007/S00500-021-06181-7
Xiao, Z., Gong, Ke., Zou, Y.: A combined forecasting approach based on fuzzy soft sets. J. Comput. Appl. Math. 228(1), 326–333 (2008). https://doi.org/10.1016/j.cam.2008.09.033
Sahar, A.M., Alkouri, U.M.J.S., Mourad, A.M.O., Adeeb, T.G., Anwar, B.: Bipolar complex fuzzy soft sets and their application. Int. J. Fuzzy Syst. Appl. (IJFSA) 11(1), 1–23 (2021)
Li, C., Li, D., Jin, J.: Generalized Hesitant Fuzzy Soft Sets and Its Application to Decision Making. Int. J. Pattern Recognit Artif Intell. 33(12), 1–30 (2019). https://doi.org/10.1142/S0218001419500198
Das, S., Malakar, D., Kar, S., Pal, T.: Correlation measure of hesitant fuzzysoft sets and their application in decision making. Neural Comput. Appl. 31(4), 1023–1039 (2019). https://doi.org/10.1007/s00521-017-3135-0
Zhan, J., Alcantud, J.C.R.: A novel type of soft rough covering and its application to multicriteria group decision making. Artif. Intell. Rev. 52, 2381–2410 (2019)
Wei, X., Ma, J., Wang, S., Hao, G.: Vague soft sets and their properties. Comput. Math. Appl. 59(2), 787–794 (2009). https://doi.org/10.1016/j.camwa.2009.10.015
Wei, B., He, X., Zhang, X.-Y., Yang, H.-Y.: A type of similarity measure for vague soft sets and its application to landmark preference. Journal of Intelligent & Fuzzy Systems 35(3), 3375–3386 (2018). https://doi.org/10.3233/JIFS-172207
Ganeshsree, S., Harish, G., Shio, Q.: Vague Entropy Measure for Complex Vague Soft Sets. Entropy 20(6), 1–19 (2018). https://doi.org/10.3390/e20060403
Feng, F., Liu, X., Leoreanu-Fotea, V., Jun, Y.B.: Soft sets and soft rough sets. Inform. Sci. 181(6), 1125–1137 (2010). https://doi.org/10.1016/j.ins.2010.11.004
Ayub, S., Shabir, M., Mahmood, W.: New types of soft rough sets in groups based on normal soft groups. Comput. Appl. Math. 39(2), 1–15 (2020). https://doi.org/10.1007/s40314-020-1098-8
Irfan Ali, M.: A note on soft sets, rough soft sets and fuzzy soft sets. Appl. Soft Comput. J. 11(4), 3329–3332 (2011). https://doi.org/10.1016/j.asoc.2011.01.003
Zhan, J., Zhu, K., Langari, R.: Reviews on decision making methods based on(fuzzy) soft sets and rough soft sets. J. Intell. Fuzzy Syst 29(3), 1169–1176 (2015). https://doi.org/10.3233/IFS-151732
Liu, Y., Qin, K., Martínez, L.: Improving decision making approaches based on fuzzy soft sets and rough soft sets. Appl. Soft Comput. 65, 320–332 (2018). https://doi.org/10.1016/j.asoc.2018.01.012
Ghosh, S.K., Ghosh, A.: A novel intuitionistic fuzzy soft set based colonogram enhancement for polyps localization. Int. J. Imaging Syst. Technol. 31(3), 1486–1502 (2021). https://doi.org/10.1002/IMA.22551
Yang, X., Young Lin, T., Yang, J., Li, Y., Yu, D.: Combination of interval-valued fuzzy set and soft set. Comput. Math. Appl. 58(3), 521–527 (2009). https://doi.org/10.1016/j.camwa.2009.04.019
Mabruka, A., Adem, K.: On Interval-Valued Fuzzy Soft Preordered Sets and Associ-ated Applications in Decision-Making. Mathematics 9(23), 1–15 (2021). https://doi.org/10.3390/MATH9233142
Hongwu, Q., Yanan, W., Xiuqin, Ma., Jin, W.: A Novel Approach to Decision Making Based on Interval-Valued Fuzzy Soft Set. Symmetry 13(12), 1–15 (2021). https://doi.org/10.3390/sym13122274
Ma, X., Qin, H., Sulaiman, N., Herawan, T., Abawajy, J.H.: The parameter reduction of the interval-valued fuzzy soft sets and its related algorithms. IEEE Trans. Fuzzy Syst. 22(1), 57–71 (2014). https://doi.org/10.1109/TFUZZ.2013.2246571
Xiuqin, M., Qinghua, F., Hongwu, Q., Huifang, Li., Wanghu, C.: A new efficient decision making algorithm based on interval-valued fuzzy soft set. Appl. Intell. 51(6), 3226–3240 (2020). https://doi.org/10.1007/S10489-020-01915-W
Yiarayong, P.: On interval-valued fuzzy soft set theory applied to semigroups. Soft. Comput. 24(5), 3113–3123 (2020). https://doi.org/10.1007/s00500-019-04655-3
Hashimah Sulaiman, N., Liyana Amalini, N., Kamal, M.: A subsethood-based entropy for weight determination in interval-valued fuzzy soft set group decision making. AIP Conf. Proc. 1974(1), 1–8 (2018). https://doi.org/10.1063/1.5041593
Qiansheng, Z., Dongfang, S.: An Improved Decision-Making Approach Based on Interval-valued Fuzzy Soft Set. J. Phys. Conf. Ser. 1828(1), 1–6 (2021). https://doi.org/10.1088/1742-6596/1828/1/012041
Zou, Y., Xiao, Z.: Data analysis approaches of soft sets under incomplete information. Knowl.-Based Syst. 21(8), 941–945 (2008). https://doi.org/10.1016/j.knosys.2008.04.004
Kong, Z., Zhang, G., Wang, L., Zhaoxia, Wu., Qi, S., Wang, H.: An efficient decision making approach in incomplete soft set. Appl. Math. Model. 38(7–8), 2141–2150 (2014). https://doi.org/10.1016/j.apm.2013.10.009
Sisi, X., Haoran, Y., Lin, C.: An incomplete soft set and its application in MCDM problems with redundant and incomplete information. Int. J. Appl. Math. Comput. Sci. 31(3), 417–430 (2021). https://doi.org/10.34768/AMCS-2021-0028
Zhi, K., Jie, Z., Lifu, W., Junjie, Z.: A new data filling approach based on probability analysis in incomplete soft sets. Expert Syst. Appl. 184, 1–12 (2021). https://doi.org/10.1016/J.ESWA.2021.115358
Qin, H., Li, H., Ma, X., Gong, Z., Cheng, Y., Fei, Q.: Data Analysis Approach for Incomplete Interval-Valued Intuitionistic Fuzzy Soft Sets. Symme-try 12(7), 1–15 (2020). https://doi.org/10.3390/sym12071061
Qin, H., Ma, X.: Data Analysis Approaches of Interval-Valued Fuzzy Soft Sets Under Incomplete Information. IEEE Access 7, 3561–3571 (2019). https://doi.org/10.1109/access.2018.2886215
Qi, X., Guo, H., Wang, W.: A reliable KNN filling approach for incomplete interval-valued data. Eng. Appl. Artif. Intell. 100, 104175 (2021). https://doi.org/10.1016/j.engappai.2021.104175
Deng, J., Zhan, J., Viedma, E.H., Herrera, F.: Regret theory-based three-way decision method on incomplete multi-scale decision information systems with interval fuzzy numbers. IEEE Trans. Fuzzy Syst. (2022). https://doi.org/10.1109/TFUZZ.2022.3193453
Acknowledgements
The authors express great thanks to the financial support from the National Natural Science Foundation of China, grant number 62162055 and the Gansu Provincial Natural Science Foundation of China, grant number 21JR7RA115.
Funding
This work was supported by the National Natural Science Foundation of China, grant number 62162055 and the Gansu Provincial Natural Science Foundation of China, grant number 21JR7RA115.
Author information
Authors and Affiliations
Contributions
Each author has participated and contributed sufficiently to take public responsibility for appropriate portions of the content.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, X., Han, Y., Qin, H. et al. KNN Data Filling Algorithm for Incomplete Interval-Valued Fuzzy Soft Sets. Int J Comput Intell Syst 16, 30 (2023). https://doi.org/10.1007/s44196-023-00190-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00190-0