
Abstract
Background
It is very important to accurately delineate the CTV on the patient’s three-dimensional CT image in the radiotherapy process. Limited to the scarcity of clinical samples and the difficulty of automatic delineation, the research of automatic delineation of cervical cancer CTV based on CT images for new patients is slow. This study aimed to assess the value of Dense-Fully Connected Convolution Network (Dense V-Net) in predicting Clinical Target Volume (CTV) pre-delineation in cervical cancer patients for radiotherapy.
Methods
In this study, we used Dense V-Net, a dense and fully connected convolutional network with suitable feature learning in small samples to automatically pre-delineate the CTV of cervical cancer patients based on computed tomography (CT) images and then we assessed the outcome. The CT data of 133 patients with stage IB and IIA postoperative cervical cancer with a comparable delineation scope was enrolled in this study. One hundred and thirteen patients were randomly designated as the training set to adjust the model parameters. Twenty cases were used as the test set to assess the network performance. The 8 most representative parameters were also used to assess the pre-sketching accuracy from 3 aspects: sketching similarity, sketching offset, and sketching volume difference.
Results
The results presented that the DSC, DC/mm, HD/cm, MAD/mm, ∆V, SI, IncI and JD of CTV were 0.82 ± 0.03, 4.28 ± 2.35, 1.86 ± 0.48, 2.52 ± 0.40, 0.09 ± 0.05, 0.84 ± 0.04, 0.80 ± 0.05, and 0.30 ± 0.04, respectively, and the results were greater than those with a single network.
Conclusions
Dense V-Net can correctly predict CTV pre-delineation of cervical cancer patients and can be applied in clinical practice after completing simple modifications.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Background
Cervical cancer is the second most common cancer in Chinese women and ranks fourth for both incidence and mortality in women worldwide, and its morbidity and mortality have revealed an upward inclination in recent years [1]. Radiotherapy is an important treatment for prolonging the life of cervical cancer patients. Radical radiotherapy is suitable for patients with stage I and stage II and whose physical conditions are not suitable for surgery. Adjuvant radiotherapy is effective for patients with intermediate and high risk factors found in postoperative pathological examination. The precise delineation of CTV plays an important role in the radiotherapy process, which is also very important for the design, assessment, and optimization of radiotherapy planning and directly impacts patients’ prognosis. Currently, the work of delineating CTV is mainly done manually by radiotherapists based on three-dimensional CT images. This is time-consuming, labor-intensive, and very boring. Many researchers try to use new methods, such as k-nearest neighbor [2], ATLAS [3], PET-ATLAAS [4], to achieve automatic delineation.
Recently, the use of deep learning for automatic lesion identification has attracted much attention and significant progress has been made in nasopharyngeal carcinoma [5, 6], rectal cancer [7], and other diseases [8, 9]. The CTV area of cervical cancer includes not only imaging visible lesions, but also subclinical lesion areas and possible invasion areas. Even in the same stage, the range of invasion and organ filling are different, which will form individual differences, which will affect the range of delineation. As a result, the research progress in this field is slow, and no relevant results have been reported in previous studies.
Therefore, in this study, we used Dense V-Net to delineate cervical cancer CTV based on CT images automatically to assess the value of Dense V-Net in predicting CTV pre-delineation inpatients with cervical cancer.
Methods
Data collection
From May 2016 to June 2019, data were collected from patients with postoperative cervical cancer that were admitted to the Department of Radiotherapy in the First Medical Center of the Chinese People’s Liberation Army General Hospital. This study was conducted according to the Declaration of Helsinki and the ethics committee of our hospital approved this study. All patients signed informed consent.
According to Radiation Therapy Oncology Group (RTOG) CTV consensus definition [10], the CTV range comprises of the uterine body, whole vagina, cervical lesions, bilateral uterine parasites, as well as common iliac, internal iliac, external iliac obturator, and presacral lymphatic drainage regions. The CT images of all patients were obtained using the SIMENS SOMATOM Definition AS large-aperture CT machine. The scanning range was from the top of the liver to the lower end of the perineum. The number of layers was 85–120 and the layer thickness was 5 mm. The scanning parameters were 120KV tube voltage, 400mAs tube current, and the reconstructed voxel value was 512*512* k. During the CT scan, the patient was setup in a supine position and fixed with a thermoplastic phantom.
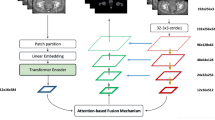
Dense V-net for segmentation
Dense V-Net [11] is a deep learning network that integrates two deep learning models of Dense Net [12, 13] and V-Net [14, 15]. The structure is shown in Fig. 1. Its three main features are the use of dense connection, horizontal connection, and fusion convolution. Firstly, the input of the dense connection convolution xl layer contains all the outputs of the previous x0, x1, … …, xl-1 layers. Each layer of the network can directly approach the feature maps of the previous layers, involving the loss function and the gradient of the original input, which assists in deepening the network structure and improves the utilization rate of the image features of each layer. The use of dropout clarifies the image information taken for each dense connection and the suitable training outcome can be achieved by using fewer parameters without relearning unnecessary feature mapping between the layers. The use of BN (Batch Normalization) also reduces the over-fitting of the training set with fewer data. Secondly, the horizontal connection joins the convolutional layer through a kernel with assize of 5*5*5 voxels and convolution up-sampling and down-sampling layer with 2*2*2 voxel-wide kernels applied with stride 2. This operation can achieve the effect of improving the output image details, deepening the image contour, and shortening the network fusion time while correctly predicting the image structure. The residual connections are used between convolution operations to break network symmetry and enhance the sensitivity of gradient calculations. In the final prediction, a convolution kernel with a volume of 1 × 1 × 1 is used to perform the convolution operation, the soft-max layer uses the Dice coefficient as the new objective function, and finally outputs the probabilistic segmentation image of the foreground and background regions. Thirdly, the convolution kernel of 3*3*3 is used in the fusion convolutional layer and the rectified linear unit (ReLu) is applied as the activation function so that the image features are fully utilized, and the segmentation outcome is enhanced. Finally, the output of the same size as the original input image is obtained [16].

Dense V-Net structure diagram
The fusion network includes the benefits of two single networks. The structure of Dense Net ensures that each layer of the image has the maximum information flow so that the parameters can be used by all the following layers, therefore, improving the utilization rate of image features and quickening the convergence of the target function while reducing unnecessary information. Performing convolution and concatenation operations on three resolution images facilitate multi-scale features extraction and add more details and global data to the results. The structure of V-Net confirms that the output prediction can reserve more image details and maintain the correctness of the image prediction in the case of a small training set. When the network deepens, the results of a deep network are still controlled by the expanding receptive field, which has a significant result in reducing over-fitting.
The experimental methods
Since the CT image contains a large amount of vacant background and the research focus area is located in the middle of the space, the CT images should be preprocessed. First, the cross-section of the CT image is intercepted at the center of the 320*320 size and resampled by bilinear interpolation to decrease the resolution of the entire training sample to 256*256*k. This operation enhances the proportion of effective data in a single training data, reduces the volume of the sample, and achieves the purpose of enhancing training precision and reducing training time.
Then, a data enhancement process should be performed by sampling and rotating the training samples: we randomly extracted 64 consecutive layers of CT images of each case to attain 10–20 training samples and then we rotated the samples at random angles within ±10 degrees along the x, y, and z axes, respectively, to further expand the data capacity. These two operations can increase the sample size while producing more extensive and accurate training results.
Finally, we completed the network training and verification. The details of the flow are shown in Fig. 2. During training, the parameters of V-Net and Dense Net were separately trained and optimized. When the loss function of the two was optimal, the fusion layer was fine-tuned so that Dense V-Net could achieve the best network fusion effect in the shortest time.

Network training and sketching verification flow chart
Data training, assessment, and testing tasks were all run on servers with dual NVIDIA (GTX 1080) graphics cards. The algorithms used were based on the TensorFlow system architecture and written and tuned in Python. We also used the DSC (Dice Similarity Coefficient) value as the loss function. The initial learning efficiency was set to 0.0005, the learning rate attenuation factor was 0.5, the attenuation step size was 1000, and the number of iterations was set to 10,000.
The quantitative evaluation
The overall assessment of the automatic delineation was completed using the DSC [17]. To describe the details further, the other seven most representative parameters were used to evaluate the automatic sketching accuracy. They were the three parameters for measuring the degree of contour deviation of the two sketches: deviation of Centroid (DC), Hausdorff Distance (HD) [18], and Minimum Average Distance (MAD), as well as four parameters that measured the difference in volume between the two sketches, namely the Deviation of Volume (∆V), Sensitivity Index (SI), Inclusiveness Index (Incl) [19], and Jaccard Distance (JD) [20]. The image and training results were then transmitted into MIM. Maestro 6.6.5 software to acquire the sketch information and the assessment parameters of the two sketches were calculated on the basis of this platform.
Statistical analysis
We used the software program SPSS 20.0 (IBM, Chicago, USA) to conduct the statistical analysis. The continuous variables of normal distribution were expressed as mean ± standard deviation, the continuous variables of a non-normal distribution were expressed as median (interquartile range [IQR]), and the categorical variables were expressed as frequency (percentage [%]). For multiple comparisons, each value was compared by one-way ANOVA following a Dunnett test when each datum conformed to a normal distribution while the non-normally distributed continuous data were compared using non-parametric tests. The counting data were tested by a chi-square test. A value of P < 0.05 was considered statistically significant.
Results
The general characteristics
A total of 133 patients with stage IB and stage IIA, according to 2018 International Federation of Gynecology and Obstetrics (FIGO 2018 stage) Cancer Report [21], were enrolled in this study. The CT images of all the patients were manually delineated by 2 attending physicians and then studied and approved by a senior chief physician. One hundred and thirteen of the patients were randomly selected as the training set and the remaining twenty patients’ CT images were used as the test set to assess the automatic delineation performance of the network. The statistical results of 8 parameters of the CTV automatically delineated by Dense V-Net are shown in Table 1 and the scatter box diagram is shown in Fig. 3.

8 parameters scatter box diagram
The DSC score
The results presented that all the 20 cases were higher than the standard 0.75 [22]. Only 5 of them were less than 0.8; the median and mean were both greater than 0.8 and the maximum reached 0.875. This showed that the overall resemblance between the automatic sketch and manual sketch was high.
The contour deviation
During the completion of the contour deviation, the automatic sketching was stable. The results presented that no extreme point existed, showing that there was no extreme identification error in the automatic delineation; the standard deviation was small, which indicated that the sketch effect was stable. MAD represents the average value of the minimum distance between the two contours and its results were on the order of millimeters, which presented that the inaccurate automatic sketch areas had little effect on the deviation of the two outlines.
The volume of each orientation
Based on the evaluation of the correctness of the automatic contour orientation, the volume of each orientation was further evaluated by the ∆V, SI, Incl, and JD. ΔV represents the proportion of the volume difference between the two sketches in the manual sketch, which is used to assess the volume stability of the network. The average value was 0.09 and the maximum value was 0.18, suggesting that the automatic sketch was partially or even completely contained. SI and IncI indicated the ratio of the coincidence volume of the two delineations to the manual and automatic contour volume, respectively; the average values were 0.84 and 0.80, respectively. SI was slightly larger than IncI, which meant that the volume of the automatic delineation volume was larger than the manual one overall. The minimum values of the two were 0.71 and 0.73, respectively, and JD represented the complement of the size of the union of the two delineations intersection. The JD values were in a narrow distribution and the standard deviation was 0.04.
The comparison between the fusion network and a single network
The fusion network was compared with the single network and the results are shown in Table 2. According to the characteristics of each parameter, it was evident that the automatic delineation similarity of the fusion network was significantly higher than the single network. Some representative evaluation parameters, such as DSC, HD, JD, had significant differences in the results (p < 0.01),while the other parameters had statistical differences (p < 0.05).
The comparison between the automatic delineation among the fusion network and manual delineation
The comparison results of automatic delineation using the fusion network and manual delineation by the radiation oncologist are shown in Fig. 4. The red regions showed the contours of CTV manually drawn by the doctors and the blue regions showed the result of the automatic sketches. It is evident that the results of the two kinds of delineations had a high degree of coincidence.

Patient CT image and sketching results
The specific segmentation results
A more detailed examination of the segmentation results found that in the following three structures, the network segmentation ability performed poorly. As shown in Fig. 5.

CT cross-sectional images of patients and Comparison of delineations in three conditions of huge difference
First, at the lower edge of the bifurcation of the presacral lymphatic drainage area, and the upper anterior boundary of the piriformis, the automatic delineation error is generally large. The deep network often fails to accurately identify this boundary, which results in redundant delineation at the anterior edge of the piriformis muscle and the third sacral vertebra.
Secondly, in the area of the posterior wall of the bladder and the anterior wall of the rectum, automatic delineation also has recognition bias. This is mainly due to the fact that when the doctor manually draws it out, the CTV boundary will be extended to the back wall of the bladder for a distance ranging from 1 to 2 mm according to the degree of the patient’s holding back. However, this deep network only pays attention to the significant anatomical differences in this part, and due to the small sample size and unequal extension distance, the learning effect here is poor.
Finally, there are a few cases of vaginal invasion due to disease progression. In actual delineation, doctors often delineate a small number of lymph nodes in the groin area as CTV. This is also difficult for the network to handle.
Discussion
Medical image analysis, especially medical image segmentation based on deep learning, is one of the most critical areas of current computer vision research. Segmentation is an important processing step in medical images, used for medical scene understanding and image analysis.
The tumor regions segmentation is a research hotspot in medical imaging analysis. There have been many reports on segmentation of visible lesions or GTV (Gross Tumor Volume) and the results show that, the accuracy has surpassed traditional methods, and some results are comparable to expert manual segmentation. For example, Alom [23] automatically outlines the tumor in the lung CT image, and the average segmentation DSC value is 98.32%.
Nevertheless, the identification and delineation of CTV is still very difficult. This is mainly because, in addition to the visible anatomical structure, CTV also includes subclinical potential lesion areas and some lesion invasion areas. These areas are often determined by the doctor’s supervisory judgment and are greatly affected by individual differences, the location of the lesion, and the stage of the cancer. Even if the stage is the same, the scope of tumor invasion and lymphatic involvement are different, which will lead to different delineation scopes. In addition, changes in the patient’s bowel position and bladder filling shape will also affect the recognition and delineation of CTV.
It is of clinical significance to differentiate and delineate CTV in cervical cancer patients. Although there have been some pioneering studies [24,25,26], they are mainly applied to the self-image sketching of patients, image-guided radiotherapy or the dose superposition evaluation of re-planning, and it is impossible to delineate the CTV of new patients. Due to the scarcity of clinical samples and problems in implementation, the research development of CTV automatic delineation based on CT images of new cervical cancer patients is slow and no relevant results have been reported yet.
To minimize the error of delineation outcomes caused by individual differences in different patients, we used a deep learning method to automatically sketch CTV based on CT images in cervical cancer patients with pelvic radiotherapy. Dense V-Net, a fusion algorithm with an accurate automatic segmentation effect for high deformation soft tissue organs [11],has the advantages of the 2 single algorithms: the dense connection structure is used to understand parameter sharing and strengthen feature transfer; dropout and BN enables a training set with a capacity of 113 to achieve good training results; horizontal connection improves the precision and correctness of the output sketch; and residual connection efficiently solves the gradient disappearance and explosion phenomena generated during training. Its unique fusion convolution layer and the unilateral inhibition of the ReLu function further enhances the outcome of feature learning, quickens the model convergence and improves the sketch efficiency. According to our research results, the characteristics of CTV can be fully learned by Dense V-Net and the automatic delineation outcome is helpful in the case of limited training samples. When designing the radiotherapy plan for cervical cancer, the network can fulfill the automatic pre-sketching of CTV, which greatly improves the clinical work effectiveness.
DSC is used to assess the proportion of the coincidence delineation of 2 sketches in the total outline. When the DSC score is greater than 0.75, it is deliberated that the two regions have a high degree of coincidence [22]. Our study showed that the overall resemblance between the automatic sketch and manual sketch was high.
During the completion of contour deviation, automatic sketching was stable. DC measures the centroid deviation of the two contours, with an average of 4.28 mm, which is less than the scanning layer thickness of 5 mm. HD represents the maximum value of the shortest distance between the two outlines. Statistics demonstrate that no extreme point exists, representing that there is no extreme identification error in automatic delineation; In our experience the standard deviation is small, which specifies that the sketch effect is stable. MAD represents the average value of the minimum distance between the two contours and its results are all on the order of millimeters, which demonstrates that the incorrect automatic sketch areas have little effect on the deviation of the two outlines.
Based on the evaluation of the accuracy of the automatic contour orientation, the volume of each orientation was further evaluated by the ∆V, SI, Incl, and JD.ΔV represents the proportion of the volume difference between the two sketches in the manual sketch, which is used to assess the volume stability of the network. Our study discovered that the volume difference between the two delineations were small and the automatic sketch was partially or even completely contained. SI and IncI indicate the ratio of the coincidence volume of the two delineations to the manual and automatic contour volume, respectively. The results of this study showed that the two delineations had a high degree of coincidence. SI was slightly larger than IncI, which meant that the volume of automatic delineation volume was larger than the manual one overall. The corresponding samples had a large contour deviation degree. JD represents the complement of the size of the union of the two delineations intersection. The JD values were in a narrow distribution, which suggested that the volume offset was small and the network sufficiently identified the sample features.
In this study, the automatic delineation resemblance of the fusion network was significantly higher than that of the single network. Representative evaluation parameters such as DSC, HD, JD, etc. have significant differences in the results while the other parameters had statistical differences. Therefore, automatic sketching using a fusion network has a smaller volume deviation, reduced less range of error identification, lower centroid deviation, and higher volume stability. The difference between the standard deviation also showed that the fusion network had stronger sketching stability and featured an accurate learning ability.
The comparison results of automatic delineation using the fusion network and manual delineation by the radiation oncologists showed that the results of the two kinds of delineations had a high degree of coincidence, which further suggested that Dense V-Net could achieve satisfactory automatic CTV sketching in CT images.
From the analysis of the evaluation parameters, when the DSC value tended to be stable, the reason for the deviation was further assessed by analyzing the other parameters. We found that the network had a weak segmentation ability in some parts of the delineation. It is evident from Fig. 3 (c), (e), and (f) that there were extreme values for HD, ΔV, and SI. The extreme value of HD suggested that there may have been large error identification or local extreme contour deviation. After completing the examination, the reason was identified to be the lack of automatic delineation; on the coronal plane, the upper bound of automatic delineation was much lower than the manual one. The extreme value of ∆V means that the volume of the two sketches was fairly different and we found that the range of the automatic sketch was too large, which essentially included the manual sketch in most areas. The extreme deviation values of SI is due to the insufficient network recognition ability, which results in the overall difference in volume between automatic drawing and manual drawing, and the overlapping volume is small.
However, the network still has many limitations. Firstly, the individual differences in the medical samples were extremely large. Even in the case of a limited sample size, there are a few cases with more specific CTV sketching and the network tends to overlook this abnormal information when learning features, which confines the compatibility of Dense V-Net to various complex conditions. Secondly, this study only focused on the cervical cancer delineation of stage IB and IIA cancer after surgery. Other stages and if surgery or other anti-cancer treatments will affect CTV delineation to a large extent needs further study. Therefore, the effect of automatic delineation for more complex clinical cases needs to be determined. Thirdly, since the judgment of the potential tumor invasion area contained in CTV, particularly the number of lymph nodes that need to be clarified, depends on the clinical experience of radiation oncologists, different doctors have diverse understandings in the delineation of CTV for the same patient, which confines the universality of the network.
Conclusions
Dense V-Net can accurately predict CTV pre-delineation of cervical cancer patients and can be utilized in clinical practice after simple modifications.
Availability of data and materials
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
Abbreviations
- CTV:
-
Clinical Target Volume
- DSC:
-
Dice Similarity Coefficient
- CT:
-
Computed tomography
- DSC:
-
Dice Similarity Coefficient
- DC:
-
Deviation of Centroid
- HD:
-
Hausdorff Distance
- MAD:
-
Minimum Average Distance
- ∆V:
-
Deviation of Volume
- SI:
-
Sensitivity Index
- JD:
-
Jaccard Distance
- IQR:
-
Interquartile range
References
Bray F, Ferlay J, Soerjomataram I, Siegel RL, Torre LA, Jemal A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2018;68(6):394–424.
Comelli A, Stefano A, Russo G, Bignardi S, Sabini MG, Petrucci G, et al. K-nearest neighbor driving active contours to delineate biological tumor volumes. Eng Appl Artif Intell. 2019;81(MAY):133–44.
Kim N, Chang JS, Kim YB, Kim JS. Atlas-based auto-segmentation for postoperative radiotherapy planning in endometrial and cervical cancers. Radiat Oncol. 2020;15(1):106.
Berthon B, Evans M, Marshall C, Palaniappan N, Cole N, Jayaprakasam V, et al. Head and neck target delineation using a novel PET automatic segmentation algorithm. Radiother Oncol. 2017;122(2):242–7.
Pereira S, Pinto A, Alves V, Silva CA. Brain tumor segmentation using convolutional neural networks in MRI images. IEEE Trans Med Imaging. 2016;35(5):1240–51.
Men K, Chen X, Zhang Y, Zhang T, Dai J, Yi J, et al. Deep Deconvolutional neural network for target segmentation of nasopharyngeal Cancer in planning computed tomography images. Front Oncol. 2017;7:315–9.
Larsson R, Xiong JF, Song Y, Ling-Fu CYZ, Xiaowei X, et al. Automatic Delineation of the Clinical Target Volume in Rectal Cancer for Radiation Therapy using Three-dimensional Fully Convolutional Neural Networks. Conf Proc IEEE Eng Med Biol Soc. 2018;2018:5898–901.
Brandao P, Zisimopoulos O, Mazomenos E, Ciuti G, Bernal J, Visentini-Scarzanella M, et al. Towards a computed-aided diagnosis system in colonoscopy: automatic polyp segmentation using convolution neural networks. J Med Robot Res. 2018;1:1–13.
Mortensen MA, Borrelli P, Poulsen MH, Gerke O, Enqvist O, Ulén J, et al. Artificial intelligence-based versus manual assessment of prostate cancer in the prostate gland: a method comparison study. Clin Physiol Funct Imaging. 2019;39(6):399–406.
Small W Jr, Mell LK, Anderson P, Creutzberg C, De Los SJ, Gaffney D, et al. Consensus guidelines for delineation of clinical target volume for intensity-modulated pelvic radiotherapy for the definitive treatment of cervix Cancer. Int J Radiat Oncol Biol Phys. 2011;79(2):348–55.
Gibson E, Giganti F, Hu Y, Bonmati E, Bandula S, Gurusamy K, Davidson B, et al. Automatic multi-organ segmentation on abdominal CT with dense V-networks. IEEE Trans Med Imaging. 2018 Aug;37(8):1822–34.
Huang G, Liu Z, Maaten LVD, Weinberger KQ. Densely Connected Convolutional Networks; 2016. p. 2261–9.
Harley AW, Derpanis KG, Kokkinos I. Learning dense convolutional Embeddings for semantic segmentation. Comput Therm Sci. 2015;79(10):1337–42.
Milletari F, Navab N, Ahmadi SA. V-net: fully convolutional neural networks for volumetric medical image segmentation// fourth international conference on 3d vision: IEEE; 2016. p. 565–71.
Adrià C, Marcel C, Irina S, Combalia M, Verónica V. Cascaded V-Net Using ROI Masks for Brain Tumor Segmentation// International MICCAI Brainlesion Workshop. Cham: Springer; 2017. p. 381–91.
Chen M, Tao G, Jiang B. Dynamic surface control using neural networks for a class of uncertain nonlinear systems with input saturation. IEEE Trans Neural Netw Learn Syst. 2017;26(9):2086–97.
Daisne JF, Blumhofer A. Atlas-based automatic segmentation of head and neck organs at risk and nodal target volumes: a clinical validation. Radiat Oncol. 2013;8(1):154.
Wu Q, Wu XF, Li XW, Jia KB. A modified image matching algorithm based on robust Hausdorff distance. High Technol Lett. 2014;20(01):29–33.
La Macchia M, Fellin F, Amichetti M, Cianchetti M, Gianolini S, Paola V, et al. Systematic evaluation of three different commercial software solutions for automatic segmentation for adaptive therapy in head-and-neck, prostate and pleural cancer. Radiat Oncol. 2012;7(1):160.
Sun R, Mazeron R, Chargari C, Barillot I. CTV to PTV in cervical cancer: from static margins to adaptive radiotherapy. Cancer Radiothér. 2016;S1278321816303663.
Bhatla N, Denny L. International Federation of Gynecology and Obstetrics (FIGO) Cancer report 2018. Int J Gynecol Obstet. 2018;143(2):2–162.
Andrews S, Hamarneh G. Multi-region probabilistic dice similarity coefficient using the Aitchison distance and bipartite graph matching. Comput Therm Sci. 2015;9:67–71.
Alom MZ, Yakopcic C, Hasan M, Taha TM, Asari VK. Recurrent residual convolutional neural network based on U-net (R2U-net) for medical image segmentation. J Med Imaging (Bellingham). 2019;6(2):025008.
ZhengQ Z, Wang YL, Zhang JC, Wang JY, Zhang HJ, Yang G, et al. Evaluation of the auto-segmentation based on self-registration and atlas in adaptive radiotherapy for cervical cancer. Chinese J Rad Oncol. 2019;28(4):292–6.
Dong L, Yang J, Zhang Y, Zhang L. TH-A−224-03: atlas based auto-segmentation based on deformable image registration. Med Phys. 2011;38(6):3841.
Chen KQ, Chen WJ, Ni XL, Li XQ, Bai PG, Zhang CX, et al. Systematic evaluation of atlas-based auto-segmentation (ABAS) software for adaptive radiation therapy in cervical cancer. Chinese J Rad Med Protect. 2015;35(2):111–3.
Acknowledgements
Not applicable.
Funding
National natural science foundation of China, 61671204 .
Clinical research fostering fund of Chinese PLA general hospital(2017FC-TSYS-3027).
Author information
Authors and Affiliations
Contributions
JZJ, GW, GSS and ZJ conceptualized and designed the study, drafted the initial manuscript, and reviewed and revised the manuscript. YW, CXH, DXK, QH and LJ designed the data collection instruments, collected data, carried out the initial analyses, and reviewed and revised the manuscript. QBL coordinated and supervised data collection, and critically reviewed the manuscript for important intellectual content. All authors approved the final manuscript as submitted and agree to be accountable for all aspects of the work. GL was partially involved in the design of this study, and Definition of knowledge content, also helped in the final review of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This study was conducted in accordance with the declaration of Helsinki. This study was conducted with approval from the Ethics Committee of People’s Liberation Army General Hospital.AHospital. A written informed consent was obtained from all participants.
Consent for publication
Consent for publication was obtained from every individual whose data are included in this manuscript.
Competing interests
All authors have contributed significantly to the manuscript and declare that the work is original and has not been submitted or published elsewhere. None of the authors have any financial disclosure or conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Ju, Z., Guo, W., Gu, S. et al. CT based automatic clinical target volume delineation using a dense-fully connected convolution network for cervical Cancer radiation therapy. BMC Cancer 21, 243 (2021). https://doi.org/10.1186/s12885-020-07595-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12885-020-07595-6