
Abstract
Objectives
To generate sagittal T1-weighted fast spin echo (T1w FSE) and short tau inversion recovery (STIR) images from sagittal T2-weighted (T2w) FSE and axial T1w gradient echo Dixon technique (T1w-Dixon) sequences.
Materials and methods
This retrospective study used three existing datasets: “Study of Health in Pomerania” (SHIP, 3142 subjects, 1.5 Tesla), “German National Cohort” (NAKO, 2000 subjects, 3 Tesla), and an internal dataset (157 patients 1.5/3 Tesla). We generated synthetic sagittal T1w FSE and STIR images from sagittal T2w FSE and low-resolution axial T1w-Dixon sequences based on two successively applied 3D Pix2Pix deep learning models. “Peak signal-to-noise ratio” (PSNR) and “structural similarity index metric” (SSIM) were used to evaluate the generated image quality on an ablations test. A Turing test, where seven radiologists rated 240 images as either natively acquired or generated, was evaluated using misclassification rate and Fleiss kappa interrater agreement.
Results
Including axial T1w-Dixon or T1w FSE images resulted in higher image quality in generated T1w FSE (PSNR = 26.942, SSIM = 0.965) and STIR (PSNR = 28.86, SSIM = 0.948) images compared to using only single T2w images as input (PSNR = 23.076/24.677 SSIM = 0.952/0.928). Radiologists had difficulty identifying generated images (misclassification rate: 0.39 ± 0.09 for T1w FSE, 0.42 ± 0.18 for STIR) and showed low interrater agreement on suspicious images (Fleiss kappa: 0.09 for T1w/STIR).
Conclusions
Axial T1w-Dixon and sagittal T2w FSE images contain sufficient information to generate sagittal T1w FSE and STIR images.
Clinical relevance statement
T1w fast spin echo and short tau inversion recovery can be retroactively added to existing datasets, saving MRI time and enabling retrospective analysis, such as evaluating bone marrow pathologies.
Key Points
-
Sagittal T2-weighted images alone were insufficient for differentiating fat and water and to generate T1-weighted images.
-
Axial T1w Dixon technique, together with a T2-weighted sequence, produced realistic sagittal T1-weighted images.
-
Our approach can be used to retrospectively generate STIR and T1-weighted fast spin echo sequences.
Graphical Abstract

Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Magnetic resonance (MR) imaging plays a crucial role in diagnostic procedures. A major strength of MRI is its ability to acquire different imaging contrasts, enabling multi-faceted diagnostic assessment of various pathologies. The two most used sequences at the spine are T1-weighted (T1w FSE) and T2-weighted fast spin echo (T2w FSE). Several techniques have been developed to suppress either fat or water signals in MR scans, generating multiple images highlighting specific tissue characteristics [1, 2]. The MR acquisition itself is time-consuming, often necessitating the acquisition of 2D images with low through-plane resolution to reduce scan times and minimize the risk of subject movement, which could compromise image acquisition. Typically, two to four sequences encompassing different acquisition techniques and orientations are acquired, but the optimal set of required images may vary depending on the diagnostic context.
Artificial intelligence is emerging as a promising tool in the field of radiology. Many deep learning approaches rely on specific acquisition techniques and slice axes. Conditional generative networks can generate missing sequences [3,4,5,6,7,8,9], and it has been shown that with the matching MR sequences, fat-saturated images can be extracted [1, 2, 10,11,12,13,14], but not yet for T1w FSE sequences. For large-scale studies such as the German National Cohort (NAKO) [15], the “Study of Health in Pomerania” (SHIP) [16, 17], or the UK Biobank [18], rescanning subjects to obtain missing sequences is impossible. These studies commonly employ the axial T1-weighted gradient echo Dixon technique (T1w-Dixon; also, volume interpolated breath-hold examination) due to its versatility. However, its limited sagittal resolution renders it unsuitable for evaluating many spinal conditions. Only SHIP has T1w FSE images, and short tau inversion recovery (STIR) images are missing in all large studies. The NAKO and the SHIP have sagittal T2w FSE images, and the T1w-Dixon images contain the necessary information to decode water from fat [19, 20]. With those two data pairs, we aim to generate commonly used sagittal T1w FSE-like images that would greatly increase the usability of images in those large endemiological studies. Our technique can also be used to reduce scan time by not requiring additional scans.
It is crucial to differentiate between increased signal intensities in sagittal T2w FSE images caused by fat and water, e.g., as this can differentiate a chronic degenerative from an active inflammatory process [21,22,23]. STIR specializes in highlighting water content, enhancing diagnostic sensitivity [24,25,26,27], and reducing the risk of unintentionally overlooking water-related hyperintensities. Combining T1w and T2w FSE images makes it possible to distinguish between fat and water, as water appears dark in T1w FSE images while fat remains brighter compared to the surrounding tissue. This study’s objective is to assess, whether the acquisition of sagittal T2w FSE and axial T1w-Dixon sequences provides sufficient information to generate sagittal T1w FSE and sagittal STIR images in the same resolution as the T2w FSE.
Materials and methods
The local ethics committee approved our research within existing legal frameworks for retrospective clinic internal data analysis. Informed consent for internal data collection was waived. All participants of the German National Cohort [15] (NAKO) and “Study of Health in Pomerania” [16, 17] (SHIP) studies signed informed consent for prospective data collection and evaluation.
While axial T1-weighted gradient echo Dixon technique (T1w-Dixon) contains information on fat and water content [19, 20], the resolution may not be sufficient to accurately assess water content in sagittal views. Therefore, to utilize axial T1w-Dixon similar to sagittal T1-weighted fast spin echo (T1w FSE), super-resolution of this data is necessary. We upscale and translate this data toward the already familiar modalities of T1w FSE and short tau inversion recovery (STIR). We use the sagittal T2-weighted (T2w) FSE image to guide the super-resolution process, ensuring that the networks utilize existing sagittal information from the T2w FSE image rather than extrapolating the structures. Thus, this study created sagittal STIR and T1w FSE volumes using sagittal T2w FSE and axial T1w-Dixon images. We employed two separate neural networks. The first network generated sagittal T1w FSE images from sagittal T2w FSE and axial T1w-Dixon images, trained on the SHIP dataset, consisting of 3165 subjects (1529 males, aged 53 ± 14 years (mean ± standard deviation); 1634 females, aged 53 ± 13 years, two others) on 1.5 Tesla MRI devices. While the sagittal FSE sequences covered the whole spine, the field of view of the T1w-Dixon images only spanned from the center of the chest to the sacrum.
The second network converted sagittal T1w FSE and T2w FSE images into sagittal STIR images based on the finding that these inputs contain sufficient biological information for STIR image reconstruction, as demonstrated in previous studies [2, 10,11,12,13,14]. Our internal dataset comprised 311 matching sequences, encompassing the entire spine, from 157 subjects (43 males, aged 54 ± 20 years; 45 females, aged 59 ± 16 years, 67 patients fully anonymized from a prior study, without age and sex available) with varying anomalies and pathologies. The internal data are acquired on either 1.5- or 3-Tesla MRI devices.
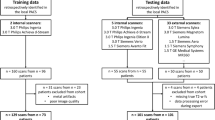
Furthermore, the NAKO contributes axial T1w-Dixon and sagittal T2w FSE images from 30,927 subjects (17,311 males, aged 48 ± 12 years; 13,616 females, aged 49 ± 12 years) on 3-Tesla MRI devices. To demonstrate the applicability of our technique, we utilize a subset of the NAKO dataset, specifically selecting patients older than 60 years with at least one observable focal signal increase in the T2w images. These selection criteria were chosen to avoid an overabundance of normal images that could potentially obscure the evaluation of our method’s performance in identifying fat and water accumulations during Turing tests. The age threshold was chosen to speed up the selection process. An overview of our data pipeline can be found in Fig. 1.

Datasets. We used the “Study of Health in Pomerania” for training the T1w generation from T1w-Dixon and T2w FSE images. The internal dataset is used for the STIR generation from T1w and T2w FSE images. For inference, we use images from the German National Cohort, where we found a fat or water uptick in the T2w FSE image. Below the dataset, the data flow is visualized, where dashed boxes indicate that they are generated by a deep learning network. STIR, sagittal short tau inversion recovery; T1w-Dixon, axial T1-weighted gradient echo Dixon technique; T1w, sagittal T1-weighted image; T2w, sagittal T2-weighted; FSE, fast spin echo image
Image preprocessing
We reorient and rescale the T2w FSE images to a standardized resolution and orientation (Right, Inferior, Posterior). We adopt a sagittal in-plane resolution of 1.1 × 1.1 mm from the sagittal SHIP images. We maintain the original resolution for the right/left dimension of around 3–4 mm. The data are saved into multiple chunks along the vertical direction, which do not match between T1w-Dixon and the splits of the other image modalities. Current freely available software assumes that the sagittal images are on the same vertical z-axis [7], which is not true for scoliosis cases, where chunks follow the spine shape. To address this, we have developed software that computes the optimal bounding box encompassing all these chunks and stitches them together.Footnote 1 The data chunks are already correctly encoded in global space. We address overlapping regions through interpolation \(1-\frac{{d}_{x}}{{\sum }_{i}{d}_{i}}\), with the distance to the next voxel where no interpolation is necessary denoted by \({d}_{i}\) of image i. This ensured a smooth transition between the two images. The T1w-Dixon images were shifted by a few voxels compared to the T2w FSE image. Rigid registration with cross-correlation was applied with nipy-plugin to reduce the shift [28]. Black-box registration is not reliable for torso and spine registration due to breathing-, organ- and inter-vertebra movement. Registration reduced the shift but did not fully eliminate it, and in 18 cases, the registration failed fully. Those cases were excluded from the dataset. We resampled the T1w-Dixon data to match the voxel resolution of the adjacent T2w FSE image.
MR image values typically range from 0 to a maximum value, which can vary between different scan runs. We rescaled the image values from [0, max-value] to the range [−1, 1] to standardize this variability. Additionally, we applied random color jitter with a brightness and contrast-factor change ranging from 0.8 to 1.2 during training to account for the histogram inconsistencies. For training purposes, we used fixed input sizes of (16, 192, 192) pixels for T1w FSE generation and (16, 256, 256) pixels for STIR generation. During inference, we can insert the full image after padding it to be divisible by 8 in all image directions. To artificially increase the training data variance, we replicated the training data three times and resampled them to random sagittal resolutions between 1.0 and 0.5 mm.
Image-to-image network
For translation, we used the Pix2Pix [29] training mechanism. It uses a fully convolutional U-Net [30] (See Fig. 2) that takes an image volume stack as input and produces the target output. The reconstruction error was computed from three criteria: The absolute difference \({{{{\mathscr{L}}}}}_{1}\), the structural similarity index measure (SSIM) loss, and a least squares generative adversarial network (GAN) loss \({{{{\mathscr{L}}}}}_{2}\). The \({{{{\mathscr{L}}}}}_{1}\) and SSIM error is weighed by a factor of 10 to 1 toward the GAN loss.

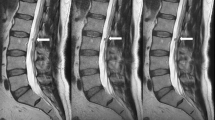
Sagittal views of input and output data. The image is from a participant of the “Study of Health in Pomerania” with Modic changes in L4/5 and L5/S1. a Example input and output of networks 1 and 2. The last vertebra contains a high-water content adjacent to L5/S1 (Modic 2), while it has high fat adjacent to L4/5 (Modic 1). The high-fat content can be seen in the T1w-Dixon fat image, while the high-water content is more difficult to distinguish. Network 2 receives the original T2w FSE image and the generated T1w FSE output of network 1. b A comparison of the generated and real image. The bone structures, the fat, and water aggregation are generated correctly. Only the stomach area differs because time has passed between the real T1w and T2w FSE image due to breathing, the digestive process, and filling their bladder during the examination. c Comparison of expression of water and fat in T1w, T2w FSE, and STIR images. In the STIR, the different hydronation of the inter-vertebra disks is easier to see than in the T2w FSE. STIR, sagittal short tau inversion recovery; T1w-Dixon, axial T1-weighted gradient echo Dixon technique; T1w, sagittal T1-weighted image; T2w, sagittal T2-weighted; FSE, fast spin echo image
\({{{{\mathscr{L}}}}}_{{total}} \, =10 \, \cdot \, {{{{\mathscr{L}}}}}_{1}\left(\hat{x}-x\right) \, + \, 10 \,\cdot \, \left(1-{{{\rm{SSIM}}}}\left(\hat{x}-x\right)\right) \, +{{{{\mathscr{L}}}}}_{2}\left(D\left(\hat{x}\right),1\right)\) where \(\hat{x}\) is the predicted volume, x is the ground truth, and D is a discriminator network. For the GAN loss, a patch-based discriminator is trained, and we followed the least squares GAN loss computation [31]. \({L}_{D}=0.5\cdot {{{{\mathscr{L}}}}}_{2}\left(D\left(\hat{x}\right),0\right)+0.5\cdot {{{{\mathscr{L}}}}}_{2}\left(D\left(x\right),1\right)\)
It is generally easier to train 2D models, but it comes at a loss of the additional information of the other slices. To stabilize the training and reduce the GPU storage for 3D Pix2Pix models, we incorporated some changes inspired by Bieder et al [32]. We used image embedding as three additional inputs to the image input stack. Each embedding is a gradient from 0 to 1 defined on the original borders of the 3D images before random cropping to the fixed patch size. Each volume dimension gets its own embedding gradient. See Fig. 3. We use addition instead of concatenation for skip-connections to reduce the GPU storage requirement. We train on a single V40 GPU with a learning rate of 0.00002 and a batch size of 3.

The network. We use 3D convolution, a group norm of 8, and a Sigmoid Linear Unit (SiLU) as the main residual block. The used channel sizes are indicated in the graphic and are changed at the first layer of the residual block. The model input (left) consists of the concatenation of all input images and the three-image position embeddings. The network produces the 3D target images as an output. The example shows network two in- and outputs
Image quality
We aim to demonstrate the necessity of our approach for achieving optimal results. We evaluated our approach based on three criteria: (1) comparing the effectiveness of our 3D approach against 2D, (2) assessing the indispensability of utilizing both input pairs and (3) confirming the requirement of a paired setting. For (1), we employed the same network in 2D as in 3D Pix2Pix but increased the batch size to 64 and added attention layers to fully leverage the graphics card and optimal parameters for the 2D training. In (2), we compared the performance of both 3D and 2D networks using two inputs compared to only the T2w FSE image. To demonstrate the essentiality of data pairs (3), we employ 2D CycleGAN [33] on the same dataset and network. We use generated images and compare them to acquired images with absolute difference (L1) mean squared error (MSE), peak signal-to-noise ratio (PSNR), and SSIM.
Turing test
A Turing test is designed to assess the ability of artificial intelligence to convincingly emulate authentic human behavior or data to deceive a human observer. In our study, we engaged seven radiologists with a set of 2D images comprising genuine T2w images and potentially generated images of another modality. The seven radiologists (P.S.P., E.O.R., S.H.K., N.L., C.R., K.J.P., O.R.K.—one radiologist with 3 years of experience; two each with 1, 2 and 6 years of experience) are tasked with distinguishing whether the adjacent image is authentic or artificially generated. We conducted this assessment separately for T1w FSE and STIR images. For T1w FSE, we employed 60 natively acquired images, with half originating from the SHIP dataset and the other half from our internal dataset. Additionally, 30 synthetic images were generated from each SHIP and NAKO dataset. In the case of the STIR Turing test, we produced 30 synthetic images from both the SHIP and NAKO datasets, while 60 authentic STIR images were extracted from our internal dataset. We exclusively utilized artificial T1w FSE images to generate synthetic STIRs in this test. Our objective was to maintain an equal balance between authentic and synthetic images. All images were standardized to a uniform size of 150 × 150 pixels with an in-plane resolution of 1.1 mm per pixel. We report the misclassification rate (false / (false + correct)) and Fleiss kappa interrater agreement test [34].
Statistical analysis and software
The model analysis was performed with the Pytorch Python packages for the model performance. The p-values were computed with the Wilcoxon signed-rank test from the scipy Python packages. The Turing test and Fleiss kappa test were analyzed in Excel. The 99% confidence error for Fleiss kappa is calculated according to Cohen et al [34]. The Fleiss kappa has the interpretation of 0–0.2 Poor, 0.21–0.4 Fair, 0.41–0.6 Moderate, 0.61–0.8 Good and 0.81–1.0 Very good.
Results
We used 212 sets of STIR/T1w FSE/T2w FSE sequences (125 subjects; mean-age 56 ± 18 years; 37 men, 49 unknown) and 2454 sets of T1w/T2w FSE and T1w-Dixon sequences (each sequence type fused to one 3D volume per subject and sequence; mean-age 53 ± 14 years; 1226 men, 2 others) for training. Testing was done on 36 (22 subjects; mean-age 62 ± 17 years; 6 men, 11 unknown) and 470 (mean-age 53 ± 13 years; 235 men) sequence pairs, respectively.
Visual analysis
In Fig. 4, we compare real and generated test samples of the SHIP dataset. The spine structure looks identical, while soft tissue has slightly moved between the two real acquisitions. The T1w FSE generation model is correct in translation water and fat hyperintensities. The spine images are nearly identical in real and artificial T1w FSE. Fatty degenerations like hemangioma and modic 2 are bright in both T1w and T2w FSE image. Watery aggregation like modic 1 and Tarlov cyst become dark in T1w FSE and bright in STIR, reproducing their expected signal behavior in these sequences. The SHIP dataset exclusively comprises old fractures. Thus the images lack the bright signals typically observed in STIR sequences, which would be characteristic of fresh fractures. In Figs. 5 and 6, we showcase pathologies like hemangioma and modic changes, where the generated images show the typical signal intensities. Even for rare or unseen pathologies during training, like fat marrow conversion by radiotherapy, the model correctly translates these tissues.

Examples from the Study of Health in Pomerania dataset with different anomalies. Artificial data was generated by the deep learning model with the T2w FSE and resampled axial T1-weighted gradient echo Dixon technique as input. Red arrows mark reconstruction artifacts in real T1w FSE data that are not reproduced in the translation. It is coincidental that we found multiple instances of these artifacts in a small sample set. STIR, sagittal short tau inversion recovery; T1w, sagittal T1-weighted image; T2w, sagittal T2-weighted; FSE, fast spin echo image

Examples of generated T1w FSE and STIR from the German National Cohort. Artificial data was generated by the deep learning model with the T2w FSE and resampled axial T1w-Dixon as input. We have no ground truth for this dataset. We can see that fatty aggregation causes black holes in the water image, but the look and feel of water image vary stronger than T1w FSE images. We show a variety of fatty anomalies like hemangioma, modic 2, fat marrow conversion and Herniationen Schmol’che. For modic 1, we see the signal drop in T1w FSE. STIR, sagittal short tau inversion recovery; T1w-Dixon water, axial T1-weighted gradient echo Dixon technique computed water part; T1w, sagittal T1-weighted image; T2w, sagittal T2-weighted; FSE, fast spin echo image

Examples of generated STIR from the Internal dataset. Artificial data was generated by the deep learning model with the T2w FSE and T1w FSE as input, as shown in previous studies. STIR, sagittal short tau inversion recovery; T1w, sagittal T1-weighted image; T2w, sagittal T2-weighted; FSE, fast spin echo image
Image quality
The tests to generate T1w FSE (Table 1) and STIR (Table 2) exhibit parallel outcomes. The unpaired generation (CycleGAN) performed worst. The final 3D approach had better results than its 2D counterparts. Not providing sagittal T1w FSE and axial T1w-Dixon has a negative impact on the translation quality. All p-values of the Wilcoxon signed-rank test between the proposed method and the others are < 0.01.
Turing test
The misclassification rate is 0.39 ± 0.09 for T1w FSE and 0.42 ± 0.18 for STIR. See Table 3 for individual results. The reviewers have a low interrater agreement with the Fleiss kappa test with 0.09 [−0.04 to 0.19–99% confidence interval] for T1w FSE and 0.09 [−0.10 to 0.13–99% confidence interval] for STIR images. For this test, a kappa below 0.2 is considered poor agreement and close to a random coin toss distribution.
Discussion
Generative AI models promise to replace missing sequences. Here, we developed and validated two generative models for sagittal T1-weighted fast spin echo (T1w FSE) and sagittal short tau inversion recovery (STIR) images from axial T1-weighted gradient echo Dixon technique (T1w-Dixon) and sagittal T2-weighted (T2w) FSE images of the spine. The axial T1w-Dixon has a lower sagittal resolution than our generated T1w FSE but still guides our network effectively in distinguishing fat and water in the T2w FSE image. Importantly, our artificial images faithfully recapitulate the imaging characteristics of these sequences and are indistinguishable from their real counterparts for trained neuroradiologists. Our models therefore offer unique opportunities to generate missing sequences in large epidemiological studies like the German National Cohort (NAKO) or “Study of Health in Pomerania” (SHIP).
This work extends earlier studies [1, 2], which generate STIR sequences from T1w FSE and T2w FSE inputs. Our ablation showed that the additional input of T1w-Dixon or T1w FSE image is necessary for the DL model. Otherwise, the model must guess necessary physical properties and extrapolate by looking at hyperintensities and whether water or fat is the cause. The general intention of multiple scans is to remove this ambiguity, and we should provide the DL application with this information to increase correctness. In our Turing test, neuroradiologists could not reliably differentiate real from artificial images. A misclassification of about 40% is consistent with other studies [2, 35]. During development, we had the impression that our STIR images were less susceptible to MR reconstruction artifacts and did not suffer from acquisition errors like real STIR. Our reviewers were blinded to this observation, which is reflected in the variance of our Turing test. Depending on the tendency of a rater to attribute acquisition errors toward machine learning might affect the misclassification rate. This would explain why some reviewers have good scores below 30% and others performed worse than random.
In contrast to previous studies [1, 2, 10,11,12,13,14], we utilized population-based data from the SHIP and NAKO rather than patient data with pathological changes. As a result, the pathology density in our training set was lower compared to other studies. We manually filtered pathologies for the NAKO test set to ensure an adequate number of pathological test samples for the Turing test. This data exhibited selection biases, as most pathologies were age-related non-acute cases, unlike the retrospectively collected internal data. The reviews were blinded to the varying likelihood of pathologies between real and generated images.
T1w-Dixon and STIR are specialized techniques, and due to time limitations, they are usually not produced in the same session. This limits this study because we have no data pairs with T2w, T1w-Dixon, and a STIR that would test our two networks from start to finish. We could only show a start to end in an unpaired manner, like the Turing test. The resolutions and MRI devices are different between the two trained networks. They should be generated on the same device with the same resolution for the sagittal images for optimal performance. We currently cannot compensate for patient movement.
Overall, we can generate artificial T1w FSE and STIR images retrospectively that can hardly be distinguished from real images. This enables us to generate the same data modalities we would encounter in everyday clinical practice in large biobank datasets.
Notes
We made this software freely available under our GitHub: https://github.com/Hendrik-code/TPTBox/tree/main/TPTBox/stitching.
Abbreviations
- FSE:
-
Fast spin echo
- GAN:
-
Generative adversarial network
- NAKO:
-
German National Cohort (NAKO Gesundheitsstudie)
- Pix2Pix:
-
(Proper name)
- PSNR:
-
Peak signal-to-noise ratio
- SHIP:
-
Study of Health in Pomerania
- SSIM:
-
Structural similarity index measure
- STIR:
-
Short tau inversion recovery
- T1w:
-
T1-weighted
- T1w-Dixon:
-
Axial T1-weighted gradient echo Dixon technique; also, volume interpolated breath-hold examination
- T2w:
-
T2-weighted
References
Schlaeger S, Drummer K, Husseini ME et al (2023) Implementation of GAN-based, synthetic T2-weighted fat saturated images in the routine radiological workflow improves spinal pathology detection. Diagnostics 13:974
Haubold J, Demircioglu A, Theysohn JM et al (2021) Generating virtual short tau inversion recovery (STIR) images from T1-and T2-weighted images using a conditional generative adversarial network in spine imaging. Diagnostics 11:1542
Li H, Paetzold JC, Sekuboyina A et al (2019) DiamondGAN: unified multi-modal generative adversarial networks for MRI sequences synthesis. In: Medical Image Computing and Computer Assisted Intervention (MICCAI 2019), 22nd International Conference, Shenzhen, China, 13–17 October 2019, part IV 22. Springer International Publishing, pp 795–803
Finck T, Li H, Grundl L et al (2020) Deep-learning generated synthetic double inversion recovery images improve multiple sclerosis lesion detection. Invest Radiol 55:318–323
Conte GM, Weston AD, Vogelsang DC et al (2021) Generative adversarial networks to synthesize missing T1 and FLAIR MRI sequences for use in a multisequence brain tumor segmentation model. Radiology 299:313–323
Thomas MF, Kofler F, Grundl L et al (2022) Improving automated glioma segmentation in routine clinical use through artificial intelligence-based replacement of missing sequences with synthetic magnetic resonance imaging scans. Invest Radiol 57:187–193
Lavdas I, Glocker B, Rueckert D et al (2019) Machine learning in whole-body MRI: experiences and challenges from an applied study using multicentre data. Clin Radiol 74:346–356
Lv J, Zhu J, Yang G (2021) Which GAN? A comparative study of generative adversarial network-based fast MRI reconstruction. Philos Trans A Math Phys Eng Sci 379:20200203
Xie H, Lei Y, Wang T et al (2022) Synthesizing high-resolution magnetic resonance imaging using parallel cycle-consistent generative adversarial networks for fast magnetic resonance imaging. Med Phys 49:357–369
Fayad LM, Parekh VS, de Castro Luna R et al (2021) A deep learning system for synthetic knee MRI: is artificial intelligence based fat suppressed imaging feasible? Invest Radiol 56:357
Kim S, Jang H, Jang J et al (2020) Deep-learned short tau inversion recovery imaging using multi-contrast MR images. Magn Reson Med 84:2994–3008
Kim S, Jang H, Hong S et al (2021) Fat-saturated image generation from multi-contrast MRIs using generative adversarial networks with Bloch equation-based autoencoder regularization. Med Image Anal 73:102198
Schlaeger S, Drummer K, Husseini M et al (2021) [241] Synthetic T2-weighted fat sat delivers valuable information for pathology assessment in the spine: validation of a task-specific generative adversarial network. Clin Neuroradiol 31:S54–S54
Kawahara D, Nagata Y (2021) T1-weighted and T2-weighted MRI image synthesis with convolutional generative adversarial networks. Rep Pract Oncol Radiother 26:35–42
Bamberg F, Kauczor H-U, Weckbach S et al (2015) Whole-body MR imaging in the German National Cohort: rationale, design, and technical background. Radiology 277:206–220
John U, Hensel E, Lüdemann J et al (2001) Study of Health In Pomerania (SHIP): a health examination survey in an east German region: objectives and design. Soz Präventivmed 46:186–194
Völzke H, Alte D, Schmidt CO et al (2011) Cohort profile: the study of health in Pomerania. Int J Epidemiol 40:294–307
Allen N, Sudlow C, Downey P et al (2012) UK Biobank: current status and what it means for epidemiology. Health Policy Technol 1:123–126
Schlaeger S, Klupp E, Weidlich D et al (2018) T2-weighted Dixon turbo spin echo for accelerated simultaneous grading of whole-body skeletal muscle fat infiltration and edema in patients with neuromuscular diseases. J Comput Assist Tomogr 42:574–579
Brandão S, Seixas D, Ayres-Basto M et al (2013) Comparing T1-weighted and T2-weighted three-point Dixon technique with conventional T1-weighted fat-saturation and short-tau inversion recovery (STIR) techniques for the study of the lumbar spine in a short-bore MRI machine. Clin Radiol 68:e617–e623
Delfaut EM, Beltran J, Johnson G et al (1999) Fat suppression in MR imaging: techniques and pitfalls. Radiographics 19:373–382
Colosimo C, Gaudino S, Alexandre AM (2011) Imaging in degenerative spine pathology. Springer, Vienna, pp 9–15
Wang B, Fintelmann FJ, Kamath RS et al (2016) Limited magnetic resonance imaging of the lumbar spine has high sensitivity for detection of acute fractures, infection, and malignancy. Skelet Radiol 45:1687–1693
Alcaide-Leon P, Pauranik A, Alshafai L et al (2016) Comparison of sagittal FSE T2, STIR, and T1-weighted phase-sensitive inversion recovery in the detection of spinal cord lesions in MS at 3 T. AJNR Am J Neuroradiol 37:970–975
Dagestad MH, Toppe MK, Kristoffersen PM et al (2024) Dixon T2 imaging of vertebral bone edema: reliability and comparison with short tau inversion recovery. Acta Radiol 65:273–283
Kristoffersen PM, Vetti N, Storheim K et al (2020) Short tau inversion recovery MRI of Modic changes: a reliability study. Acta Radiol Open 9:2058460120902402
Vanel D, Dromain C, Tardivon A (2000) MRI of bone marrow disorders. Eur Radiol 10:224–229
Brett M, Taylor J, Burns C et al (2009) NIPY: an open library and development framework for FMRI data analysis. NeuroImage 47:S196
Isola P, Zhu J-Y, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017. pp 1125–1134
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), 18th International Conference, Munich, Germany, Springer International Publishing, pp 234–241
Mao X, Li Q, Xie H et al (2017) Least squares generative adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision, Venice. pp 2794–2802
Bieder F, Wolleb J, Durrer A et al (2023) Memory-efficient 3D denoising diffusion models for medical image processing. In: Medical Imaging with Deep Learning (MIDL 2023), Proceedings of Machine Learning Research, Nashville, Tennessee, PMLR, pp 552–567
Zhu J-Y, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision, Venice. pp 2223–2232
Cohen J (1960) A coefficient of agreement for nominal scales. Educ Psychol Meas 20:37–46
Ouyang H, Meng F, Liu J et al (2022) Evaluation of deep learning-based automated detection of primary spine tumors on MRI using the Turing test. Front Oncol 12:814667
Funding
The research for this article received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (101045128—iBack-epic—ERC2021-COG). This project was conducted with data from the German National Cohort (NAKO) (www.nako.de). The NAKO is funded by the Federal Ministry of Education and Research (BMBF) (project funding reference numbers: 01ER1301A/B/C and 01ER1511D), federal states and the Helmholtz Association with additional financial support by the participating universities and the institutes of the Leibniz Association. We thank all participants who took part in the NAKO study and the staff in this research program. SHIP is part of the Community Medicine Research Network of the University Medicine Greifswald, which is supported by the German Federal State of Mecklenburg-West Pomerania. Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Guarantor
The scientific guarantor of this publication is R.G.
Conflict of interest
The first authors of this manuscript declare relationships with the following companies: J.S.K. is a cofounder and shareholder of Bonescreen GmbH. See https://bonescreen.de/. The other authors of this manuscript declare no relationships with any companies, whose products or services may be related to the subject matter of the article.
Statistics and biometry
One of the authors has significant statistical expertise.
Informed consent
Prospective data (NAKO/SHIP): Written informed consent was obtained from all subjects (patients) in this study. Internal data: Written informed consent was not required for this study because we used existing MRI images from the Clinic “Rechts der Isar.” We anonymized the MRI. According to German law (Bavarian hospital law), we can do research with existing images without written consent internally if we follow the guidelines of patient privacy and ethics. We adhere to the German ethics standards for medical research on patient data generated by normal clinical routine.
Ethical approval
The ethics committee of the Technical University Munich approved our German-law-compliant studies (593/21 S-NP). Study-specific ethics approval is not required as long we stay in the rules of the Bavarian hospital law for retrospective data analysis and privacy protection.
Study subjects or cohorts overlap
Some study subjects or cohorts have been previously reported. NAKO and SHIP are shared large datasets and have multiple studies. The internal data was used in studies by Schläger et al in: https://doi.org/10.3390/diagnostics11091542; https://doi.org/10.1007/s00330-023-09512-4. The internal data consists of two data collections. One of the data collections did not collect the age, sex, height, and weight information from the scanner and cannot be retrieved. The transformation from T1-weighted Dixon + T2w FSE to T1w and STIR imaging is a novel contribution. All experiments and deep learning models presented in the study are newly developed.
Methodology
-
Retrospective with prospective and retrospective data
-
Experimental
-
Performed at one institution; data is from different institutes
Additional information
Publisher’s Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Graf, R., Platzek, PS., Riedel, E.O. et al. Generating synthetic high-resolution spinal STIR and T1w images from T2w FSE and low-resolution axial Dixon. Eur Radiol (2024). https://doi.org/10.1007/s00330-024-11047-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00330-024-11047-1