
Abstract
The study objective was to assess the potential benefits of using genomic tools in organic plant breeding programs to enhance selection efficiency. A diversity panel of 247 spring naked barley accessions was characterized under Irish organic conditions over 3 years. Genome-wide association studies (GWAS) were performed on 19 traits related to agronomy, phenology, diseases, and grain quality, using the information on 50 K Single Nucleotide Polymorphisms (SNP). Four models (EMMA, G model, BLINK, 3VMrMLM) were applied to 5 types of Best Linear Unbiased Predictors (BLUP): within-year, mean, aggregated within-year). 1653 Marker-Trait-Associations (MTA) were identified, with 259 discovered in at least two analyses. 3VMrMLM was the best-performing model with significant MTA together explaining the largest proportion of the additive variance for most traits and BLUP types (from 1.4 to 50%). This study proposed a methodology to prioritize main effect MTA from different models’ outputs, using multi-marker regression analyses with markers fitted as fixed or random factors. 36 QTL, considered major, explained more than 5% of the trait variance on each BLUP type. A candidate gene or known QTL was found for 18 of them, with 13 discovered with 3VMrMLM. Multi-model GWAS was useful for validating additional QTL, including 8 only discovered with BLINK or G model, thus allowing a broader understanding of the traits’ genetic architecture. In addition, results highlighted a correlation between the trait value and the number of favorable major QTL exhibited by accessions. We suggest inputting this number in a multi-trait index for a more efficient Marker-Assisted Selection (MAS) of accessions best balancing multiple quantitative traits.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Now that the barley genome has been entirely mapped (Beier et al. 2017; Mascher et al. 2017) and the cost-efficiency of genotyping technology is continuously improving, molecular markers are widely used in plant breeding to accelerate crop improvement by increasing the genetic gain per generation (Bernardo 2008; Yabe and Iwata 2020). In organic farming, due to the higher variability in crop yield and product quality across environments, testing across more years and locations is required to identify varieties showing stable performance under low input growing conditions. Marker-assisted selection (MAS) would allow the pre-selection of lines based on the occurrence of genomic regions known to influence the trait of interest and thus reduce the need for extensive phenotyping. However, consecutive breeding programs focused primarily on yield improvement may have inadvertently suppressed favorable alleles for valuable traits under low input conditions such as disease resistance, straw strength, weed competitive ability, and nitrogen use efficiency (Newton et al. 2010).
Reintroducing in breeding programs ancient varieties preserved in Genebanks may help recover some favorable alleles (Alqudah et al. 2020). Genome-wide association study (GWAS) is a powerful tool to identify genes of interest by screening a large and diverse population on their phenotype and genotype. Many factors influence the statistical power of GWAS models, including population size, marker density, minor allele frequency (MAF), and linkage disequilibrium (LD) (Alqudah et al. 2020). LD represents the degree of correlation between markers. The more rapidly LD decreases with increased markers distance, the higher the marker density needed to cover the whole genome information. Single Nucleotide Polymorphisms (SNP) are now commonly used in GWAS because they are cheap and available in large quantities across the genome. Moreover, marker density has been enhanced considerably over the past decade, with, for example, a barley 50 k SNP genotyping chip released in 2017 (Bayer et al. 2017).
The first GWAS models developed were testing each marker independently. Whole genome models were developed thereafter to estimate all effects simultaneously and avoid overestimating single marker effect in the presence of markers in LD creating noise and redundancy in the analysis (Tibbs Cortes et al. 2021).
GWAS may also result in false positives due to confounding factors, such as genetic population structure due to common ancestry, cryptic relatedness due to genetic proximity between individual (He et al. 2019), with common SNP explaining a large part of the trait heritability. When many markers are tested, correcting the p-value significance threshold for multiple testing is also critical to identify true associations. A stringent correction such as Bonferroni is efficient to control the rate of false positives but may lead to a higher rate of false negatives because markers are assumed to be independent (Kaler and Purcell 2019). This hypothesis is not true because of LD pattern. A correction based on the number of independent tests instead of the total number of markers tested has been proposed by Cheverud (2001), but the traditional Bonferroni correction remains widely used.
To increase the statistical power to detect true associations while optimizing the computation efficiency, various statistical models were developed. The Efficient Mixed Effect Association (EMMA) (Kang et al. 2008) is a single-locus mixed linear model (MLM), which can use the Population Parameter Previously Determined (P3D) allowing to estimate variance components only once for all the single-marker tests, thus considerably improving the computational efficiency. Generally, in mixed-effect models, the major genetic principal components are included as fixed factors and a kinship matrix as a random factor to correct for population structure and relatedness, respectively. The G model is a multi-locus model developed by Bernardo (2013) that unlike common GWAS models accounts for population structure or relatedness by calculating markers effects on each chromosome separately while controlling for the background effect of markers on the remaining chromosomes. In a second step, most significant markers are identified via stepwise regression analyses. The author argues that this method corrects for an additional level of redundancy, and may thus be more effective in identifying “true” associations. For example, the G model has been used to validate results from other methods (Gao et al. 2016; Sallam et al. 2017). Another approach to correct for LD patterns is the Bayesian-information and Linkage-disequilibrium Iteratively Nested Keyway (BLINK) (Huang et al. 2019). This model uses LD to select a set of independent markers that are then tested in a mixed effect model, and repeats this procedure multiple times. This method has been proven to have high power to detect large-effect QTL. Lastly, the recently developed GWAS model 3VMrMLM (Zhang et al. 2022) is a two-step method that first estimates markers’ effects in a single-locus model to select a set of markers based on a relaxed p-value significance threshold, and next applies to this selection a multi-locus compressed analysis of variance (Li et al. 2022a, b). This method has proven to have an increased statistical power to detect small effect and dominant effect markers when heterozygosity is present. Indeed, unlike other models, 3VMrMLM estimates additive and dominant allelic effects in the second step. Moreover, multi-environmental analyses with 3VMrMLM allows to explore markers by environment interactions.
The efficient prioritization of significant Marker-Trait Associations (MTA) discovered in GWAS relies on accurate marker effect calculation, which is challenging in the presence of non-additive effects (dominant, heterozygous, epistatic, marker-by-environment interaction) (Zhu and Zhou 2020). Some but not all GWAS models provide in the output an estimate of the proportion of the trait variance explained by the marker (PVE). There are multiple ways to calculate the markers effects, which may lead to contrasting results: over or under-estimated. The additive effect of one allele is commonly estimated, but may under-estimate the true effect in the occurrence of non-additive effects. Similarly, estimating the effect in a single-marker regression may over or under estimate the effect due to epistatic effect. The effect may also vary across environments, thus if we were looking for QTL with a consistent effect, carrying out the calculations based on the mean BLUP would not necessarily provide reliable estimates.
In this study, the first objective was to compare different GWAS models, including a single locus model EMMA and 3 multi-locus models, namely the G model, BLINK, and 3VMrMLM., on their ability to identify genetic associations with key agronomic, diseases and grain quality traits for naked barley grown under organic conditions. The second objective was to prioritize MTA from multiple model outputs for the identification of major Quantitative-Trait Loci (QTL) and investigate associated candidate genes. The last objective was to investigate the practical use of those QTL in organic naked barley breeding programs to favor long-term genetic gain.
Material and methods
Plant material
The diversity panel comprised 247 spring naked barley lines, including 58 lines from Genebanks and 189 from recent international breeding programs (Table S1).
Field trial
The panel was grown over 3 years (2019, 2020, 2021) on an organic-certified field in Camolin, Co. Wexford, Ireland (52° 37′ 21.5′′ N, 6° 25′ 06.1′′ W). The trial followed a type II modified augmented experimental design (MAD2) (Lin and Poushinsky 1985). Tested lines were un-replicated, while 3 checks were replicated within the design: Full Pint, a two-row malting hulled barley variety (OSU) released in 2014; CDC Clear, a two-row malting naked barley variety (CDC, Canada) released in 2012; Annapurna, a two-row food naked barley variety (Semillas Batlle, Spain) released in 2018. They were selected in different climate zones and on different quality criteria, and therefore considered to be representative of the panel.
Sowing dates were 04/05/2019, 22/04/2020, and 24/04/2021. Accessions were sown with a Hege cartridge seeder in rows of 1.5 m length organized in a rectangular plot of 25 m length and 15 m width, with 10 rows by 30 columns broken into 20 incomplete blocks distributed in 2 Rows and 10 Columns. Plots were spaced by 0.5 m horizontally and 1 m vertically. The primary check was assigned to the central plot of each Block and was different each year (Full Pint in 2019, CDC Clear in 2020, Annapurna in 2021). The 2 secondary check lines were randomly assigned to 2 plots within 4 of the 10 Blocks in each Row, bringing to 36 the number of plots allocated to checks. The randomized tested lines were then allocated to the remaining plots (Fig. S1).
The trial was conducted under organic conditions. The farmer usually incorporates about 4t/ha of beef cattle manure in the soil every other year or depending on results from soil sample analysis. No pest or disease management was applied to the field because the plant response to natural infection was to be assessed. Hand weeding was carried out every two or three weeks, depending on the weed pressure. Each plot was harvested leaving a residue height of 5 cm and tied into a bundle. Samples were run through an experimental thresher (Almaco (Small Vogel Plot or Bundle Thresher)), as much as required to ensure complete separation of grain and husks. Each sample was then run through an Air Blast Seed Cleaner (Almaco) to remove remaining crop residues, straws, and husks.
Phenotyping
Seedlings’ early vigor was scored 3 weeks after sowing (Vigour, score 1–8). Growing Degree Days required to reach Anthesis (GDDA, °Cd) and to Physiological Maturity (GDDPM, °Cd) were estimated using Zadoks’ scale (Zadoks et al. 1974). Plant height (PH, cm) and straw strength (Lodging, score) were measured at the grain-filling stage. Disease severity was estimated by visual screening of the percentage of the whole plot leaf area covered by symptoms (AHDB 2008; FAO 2016; Spaner et al. 1998). The maximal percentage for each genotype was converted to a score using the following scale: 0 (0%), 1 (< 5%), 2 (5–10%), 3 (10–20%), 4 (20–30%), 5 (30–40%), 6 (40–50%), 7 (50–65%), 8 (65–80%), 9 (> 80%). Major diseases observed included Brown Rust (Puccinia triticana) (BrownRust), Net Blotch (Pyrenophora teres) (NetBlotch), Powdery Mildew (Blumeria graminis) (Mildew), Ramularia leaf spot (Ramularia collo-cygni) (Ramularia), Rhynchosporium leaf scald (Rhynchosporium secalis) (Rhyn), and barley yellow dwarf virus (BYDV).
Traits related to threshing hardness comprised the number of runs required for threshing (Thresh, count) and the weight proportion of hulled grains remaining after threshing (hulled, %). Yield and grain quality traits included grain yield (yield, g/plot), harvest index (HI, %) (grain yield/total bundle weight), thousand kernel weight (TKW, g/1000 grains), grain plump fraction above 2.5 mm screen (plump, %), and grain protein (protein, %) and beta-glucan (Bgluc, %) content. Grain protein and moisture levels were estimated by Near Infrared technology with the ®GrainSense tool. Beta glucan content was estimated with the mixed-linkage method on flour samples (McCleary and Codd 1991) using the Megazyme kit (Megazyme 2021). To adapt the protocol to the material available in our laboratory, we used part of the modified protocol proposed by Hu and Burton (2008). After incubation, 1 mL of each test tube was transferred into 1.2 mL cluster tubes and centrifuged at 2200 rpm for 15 min in a microcentrifuge (Thermo Scientific (Pico 21)). The data was adjusted for grain moisture content to get the beta-glucan percentage of the dry weight.
3 years of data were collected on GDDA, BYDV, yield, TKW, protein, and Bgluc. 2 years of data were collected on Vigour, GDDPM, PH, Ramularia, Mildew, Rhyn, BrownRust, NetBlotch, Lodging, HI, Thresh, hulled, plump.
Phenotypic data analysis
Data was first adjusted for external factors such as field heterogeneity and environmental variations. Mixed linear modeling was performed with the R packages lme4 and LmerTest using Restricted Maximum Likelihood Estimation (REML) and the Nelder-Mead correction (Rice et al. 2020). In the next section we will present the models with random terms underlined and fixed term not.
Adjustment of beta-glucan data
Bgluc values were first adjusted for batch effect when significant, each year separately, using the values obtained on the barley flour control. 2 dummy variables were created to differentiate control from tested flour samples: 0 was assigned to control flour samples in both ControlsvsTested and Tested, while for tested flour samples, ControlsvsTested equals 1 and Tested equals the sample plot number. The Eq. (1) was used to fit the mixed model with μ, the grand mean, Day, the day the assay was analyzed and Batch, the batch number, both fixed effects, Assay, the random effect of the assay for tested samples only (i.e., the interaction between ControlsvsTested and Tested) and ϵ, the random experimental error.
Heritability calculation
For the following analyses, 3 dummy variables were created to separate check varieties from tested lines, as described by Piepho and Williams (2016). CheckvsTested equals 0 if a check line and 1 if a tested line, Check equals 0 for tested lines and the genotype identification number (gid) of check lines. Tested equals 0 for check lines and the the gid for tested lines. The effect of tested lines alone (Geno) or check lines alone (Checks) corresponds to the interaction effect between CheckvsTested and Tested, or CheckvsTested and Check, respectively. The Eq. (2) describes the fitted mixed model with μ, the grand mean, Year, the experimental year, Year:CheckvsTested, the difference between checks and tested lines in each year, Year:Checks the difference between check lines in each year, Year:Row, Year:Column, and Year:Block, the field effects in each year, Geno, the effect of tested lines, Geno:Year, the genotype by year interaction effect. ϵ, the random experimental error.
Trait heritability (H2) was estimated using variance components extracted from model (2) with the VarCorr function. The phenotypic variance was calculated on the genotype mean basis using the formula described by You et al. (2016) for MAD2 designs (3). \({\upsigma }_{\text{g}}^{2}\) refers to the genetic variance associated with the term Geno; \({\upsigma }_{\text{gy}}^{2}\) the tested line by year interaction variance associated with the term Geno:Year; \({\upsigma }_{\text{e}}^{2}\) the residual error variance; y, the number of years; n, the average number of check replicates, ni the number of replicates of the ith check.
Calculation of adjusted means
Adjusted means for tested lines were estimated using model Eq. (4). The only term differing from Eq. (2) is Year|Geno, referring to the within-year effect of tested lines. Field effects were only accounted for when improving the model significantly, with the Bayesian Information Criterion (BIC) used to select the best model fit. The model residuals were considered normally distributed if absolute values for the skewness and kurtosis parameters were below 0.8 and 4, respectively. The data was quantile transformed otherwise, using the orderNorm function of the BestNormalized package. The protein readings with NIR technology were low for black grains, with no calibration for darker colors yet available. Therefore, the seed color was considered a fixed factor in the model for protein data adjustment.
The Best Linear Unbiased Predictors (BLUP) for the term Year|Geno were extracted from the model output using the ranef function. Those values represented the deviation from the grand mean of each accession in each year. Final adjusted mean values were obtained by adding the yearly trait mean across all accessions.
Genotyping data
The genotyping data obtained with the Illumina 50 K Single Nucleotide Polymorphism (SNP) markers bead chip (Bayer et al. 2017) was provided by Oregon State University (OSU) in HapMap format with 247 genotypes and 44,040 SNP. Data quality checks and filtering were performed in TASSEL 5.0, with SNP and genotypes with more than 10% missing data and SNP with MAF lower than 5% removed from the dataset. For population structure and relatedness analyses, data was further filtered for LD < 0.2 with the function snpgdsLDpruning of the R package SNPRelate, to avoid bias related to correlated markers.
Population structure analysis
A Principal Component Analysis (PCA) was performed with the snpgdsPCA function on the pruned dataset. The function snpgdsDiss was used on the pruned set of SNP to compute the dissimilarity matrix to input in the hclust function for hierarchical clustering with the Ward.D2 method, chosen based on the agnes criterion. Results were visualized on a dendrogram, allowing the identification of the optimal number of clusters. Genetic clusters were then represented on a PCA plot of individuals using the ggplot2 R package.
Relatedness analysis
Kinship coefficients were computed with Identity-By-Descent (IBD) and maximum likelihood estimation (MLE) and assembled in a 247 by 247 kinship matrix. The pruned dataset was inputted in the function snpgdsIBDMLE, and the resulting matrix was normalized to obtain a positive semi-definite kinship matrix required in GWAS. A heatmap was generated with the GAPIT package.
LD analysis
LD was estimated by the squared Pearson correlation coefficient between allelic states of two markers (r2). r2 and its p-value were estimated for each pair of markers in TASSEL 5.0. Markers were considered unlinked when the p-value was above the significance threshold (0.05). The 95% percentile of squared transformed values of unlinked r2 corresponds to the critical r2 (Bengtsson et al. 2017) and LD decay distance to the distance over which markers are unlikely to be associated i.e., mean distance between markers with LD below the estimated critical r2. A non-linear model was fitted between r2 value and markers distance to estimate the mean decay distance for each chromosome and across the whole genome (Remington et al. 2001).
Genome-wide association study
Four methods were used for GWAS, including a single locus model (EMMA) and 3 multi-locus models (BLINK, G model, and 3VMrMLM). 3 types of phenotypes were used in the study: (a) within-year adjusted means (2019, 2020, 2021), (b) average of the within-years adjusted means (mean), (c) multiple within year adjusted means fitted together (multi). All the models were able to fit the phenotypes (a) and (b), while multi-environmental data could only be explored with 3VMrMLM and EMMA.
For multi-year analysis, 3VMrMLM was fitted with the “Multi-env” option in the IIIVMrMLM package and function, while the GWAS function of the R package rrBLUP was used to fit EMMA with the modified code proposed by Isidro-Sánchez et al. (2017). For the analyses on single year datasets and the means across years, BLINK was fitted with GAPIT R package, 3VMrMLM with the “Single-env” option in the IIIVMrMLM R package and function, and the G model with the Fortran program developed by Bernardo (2013).
Relatedness was accounted for as random effect with an additive relationship matrix computed with the A.mat function (rrBLUP R package) in EMMA, or the kinship matrix previously obtained by IBD for BLINK and 3VMrMLM. Population structure was accounted for in 3VMrMLM and EMMA by fitting the 4 first genetic principal components (PC) as fixed factors. For BLINK, the model was fitted with 0 to 4 PC. The optimal number of PC to include was determined according to the genomic inflation factor (λ < 1.1) (Yang et al. 2011) and the number of MTA (maximal). For the G model, LD pruning was carried out before analysis with snpgdsLDpruning to remove the highest level of redundancy, which is mostly associated with the genetic background and population structure, only keeping one marker among highly correlated markers (r2 > 0.85).
The Bonferroni correction was applied to the significance threshold (0.05/number of tested SNP) for all models, but the pruned set of SNP was used in the G model. Unlike the other models, the denominator was the number of SNP after pruning in the G model.
All the significant MTA identified across methods and datasets were compiled. LD blocks were investigated using the trio package and the functions getLD and findLDblocks to define groups of correlated SNP. To avoid bias related to multicollinearity in multivariate regression carried out in a later stage, the MTA with the lowest p-value was selected as representative of the block.
Comparison of GWAS models
Multivariate linear regression analysis was used to compare the models on their ability to explain the trait additive variance and their ability to detect large effect markers. For each analysis (1 trait—1 BLUP type—1 model), the allelic information on all the SNP found significant with the corresponding model were fitted against the trait phenotypic values in the analyzed dataset. The phenotypic data was standardized before analysis using the scale function, and the filtered genotyping data was converted to numeric according to the number of copies of the minor allele with genotypes homozygous for the minor allele coded as 2, heterozygous as 1, and the homozygous for the major allele as 0.
The total variance explained by selected SNP (PVEtotal) was estimated by subtracting the R squared of the reduced model (without SNP) from the R squared of the full model (with SNP and covariates). The formulas are presented in (5) with μ the trait grand mean for the BLUP type analyzed, Year the year effect (for multi-year BLUP type), PCj the jth principal components to account for population structure effect, and SNPi the effect of the ith SNP significant in the analysis and \(\epsilon\) representing the error variance.
SNP effects were estimated simultaneously to account for possible epistasis effect. The percentage of variance explained by each significant SNP (PVEsnp) was estimated according to formula (6) with a, the associated regression coefficient, and p, the minor allele frequency (MAF).
SNP prioritization
LDBlock-Trait associations detected with at least 2 analyses were selected (i.e. SNP in the same LD block found significantly associated with the trait). Among those SNP in the same LD block, the one with the lowest p-value across analyses was selected as representative of the block. The variance explained by all (PVEtotal) and each (PVEsnp) selected SNP were estimated for each BLUP type (single-year, multi-year, mean) by multivariate regression analysis, with SNP fitted as fixed factors (PVEtotal_fixed, PVEsnp_fixed) and random factors (PVEtotal_random, PVEsnp_random). The first relates to the SNP additive effect, while the latter also accounts for the heterozygous effect. For the fixed PVE, the same methodology based on formula (5) and (6) was applied to the n selected SNP, while for the random PVE the mixed model formula (7) similar to the full model in (6) but with SNP as random factors.
The function r.squaredGLMM from the R package MuMIn allowed estimating PVEtotal_random. Variance components were extracted with Varcorr (R lmerTest). PVEsnp_random was also calculated with formula (6) as for PVEsnp_fixed.
Mapping and identification of candidate genes
Barleymap (Cantalapiedra et al. 2015) was used to get the physical position of all validated SNP on the Morex v3 reference genome map. Candidate genes were investigated for SNP with a PVEsnp fixed or random above 5% across all the BLUP types (within-year, mean, multi-year). Those were defined as potential Quantitative-Trait-Loci (QTL) hotspots. The GrainGenes platform (Yao et al. 2022) was used for investigating previously reported MTA or QTL at similar positions.
Favorable haplotypes
A relationship between the number of favorable alleles exhibited by accessions and the trait value was shown in Gao et al. (2016). However, this approach does not consider possible outperforming heterozygous genotypes, which may be more favorable than the homozygous. Therefore, the relationship between the number of favorable QTL for SNP with medium to large effect size (PVE above 5% consistent across BLUP types) (NbFav) and the trait value was investigated. The SNP random effects (i.e. deviation from the trait mean due to the SNP in each allelic state existing in the population) were extracted from model (7) using the ranef function (lmerTest). For each SNP, a genotype (allelic state) was considered favorable if the sign of the effect matched the expectations. Desirable barley traits may vary between end-uses. Here, we consider the grain quality requirements for malting: low protein, low beta-glucan level, high TKW and plumpness…, etc. For each trait, calculations were based on the mean BLUP type and SNP genotypes were coded as 2 for the most favorable, 1 for the second favorable (if any), and 0 for unfavorable (opposite effect sign). NbFav was obtained by summing up these numbers for each accession.
A multivariate regression was then fitted for multiple comparison of means between groups of accessions possessing the same NbFav using the formula Trait ~ μ + Year + NbFav + Year:NbFav + ϵ.
The R package emmeans was used for the calculation of marginal means and confidence intervals corresponding to the interaction term (Year:NbFav). The cld function of the multcomp package applied to the result allowed for grouping means into statistical groups using the Bonferroni corrected significance threshold.
Multi-trait genotype ideotype distance index applied to marker-assisted selection
Marker-Assisted Selection (MAS) is generally based on the presence/absence of one or a few SNP found associated with a trait of interest. Organic farmers are looking for crops with good overall performance across multiple traits. Indices such as the multi-trait genotype-ideotype distance index (MGIDI) (Olivoto and Nardino 2021) are used in phenotypic selection to identify lines best balancing multiple traits. We investigated the potential of applying MGIDI in MAS, by inputting each trait NbFav, instead of the phenotypic values. The R package metan and mgidi function was used for calculations. The objective was to maximize NbFav for desirable traits, namely low protein, low beta-glucan level, high plumpness, high TKW, high yield, low threshing hardness, high Vigour, high resistance to lodging, low disease scores, long degree days to maturity but short degree days to anthesis. The function first groups correlated traits into factors. A score is then calculated for each factor and the sum of those scores is the final index value of an accession. The lower the index, the closer the line is from the ideotype. A selection intensity of 15% was applied to the panel. Selected accessions were compared to the whole panel on the proportion of accessions from each breeding origin and on the BLUP population means for key naked barley traits.
All the figures were generated with R using ggplot2 package.
Results
Population structure and relatedness
35,552 SNP markers remained after filtering for missing data, MAF, and unknown map position. A subset of 6505 independent SNP was used for population structure and relatedness analyses. In the Principal Component Analysis, the 4 first Principal Components explained 32% of the genotypic variation among the diversity panel, with the remaining PC explaining less than 4% each. We can conclude with a medium population structure.
The dendrogram associated with the heatmap shows how the population can be divided according to genetic relatedness and suggests at least 2 groups (Fig. 1). However, the heatmap indicates that within groups, there are some small subgroups of highly genetically related lines but also lines that are not close to any other accession.

(left) Kinship matrix heatmap and associated dendrogram with genotypes represented on each axis; (right) PCA plot representing the accessions position according to the 2 first PCs. Point shape and ellipses indicate the genetic groups resulting from hierarchical clustering analysis described in Table 1
Hierarchical clustering identified 2, 4, or 6 groups, with 4 being the optimal number. The main criteria differentiating the groups are the line breeding history (Genebanks (G1, G2) or breeding programs (G3, G4)), the seed color (either yellow (G3, G4) or colored (G1, G2)), the specific line donor or breeding program and the spike morphology (2 or 6-rows). Table 1 summarizes the number of lines in each genetic group for each possible combination of these criteria.
Linkage disequilibrium (LD)
The maximum LD between 2 SNP markers was 0.46, and the critical r2 was 0.12. Figure 2 shows that LD decays rapidly, with LD decay estimated at 1.72 Mbp. However, LD decay varied across chromosomes (1.91 ± 0.40 Mbp).

LD between 2 SNP markers depending on their distance. Mbp = Mega base pair: horizontal line = r2 critical value; vertical line = LD decay distance
Phenotypic data range and distribution
In the following sections, results on individual traits are only described for 7 of the 19 traits, each representing a trait category: phenology (GDDA), agronomy (Lodging), diseases (Rhyn), yield, threshing hardness (Thresh), grain quality (plump), and nutritional value (Bgluc). Results for the remaining traits are provided in supplementary materials.
Figure 3 represents the data range and distribution of genotypic BLUPs for each trait and BLUP type (within-year BLUP, mean of within year BLUP, multiple within-year BLUP). Out of the 84 datasets analyzed, only 14 passed the Shapiro–Wilk test (p-value ≥ 0.01) but only 9 had an absolute value of skewness above 0.8 and kurtosis remained below 4, indicating only slight deviation from normality and may thus not affect GWAS analyses (Table S4). Only three traits had heritability below 60% (yield, HI, and hulled) (Table S3), indicating good reproducibility of the data.

Violin plots and boxplots for each trait and each BLUP type. See material and methods for full description of traits and measurement units; Lodging, Rhyn, and Thresh were quantile transformed prior mixed linear modeling
Genome-wide association studies
The study identified 1742 Marker-Trait Associations (MTA) across traits, models, and BLUP types. 1653 MTA remained after grouping significant SNP into LD blocks and selecting the most significant as representative SNP of the block.
Comparison of GWAS models
Overall, the 3VMrMLM model performed best with significant MTA explaining the largest proportion of the trait additive variance in most analyses (Table 2). 3VMrMLM also covered all the effect size ranges (Table 3). BLINK and 3VMrMLM respectively discovered 3 and 11 MTA that explained more than 5% of the trait variance, while the other models discovered small effect markers. On the multi-year BLUP type, EMMA failed to detect significant associations for 8 of the 19 traits and did not detect any on the within-year BLUP types (Table 2). The G model generally identified more MTA but with similar or lower PVEtotal. Interestingly, the model performed better on some agronomic and disease traits (plump, Ramularia). BLINK identified a smaller number of markers, but their effects combined explained a larger proportion of the variance in some cases.
MTA validation and QTL identification
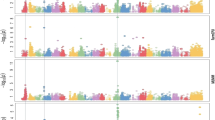
In total, 259 MTA were significant in at least two analyses (Fig. 4, Table S6). The position and effect size of SNP associated with 7 of the 19 traits are represented in Fig. 5. Discovered on multiple BLUP types, 175 MTA were selected with the G model, 13 with BLINK, and 50 with 3VMrMLM. 29 MTA were validated with at least 2 models and/or on several BLUP types but none by all 4 models: 13 with BLINK and 3VMrMLM (including 2 QEI), 7 with 3VMrMLM and EMMA, 2 with BLINK, EMMA and 3VMrMLM, 1 with G model and 3VMrMLM, 1 with G model and EMMA. Rhyn was associated with 14 SNP only, but above half were selected, while 111 MTA were discovered for GDDA but only 24 in several analyses.

Venn diagram representing the number of common MTA between BLUP types across models and traits and between models across BLUP types and traits

Position and effect size category of MTA validated across analyses. Across BLUP types, minimal percentage of variance explained by SNP when fitted as random
Selected SNP explained a larger proportion as random compared to fixed effect (Table 4). Fixed and random PVE were correlated for both PVEtotal (\(rpearson=0.69\)) and PVEsnp effect (\(rpearson=0.43\)) (Fig. S3). Based on the PVE calculated from random effects, 36 MTA were identified as “major QTL” and explained above 5% of the trait variance on each the BLUP types (Table 5, Table S7).
The investigation of candidate genes or known QTL in LD with the markers led to the further validation of 20 of them, explaining up to 26% of the trait variance on average across BLUP types (Table S7). For example, Q.Thresh4H explained at least 20.9% of Thresh and Q.Lodging3H.1 explained 21.2% of Lodging variance.
Relationship between the number of favorable major QTL and the trait value
Figure 6 shows an additive effect of the number of favorable major QTL, and consistency across years for most traits. Overall, significant differences were observed between the low and high NbFav, except when the number of accessions was too small leading to high standard error. However, results highlight the presence of a genotype-by-year interaction. Yield had only one major QTL identified and was significantly improved by the favorable genotype in 2020 and 2021 but not in 2019. Rhyn had low disease levels in 2021 for all the haplotypes (i.e., combinations of alleles from all major QTL), mainly due to reduced disease pressure compared to 2020.

Effect of combination of favorable allelic states at major QTL associated with 7 of the 19 studied traits. Letters correspond to statistical groups from multiple comparison of means with p-value Bonferroni correction. Square dots correspond to the marginal means and error bars to the associated confidence intervals. The number of lines corresponding to each haplotype is indicated above the x-axis
Multi-trait marker assisted selection with MGIDI on the number of favorable QTL (NbFav)
The MGIDI index selected 37 accessions with maximized NbFav across the studied traits. Figure 7A shows how the traits were grouped into factors according to NbFav values, and the proportion of the selection index explained by each factor. A high contribution to MGIDI indicates a strength and a low contribution, a weakness. Overall, all the accessions exhibited strength on plump and Thresh, while there is more disparity on the other factors (Table S12). Setana Hadaka seems to maximize NbFav for FA2 corresponding to yield and disease resistance, while some of the DH lines show weaknesses on the FA1 regrouping agronomic and nutritional traits. The comparison of trait means between the selection and the full panel confirms that the selection favored genetic gain for plump, TKW, and Thresh (Table 6). For other important traits such as protein, Bgluc, and Lodging, although no genetic gain was observed, mean values remain in an acceptable range. The diversity within the panel was also maintained with similar proportions of accessions from each breeding history for the selection and the full panel (Fig. 7B).

(A) Radar chart representing the contribution of each factor to the MGIDI index, for each accession selected based on NbFav. (B) Proportion of accessions from each breeding history (Donors) in the whole panel (p0) versus in the selection (pS)(%)(acronyms related to Donors described in Table 1)
Discussion
Performance and complementarity of different GWAS models
The recent model 3VMrMLM showed the best performance identifying main effect markers, with 24 out of the 36 major QTL identified with this model, including 17 with this model only. Since its development, a few studies have also demonstrated the high power of this model to estimate the markers’ effect in an unbiased manner and detect markers from all ranges of effect sizes. He et al. (2022), Li et al. (2022a, b), Wei et al. (2022), and Zhang et al. (2022) compared 3VMrMLM to a single-locus method, GEMMA, REMMA, MLM and EMMA, respectively, and demonstrated a lower power to detect small effect and stable QTNs. In the present study, the single locus model EMMA failed to identify any significant MTA within the single-year and the mean BLUP types. However, using multi-year data increased the population size and thus improved the power of the model to detect associations and allowed the identification of 369 MTA across 11 out of 19 traits, of which only 8 were also discovered with other models. The fair comparison of 3VMrMLM, BLINK, G model, and EMMA is not straightforward and rather complex due to their very different characteristics (SNP starting number, steps of analysis, … etc.). Only 3VMrMLM and EMMA can fit multi-environmental data, and only 3VMrMLM is able to explore SNP by environment interaction. Thus, no comparison could be made for the latter.
QTL were mostly selected based on multiple analyses with the same model on different BLUP types, but the combination of models allowed to explain a larger part of the variance for 7 of the 19 traits (Table S9). Each model seems to have its strengths and weaknesses depending on the trait category. For example, major QTL discovered with the G model or 3VMrMLM alone explained up to 18% of the random variance each, whereas combining QTL selected from the two models’ outputs explained up to 47%. Similarly, for Bgluc, QTL found with BLINK and 3VMrMLM alone explained up to 29% and 37%, respectively, while selecting QTL from the two models ‘outputs explained up to 58% of the random variance. This suggests that very different GWAS models can be complementary and allow broader understanding of the trait genetic architecture.
Efficient markers prioritization for the identification of major QTL
Grouping correlated SNP markers into LD blocks and selecting blocks found associated with a trait in more than 1 analysis allowed prioritizing more associations than restricting the selection to specific SNP. While it was not necessarily the case for within-model selection across BLUP types, between-models selection identified 29 MTA if based on LD blocks against 22 if based on SNP. For example, only 2 MTA were selected between the G model and other models, whereas 4 additional SNP were selected based on LD blocks. Similarly, Gao et al. (2016) used the G model to validate results from MLM for wheat leaf rust resistance and the two models did not necessarily discover the same but closely mapped markers.
The second step of SNP prioritization is based on its effect size. GWAS model outputs do not necessarily provide this information, and if provided, the values are not calculated the same way across models. Indeed, multiple statistical methods can be used for marker effect estimation, each with specific advantages and limitations (Xavier 2019; Zhu and Zhou 2020). Compared to the fixed effect procedure, the random effect procedure allowed prioritizing more MTA and identify outperforming heterozygous that may be of interest This study proposed a methodology to prioritize SNP discovered with multiple models ran on multiple BLUP types. Calculating the effect of markers on each BLUP type and prioritizing SNP based on their minimum PVE across BLUP types guaranteed the selection of SNP with a consistently large effect across years.
Validating prioritized SNP with genes previously characterized for impacting the studied trait, provides an additional level of reliability to the marker. Half of the 36 major QTL are potentially novel i.e., with no obvious candidate gene or co-localized QTL identified. One explanation for not finding a candidate gene may be that the gene has not been characterized yet. Candidate genes are usually searched for in direct proximity to the SNP but due to the intra-chromosome variation of LD pattern on top of the inter-chromosome variation, the associated gene might be located slightly farther than expected. For example, Pasam et al. (2012) observed a faster LD decay among landraces than modern barley cultivars, and a higher LD between SNP among 6-rows than 2-rows.
Some QTL may be expressed differently in one environment from another. GWAS analysis on the aggregated within-year BLUP with 3VMrMLM identified 13 significant QTN by environment interaction (QEIs) associated with Bgluc, protein, yield, HI, Vigour, BYDV, GDDA, which explained between 0.7 and 3.9% of the trait variance (Table S8). Interestingly, Q.BYDV3H.1 was a QEI also identified as major QTL. Candidate genes for QEI mainly encode for proteins involved in various biotic and abiotic stress tolerance mechanisms such as chaperone proteins, hexosyltransferase (Dawood et al 2020), Zinc finger proteins (Hussain et al. 2022), ferredoxin (Wójcik-Jagła et al. 2020), and serine/threonine protein kinase. This result coincides with the contrasted weather conditions at the experimental site: 2020 was characterized by a warm and dry spring followed by a wet and cool summer and 2021 by a cold spring but a warm and dry summer with a reduced disease pressure compared to 2020.
The environmental effect was also highlighted by year-specific MTA. 3 major QTL for Thresh, Ramularia, and GDDPM were only identified on the 2020 and the mean datasets, and 1 QTL for Lodging only on the 2021 and the mean datasets. As highlighted previously for diseases, low symptom severity may have led to only partial or no expression of the QTL, thus explaining the inconsistency in GWAS output. For example, JHI-Hv50k-2016-426290 on 6H (546.7 Mbp) explained up to 29% of the variance for Ramularia in 2020 but only 3% in 2021. A relevant candidate gene is HORVU.MOREX.r3.6HG0627440 encoding for an Agmatine coumaroyltransferase-2 protein involved in the reinforcement of cell walls to prevent from pathogen infection (Lemcke et al. 2021). Although this SNP was not prioritized based on our data, it may be a SNP of interest. This observation highlights the need for phenotyping in more years/locations for QTL validation.
Predicting the genotype performance using major QTL identified in multi-model GWAS
The relationship between the number of favorable alleles and the trait value was demonstrated for wheat coleoptile length, based on the allelic additive effect (Wei et al. 2022). However, in the presence of heterozygous effect, it may be more accurate to consider the favorable genotypes of major QTL (i.e. heterozygous, homozygous for the minor or major allele). In this study, multiple comparison of haplotypes showed that the haplotype combining the most favorable genotypes of all major QTL had the best trait value. However, this theoretical best haplotype was not always existent in the studied population, or the number of accessions exhibiting this haplotype was too low to detect a significant difference (Table S11). Nevertheless, our results highlighted a correlation between the number of favorable genotypes at major QTL (NbFav) and the trait value.
A practical application of this finding is the use of NbFav in a multi-trait index for more efficient Marker-Assisted-Selection (MAS). Based on our data, the selection succeeded in identifying a subset of lines best-balancing multiple traits while maintaining genetic diversity. If we were to compare MAS to phenotypic selection, short-term genetic gain may be lower but higher on the long-term, with better trait stability.
In early stage of plant breeding programs, the idea of MAS may be more to eliminate the less desirable accessions, rather than selecting the best. Part of the trait variance remains unexplained because of the highly quantitative nature of some traits such as phenological traits or yield. Those traits are controlled by many genes with rather small effect and are highly influenced by the environment. The QTL identified in this study may not be effective at other locations, thus further phenotyping in multiple environments would be required to select reliable QTL for their broad use in MAS. Finally, the identification of environment-specific QTL may also be of interest to select for local adaptation.
Conclusion
Each of the 4 GWAS models tested showed strengths and limitations but 3VMrMLM performed best overall. Using multiple models allowed validating more MTA than single model analysis on multiple datasets. Prioritizing validated MTA based on their minimum random PVE across BLUP types allowed the identification of 36 large effect QTL including 18 associated with a candidate gene or a known QTL and the remaining potentially novel. The study also highlighted a relationship between the number of favorable genotypes at major QTL and the trait value. Thus, maximizing this number for each trait of interest in a selection index using an ideotype design may lead to efficient Marker-Assisted Selection (MAS) for accessions best balancing multiple quantitative traits.
References
AHDB (2008) The encyclopaedia of cereal diseases. Accessed from http://www.agricentre.basf.co.uk/agroportal/uk/media/marketing_pages/cereal_fungicides/BASF_Disease_Encyclopedia.pdf
Alqudah AM, Sallam A, Stephen Baenziger P, Börner A (2020) GWAS: fast-forwarding gene identification and characterization in temperate Cereals: lessons from barley—a review. J Adv Res 22:119–135. https://doi.org/10.1016/j.jare.2019.10.013
Arrieta M, Macaulay M, Colas I, Schreiber M, Shaw PD, Waugh R, Ramsay L (2021) An induced mutation in HvRECQL4 increases the overall recombination and restores fertility in a barley HvMLH3 mutant background. Front Plant Sci 12:1–12. https://doi.org/10.3389/fpls.2021.706560
Bayer MM, Rapazote-Flores P, Ganal M, Hedley PE, Macaulay M, Plieske J, Waugh R (2017) Development and evaluation of a barley 50k iSelect SNP array. Front Plant Sci 8:1792. https://doi.org/10.3389/fpls.2017.01792
Beier S, Himmelbach A, Colmsee C, Zhang XQ, Barrero RA, Zhang Q, Mascher M (2017) Construction of a map-based reference genome sequence for barley Hordeum vulgare L. Sci Data 4(1):1–24. https://doi.org/10.1038/sdata.2017.44
Bengtsson T, Åhman I, Manninen O, Reitan L, Christerson T, Due Jensen J, Orabi J (2017) A novel QTL for powdery mildew resistance in nordic spring barley (Hordeum vulgare L. ssp. vulgare) revealed by genome-wide association study. Front Plant Sci 8:1954. https://doi.org/10.3389/fpls.2017.01954
Bernardo R (2008) Molecular markers and selection for complex traits in plants: learning from the last 20 years. Crop Sci 48:1649–1664. https://doi.org/10.2135/cropsci2008.03.0131
Bernardo R (2013) Genomewide markers as cofactors for precision mapping of quantitative trait loci. Theor Appl Genet 126(4):999–1009. https://doi.org/10.1007/s00122-012-2032-2
Botticella E, Savatin DV, Sestili F (2021) The triple jags of dietary fibers in cereals: how biotechnology is longing for high fiber grains. Front Plant Sci 12(September):1–18. https://doi.org/10.3389/fpls.2021.745579
Cantalapiedra CP, Boudiar R, Casas AM, Igartua E, Contreras-Moreira B (2015) BARLEYMAP: physical and genetic mapping of nucleotide sequences and annotation of surrounding loci in barley. Mol Breed 35(1):1–11. https://doi.org/10.1007/s11032-015-0253-1
Cheverud JM (2001) A simple correction for multiple comparisons in interval mapping genome scans. Heredity 87(1):52–58. https://doi.org/10.1046/j.1365-2540.2001.00901.x
Dawood MFA, Moursi YS, Amro A, Baenziger PS, Sallam A (2020) Investigation of heat-induced changes in the grain yield and grains metabolites, with molecular insights on the candidate genes in barley. Agronomy 10(11):1730. https://doi.org/10.3390/agronomy10111730
FAO (2016) For monitoring diseases, pests and weeds in cereal crops. Accessed from https://www.fao.org/publications/card/en/c/6b4cdb2a-d8a0-4e0d-97bc-f5a8a8e24497/
Gao L, Kathryn Turner M, Chao S, Kolmer J, Anderson JA (2016) Genome wide association study of seedling and adult plant leaf rust resistance in elite spring wheat breeding lines. PLoS ONE 11(2):e0148671. https://doi.org/10.1371/journal.pone.0148671
He L, Xiao J, Rashid KY, Yao Z, Li P, Jia G, You FM (2019) Genome-wide association studies for pasmo resistance in flax (Linum usitatissimum L.). Front Plant Sci 9:1982. https://doi.org/10.3389/fpls.2018.01982
He L, Wang H, Sui Y, Miao Y, Jin C, Luo J (2022) Genome-wide association studies of five free amino acid levels in rice. Front Plant Sci 13(November):1–17. https://doi.org/10.3389/fpls.2022.1048860
Huang M, Liu X, Zhou Y, Summers RM, Zhang Z (2019) BLINK: a package for the next level of genome-wide association studies with both individuals and markers in the millions. GigaScience 8(2):1–12. https://doi.org/10.1093/gigascience/giy154
Hussain A, Liu J, Mohan B, Burhan A, Nasim Z, Bano R, Pajerowska-Mukhtar KM (2022) A genome-wide comparative evolutionary analysis of zinc finger-BED transcription factor genes in land plants. Sci Rep 12(1):1–15. https://doi.org/10.1038/s41598-022-16602-8
Isidro-Sánchez J, Akdemir D, Montilla-Bascón G (2017) Genome-Wide Association Analysis Using R. Methods in Molecular Biology, vol 1536. Springer, Berlin, pp 189–207. https://doi.org/10.1007/978-1-4939-6682-0_14
Jiang L, Jiang N, Hu Z, Sun X, Xiang X, Liu Y, Luo X (2023) TATA-box binding protein-associated factor 2 regulates grain size in rice. Crop J 11(2):438–446. https://doi.org/10.1016/j.cj.2022.08.010
Kaler AS, Purcell LC (2019) Estimation of a significance threshold for genome-wide association studies. BMC Genomics 20(1):618. https://doi.org/10.1186/s12864-019-5992-7
Kang HM, Zaitlen NA, Wade CM, Kirby A, Heckerman D, Daly MJ, Eskin E (2008) Efficient Control of population structure in model organism association mapping. Genetics 178(3):1709–1723. https://doi.org/10.1534/genetics.107.080101
Kiełbowicz-Matuk A, Banachowicz E, Turska-Tarska A, Rey P, Rorat T (2016) Expression and characterization of a barley phosphatidylinositol transfer protein structurally homologous to the yeast Sec14p protein. Plant Sci 246:98–111. https://doi.org/10.1016/j.plantsci.2016.02.014
Kim J-S, Takahagi K, Inoue K, Shimizu M, Uehara-Yamaguchi Y, Kanatani A, Mochida K (2022) Exome-wide variation in a diverse barley panel reveals genetic associations with ten agronomic traits in Eastern landraces. J Genet Genomics. https://doi.org/10.1016/j.jgg.2022.12.001
Koppolu R, Schnurbusch T (2019) Developmental pathways for shaping spike inflorescence architecture in barley and wheat. J Integr Plant Biol 61(3):278–295. https://doi.org/10.1111/jipb.12771
Lemcke R, Sjökvist E, Visentin S, Kamble M, James EK, Hjørtshøj R, Lyngkjær MF (2021) Deciphering molecular host-pathogen interactions during Ramularia Collo-Cygni infection on barley. Front Plant Sci 12:747661. https://doi.org/10.3389/fpls.2021.747661
Li L, Wu X, Chen J, Wang S, Wan Y, Ji H, Zhang J (2022a) Genetic dissection of epistatic interactions contributing yield-related agronomic traits in rice using the compressed mixed model. Plants 11(19):2504. https://doi.org/10.3390/plants11192504
Li M, Zhang YW, Zhang ZC, Xiang Y, Liu MH, Zhou YH, Zhang YM (2022b) A compressed variance component mixed model for detecting QTNs and QTN-by-environment and QTN-by-QTN interactions in genome-wide association studies. Mol Plant 15(4):630–650. https://doi.org/10.1016/j.molp.2022.02.012
Lin C, Poushinsky G (1985) A modified augmented design (type 2) for rectangular plots. Can J Plant Sci 749(I):743–749
Mascher M, Gundlach H, Himmelbach A, Beier S, Twardziok SO, Wicker T, Stein N (2017) A chromosome conformation capture ordered sequence of the barley genome. Nature 544(7651):427–433. https://doi.org/10.1038/nature22043
McCleary BV, Codd R (1991) Measurement of (1 → 3), (1 → 4)-β-D-glucan in barley and oats: a streamlined enzymic procedure. J Sci Food Agric 55(2):303–312. https://doi.org/10.1002/jsfa.2740550215
Megazyme (2021) Mixed-linkage beta-glucan assay procedure (McCleary method). Accessed from www.megazyme.com
Milner SG, Jost M, Taketa S, Mazón ER, Himmelbach A, Oppermann M, Stein N (2019) Genebank genomics highlights the diversity of a global barley collection. Nat Genet 51(2):319–326. https://doi.org/10.1038/s41588-018-0266-x
Newton ACC, Akar T, Baresel JPP, Bebeli PJJ, Bettencourt E, Bladenopoulos KVV, Vaz Patto MC (2010) Cereal landraces for sustainable agriculture. A review. Agron Sustain Dev 30(2):237–269. https://doi.org/10.1051/agro/2009032
Olivoto T, Nardino M (2021) MGIDI: toward an effective multivariate selection in biological experiments. Bioinformatics 37(10):1383–1389. https://doi.org/10.1093/bioinformatics/btaa981
Pasam RK, Sharma R, Malosetti M, van Eeuwijk FA, Haseneyer G, Kilian B, Graner A (2012) Genome-wide association studies for agronomical traits in a World Wide spring barley collection. BMC Plant Biol 12(1):16. https://doi.org/10.1186/1471-2229-12-16
Piepho H-P, Williams ER (2016) Augmented row-column designs for a small number of checks. Agron J 108(6):2256–2262. https://doi.org/10.2134/agronj2016.06.0325
Qin D, Liu G, Liu R, Wang C, Xu F, Xu Q, Li C (2023) Positional cloning identified HvTUBULIN8 as the candidate gene for round lateral spikelet (RLS) in barley (Hordeum vulgare L.). Theor Appl Genet 136(1):1–16. https://doi.org/10.1007/s00122-023-04272-7
Remington DL, Thornsberry JM, Matsuoka Y, Wilson LM, Whitt SR, Doebley J, Kresovich S, Goodman MM, Buckler ES (2001) Structure of linkage disequilibrium and phenotypic associations in the maize genome. Proc Natl Acad Sci 98(20):11479–11484. https://doi.org/10.1073/pnas.201394398
Rice BR, Fernandes SB, Lipka AE (2020) Multi-trait genome-wide association studies reveal loci associated with maize inflorescence and leaf architecture. Plant Cell Physiol 61(8):1427–1437. https://doi.org/10.1093/pcp/pcaa039
Sallam AH, Tyagi P, Brown-Guedira G, Muehlbauer GJ, Hulse A, Steffenson BJ (2017) Genome-wide association mapping of stem rust resistance in Hordeum vulgare subsp. spontaneum. G3 Genes Genomes Genet 7(10):3491–3507. https://doi.org/10.1534/g3.117.300222
Schmalenbach I, March TJ, Pillen K, Bringezu T, Waugh R (2011) High-resolution genotyping of wild barley introgression lines and fine-mapping of the threshability locus thresh-1 using the illumina goldengate assay. G3 Genes Genomes Genet 1(3):187–196. https://doi.org/10.1534/g3.111.000182
Spaner D, Shugar LP, Choo TM, Falak I, Briggs KG, Legge WG, Mather DE (1998) Mapping of disease resistance loci in barley on the basis of visual assessment of naturally occurring symptoms. Crop Sci 38(3):843–850. https://doi.org/10.2135/cropsci1998.0011183X003800030037x
Tibbs Cortes L, Zhang Z, Yu J (2021) Status and prospects of genome-wide association studies in plants. Plant Genome 14(1):1–17. https://doi.org/10.1002/tpg2.20077
Wabila C, Neumann K, Kilian B, Radchuk V, Graner A (2019) A tiered approach to genome-wide association analysis for the adherence of hulls to the caryopsis of barley seeds reveals footprints of selection. BMC Plant Biol. https://doi.org/10.1186/s12870-019-1694-1
Wei N, Zhang SQ, Liu Y, Wang J, Wu B, Zhao J, Zheng J (2022) Genome-wide association study of coleoptile length with Shanxi wheat. Front Plant Sci 13(September):1–12. https://doi.org/10.3389/fpls.2022.1016551
Wójcik-Jagła M, Rapacz M, Dubas E, Krzewska M, Kopeć P, Nowicka A, Żur I (2020) Candidate genes for freezing and drought tolerance selected on the basis of proteome analysis in doubled haploid lines of barley. Int J Mol Sci 21(6):2062. https://doi.org/10.3390/ijms21062062
Xavier A (2019) Efficient estimation of marker effects in plant breeding. G3 Genes|genomes|genet 9(11):3855–3866. https://doi.org/10.1534/g3.119.400728
Yabe S, Iwata H (2020) Genomics-assisted breeding in minor and pseudo-cereals. Breed Sci 70:19–31. https://doi.org/10.1270/jsbbs.19100
Yang J, Weedon MN, Purcell S, Lettre G, Estrada K, Willer CJ, Visscher PM (2011) Genomic inflation factors under polygenic inheritance. Eur J Human Genet 19(7):807–812. https://doi.org/10.1038/ejhg.2011.39
Yao E, Blake VC, Cooper L, Wight CP, Michel S, Cagirici HB, Sen TZ (2022) GrainGenes: a data-rich repository for small grains genetics and genomics. Database 2022:baac034. https://doi.org/10.1093/database/baac034
Yates G, Srivastava AK, Sadanandom A (2016) SUMO proteases: uncovering the roles of deSUMOylation in plants. J Exp Bot 67(9):2541–2548. https://doi.org/10.1093/jxb/erw092
You F, Jia G, Cloutier S, Booker H, Duguid S, Rashid K (2016) A method of estimating broad-sense heritability for quantitative traits in the type 2 modified augmented design. J Plant Breed Crop Sci 8(11):257–272. https://doi.org/10.5897/jpbcs2016.0614
Zadoks JC, Chang TT, Konzak CF (1974) A decimal code for the growth stages of cereals. Weed Res 14(6):415–421. https://doi.org/10.1111/j.1365-3180.1974.tb01084.x
Zeng J, Ye Z, He X, Zhang G (2019) Identification of microRNAs and their targets responding to low-potassium stress in two barley genotypes differing in low-K tolerance. J Plant Physiol 234–235(January):44–53. https://doi.org/10.1016/j.jplph.2019.01.011
Zhang J, Wang S, Wu X, Han L, Wang Y, Wen Y (2022) Identification of QTNs, QTN-by-environment interactions and genes for yield-related traits in rice using 3VmrMLM. Front Plant Sci 13(October):1–15. https://doi.org/10.3389/fpls.2022.995609
Zhu H, Zhou X (2020) Statistical methods for SNP heritability estimation and partition: a review. Comput Struct Biotechnol J 18:1557–1568. https://doi.org/10.1016/j.csbj.2020.06.011
Acknowledgements
Thanks to our collaborators from Oregon State University, Dr. Brigid Meints and Dr. Patrick Hayes, for providing the seeds and the experimental design in the first year of the trial, as well as the genotyping data. Thanks also to Dr. Julio Isidro Sánchez for collecting the field data in 2019 and supervising my first months as a PhD student.
Funding
Open Access funding provided by the IReL Consortium. The Irish Research Council (IRC) supported this research with a Government of Ireland Post-Graduate scholarship (GOIPG/2019/3601).
Author information
Authors and Affiliations
Contributions
Laura Paire: Fieldwork, Data collection, Data analysis, Conceptualization, Methodology, Investigation, Writing- original draft, Writing review and editing, Visualization. Cathal McCabe: Writing-review and editing. Tomás McCabe: Funding, Supervision, Writing-review
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Paire, L., McCabe, C. & McCabe, T. Multi-model genome-wide association study on key organic naked barley agronomic, phenological, diseases, and grain quality traits. Euphytica 220, 118 (2024). https://doi.org/10.1007/s10681-024-03374-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10681-024-03374-7