
Abstract
Additive manufacturing of metal components with laser-powder bed fusion is a very complex process, since powder has to be melted and cooled in each layer to produce a part. Many parameters influence the printing process; however, defects resulting from suboptimal parameter settings are usually detected after the process. To detect these defects during the printing, different process monitoring techniques such as melt pool monitoring or off-axis infrared monitoring have been proposed. In this work, we used a combination of thermographic off-axis imaging as data source and deep learning-based neural network architectures, to detect printing defects. For the network training, a k-fold cross validation and a hold-out cross validation were used. With these techniques, defects such as delamination and splatter can be recognized with an accuracy of 96.80%. In addition, the model was evaluated with computing class activation heatmaps. The architecture is very small and has low computing costs, which means that it is suitable to operate in real time even on less powerful hardware.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, additive manufacturing (AM) as an industry has experienced enormous growth. The layer-by-layer production process makes it easy to manufacture products with complex geometries and different materials. The material segment of the industry reported a record growth in 2018, with metal materials in particular increasing by 41.9%. A continuation of a 5-year growth phase of more than 40% per year was recorded in the latest edition of the annual Wohler's Report [1]. This growth demonstrates the need to find solutions that are better suited for mass manufacturing rather than rapid prototyping. AM has significant potential in the medical field, particularly for custom designs, aerospace, and automotive for lightweight construction and functionally critical parts manufactured locally at distant locations [2, 3]. However, uncertainties regarding component quality currently delay the full introduction of AM technology in these areas. The implementation of in-situ and real-time process monitoring is necessary to meet the high-quality requirements of these applications, particularly with metal powder.
Laser-powder bed fusion (L-PBF) is an AM process that uses metal powder material, which is dispensed in a layer-by-layer fashion, to create geometries from digital files. The digital parts are sliced into layers with a typical constant thickness between 20 and 100 µm. During the printing process, a laser selectively melts successive layers of metal powder on the substrate plate. After each melting cycle, a new layer of metal powder is applied upon the previous layer and a new melting cycle begins until the complete component is produced. The manufactured parts have hundreds to thousands of layers with a production time ranging from hours to days dependent on the part dimensions [4,5,6].
Despite the great development of the L-PBF process in recent years, the major breakthrough in the industry has yet to materialize due to process capabilities. The process itself has many input parameters which influence the quality of the product. Van Elsen has identified over 50 parameters which can influence the quality of printed components [7]. Many experimental studies have been conducted to evaluate the effects of energy density, scanning speed, hatch distance, and scanning strategy. The defects like lack of fusion, balling, porosity, cracks, and inclusions negatively affect mechanical properties [8,9,10]. Defects are usually examined after the process; porosity is measured using computer tomography, the Archimedes method, or metallographic imaging [11]. To measure Young’s modulus of elasticity, hardness, ultimate tensile strength, etc., destructive component tests are used for many materials [12]. However, delamination, overhanging structures, unsuitable supports, and residual stresses are critical defects during the process [13, 14] and, thus, need to be tracked.
With the implementation of in-situ process monitoring, tracing of defects during the process becomes possible. Generally, the process monitoring can be subdivided in three groups [15]. The first group uses melt pool monitoring to characterize the melt pool and the surroundings [14, 16]. The dimensions and temperature characteristics of the molten pool supply information on process reliability and the presence of local defects. The second group looks at the analysis of the entire layer to detect errors in different areas of each layer. The temperature distribution and surface after scanning is observed. The third group considers the geometric growth of the build, from slice to slice. The analysis from the second group is used repeatedly for every layer over the whole build of components. Up to now, the printing process cannot be monitored and evaluated in real time, because the printing times vary greatly. That is why, automatic in-situ monitoring and real-time defect detection are needed.
Machine learning (ML) is one of the possibilities for use in evaluating large amounts of data in real time [17,18,19,20,21,22,23,24,25,26]. Over the last decades with more powerful hardware, more and better ML architectures were developed and refined. ML methods are capable of identifying complex non-linear relationships in large amounts of data. ML approaches are subdivided in three learning categories: supervised, semi-supervised and unsupervised [27]. Supervised approaches consist of two steps for training: In the first step, the data must be labeled as, e.g., “acceptable” and “not acceptable”. In the second step, the ML network is trained with the labeled data [28, 29]. This means before learning, the user must know and identify the defects and label them. An unsupervised approach is used without labeling of the data [27, 28]. An algorithm tries to identify defects itself. Semi-supervised use supervised and unsupervised approaches at the same time [30]. This means that the ML algorithm utilizes both labeled and unlabeled data.
In this work, thermographic images were taken during the metal printing process. The thermographic data were used to train a created convolutional neural network architecture with depthwise-separable convolutions. For performance evaluation, k-fold cross and hold-out cross validation was used. Heatmaps are utilized to show the exact positions of defects.
2 Related work
ML has been successfully used in different defect detection scenarios during the AM process. Gobert et al. [31] used in-situ layerwise imaging with a digital single-lens reflex camera to take images for supervised ML defect detection during the L-PBF process. CT scans were used to evaluate the results. The resulting accuracy of defect detection during the process was up to 85%. Scime and Beuth [32] used grayscale imaging in visual range to classify powder bed anomaly classes. These classes were used to develop an ML algorithm for in-situ process monitoring. The algorithm is working, but before it can be used as in-situ monitoring environment, its classification accuracy needs to be improved. Okaro et al. [33] used photodiode measurements to develop a semi-supervised ML algorithm. The accuracy of the algorithm was at 77% and reduced experimental data are needed for training compared to supervised ML. Shevchik et al. [34] and Ye et al. [35] used acoustic signals for defect detection with ML. The acoustic signals need more data preparation before they can be used in algorithm. The accuracy using raw data is at 70% and goes up to 93% after performing a fast Fourier transformation. Khanzadeh et al. [36] used melt pool monitoring images as a source of comparison for different supervised ML techniques. The best tested algorithm was k-nearest neighbor with an accuracy of about 98% for the detection of melt pool anomalies and potentially microstructure anomalies in real time.
Many works use ML architectures in combination with acoustics or visual monitoring for automatic defects detection during the printing process. In this paper, the ML architecture is based on in-situ off-axis thermographic imaging. A convolutional neural network has been trained and evaluated for automatic defects detection.
3 Methods
To utilize ML for error recognition, the thermographic imaging data from the laser-powder bed fusion process are used. In Sect. 3.1, the in-situ measurement setup with the thermographic camera setup and manufacturing conditions of specimens are described. Theoretical background on the convolutional neural networks is given in Sects. 3.2, 3.3, while Sect. 3.4 provides background knowledge about the advanced deep-learning techniques used in our architecture. Data preprocessing and model evaluation are characterized in Sect. 3.5.
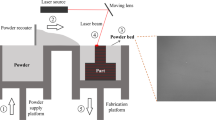
3.1 Measurement setup
The L-PBF process has been monitored using a thermographic camera to get the images of detectable errors. An SLM 280HL (SLM Solutions AG, Lübeck, Germany) was used for the metal printing process. The printing system has a 400 W Ytterbium fiber laser mounted and a building space of 280 mm × 280 mm × 350 mm with the heating up to 200 °C. If a heating system up to 650 °C is used during the process, the building space reduces to Ø 90 mm × 100 mm. The operating gas is Argon through the printing process. The material of the specimens is 1.2344 (H13) and has been printed with a layer thickness of 30 µm. The printing system manufacturer provided the remaining parameters.
The thermographic camera PYROVIEW 640G/50 Hz/25° × 19°/compact + (DIAS Infrared GmbH, Dresden, Germany) is used for taking images in the middle infrared range. The camera has 640 × 480 sensor elements (optical resolution) with a spectral range from 4.8 to 5.2 µm and takes up to 50 images per second. The camera position is above the process chamber at an angle of 60° to the substrate plate. Körperich and Merkel [37] have measured emissivity at assigned temperatures for H13 material, which is needed for thermographic imaging during the process. This measurement setup is a standard procedure for material analysis and process optimization.
3.2 Convolutional neural networks
In recent years, convolutional neural networks have become the prime algorithm for solving many complex computer vision problems [38,39,40]. In the field of image recognition, the convolutional neural networks are among the latest deep-learning methods. Convolutional neural networks are based on the multi-layered structure of real brain structures of the visual cortex and have shown remarkable results in many highly complex application scenarios [40,41,42,43].
Classic ML approaches for image recognition consist of two separate steps. In the first step, the so-called feature engineering, one tries to extract relevant data representations from the raw image data, using various algorithms, such as HOG [44], SURF [45], or HOUP [46]. In the second step, the so-called classification, a machine-learning algorithm tries to learn a pattern, which maps a-priori generated data representations and a target variable. The algorithm can only learn these patterns if they have been extracted by feature engineering before. In particular, manual extraction of the relevant data representations often leads to suboptimal classification results [43].
The fundamental difference between convolutional neural networks and classical ML approaches for computer vision is the combination of these two steps. The classification automatically influences the feature engineering process, so that features that are more meaningful for the classification results are extracted. Unimportant data are automatically excluded. Therefore, convolutional neural networks can convert raw data, such as pixel data from images, into more meaningful data representations, the so-called feature maps, which in turn supports the final classification [43, 47]. These feature maps represent characteristic areas of images, e.g. a nose in face recognition.
3.3 General convolutional neural network architectures
Common convolutional neural network architectures consist of multiple convolutional layers. Each image is processed as a three-dimensional array. By applying multiple small filter kernels onto the image array, the convolutional layers transform the original input into feature maps [47, 48]. As shown in Fig. 1, the filter matrices are applied to all areas of the original images, which preserve spatial information [43]. These feature maps are then passed through a non-linearity function like ReLU [49], a batch-normalization layer [50], convolutional layer, and a pooling layer [48]. By combining several convolutional, activation, batch normalization, and pooling layers, convolutional neural networks are able to automatically extract useful feature representation with fully connected layers from the raw image and optimize them to represent certain target classes [41, 43, 51].

Example of a typical convolutional neural network architecture, in which the network consists of multiple blocks of convolutional layers followed by pooling layers and one or more fully connected layers at the end for classification
The huge advancements made in the development of convolutional neural networks are mainly driven by the ImageNet Large Scale Visual Recognition Competition (ILSVRC) [52]. The ImageNet competition is one of the most complex and interesting computer vision competitions. Many of today’s state-of-the-art techniques are based on famous ImageNet winning architecture, evolving from classical stacks of layers, such as AlexNet [53], VGG [54], to more sophisticated architectures, such as Inception [51], ResNet [42], Xception [41], MobileNetV2 [55] or DenseNet [56].
3.4 Depthwise-separable convolutions
Classical convolutional neural network architectures for deep learning typically consist of multiple layers of convolutional, max pooling, and normalization layers, followed by a classifier consisting of fully connected layers and dropout. Until the development of the Inception modules, convolutional neural networks grew in size to learn more complex feature maps and achieve a better classification performance [53, 54]. The disadvantage of this increase in network size is the strong increase in network parameters and the computational resources required [55].
In normal convolutional layers, the kernel must learn spatial feature representations and cross-channel representations simultaneously. The Inception module divides this combined operation into separate steps, which handle cross-channel information and spatial information independently. First, the cross-channel information is summarized by a 1 × 1 convolution, which maps the dimensions of the input data to a smaller feature space (feature map). For example, the three color channels red–green–blue are combined to a mixed color channel. The spatial information is then extracted with a standard 3 × 3 or 5 × 5 convolution [51]. In this paper, the 3 × 3 approach is implemented, because this makes the network smaller and reduces computational costs. A simplified version of an Inception module is shown in Fig. 2. The input is divided in three parts; each part goes through 1 × 1 convolution and then 3 × 3 convolution. At the end, all parts join together in concatenation for further extraction of useful features. Inception modules have enabled a significant improvement in classification performance while simultaneously reducing the number of model parameters [41, 51, 55].

Simplified version of the Inception module from [41]
The depthwise-separable convolutions are based on the Inception modules. However, the order between 1 × 1 convolution and 3 × 3 convolution is inverted. Consequently, the spatial information is first extracted before a new feature map is created [41].
3.5 Our network architecture
Our network architecture consists of three blocks of convolutional and batch-normalization layers. Inspired by architectures in [40, 41, 55], depthwise-separable convolutions were used in blocks 2 and 3, effectively reducing the amount of trainable parameters. The convolutional blocks are followed by a global average pooling layer and a fully connected softmax layer for the final classification.
The first layer in our network is a regular convolutional layer, followed by a batch normalization layer (see Fig. 3). All consecutive convolutional layers are depthwise-separable convolutional layers. The output shape of each layer block is given below. The usage of depthwise-separable convolutions reduces the channel dimension, where the number of channels is equal to the number of filters in the layers. A large fully connected classifier is not used, but, instead, dropout is used to control the overfitting and directly feed into a softmax layer.

Our final model architecture
3.6 Evaluation and data preprocessing
The data set used to train and evaluate our convolutional neural network consisted of 4,314 RGB color images. To extract the images, the proprietary IRDX files are converted into standard AVI video files without video compression and 1280 × 768 px (pixels) resolution. From the original video, 18 short video sequences are extracted showing either delamination, splatters, or images without defects. Each frame of these video files is extracted and saved as a lossless PNG image file. The images are cropped to 270 × 270 px to remove unnecessary information like the camera manufacturer’s logo, temperature scales, and borders.
For the performance evaluation of the predictor, a combination of k-fold cross validation and hold-out cross validation is used. First, the entire data set was split into training and validation subsets. The validation data set is never shown to the model during training, and is only used to calculate performance values after the training is finished. To prevent information leakage, the data set was split into training and validation data sets before extracting frame-wise images. Therefore, the model is prevented from overfitting on certain sequences of images.
The training data set was used to train the model using a k-fold cross validation, where the training data set is repeatedly split into training and test subsets. At each split, the model is trained with the training data and the best model is selected using the test split. After the model training is finished, the calculation of the performance metrics using the previously mentioned validation data set is carried out. This approach allows clear identification of potential overfitting during the validation [57].
As for ML preprocessing, the images where resized to 224 × 244 px for faster processing and scaled to [0,1], also known as data normalization, to overcome different learning problems. To improve the classification accuracy and decrease model overfitting [53], data augmentation techniques were applied to the training set images. The images were rotated by 90 and 270°, flipped horizontally and vertically, and applied with random image noise and blur.
4 Results
Keras 2.1.5 package [58] with Tensorflow 1.8 backend [59] was used to train the convolutional neural network. Training was conducted on an Nvidia GeForce GTX 1080 Ti for 10-folds and 20 epochs on each fold. After each fold, the model was evaluated using the validation subset, averaging the results of all 10-folds arithmetically.
4.1 Performance evaluation
For model evaluation balanced accuracy, class averaged sensitivity (true positive ratio), precision (positive predictive value), and Cohen’s Kappa score were used. As shown in Table 1, our model achieves good performance values.
The results show that our convolutional neural network can identify delamination defects and splatters with a very good accuracy of 96.80%. Cohen’s Kappa score is 96.42%, while the true negative rate is at 91.04%. These results underpin the good performance of our model. As shown in Table 2, the model correctly identifies all delaminations as well as all cases of splashes. Only 22 images were incorrectly classified as splatter cases, while in the actual image, no splatters can be seen.
4.2 Heatmaps
In addition, our model was evaluated with computing class activation heatmaps. These heatmaps indicate the importance of spatial locations for a particular class. Therefore, class activation heatmaps can be used to visually explain the class predicted by the network. In particular, we used the gradient-weighted class activation mapping (Grad-CAM) algorithm [60].
The Grad-CAM heatmap in Fig. 4 indicated that our network considers the very hot part in the top part as relevant for assigning the class “delamination”. Furthermore, the heatmap also shows the importance of the colder image regions in the bottom and right part. This indicated that our model considers the temperature difference between the delaminated part and a non-delaminated part as highly important for the final decision.

Heatmap for one example of a delamination defect: a the original thermographic image; b the class activation heatmap of our network where important spatial areas are highlighted, with the red circles indicating the area of high importance in the Grad-CAM heatmap
5 Discussion
As demonstrated in Table 1, our convolutional neural network performs very well and achieves excellent classification results. These results were underpinned by the confusion matrix in Table 2. The confusion matrix shows that all of the highly relevant delamination defects are correctly classified, while only 22 out of 1,987 images are falsely classified as splatters, where the correct label would be “OK”. However, the model correctly identified all cases of the more severe type of defect, the delaminations. The evaluation of the Grad-CAM shows that the network considers the unusually heated parts of the thermographic images as highly relevant for the final decision. This further underpins the good results, as shown in Table 1.
Previous studies have shown that machine learning can be deployed for defect detection in the L-PBF process, using various techniques like acoustic sensors [34], thermal [36], grayscale [32], or high-resolution imaging [31]. While the current benchmarks range from 77 to 98% accuracy in detecting errors, they rely on either extensive data preprocessing or upon additional imaging techniques.
With a mean balanced accuracy of 96.80% and a top balanced accuracy of 98.80%, our model outperforms all the current benchmarks for in-situ defect detection during the L-PBF process. Most of the current image-based algorithms use classical feature extraction in combination with a shallow machine-learning algorithm. The results in Tables 1 and 2 show the benefit of using the convolutional neural networks. In comparison to [32], we process the entire image instead of processing the image pixel-wise. Therefore, we can evaluate whether the entire image shows a defect, instead of classifying if a certain pixel shows a potential defect. As compared to melt pool monitoring or pixel-wise classification, we can detect larger defect types like metal splatters, which can only be detected when monitoring the entire image. Our model also does not need extensive data preprocessing and is not dependent upon additional imaging sources like X-ray, but is able to identify defects from thermographic images directly.
Furthermore, our model is very small and light on computational costs. As shown in Fig. 3, our model is relatively small in comparison to well-known architectures such as VGG [54] or ResNet [42]. These large models are capable of solving very complex object recognition tasks such as the ImageNet competition, but do have a strong tendency to overfit on less complex problems. Small models are usually more specialized for the given task and provide high accuracy values, while being light on computational resources [40].
6 Conclusions
In this work, it could be shown that a convolutional neural deep network can be used to detect and identify defects during printing processes with an average balanced accuracy of 96.80%. Our model is very small and light on computational costs that achieves fast compilation and training without a need for powerful hardware. For training and testing, thermographic images were used, which were taken during in-situ off-axis monitoring in the printing process of H13 steel specimens. One geometrical shape, a critical defect delamination and an uncritical defect splatter were chosen for the training of the network. In addition to deciding on the type and position of error, the network can also output a heatmap.
Our model is well suited for in-situ defect detection of L-PBF processes and can be easily adopted to other defect types, material systems, and geometric shapes. Since our model is only based on a single source of information, it is easy to adopt to other defect types and materials, without the need to carry out additional evaluations using expensive and time-consuming methods like X-ray or CT.
6.1 Limitations
This convolutional neuronal network can only detect defects such as splatter and delamination. However, other defect types such as cracks, pores, balling, and unfused powder have not been evaluated in the current experimental setup. Further tests are necessary to fully evaluate the generalizability of our model towards other types of defects. Additionally, only one geometrical shape and H13 material were used for the training and evaluation of our current model. Since different materials have different temperature fields, which directly influence the thermographic imaging, further tests using other materials are necessary.
6.2 Future work
In future work, we will re-evaluate the performance of our network using a broader variety of materials and geometric shapes, thereby showing the models performance in more potential applications, while other errors should also be recognizable.
Furthermore, we will re-evaluate our work by conducting additional experiments on a broader variety of defect types such as cracks, pores, overheating, or balling defects. Additionally, we plan to evaluate the runtime performance of our model using an embedded hardware platform and low-powered computing devices like a Raspberry Pi to assess the runtime performance of our model on limited computational resources.
References
Wohlers Associates (2019) Wohlers report 2019: 3D printing and additive manufacturing state of the industry. Wohlers Associates Inc, Fort Collins, Colorado
O’Regan P, Prickett P, Setchi R et al (2016) Metal based additive layer manufacturing: variations, correlations and process control. Proc Comput Sci 96:216–224. https://doi.org/10.1016/j.procs.2016.08.134
Taminger KM, Hafley RA (2006) Electron beam freeform fabrication for cost effective near-net shape manufacturing. https://hdl.handle.net/2060/20080013538
Gibson I, Rosen DW, Stucker B (2015) Additive manufacturing technologies: 3D printing, rapid prototyping and direct digital manufacturing, 2nd ed. Springer, New York
Rashid R, Masood SH, Ruan D et al (2017) Effect of scan strategy on density and metallurgical properties of 17–4PH parts printed by selective laser melting (SLM). J Mater Process Technol 249:502–511. https://doi.org/10.1016/j.jmatprotec.2017.06.023
Gao W, Zhang Y, Ramanujan D et al (2015) The status, challenges, and future of additive manufacturing in engineering. Comput Aided Des 69:65–89. https://doi.org/10.1016/j.cad.2015.04.001
van Elsen M (2007) Complexity of selective laser melting: a new optimisation approach. https://lirias.kuleuven.be/retrieve/67187
Sames WJ, List FA, Pannala S et al (2016) The metallurgy and processing science of metal additive manufacturing. Int Mater Rev 61(5):315–360. https://doi.org/10.1080/09506608.2015.1116649
Liu QC, Elambasseril J, Sun SJ et al (2014) The Effect of manufacturing defects on the fatigue behaviour of Ti-6Al-4V specimens fabricated Using selective laser melting. In: 11th international fatigue congress proceedings, pp 1519–1524
Gong H, Rafi K, Gu H et al (2015) Influence of defects on mechanical properties of Ti–6Al–4V components produced by selective laser melting and electron beam melting. Mater Des 86:545–554. https://doi.org/10.1016/j.matdes.2015.07.147
Spierings AB, Schneider M, Eggenberger R (2011) Comparison of density measurement techniques for additive manufactured metallic parts. Rapid Prototyp J 17(5):380–386. https://doi.org/10.1108/13552541111156504
Hitzler L, Merkel M, Hall W et al (2018) A review of metal fabricated with laser- and powder-bed based additive manufacturing techniques: process, nomenclature, materials, achievable properties, and its utilization in the medical sector. Adv Eng Mater 20(5):1. https://doi.org/10.1002/adem.201700658
Tapia G, Elwany A (2014) A review on process monitoring and control in metal-based additive manufacturing. J Manuf Sci Eng 136(6):60801. https://doi.org/10.1115/1.4028540
Clijsters S, Craeghs T, Buls S et al (2014) In situ quality control of the selective laser melting process using a high-speed, real-time melt pool monitoring system. Int J Adv Manuf Technol 75(5):1089–1101. https://doi.org/10.1007/s00170-014-6214-8
Everton SK, Hirsch M, Stravroulakis P et al (2016) Review of in-situ process monitoring and in-situ metrology for metal additive manufacturing. Mater Des 95:431–445. https://doi.org/10.1016/j.matdes.2016.01.099
Lott P, Schleifenbaum H, Meiners W et al (2011) Design of an optical system for the in situ process monitoring of selective laser melting (SLM). Phys Proc 12:683–690. https://doi.org/10.1016/j.phpro.2011.03.085
Sauer S, Buettner R, Heidenreich T et al (2018) Mindful Machine Learning. Eur J Psychol Assess 34(1):6–13. https://doi.org/10.1027/1015-5759/a000312
Rieg T, Frick J, Hitzler M et al (2019) High-performance detection of alcoholism by unfolding the amalgamated EEG spectra using the Random Forests method. In: HICSS-52 proceedings, pp 3769–3777
Buettner R, Schunter M (2019) Efficient machine learning based detection of heart disease. In: IEEE healthcom 2019 proceedings. IEEE, Bogotá, Colombia (in press)
Buettner R, Sauer S, Maier C et al (2018) Real-time prediction of user performance based on pupillary assessment via eye-tracking. AIS THCI 10(1):26–60. https://doi.org/10.17705/1thci.00103
Buettner R (2018) Robust user identification based on facial action units unaffected by users’ emotions. In: HICSS-51 proceedings, pp 265–273
Buettner R, Fuhrmann J, Kolb L (2019) Towards high-performance differentiation between Narcolepsy and Idiopathic Hypersomnia in 10 minute EEG recordings using a novel machine learning approach. In: IEEE healthcom 2019 proceedings. IEEE, Bogotá, Colombia (in press)
Buettner R, Hirschmiller M, Schlosser K et al (2019) High-performance exclusion of schizophrenia using a novel machine learning method on EEG data. In: IEEE healthcom 2019 proceedings. IEEE, Bogotá, Colombia (in press)
Buettner R, Grimmeisen A, Gotschlich A (2020) High-performance diagnosis of sleep disorders: a novel, accurate and fast machine learning approach using electroencephalographic data. In: HICSS-53 proceedings, pp 3246–3255
Buettner R, Beil D, Scholtz S et al (2020) Development of a machine learning based algorithm to accurately detect schizophrenia based on one-minute EEG recordings. In: HICSS-53 proceedings, pp 3216–3225
Buettner R, Frick J, Rieg T (2019) High-performance detection of epilepsy in seizure-free EEG recordings: A novel machine learning approach using very specific epileptic EEG sub-bands. In: ICIS 2019 proceedings, paper ID 2536, pp 1–16
Baumann F, Emmert D, Baumgartl H et al (2018) Hardcore Gamer Profiling: Results from an unsupervised learning approach to playing behavior on the Steam platform. Proc Comput Sci 126:1289–1297. https://doi.org/10.1016/j.procs.2018.08.078
Dougherty J, Kohavi R, Sahami M (1995) Supervised and unsupervised discretization of continuous features. In: ICML 1995 proceedings, pp 194–202
Buettner R (2016) Personality as a predictor of business social media usage: An empirical investigation of XING usage patterns. In: PACIS 2016 proceedings, p 163
Chapelle O, Scholkopf B, Zien EA (2009) Semi-supervised learning (Chapelle, O. et al., Eds.; 2006) [Book reviews]. IEEE Trans Neural Netw Learn Syst 20(3):542. https://doi.org/10.1109/TNN.2009.2015974
Gobert C, Reutzel EW, Petrich J et al (2018) Application of supervised machine learning for defect detection during metallic powder bed fusion additive manufacturing using high resolution imaging. Addit Manuf 21:517–528. https://doi.org/10.1016/j.addma.2018.04.005
Scime L, Beuth J (2018) Anomaly detection and classification in a laser powder bed additive manufacturing process using a trained computer vision algorithm. Addit Manuf 19:114–126. https://doi.org/10.1016/j.addma.2017.11.009
Okaro IA, Jayasinghe S, Sutcliffe C et al (2019) Automatic fault detection for laser powder-bed fusion using semi-supervised machine learning. Addit Manuf 27:42–53. https://doi.org/10.1016/j.addma.2019.01.006
Shevchik SA, Kenel C, Leinenbach C et al (2018) Acoustic emission for in situ quality monitoring in additive manufacturing using spectral convolutional neural networks. Addit Manuf 21:598–604. https://doi.org/10.1016/j.addma.2017.11.012
Ye D, Hong GS, Zhang Y et al (2018) Defect detection in selective laser melting technology by acoustic signals with deep belief networks. Int J Adv Manuf Technol 96(5):2791–2801. https://doi.org/10.1007/s00170-018-1728-0
Khanzadeh M, Chowdhury S, Marufuzzaman M et al (2018) Porosity prediction: supervised-learning of thermal history for direct laser deposition. J Manuf Syst 47:69–82. https://doi.org/10.1016/j.jmsy.2018.04.001
Körperich JP, Merkel M (2018) Thermographic analysis of the building height impact on the properties of tool steel in selective laser beam melting. Materialwiss Werkstofftech 49(5):689–695. https://doi.org/10.1002/mawe.201800010
Baumgartl H, Buettner R (2020) Development of a highly precise place recognition module for effective human-robot interactions in changing lighting and viewpoint conditions. In: HICSS-53 proceedings, pp 563–572
Baumgartl H, Tomas J, Buettner R et al (2019) A novel deep-learning approach for automated non-destructive testing in quality assurance based on convolutional neural networks. In: ACEX 2019 proceedings
Buettner R, Baumgartl H (2019) A Highly effective deep learning based escape route recognition module for autonomous robots in crisis and emergency situations. In: HICSS-52 proceedings, pp 659–666
Chollet F (2017) Xception: deep learning with depthwise separable convolutions. In: IEEE CVPR 2017 proceedings, IEEE, pp 1800–1807
He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: IEEE CVPR 2016 proceedings, IEEE, pp 770–778
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444. https://doi.org/10.1038/nature14539
Dalal N, Triggs B (2005) Histograms of oriented gradients for human detection. In: IEEE CVPR 2005 proceedings, IEEE, pp 886–893
Bay H, Tuytelaars T, van Gool L (2006) SURF: speeded up robust features. In: ECCV 2006 proceedings, vol 3951. Springer, pp 404–417
Fazl-Ersi E, Tsotsos JK (2012) Histogram of oriented uniform patterns for robust place recognition and categorization. Int J Robot Res 31(4):468–483. https://doi.org/10.1177/0278364911434936
Yosinski J, Clune J, Bengio Y et al (2014) How transferable are features in deep neural networks? In: NIPS 2014 proceedings, pp 3320–3328
LeCun Y, Bottou L, Bengio Y et al (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324. https://doi.org/10.1109/5.726791
Vinod Nair, Geoffrey E. Hinton (2010) Rectified linear units improve restricted Boltzmann machines. In: ICML-10 proceedings, pp 807–814
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: ICML’15 proceedings, pp 448–456
Szegedy C, Liu W, Jia Y et al (2015) Going deeper with convolutions. In: IEEE CVPR 2015 proceedings. IEEE, pp 1–9
Russakovsky O, Deng J, Su H et al (2015) ImageNet large scale visual recognition challenge. Int J Comput Vis 115(3):211–252. https://doi.org/10.1007/s11263-015-0816-y
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In: NIPS 2012 proceedings, pp 1097–1105
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: ICLR 2015 proceedings
Sandler M, Howard A, Zhu M et al (2018) MobileNetV2: inverted residuals and linear bottlenecks. In: IEEE CVPR 2018 proceedings, IEEE, pp 4510–4520
Huang G, Liu Z, van der Maaten L et al (2017) Densely connected convolutional networks. In: IEEE CVPR 2017 proceedings, IEEE, pp 2261–2269
Arlot S, Celisse A (2010) A survey of cross-validation procedures for model selection. Stat Surv 4:40–79. https://doi.org/10.1214/09-SS054
Chollet F et al (2015) Keras. https://keras.io
Abadi M, Barham P, Chen J et al (2016) TensorFlow: a system for large-scale machine learning. In: USENIX-OSDI 2016 proceedings, pp 265–283
Selvaraju RR, Cogswell M, Das A et al (2017) Grad-CAM: visual explanations from deep Networks via gradient-based localization. In: IEEE ICCV 2017 proceedings, IEEE, pp 618–626
Acknowledgements
Open Access funding provided by Projekt DEAL. The authors acknowledge support by the German Federal Ministry of Education and Research within the program “FH-Impuls” (Project SmartPro, subproject AddFunK, Grant no. 13FH4I04IA and subproject PreMo-LiB Grant no. 13FH4E03IA). On behalf of all authors, the corresponding author states that there is no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Baumgartl, H., Tomas, J., Buettner, R. et al. A deep learning-based model for defect detection in laser-powder bed fusion using in-situ thermographic monitoring. Prog Addit Manuf 5, 277–285 (2020). https://doi.org/10.1007/s40964-019-00108-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40964-019-00108-3