
Abstract
Background & Aim
Chronic kidney disease (CKD) is a heterogeneous disorder that affects the kidney structure and function. This study investigated the effect of the interaction between genetic factors and dietary pattern on kidney dysfunction in Korean adults.
Methods
Baseline data were obtained from the Ansan and Ansung Study of the Korean Genome and Epidemiology Study involving 8230 participants aged 40–69 years. Kidney dysfunction was defined as an estimated glomerular filtration rate < 90 mL/minute/1.73 m2. Genomic DNAs genotyped on the Affymetrix® Genome-Wide Human SNP array 5.0 were isolated from peripheral blood. A genome-wide association study using a generalized linear model was performed on 1,590,162 single-nucleotide polymorphisms (SNPs). To select significant SNPs, the threshold criterion was set at P-value < 5 × 10−8. Linkage disequilibrium clumping was performed based on the R2 value, and 94 SNPs had a significant effect. Participants were divided into two groups based on their generic risk score (GRS): the low-GR group had GRS > 0, while the high-GR group had GRS ≤ 0.
Results
Three distinct dietary patterns were extracted, namely, the “prudent pattern,” “flour-based and animal food pattern,” and “white rice pattern,” to analyze the effect of dietary pattern on kidney function. In the “flour-based and animal food pattern,” higher pattern scores were associated with a higher prevalence of kidney dysfunction in both the low and high GR groups (P for trend < 0.0001 in the low-, high-GR groups of model 1; 0.0050 and 0.0065 in the low-, high-GR groups of model 2, respectively).
Conclusions
The results highlight a significant association between the ‘flour-based and animal food pattern’ and higher kidney dysfunction prevalence in individuals with both low and high GR. These findings suggest that personalized nutritional interventions based on GR profiles may become the basis for presenting GR-based individual dietary patterns for kidney dysfunction.
Similar content being viewed by others

Introduction
Chronic kidney disease (CKD) is a major global health issue affecting millions of people worldwide, and its incidence continues to rise [1]. It is characterized by a gradual loss of kidney function over time, leading to the accumulation of toxic waste products in the body as well as other complications [2]. Kidney dysfunction is a significant risk factor for end-stage renal disease, cardiovascular disease, and premature death [3,4,5]. Identifying/detecting CKD development at an early stage is important as CKD potentially causes comorbidities, such as cardiovascular disease, as it progresses. The risk of developing cardiovascular disease is considerably high, even during the early stages of CKD [6], and the treatment of patients with cardiovascular risk factors is also known to be effective in attenuating early-stage CKD progression, which causes kidney dysfunction [7]. Consequently, identifying the risk factors for kidney dysfunction is critical for developing effective prevention and treatment strategies.
Certain risk factors for kidney dysfunction, including hypertension, diabetes mellitus, and obesity, have been identified; moreover, increasing evidence suggests that genetic factors may also play a role [8], including several single and polygenic causes [9, 10]. Genome-wide association studies (GWASs) have emerged as a powerful approach toward identifying genetic variants associated with complex diseases. A GWAS is a hypothesis-free study that analyzes millions of common genetic variants across the entire genome to identify those associated with disease risk [11]. It can identify common genetic variants with small-to-moderate effects on disease risk and potentially unravels the biological mechanisms underlying disease development [12]. One important GWAS application is the calculation of genetic risk scores (GRSs), which can estimate an individual’s overall genetic risk (GR) of developing a particular disease [13]. This highlights the importance of GWASs in identifying new GR factors for kidney dysfunction and developing personalized risk-prediction models.
Dietary intake is a well-established modifiable risk factor for CKD, and several dietary patterns have been associated with increased risk [14,15,16,17]. The use of dietary patterns instead of individual nutrients or food groups enables the evaluation of the combined effects of multiple nutrients and foods in the diet as well as the impact of their interactions [18, 19]. A healthy dietary pattern is associated with a lower CKD risk, whereas an unhealthy one, such as the Western dietary pattern, is associated with a higher CKD risk [20, 21]. However, genetic contributions to the effects of diet on CKD risk are yet to be fully elucidated. Therefore, investigating the interactions between genetic and dietary factors is essential for enhancing our understanding of the etiology of kidney dysfunction. An interaction analysis of genetic and dietary data can help identify individuals at the highest risk of CKD who may benefit the most from personalized dietary interventions [22]. This method potentially identifies interactions that are typically overlooked when examining each factor individually, providing a more comprehensive understanding of disease etiology. Interaction analyses require large sample sizes, such as a cohort, to detect significant interactions, and this can present a challenge for diseases [23].
Therefore, this study aimed to propose an appropriate GRS-based dietary pattern for kidney dysfunction in the Korean population. In addition, it sought to identify new GR factors and calculate GRSs for kidney dysfunction in a large, population-based cohort in Korea by cross-sectional analysis. Furthermore, it also investigated dietary patterns as well as the effect of the interactions between genetic and dietary factors on kidney dysfunction risk using both association and interaction analyses. This study’s findings may provide new insights into the etiology of kidney dysfunction in the Korean population and help develop personalized dietary recommendations for individuals at high risk of kidney dysfunction.
Materials and methods
Study design and population
Participants were recruited from the Ansan and Ansung Study of the Korean Genome and Epidemiology Study (KoGES) conducted from 2001 to 2002 to investigate common chronic diseases in Koreans by Korea Disease Control and Prevention Agency (KDCA). A total of 8230 Korean adults aged 40–69 years, including men (47.9%) and women (52.1%), were enrolled, and whole-genome single-nucleotide polymorphism (SNP) genotyping was performed. This study was performed to investigate the environmental and genetic causes of common diseases associated with kidney dysfunction. From the 10,030 participants, those without dietary intake and serum creatinine level data (n = 697) as well as those with serum creatinine levels outside the three-standard-deviation range from the mean value (n = 2) were excluded. Moreover, participants on CKD medication (n = 262), those with abnormal energy intake (< 500 or > 5000 kcal), those with a body mass index (BMI) > 50 kg/m2 (n = 373), and those with missing genotypic data (n = 466) were also excluded. In addition, participants with a history of CKD were excluded during the selection process. Thus, 8230 participants were finally included (Fig. 1). The data-use protocol was adopted from the KoGES (4851–302) and approved by the National Research Institute of Health, Centers for Disease Control and Prevention, Ministry of Health and Welfare, Republic of Korea.

Participants were selected from the Ansan and Ansung cohort of the KoGES study, starting with an initial pool of 10,030 individuals. Exclusions were made for missing dietary intake or serum creatinine data, history of CKD, extreme energy intake or BMI, and missing genotype data, resulting in a final sample of 8230 participants.
Definition of kidney dysfunction
CKD is classified into stages 1–5 based on the estimated glomerular filtration rate (eGFR), and this classification can evaluate kidney function, with the degree of kidney damage and decrease in function varying depending on the stage [24]. Moderate CKD is diagnosed based on the stage when the eGFR level is < 60 mL/min/1.73 m2. This study analyzed genetic and dietary effects on early stage of CKD, including stage 2, wherein kidney function begins to deteriorate. Stage 2 CKD is defined as an eGFR < 90 mL/min/1.73 m2 [25]. In this study, we specifically defined kidney dysfunction as an eGFR < 90 mL/min/1.73 m2, marking the onset of potential early-stage CKD [26]. We focused on the decline in eGFR as an indicator of kidney dysfunction and aim to explore the onset and progression of kidney dysfunction starting from these early stages, in order to identify potential early indicators and interventions for CKD. Serum creatinine levels were measured colorimetrically (Hitachi Automatic Analyzer 7600), and the eGFR was calculated using the Chronic Kidney Disease Epidemiology Collaboration equation [27]
For females, if the serum creatinine concentration (μmol/L [mg/dL]) was ≤ 62 (≤ 0.7),
For females, if the serum creatinine concentration (μmol/L [mg/dL]) was > 62 (> 0.7),
For males, if the serum creatinine concentration (μmol/L [mg/dL]) was ≤ 80 (≤ 0.9),
For males, if the serum creatinine concentration (μmol/L [mg/dL]) was > 80 (> 0.9),
GRS estimation
Genomic DNA was extracted from peripheral leukocytes drawn from Ansung and Ansan cohort participants. Genotyping was performed using Affymetrix® Genome-Wide Human SNP Array 5.0 (Affymetrix, Inc., Santa Clara, CA, USA). Through the KDCA, imputed data containing whole-genome information for the cohort was obtained. Markers were filtered for call rate, minor allele frequency (MAF), and the Hardy–Weinberg equilibrium by referring to the criteria applied in a previous study [28]. SNP imputation was performed using the IMPUTE program [29]. The imputation was based on NCBI build 35 and dbSNP build 126, and it initially included 90 individuals from JPT and CHB founders in HapMap as a reference (HapMap release 22). After removing SNPs with a MAF < 0.01 and an SNP missing rate > 0.05, Ansung and Ansan cohort SNPs were combined with 1.5 million imputed SNPs for association analyses with the selected quantitative trait.
A GWAS of the interaction between SNPs and kidney dysfunction was performed using the GCTA program tested by generalized linear association analysis after adjusting for sex as a fixed effect and age, BMI, hemoglobin A1c, and blood pressure as covariates using 1,590,162 SNPs [30]. The threshold criterion was set at P-value < 5 × 10–8 for SNPs from the GWAS. Linkage disequilibrium (LD) clumping and LD analysis were performed using the causal variants identified in the associated regions (CAVIAR) program to identify causal SNPs located in trait-associated regions [31]. SNP locations and nomenclature were defined using Ensembl 54. Each participant’s GRS was calculated using the 94 most strongly associated SNPs according to the following model [1]:
The beta values represent the effective size of increasing the GFR in each SNP. Therefore, a high or low GRS is associated with a high or low risk of developing low GFR levels, respectively. For the analysis, the low-GR group included participants with a GRS > 0, whereas the high-GR group included those with a GRS ≤ 0.
Covariates
This population’s general attributes were obtained via questionnaires as well as anthropometric and clinical measurements, such as height, weight, and BMI (weight [kg] ÷ height2 [m2]). Demographic data were categorized based on two cities (Ansan and Ansung); household income level (expressed as monthly income in Korean won [KRW], where 1 million KRW is approximately 750 United States dollars), which was categorized into three brackets (< 1 million, < 3 million, and > 3 million KRW); drinking habits (current drinker, past drinker, or non-drinker); smoking habits (current smoker, past smoker, or non-smoker); and daily physical activity (none, < 30 min, 30–60 min, 60–90 min, 90 min to 2 h, 2–3 h, 3–4 h, 4–5 h, or > 5 h). Physical activity was measured in metabolic equivalents (MET) [32], and based on the International Physical Activity Questionnaire (IPAQ), and participants were categorized into three groups based on the International Physical Activity Questionnaire (IPAQ): “low,” “moderate,” and “high” [33]. “High activity” individuals met specific criteria, which included engaging in vigorous-intensity activity on ≥ 3 days per week, resulting in a minimum of 1500 MET-min per week, or participating in ≥ 7 days of various activities, achieving a minimum of 3000 MET-min per week. The “moderate activity” group comprised individuals who met any of the following criteria: vigorous-intensity activity for ≥ 20 min per day on ≥ 3 days per week, engaging in moderate-intensity activity and/or walking for ≥ 30 min per day on ≥ 5 days per week, or participating in any combination of walking, moderate-intensity activity, and/or vigorous-intensity activity for ≥ 5 days per week, resulting in a total physical activity of ≥ 600 MET-min per week. Individuals who did not meet the criteria outlined above were classified in the “low activity” group.
Dietary assessment and dietary pattern analysis
Dietary intake was assessed using a food-frequency questionnaire to extract information regarding the average consumption frequencies and serving sizes of 103 food items [34]. For factor extraction, principal component analysis was applied, and for factor rotation, varimax rotation was employed. We identified and selected the initial 22 factors that had eigenvalues ≥ 1.4 (Supplementary Table 1). To construct the final factors, we specifically considered components that effectively accounted for a significant portion of the variance within each factor and exhibited factor loadings ≥ 0.3. By adhering to these criteria, we established a total of three dietary patterns and assigned them names based on the characteristic food groups they encompassed. To explore the relationship between these dietary patterns and kidney dysfunction, we divided the factor scores into tertiles, denoted as T1, T2, and T3. We calculated representative nutrient intake levels based on tertiles for each dietary pattern (Supplementary Table 3).
Statistical analysis
Statistical analyses were conducted using SAS software (version 9.4; SAS Institute, Inc.), and statistical significance was set at P-value < 0.05. Categorical data are expressed as the number of participants (%), while continuous data are presented as the mean ± standard deviation. Multivariable-adjusted logistic regression and joint interaction analyses were employed to determine the odds ratios (ORs) and 95% confidence intervals (CIs) of kidney dysfunction across the tertiles of each dietary factor and two GR groups, with adjustments made for covariates. Regression modeling was performed to analyze P-values for trends.
Results
Characteristics of the study population
The participants’ general characteristics based on the KoGES Ansung and Ansan cohort are described in Table 1. Participants were categorized into two GR groups. Those with high GR tended to have a lower eGFR (P-value < 0.0001) and household income (P-value < 0.0001) and were more likely to be current alcohol drinkers (P = 0.0034) and smokers (P = 0.0185).
GWAS of kidney dysfunction
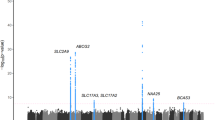
A total of 1,590,162 SNPs were utilized in the GWAS. The highest number of SNPs was found on human chromosome 1, while the lowest was observed on chromosome 19. On average, the SNPs located on each chromosome were approximately 1856.0 base pairs apart. Among the chromosomes, chromosome 19 had the widest interval between SNPs, while chromosome 6 had the narrowest. These details are summarized in Table 2. A GWAS was performed to identify significant loci related to kidney dysfunction. Quantile-quantile (Q-Q) plot and Manhattan plot for the genetic association were presented to visualize the distribution of observed P-values against the expected values (Fig. 2 and Supplementary Fig. 1). Among the 86,030 significant SNPs (P-value < 0.05), 109 were selected based on a P-value < 5 × 10−8. We identified 94 SNPs after screening for crucial effects on the GFR and calculted GRS on each participant. The odds ratio according to GR group is presented in Suppplementary Table 4. These SNPs were annotated on twenty chromosomes. Among them, the most significant SNPs with the highest absolute beta values were rs17071575 on chromosome 3 (beta value: −7.3) and rs12242220 on chromosome 10 (beta value: −7.6). These SNPs were annotated on the ADAMTS9 and WDFY4 genes. ADAMTS9 has been implicated in the pathogenesis of juvenile nephronophthisis and nephronophthisis, two pathological conditions [35]. Relevant ADAMTS9-associated biological pathways include those related to O-glycosylation of proteins and protein metabolism. Moreover, the function of WDFY4 is associated with its involvement in various cellular processes, including autophagy, endocytosis, and intracellular trafficking. Gene ontology (GO) enrichment analyses were performed with significant genes based on the GWAS results (Fig. 3). In terms of the biological process, ventricular septum morphogenesis was significantly enriched. Regarding cellular composition, cell surfaces were enriched, and tyrosine phosphatase activity was significantly enriched in molecular function. Moreover, enriched pathways for annotated genes were determined using the Kyoto Encyclopedia of Genes and Genomes database. In particular, the glycosaminoglycan biosynthesis–chondroitin sulfate/dermatan sulfate pathway was enriched.

The GWAS results for eGFR levels are shown, with –log10 P-values for SNPs plotted across all chromosomes. The red horizontal line indicates the genome-wide significance threshold of P-value < 5 × 10–8.

A Gene Ontology treemaps of biological processes, cell components, and molecular function according to significant genes. B Bar graph of Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways.
The interactive effects of dietary patterns and GR on kidney dysfunction prevalence
Three major dietary patterns were identified from the factor analysis, and they were named after foods or food groups with high factor-loading values (Fig. 4, Supplementary Table 2). The intake of energy, carbohydrates, proteins, and lipids increased with higher adherence to prudent, flour-based, and animal food patterns, while it decreased in the white rice pattern (all P-value < 0.0001) (Supplementary Table 3) and odds ratio for each dietary pattern is shown in Supplementary Table 5. The “prudent pattern” was characterized by a high consumption of vegetables, kimchi, fermented paste, sauce, seasoning, and mushroom. The “flour-based and animal food pattern” was typified by a high consumption of wheat flour and bread, eggs, fish, and shellfish. The “white rice pattern” featured highly positive factor loadings for white rice and negative factor loadings for whole grains.

A “Prudent pattern”, B “Flour-based and animal food pattern”, C “White rice pattern”. The dietary patterns were named based on the top food groups that had the highest factor-loading values.
The ORs and 95% CIs of kidney dysfunction across the interactions of dietary pattern tertiles with eGFR levels are presented in Table 3. The kidney dysfunction prevalence was analyzed based on alterations in the dietary pattern score at each GR level, and the lowest tertile (T1) at each GR level was used as the reference group. First, the highest “prudent pattern” tertile exhibited a significantly decreased kidney dysfunction prevalence compared with T1 in model 1 of the high-GR group (P for trend = 0.0332); however, this association attenuated after adjustments in model 2 (P for trend = 0.2152). Participants in the T2 and T3 “prudent pattern” tertiles of the low-GR group displayed a borderline decrease; nevertheless, it was not significant compared with that in T1 (P for trend = 0.0782 and 0.0840 in models 1 and 2, respectively). In the “flour-based and animal food pattern,” a higher pattern score was associated with a higher OR in the low- and high-GR groups of both models 1 and 2 (P for trend < 0.0001 in the low- and high-GR groups of model 1; P for trend = 0.0050 and 0.0065 in the low- and high-GR groups of model 2, respectively). In contrast, in the “white rice pattern” of the high-GR group, participants with the highest pattern scores had a significantly decreased kidney dysfunction prevalence compared with those in T1 of model 1 (P for trend < 0.0001); nonetheless, the association weakened after adjustments in model 2, and no significant interactions were observed (P for trend = 0.0775). Low-GR participants with T2 and T3 pattern scores exhibited an increased prevalence of kidney dysfunction; however, it was not significant compared with that of those in T1 (P for trend = 0.9413 and 0.0894 in models 1 and 2, respectively).
In the joint-effect model, with a low dietary pattern score and low GR as reference points, a high “prudent pattern” score and low GR were associated with the lowest prevalence of kidney dysfunction (OR: 0.899, 95% CI: 0.758–1.065, P for trend = 0.0840). The highest prevalence was observed in individuals with a low pattern score and high GR (OR: 1.608, 95% CI: 1.373–1.883, P for trend = 0.2152). In the “flour-based and animal food pattern,” the lowest prevalence was observed in low-GR individuals with T2 pattern scores (OR: 0.971 95%, CI: 0.82–1.148, P for trend = 0.0050), whereas the highest prevalence was noted in high-GR individuals with high pattern scores (OR: 2.061, 95% CI: 1.719–2.471, P for trend = 0.0065). In addition, in the “white rice pattern,” the lowest prevalence was observed in those with low pattern scores and low GR (reference group), while the highest prevalence was noted in those with low pattern scores and high GR (OR: 1.828, 95% CI: 1.560–2.142, P for trend 0.0775) (Table 4).
Discussion
Kidney dysfunction is a global public health concern with increasing prevalence, leading to complications like cardiovascular disease and end-stage kidney disease. This study investigates how genetic risk scores (GRSs) interact with dietary choices to influence kidney dysfunction risk in a Korean population, aiming to provide personalized dietary recommendations for prevention.
Genetic-variant identification and gene function associated with kidney dysfunction
GWAS analysis of genetic influence revealed that the final 94 SNPs were significantly related to renal function deterioration. Regarding genetic influence, the disease was not affected by a specific gene or loci, but by several genes.
Specifically, rs17071575 and rs12242220 (located on the ADAMTS9 and WDFY4 genes) on chromosomes 3 and 10, respectively, were the most significant SNPs with the highest absolute beta values in relation to kidney dysfunction. These findings are consistent with those of previous studies that also identified a link between these genes and kidney disease. Numerous studies have suggested that the WDFY4 gene plays a significant role in kidney dysfunction development as well as hypertension, which is a common risk factor for kidney dysfunction [36], and exerts a significant effect on kidney function and immune response [37, 38]. Moreover, the WDFY4 gene is reportedly involved in regulating the glomerular filtration barrier size in the kidneys, suggesting its crucial role in renal physiology [39, 40]. Furthermore, the ADAMTS9 gene is potentially involved in kidney dysfunction development. Several genetic association studies have found a significant association between ADAMTS9 polymorphisms and kidney function decline in different populations, including European, Chinese, and Japanese individuals [41, 42]. Furthermore, a GWAS identified ADAMTS9 as a novel genetic locus associated with kidney function in the general population [43]. ADAMTS9 reportedly regulates the extracellular matrix and cell signaling pathways, which serve crucial roles in renal physiology [44]. The ADAMTS9 gene has also been linked to hypertension, a common risk factor for kidney disease. These findings suggest that the WDFY4 and ADAMTS9 genes potentially play an essential role in kidney dysfunction pathogenesis and highlight the requirement for further investigation to elucidate the mechanisms underlying this relationship.
Kidney dysfunction prevalence according to dietary pattern
As several treatments for kidney-related diseases are diet-based, specific nutrient intake is also important; however, the strong association between the main dietary pattern and kidney dysfunction prevalence in Koreans bears significance. Koreans have been found to exhibit three main consumption patterns: the “prudent pattern,” “flour-based animal food pattern,” and “white rice pattern.”
The “prudent dietary pattern” is reportedly beneficial for people with kidney dysfunction in several ways. Adherence to a healthy dietary pattern, such as high fruit, vegetable, whole-grain, and low-fat dairy product intakes, has been associated with a lower risk of developing CKD in women [20]. Additionally, limiting dietary phosphorus and protein intakes by reducing the consumption of animal protein-source foods, such as meat, may help decelerate CKD progression [45]. A low-phosphorus diet reportedly alleviates CKD by reducing the levels of serum fibroblast growth factor 23, which is associated with CKD development and progression [46]. Concerning protein intake, debate regarding the optimal intake for people with kidney dysfunction persists. A low-protein diet (0.6 g of protein per kilogram of body weight per day) has been found to attenuate CKD progression in patients with moderate-to-severe kidney dysfunction [47]. However, other studies have suggested that a higher protein intake may be safe and even beneficial for some patients with kidney dysfunction. Evidently, the “prudent dietary pattern” can be helpful for people with kidney dysfunction.
The “flour-based animal food pattern” typically refers to a diet that is high in refined grains and processed meats, which are both associated with an increased risk of kidney dysfunction. Previous research has revealed an association between a higher intake of processed meats and a greater risk of developing CKD [48]. Excessive protein intake, particularly from animal sources, is potentially harmful to the kidneys and may contribute to CKD development or progression [49]. Additionally, a high sodium intake, which is common in flour- and animal-based foods, can increase blood pressure and exacerbate fluid retention, further compromising kidney function [50]. Previous studies have found that individuals with CKD who consume high-protein diets experience a faster decline in kidney function than those who consume low-protein diets [47]. Moreover, a diet high in animal protein has been associated with an increased risk of kidney stone formation [51]. Conversely, plant-based protein sources, such as legumes and tofu, are reportedly beneficial to kidney function. A low-protein, high-fiber diet that included plant-based protein sources was found to improve kidney function in individuals with CKD [52]. Therefore, the “flour-based animal food pattern” may not be the optimal dietary approach for individuals with kidney dysfunction. Instead, a diet that is low in animal-based protein and high in plant-based protein and fiber may be more beneficial for supporting kidney function.
Previous studies have established an association between the “white rice pattern,” characterized by a high intake of white rice, and increased CKD. Positive correlations exist between the frequency of white rice consumption and CKD incidence in Korean adults. A high intake of white rice potentially increases kidney dysfunction risk in Koreans. The high glycemic index (GI) of white rice has been suggested as a potential mechanism underlying the association between white rice consumption and kidney dysfunction. High GI foods potentially lead to a rapid increase in blood glucose and insulin levels, which may contribute to insulin resistance, inflammation, and oxidative stress, all of which are associated with kidney dysfunction [53].
Interactive effects of GR and dietary patterns on kidney dysfunction prevalence
Our study provides evidence that the prevalence of kidney dysfunction may be significantly influenced by the interactive effects of GR and dietary patterns. This finding is consistent with those of previous studies that have demonstrated how disease prevalence can be influenced by varying dietary intakes, depending on GRSs. For instance, higher-GR individuals who consume fried foods are more likely to have an increased BMI [54], while those with a higher GR for obesity who follow a healthy diet have a lower risk of weight gain [55]. This highlights the importance of personalized diets in reducing disease prevalence. Customized dietary interventions potentially reduce disease prevalence among individuals with specific GR profiles. It emphasizes the potential advantages of modifying dietary patterns based on an individual’s GR profile. This enables personalized nutritional interventions that enhance health outcomes in the prevention and management of kidney dysfunction. Our research has limitations as it focused on a specific population, which may affect result variations in different ethnic or demographic groups. Additionally, the dietary data collected were self-reported, which may introduce bias and inaccuracies. Furthermore, dietary patterns can vary over time, and our study captured only a snapshot of participants’ diets. However, recognizing these limitations, our study underscores the importance of considering dietary patterns in conjunction with genetic risk factors for personalized nutritional interventions that enhance health outcomes in the prevention and management of kidney dysfunction. Future studies should replicate our findings in diverse populations to improve generalizability. Exploring molecular pathways and gene-diet interactions can further enhance our understanding and allow for customized prevention strategies, ultimately transforming public health interventions for more effective kidney disease prevention.
Conclusion
Our study emphasizes the significant interaction between dietary patterns and genetic susceptibility, and kidney dysfunction. This study’s findings have significant implications for public health interventions targeted at mitigating the impact of kidney dysfunction. Encouraging healthier dietary patterns, particularly in individuals with a significant genetic predisposition, is a potentially effective approach toward preventing or managing kidney dysfunction. Additionally, evaluating genetic susceptibility can assist in the identification of individuals who may benefit the most from targeted dietary interventions.
Data availability
The datasets used and/or analyzed during the current study are owned by a third-party organization (The Korean Genome and Epidemiology Study–Ansan and Ansung Study, KoGES; 4851-302). These data have been availed by an online sharing service under the permission of the Division of Epidemiology and Health Index, Korea Centers for Disease Control and Prevention (KCDC). Further details are available in English on the following website: http://www.nih.go.kr/contents.es?mid=a50401010400#1.
References
Hill NR, Fatoba ST, Oke JL, Hirst JA, O’Callaghan CA, Lasserson DS, et al. Global prevalence of chronic kidney disease–a systematic review and meta-analysis. PloS one. 2016;11:e0158765.
Webster AC, Nagler EV, Morton RL, Masson P. Chronic kidney disease. Lancet. 2017;389:1238–52.
Gansevoort RT, Correa-Rotter R, Hemmelgarn BR, Jafar TH, Heerspink HJL, Mann JF, et al. Chronic kidney disease and cardiovascular risk: epidemiology, mechanisms, and prevention. Lancet. 2013;382:339–52.
Levey AS, Coresh J. Chronic kidney disease. Lancet. 2012;379:165–80.
Consortium CKDP. Association of estimated glomerular filtration rate and albuminuria with all-cause and cardiovascular mortality in general population cohorts: a collaborative meta-analysis. Lancet. 2010;375:2073–81.
Locatelli F, Pozzoni P. The importance of early detection of chronic kidney disease. Nephrol Dialysis Transpl. 2002;17:2–7.
Mann JF, Gerstein HC, Pogue J, Bosch J, Yusuf S, Investigators H. Renal insufficiency as a predictor of cardiovascular outcomes and the impact of ramipril: the HOPE randomized trial. Ann Intern Med. 2001;134:629–36.
Barbour SJ, Er L, Djurdjev O, Karim M, Levin A. Differences in progression of CKD and mortality amongst Caucasian, Oriental Asian and South Asian CKD patients. Nephrol Dialysis Transplant. 2010;25:3663–72.
Böger CA, Gorski M, Li M, Hoffmann MM, Huang C, Yang Q, et al. Association of eGFR-related loci identified by GWAS with incident CKD and ESRD. PLoS Genet. 2011;7:e1002292.
Qiu C, Huang S, Park J, Park Y, Ko Y-A, Seasock MJ, et al. Renal compartment–specific genetic variation analyses identify new pathways in chronic kidney disease. Nat Med. 2018;24:1721–31.
Visscher PM, Brown MA, McCarthy MI, Yang J. Five years of GWAS discovery. Am J Hum Genet. 2012;90:7–24.
Köttgen A. Genome-wide association studies in nephrology research. Am J Kidney Dis. 2010;56:743–58.
Khera AV, Chaffin M, Aragam KG, Haas ME, Roselli C, Choi SH, et al. Genome-wide polygenic scores for common diseases identify individuals with risk equivalent to monogenic mutations. Nat Gen. 2018;50:1219-24.
Rebholz CM, Crews DC, Grams ME, Steffen LM, Levey AS, Miller ER III, et al. DASH (Dietary Approaches to Stop Hypertension) diet and risk of subsequent kidney disease. Am J Kidney Dis. 2016;68:853–61.
Ko GJ, Obi Y, Tortoricci AR, Kalantar-Zadeh K. Dietary protein intake and chronic kidney disease. Curr Opin Clin Nutr Metab Care. 2017;20:77.
Uribarri J, editor Phosphorus homeostasis in normal health and in chronic kidney disease patients with special emphasis on dietary phosphorus intake. Semin Dialysis. 2007;20:295–301.
Krishnamurthy VMR, Wei G, Baird BC, Murtaugh M, Chonchol MB, Raphael KL, et al. High dietary fiber intake is associated with decreased inflammation and all-cause mortality in patients with chronic kidney disease. Kidney Int. 2012;81:300–6.
Khera AV, Chaffin M, Wade KH, Zahid S, Brancale J, Xia R, et al. Polygenic prediction of weight and obesity trajectories from birth to adulthood. Cell. 2019;177:587–96.e9.
McCullough ML, Feskanich D, Stampfer MJ, Giovannucci EL, Rimm EB, Hu FB, et al. Diet quality and major chronic disease risk in men and women: moving toward improved dietary guidance. Am J Clin Nutr. 2002;76:1261–71.
Hu EA, Pan A, Malik V, Sun Q. White rice consumption and risk of type 2 diabetes: meta-analysis and systematic review. Bmj. 2012;344:e1454.
Yang Q, Zhang Z, Kuklina EV, Fang J, Ayala C, Hong Y, et al. Sodium intake and blood pressure among US children and adolescents. Pediatrics. 2012;130:611–9.
Moore JH, Williams SM. Traversing the conceptual divide between biological and statistical epistasis: systems biology and a more modern synthesis. Bioessays. 2005;27:637–46.
Cordell HJ. Detecting gene–gene interactions that underlie human diseases. Nat Rev Genet. 2009;10:392–404.
Levey AS, De Jong PE, Coresh J, Nahas ME, Astor BC, Matsushita K, et al. The definition, classification, and prognosis of chronic kidney disease: a KDIGO Controversies Conference report. Kidney Int. 2011;80:17–28.
Rule AD, Larson TS, Bergstralh EJ, Slezak JM, Jacobsen SJ, Cosio FG. Using serum creatinine to estimate glomerular filtration rate: accuracy in good health and in chronic kidney disease. Ann Intern Med. 2004;141:929–37.
Navise NH, Mokwatsi GG, Gafane-Matemane LF, Fabian J, Lammertyn L. Kidney dysfunction: prevalence and associated risk factors in a community-based study from the North West Province of South Africa. BMC Nephrol. 2023;24:23.
Levey AS, Stevens LA, Schmid CH, Zhang Y, Castro AF III, Feldman HI, et al. A new equation to estimate glomerular filtration rate. Ann Intern Med. 2009;150:604–12.
Cho YS, Go MJ, Kim YJ, Heo JY, Oh JH, Ban H-J, et al. A large-scale genome-wide association study of Asian populations uncovers genetic factors influencing eight quantitative traits. Nat Genet. 2009;41:527–34.
Marchini J, Howie B, Myers S, McVean G, Donnelly P. A new multipoint method for genome-wide association studies by imputation of genotypes. Nat Genet. 2007;39:906–13.
Yang J, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet. 2011;88:76–82.
Hormozdiari F, Kostem E, Kang EY, Pasaniuc B, Eskin E, editors. Identifying causal variants at loci with multiple signals of association. Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics. 2014:610-11.
Jetté M, Sidney K, Blümchen G. Metabolic equivalents (METS) in exercise testing, exercise prescription, and evaluation of functional capacity. Clin Cardiol. 1990;13:555–65.
Committee IR. Guidelines for data processing and analysis of the International Physical Activity Questionnaire (IPAQ)-short and long forms. http://www.ipaq.ki.se/scoring.pdf. 2005.
Ahn Y, Kwon E, Shim J, Park M, Joo Y, Kimm K, et al. Validation and reproducibility of food frequency questionnaire for Korean genome epidemiologic study. Eur J Clin Nutr. 2007;61:1435–41.
Choi YJ, Halbritter J, Braun DA, Schueler M, Schapiro D, Rim JH, et al. Mutations of ADAMTS9 cause nephronophthisis-related ciliopathy. Am J Hum Genet. 2019;104:45–54.
Kottgen A, Pattaro C, Boger CA, Fuchsberger C, Olden M, Glazer N, et al. New loci associated with kidney function and chronic kidney disease. Nat Genet. 2010;42:376–U34.
Glorieux G, Mullen W, Duranton F, Filip S, Gayrard N, Husi H, et al. New insights in molecular mechanisms involved in chronic kidney disease using high-resolution plasma proteome analysis. Nephrol Dialysis Transplant. 2015;30:1842–52.
Della-Morte D, Pacifici F, Rundek T. Genetic susceptibility to cerebrovascular disease. Curr Opin Lipidol. 2016;27:187.
Eknoyan G, Lameire N, Eckardt K, Kasiske B, Wheeler D, Levin A, et al. KDIGO 2012 clinical practice guideline for the evaluation and management of chronic kidney disease. Kidney int. 2013;3:5–14.
Yasuda K, Miyake K, Horikawa Y, Hara K, Osawa H, Furuta H, et al. Variants in KCNQ1 are associated with susceptibility to type 2 diabetes mellitus. Nat Genet. 2008;40:1092–7.
Guo Y, Tan L-J, Lei S-F, Yang T-L, Chen X-D, Zhang F, et al. Genome-wide association study identifies ALDH7A1 as a novel susceptibility gene for osteoporosis. PLoS Genet. 2010;6:e1000806.
Parsa A, Kao WL, Xie D, Astor BC, Li M, Hsu C-y, et al. APOL1 risk variants, race, and progression of chronic kidney disease. N. Engl J Med. 2013;369:2183–96.
Teumer A, Tin A, Sorice R, Gorski M, Yeo NC, Chu AY, et al. Genome-wide association studies identify genetic loci associated with albuminuria in diabetes. Diabetes. 2016;65:803–17.
Parsa A, Kanetsky PA, Xiao R, Gupta J, Mitra N, Limou S, et al. Genome-wide association of CKD progression: the chronic renal insufficiency cohort study. J Am Soc Nephrol. 2017;28:923–34.
D’Alessandro C, Piccoli GB, Cupisti A. The “phosphorus pyramid”: a visual tool for dietary phosphate management in dialysis and CKD patients. BMC Nephrol. 2015;16:1–6.
Musgrove J, Wolf M. Regulation and effects of FGF23 in chronic kidney disease. Annu Rev Physiol. 2020;82:365–90.
Klahr S, Levey AS, Beck GJ, Caggiula AW, Hunsicker L, Kusek JW, et al. The effects of dietary protein restriction and blood-pressure control on the progression of chronic renal disease. N. Engl J Med. 1994;330:877–84.
Mafra D, Borges NA, de Franca Cardozo LFM, Anjos JS, Black AP, Moraes C, et al. Red meat intake in chronic kidney disease patients: two sides of the coin. Nutrition. 2018;46:26–32.
Brenner BM, Meyer TW, Hostetter TH. Dietary protein intake and the progressive nature of kidney disease: the role of hemodynamically mediated glomerular injury in the pathogenesis of progressive glomerular sclerosis in aging, renal ablation, and intrinsic renal disease. N. Engl J Med. 1982;307:652–9.
Institute of Medicine. Sodium intake in populations: assessment of evidence. National Academies Press: Washington, DC. 2013.
Taylor EN, Stampfer MJ, Curhan GC. Dietary factors and the risk of incident kidney stones in men: new insights after 14 years of follow-up. J Am Soc Nephrol. 2004;15:3225–32.
Garneata L, Stancu A, Dragomir D, Stefan G, Mircescu G. Ketoanalogue-supplemented vegetarian very low–protein diet and CKD progression. J Am Soc Nephrol. 2016;27:2164–76.
Shin S, Kim H. The effect of sitagliptin on cardiovascular risk profile in Korean patients with type 2 diabetes mellitus: a retrospective cohort study. Ther Clin Risk Manag. 2016;12:435–44.
Qi Q, Chu AY, Kang JH, Huang J, Rose LM, Jensen MK, et al. Fried food consumption, genetic risk, and body mass index: gene-diet interaction analysis in three US cohort studies. BMJ. 2014;348:g1610.
Wang T, Heianza Y, Sun D, Huang T, Ma W, Rimm EB, et al. Improving adherence to healthy dietary patterns, genetic risk, and long term weight gain: gene-diet interaction analysis in two prospective cohort studies. BMJ. 2018;360:j5644.
Acknowledgements
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2018R1A6A1A03025159).
Author information
Authors and Affiliations
Contributions
All the authors participated in the writing of the manuscript. Min-Jae Jang: Formal analysis, Original draft preparation, Review, and Editing. Li-Juan Tan: Methodology and Review. Min Young Park: Review and Editing. Sangah Shin: Conceptualization, Methodology, Review, Editing, and Supervision. Jun-Mo Kim: Conceptualization, Methodology, Review, Editing, Supervision, and Project administration.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and consent to participate
This study was conducted in accordance with the Declaration of Helsinki. The protocol of the current study was approved by the Institutional Review Board (IRB) of Chung-Ang University (IRB no. 1041078-201908-HRBR-239-01). Written informed consent was obtained from all participants prior to their inclusion in the study. No identifiable images or other personal data of participants are included in this publication.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jang, MJ., Tan, LJ., Park, M.Y. et al. Identification of interactions between genetic risk scores and dietary patterns for personalized prevention of kidney dysfunction in a population-based cohort. Nutr. Diabetes 14, 62 (2024). https://doi.org/10.1038/s41387-024-00316-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41387-024-00316-z
- Springer Nature Limited