
Abstract
A neutrosophic statistic is a random variable and it has a neutrosophic probability distribution. So, in this paper, we introduce the new neutrosophic Birnbaum–Saunders distribution. Some statistical properties are derived, using Mathematica 13.1.1 and R-Studio Software. Two different estimation methods for parameters estimation are introduced for new distribution: maximum likelihood estimation method and Bayesian estimation method. A Monte-Carlo simulation study is used to investigate the behavior of parameters estimates of new distribution, compare the performance of different estimates, and compare between our distribution and the classical version of Birnbaum–Saunders. Finally, study the validity of our new distribution in real life.
Similar content being viewed by others

Introduction
Normal distribution is considered the most distribution used in our real life. Many new distributions are derived from normal distribution using different transformations. Two parameter Birnbaum–Saunders (BS) distribution is considered one of these distributions. 1introduced the BS distribution as a statistical model for fatigue life of structures under cyclic stress. In the recent years the BS distribution is used in many fields to its theoretical arguments associated with cumulative damage processes, its properties, and its relationship with the normal distribution. BS distribution is unimodal, positively skewed also it investigated for applications in engineering by many authors see2,3,4,5. Also, BS distribution has many applications in other fields such as business, environment and medicine see 6,7,8,9,10,11,12,13,14,15,16,17,18,19. Also, the BS distribution can be obtained as an approximation of inverse Gaussian (IG) distribution see20, it can see equal mixture of an inverse Gaussian and its reciprocal see21, Many statistical properties of BS distribution is studied by many authors such that probability density function pdf, hazard function (hf) because it plays an important role in lifetime data see22,23,24,25.
Definition 1:
A random variable \(X\) is said to be Birnbaum–Saunders distribution with shape parameter \(\alpha >0\), scale parameter \(\beta >0\) and denoted by \(X\sim BS(\alpha ,\beta )\), if the probability density function (pdf) and the cumulative distribution (cdf) of \(X\) are defined as follows respectively.
where, \(Erf\) is the error function.
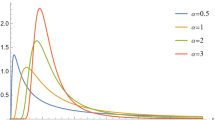
Figure 1 shows the pdf of \(BS(\alpha ,\beta )\) for different values of shape parameter \(\alpha \) we can the BS distribution is unimodal distribution. Also, Fig. 2 shows the cdf of \(BS(\alpha ,\beta )\) for different values shape parameter \(\alpha \). Two Figures show the changes in the distribution curve when the shape parameter takes different values.

The pdf of \(BS(\alpha ,\beta )\) for different values of shape parameter \(\alpha \).

The cdf of \(BS(\alpha ,\beta )\) for different values of shape parameter \(\alpha \).
The hazard function of BS distribution is defined as,
Figure 3 shows the hf of \(BS(\alpha ,\beta )\) for different values of shape parameter \(\alpha .\) The Figure shows the changes in the distribution curve when the shape parameter takes different values.

The hf of \(BS(\alpha ,\beta )\) for different values of shape parameter \(\alpha .\)
The main reason of choosing BS distribution as a fatigue failure life distribution by 1 is known that for the analysis fatigue data used any two-parameter distribution such as Weibull, log-normal and gamma distributions. For importance of BS distribution, we proposed in this paper a new distribution called neutrosophic Birnbaum–Saunders distribution and denoted by \(NBS({\alpha }_{N},{\beta }_{N}). NBS(\alpha ,\beta )\). In the literature of neutrosophic statistics, the start work in neutrosophic statistics is introduced by 26 when he showed that the neutrosophic logic is more efficient than fuzzy logic. Also, Smarandache27 present the neutrosophic statistics and showed also it is more efficient than classical statistics. Neuterosophic statistics is considered as the generalized of classical statistics and it is reduced to classical statistics when imprecise observations in the data. For the efficient of neutrosophic statistics see also28,29,30. Many authors introduced the neutrosophic probability distributions such as Poisson, exponential, binomial, normal, uniform, Weibull and so on see27,31,32,33,34,35 introduced the neutrosophic queueing theory in stochastic modeling.36,37 and38 investigated the neutrosophic time series. Recently, many authors studied the neutrosophic random variables see39,40 inserted the new notions on neutrosophic random variables. Granados and Sanabria41 studied independence neutrosophic random variables. Neutrosophic has many applications in many fields such as decision making, machine learning, intelligent disease diagnosis, communication services, pattern recognition, social network analysis and e-learning systems, physics, sequences spaces and so on for more details see27,42,43,44,45,46,47,48,49,50,51 and52. This paper is organized as follows, in section “Neutrosophic Birnbaum–Saunders distribution and its statistical properties”, we introduce the new distribution \(NBS({\alpha }_{N},{\beta }_{N})\). and derived its statistical properties. In section “Parameter estimation”, Bayesian and non-Bayesian estimation methods are discussed to estimate the parameters of new distribution. In section “Simulation and comparative study”, the Monte-Carlo simulation and comparative study is performed to investigate the behavior of different estimates for the parameters of our distribution and compare between different estimates of parameters of new distribution. In section “Comparative study using real application”, real life data analysis is introduced. Finally, in section “Conclusion”, the conclusion of our study is introduced.
Neutrosophic Birnbaum–Saunders distribution \(NBS({\alpha }_{N},{\beta }_{N})\). and its statistical properties
In this section, we introduce the new distribution which called neutrosophic Birnbaum–Saunders distribution and denoted by \(NBS({\alpha }_{N},{\beta }_{N})\). where \(\alpha \) is a shape parameter and \(\beta \) is the scale parameter. We use Mathematica 13.1 in all calculations in this section, for more details see53.
Definition 2:
(The neutrosophic probability density function and neutrosophic cumulative distribution function of \(NBS({\alpha }_{N},{\beta }_{N})\))
Let \({I}_{N}\in ({I}_{L},{I}_{U})\) be an indeterminacy interval, where \(N\) is the neutrosophic statistical number and let \({X}_{N}={X}_{L}+{X}_{U} {I}_{N}\) be a random variable following neutrosophic Birnbaum–Saunders with scale parameter \({\beta }_{N}\) and shape parameter \({\alpha }_{N}\). If the neutrosophic probability density function \((npdf\)) and neutrosophic cumulative distribution function \((ncdf)\) are defined as follows respectively,
Note that, the neutrosophic distribution go to the classical distribution when \({I}_{N}=0\). Figures 4 and 5 show \(npdf\) and \(ncdf\) for different values of \({\alpha }_{N}\) and \({\beta }_{N}.\) Two show the changes in the distribution curve when the shape parameter takes different values. Also we can see the effect of indeterminacy parameter on curves.

The \(npdf\) for different values of \({\alpha }_{N}\) and \({\beta }_{N}\).

The \(ncdf\) for different values of \({\alpha }_{N}\) and \({\beta }_{N}\).
Definition 3:
(The neutrosophic reliability function and neutrosophic hazard function of \(NBS({\alpha }_{N},{\beta }_{N})\))
The neutrosophic reliability function of \({X}_{N}\) is a random variable following neutrosophic Birnbaum–Saunders with scale parameter \({\beta }_{N}\) and shape parameter \({\alpha }_{N}\) is defined as,
and the neutrosophic hazard function of \({X}_{N}\) is defined as,
and denoted by \(nhf\). Figure 6 shows the \(nhf\) for different values of \({\alpha }_{N}\) and \({\beta }_{N}.\) The Figure show the changes in the distribution curve when the shape parameter takes different values. Also we can see the effect of indeterminacy parameter on curves.

The nhf for different values of \({\alpha }_{N}\) and \({\beta }_{N}\).
Now,we discuss some statistical properties of new proposed distribution \(NBS({\alpha }_{N},{\beta }_{N})\) such as mode, median, moments, moment generating function, quantile function, order statistics, entropy.
I. Mode:
To find the mode of neutrosophic Birnbaum- Saunders distribution solve the following nonlinear equation with respect to \({x}_{N}\),
Then, the mode at \({x}_{N}={\text{Root}}[-1+(-{\beta }_{N}+3{{\alpha }_{N}}^{2}\beta )\#1+({{\beta }_{N}}^{2}+{{\alpha }_{N}}^{2}{{\beta }_{N}}^{2}){\#1}^{2}+{{\beta }_{N}}^{3}{\#1}^{3}\&,1]\)
Where, \(0<{\alpha }_{N}<{\text{Root}}[-64+64{\#1}^{2}-92{\#1}^{4}+9{\#1}^{6}\&,\mathrm{2,0}]\&\&{\beta }_{N}>0)||({\text{Root}}[-64+64{\#1}^{2}-92{\#1}^{4}+9{\#1}^{6}\&,\mathrm{1,0}]<{\alpha }_{N}<0\&\&{\beta }_{N}>0)||{\beta }_{N}<0\).
When \({\alpha }_{N}=1.5, \beta =2\) then \({x}_{N}=0.0794\).
II. Median
The median of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by.
When \({\alpha }_{N}=1.5, {\beta }_{N}=2, { I}_{N}=0.2\) then \(m=(\mathrm{0.3651,0.6846})\).
III. r-th moments of origin
The r-th moments of origin of \(NBS({\alpha }_{N},{\beta }_{N})\) is defined as
IV. Mean
The mean of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by,
V. Variance
The Variance of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by.
VI. Moment generating function
The moment generating function of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by,
VII. Characteristic function
The characteristic function of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by,
where \(i=\sqrt{-1}\).
VIII. Cumulant generating function
The cumulant generating function of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by.
where \(i=\sqrt{-1}.\)
IX. Quantile function
The quantile function of \(NBS({\alpha }_{N},{\beta }_{N})\) is given by.
where, \(k^{2} = {\text{InverseErf}}\left[ {\frac{{2 P - 1 - I_{N} }}{{1 + I_{N} }}} \right]^{2}\).
X. Order statistics
For given any random variables \({X}_{N1}\dots {X}_{NN}\), the order statistics. \({X}_{N(1)}\dots {X}_{N(N)}\) are also random variables, defined by sorting the values of \({X}_{N1}\dots {X}_{NN}\) in increasing order. For a random sample \({X}_{N(1)}\dots {X}_{N(N)}\) the npdf \({f}_{{X}_{N}\left(r\right)}\left({x}_{N}\right)\) and ncdf \({F}_{{X}_{N}\left(r\right)}\left({x}_{N}\right)\) are defined as follows:
XI. Entropy
Entropy is considered one of the most popular measures of uncertainty.54 introduced the differential entropy \(H(X)\) as follows:
Rényi55 introduced Renyi entropy which finds its source in the information theory. He defined the Renyi entropy as follow:
Where, \(\delta \ne 1\) and \(\delta >0.\)
Tsallis56 introduced q-entropy which comes from statistical physics. He defined the q-entropy as follows:
Where, \(q\ne 1\) and \(q>0.\) Now, the three entropies are defined for \(NBS({\alpha }_{N},{\beta }_{N})\) as follows:
\(\begin{aligned} I_{\delta } \left( {X_{N} } \right) & = \frac{1}{1 - \delta }Log\left[ {k^{\delta } \mathop \sum \limits_{c = 0}^{\delta } \left( {\begin{array}{*{20}c} \delta \\ c \\ \end{array} } \right) \frac{{\beta_{N}^{c} }}{{\sqrt {2\pi } \alpha_{N} \sqrt {\beta_{N} } }}\left( {{\text{exp}}\left( {2/\alpha_{N}^{2} } \right)\left( {\frac{{\beta_{N} }}{{\alpha_{N}^{2} }}} \right)^{{\frac{1}{4}\left( { - 1 - 2c + 3\delta } \right)}} \left( {\alpha_{N}^{2} \beta_{N} } \right)^{{\frac{1}{4}\left( { - 1 - 2c + 3\delta } \right)}} } \right.} \right. \\ & \quad \left. {\left. {\left( {\beta {\text{BesselK}}\left[ {\frac{1}{2}\left( { - 1 - 2c + 3\delta } \right),\frac{{2\sqrt {\frac{{\beta_{N} }}{{\alpha_{N}^{2} }}} }}{{\sqrt {\alpha_{N}^{2} \beta_{N} } }}} \right] + \sqrt {\frac{{\beta_{N} }}{{\alpha_{N}^{2} }}} \sqrt {\alpha_{N}^{2} \beta_{N} } {\text{BesselK}}\left[ {\frac{1}{2}\left( {1 - 2c + 3\delta } \right),\frac{{2\sqrt {\frac{{\beta_{N} }}{{\alpha_{N}^{2} }}} }}{{\sqrt {\alpha_{N}^{2} \beta_{N} } }}} \right]} \right)\left( {1 + I_{N} } \right)} \right)} \right] \\ \end{aligned}\)where, \(k=\frac{1+{I}_{N}}{2 {\alpha }_{N} \sqrt{2 {\beta }_{N} \pi }}.\)
where, \(k=\frac{1+{I}_{N}}{2 {\alpha }_{N} \sqrt{2 {\beta }_{N} \pi }}.\)
Parameter estimation
In this section, maximum likelihood and Bayesian estimation methods were used to estimate the parameters of our new proposed distribution neutrosophic Birnbaum–Saunders distribution.
Maximum likelihood estimation method
Let \({X}_{N1}\dots {X}_{Nn}\) be a random sample from \(NBS({\alpha }_{N},{\beta }_{N})\). Then the likelihood function is given by.
\(\begin{aligned} L\left( {x_{Ni} ;\alpha_{N} ,\beta_{N} } \right) & = \mathop \prod \limits_{i = 1}^{n} f\left( {x_{Ni} ;\alpha_{N} ,\beta_{N} } \right). \\ & = \mathop \prod \limits_{i = 1}^{n} \frac{{\left( {1 + I_{N} } \right)}}{{2 \alpha_{N} \sqrt {2 \pi x_{Ni}^{3} } }} \left( {1 + \beta_{N} x_{Ni} } \right)\exp \left( {\frac{{ - \left( {\beta_{N} x_{Ni} - 1} \right)^{2} }}{{2 \alpha_{N}^{2} \beta_{N} x_{Ni} }}} \right), \\ \end{aligned}\)
and its corresponding log-likelihood function is given by,
Now get the derivatives of log-likelihood function with respect to \({\alpha }_{N}\) and \({\beta }_{N}\) to get the maximum likelihood estimates for \({\alpha }_{N}\) and \({\beta }_{N}\) which denoted by \({\widehat{\alpha }}_{N}\) and \({\widehat{\beta }}_{N}\) as follows:
Normal equations can’t solve analytic. So, we can’t get the closed form for \({\widehat{\alpha }}_{N}\) and \({\widehat{\beta }}_{N}\). Hence, numerical method is used to solve these equations. Since the maximum likelihood estimates for unknown parameters of new proposed distribution \({\widehat{\alpha }}_{N}\) and \({\widehat{\beta }}_{N}\) can’t get in closed form, so the exact distributions of these parameters not derived, so we derive the asymptotic confidence intervals of these parameters. For large sample and \({\alpha }_{N}>0\) and \({\beta }_{N}>0\). The \({\widehat{\alpha }}_{N}\) and \({\widehat{\beta }}_{N}\) are bivariate normal distribution with the mean \({\alpha }_{N}\) and \({\beta }_{N}\) and covariance matrix \({I}_{n}^{-1}\). Where \({I}_{n}^{-1}\) is the inverse of information matrix, where,
For more details see57. Now the \(100\left(1-\gamma \right)\%\) confidence interval of parameters \({\alpha }_{N}\) and \({\beta }_{N}\) are \({\widehat{\alpha }}_{N}\pm {z}_{\gamma /2}\sqrt{Var({\widehat{\alpha }}_{N})}\) and \({\widehat{\beta }}_{N}\pm {z}_{\gamma /2}\sqrt{Var({\widehat{\beta }}_{N})}\) respectively.
Bayesian estimation method
The Bayes estimation using MCMC technique is used to estimate the unknown parameters of new proposed distribution \(NBS({\alpha }_{N},{\beta }_{N})\). For more details of MCMC technique using Gibb sampling procedure see58,59. Also, for more details of MCMC technique using Metropolis Hasting (MH) method see60 and61. The two methods are used to generate samples from the posterior density function to compute point Bayes estimators for unknown parameters and construct credible intervals. For this aim, we suppose that independent gamma prior distributions for unknown parameters of new proposed distribution \(NBS({\alpha }_{N},{\beta }_{N})\) as follows:
In this case the joint prior distribution of \({\alpha }_{N}\) and \({\beta }_{N}\) is given by,
And the joint posterior is given by,
Under square error loss the Bayes estimates of \({\alpha }_{N}\) and \({\beta }_{N}\) are given by.
These estimates can’t be computed analytically. So, we use MCMC method using MH technique to get the \({\alpha }_{N}^{B}\) and \({\beta }_{N}^{B}\) as follows:
-
i.
Choose initial values of \({\alpha }_{N}^{(0)}\) and \({\beta }_{N}^{(0)}.\)
-
ii.
Suppose the values of \({\alpha }_{N}\) and \({\beta }_{N}\) at the kth step by \({\alpha }_{N}^{(k)}\) and \({\beta }_{N}^{(k)}.\)
-
iii.
Generate \({\alpha }_{N}^{(k)}\) using \({\pi }^{*}\left({\alpha }_{N}\left|{\beta }_{N}^{(k-1)},{X}_{N}\right.\right)\) and \({\pi }^{*}\left({\beta }_{N}\left|{{\alpha }_{N}^{(k-1)},X}_{N}\right.\right)\) respectively.
-
iv.
Repeat step 3 N-times.
-
v.
Compute Bayes estimates of \({\alpha }_{N}\) and \({\beta }_{N}\) as follows:
$$ \alpha_{N}^{B} = \frac{1}{N - B} \mathop \sum \limits_{k = B + 1}^{N} \alpha_{N}^{\left( k \right)} ,\beta_{N}^{B} = \frac{1}{N - B} \mathop \sum \limits_{k = B + 1}^{N} \beta_{N}^{\left( k \right)} , $$where \(B\) is the burn-in period.
-
vi
Compute \(\left(100-\gamma \right)\%\) HPD credible intervals for \({\alpha }_{N}\) and \({\beta }_{N}\) as follows:
$$ \left( {\alpha_{{N\left( {\frac{\gamma }{2}} \right)}} ,\alpha_{{N\left( {1 - \frac{\gamma }{2}} \right)}} } \right),\left( {\beta_{{N\left( {\frac{\gamma }{2}} \right)}} ,\beta_{{N\left( {1 - \frac{\gamma }{2}} \right)}} } \right). $$
Note that we use R-Studio Software to get results in this section using many packages such that, nlme, MASS, coda, mcmc, distr, VGAM and RCPP.
Simulation and comparative study
In this section, we perform Monte-Carlo simulation study to investigate the behavior of two different estimators for parameters of new proposed distribution \(NBS({\alpha }_{N},{\beta }_{N})\) maximum likelihood estimators and Bayesian estimates according to different sample sizes, different start values of \({\alpha }_{N}\) and \({\beta }_{N}\) and different indeterminacy measure. Also, we introduce comparative study to compare between maximum likelihood estimates (MLE’s) and Bayesian estimates to get the best for parameters of new proposed distribution \(NBS({\alpha }_{N},{\beta }_{N})\). Compare between classical and neutrosophic version of BS distribution to show the flexibility of neutrosophic version. Finally, compare Bayesian estimates for different prior distributions. For the aim of comparative study, we use bias and mean square error (MSE) to compare between different point estimators. Use also the Akaike information criterion (AIC) to compare maximum likelihood estimator for classical and neutrosophic version but use asymptotic confidence length (ACL) to compare between different interval estimators. Now we perform these studies according to the following steps:
-
i.
Choose the different initial values of \(\left({\alpha }_{N},{\beta }_{N}\right)=\left(\mathrm{1.25,3}\right), \left(\mathrm{0.5,3}\right), \left(\mathrm{1,3}\right).\)
-
ii.
For Bayesian estimators choose different values of the parameter for gamma prior follows \(\left(a,b\right)=\left(\mathrm{1,2}\right), \left(\mathrm{1,1}\right), (\mathrm{2,1})\).
-
iii.
Use two indeterminacy measure \({I}_{N}=\left(\mathrm{0.2,0.5}\right), (\mathrm{0.6,0.8})\). Note that when \({I}_{N}=0\), the classical version of Birnbaum Saunders is obtained.
-
iv.
Generate different sample sizes \(n=50, 100, 200, 500.\)
-
v.
Find point estimators using maximum likelihood estimation method and Bayesian estimation method.
-
vi.
Calculate asymptotic confidence interval and credible interval.
-
vii.
Perform the comparative study by calculating bias, MSE and AIC to compare MLE’s in both cases classical and neutrosophic version of BS distribution, calculating bias, MSE for comparing MLE’s and Bayesian estimates in both cases classical and neutrosophic version of BS distribution. And use ACL for comparing interval estimation.
All calculations in this section we use R package For more details about R-Package see62. Results of simulation and comparative study between our new proposed distribution neutrosophic Birnbaum–Saunders distribution and its classical version Birnbaum–Saunders distribution are shown in Tables 1, 2, 3, 4, 5 and 6 which get using R-Studio Software. From These Tables, we get, Tables 1 and 2 shown bias’s, MSE’s and AIC for MLE’s for \({\text{BS}}(\mathrm{\alpha },\upbeta )\) and \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) respectively, we get \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has smaller bias’s, MSE’s and AIC than \({\text{BS}}\left(\mathrm{\alpha },\upbeta \right)\) so, we can decided that the neutrosophic version is better than the classical version. Also, in the context of interval estimation the \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has smaller ACL for asymptotic confidence interval than \({\text{BS}}(\mathrm{\alpha },\upbeta )\). So, For MLE’s the \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has good behavior than \({\text{BS}}\left(\mathrm{\alpha },\upbeta \right).\) Also, we get for two versions bias’s and MSE’s decrease when sample size increase. For Bayesian estimator results are shown in Tables 3, 4, 5 and 6, we get also, \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has smaller bias’s and MSE’s than \({\text{BS}}\left(\mathrm{\alpha },\upbeta \right)\) as shown in Tables 5 and 6. Also, for credible intervals \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has smaller ACL than \({\text{BS}}\left(\mathrm{\alpha },\upbeta \right).\) The behavior of Bayesian estimation got for different three prior distributions. So, we can decide also, \({\text{NBS}}({\mathrm{\alpha }}_{{\text{N}}},{\upbeta }_{{\text{N}}})\) has good behavior than \({\text{BS}}\left(\mathrm{\alpha },\upbeta \right)\).
Comparative study using real application
The main aim of this section is a comparative study between the \(NBS({\alpha }_{N},{\beta }_{N})\) and \(BS\left(\alpha ,\beta \right)\). We introduced two real applications as follows:
Application 1
Based on data of alloy melting points. For more details see63 which mentioned that A combination of material constituents, including at least one metal, makes up an alloy. In general, evaluating melting points is quite challenging, therefore observations are indeterministic and can be communicated in intervals as follows:
[563.3, 545.5], [529.4, 511.6], [523.1, 503.5], [470.1,449.2], [506.7, 489.0], [495.6, 479.1], [495.3, 467.9],[520.9, 495.6], [496.9, 472.8], [542.9, 519.1], [505.4,484.0], [550.7, 525.9], [517.7, 500.9], [499.2, 483.0],[500.6, 480.0], [516.8, 499.6], [535.0, 515.1], [489.3,464.4].
Application 2
The data represent the lifetime of batteries. The lifetime in 100hours of 23 batteries is given as:
[2.9,3.99], [5.24,7.2],[6.56,9.02], [7.14,9.82], [11.6,15.96], [12.14,16.69], [12.65,17.4], [13.24,18.21], [13.67,18.79], [13.88,19.09], [15.64,21.51], [17.05,23.45], [17.4,23.93], [17.8,24.48], [19.01,26.14], [19.34,26.59], [23.13,31.81], [23.34,32.09],[26.07,35.84], [30.29,41.65], [43.97,60.46], [48.09,66.13], [73.48,98.04]. For more details see64.
Figure 7 shows the architectural diagram of the proposed algorithm in this section. To show the performance of our new distribution the \(NBS({\alpha }_{N},{\beta }_{N})\). We compare it with its classical version \(BS\left(\alpha ,\beta \right)\) using three statistical criteria log -likelihood (− 2LL), Akaike’s Information Criteria (AIC) and Bayesian Information Criteria (BIC), where,
where, \(\underset{\_}{\Theta }\): the vector of distribution parameters, \(L\left(\underset{\_}{\Theta }\right)\): the likelihood function, \(k\): the number of estimates, n: the data size. The small value of -2LL, AIC and BIC mean good-fit distribution. Table 7 shows the result of comparison between our new distribution and other distribution under classical statistics. The result in Table 7 shows our new distribution is better for this data than its classical version in two applications because all goodness of fit tests having smaller values in neutrosophic version than the classical version.

Architectural Diagram of the Proposed Algorithm.
Conclusion
A new distribution introduced which called neutrosophic Birnbaum–Saunders distribution and denoted by \(NBS({\alpha }_{N},{\beta }_{N})\). some statistical properties such as neutrosophic probability density function, neutrosophic cumulative distribution function, neutrosophic hazard function, neutrosophic mean, mode, median, variance, moment of origin, moment generating function, characteristic function, quantile function, cumulant generating function, order statistic and entropies. The neutrosophic maximum likelihood estimators and neutrosophic Bayesian estimators are derived. The simulation study is performed to study the behavior of different estimators at different parameter values and different sample sizes. Also, compare between neutrosophic Birnbaum-Saunders distribution and its classical version using statistical criteria such as bias, MSE, AIC and ACL. Finally, real data of the melting point of alloy and real data of the lifetime of batteries are used to show the validity of \(NBS({\alpha }_{N},{\beta }_{N})\) in real life. Also, compare the performance of \(NBS({\alpha }_{N},{\beta }_{N})\) and \(BS\left(\alpha ,\beta \right)\) on this data using AIC, BIC and − 2LL, which shows the good performance of \(NBS({\alpha }_{N},{\beta }_{N})\) than \(BS\left(\alpha ,\beta \right).\) The neutrosophic field has more points need more and more search so, in future we try to introduce more netrosophic distribution to used solve and describe more real life applications also we will try to introduce many researches in different points in neutrosophic statistics.
Data availability
The data is given in the paper.
References
Birnbaum , Z. W. & Saunders , S. C. in Journal of Applied Probability 319–327 (1969a).
Johnson, N., Kotz, S. & Balakrishnan, N. Continuous Univariate Distributions Vol. 2 (John Wiley & Sons, 1995).
Owen, W. J. & Padgett, W. J. Birnbaum–Saunders accelerated life model. IEEE Trans. Reliab. 49, 224–229 (2000).
Guiraud, P., Leiva, V. & Fierro, R. A non-central version of the Birnbaum–Saunders distribution for reliability analysis. IEEE Trans. Reliab. 58, 152–160 (2009).
Ho, J. W. Parameter estimation for the Birnbaum–Saunders distribution under an accelerated degradation test. Eur. Ind. Eng. 6, 644–665 (2012).
Leiva, V., Barros, M., Paula, G. A. & Galea, M. Influence diagnostics in log-Birnbaum–Saunders regression models with censored data. Comput. Stat. Data Anal. 51, 5694–5707 (2007).
Leiva, V., Barros, M., Paula, G. A. & Sanhueza, A. Generalized Birnbaum–Saunders distributions applied to air pollutant concentration. Environmetrics 19, 235–249 (2008).
Leiva, V., Sanhueza, A. & Angulo, J. M. A length-biased version of the Birnbaum–Saunders distribution with application in water quality. Stoch. Env. Res. Risk Assess. 23, 299–307 (2009).
Leiva, V., Vilca, F., Balakrishnan, N. & Sanhueza, A. A skewed sinh-normal distribution and its properties and application to air pollution. Commun. Stat. Theory Methods 39, 426–443 (2010).
Leiva, V., Athayde, E., Azevedo, C. & Marchant, C. Modeling wind energy flux by a Birnbaum–Saunders distribution with unknown shift parameter. J. Appl. Stat. 38, 2819–2838 (2011).
Leiva, V., Ponce, M. G., Marchant, C. & Bustos, O. Fatigue statistical distributions useful for modeling diameter and mortality of trees. Colomb. J. Stat. 35, 349–367 (2012).
Barros, M., Paula, G. A. & Leiva, V. A new class of survival regression models with heavy-tailed errors: Robustness and diagnostics. Lifetime Data Anal. 14, 316–332 (2008).
Bhatti, C. R. The Birnbaum–Saunders autoregressive conditional duration model. Math. Comput. Simul. 80, 2062–2078 (2010).
Vilca, F., Sanhueza, A., Leiva, V. & Christakos, G. An extended Birnbaum–Saunders model and its application in the study of environmental quality in Santiago Chile. Stoch. Env. Res. Risk Assess. 24, 771–782 (2010).
Vilca, F., Santana, L., Leiva, V. & Balakrishnan, N. Estimation of extreme percentiles in Birnbaum–Saunders distributions. Comput. Stat. Data Anal. 55, 1665–1678 (2012).
Paula, G. A., Leiva, V., Barros, M. & Liu, S. Robust statistical modeling using the Birnbaum–Saunders t-distribution applied to insurance. Appl. Stoch. Model. Bus. Ind. 28, 16–34 (2012).
Ferreira, M., Gomes, M. I. & Leiva, V. On an extreme value version of the Birnbaum–Saunders distribution. Revstat-Stat. J. 10, 181–210 (2012).
Marchant, C., Bertin, K., Leiva, V. & Saulo, H. Generalized Birnbaum–Saunders kernel density estimators and an analysis of financial data. Comput. Stat. Data Anal. 63, 1–15 (2013).
Marchant, C., Leiva, V., Cavieres, M. F. & Sanhueza, A. Air contaminant statistical distributions with application to PM10 in Santiago, Chile. Rev. Environ. Contam. Toxicol. 223, 1–13 (2013).
Bhattacharyya, G. K. & Fries, A. Fatigue failure models—Birnbaum–Saunders versus inverse Gaussian. IEEE Trans. Reliab. 31, 439–440 (1982).
Desmond, A. F. On the relationship between two fatigue-life models. IEEE Trans. Reliab. 35, 167–169 (1986).
Mann, N. R., Schafer, R. E. & Singpurwalla, N. D. Methods for Statistical Analysis of Reliability and Life Data (John Wiley and Sons, 1974).
Kundu, D., Kannan, N. & Balakrishnan, N. On the hazard function of Birnbaum–Saunders distribution and associated inference. Comput. Stat. Data Anal. 52, 2692–2702 (2008).
Bebbington, M., Lai, C. D. & Zitikis, R. A proof of the shape of the Birnbaum–Saunders hazard rate function. Math. Sci. 33, 49–56 (2008).
Gupta, R. C. & Akman, H. O. Estimation of critical points in the mixture of inverse Gaussian distribution. Stat. Pap. 38, 445–452 (1997).
Smarandache, F. Neutrosophic logic-a generalization of the intuitionistic fuzzy logic. Multispace Multistruct. Neutrosophic Transdiscipl. (100 Collect. Papers Sci.) 4, 396 (2010).
Smarandache, F. Introduction to Neutrosophic Statistics, Sitech and Education Publisher, Craiova 123 (Romania-Educational Publisher, 2014).
Chen, J., Ye, J. & Du, S. Scale effect and anisotropy analyzed for neutrosophic numbers of rock joint roughness coefficient based on neutrosophic statistics. Symmetry 9, 208 (2017).
Aslam, M. A new sampling plan using neutrosophic process loss consideration. Symmetry 10, 132 (2018).
Nayana, B. M., Anakha, K. K., Chacko, V. M., Aslam, M. & Albassam, M. A new neutrosophic model using DUS-Weibull transformation with application. Complex Intell. Syst., 1–10 (2022).
Alhabib, R., Ranna, M. M., Farah, H. & Salama, A. Some neutrosophic probability distributions. Neutrosophic Sets Syst. 22, 30–38 (2018).
Alhasan, K. H. & Smarandache, F. Neutrosophic Weibull distribution and neutrosophic family Weibull distribution. Neutrosophic Sets Syst. 28, 191–199 (2019).
Patro, S. K. & Smarandache, F. The neutrosophic statistical distribution, more problems, more solutions. Neutrosophic Sets Syst. 12, 73–79 (2016).
Zeina, M. B. Neutrosophic event-based queueing model. Int. J. Neutrosophic Sci. 6, 48–55 (2020).
Zeina, M. B. Erlang service queueing model with neutrosophic parameters. Int. J. Neutrosophic Sci. 6, 106–112 (2020).
Alhabib, R. & Salama, A. A. The neutrosophic time series-study its models (linear-logarithmic) and test the coefficients significance of its linear model. Neutrosophic Sets Syst. 33, 105–115 (2020).
Alhabib, R. & Salama, A. A. Using moving averages to pave the neutrosophic time series. Int. J. Neutrosophic Sci. 3, 14–20 (2020).
Cruzaty, L. E. V., Tomalá, M. R. & Gallo, C. M. C. A neutrosophic statistic method to predict tax time series in ecuador. Neutrosophic Sets Syst. 34, 33–39 (2020).
Bisher, M. & Hatip, A. Neutrosophic random variables. Neutrosophic Sets Syst. 39, 45–52 (2021).
Granados, C. New results on neutrosophic random variables. Neutrosophic Sets Syst. 47, 286–297 (2021).
Granados, C. & Sanabria, J. On independence neutrosophic random variables. Neutrosophic Sets Syst. 47, 541–557 (2021).
Kandasamy, W. B. V. & Smarandache, F. Neutrosophic rings (2006).
Salama, A., Sharaf Al-Din, A., Abu Al-Qasim, I., Alhabib, R. & Badran, M. Introduction to decision making for neutrosophic environment study on the Suez Canal Port. Neutrosophic Sets Syst. 35, 22–44 (2020).
Kamaci, H. Neutrosophic cubic Hamacher aggregation operators and their applications in decision making. Neutrosophic Sets Syst. 33, 234–255 (2020).
Olgun, N. & Hatip, A. The Effect of the Neutrosophic Logic on The Decision Making, in Quadruple Neutrosophic Theory and Applications, (Pons Editions Brussels, Belgium, 2020).
Sahin, R. Neutrosophic hierarchical clustering algoritms. Neutrosophic Sets Syst. 2, 19–24 (2014).
Shahzadi, G., Akram, M. & Saeid, A. B. An application of single-valued neutrosophic sets in medical diagnosis. Neutrosophic Sets Syst. 18, 80–88 (2017).
Ejaita, O. A. & Asagba, P. An improved framework for diagnosing confusable diseases using neutrosophic based neural network. Neutrosophic Sets Syst. 16, 28–34 (2017).
Chakraborty, A., Banik, B., Mondal, S. P. & Alam, S. Arithmetic and geometric operators of pentagonal neutrosophic number and its application in mobile communication service based MCGDM problem. Neutrosophic Sets Syst. 32, 61–79 (2020).
Sahin, M., Olgun, N., Uluçay, V., Kargon, A. & Smarandache, F. A new similarity measure based on falsity value between single valued neutrosophic sets based on the centroid points of transformed single valued neutrosophic numbers with applications to pattern recognition. Neutrosophic Sets Syst. 15, 31–48 (2017).
Lotfy, M. M., ELhafeez, S., Eisa, M. & Salama, A. A. Review of recommender systems algorithms utilized in social networks based e-learning systems & neutrosophic system. Neutrosophic Sets Syst. 8, 32–41 (2015).
Nabeeh, N. A., Smarandache, F., Abdel-Basset, M., El-Ghareeb, H. A. & Aboelfetouh, A. An integrated neutrosophic topsis approach and its application to personnel selection: A new trend in brain processing and analysis. IEEE Access 7, 29734–29744 (2017).
Cover, T. M. & Thomas, J. A. Elements of Information Theory (Wiley, 2005).
Rényi, A. On measures of entropy and information. In Proceedings of the 4th Fourth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley,CA, USA 547–561 (1961).
Tsallis, C. Possible generalization of Boltzmann–Gibbs statistics. J. Stat. Phys. 52, 479–487 (1988).
Lawless, J. F. Statistical Models and Methods for Lifetime Data. (John Wiley and Sons, 2003).
Geman, S. & Geman, D. Stochastic relaxation, Gibbs distributions and the Bayesian restoration of images. IEE Transaction on Pattern Analysis and Machine Intelligent 12, 609–628 (1984).
Smith, A. & Roberrs, G. Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. Journal of Reliability & Statistical Society 55, 2–23 (1993).
Metropolis, N., Rosenbluth, A. W., Rosenbluth, A. H., Teller, A. H. & Teller, E. Equations of state calculations by fast computing machine. Journal of Chemistry Physics 21, 1087–1092 (1953).
Hastings, W. K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57, 97–101 (1970).
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2023).
Rao, G. S. Neutrosophic log-logistic distribution model in complex alloy metal melting point applications. Int. J. Comput. Intell. Syst. 16, 48 (2023).
Aslam, M. A new goodness of fit test in the presence of uncertain parameters. Complex Intell. Syst. 7(1), 359–365 (2021).
Acknowledgements
The authors are deeply thankful to the editor and reviewers for their valuable suggestions to improve the quality and presentation of the paper.
Author information
Authors and Affiliations
Contributions
M.K.H.H and M.A wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, M.K., Aslam, M. Birnbaum Saunders distribution for imprecise data: statistical properties, estimation methods, and real life applications. Sci Rep 14, 6955 (2024). https://doi.org/10.1038/s41598-024-57438-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-57438-8
- Springer Nature Limited