
Abstract
Breast cancer remains a leading cause of cancer-related deaths among women globally, necessitating the development of more effective therapeutic agents with minimal side effects. This study explores novel 1,2,4-triazine-3(2H)-one derivatives as potential inhibitors of Tubulin, a pivotal protein in cancer cell division, highlighting a targeted approach in cancer therapy. Using an integrated computational approach, we combined quantitative structure–activity relationship (QSAR) modeling, ADMET profiling, molecular docking, and molecular dynamics simulations to evaluate and predict the efficacy and stability of these compounds. Our QSAR models, developed through rigorous statistical analysis, revealed that descriptors such as absolute electronegativity and water solubility significantly influence inhibitory activity, achieving a predictive accuracy (R2) of 0.849. Molecular docking studies identified compounds with high binding affinities, particularly Pred28, which exhibited the best docking score of − 9.6 kcal/mol. Molecular dynamics simulations conducted over 100 ns provided further insights into the stability of these interactions. Pred28 demonstrated notable stability, with the lowest root mean square deviation (RMSD) of 0.29 nm and root mean square fluctuation (RMSF) values indicative of a tightly bound conformation to Tubulin. The novelty of this work lies in its methodological rigor and the integration of multiple advanced computational techniques to pinpoint compounds with promising therapeutic potential. Our findings advance the current understanding of Tubulin inhibitors and open avenues for the synthesis and experimental validation of these compounds, aiming to offer new solutions for breast cancer treatment.
Similar content being viewed by others
Introduction
Breast cancer remains the most diagnosed cancer among women globally. According to the World Health Organization's 2023 report1, each year, more than 2.3 million women are diagnosed with breast cancer, making it the most common cancer in the world affecting all adults. This accounts for nearly 25% of all cancers in women. These statistics highlight the persistent challenge breast cancer poses and underscore the critical need for developing more effective therapeutic strategies.
The 1,2,4-triazine-3(2H)-one derivatives have emerged as a promising class of anticancer agents, with several studies reporting their potent anticancer activity against2 breast cancer cell lines. These derivatives act by disrupting microtubule dynamics, which are essential for cell division3, through their interaction with Tubulin, specifically the Colchicine binding site. The Tubulin protein was chosen as the focal point of our research due to its critical role in regulating microtubule dynamics and its active involvement in the division of breast cancer cells. Our decision to focus on Tubulin-Colchicine as the target protein for our study was made after thoughtful deliberation regarding its importance in cancer treatment. Tubulin proteins are key components of the cellular cytoskeleton and are crucial for cell division, making them an attractive target for cancer therapy. Colchicine-binding to Tubulin disrupts its polymerization, thereby inhibiting mitosis and cell proliferation. Given the mechanism of action and the success of Colchicine and its analogs in cancer treatment, targeting the Tubulin-Colchicine site provides a rational approach for novel anticancer drug design. Furthermore, the 1,2,4-triazine-3(2H)-one derivatives were chosen for their structural similarities to known Tubulin-Colchicine inhibitors, as well as their promising pharmacokinetic profiles, making them viable candidates for further investigation4,5,6,7.
It is important to note that the focus of this study is on targeting the Tubulin-Colchicine binding site as a general approach to breast cancer therapy. While Tubulin inhibitors have shown efficacy in various types of breast cancer, the applicability of our 1,2,4-triazine-3(2H)-one derivatives to specific subtypes such as Triple-Negative Breast Cancer (TNBC) has not been investigated in this study. Future work should delve into the subtype-specific efficacy of these compounds.
In this context, computational tools such as quantitative structure–activity relationship (QSAR) modeling, molecular docking, and molecular dynamics simulations are pivotal in enhancing the efficiency and efficacy of drug discovery processes. QSAR modeling is crucial for understanding the relationship between chemical structures and their biological activities. This method allows researchers to predict the activity of new compounds based on their chemical properties, thereby streamlining the identification of promising candidates for further experimental validation. QSAR models provide insights into the essential features influencing drug efficacy and safety, guiding the synthesis of compounds with optimized pharmacological profiles8,9.
Molecular docking techniques simulate the interaction between a molecule and its biological target, typically a protein involved in disease pathways. By predicting how small molecules fit into the binding sites of target proteins, molecular docking helps to ascertain the binding affinity and interaction mechanisms, crucial for assessing the therapeutic potential of new drugs. This approach is instrumental in refining the molecular structures of drug candidates to enhance their specificity and potency against cancer targets10,11.
Molecular dynamics simulations further extend our understanding of drug-target interactions over time, offering insights into the stability and behavior of these interactions under physiologically relevant conditions. By examining the dynamics of protein–ligand complexes through simulations, we can assess the flexibility and conformation changes of both the target and the ligands. This method provides valuable data on the durability of the binding over time, essential for predicting the in vivo efficacy and stability of therapeutic candidates.
In our study, we employ these advanced computational techniques to explore the potential of 1,2,4-triazine-3(2H)-one derivatives as inhibitors of Tubulin, a key protein in cell division and a validated target in cancer treatment. Integrating QSAR modeling, ADMET12, molecular docking, and molecular dynamics simulations allows us to comprehensively predict and analyze the interactions, stability, and efficacy of these compounds. This holistic approach not only informs the drug design process but also aligns with the broader goal of accelerating the discovery and optimization of effective cancer therapies.
Materials and methods
Data set
Based on the research of Eissa et al. a database of 32 1,2,4-triazine-3 (2H)-one derivative with their inhibitory efficacy against the MCF-7 breast cancer cell line was created13, has been compiled to perform this study. The selection of this database is due to the following reasons: (i) the compounds in our database represent structural diversity with pIC50 (3.460–4.963), (ii) actually, the 1,2,4-triazin-3(2H)-one derivatives present a privileged heterocyclic for drug design in therapeutic medicinal. The reported IC50 values of compounds have been converted into corresponding pIC50 (−log IC50) (Table S1).
To ensure the robustness and reliability of our QSAR model, we adopted an 80:20 ratio for dividing our dataset into training and test sets. This ratio is widely recognized in computational drug design for balancing extensive model training with adequate external validation. We implemented a randomized split to avoid potential biases related to the order of data entries, ensuring that both subsets are representative of the overall dataset. This approach allows for comprehensive training of the model on diverse chemical entities while providing a substantial and unbiased test set for evaluating the model's predictive accuracy on unseen data.
Molecular descriptors
Currently, several different in QSAR research, molecules are employed as descriptors. The results may be used to forecast the activity of substances that have not been tested after being validated. The Gaussian 09W program was used to compute the electronic descriptors14. The 32 1,2,4-triazine-3(2H)-one derivatives' geometries were optimized using the DFT approach and the B3LYP functional15 and 6-31G (p, d) base set16,17,18. Then, several related structural parameters were selected from the results of the quantum computation as follows: highest occupied molecular orbital energy (EHOMO), lowest unoccupied molecular orbital energy (ELUMO), dipole moment (μm), total energy (TE), absolute hardness (η), absolute electronegativity (χ) and reactivity index (ω)19. The η, χ and ω were determined using the following equations:
ChemOffice software 16.020 was used to calculate the topological descriptors, as follows: molecular weight (MW), Number of HBond Acceptors (NHA), Number of HBond Donors (NHD), Octanol–Water Partition Coefficient (LogP), Water Solubility (LogS), Balaban Index (J), Molecular Topological Index (MTI), Polar Surface Area (PSA), Radius (RDWV), Shape Coefficient (I), Sum of Valence Degrees (SVD), Wiener Index (WI) and Number Rotatable Bonds (NROT).
The selection of molecular descriptors was a critical step in the development of our QSAR model. We employed a combination of statistical analyses and biological reasoning to arrive at our final set of descriptors. Each descriptor was chosen based on its ability to provide unique and non-redundant information about the biological activity of the compounds under study. For instance, the descriptor 'χ' (absolute electronegativity) was selected due to its relevance in predicting molecular interactions, while 'LogS' was chosen for its importance in solubility prediction. Furthermore, the selected descriptors showed low multicollinearity and were statistically significant in the model according to the variance inflation factor (VIF) and p-values.
Statistical analysis
Developing empirical models that connect a compound's biological activity to its chemical make-up is the goal of a quantitative structure–activity relationship (QSAR) research. In this QSAR study, the chemical structure is described quantitatively and the link between the chemical structure and biological activity is described mathematically. These 24 descriptors are produced for the 32 compounds using the Gaussian 09W and ChemOffice programmers to illustrate the structure–activity link.
Statistical techniques based on principal component analysis (PCA) are used to examine the quantitative characteristics of the substituted 1,2,4-triazine-3(2H)-one21 using XLSTAT version 2019 software22. PCA is a helpful statistical method for collecting all of the data included in the compound structures. Understanding the distribution of the chemicals is also made easier by it23. This statistical approach is mostly descriptive and seeks to visualize the most relevant information from the data, as shown in Tables S1 and S2.
The structure–activity link is modeled employing a descendent selection and variable removal multiple linear regression (MLR) approach. It is a mathematical technique designed to lessen the difference between observed and predicted values.
XLSTAT version 2019 was used to create the MLR model. Equations are supported by the correlation coefficient (R), mean squared error (MSE), Fisher's criteria (F), and significance level (P) to determine the pIC50.
where \({\text{Y}}_{\text{obs}}\) is the value of the observed response, \({\text{Y}}_{\text{pred}}\) is the value of the predicted response, \({\overline{\text{Y}} }_{\text{pred}}\) is the average value of observed/predicted responses, and p is the number of explicative variables in the model, and n is the number of individuals.
The final QSAR models were validated internally and externally. The internal validation procedure used was leave-one-out (LOO) cross-validation. The predicted values for the internal validation set were gathered, and the accuracy of the prediction of the pIC50 was evaluated using cross-validated R2 (Q2-LOO).
Additionally, the Golbraikh and Tropsha-proposed parameters for calculating a QSAR model's external predictability were derived24. In light of this, a QSAR model is deemed predictive if the following criteria are met:
-
R2 > 0.6
-
Q2 > 0.5
-
\(\frac{{\text{R}}^{2}-{\text{R}}_{0}^{2}}{{\text{R}}^{2}}<0.1 \;\; \text{ and }\;\; 0.85 \le \text{k}\le 1.15 \;\; \text{ or} \;\; \frac{{\text{R}}^{2}-{{\text{R}}^{{{\prime}}}}_{0}^{2}}{{\text{R}}^{2}}<0.1\text{ and }0.85 \le \text{k}^{\prime}\le 1.15\)
-
\(\left|{R}_{0}^{2}-\left.{R^{\prime}}_{0}^{2}\right|<0.3\right.\)
R2 and \({\text{R}}_{\text{0}}^{2}\) re the square correlation coefficients between the observed and the predicted activity values with and without intercept, respectively, while \({\text{R}}_{0}^{{\prime}2}\) represents the same information as \({\text{R}}_{0}^{2}\) does but with inverted axis (linear regression between the predicted against the observed values). These parameters can be calculated as follows:
where \({\overline{\text{Y}} }_{\text{pred}}\) and \({\overline{\text{Y}} }_{\text{obs}}\) refer to the mean values of the predicted and observed activity data, respectively. The regression lines through the origin are defined by \({Y^{\prime}}_{obs}^{0}=k {Y}_{pred}\) and \({Y^{\prime}}_{pred}^{0}={k}^{\prime} {Y}_{obs}\), while the slopes k and k’ are calculated as follows:
Likewise, \({R}_{m}^{2}\) metrics proposed by Ojha et al.25 for external validation were calculated to further evaluate the correlation between the observed and predicted activity:
where
and
Y-Randomization test
Randomization of the response variable and the Y-randomization test were employed to determine the model's robustness. The whole training set's calculations are redone for this test using randomly generated activities.
The Q2 and R2 of the new QSAR models were lower than those of the original models. To rule out the potential of random correlation, this approach was used. Higher Q2 and R2 values indicate that structural redundancy and random correlation prevent the generation of a suitable QSAR for this dataset26.
The Y-randomization test also calculates the coefficient of determination, or cR2p value, which is stated to need to be larger than 0.5 to pass the test27:
Model applicability domain
A model cannot be used to predict the biological activity for the entire chemicals in the universe except for those in its region of reliable/acceptable prediction, which is defined in terms of descriptors contained in the model. This region is known as the applicability domain (AD) of the model. In this study, the AD of the developed model was defined using the extent of the extrapolation method. This method employs leverage h values of dataset molecules and the standardized prediction residual (SDR) of the models to define their AD. The result of this method is often visualized by the plot of h versus SDR (Williams plot)28.
Leverage h is a special type of distance measures used to show similarity/dissimilarity among objects and it’s obtained as the diagonal element of a hat matrix hi:
where each of the compounds as defined by i can take values from 1, 2,…, n.
Within the model that was developed, xi is taken as the row-vector descriptor for the main query complex. Additionally, X is the result of \(n\times (k-1)\) matrix of k model and the descriptor values for the n training set compounds. In addition, T (depicted as a superscript number), refers to the transpose of matrix/vector29.
In general, the AD of the models in the research was defined as a square region with vertical boundary 0 < hi < h* and horizontal boundary −3 < SDR < 3, where hi’s were molecules leverages values and h* was the models warning leverage expressed as:
In Eq. (16)30, k is the number of descriptors in the model, and n is the number of training set molecules. Standardized residual (SDR) was calculated with the equation below:
In Eq. (17), \({Y}_{obs}\) and \({Y}_{pred}\) are observed and predicted response respectively for either training or test set molecules, and n is the number of dataset molecules.
Molecular docking studies
The crystal structure of human Tubulin-Colchicine was retrieved from the Protein Data Bank (PDB code: 1SA0, resolution 3.58 Å)31 and was used for the MD study. The protein preparation was further conducted by AutoDock Tools32,33: All ligands were extracted from the protein structure, missing residues were added and polar hydrogen atoms, Kollman charges and applying Gasteiger Marsili charges were added and removing water molecules were added using AutoDock Tools. For structures that were modelled using a template, energy minimization was carried out using using ChemOffice program with Minimum RMS Gradient of 0.010 to relieve any steric clashes and to optimize the geometry. The energy-minimized structure was then used for subsequent docking studies. The grid maps were created at 40 \(\text{\AA }\) in all three dimensions (X, Y, Z), the center of this box is determined by the coordinates X = 117.219, Y = 90.179, and Z = 6.289 angstrom (Å) with a default grid space size of 0.375 \(\text{\AA }\). 2D and 3D ligand interactions were visualized using Discovery studio to evaluate the strength of ligand–protein interactions.
Molecular dynamic studies
To explore the structure–function relationship, molecular dynamics simulations (MD) were conducted with GROMACS 2019.334 on the docked complexes comprising compounds Pred3, Pred13, Pred28, and Colchicine. The protein utilized the CHARMM27 force field35, while ligand topologies were developed via the Swissparam server36. Each complex was placed in a dodecahedral box with a 1.0 nm edge length, filled with TIP3P water, and neutralized with Na + ions37. Energy minimization was achieved using the steepest descent method, targeting a maximum force of 1000 kJ/mol/nm38. Two 100 ps simulations were sequentially run at 300 K and 1 bar using NVT and NPT ensembles to equilibrate the system. Finally, 100 ns MD simulations were performed on each molecule, producing trajectories and data files that were analyzed to elucidate protein behavior.
Results and discussion
Twenty-four chemical descriptors and the biological activity of 32 1,2,4-triazine-3(2H)-one derivative as microtubule assembly inhibitors were used in the QSAR analysis (Table S1). The most effective correlation models were determined using the multi-linear regression technique using a set of non-collinear descriptors. Models that do not meet the OCDE standards and Golbraikh and Tropsha's requirements were disqualified39. The best linear model was represented by the following equation, which included the five chemical descriptors χ, TE, NHD, LogS, and I.
MLR model for pIC50 breast cancer
Since TE, LogS, and I all have negative signs in the model equation, lowering their values may raise the value of pIC50. The pIC50 value may be improved by raising X and NHD since they both have positive signs. Based on the MLR equation, it is evident that the values of the studied activity (pIC50) are linearly correlated with the five selected descriptors. As shown in Table 1, the greatest value of the coefficient of determination (R2 > 0.6), Furthermore, the created model is predictive, as shown by the high-value R2test. The variables were selected based on statistical significance, and we excluded variables that had high multicollinearity, as shown by the lower value of MSE and the strong statistical significance of the confidence level F (Fisher's parameter). Additionally, the robustness of the developed MLR model is shown by Q2's value (more than 0.5).
The MLR results include normalized descriptor coefficients and the correlation between observed and predicted actions (Fig. 1)40. The experimentally determined and theoretical pIC50 values displayed in Fig. 2 exhibit a strong correlation. The model consisted of five descriptors (Table 2) based on the normalization diagram of coefficients (Fig. 1), with NHD, LogS, TE, and X being the most significant.

Contribution of the descriptors in model.

The correlation between the observed and predicted activities.
There is no multicollinearity among the specified descriptors, and the MLR model has strong stability, as shown by the variance inflation factor (VIF) of less than 10 for all of the created model's selected descriptors41. The VIF values of the derived model are shown in Table 3. Therefore, it is evident that all five of the model's descriptors have a strong correlation with pIC50. Table 2 displays the observed and predicted activity values, while their correlational relationship is illustrated in Fig. 1.
The VIF values were within an acceptable range, suggesting that multicollinearity among the selected descriptors is not a significant concern in this specific model42.
Validation of the QSAR model focusing on the reliability of two-dimensional chemical descriptors
Y-Randomization test
A randomization test is used, and 100 models for MLR have been generated, to prevent random correlation and check the MLR model that has been built. The low values of, \({Q}_{cv \left(LOO\right)(Rand)}^{2}\) and, \({R}_{Rand}^{2}\) found for the MLR model are shown in Table S3. The findings show that the model developed is not the product of random correlation43.
Golbraikh and Tropsha criteria
The MLR model's outcomes and Golbraikh and Tropsha's parameters were compared. The findings in Table 4 demonstrate that the MLR model adheres to the standards set forth by Golbraikh and Tropsha. The model proposed is able to predict with high performance for new compounds.
Applicability domain
By plotting the leverage effect values (hi) vs the residual values, the application domain of the verified model was identified. The distribution of normalized residual values, the leverage level values, and the threshold leverage effect (h* = 0.56), with \({h}^{*}=3\times \frac{k+1}{n}\); k = 5; N = 32, as well as the distribution of normalized residual values and the leverage level values have calculated as shown in following William’s plot (Fig. 3). Based on the levers (h* > 0.56), none of the compounds was found outside the AD of the developed model.

Williams plot of standardized residual versus leverage for the MLR model (with: h* = 0.56 and residual limits = ± 2.5); training samples in the black color and test samples in the red color.
Using MatlabV2021a software, we define the Williams plot type's application domain in this study.
Design of new compounds
The suggested model demonstrates how adjustments to the QSAR model's appeared descriptors might improve activity. The finished model's descriptors, on the other hand, may be used to interpret the data. Finding the connection between the descriptor values and the researched compounds' structural specifics is simple.
Absolute electronegativity (χ)
This descriptor represents the tendency of a molecule to attract electrons. In our QSAR model, a higher value of χ corresponds to increased electron-withdrawing capacity, which enhances the interaction of the molecule with the target protein, thereby increasing the pIC50 values. This suggests that molecules with higher electronegativity are more effective in disrupting the Tubulin dynamics critical for cancer cell viability.
Total energy (TE)
The total energy of a molecule reflects its stability; in our study, a lower TE is associated with higher biological activity. Molecules with lower total energy are more stable and can more readily interact with the target site on the Tubulin protein, which could explain their enhanced inhibitory effects on breast cancer cell lines.
Number of hydrogen bond donors (NHD)
Hydrogen bond donors play a crucial role in drug-target interactions by forming hydrogen bonds with the target protein, stabilizing the drug-protein complex. Our findings indicate that an increase in NHD enhances pIC50, suggesting that additional hydrogen bonds contribute positively to the binding affinity and thus the effectiveness of the inhibition.
Water solubility (LogS)
Solubility is critical for the bioavailability of a drug. In our model, compounds with better solubility (higher LogS values) generally exhibited lower pIC50, indicating that while solubility is crucial for overall drug performance, excessively soluble compounds may be too hydrophilic to efficiently permeate cell membranes and reach intracellular targets.
Shape coefficient (I)
This descriptor quantifies the three-dimensional shape and bulk of the molecule, influencing how well the molecule fits into the target binding site. Our results suggest that a smaller shape coefficient, indicating a more compact molecular structure, is beneficial for interacting with the specific contours of the Tubulin binding site, thereby enhancing inhibitory activity.
As a result, we decided to search for novel compounds with specific alterations in the structural characteristics of the compounds under study. The impact of descriptors on the biological activity and structural characteristics of the most active compounds led to the suggestion of several compounds. ChemOffice software was used to sketch and optimize the structures of the suggested compounds, and ChemOffice and Gaussian software was used to determine the effective descriptors.
The structures of the proposed compounds and their corresponding predicted pIC50 values are summarized in Tables S4 and 5. The data indicate that increases in the values of X and NHD enhance the anti-cancer activity of the dataset compounds, whereas increases in the values of TE, LogS, and I diminish this activity. The addition of elements with greater electronegativity than carbon (e.g., F, Cl, O, and N) and an increase in molecular size lead to an increase in the value of X and a decrease in the value of the descriptor TE. Based on this information, modifications were made to the 1,2,4-triazin-3(2H)-one ring in the template compound 5i. This phase involved the design of 28 compounds and the calculation of their leverage values to identify outliers. Equation (18) was utilized to determine the pIC50 values. Tables S4 and 5 present the structures, values of chemical descriptors, and pIC50 values of these compounds.
Drug‑likeness assessment and ADMET predictions
The physicochemical characteristics of the substances are often linked to certain filter variations when assessing how drug-like they are. So, via the ADMETlab 2.0 Web server, pertinent physicochemical parameters (Table S5) are produced. According to the radar charts, the physicochemical characteristics of the fourteen compounds fall between the upper (brown) and lower (red) bounds (Table S5). The fourteen compounds (Table S6) that passed the Lipinski rule of five were further evaluated using the SwissADME Web server utilizing various drug-likeness filter rules, including the Ghose filter rule, Veber's rule, and Egan's rule. The results are reported in Table S6.
Using Lipinski's rule of five as a filter, the SwissADME web server was used to theoretically forecast the drug-like characteristics of the examined compounds (Table S6), including the best-hit compounds. Any small molecule that fails to meet more than one of the aforementioned requirements may have problems with bioavailability. The novel compounds' pharmacokinetic analysis is shown in Table S6, and All of the compounds pass the Lipinski rule of five tests, including the criterion for molecular weight, which stipulates a maximum of 500 g/mol. Furthermore, all of the best hit compounds had one hydrogen bond acceptors, which was within the accepted range. For the number of hydrogen bond donors, between 3 and 8 is also within the accepted range. Additionally, the estimated LogP value never went beyond or below the acceptable bounds. The best-hit compounds were determined to be drug-like based on these filtering requirements by not exceeding the established threshold values (or by not having more than one violation of the filtering conditions used). They were all further determined to be orally bioavailable based on the value of their bioavailability score (all having 0.56)26. Given that these substances complied with all of the filtering requirements, it was generally anticipated that there would be no problems with their bioavailability.
The examined compounds, including the top hit compounds, were theoretically evaluated for their ADMET/pharmacokinetic characteristics using the online web server pkCSM (Table S7). Human intestinal absorption of the best-identified hit compounds was all found to vary between 63.568 and 96.568%. These small molecules can be absorbed inside the human gut if their values of intestinal absorption in humans are larger than the minimum suggested rate of 30% given for the assessment of this attribute. The accepted threshold value for the central nervous system (CNS) permeability is > − 2 to < − 3, while that for the blood–brain barrier (BBB) permeability is > − 0.3 to < − 1. The BBB permeability for these small molecules was found to be − 1 except for compounds Pred9, Pred10, Pred11, Pred15, Pred27, and Pred28, which was > − 1. This indicates that all of the compounds, except for compounds Pred9, Pred10, Pred11, Pred15, Pred27, and Pred28, only partially infiltrate or permeate the BBB. Except for compounds Pred2, Pred9, Pred10, Pred11, and Pred27, all of the compounds had a CNS permeability value of < − 3, indicating that they only partially infiltrate or permeate the CNS.
The cytochrome (CYP) is recognized as being crucial for the body's enzymatic breakdown and small molecule metabolism. As a result, it is important to consider how these small molecules are metabolized and processed by the human body. The body's mechanisms for breaking down and metabolizing small compounds include CYP1A2, 2C9, 2C19, 2D6, and 3A4, with CYP3A4 playing the most important role (a good small molecule is expected to be both a substrate and inhibitor of CYP3A4)26. The most popular hits were all CYP3A4 substrates and inhibitors. This led to more confirmation that the body can break down these small compounds. Excretion/total clearance, which specifies the connection/relationship between the rate of these small molecules' elimination and concentration inside the body, is another crucial consideration. The best-hit compounds showed a higher excretion value and were tested within the acceptable range for a medication. The comprehensive toxicity and pharmacokinetic evaluation detailed in Table S7 reveals a mixed safety profile for the best-identified hit drugs. While none of the compounds displayed mutagenicity, suggesting a low risk of genetic toxicity which bolsters their overall safety profiles, several compounds, specifically Pred1, Pred2, Pred3, Pred4, Pred10, Pred12, Pred14, and Pred15, exhibited potential hepatotoxic effects. These findings necessitate further in-depth investigations, including in vitro and in vivo studies, to thoroughly understand the implications for liver health and to mitigate any adverse effects. Moreover, only Pred11 was flagged for potential carcinogenic risks, indicating a need for extended research and evaluation through long-term animal studies to ascertain the full extent of this risk. Despite these concerns, the broad ADMET properties of these compounds were typical, aligning with expected pharmacokinetic profiles and confirming that none were overtly harmful.
Molecular docking study
An Intel (R) core (TM) i5 10th Gen processor-equipped microcomputer was used to carry out the computations for molecular docking. The operating system for all apps was Windows 10, 64-bit version 2020. The software AutoDockTools version 1.5.7 was used to carry out the molecular docking33, this employs the Genetic algorithm-based trajectory modeling technique. Additionally, we used Biovia Discovery Studio version 2021 software44 to display the many interactions that have been created between the ligands and the target active site.
Molecular docking has become an increasingly popular approach for the development of new drugs, in part because of the favorable time and pecuniary costs of in silico drug screening compared with traditional laboratory experiments. In this study, the fourteen designed compounds were docked, using AutoDock 1.5.7 software, with the crystal structure 1SA0 of the target protein’s binding site31. To perform docking by re-docking the co-crystallized ligand at the Tubulin enzyme Fig. 4 represented the superimposed view of docked conformation45,46,47,48,49 and the co-crystallized ligand and the RMSD value is 1.084 Å. The RMSD (Root Mean Square Distance) of the docked co-crystallized ligand was within the reliable range of 2 Å. The binding affinity of the designed compounds with the receptors 1SA0 was reported in Table 6.

Re-docking pose with an RMSD value of 1.084 Å (Green = native ligand, blue = docked ligand).
Microtubule protein A and B chains: structural and functional insights
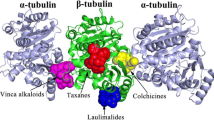
Microtubules, essential components of the cytoskeleton, are composed of α-Tubulin (A chain) and β-Tubulin (B chain) that form heterodimers. α-Tubulin forms the stable minus end of the microtubule and harbors a non-exchangeable GTP molecule, providing structural stability. In contrast, β-Tubulin constitutes the dynamic plus end, featuring an exchangeable GTP site crucial for microtubule dynamics through GTP hydrolysis post-polymerization. This differential GTP activity between the chains underpins the dynamic instability vital for cellular processes such as mitosis and intracellular transport. Given β-Tubulin's pivotal role in these processes and its drug target accessibility, our study focuses on inhibitors that target β-Tubulin to disrupt microtubule dynamics, offering potential therapeutic strategies against rapidly dividing cancer cells.
All the designed compounds exhibited docking score values between − 8.5 and − 9.6 kcal/mol, having lower binding energies than the co-crystallized ligand -7.9 kcal/mol. The compounds Pred3, Pred5, Pred12, Pred13 and Pred28 showed the best binding score with the protein Tubulin. The best conformation from Autodock resulted with good binding affinity of compound Pred28 with 1SA0 protein as − 9.6 kcal/mol, based on Table S8 and Fig. S1, has six conventional hydrogen bonds interactions with Lys (B: 254), Gly (A: 146), Gly (A: 142), Thr (A: 145), Gln (A: 11), Asn (A: 101), and H-donor, two carbon hydrogen bonds with Lys (B: 254) and Gln (A: 11), two halogen type fluorine bonds with Glu (A: 183) and Glu (A: 142), hydrophobic interactions with Lys (B: 254), Ala (A: 12), Ile (A: 171), Pro (A: 173), and Leu (B: 248) residues.
The compound Pred13 formed six conventional hydrogen bonds interactions with Gly (A: 144), Asn (A: 101), Asp (A: 69), Gly (A: 142), Lys (B: 254), and Thr (A: 145), two carbon hydrogen bonds with Lys (B: 254) and Gln (A: 11), one halogen bond with Glu (A: 183), it exhibited also hydrophobic interactions with Tyr (A: 224), Lys (B: 254), Leu (B: 248), Ala (A: 12), Ile (A: 171), and Pro (A: 173) residues.
The compound Pred12 formed five conventional hydrogen bonds interactions with Gly (A: 146), Asn (A: 101), Thr (A: 145), Gln (A: 11), and Ala (A: 12), one carbon hydrogen bond with Gln (A: 11), hydrophobic interactions with Ala (A: 12), Tyr (A: 224), Leu (B: 248), Ala (A: 12), and Ile (A: 171) residues.
The compound Pred5 formed five conventional hydrogen bonds interactions with Gly (A: 146), Asn (A: 101), Tyr (A: 224), Ser (A: 140), and Lys (B: 254), one carbon hydrogen bond Pro (A: 173), one halogen bond with Asn (A: 206), it exhibited also hydrophobic interactions with Gly(A: 143), Gly (A: 10), and Ala (A: 12) residues.
The compound Pred3 formed six conventional hydrogen bonds interactions with Gly (A: 146), Asn (A: 101), Tyr (A: 224), Glu (A: 183), Lys (B: 254), and Ser (A: 140), three carbon hydrogen bonds with Pro (A: 173), Glu (A: 71), and Asp (A: 98), two halogen bonds with Asn (A: 206) and Tyr (A: 172), hydrophobic interactions with Gly (A: 143), Gly (A: 10), and Ala (A: 12) residues.
The compound co-crystallized ligand formed two carbon hydrogen bonds interactions with Ser (A: 178) and Val (B: 315), one Pi-Sulfur bond with Met (B: 259), hydrophobic interactions with Ala (B: 316), Ala (A: 180), Lys (B: 352), Leu (B: 248), Ala (A: 180), and Lys (B: 352) residues.
A significant aspect of our study lies in correlating the molecular descriptors used in the QSAR model with the binding modes observed in the docking studies. For example, the descriptor 'χ' (absolute electronegativity) correlates with the affinity of the ligand for the negatively charged regions of the protein active site. On the other hand, 'LogS' (solubility log) is reflective of the hydrophobic interactions that are crucial for the stability of the ligand–protein complex. Thus, each descriptor serves not only as a statistical variable but also as a biologically relevant parameter that can be linked to specific aspects of ligand–protein interactions.
We fully acknowledge that while computational methods like QSAR modeling and molecular docking are valuable tools for predicting the biological activity of compounds, they are not a substitute for experimental validation. In an ideal scenario, the next step would involve the chemical synthesis and experimental testing of the predicted 1,2,4-triazine-3(2H)-one derivatives. Due to limitations in scope and resources, this was not possible within the confines of the present study. However, we strongly advocate for such experimental validation in future work to confirm the predicted activities of these promising compounds.
Molecular dynamic simulation
In this study, Molecular Dynamics Simulations (MDS) were conducted for 100 ns to investigate the binding interactions, structural dynamics, and flexibility of Tubulin when bound to the top three hits (Pred3, Pred13, and Pred28). Key metrics, including Root Mean Square Deviation (RMSD), Root Mean Square Fluctuation (RMSF), and Radius of Gyration (Rg), were calculated from the trajectory data collected over the 100-ns period50.
RMSD calculation
The root mean square deviation (RMSD) is the most important indicator of a biomolecular system's structural stability. The computer-aided drug design community believes that a lower RMSD value signifies a more stable system. In contrast, complexes with larger RMSD values are less likely to be stable51. The RMSD graph in Fig. 5A shows that, except for the complex formed by Pred3-Tubulin, all the remaining protein–ligand entities exhibit lower fluctuations in their spectra. This implies that their conformational dynamics have been minimally perturbed during the simulation. The average RMSD values for Pred3, Pred13, Pred28, and Colchicine (with their receptors) are calculated to be 0.65 nm, 0.34 nm, 0.29 nm, and 0.34 nm, respectively. This indicates that Pred28, with its lower RMSD value, is most similar to the standard Colchicine drug and may represent the most stable drug candidate among the promising inhibitors. This finding aligns with the docking simulation results, where Pred28 exhibited the best binding affinity (Table 6). However, the RMSD measurements are insufficient to ensure the stability of the system because they do not account for fluctuations in certain sections of the structure. Therefore, an RMSF diagram was also constructed to evaluate the atomic variations of each residue along the trajectory.

The results of the molecular dynamics study: (A) Time evolution of the backbone of three best hits inhibitors and the standard (Colchicine); (B); RMSF spectra of three promising inhibitors and the standard (Colchicine); (C) The comparative Radius of gyration values for the target protein with three best hits inhibitors and the standard (Colchicine); (D) The comparative hydrogen bonds for the target protein with the reference drug (Colchicine) and three best hits.
RMSF calculation
For a comprehensive description of residue stability in MD simulation, RMSF measurement is the gold standard52. In the simulation, this approach assesses protein flexibility and can identify residues with high or low flexibility. Root-mean-square-fluctuations (RMSF) were calculated for each complex to reveal which residues changed the most during the MD simulation47,53. Higher RMSF values for biomolecular system corresponds to a lower residual stability and vice versa. As demonstrated in Fig. 5B, except the Pred3, all the remaining proposed compound exhibit a very similar RMSF pattern to the standard drug. The average RMSF values are 0.31 nm for Pred3, 0.16 nm for Pred13, 0.15 nm for Pred28, and 0.15 nm for Colchicine. Notably, Pred28, which has the lowest average RMSF value, indicates it may be a better inhibitor compared to the other compounds.
Radius of gyration analysis
We investigated how the binding of various ligands influenced the overall compactness of the protein's structure48. To achieve this, we calculated the radius of gyration (Rg) as a function of time. Ligands with higher Rg values tend to be more flexible and, consequently, less stable. Conversely, lower Rg values indicate a denser and more compact conformation38. Among the complexes examined (Fig. 5C), the Pred3 exhibited the largest radius of gyration, while compound Pred28 had the smallest, indicating it is the most stable. The average Rg values for protein-Reference drug complexe and protein-designed molecule complexes (including Pred03, Pred13, and Pred28) were 3.11 nm, 3.35, 3.07 nm, and 3.06 nm, respectively. This suggests that complex Pred28 is the most the most compact biomolecular system.
H-BOND analysis
In a water environment, hydrogen bonds and their relative strength play a crucial role in protein–ligand interactions, especially when the mechanism involves hydrolysis, where water is essential for breaking down a chemical54. These hydrogen bonds form when an electronegative atom from a hydrogen-bond acceptor comes into contact with a hydrogen atom directly bonded to an electronegative atom from a hydrogen-bond donor55.
In this study, we examined the intermolecular hydrogen bonds formed between Tubulin and the selected compounds (Pred3, Pred13, Pred28, and Colchicine). The results, presented in Fig. 5D, show that Pred28 and Colchicine have the most significant H-bond spectra among all the simulated compounds, with average H-bonds of 1.75 and 1.94, respectively. In contrast, Pred3 and Pred13 formed fewer intermolecular H-bonds with their receptor, averaging 1.37 and 1.02 H-bonds, respectively. This finding aligns with earlier RMSD and RMSF analyses, further supporting that Pred28 is the best compound, as the H-bonding spectrum results corroborate this conclusion.
Conclusion
In this study, we have demonstrated the potential of 1,2,4-triazine-3(2H)-one derivatives as effective Tubulin inhibitors through a comprehensive application of QSAR modeling, molecular docking, and molecular dynamics simulations. These findings not only enhance our understanding of the chemical interactions necessary for Tubulin inhibition but also highlight the robust potential of these compounds to serve as templates for developing new anticancer drugs. The integration of multiple computational techniques has allowed for a nuanced assessment of the compounds' interactions with Tubulin, revealing that among the tested derivatives, Pred28 emerged as a particularly promising candidate due to its stability and strong binding affinity. Our study extends beyond the conventional discovery phase to provide a detailed characterization of the dynamic interactions and stability profiles of these inhibitors, setting the stage for future in vitro and in vivo evaluations. Furthermore, our research contributes to the ongoing efforts to optimize anticancer therapies by providing a clearer pathway for the rational design of drug candidates. By identifying and characterizing novel inhibitors that can potentially overcome resistance mechanisms or reduce adverse effects associated with current treatments, this work paves the way for more targeted and effective cancer treatment strategies. Looking forward, the promising results obtained from Pred28 warrant further investigation to confirm its therapeutic value and explore its efficacy in clinical settings. Additionally, the methodologies applied in this study can be adapted to other therapeutic targets and diseases, underscoring the versatility and impact of computational approaches in modern drug discovery. In conclusion, the findings from this study not only advance our knowledge of the molecular underpinnings of Tubulin inhibition but also provide a solid foundation for the future development of more effective and safer anticancer therapies. As we continue to explore these novel compounds, it is our hope that they will contribute to a more effective arsenal against cancer, ultimately improving patient outcomes.
Data availability
All available data can be found within the article and in the supplementary file. Further inquiries can be directed to the corresponding author.
References
World Health Organization. World health statistics 2023: monitoring health for the sdgs, sustainable development goals https://www.who.int/publications/book-orders (2023).
Singh, P. et al. Tailoring the substitution pattern on 1,3,5-triazine for targeting cyclooxygenase-2: Discovery and structure-activity relationship of triazine-4-aminophenylmorpholin-3-one hybrids that reverse algesia and inflammation in Swiss albino mice. J. Med. Chem. 61, 7929–7941. https://doi.org/10.1021/acs.jmedchem.8b00922 (2018).
Zaki, I. et al. Design, synthesis and screening of 1, 2, 4-triazinone derivatives as potential antitumor agents with apoptosis inducing activity on MCF-7 breast cancer cell line. Eur. J. Med. Chem. 156, 563–579. https://doi.org/10.1016/j.ejmech.2018.07.003 (2018).
Prota, A. E. et al. Structural basis of tubulin tyrosination by tubulin tyrosine ligase. J. Cell Biol. 200, 259–270. https://doi.org/10.1083/jcb.201211017 (2013).
Karimikia, E. et al. Colchicine-like β-acetamidoketones as inhibitors of microtubule polymerization: Design, synthesis and biological evaluation of in vitro anticancer activity, Iran. J. Basic Med. Sci. 22, 1138–1146. https://doi.org/10.22038/ijbms.2019.34760.8242 (2019).
Yang, X. H. et al. Synthesis, biological evaluation, and molecular docking studies of 1,3,4-thiadiazol-2-amide derivatives as novel anticancer agents. Bioorganic Med. Chem. 20, 2789–2795. https://doi.org/10.1016/j.bmc.2012.03.040 (2012).
Braga, D., Grepioni, F. & Desiraju, G. R. Crystal engineering and organometallic architecture. Chem. Rev. 98, 1375–1405. https://doi.org/10.1021/cr960091b (1998).
Er-rajy, M. et al. Design of novel anti-cancer agents targeting COX-2 inhibitors based on computational studies. Arab. J. Chem. 16, 105193. https://doi.org/10.1016/j.arabjc.2023.105193 (2023).
Er-Rajy, M., El Fadili, M., Faris, A., Zarougui, S. & Elhallaoui, M. Design of potential anti-cancer agents as COX-2 inhibitors, using 3D-QSAR modeling, molecular docking, oral bioavailability proprieties, and molecular dynamics simulation. Anticancer Drugs. 35, 117–128. https://doi.org/10.1097/CAD.0000000000001492 (2024).
Er-rajy, M. et al. 2D-QSAR modeling, drug-likeness studies, ADMET prediction, and molecular docking for anti-lung cancer activity of 3-substituted-5-(phenylamino) indolone derivatives. Struct. Chem. https://doi.org/10.1007/s11224-022-01913-3 (2022).
Er-rajy, M., El Fadili, M., Mujwar, S., Zarougui, S. & Elhallaoui, M. Design of novel anti-cancer drugs targeting TRKs inhibitors based 3D QSAR, molecular docking and molecular dynamics simulation. J. Biomol. Struct. Dyn. 41, 11657–11670. https://doi.org/10.1080/07391102.2023.2170471 (2023).
Norinder, U. & Bergström, C. A. S. Prediction of ADMET properties. ChemMedChem. 1, 920–937. https://doi.org/10.1002/cmdc.200600155 (2006).
Eissa, I. H. et al. Design and discovery of new antiproliferative 1,2,4-triazin-3(2H)-ones as tubulin polymerization inhibitors targeting colchicine binding site. Bioorg. Chem. https://doi.org/10.1016/j.bioorg.2021.104965 (2021).
Frisch, M. J. et al. Gaussian 09, Revision B.01, Gaussian 09, Revis. B.01, 1–20. citeulike-article-id:9096580 (Gaussian, Inc., 2009).
Lee, C., Yang, W. & Parr, R. G. Development of the Colle-Salvetti correlation-energy formula into a functional of the electron density. Phys. Rev. B. Condens. Matter. 37, 785–789. https://doi.org/10.1103/PHYSREVB.37.785 (1988).
Hariharan, P. C. & Pople, J. A. The influence of polarization functions on molecular orbital hydrogenation energies. Theor. Chim. Acta. 28, 213–222. https://doi.org/10.1007/BF00533485 (1973).
Kerraj, S., Salah, M., Belaaouad, S. & Mohammed, M. Effects of chelate ligands containing NN, PN, and PP on the performance of half-sandwich ruthenium metal complexes as sensitizers in dye sensitized solar cells (DSSCs): Quantum chemical investigation. Polyhedron. 230, 116190. https://doi.org/10.1016/j.poly.2022.116190 (2023).
Kerraj, S. et al. Theoretical study of photovoltaic performances of Ru, Rh and Ir half sandwich complexes containing N, N chelating ligands in dye-sensitized solar cells (DSSCs). DFT and TD-DFT investigation. Comput. Theor. Chem. 1209, 113630. https://doi.org/10.1016/j.comptc.2022.113630 (2022).
Kerraj, S. et al. Computational analysis of ligand design for Ru half-sandwich sensitizers in bulk heterojunction (BHJ) solar cells: Exploring the role of –NO2 group position and π-conjugation in optimizing efficiency. J. Indian Chem. Soc. 101, 101148. https://doi.org/10.1016/j.jics.2024.101148 (2024).
ChemOffice, PerkinElmer Informatics (n.d.). http://www.cambridgesoft.com (2020).
David, C. C. & Jacobs, D. J. Chapter 11 the Essential Dynamics of Proteins. https://doi.org/10.1007/978-1-62703-658-0 (2014).
XLSTAT version 2019.1, XLSTAT, Your data analysis solution. (n.d.). https://www.xlstat.com/fr/articles/xlstat-version-2019-1.
Chtita, S., Bouachrine, M. & Lakhlifi, T. Basic approaches and applications of {QSAR}/{QSPR} methods, Rev. Interdiscip. 1 (2016).
Chtita, S. et al. QSAR study of unsymmetrical aromatic disulfides as potent avian SARS-CoV main protease inhibitors using quantum chemical descriptors and statistical methods. Chemom. Intell. Lab. Syst. https://doi.org/10.1016/j.chemolab.2021.104266 (2021).
Ojha, P. K., Mitra, I., Das, R. N. & Roy, K. Further exploring rm2 metrics for validation of QSPR models. Chemom. Intell. Lab. Syst. 107, 194–205. https://doi.org/10.1016/j.chemolab.2011.03.011 (2011).
Baassi, M. et al. Towards designing of a potential new HIV-1 protease inhibitor using QSAR study in combination with molecular docking and molecular dynamics simulations. PLoS ONE. 18, e0284539. https://doi.org/10.1371/journal.pone.0284539 (2023).
Olasupo, S. B., Uzairu, A., Shallangwa, G. & Uba, S. QSAR analysis and molecular docking simulation of norepinephrine transporter (NET) inhibitors as anti-psychotic therapeutic agents. Heliyon. 5, e02640. https://doi.org/10.1016/j.heliyon.2019.e02640 (2019).
Daoui, O. et al. Design of novel carbocycle-fused quinoline derivatives as potential inhibitors of lymphoblastic leukemia cell line MOLT-3 using 2D-QSAR and ADME-Tox studies. RHAZES Green Appl. Chem. 14, 36–61 (2022).
Gramatica, P. Principles of QSAR models validation: Internal and external. QSAR Comb. Sci. 26, 694–701. https://doi.org/10.1002/qsar.200610151 (2007).
Netzeva, T. I. et al. Current status of methods for defining the applicability domain of (quantitative) structure-activity relationships. ATLA Altern. Lab. Anim. 33, 155–173. https://doi.org/10.1177/026119290503300209 (2005).
Ravelli, R. B. G. et al. Insight into tubulin regulation from a complex with colchicine and a stathmin-like domain. Nature. 428, 198–202. https://doi.org/10.1038/nature02393 (2004).
Trott, O. & Olson, A. J. AutoDock Vina: Improving the speed and accuracy of docking with a new scoring function, efficient optimization, and multithreading. J. Comput. Chem. https://doi.org/10.1002/JCC.21334 (2009).
Download AutoDock4 – AutoDock, (n.d.). https://autodock.scripps.edu/download-autodock4/ (Accessed 30 Dec 2022).
Al-Khafaji, K. & Taskin Tok, T. Molecular dynamics simulation, free energy landscape and binding free energy computations in exploration the anti-invasive activity of amygdalin against metastasis. Comput. Methods Programs Biomed. 195, 105660. https://doi.org/10.1016/j.cmpb.2020.105660 (2020).
Chen, K., Sun, M., Chen, H., Lee, C. & Chen, C. Y. Potential smoothened inhibitor from traditional Chinese medicine against the disease of diabetes. Obes. Cancer https://doi.org/10.1155/2014/873010 (2014).
Grosdidier, L., Michielin, O., Zoete, V. & Cuendet, M. A. SwissParam: A fast force field generation tool for small organic. Molecules https://doi.org/10.1002/jcc (2011).
Mark, P. & Nilsson, L. Structure and dynamics of the TIP3P, SPC, and SPC/E water models at 298 K. J. Phys. Chem. A 105, 9954–9960. https://doi.org/10.1021/jp003020w (2001).
Baammi, S., Daoud, R. & El Allali, A. In silico protein engineering shows that novel mutations affecting NAD+ binding sites may improve phosphite dehydrogenase stability and activity. Sci. Rep. 13, 1–18. https://doi.org/10.1038/s41598-023-28246-3 (2023).
Golbraikh, A. & Tropsha, A. Predictive QSAR modeling based on diversity sampling of experimental datasets for the training and test set selection. J. Comput. Aided. Mol. Des. 16, 357–369. https://doi.org/10.1023/A:1020869118689 (2002).
Moussaoui, M. et al. In silico design of novel CDK2 inhibitors through QSAR, ADMET, molecular docking and molecular dynamics simulation studies. J. Biomol. Struct. Dyn. https://doi.org/10.1080/07391102.2023.2212304 (2023).
Thompson, C. G., Kim, R. S., Aloe, A. M. & Becker, B. J. Extracting the variance in flation factor and other multicollinearity diagnostics from typical regression results. Basic Appl. Soc. Psych. 39, 81–90. https://doi.org/10.1080/01973533.2016.1277529 (2017).
Soufi, H. et al. Multi-combined QSAR, molecular docking, molecular dynamics simulation, and ADMET of Flavonoid derivatives as potent cholinesterase inhibitors. J. Biomol. Struct. Dyn. 0, 1–15. https://doi.org/10.1080/07391102.2023.2238314 (2023).
Nour, H. et al. 2D-QSAR and molecular docking studies of carbamate derivatives to discover novel potent anti-butyrylcholinesterase agents for Alzheimer’s disease treatment. Bull. Korean Chem. Soc. https://doi.org/10.1002/BKCS.12449 (2021).
Free Download: BIOVIA Discovery Studio Visualizer - Dassault Systèmes, (n.d.). https://discover.3ds.com/discovery-studio-visualizer-download (Accessed 9 Apr 2023).
Mahmoudi, M. et al. Structural evolution of delta lineage of SARS-CoV-2. Int. J. Biol. Macromol. 226, 1116–1140. https://doi.org/10.1016/j.ijbiomac.2022.11.227 (2023).
Chebaibi, M. et al. Ethnobotanical study of medicinal plants used against COVID-19. Medicine 2022, 1–6 (2022).
Baammi, S., El Allali, A. & Daoud, R. Unleashing nature’s potential: A computational approach to discovering novel VEGFR-2 inhibitors from African natural compound using virtual screening, ADMET analysis, molecular dynamics, and MMPBSA calculations. Front. Mol. Biosci. https://doi.org/10.3389/fmolb.2023.1227643 (2023).
Baammi, S., ElAllali, A. & Daoud, R. Potent VEGFR-2 inhibitors for resistant breast cancer: A comprehensive 3D-QSAR, ADMET, molecular docking and MMPBSA calculation on triazolopyrazine derivatives. Front. Mol. Biosci. https://doi.org/10.3389/fmolb.2023.1288652 (2023).
Tabti, K., Baammi, S., Sbai, A., Maghat, H. & Bouachrine, M. Molecular modeling study of pyrrolidine derivatives as novel myeloid cell leukemia-1 inhibitors through combined 3D-QSAR, molecular docking, ADME/Tox and MD simulation techniques ADME/Tox and MD simulation techniques. J. Biomol. Struct. Dyn. 0, 1–17. https://doi.org/10.1080/07391102.2023.2183032 (2023).
Broni, E., Kwofie, S. K., Asiedu, S. O., Miller, W. A. & Wilson, M. D. A molecular modeling approach to identify potential antileishmanial compounds against the cell division cycle (Cdc)-2-related kinase 12 (crk12) receptor of leishmania donovani. Biomolecules. 11, 1–32. https://doi.org/10.3390/biom11030458 (2021).
Yang, S. & Kar, S. Protracted molecular dynamics and secondary structure introspection to identify dual-target inhibitors of Nipah virus exerting approved small molecules repurposing. Sci. Rep. 14, 1–14. https://doi.org/10.1038/s41598-024-54281-9 (2024).
Wang, S. et al. Identification of new EGFR inhibitors by structure-based virtual screening and biological evaluation. Int. J. Mol. Sci. https://doi.org/10.3390/ijms25031887 (2024).
Sargsyan, K., Grauffel, C. & Lim, C. How molecular size impacts RMSD applications in molecular dynamics simulations. J. Chem. Theory Comput. 13, 1518–1524. https://doi.org/10.1021/acs.jctc.7b00028 (2017).
Ashiru, M. A. et al. Identification of EGFR inhibitors as potential agents for cancer therapy: Pharmacophore-based modeling, molecular docking, and molecular dynamics investigations. J. Mol. Model. 29, 1–12. https://doi.org/10.1007/S00894-023-05531-6/METRICS (2023).
Gao, Y., Mei, Y. & Zhang, J. Z. H. Treatment of hydrogen bonds in protein simulations. Adv. Mater. Renew. Hydrog. Prod. Storage Util. https://doi.org/10.5772/61049 (2015).
Acknowledgements
We would like to thank all the members of the physical chemistry of materials laboratory and the heads of the chemistry department of the Ben M’Sick Faculty of Science for their encouragement and help in carrying out this work.
Author information
Authors and Affiliations
Contributions
M.M, S.Bammi: conceptualization, data curation, formal analysis, investigation, methodology, validation, writing—original draft, writing—review and editing, software. H.S, M.B: data curation, writing—review and editing. A.E, R.D: data curation, formal analysis, investigation, methodology, validation, writing–review and editing, resources. ME.B: conceptualization, data curation, formal analysis, investigation, methodology, resources, supervision, validation, writing–original draft, writing—review and editing. S.Belaaouad: conceptualization, data curation, formal analysis, investigation, methodology, resources, supervision, validation, writing—original draft, writing—review and editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Moussaoui, M., Baammi, S., Soufi, H. et al. QSAR, ADMET, molecular docking, and dynamics studies of 1,2,4-triazine-3(2H)-one derivatives as tubulin inhibitors for breast cancer therapy. Sci Rep 14, 16418 (2024). https://doi.org/10.1038/s41598-024-66877-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-66877-2
- Springer Nature Limited